实验五-编译-用语法制导方式生成中间代码生成器
- 格式:doc
- 大小:198.00 KB
- 文档页数:24

编译原理中间代码生成在编译原理中,中间代码生成是编译器的重要阶段之一、在这个阶段,编译器将源代码转换成一种中间表示形式,这种中间表示形式通常比源代码抽象得多,同时又比目标代码具体得多。
中间代码既能够方便地进行优化,又能够方便地转换成目标代码。
为什么需要中间代码呢?其一,中间代码可以方便地进行编译器优化。
编译器优化是编译器的一个核心功能,它能够对中间代码进行优化,以产生更高效的目标代码。
在中间代码生成阶段,编译器可以根据源代码特性进行一些优化,例如常量折叠、公共子表达式消除、循环不变式移动等。
其二,中间代码可以方便地进行目标代码生成。
中间代码通常比较高级,比目标代码更具有表达力。
通过中间代码,编译器可以将源代码转换成与目标机器无关的形式,然后再根据目标机器的特性进行进一步的优化和转换,最终生成目标代码。
中间代码生成的过程通常可以分为以下几步:1.词法分析和语法分析:首先需要将源代码转换成抽象语法树。
这个过程涉及到词法分析和语法分析两个步骤。
词法分析将源代码划分成一个个的词法单元,例如标识符、关键字、运算符等等。
语法分析将词法单元组成树状结构,形成抽象语法树。
2.语义分析:在语义分析阶段,编译器会对抽象语法树进行静态语义检查,以确保源代码符合语言的语义规定。
同时,还会进行类型检查和类型推导等操作。
3.中间代码生成:在中间代码生成阶段,编译器会将抽象语法树转换成一种中间表示形式,例如三地址码、四元式、特定的中间代码形式等。
这种中间表示形式通常比较高级,能够方便进行编译器的优化和转换。
4.中间代码优化:中间代码生成的结果通常不是最优的,因为生成中间代码时考虑的主要是功能的正确性,并没有考虑性能的问题。
在中间代码生成之后,编译器会对中间代码进行各种优化,以产生更高效的代码。
例如常量折叠、循环优化、死代码删除等等。
5.中间代码转换:在完成了中间代码的优化之后,编译器还可以对中间代码进行进一步的转换。
这个转换的目的是将中间代码转换成更具体、更低级的形式,例如目标机器的汇编代码。



中间代码生成实习指导编译器里核心的数据结构之一就是中间代码(Intermediate representation,简称IR)。
中间代码应当包含哪些信息,这些信息又应当有怎样的内部表示将会极大地影响到编译器的代码复杂程度、编译器的运行效率以及编译出来的目标代码的运行效率。
广义地说,编译器中根据输入程序所构造出来的绝大多数结构都被称为中间代码(或者更精确地译作“中间表示”)。
例如,我们之前所构造的词法流、语法树、带属性的语法树等等,都可以看作是一种中间代码。
使用中间代码的主要原因当然是为了方便我们在编程时的各种操作,毕竟如果我们在需要有关输入程序的任何信息时都只能重新去读入并处理输入程序的源代码的话,不仅会使得编译器的编写变得麻烦,也会大大减慢其运行效率。
况且经过前面两次实习我们都应该清楚,输入程序里包含的绝大部分编译器需要的信息都没有被显式地表达出来。
狭义地说,中间代码是编译器从源语言到目标语言之间采用的一种过渡性质的代码形式(这时它常被称作intermediate code)。
看到这里你可能会产生疑问:为什么编译器不能直接把输入程序直接翻译成目标代码,而是要额外地多一道手续,引入中间代码呢?这难道不是自己给自己找麻烦吗?实际上,引入中间代码有两个主要的好处:一方面,中间代码将编译器自然地分成了前端和后端两个部分。
当我们需要改变编译器的源语言或者目标语言时,如果采用中间代码,那么我们只需要替换原有编译器的前端或者后端,而不需要重写整个编译器。
另一方面,即使源语言和目标语言是固定的,采用中间代码也有利于编译器的模块化。
人们将编译器设计中的那些复杂但相关性又不是很大的任务分别放在前端和后端的各个模块之中,这样既简化了模块内部的处理,又使得我们能单独对每个模块进行调试与修改而不影响到其它模块。
下文中,如果不是特别说明,那么所有出现的“中间代码”都指的是本段所介绍的狭义的中间代码。
中间代码的分类中间代码的设计可以说更多的是一门艺术而不是技术。


第1篇一、实验目的本次实验旨在通过编写中间生成代码,加深对编译原理中中间代码生成过程的理解,掌握中间代码的表示方法、生成算法以及优化技术,并能够将高级语言翻译成相应的中间代码。
二、实验环境1. 操作系统:Windows 102. 编程语言:Java3. 开发工具:Eclipse三、实验内容1. 中间代码表示方法(1)选择中间代码表示方法:本次实验选择四元式作为中间代码的表示方法。
(2)定义四元式结构:四元式由四个字段组成,分别为操作符(OP)、操作数1(ARG1)、操作数2(ARG2)和结果(RESULT)。
2. 中间代码生成算法(1)选择源语言:以C语言为例,编写一个简单的C程序。
(2)编写分析器:对C程序进行词法分析、语法分析,生成抽象语法树(AST)。
(3)遍历AST:根据AST的结构,生成相应的中间代码。
(4)中间代码优化:对生成的中间代码进行优化,提高程序执行效率。
3. 实验步骤(1)创建Java项目,导入必要的库。
(2)编写词法分析器:识别C语言中的关键字、标识符、运算符、常数等。
(3)编写语法分析器:根据词法分析器的结果,构建抽象语法树(AST)。
(4)遍历AST:根据AST的结构,生成四元式中间代码。
(5)中间代码优化:对生成的中间代码进行优化。
(6)生成目标代码:将优化后的中间代码翻译成目标代码。
四、实验结果与分析1. 中间代码表示方法(1)四元式表示方法:本次实验采用四元式表示中间代码,具有以下特点:- 结构简单,易于理解。
- 便于优化。
- 可用于多种目标代码生成。
(2)四元式示例:```OP = ADDARG1 = t1ARG2 = t2RESULT = t3```2. 中间代码生成算法(1)词法分析器:识别C语言中的关键字、标识符、运算符、常数等。
(2)语法分析器:构建抽象语法树(AST),表示C程序的结构。
(3)遍历AST:根据AST的结构,生成四元式中间代码。
(4)中间代码优化:对生成的中间代码进行优化,提高程序执行效率。



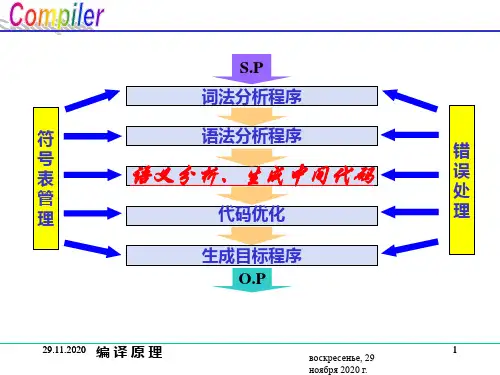
编译原理-第⼆章⼀个简单的语法指导编译器-2.8⽣成中间代码⽣成中间代码:两种中间表⽰形式:树形结构:语法分析树、抽象语法树抽象语法树的构造:可以为任意的构造创建抽象语法树,每个构造⽤⼀个结点表⽰,其⼦结点代表此构造中具有语义含义的组成部分在语法分析过程中,将创建抽象语法树的结点来表⽰有意义的程序构造,随着分析的进⾏,信息以与结点相关的属性的形式被添加到这些结点上例:树节点:类Node⼦类:expr(代表各种表达式)、stmt(代表各种语句)语句的语法树:⼀个叶⼦结点null表⽰⼀个空语句序列运算符seq表⽰⼀个语句序列线性结构:三地址代码三地址代码:由⼀个基本程序步骤(如将两个值相加)组成的序列,⽆层次化的结构,组成:由x = y op z形式的指令组成的序列,x、y和z可以是名字,常量或由编译器⽣成的临时量,⽽op表⽰⼀个运算符语句的翻译:通过跳转指令实现语句内部的控制流,就可以将语句转换成为三地址代码使⽤⼀些跳转指令在语句的各个组成部分对应的代码之间进⾏跳转例:对 if expr then stmt1的翻译:跳转指令:if False x goto after类if是类stmt的⼀个⼦类,stmt的每⼀个⼦类都有⼀个构造函数及⼀个为此类语句⽣成三地址代码的函数gen构造函数if构建了if语句的语法树特点,有两个参数,⼀个表达式结点x和⼀个语法树结点y,分别被存放在属性E和S中同时,构造函数调⽤了函数newlable()给属性after赋予⼀个唯⼀的新标号⼀旦源程序的整个抽象语法树被创建完毕,函数gen在此抽象语法树的根结点处被调⽤表达式的翻译:Access(y,z)表⽰数组操作:y数组名,z数组下标例:改进:优化阶段减少拷贝指令的数⽬充分考虑上下⽂的情况作⽤:优化代码,可以将组成程序很长的三地址语句序列分解为基本块,“基本块”就是⼀个总是逐个顺序执⾏的语句序列,执⾏时不会出现分⽀跳转静态检查:作⽤:编译器前端会检查源程序是否遵循源语⾔的语法和语义规则,确保⼀些特定类型的程序错误,包括类型不匹配,能在编译过程中被检测并报告组成:语法检查:语法要求⽐⽂法中的要求多,它们并不包括在⽤于语法分析的⽂法中类型检查:确保⼀个构造的类型符合其上下⽂对它的期望⼀种语⾔的类型规则确保⼀个运算符或函数被应⽤到类型和数量都正确的运算分量中类型检查规则按照抽象语法中运算符/运算分量的结构进⾏描述参考——《编译原理(第⼆版)》。

。 -可编辑修改- 实验5 用语法制导方式生成中间代码生成器 一、实验目的 掌握语法制导定义和翻译的原理和技术,在语法分析器的基础上,加上语义分析,构造一个中间代码生成器。 二、实验内容 在实验四生成的语法分析器基础上加入语义动作,将源程序翻译为对应的中间代码序列。
三、实验要求 1. 个人完成,提交实验报告。实验报告必须包括设计的思路,以及测试报告(输入测试例子,输出结果)。 2. 实验报告中给出采用测试源代码片断,及其对应的三地址码形式(内部表示形式可以自行考虑)。 例如,程序片断 。
-可编辑修改- 对应的中间代码为:
四、实验过程 本次实验运用flex和bison工具进行中间代码的生成。并自动生成中间代码。 1. 首先创建一个example文件夹,该文件夹中包含有flex.exe 2. 用文本编译器编辑相应的flex文件mylex.l,此次mylex.l可以在上次实验的l文件上做一些修改,再利用flex将l文件生成相应的lex.yy.c程序,mylex.l的代码如下所示: mylex.l 。 -可编辑修改- %{ #include "myyacc.tab.h" %} delim [ \t\n\r] ws {delim}+ letter [A-Za-z] digit [0-9] id {letter}({letter}|{digit})* integer {digit}+ exponent E[+-]?{integer} number {integer}{exponent}? real integer(\.integer)?{exponent}? %option noyywrap %% "<"|"<="|">"|">="|"!="|"==" { filloperator(&yylval, yytext); return( REL); } if { return( IF ); } else { return( ELSE ); } while { return( WHILE ); } do { return( DO ); } for { return( FOR ); } switch { return( SWITCH ); } 。 -可编辑修改- case { return( CASE ); } default { return( DEFAULT ); } break { return( BREAK ); } true { return( TRUE ); } false { return( FALSE ); } int { return( INT ); } long { return( LONG ); } char { return( CHAR ); } bool { return( BOOL ); } float { return( FLOAT ); } double { return( DOUBLE ); } "&&" { return( AND ); } "||" { return( OR ); } "!" { return( '!'); } "++" { return( INC ); } "--" { return( DEC ); } "+" { return( '+' ); } "-" { return( '-' ); } "*" { return( '*' ); } "/" { return( '/' ); } "=" { return( '=' ); } "{" { return( '{' ); } 。 -可编辑修改- "}" { return( '}' ); } "[" { return( '[' ); } "]" { return( ']' ); } "(" { return( '(' ); } ")" { return( ')' ); } ";" { return( ';' ); } {ws} { } {id} { filllexeme(&yylval, yytext); return( ID ); } {number} { filllexeme(&yylval, yytext); return( NUMBER ); } {real} { filllexeme(&yylval, yytext); return( REAL ); } %% 在代码中,先定义正则定义,即对letter,digit,专用符号, 空格进行声明;接着在转换规则中,定义一些识别规则的代码。 完成词法分析后,就可以将获取的每一个词素用于语法分析器使用。 将mylex.l与myyacc.y相结合的方法是在每获得一个词素,则用return语句返回,即如果获得的是if,则return(if),并且在头文件中加入#include "myYacc.tab.h",则在myyacc中定义的类型在mylex中可利用,否则会出现返回的单元未定义的错误。 3. 用文本编译器编辑相应的bison文件myyacc.y,myyacc.y文件中,在每个生成式后加上语法制导翻译,主要是依据truelist和falselist来实现回填功能。编写完后,在myyacc.y中以头文件的方式加入自己编写的myyacc.h文件,编译即可。Myyacc.y的代码如下所示: 。 -可编辑修改- Myyacc.y %{ #include "myyacc.h" #define YYSTYPE node #include "myyacc.tab.h" int yyerror(); int yyerror(char* msg); extern int yylex(); codelist* list; %} %token BASIC NUMBER REAL ID TRUE FALSE %token INT LONG CHAR BOOL FLOAT DOUBLE %token REL %token IF ELSE WHILE DO BREAK FOR SWITCH CASE DEFAULT %token OR AND %left OR %left AND %right '!' %left '+' '-' %left '*' '/' %right UMINUS %right INC DEC 。 -可编辑修改- %% program : block { } ; block : '{' decls statementlist '}' { } ; decls : decls decl { } | { } ; decl : type ID ';' { } ; type : type '[' NUMBER ']' { } | BASIC { } ; statementlist : statementlist M statement { backpatch(list, $1.nextlist, $2.instr); $$.nextlist = $3.nextlist; } | statement { $$.nextlist = $1.nextlist; } ; Statement : IF '(' boolean ')' M statement ELSE N M statement { backpatch(list, $3.truelist, $5.instr); backpatch(list, $3.falselist, $9.instr); $6.nextlist = merge($6.nextlist, $8.nextlist); 。 -可编辑修改- $$.nextlist = merge($6.nextlist, $10.nextlist); } | IF '(' boolean ')' M statement { backpatch(list, $3.truelist, $5.instr); $$.nextlist = merge($3.falselist, $6.nextlist); } | WHILE M '(' boolean ')' M statement { backpatch(list, $7.nextlist, $2.instr); backpatch(list, $4.truelist, $6.instr); $$.nextlist = $4.falselist; gen_goto(list, $2.instr); } | DO M statement M WHILE '(' boolean ')' M ';' { backpatch(list, $3.nextlist, $4.instr); backpatch(list, $7.truelist, $9.instr); $$.nextlist = $7.falselist; gen_goto(list, $2.instr); } | FOR '(' assignment ';' M boolean ';' M assignment ')' N M statement { backpatch(list, $6.truelist, $12.instr); backpatch(list, $11.nextlist, $5.instr); backpatch(list, $13.nextlist, $8.instr); $$.nextlist = $6.falselist; gen_goto(list, $8.instr); } | BREAK ';' { } | '{' statementlist '}' { $$.nextlist = $2.nextlist; }