分布式爬虫实验设计文档
- 格式:docx
- 大小:304.22 KB
- 文档页数:14

分布式网络爬虫关键技术分析与实现——分布式网络爬虫体系结构设计一、研究所属范围分布式网络爬虫包含多个爬虫,每个爬虫需要完成的任务和单个的爬行器类似,它们从互联网上下载网页,并把网页保存在本地的磁盘,从中抽取URL并沿着这些URL的指向继续爬行。
由于并行爬行器需要分割下载任务,可能爬虫会将自己抽取的URL发送给其他爬虫。
这些爬虫可能分布在同一个局域网之中,或者分散在不同的地理位置。
根据爬虫的分散程度不同,可以把分布式爬行器分成以下两大类:1、基于局域网分布式网络爬虫:这种分布式爬行器的所有爬虫在同一个局域网里运行,通过高速的网络连接相互通信。
这些爬虫通过同一个网络去访问外部互联网,下载网页,所有的网络负载都集中在他们所在的那个局域网的出口上。
由于局域网的带宽较高,爬虫之间的通信的效率能够得到保证;但是网络出口的总带宽上限是固定的,爬虫的数量会受到局域网出口带宽的限制。
2、基于广域网分布式网络爬虫:当并行爬行器的爬虫分别运行在不同地理位置(或网络位置),我们称这种并行爬行器为分布式爬行器。
例如,分布式爬行器的爬虫可能位于中国,日本,和美国,分别负责下载这三地的网页;或者位于CHINANET,CERNET,CEINET,分别负责下载这三个网络的中的网页。
分布式爬行器的优势在于可以子在一定程度上分散网络流量,减小网络出口的负载。
如果爬虫分布在不同的地理位置(或网络位置),需要间隔多长时间进行一次相互通信就成为了一个值得考虑的问题。
爬虫之间的通讯带宽可能是有限的,通常需要通过互联网进行通信。
在实际应用中,基于局域网分布式网络爬虫应用的更广一些,而基于广域网的爬虫由于实现复杂,设计和实现成本过高,一般只有实力雄厚和采集任务较重的大公司才会使用这种爬虫。
本论文所设计的爬虫就是基于局域网分布式网络爬虫。
二、分布式网络爬虫整体分析分布式网络爬虫的整体设计重点应该在于爬虫如何进行通信。
目前分布式网络爬虫按通信方式不同分布式网路爬虫可以分为主从模式、自治模式与混合模式三种。

网络爬虫试验报告.doc
网络爬虫作为信息技术的重要分支,深刻地影响着人们的日常生活。
本次实验采用Python语言编写,考察网络爬虫原理与应用能力,试验表明:
1. 爬虫程序在搜索网页时,确实能找出其中指定网站上的所有信息,具有完善的基本功能;
2. 爬虫程序能够以字符串的方式对网页内容搜索,实现了精准搜索;
3. 爬虫程序还可以获取更为丰富的信息,比如网页布局和源代码。
4. 同时,爬虫程序还可以使用cookies变量和会话技术,以实现用户认证及数据的追踪,帮助风险识别及分析。
整体而言,爬虫程序是一款功能强大,应用广泛的信息搜索工具。
它不仅可以有效提高信息检索效率,而且可以将搜索结果汇总成报告,有助于数据挖掘与分析工作。
经过本次试验,主要原理、应用能力以及用户友好的界面设计能力得到了充分验证,适用于实际项目的网络搜索。

分布式聚焦网络爬虫系统的设计与实现的开题报告一、选题背景随着互联网信息的爆炸式增长,信息检索和挖掘技术的需求也越来越迫切。
在大量的数据来源中,网络编程不仅是面对数据源最常见的方式,也是最有效的方式之一。
因此,网络爬虫技术应运而生,具有自动化地抓取、处理、存储网络上的大量数据的特点。
同时,随着云计算、虚拟化、分布式系统等大数据相关技术的发展,将数据爬取、处理任务分布到多台计算机上处理,也成为提高爬虫系统性能的关键。
二、研究目的本文旨在研究并实现一个基于分布式聚焦网络爬虫技术设计的Web爬虫系统,该系统可实现爬取全网或指定部分网址内容,解析HTML、XML等相关结构体文档,对爬取到的数据进行抽取、清洗、存储,并以分布式处理数据的方式来使其更高效和灵活。
三、研究内容1. 针对目标站点和数据抓取需求进行系统需求分析。
2. 设计并实现分布式聚焦网络爬虫系统的整体架构。
3. 实现分布式任务调度与管理。
4. 实现数据爬取、解析、抽取、清洗,并存储相关数据。
5. 解决分布式聚焦网络爬虫系统中的反爬机制问题。
四、预期成果1. 具有高效灵活的爬虫系统,具有高效的采集、抽取、清洗、存储能力,并具有良好的可拓展性和可维护性。
2. 支持自适应反爬策略,能够自行识别并规避页面反爬虫,保证系统的正常运行。
五、研究意义1. 提高数据采集、抽取、清洗、存储的效率和精确度,同时降低了人力成本和时间成本。
2. 提高Web应用程序性能和用户体验,利于商业应用的发展。
3. 对分布式计算、数据挖掘和大数据分析等领域的研究具有重要的借鉴作用。
四、研究方法1. 整理相关技术文献,对分布式聚焦网络爬虫系统的技术架构和实现方法进行综合研究。
2. 使用Python语言开发实验平台,对系统进行实现与测试。
3. 对系统进行性能测试,并根据测试结果进行优化和改进。
五、进度安排1. 第一阶段:文献综述、需求分析、系统设计和技术选型。
2. 第二阶段:基于Python语言开发分布式聚焦网络爬虫系统的实验平台,完成基础功能测试。

基于Python的分布式网络爬虫系统的设计与实现作者:逄菲来源:《电子技术与软件工程》2018年第23期摘要现在人们和网络有着密不可分的联系,人们从网络上可以获取丰富的信息。
但是存在用户很难在大量信息中准确挖掘自身需要信息的情况,因此如何从网络上丰富的信息中找到自己最需要的信息是用户很重视的一个问题。
网络爬虫是一项能够自动对信息进行提取筛选的程序,但是其中也存在着一些爬虫系统收集信息效率低、没有良好的扩展性能等问题,网页数据爬取效率和数据选择的速度是当前爬虫系统需要优化的几个方面。
根据当前网络信息特点,本文将会对Python的分布式网络爬虫系统的设计和实现做出简介,并且将此作为对传统文件共享形式的一种补充,也是一种新的尝试。
【关键词】Python 分布式网络爬虫系统大数据时代下,信息的传播和分享是人们交流和交往最需要的,信息的传播和分享能够有效的创造效益。
在信息发达的今天,每条信息和其背后所牵扯到的东西都是大数据所组成的部分。
因此,人们对信息的分享和传播越来越重视,在人们对传播的信息进行提取时,对消息是否有效十分关注。
在平时的生活和工作中,通过组建一个安全、开放、智能的系统进行信息分享,对完成工作的效率有很大的提高,还一定程度节约了工作成本。
1 爬虫技术简介网络蜘蛛是网络爬虫的另一个说法,这是一个可以对网页信息进行提取的程序,可以模仿游览器查询网络资料,给出用户所需要的信息,并且它还是搜索引擎的重要组成部分,可以进行网页信息下载。
网络爬虫可以分为通用性爬虫、聚焦性爬虫、增量型爬虫、深层爬虫,通用性的爬虫就是全网爬虫,其特点是对储存量的要求十分的高,还要求具有很快的存储速度;聚焦性爬虫指的就是对某一方面进行专注的爬虫,根据所给的关键词进行固定的信息搜索;增量型爬虫则是间隔性的信息收集,一定的时间过后重新爬取进行数据的更新;深层爬虫通过登录提交数据,之后才能进入页面提取信息。
利用网络爬虫用户可以对网络中的一些信息进行快速的保存。

基于JAVA的京东商品分布式爬虫系统的设计与实现作者:曹根源董斌智来源:《电子技术与软件工程》2018年第16期摘要数据科学正在改变着人们的生活从百度搜索推荐到今天网上的推荐资讯。
对数据科学的构建,数据来源则是千里行之始。
本文介绍用JAVA结合分布式技术实现的一个高效爬虫系统,希望能为数据研究者垒好数据高楼的基石。
【关键词】数据分析爬虫分布式1 引言京东是一家电商平台,本文通过爬虫技术获取相关商品信息。
JAVA是一门具备数据处理能力和并发多线程机制的成熟语言。
本文通过爬虫系统获取商品信息,将数据保存到本地数据库,最后进行数据分析。
本系统可快速获取商品信息,使用户快速寻找心仪商品。
分布式的技术也可供企业进行大规模数据爬取使用。
2 分布式爬虫系统设计2.1 设计需求主要解决问题:2.1.1 数据获取和异常处理通过URL爬取商品ID;分析页面源码,提取所需信息;建立数据字典并将数据存入数据库。
当某ID没有爬取到时使用查错机制。
2.1.2 分布式通信和多线程技术前者用Socket实现;后者使用Java线程池。
2.1.3 可复用技术和内存优化前者用心跳检查机制,释放失效主机;后者采用数据库去重。
检测每台主机的性能,分发合适的任务。
2.1.5 反爬应对和数据库优化前者使用cookies替换、IP代理等手段。
后者采用水平划分将ID独立成表,为数据库添加索引等。
2.2 相关JAVA模块2.2.1 网址管理实现网址管理的方法有以下2类;(1)JAVA内存:分析网站结构,减少重复URL的爬取。
采用排队机制,减少内存开销。
(2)数据库存储和URL去重:前者采用数据库去重。
后者使用HashSet等进行去重。
2.2.2 分布式通信分布式通信是爬虫的主要模块。
(1)Socket:采用JAVA的Socket包,让客户机在同一局域网内基于TCP进行通信。
(2)负载均衡:每次通信时检测客户机状态,根据LoadBalance算法计算出分配任务月巨。

基于Hadoop的分布式爬虫及其实现引言随着互联网的快速发展和信息的爆炸式增长,大数据时代已经来临。
海量的数据涌入网络,并形成了一个巨大的信息资源库。
如何有效地从这个海洋中提取有价值的信息,成为了当今互联网领域面临的重要挑战之一。
为了应对这一挑战,分布式爬虫技术应运而生。
本文将介绍基于Hadoop的分布式爬虫的实现过程及其优势。
一、分布式爬虫的背景与意义1.1 现有的爬虫技术传统的爬虫技术主要是基于单机环境下的串行爬虫,即一个爬虫程序在一个机器上运行,通过遍历链接、下载网页并解析的方式进行信息抓取。
然而,在处理大规模的数据量时,单机环境面临着许多挑战,如性能瓶颈、系统崩溃等。
1.2 分布式爬虫的优势与应用分布式爬虫依赖于分布式计算框架,如Hadoop,将爬取任务进行拆分,通过多个爬虫节点并行执行,大大提高了爬取效率。
同时,分布式爬虫还能够充分利用多个计算节点的存储资源,提高数据的采集速度和处理能力。
因此,分布式爬虫在大规模数据挖掘、搜索引擎优化等领域具有广泛的应用前景。
二、基于Hadoop的分布式爬虫的实现步骤2.1 爬虫任务的拆解与调度在分布式爬虫中,首先需要将爬取任务进行拆分,分配给多个爬虫节点。
如何进行任务的拆解与调度是整个分布式爬虫实现的重要环节。
Hadoop的MapReduce框架提供了良好的任务调度机制,可以将爬取任务拆解成独立的Map任务,再通过Reduce任务进行合并和处理。
2.2 爬虫节点的配置与管理在分布式爬虫中,每个爬虫节点都需要配置相应的设备和环境。
常见的配置包括网络代理、数据存储路径、爬取深度等。
此外,还需要对爬虫节点进行管理和监控,确保节点的正常工作和性能优化。
2.3 数据的采集与清洗数据的采集是分布式爬虫的核心步骤之一。
在分布式爬虫中,不同的爬虫节点负责采集不同的数据片段,并将采集结果通过消息队列等方式传递给中心节点。
中心节点进行数据的合并和清洗,去除重复数据和无效信息,得到最终的爬取结果。
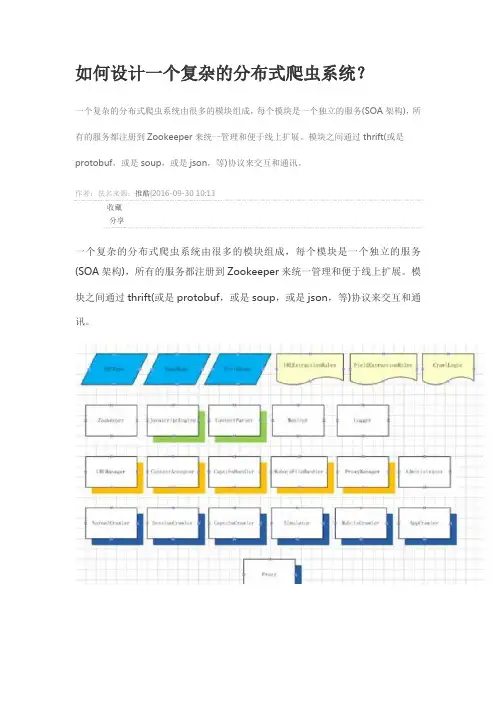
如何设计一个复杂的分布式爬虫系统?一个复杂的分布式爬虫系统由很多的模块组成,每个模块是一个独立的服务(SOA架构),所有的服务都注册到Zookeeper来统一管理和便于线上扩展。
模块之间通过thrift(或是protobuf,或是soup,或是json,等)协议来交互和通讯。
作者:佚名来源:推酷|2016-09-30 10:13收藏分享一个复杂的分布式爬虫系统由很多的模块组成,每个模块是一个独立的服务(SOA架构),所有的服务都注册到Zookeeper来统一管理和便于线上扩展。
模块之间通过thrift(或是protobuf,或是soup,或是json,等)协议来交互和通讯。
Zookeeper负责管理系统中的所有服务,简单的配置信息的同步,同一服务的不同拷贝之间的负载均衡。
它还有一个好处是可以实现服务模块的热插拔。
URLManager是爬虫系统的核心。
负责URL的重要性排序,分发,调度,任务分配。
单个的爬虫完成一批URL的爬取任务之后,会找URLManager要一批新的URL。
一般来说,一个爬取任务中包含几千到一万个URL,这些URL最好是来自不同的host,这样,不会给一个host在很短一段时间内造成高峰值。
ContentAcceptor负责收集来自爬虫爬到的页面或是其它内容。
爬虫一般将爬取的一批页面,比如,一百个页面,压缩打包成一个文件,发送给ContentAcceptor。
ContentAcceptor收到后,解压,存储到分布式文件系统或是分布式数据库,或是直接交给ContentParser去分析。
CaptchaHandler负责处理爬虫传过来的captcha,通过自动的captcha识别器,或是之前识别过的captcha的缓存,或是通过人工打码服务,等等,识别出正确的码,回传给爬虫,爬虫按照定义好的爬取逻辑去爬取。
RobotsFileHandler负责处理和分析robots.txt文件,然后缓存下来,给ContentParser和URLManager提供禁止爬取的信息。

爬⾍设计⽅案⽂章⽬录1 引⾔通过本项⽬的实施与建设,在以服务科研⼯作为主导的原则下,基于⾼性能⼤数据软硬件设施,构建多样化、专业化、柔性化的科研数据服务应⽤平台。
利⽤⼤数据技术,对预报中⼼数据进⾏管理统计,形成可视化的坐标,表格,图形等。
2 系统主要功能需求要构建多样化、专业化、柔性化的科研数据服务应⽤平台,现有系统很难承担⽇益增长的数据分析需求。
迫切需要⼀种全新的系统架构来满⾜⽇常业务及数据分析。
并有效利⽤数据的价值,提⾼数据安全性、系统⾼可⽤等。
需求分析如下:1. 构建新的系统架构,从物理架构、数据架构、业务模型架构及应⽤架构等⼏⽅⾯满⾜业务需求,根据数据下载需求对各个地⽅发布的数据进⾏抓取和传输、存储、调⽤。
2. 构建新的系统架构,从数据抓取架构、数据存储架构、业务模型架构及应⽤架构等⼏⽅⾯满⾜业务需求。
3. 定时抓取互联⽹数据,将数据提取筛选存⼊数据库,积累数据,进⾏⼤数据统计分析,形成可视化的图形坐标等。
4. 系统多平台整合,建设统⼀的底层平台,提⾼系统安全等保级别,规避系统单点风险。
3 系统架构根据对项⽬背景和需求的分析,为了能够更好地在⼤数据时代下⽀撑⼤规模数据的应⽤,分别从爬⾍系统架构,微服务系统架构及数据架构建设⼤数据平台系统。
3.1整体架构整体架构主要分三⼤板块:爬⾍系统架构使⽤基于TypeScript开发语⾔为框架,使⽤RabbitMQ作为消息队列来搭建爬⾍分布式系统,实现系统的⾼可⽤性,⾼性能,⾼扩展性,⾼容错率。
数据存储分为三⼤模块:Redis集群:主要⽤来存储缓存数据,实现快速读写,提⾼数据的运⾏效率;Oracle数据库集群:可以实现读写分离,提⾼数据的读写效率,实现负载均衡,失败转移;⽂件系统集群:主要⽤来存储资源⽂件数据,具有安全性,⾼扩展性,⾼传输。
微服务架构使⽤Netcore webapi来搭建,将模块拆分成⼀个独⽴的服务单元通过接⼝来实现数据的交互,使⽤Nginx作为负载均衡和反向代理服务器来实现分布式架构;Vue框架调⽤微服务接⼝来实现前后端分离的概念,通过接⼝获取时间展⽰在前端⽹页,⼤屏或移动设备上。

python3编写⽹络爬⾍23-分布式爬⾍⼀、分布式爬⾍前⾯我们了解Scrapy爬⾍框架的基本⽤法这些框架都是在同⼀台主机运⾏的爬取效率有限如果多台主机协同爬取爬取效率必然成倍增长这就是分布式爬⾍的优势1. 分布式爬⾍基本原理1.1 分布式爬⾍架构Scrapy 单机爬⾍中有⼀个本地爬取队列Queue 这个队列是利⽤ deque 模块实现的如果新的 Request ⽣成就会放在队列⾥⾯随后 Request 被Scheduler调度之后 Request 交给 Downloader 执⾏爬取简单的调度架构如图单主机爬⾍架构如果两个 Scheduler同时从队列中取 Request 每个 Scheduler 都有其对应的 Downloader 那么在带宽⾜够正常爬取且不考虑队列存取压⼒的情况下爬取效率会翻倍这样 Scheduler 可以拓展多个 Downloader 也可以多拓展⼏个⽽爬取队列Queue 必须始终为⼀也就是所谓的共享爬取队列这样才能保证Scheduler 从队列⾥调度某个 Request 之后其他 Scheduler 不会重复调度此 Request 就可以多个 Scheduler 同步爬取这就是分布式爬⾍的雏形简单的调度架构如图分布式爬⾍架构需要多台主机同时运⾏爬⾍任务协同爬取⽽协同爬取的前提就是共享爬取队列这样各台主机就不要各⾃维护爬取队列⽽从共享爬取队列存取Request 但是各台主机还是与各⾃的 Scheduler 和 Downloader 所以调度和下载功能分别完成不考虑队列存取性能消耗爬取效率还是会成倍提⾼如图主机与从机1.2 维护爬取队列队列⽤什么维护⾸先考虑的就是性能问题基于内存存储的Redis ⽀持多种数据结构例如列表集合有序集合等存取操作也相对简单redis ⽀持的这⼏种数据结构存储各有优点列表有 lpush() lpop() rpush() rpop() ⽅法我们可以⽤它来实现先进先出式爬取队列也可以实现先进后出栈式爬取队列集合元素是⽆序不重复的可以⾮常⽅便的实现随机排序且不重复的爬取队列有序集合带有分数标识⽽ Scrapy 的 Request 也有优先级的控制可以⽤它来实现带优先级的调度队列需要根据具体爬⾍的需求灵活选择不同队列1.3 如何去重scrapy 有⾃动去重使⽤了python中的集合集合记录了 Scrapy中每个 Request的指纹其内部使⽤的是hashlib 的 sha1 ⽅法计算的字段包括 Request 的 method URL Body Headers这⾥⾯只要有⼀点不同那么计算的结果就不同计算得到的结果是加密后的字符串也就是指纹每个Request 都有独有的指纹指纹就是⼀个字符串判断字符串是否重复⽐判断 Request 对象是否重复容易的多scrapy中实现def__init__(self):self.fingerprints = set()def request_seen(self,request):fp = self.request_fingerprints(request)if fp in self.fingerprints:return Trueself.fingerprints.add(fp)对于分布式爬⾍肯定不能利⽤每个爬⾍各⾃的集合来去重这样做还是每个主机单独维护⾃⼰的集合不能做到共享多台主机如果⽣成了相同的request 只能各⾃去重各个主机之间就⽆法做到去重redis集合redis提供集合数据结构在redis集合中存储每个 Request的指纹在向 Request 队列中加⼊ Request 前⾸先验证这个 Request的指纹是否已经加⼊集合中如果已存在则不添加 Request到队列如果不存在则将 Request 添加⼊队列并将指纹加⼊集合利⽤同样的原理不同的存储结构实现了分布式 Request的去重1.4 防⽌中断在 scrapy中爬⾍运⾏时的Request队列放在内存中爬⾍运⾏中断后这个队列空间就被释放了队列就被销毁了所以爬⾍⼀旦运⾏中断爬⾍再次运⾏就相当于全新的爬取过程要做到中断后继续爬取可以将队列保存起来下次爬取直接读取保存数据即可获取上次爬取队列在scrapy中指定爬取队列存储路径即可路径使⽤JOB_DIR变量标识可以使⽤命令实现scrapy crawl spider -s JOB_DIR=crawlS/spider在 scrapy 实际把爬取队列保存到本地第⼆次爬取直接读取并恢复队列分布式中爬取队列本⾝就是数据库保存如果中断了数据库中request依然存在下次启动就会接着上次中断的地⽅继续爬取1.5 架构实现实现这个架构⾸先要实现共享的爬取队列还要实现去重重写 Scheduler 可以从共享爬取队列存储 RequestScrapy-Redis 提供了分布式的队列调度器去重等功能 GitHub地址https:///rmax/scrapy-redis2. Scrapy-Redis 源码解析⾸先下载源代码核⼼源码在scrapy-redis/src/scrapy_redis2.1 爬取队列源码⽂件为 queue.py⽗类Base 中 _encode_request 和 _decode_request 分别可以实现序列化和反序列化原因把Request对象存储到数据库中数据库⽆法直接存储对象需要先将 Request 序列化转成字符串⽗类中__len__ push pop 都是未实现的直接使⽤会报异常源码中有三个⼦类实现FifoQueue 类继承⽗类重写三个⽅法都是对server 对象的操作此爬取队列使⽤了Redis的列表序列化后的 Request存⼊列表中push调⽤ lpush 从列表左侧存储数据 pop调⽤rpop 操作从列表右侧取出数据Request 在列表中存取顺序是左侧进右侧出是有序的进出先进先出LifoQueue 类与 FifoQueue相反使⽤lpop操作左侧出 push 依然使⽤lpush 左侧⼊先进后出后进先出存取⽅式类似栈PriorityQueue 类优先级队列存储结果是有序集合2.2 去重过滤源码⽂件 dupefilter.py使⽤的是redis中的集合数据结构request_seen 和 scrapy中 request_seen ⽅法类似使⽤的是数据库存储⽅式鉴别重复⽅式还是使⽤指纹依靠request_fingerprint ⽅法获取直接向集合添加指纹添加成功返回1 表⽰指纹不存在集合中代码中最后返回结果判定添加结果是否为0 如果返回1 判定false 不重复否则判定重复2.4 调度器源码⽂件 scheduler.py核⼼⽅法存取⽅法enqueue_request向队列中添加 Request 调⽤ Queue 的push 操作还有统计和⽇志操作next_request 从队列取出 Request 调⽤ Queue 的pop操作此队⾥中如果还有 Request 则直接取出爬取继续如果为空爬取重新开始总结1.爬取队列的实现提供三种队列使⽤redis的列表或者集合来维护2.去重的实现使⽤redis集合来保存 Request 的指纹提供重复过滤3.中断就重新爬取的实现中断后 reids的队列没有清空爬取再次启动调度器 next_request 会从队列中取到下⼀个 Request 爬取继续以上就是 scrapy-redis中的源码解析 Scrapy-Redis还提供了 Spider Item Pipline 的实现不过它们并不是必须使⽤3.分布式爬⾍实现利⽤ Scrapy-Redis 实现分布式对接需要安装 Scrapy-Redis pip install scrapy-redis验证 import scrapy_redis ⽆报错表⽰安装成功3.1 搭建 Redis服务器要实现分布式部署多台主机需要共享爬取队列和去重集合⽽在两部分内容都是存于 Redis数据库中的需要搭建⼀个公⽹访问的 Redis服务器推荐使⽤Linux服务器可以购买阿⾥云腾讯云等提供的云主机⼀般都会配有公⽹IP需要记录redis 的运⾏ IP 端⼝地址3.2 配置 Scrapy-Redis修改 settings 配置⽂件将调度器的类和去重类替换为 Scrapy-Redis 提供的类SCHEDULER = 'scrapy_redis.scheduler.Scheduler'DUPEFILTER_CLASS = 'scrapy_redis.dupefilter.RFPDupeFilter'配置redis连接信息REDIS_URL = 'redis://password@host:port'配置调度队列 (可选)默认使⽤ PriorityQueue 可在 settings中修改SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.PriorityQueue'配置持久化(可选)默认false 会在爬取完成后清空爬取队列和去重指纹集合SCHEDULER_PERSIST = True (不清空)在强制中断爬⾍运⾏时不会⾃动清空配置重爬(可选)默认falseSCHEDULER_FLUSH_ON_START = True #每次爬取后清空队列和指纹单机爬⾍⽐较⽅便分布式不常⽤Pipline配置(可选)默认不启动 scrapy-redis 实现⼀个存储到 Redis 的 item pipeline 如果启⽤爬⾍会把⽣成的item 存储到 redis数据库中数据量⽐较⼤的情况下⼀般不这么做因为redis是基于内存的利⽤它是处理速度快的特性存储就太浪费了ITEM_PIPELINES = { 'scrapy_redis.pipelines.RedisPipline:300',}配置存储⽬标可以在服务器搭建⼀个MongoDB 服务存储⽬标放在同⼀个MongoDB中配置修改MONGO_URL = 'mongodb://user:password@host:port'3.3 运⾏将爬⾍代码部署到各台主机即可启动爬取每台主机启动爬⾍后就会配置redis数据库中调度request 做到爬取队列共享和指纹集合共享同时每台主机占⽤各⾃的带宽和处理器不会互相影响。

分布式网络爬虫技术分析与实现 (1)2010-06-17 17:39:38 来源:互联网1990年以前,没有任何人能搜索互联网。
所有搜索引擎的祖先,是1990年由Montreal的McGill University学生Alan Emtage,Peter Deutsch.BillWheelan发明的Archie(Archie FAQ)。
一个可以用文件名查找文件的系统, ...1990年以前,没有任何人能搜索互联网。
所有搜索引擎的祖先,是1990年由Montreal的McGill University学生Alan Emtage,Peter Deutsch.BillWheelan发明的Archie(Archie FAQ)。
一个可以用文件名查找文件的系统,于是便有了Archie.Archie是第一个自动索引互联网上匿名FTP网站文件的程序,但它还不是真正的搜索引擎。
1995年12月,Altavista永远改变了搜索引擎的定义。
AltaVista是第一个支持自然语言搜索的搜索引擎,AltaVista是第一个实现高级搜索语法的搜索引擎(如AND,OR,NOT等)。
用户可以用Altavista搜索Newsgroups新闻组)的内容并从互联网上获得文章,还可以搜索图片名称中的文字、搜索Titles、搜索Javaapplets、搜索ActiveX objects.许多关于网络爬虫的论文都在第一届和第二届World Wide Web conferences被发表。
1998年,Google在Pagerank、动态摘要、网页快照、DailyRefresh、多文档格式支持、地图股票词典寻人等集成搜索、多语言支持、用户界面等功能上的革新,象Altavista一样,再一次永远改变了搜索引擎的定义。
至2005年4月21为止,Google中所收集的Web页面数量已经达到8,058,044,651张。
现阶段,出现了Ask Jeeves,,,MySimon,Dito等内容类别不同的搜索引擎。

基于P2P分布式的网络爬虫设计摘要:未解决传统网络爬虫的在扩展性、容错性和低效性,提出一种基于P2P 的分布式网络爬虫。
分布式网络爬虫通过爬虫协调节点提高网络爬虫的爬取数据的效率和扩展性。
本文首先介绍了传统的网络爬虫的原理,在此原理的基础上对其进行了改进,分析了分布式网络爬虫的结构设计,均衡负载策略和通信策略,从而提高网络爬虫的容错性。
关键字网络爬虫 P2P 分布式负载策略通信策略1. 引言Web资源是当今社会中获取资源重要途径之一,随着信息爆炸性增长,人们对信息资源的需求也越来越大,如何使用网络爬虫技术高效的爬取Web中的数据成为了一个严峻的问题?由于传统的网络爬虫的扩展性和容错性比较差,因此在很多方面已经无法胜任高效爬取的任务。
由于Web信息具有分布式的特性,因此将网络爬虫采取分布式的方式进行设计可以大大提高爬取数据的效率。
分布式的网络爬虫可以借助普通PC用户提供的空闲资源来获取网络,可以降低爬取数据的成本,减少对网络造成的负担。
设计一个分布式的网络爬虫首要了解传统的网络爬虫爬取数据的原理,在其基础上进行改进和优化。
本文详细介绍了分布式系统中常见的几种结构,并以P2P结构为例,说明了如何对资源的分配策略已达到每个节点的公平性,同时介绍了节点间的通信协议如何保证分布式网络爬虫的良好容错性和扩展性。
2. 传统网络爬虫2.1 工作原理网络爬虫是一个Web程序,按照某种规则自动爬取万维网中的Web页面,将爬取到的网页中的关键字存入关键字数据库中,用户通过搜索引擎或许相关信息的页面。
传统的网络爬虫由带爬取的URL库、未爬取的URL库、爬虫主题线程模块和内容提取模块组成。
其工作原理]1[如图1,网络爬虫从一个或若干个初始网页的URl开始,通过爬虫主题线程模块从万维网中获得初始网页上的URL和网页信息,将新获取的URL存放在待爬取的URL队列中,将获取到的网页信息传给内容提取模块,内容提取模块将访问过的URL存入已爬行URL库中,将网页信息存入页面信息库中,直到满足一定停止条件。
2017年软 件2017, V ol. 38, No. 10基金项目: 湖北省自然科学基金资助项目“面向数字取证的数据约简技术研究”(2015CFB764)作者简介: 罗娇敏(1984-),女,讲师,主要研究方向:数据挖掘、分布式系统;耿茜(1963-),女,副教授,主要研究方向:信息技术。
一种基于Redis 的分布式爬虫系统设计与实现罗娇敏,耿 茜(南京航空航天大学 金城学院信息工程系,江苏 南京 211156)摘 要: 随着互联网技术的飞速发展,互联网信息和资源呈指数级爆炸式增长。
如何快速有效的从海量的网页信息中获取有价值的信息,用于搜索引擎和科学研究,是一个关键且重要的基础工程。
分布式网络爬虫较集中式网络爬虫具有明显的速度与规模优势,能够很好的适应数据的大规模增长,提供高效、快速、稳定的Web 数据爬取。
本文采用Redis 设计实现了一个主从式分布式网络爬虫系统,用于快速、稳定、可拓展地爬取海量的Web 资源。
系统实现了分布式爬虫的核心框架,可以完成绝大多数Web 内容的爬取,并且节点易于拓展,爬取内容可以定制,主从结构使得系统稳定且便于维护。
关键词: Redis ;分布式;主从式;爬虫系统中图分类号: TP393.07 文献标识码: A DOI :10.3969/j.issn.1003-6970.2017.10.015本文著录格式:罗娇敏,耿茜. 一种基于Redis 的分布式爬虫系统设计与实现[J]. 软件,2017,38(10):83-87Design and Implementation of a Distributed Crawler System Based on RedisLUO Jiao-min, GENG Qian(Department of information engineering, Nanhang Jicheng College, Nanjing Jiangshu, 211156)【Abstract 】: With the rapid development of Internet technology, the Internet information and resources are expo-nentially explosive growth. How to quickly and effectively obtain valuable information from a large amount of web pages for search engines and scientific research is a key and important infrastructure project. Distributed web crawler has obvious advantages in speed and scale, which can adapt to the massive growth of data, and provide effi-cient, fast and stable Web data crawling. In this paper, Redis is used to design and implement a master-slave distrib-uted network crawler system, which can be used for fast, stable and scalable crawling Web resources. The system realizes the core framework of the distributed crawler, which can complete the crawling of the vast majority of Web content, and the nodes are easy to expand, the crawling content can be customized, and the master-slave structure makes the system stable and easy to maintain.【Key words 】: Redis; Distribute; Master-slave; Crawler system0 引言互联网的快速崛起极大的改变了人们的生活,互联网上的资源和信息以一种爆炸式的方式增长。
一种基于Hadoop的分布式网络爬虫的研究与设计中期报告一、项目概述该项目是一个基于Hadoop的分布式网络爬虫,目的是从互联网上获取大量数据并存储在分布式文件系统中,以供后续的数据挖掘和分析处理。
项目的重点包括爬虫框架的设计与实现、数据存储的方式、数据的去重和增量爬取等方面。
二、进展情况1. 爬虫框架的设计与实现我们已经完成了爬虫框架的设计,采用分布式架构,包括master和worker两个节点,实现了URL调度、爬取、解析和存储等功能。
我们使用了Hadoop的MapReduce框架来实现分布式的爬取功能,将爬取任务划分为多个Map任务,同时利用HDFS来存储爬取的数据。
2. 数据存储的方式我们通过MySQL来存储爬取的数据,MySQL提供了较好的数据管理和查询功能,在我们的实验中表现较为稳定和可靠。
我们采用了分表的方式来存储数据,每个节点都会将爬取到的数据通过MapReduce程序写入到MySQL中的对应表中。
3. 数据的去重和增量爬取我们采用了布隆过滤器来实现数据的去重,目前已经完成了布隆过滤器的实现,并对我们的爬虫系统进行了测试。
同时为了实现增量爬取,我们也利用了MySQL提供的增量查询和时间戳字段来实现增量爬取。
三、下一步工作1. 完善数据存储方式我们计划对数据进行压缩和优化存储,利用HBase等分布式数据库代替MySQL,来提高数据的读取和写入速度。
2. 优化爬虫系统我们计划进一步优化爬虫系统的性能,包括增加节点数量、优化算法等方面,来提高爬虫系统的效率和稳定性。
3. 实现分布式的数据挖掘和分析处理我们计划通过MapReduce等技术实现分布式的大数据挖掘和分析处理,来深度挖掘爬虫所获取的数据,为后续的应用提供支持。
四、结语本项目是一个基于Hadoop的分布式网络爬虫,目的是获取大量数据以供后续的数据挖掘和分析处理。
我们已经完成了爬虫框架的设计和实现,并在数据存储和数据去重方面实现了相应的功能。
分布式网络爬虫实验 五组 赵成龙、黄莹 一、需求分析 ................................................................. 2 二、实验架构及原理 ........................................................... 2 三、模块设计及代码实现 ....................................................... 3 爬取网页模块设计 ......................................................... 3 DNS解析 ............................................................ 4 Socket连接 ......................................................... 4 发送HTTP请求头并获得相应 ........................................... 6 网页解析模块设计 ......................................................... 7 正则表达式的设计 ..................................................... 8 测试用例的设计 ....................................................... 8 利用Regex库提取网页URL ............................................. 8 利用Pcre库提取网页URL ............................................. 10 四、心得体会 ................................................................ 12 一、需求分析 随着国际互联网的迅速发展,网上的信息越来越多,全球网页数量超过20亿,每天新增加730万网页。要在如此浩瀚的信息海洋里寻找信息,就像“大海捞针”一样困难。在实际生活中我们经常会使用像百度、Google这些搜索引擎检索各种信息,搜索引擎正是为了解决这个问题而出现的技术,而网络爬虫正是搜索引擎所需要的关键部分
既然百度、Google这些搜索引擎巨头已经帮我们抓取了互联网的大部分信息,为什么还要自己写爬虫呢因为深入整合信息的需求是广泛存在的,在企业中,爬虫抓取下来的信息可以作为数据仓库多维展现的数据源,也可以作为数据挖掘的来源,甚至有人为了炒股,专门抓取股票信息。这些实际问题的解决所需要的根本技术就是分布网络爬虫。
本次实验主要的内容就是利用IO复用抓取网页,并多线程的分析每个抓取到的网页所包含的URL信息,通过消息队列将抓取网页的部分和分析网页部分进行通信,最终记录下160000网页中所包含的所有URL,实现分布式网络爬虫。
二、实验架构及原理
本实验分为两个模块:爬取网页模块、网页分析模块。实验架构如图所示 图 分布是网络爬虫框架 爬取网页模块采用socket通信方式实现客户端与服务器的通信:首先将客户端与服务器进行三次握手后建立连接,客户端发送HTTP请求头,服务器端收到客户端请求后,进行HTTP响应,发送相应的网页信息,客户端收到服务器的响应后将所获得网页文件交给网页分析模块进行处理并提取URL。流程图如图所示:
图 爬取网页模块流程图 网页分析模块主要工作如下图流程图所示。而本模块的网页分析处理主要在于对抓取到的HTML文件的内容进行URL的提取,我们主要运用正则表达式进行字符串的匹配操作。通过采用Regex正则表达式库和Pcre正则表达式库进行了两种尝试,并根据网页的情况设计了测试用例,进行程序的检验。
分布式消息队列
读取抓取的HTML
根据响应头解压缩
识别网页字符集
提取网页URL
图 网页分析模块流程图 三、模块设计及代码实现
爬取网页模块设计 DNS解析 考虑到网页爬取域名转换的问题,需要将URL进行DNS解析。DNS解析是将一一对应的域名与IP地址进行转换的一种技术,域名解析需要由专门的域名解析服务器来完成,整个过程是自动进行的。首先利用接口struct hostent *gethostbyname(const char *name)将需要解析的域名名称作为参数传入到函数中,然后函数执行后返回一个结构体hostent,其中包括了域名所对应的ip地址列表信息。具体代码如下:
char* dns_decode(char host[]) { struct hostent* ht=NULL; struct in_addr* tmp; char *dns[20]; int i=0; if((ht=gethostbyname(host))==NULL) { herror("gethostbyname wrong!\n"); return NULL; } else { printf("get the host:%s\n",host); while(tmp=(struct in_addr*)*ht->h_addr_list) { dns[i]=(char *)inet_ntoa(*tmp); printf("IP:%s\n",dns[i]); i++; a/b/类型
正则表达式为:]*href\\s*=\\s*\"\\./(\\w*/)*\\.html\"\\s*> (2)../a/b/类型 正则表达式为:]*href\\s*=\\s*\"\\.\\./(\\w*/)*\\.html\"\\s*> (3)./../a/b/类型 正则表达式为:]*href\\s*=\\s*\"\\./\\.\\./(\\w*/)*\\.html\"\\s*> (4)a/b/类型 正则表达式为:]*href\\s*=\\s*\"(\\w*/)*\\.html\"\\s*> 然后将上述四种情况综合起来,通过“或”(即“|”)连接组成最终的提取URL的正则表达式如下:
]*href\\s*=\\s*\"\\./(\\w*/)*\\.html\"\\s*>|]*href\\s*=\\s*\"\\.\\./(\\w*/)*\\.html\"\\s*>|]*href\\s*=\\s*\"\\./\\.\\./(\\w*/)*\\.html\"\\s*>|]*href\\s*=\\s*\"(\\w*/)*\\.html\"\\s*>
测试用例的设计 由于两人分工,在没有得到抓取的html文件内容时,先根据上述不同四种情况设计了测试用例。作为正则表达式的待检测字符串,用来检验程序的正确性,具体如下所示:
" adfaaf134 affdsfasdf href=\"./../aff/\">afdsa ";
利用Regex库提取网页URL 首先利用了Regex正则表达式库进行URL的字符串匹配。采用接口int regcomp(regex_t *preg, const char *pattern, int cflags) 将要进行匹配的正则表达式进行编译,做匹配前的准备工作。编译后采用int regexec(const regex_t *preg, const char *string, size_t nmatch, regmatch_t pmatch[],int eflags)用来检测字符串是否 匹配正则表达式,具体的相应代码如下: #include<> #include<> #include<> #include int main() { int i,j,k; char *result[30]; char *s = " adfaaf134 affdsfasdf afdsa ";
char *pattern = "]*href\\s*=\\s*\"\\./(\\w*/)*\\.html\"\\s*>|]*href\\s*=\\s*\"\\.\\./(\\w*/)*\\.html\"\\s*>|]*href\\s*=\\s*\"\\./\\.\\./(\\w*/)*\\.html\"\\s*>|]*href\\s*=\\s*\"(\\w*/)*\\.html\"\\s*>";
m_so); m_eo); m_so,k=0;i {