适用于机器人视觉的手势识别系统
- 格式:pdf
- 大小:212.39 KB
- 文档页数:4

基于Leap Motion指尖位置的手势提取和识别技术研究周开店;谢钧;罗健欣【摘要】Leap Motion是最近推出的一款比较新颖的手部信息采集设备,它能够高精度、高帧率地跟踪捕获手部信息,基于此特性,本文阐述了一种基于指尖位置和方向信息进行手势提取和识别的研究方案.采用Leap Motion传感器进行手势的三维空间坐标信息采集,从中提取指尖坐标及方向向量信息,建立手势识别模型,构建手势特征数据.对特征数据进行归一化处理后输入到支持向量机进行训练,实现对特定手势的识别.实验结果表明,提出的手势识别方案平均识别精度达到97.33%,具有较高的准确性和鲁棒性.【期刊名称】《微型机与应用》【年(卷),期】2017(036)002【总页数】4页(P48-51)【关键词】手势识别;LeapMotion;指尖位置;方向信息;支持向量【作者】周开店;谢钧;罗健欣【作者单位】解放军理工大学指挥信息系统学院,江苏南京210007;解放军理工大学指挥信息系统学院,江苏南京210007;解放军理工大学指挥信息系统学院,江苏南京210007【正文语种】中文【中图分类】TP391.4近年来,手势识别在众多领域(如:人机交互、机器人应用、电脑游戏、手语翻译等方面)的广泛应用得到了更多人的关注。
当前可用于手势识别的相对低成本的深度相机有:TOF相机和微软公司推出的Kinect设备,通过不同的方法获取手部的深度信息以提高手势识别的准确性。
这些方法提供的手势识别方案均是从深度信息提取的特征值,通用摄像头采集人手图像虽然能够获得稳定的图像序列乃至深度信息,但提取出的人手信息必须经过复杂的图像处理与识别过程,难以保证快速、准确地估计人手姿态,同时它们无法实现近距离的高精度手势识别[1]。
Leap Motion传感器的推出给手势识别领域带来了一种全新的方式,不同于Kinect对视野范围内追踪到物体的整体框架描述,Leap Motion的目标是只针对手部信息的追踪描述,通过对手部信息包括指尖、关节点、方向向量、法向量等的精细化描述,利用这些信息实现对手势的特征提取和准确识别[2]。

控制机器人的方法
有多种方法可以控制机器人,以下是其中一些常见的方法:
1. 遥控器:使用无线遥控器或手持设备发送指令,远程控制机器人的运动和操作。
2. 编程控制:使用编程语言编写代码,通过控制机器人的主控板或控制系统来实现对机器人的控制。
3. 自动化控制:通过传感器和反馈系统来实现自动控制,机器人能够根据环境的变化自主调整行为。
4. 视觉控制:使用摄像头或其他传感器来获取图像信息,然后通过图像处理和计算机视觉算法来识别并控制机器人的行动。
5. 语音控制:通过语音识别技术,将语音命令转化为机器能够理解的指令,从而控制机器人的行为。
6. 手势控制:使用摄像头或其他传感器来捕捉用户的手势动作,通过手势识别算法将手势转化为机器人的指令。
7. 脑机接口控制:利用脑波传感器或其他生理传感器来读取用户的思维或生理
信号,将其转化为机器人的指令,实现通过思维来控制机器人的行为。
这些方法可以单独或结合使用,具体选择和应用取决于机器人的功能和应用场景。

基于深度学习的人手视觉追踪机器人①林粤伟1,2, 牟 森11(青岛科技大学 信息科学技术学院, 青岛 266061)2(海尔集团博士后工作站, 青岛 266000)通讯作者: 林粤伟, E-mail: ******************.cn摘 要: 视觉追踪是智能机器人的核心功能之一, 广泛应用于自动驾驶、智慧养老等领域. 以低成本树莓派作为下位机机器人平台, 通过在上位机运行事先训练好的深度学习SSD 模型实现对人手的目标检测与视觉追踪. 基于谷歌TensorFlow 深度学习框架和美国印第安纳大学EgoHands 数据集对SSD 模型进行训练. 机器人和上位机的软件使用Python 在Linux 系统下编程实现, 两者之间通过WiFi 进行视频流与追踪控制命令的交互. 实测表明, 所研制智能机器人的视觉追踪功能具有良好的稳定性和性能.关键词: 深度学习; SSD 模型; 树莓派; 计算机视觉; 机器人引用格式: 林粤伟,牟森.基于深度学习的人手视觉追踪机器人.计算机系统应用,2020,29(11):227–231. /1003-3254/7594.htmlHuman Hands Visual Tracking Robot Based on Deep LearningLIN Yue-Wei 1,2, MU Sen 11(College of Information Science and Technology, Qingdao University of Science and Technology, Qingdao 266061, China)2(Postdoctoral Workstation of Haier Group, Qingdao 266000, China)Abstract : Vision tracking is one of the core functions of smart robots, and widely used in automatic driving, intelligent pension and other fields. The low-cost Raspberry Pi is employed as the slave computer robot platform. The object detection and visual tracking of human hands is implemented through running the pre-trained deep learning SSD model on host computer. The SSD model is trained based on Google’s TensorFlow deep learning framework and US Indiana University’s EgoHands dataset. Both of the robot and host computer’s software is written by Python in Linux systems.Video stream and tracking control commands are exchanged between robot and host via WiFi. The practical tests show that the vision tracking function of the developed smart robot has good stability and performance.Key words : deep learning; SSD model; Raspberry Pi; computer vision; robot智能机器人的开发是科学研究、大学生科技创新大赛的热点, 基于计算机视觉的目标检测技术在智能小车、无人机、机械臂等领域得到了广泛应用. 在企业界, 零度智控公司开发了Dobby (多比)、大疆公司开发了Mavic 等, 研发出了具有视觉人体追踪与拍摄功能的家用小四轴自拍无人机. 在学术界, 文献[1] 从检测、 跟踪与识别三方面对基于计算机视觉的手势识别的发展现状进行了梳理与总结; 文献[2]基于传统的机器学习方法-半监督学习和路威机器人平台实现了视觉追踪智能小车; 文献[3]基于微软Kinect 平台完计算机系统应用 ISSN 1003-3254, CODEN CSAOBNE-mail: ************.cn Computer Systems & Applications,2020,29(11):227−231 [doi: 10.15888/ki.csa.007594] ©中国科学院软件研究所版权所有.Tel: +86-10-62661041① 基金项目: 青岛科技大学教学改革研究面上项目(2018MS44); 青岛市博士后应用研究项目Foundation item: General Program of Education Reform of Qingdao University of Science and Technology (2018MS44); Post Doctorial Application Research of Qingdao City收稿时间: 2020-01-08; 修改时间: 2020-02-08, 2020-03-17; 采用时间: 2020-03-24; csa 在线出版时间: 2020-10-29成了视觉追踪移动机器人控制系统的设计; 文献[4]对服务机器人视觉追踪过程中的运动目标检测与跟踪算法进行研究并在ROS (Robot Operating System, 机器人操作系统)机器人平台进行实现.上述视觉追踪功能的实现大多采用传统的目标检测方法, 基于图像特征和机器学习, 且所采用平台成本相对较高. 近年随着大数据与人工智能技术的兴起, 利用深度学习直接将分类标记好的图像数据集输入深度卷积神经网络大大提升了图像分类、目标检测的精确度. 国内外基于Faster R-CNN (Faster Region-Convolutional Neural Network, 更快的区域卷积神经网络)、YOLO (You Only Look Once, 一种single-stage 目标检测算法)、SSD (Single Shot multibox Detector, 单步多框检测器)等模型的深度学习算法得到广泛应用,如文献[5]将改进的深度学习算法应用于中国手语识别. 本文基于深度学习[6]技术, 在低成本树莓派[7]平台上设计实现了视觉追踪智能机器人(小车), 小车能够通过摄像头识别人手并自动追踪跟随人手. 与现有研究的主要不同之处在于使用了更为经济的低成本树莓派作为机器人平台, 并且在目标检测的算法上使用了基于TensorFlow [8]深度学习框架的SSD 模型, 而不是基于传统的图像特征和机器学习算法.1 关键技术1.1 系统架构如图1, 整个系统分为机器人小车(下位机)和主控电脑(上位机)两部分. 上位机基于深度学习卷积神经网络做出预测, 下位机负责机器人的行进以及视频数据采集与传输, 两者之间通过WiFi 通信. 其中, 小车主控板为开源的树莓派3代B 开发板, CPU (ARM 芯片)主频1.2 GHz, 运行有树莓派定制的嵌入式Linux 操作系统, 配以板载WiFi 模块、CSI 接口摄像头、底盘构成下位机部分. 上位机操作运行事先训练好的SSD 模型[9]. 小车摄像头采集图像数据, 将其通过WiFi 传输给上位机, 并作为SSD 模型的输入. SSD 模型如果从输入的图像中检测到人手, 会得到人手在图像中的位置, 据此决定小车的运动方向和距离(需要保持人手在图像中央), 进而向小车发送控制命令, 指示运动方向和距离. 小车收到上位机发来的远程控制命令后,做出前进、转向等跟踪人手的动作. 智能小车和主控电脑两端皆运行用Python [10]编写的脚本程序.1.2 深度学习SSD 模型SSD 模型全名为Single Shot multibox Detector [9],是一种基于深度学习的one stage (一次)目标检测模型. SSD 模型由一个基础网络(base network)的输出级后串行连接几种不同的辅助网络构成, 如图2所示. 不同于之前two stage 的Region CNN [11], SSD 模型是一个one stage 模型, 即只需在一个网络中即可完成目标检测, 效率更高.摄像头控制图传传输图像发送命令SSD 模型树莓派图1 智能机器人系统架构S S D300300351210241024512256256256Image 3838Conv4_3Conv6_21919Conv6(FC6)1919Conv7(FC7)1919Conv9_255Conv10_2Conv11_2331Conv: 3×3×1024Conv: 1×1×1024Conv: 1×1×256Conv: 3×3×512−s2Conv: 1×1×128Conv: 3×3×256−s2Conv: 1×1×128Conv: 3×3×256−s1Conv: 1×1×128Conv: 3×3×256−s1VGG-16Through Conv5_3 layerClassifier: Conv:3×3×(4×(Classes+4))Classifier: Conv:3×3×(6×(Classes+4))Conv: Conv:3×3×(4×(Classes+4))D e t e c t i o n s : 8732 p e r c l a s sN o n -m a x i m u m s u p p r e s s i o n74.3 mAP 59 FPS图2 SSD 模型SSD 模型采用多尺度特征预测的方法得到多个不同尺寸的特征图[9]. 假设模型检测时采用m 层特征图,则得到第k 个特征图的默认框比例公式如式(1):S k =S min +S max −S minm −1(k −1),k ∈{1,2,···,m }(1)其中, S k 表示特征图上的默认框大小相对于输入原图计算机系统应用2020 年 第 29 卷 第 11 期的比例(scale). 一般取S min =0.2, S max =0.9. m 为特征图个数.SSD 模型的损失函数定义为位置损失与置信度损失的加权和[9], 如式(2)所示:L (x ,c ,l ,g )=1N(L conf (x ,c )+αL loc (x ,l ,g ))(2)其中, N 表示与真实物体框相匹配的默认框数量; c 是预测框的置信度; l 为预测框的位置信息; g 是真实框的位置信息; α是一个权重参数, 将它设为1; L loc (x,l,g )位置损失是预测框与真实框的Smooth L1损失函数;L conf (x,c )是置信度损失, 这里采用交叉熵损失函数.1.3 TensorFlow 平台使用谷歌TensorFlow 深度学习框架对SSD 模型进行训练. TensorFlow 能够将复杂的数据结构传输至人工智能神经网络中进行学习和预测, 近年广泛应用于图像分类、机器翻译等领域. TensorFlow 有着强大的Python API 函数, 而本文实现的智能小车和主控电脑端运行的程序皆为Python 脚本, 可以方便的调用Python API 函数.2 设计与实现系统主程序软件流程如图3所示. 上位机运行自行编写的Python 脚本作为主程序, 接收下位机发来的图像, 并将其输入到事先训练好的深度学习SSD 模型中, 以检测人手目标. 若检测到人手, 则产生、发送控制命令至下位机. 下位机运行两个自行编写的Python 脚本, 其中一个脚本基于开源的mjpg-streamer 软件采集、传输图像至上位机, 另一个接收来自上位机的控制命令并通过GPIO 端口控制车轮运动.机器人上电Linux 系统启动采集图像图传进程控制进程打开摄像头把采集到的图像以流的方式通过 IP 网络传输到上位机机器人掉电启动进程连接 WiFi AP启动 http 服务器是否有上位机控制命令?控制车轮Y N智能机器人/下位机 (服务端)电脑/上位机 (客户端)连接 WiFi AP 进程启动接收图像将图像输入SSD 模型进行识别是否检测到人手?根据人手在图像中的位置生成并发送命令进程退出YNhttp/WiFi 通信图3 主程序软件流程2.1 深度学习SSD 模型训练上位机电脑和CPU 型号为联想Thinkpad E540酷睿i5 (第4代), 操作系统为Ubuntu 16.04 LTS 64位,TensorFlow 版本为v1.4.0, 采用TensorFlow Object Detection API 的SSD MobileNet V1模型. 训练数据直接使用了美国印第安纳大学计算机视觉实验室公开的EgoHands 数据集, 该数据集是一个向外界开放下载的1.2 GB 的已经标注好的数据集, 用谷歌眼镜采集第一视角下的人手图像数据, 例如玩牌、下棋等场景下人手的姿态. 首先对数据集进行数据整理, 将其转换为TensorFlow 专有的TF Record 数据集格式文件, 然后修改TensorFlow 目标检测训练配置文件ssd_2020 年 第 29 卷 第 11 期计算机系统应用mobilenet_v1_coco.config. 训练全程在电脑上由通用CPU运行, 共运行26小时. 结束训练后将protobuf格式的二进制文件(真正的SSD模型)保存下来以便下文介绍的上位机Python主程序调用.2.2 上位机设计考虑到小车回传视频的帧数比较高, 且深度学习神经网络的计算也是一件耗时的任务, 在上位机主程序(Python脚本)中建立了两个队列, 一个输入队列用来存储下位机传来的原始图像, 一个输出队列用来存储经神经网络运算处理之后带有标注结果的图像. 上位机通过开源软件OpenCV的cv2.videoCapture类用文件的方式读取视频信息. 运行SSD目标检测模型进行人手识别时, 会得到目标的标注矩形框中心, 当中心落到整幅图像的左侧并超出一定距离时, 产生turnleft 左转指令; 当中心落到整幅图像右侧且超出一定距离的时, 产生turnright右转指令; 当中心落到图像的上半部分并超过一定距离时, 产生forward前进指令. 距离值默认设定为60个像素, 该参数可修改. 预测小车行进方向功能的伪代码如算法1所示.算法1. 上位机预测行进方向伪代码Require: 距离阈值(默认为60像素) while 全部程序就绪 do if 没有识别到目标: Continue; else if 识别到目标: if 识别到目标面积过大, 目标离摄像头太近: Send(“stop”); else: if 目标中心 x<640/2–距离阈值: Send(“turnleft”); if 目标中心 x>640/2+距离阈值: Send(“turnright”); else: Send(“forward”); end while2.3 下位机设计下位机基于低成本树莓派平台实现, 使用开源软件Bottle部署了一个多线程的HTTP服务器, 该服务器接收上位机发出的HTTP POST请求, 提取其中的控制命令进行运动控制. 使用开源软件mjpg-streamer控制网络摄像头采集图像, 并将图像数据以视频流的方式通过IP网络传输到上位机客户端.3 测试结果与评估搭建局域网环境(也支持广域网), 使上位机和下位机接入同一无线路由器. 当摄像头采集到的画面右侧出现人手时, 如图4所示的实时图像中, 标注方框标记出了检测到的人手的位置, 同时控制台输出turnright (右转)控制命令, 此时小车向右侧做出移动. 当屏幕中没有人手时, 画面上面没有用彩色画出的区域, 上位机的终端也不打印输出任何控制命令.图4 人手目标检测功能测试结果功能方面, 针对人手在小车视野的不同位置情况进行所研制小车人手视觉追踪的功能测试. 比如, 当人手在小车前方且完整出现时, 上位机应发出forward (前进)命令, 进而小车收到该命令后向前行进. 当小车视野里没有或只有部分人手时, 应当无命令输出, 小车原地不动. 功能测试用例如表1所示, 测试结果均为预期的正常结果. 性能方面, 所采用基于深度学习SSD 模型的人手目标检测算法的准确性与实时性较好, 算法的mAP (平均精准度) 为74%, 检测速率40 fps左右,可以较好的满足系统要求.表1 人手视觉功能测试结果测试用例输出命令小车动作手在小车正前方60 cm处forward向前行进手在小车左前方60 cm处turnleft向左行进手在小车右前方60 cm处turnright向右行进手在小车正前方130 cm处forward向前行进手在小车左前方130 cm处turnleft向左行进手在小车右前方130 cm处turnright向右行进视野里只有半只手无输出原地不动手在小车视野下方无输出原地不动小车(机器人平台)外观如图5所示. 另外, 由于动态视频文件无法在论文中展示, 这里展示的是录制好计算机系统应用2020 年 第 29 卷 第 11 期的测试视频中2个帧的截图, 如图6所示, 从小车的位置变化可以看出其可以追踪人手.图5 机器人外观图6 追踪人手4 结论本文利用深度学习SSD 目标检测模型对目标进行识别, 将识别的结果用于修正智能小车机器人的行进路线, 满足了智能机器人的视觉追踪功能需求. 其特色主要在于采用了低成本树莓派, 以及深度学习而非传统的神经网络识别算法, 省去了设置特征的步骤. 系统暂时只能用来识别人手, 小车能够跟随人手移动, 功能稳定性与性能良好. 若要识别追踪其他物体, 可以使用其他自己制作或第三方数据集对SSD 模型进行训练, 以把网络的识别对象训练成拟追踪的目标类型. 未来也可应用5G 通信模块, 进行更为稳定低时延的视频传输与控制.参考文献Rautaray SS, Agrawal A. Vision based hand gesturerecognition for human computer interaction: A survey.Artificial Intelligence Review, 2015, 43(1): 1–54. [doi: 10.1007/s10462-012-9356-9]1张子洋, 孙作雷, 曾连荪. 视觉追踪机器人系统构建研究.电子技术应用, 2016, 42(10): 123–126, 130.2王道全. 基于视觉的智能追踪机器人的设计研究[硕士学位论文]. 青岛: 青岛科技大学, 2016.3周燕秋. 服务机器人视觉追踪技术研究[硕士学位论文].上海: 上海师范大学, 2018.4周舟, 韩芳, 王直杰. 改进SSD 算法在中国手语识别上的应用. 计算机工程与应用: 1–7. /kcms/detail/11.2127.TP.20191207.1137.006.html . [2020-03-19].5Goodfellow I, Bengio Y, Courville A. Deep Learning 深度学习. 赵申剑, 黎彧君, 符天凡, 等译. 北京: 人民邮电出版社,2017.6许艳, 孟令军, 王志国. 基于树莓派的元器件检测系统设计. 电子技术应用, 2019, 45(11): 63–67, 71.7郑泽宇, 梁博文, 顾思宇. TensorFlow: 实战Google 深度学习框架. 2版. 北京: 电子工业出版社, 2018.8Liu W, Anguelov D, Erhan D, et al . SSD: Single shotMultiBox detector. Proceedings of the 14th European Conference on Computer Vision. Amsterdam. 2016. 21–37.9Chun W. Python 核心编程. 孙波翔, 李斌, 李晗, 译. 3版. 北京: 人民邮电出版社, 2016.10Girshick R, Donahue J, Darrell T, et al . Rich featurehierarchies for accurate object detection and semantic segmentation. Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Columbus, OH,USA. 2014. 580–587.112020 年 第 29 卷 第 11 期计算机系统应用。

物联网技术 2017年 / 第6期 81 作品简介我国听力、语言残障人士超过2 000万人,然而全球有近5亿人饱受交流障碍的困扰。
聋哑人之间基本的交流方式是“手语”,虽然这使他们内部之间的交流方便很多,但与正常人交流时,却常常因为对方不理解手语造成交流困难。
“手语识别”是指通过采集设备获得聋哑人的手语数据,采用模式识别算法,结合上下文知识获知手语含义,进而翻译成语音,传达给不懂手语的正常人,从而“听懂手语”。
现有的主流手语识别设备是基于数据手套的手语识别系统,利用数据手套和位置跟踪器测量手势在空间运动的轨迹和时序信息,其缺点明显,如穿戴复杂,设备昂贵,不易携带与推广。
基于此,本课题组设计了一套便于装载在可移动便携设备如手机、平板上的手语识别系统,能够对手语进行实时传输分析并转换成音频输出,为打手势者配备“同步翻译师”,解决交流困难这一难题。
手语示例如图1所示。
该手势识别系统主要基于图像处理与分析技术,考虑到实时交流的通畅性和便利性,设计的识别系统选择手机等移动设备作为图像摄取端和文字语音输出端,即将照相机镜头对准对方手势进行拍摄,避免了传统加载诸多传感器带来的操作不便和数据处理方面的困难。
图1 手语示例识别系统将主要的处理模块以“中继服务器”的形式分离出来,通过与手机终端设计的App 结合使用,对拍摄手势进行实时处理,随后以文字的形式显示或语音的方式播放,达到有需求就能下载,下载后就能立即翻译的效果,辅以文字和语音等多种输出形式,辅助解决聋哑人与常人交流困难的 “你说我懂”移动设备手语识别系统摘 要:针对我国听力、语言残障人士交流困难的问题,文中设计了一款“你说我懂”移动设备手语识别系统。
该系统可装载在手机、平板等移动设备上,能够对手语进行实时传输分析并转换成音频输出,解决了残障人士与正常人沟通不畅的难题,具有良好的社会效益与经济效益。
关键词:手语识别;同步翻译现数据的一体化管理。
(2)通过增加子模块增加系统的量程,减少系统升级的成本。

手形特征与运动轨迹相结合的动态手势识别-图文(精)Y973475学校代码:10254密级:论文编号:上治廖教学SHANGHAIMARITIMEUNIVERSITY硕士掌位论文MASTERDISSERTATION手形特征与运动轨迹论文题目:担箜金煎盘查壬夔迟型学科专业:盐越旦垫盎作者姓名:望竖垫指导教师:至盎盘耋咝完成日期:三QQ五生六月摘要人与计算机的交互活动越来越成为人们日常活动的一个重要组成部分。
而由于手势本身具有的多样性、多义性,以及时『BJ和空间上的差异性等特点,加之人手是复杂的变形体以及视觉本身的不适定性,使此方向研究成为一个极富挑战性的多学科交叉研究课题。
本文结合上海市自然科学基金资助课题。
手势识别与合成”,从手势图像的预处理、手势的特征提取和手势的分类器设计等三方面研究了基于视觉的动态手势识别的识别算法。
在图像预处理阶段,我们先对手势图像进行无冗余的帧分离操作,将我们感兴趣的手势图像从视频流中分离出来,接下来我们进行灰度化处理和平滑去噪,平滑后我们用自适应阈值法对手势图像进行二值化,得到了较好的二值化效果。
在特征提取环节,我们先提取手形特征并依据手形特征进了粗分类,然后提取手势图像的运动轨迹特征与手势的手形特征相结合产生了手势的特征向量。
在分类器的设计上,我们将14套手势图像这样划分:4套为训练集10套为测试集。
然后先根据手势训练集学习手势特征,再计算测试集中手势与训练集中手势的欧氏距离,最后用近邻法来识别判断。
实验的结果证明了我们的方法是完全行之有效的,识别率达到了93.3%。
关键词:动态手势识别,图像预处理,白适应阈值,近邻法Handgesturesplayanaturalandintuitivecommunicationmodeforallhumandialogs.Theabilityforcomputertovisuallyrecognizehandgesturesisessentialforfuturehuman・computerinteraction.However.vision—basedrecognitionofhandgesturesreasonsisanextremelychallenginginterdisciplinaryprojectforthefollowinghandgesturesaredchindiversities.mu似-meaningsandspace-timevadeUes;humanhandsarecomplexnon—dgidill—posedproblem.Thispaperdiscussedtheresearchofvision・basedDynamicGestureobjects;computervisionitseffisanRecognitionbasedin3aspects:gestureimagepreprocessing,featureextractionandthedesignofclassifier.Intheprocessofimagepreprocessingweextracttheframesthatweareinterestedinfromthevideofilefirst.thenthereareseveralimageoperationsweshoulddo.WetumtheRGBcolorimagesintogray-scaledimages,takethesmoothingmeasuretoreducethenoiseintheimages,thenwegetthebinaryversionoftheimagesbythemeansofadaptiveshrinkagevalue.Followingtheimagepreprocessing,it'sturntoextractthedghtfeaturefromthegesture.Wegrosslyclassifiedthegestureaccordingtothetrackofthehandandtheshapeofthehand.andthenweInthecalculatethevalueof仇efeature.classifierdesigning,wesplitthe14setsofgestureimagesinto10testingsetsand4designingsets.Thesystemgetsthefeaturefromthedesigningsetsandsaveitasatemplate,andthenitcalculatesthefeatureoftheinputgestureofthetestingsets.Compadngwiththetemplateusingitgetstheresuitbynearestneighborrule.TheEuclideamourDistence。

图片操作的手势动态识别系统作者:陈守满朱伟王庆春来源:《现代电子技术》2012年第22期摘要:为了实现图片操作命令的手势输入,设计了图片操作的手势动态识别系统。
系统以ARM(S3C6410)为硬件处理核心,利用数字图像处理和嵌入式视觉技术,由摄像头捕捉帧图像,经OpenCV技术处理识别后,发出相应命令,操作显示屏上的图片,实现了对图片非接触式的缩放和切换操作等功能。
进行实验测试,取得了良好的效果,所提出的设计思想为手语输入、机器人视觉输入的方案设计提供了参考。
关键词:手势识别;图片操作;ARM;OpenCV;QT/E中图分类号:TN91934;TP391.4 文献标识码:A 文章编号:1004373X(2012)22000403数字图像处理技术是将获得的低质量图像利用计算机处理成更适合人眼观察或仪器检测的图像的技术[1]。
嵌入式视觉技术是使用摄像机和计算机代替人眼对目标进行识别、跟踪和测量的技术[2]。
因此。
数字图像处理技术和嵌入式视觉技术被广泛地应用在基于图像的识别控制系统中[38]。
当前人机交互的主要信息输入方式有键盘输入、鼠标输入、触摸屏输入、语音输入、视觉输入。
对于鼠标、键盘和触屏输入方式,信息输入者需要接触输入设备,而语音输入和视觉输入不需要接触输入设备。
语音输入对特定语音识别率较高,非特定语音输入识别率低,因此语音输入普适性差;基于视觉的输入通过摄像头捕捉手部运动,将手语转换成对应的命令,实现手势输入,这就可以让人摆脱人机交互时接触的限制。
本文介绍了一种基于ARM的操作图片的手势动态识别系统,利用数字图像处理技术和嵌入式视觉技术,通过摄像头捕捉手势动态来操作显示屏上的图片,实现以非接触的方式对图片进行放大、缩小、切换等操作。
1系统硬件架构如图1所示,手势动态识别的硬件系统主要由ARM S3C6410处理器、USB摄像头、USB控制器、LCD控制器、存储器控制器等组成。
系统由摄像头获取手势动态的图片,经过S3C6410处理判断操作者意图,对显示屏的图片进行操作。
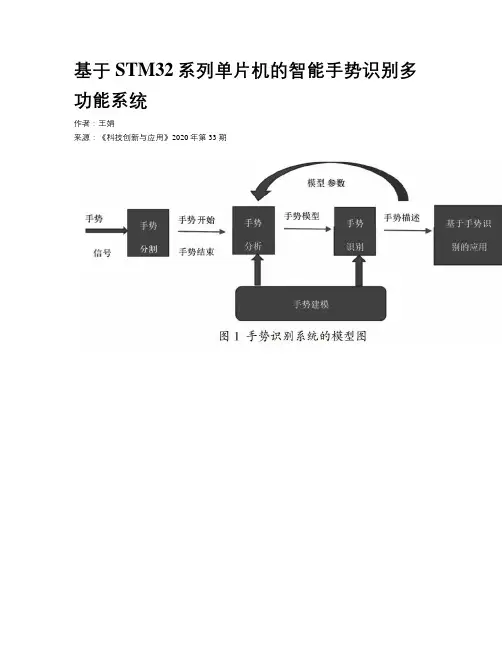
基于STM32系列单片机的智能手势识别多功能系统作者:***来源:《科技创新与应用》2020年第33期摘; 要:智能手势识别多功能系统主要由PAJ7620手势传感器通过不同手势动作的识别,获取探测目标特征原始数据,再对原始数据进行识别处理,最后将手势结果存到寄存器中,根据IIC接口对原始数据和手势识别的结果进行读取,由STM32F401RBT6主控芯片处理和分析,从而来识别不同手势,进而在OLED屏上显示出手势的信息和驱动载体作出不同响应的效果。
关键词:手势识别;STM32F401RBT6;PAJ7620中图分类号:TP391; ; ; ; ;文献标志码:A; ; ; ; ;文章编号:2095-2945(2020)33-0043-02Abstract: The multi-function system of intelligent gesture recognition is mainly composed of PAJ7620 gesture sensors to obtain the original data of the detected target through the recognition of different gestures, then recognize and process the original data, and finally store the gesture resultsin the register, read the original data and gesture recognition results. According to the IIC interface, the original data and the results of gesture recognition are read, processed and analyzed by the STM32F401RBT6 main control chip, so as to identify different gestures, and then display the information of gestures on the OLED screen, and drive the carrier to make different responses.Keywords: gesture recognition; STM32F401RBT6; PAJ7620緒论基于STM32F401RBT6系列单片机的手势识别研究是顺应时代AI人工智能发展的潮流[1]。

第13卷㊀第7期Vol.13No.7㊀㊀智㊀能㊀计㊀算㊀机㊀与㊀应㊀用IntelligentComputerandApplications㊀㊀2023年7月㊀Jul.2023㊀㊀㊀㊀㊀㊀文章编号:2095-2163(2023)07-0173-06中图分类号:TP391.9文献标志码:B基于PSO-SVM的表面肌电信号多手势识别王㊀博,闫㊀娟,杨慧斌,徐春波,吴㊀晗(上海工程技术大学机械与汽车工程学院,上海201620)摘㊀要:作为人机交互的一种重要形式,手势识别在医疗康复领域已尤显重要㊂针对手势识别技术存在的不足,提出粒子群优化支持向量机(PSO-SVM)的多手势精确识别方法㊂首先,利用表面肌电信号采集仪采集16种手势所对应的表面肌电信号(SEMG);其次,分别从时域㊁频域和时频域提取所需要的SEMG特征;然后,采用主成分分析法(PCA)对数据特征进行降维;最后,使用PSO-SVM对降维后的数据特征进行分类识别㊂经过与传统支持向量机(SVM)分类以及遗传算法优化支持向量机分类(GA-SVM)相对比,本方法识别精度高㊁速度快,研究结果可为手势识别提供新的思路,为人体上肢动作判断和上肢康复机器人的研究提供参考㊂关键词:手势识别;表面肌电信号;主成分分析;粒子群优化;支持向量机Multi-gesturerecognitionofSEMGsignalsbasedonPSO-SVMWANGBo,YANJuan,YANGHuibin,XUChunbo,WUHan(SchoolofMechanicalandAutomotiveEngineering,ShanghaiUniversityofEngineeringScience,Shanghai201620,China)ʌAbstractɔAsanimportantformofhuman-computerinteraction,gesturerecognitionhasbecomethefocusofresearchinthefieldofmedicalrehabilitation.Aimingattheshortcomingsofgesturerecognitiontechnology,amulti-gestureaccuraterecognitionmethodbasedonparticleswarmoptimizationsupportvectormachine(PSO-SVM)isproposed.Firstly,surfaceelectromyography(SEMG)signalscorrespondingto16kindsofhumangesturesarecollectedbysurfaceelectromyographysignalacquisitioninstrument.Secondly,SEMGfeaturesareextractedfromtimedomain,frequencydomainandtime-frequencydomainrespectively.Then,principalcomponentanalysis(PCA)isusedtoreducethedimensionofdatafeatures.Finally,accordingtothedatacharacteristics,PSO-SVMisusedforclassificationandrecognition.Comparedwithtraditionalsupportvectormachine(SVM)classificationandgeneticalgorithmoptimizedsupportvectormachineclassification(GA-SVM),thismethodhashighrecognitionaccuracyandspeed.Theresearchresultscanprovideanewideaforgesturerecognition,andprovidethereferenceforhumanupperlimbmotionjudgmentandtheresearchofupperlimbrehabilitationrobot.ʌKeywordsɔgesturerecognition;surfaceelectromyographysignal;principalcomponentanalysis;particleswarmoptimization;supportvectormachine作者简介:王㊀博(1997-),男,硕士研究生,主要研究方向:智能控制㊁机器学习;闫㊀娟(1978-),女,高级实验师,硕士生导师,主要研究方向:智能控制算法研究㊁机械自动化;杨慧斌(1983-),男,实验师,主要研究方向:智能控制㊁机械自动化;徐春波(1997-),男,硕士研究生,主要研究方向:机器视觉㊁智能控制;吴㊀晗(1997-),男,硕士研究生,主要研究方向:智能控制㊂通讯作者:闫㊀娟㊀㊀Email:aliceyan_shu@126.com收稿日期:2022-08-260㊀引㊀言目前,国内人口老龄化的问题较为严峻,老年人的健康问题已经逐渐成为人们关注的焦点㊂研究可知,老年人往往行动不便或者难以表达,因此通过手势表达内心想法便成为非常重要的一种途径㊂目前,主要的手势识别方式有视觉识别[1]和人体生物信号[2]识别两种,其中表面肌电信号(SEMG)识别方式作为一种生物信号显得尤为重要,因为其中蕴含着大量的信息㊂基于此,本文中通过人体表面肌电信号进行手势识别,通过手势识别的研究为后续研究提供基础㊂迄今为止,关于肌电信号对人体手势识别的研究已经取得较多成果,但大多研究对手势识别研究不够深入,赵诗琪等学者[3]使用了支持向量机来识别4种手势,识别结果为99.92%㊂隋修武等学者[4]通过非负矩阵分解与支持向量机的联合模型识别6种手势动作,识别结果为93%㊂江茜等学者[5]通过多通道相关性特征识别8种手势动作,识别结果为94%㊂当识别的手势种类增多时,分类器的识别精度将会随之降低,大量学者对分类器进行优化以利于提高识别精度㊂Leon等学者[6]对9Copyright ©博看网. All Rights Reserved.种手势进行识别,识别精度为94%㊂Lian等学者[7]通过K最邻近和决策树算法识别10种手势动作,识别率仅为89%㊂综上所述,为了满足当前医疗康复设备的需求,多手势识别的精确度还有待提高㊂使用SEMG信号进行手势识别时,特征提取和模式识别是提高手势识别精度的关键㊂典型的特征提取方法主要包括时域特征提取㊁频域特征提取和时频域特征提取[8]㊂模式识别主要通过搭建分类器实现,基于SEMG识别常用的分类器主要包括BP(BackPropagation)神经网络[9]㊁极限学习机(ExtremeLearningMachine,ELM)[10]㊁卷积神经网络(ConvolutionalNeuralNetworks,CNN)[11]和支持向量机(SupportVectorMachine,SVM)[12]等分类模型㊂但以上方法均存在一定程度的不足:BP神经网络在识别手势时准确率较低;由于极限学习机要经过反复的迭代学习,因此其训练速度在一定程度上相对缓慢;KNN计算量较大,计算时间长;SVM分类思想简单㊁分类效果较好,但训练参数值的选取会影响分类器的效果[13]㊂基于上述分析,本文中提出一种基于粒子群算法(ParticleSwarmOptimization,PSO)优化支持向量机的多手势识别方法,以提高多手势的识别精度㊂首先,利用主成分分析法对提取的表面肌电信号特征进行降维处理;然后,利用PSO对SVM的惩罚参数C和核函数半径参数g迭代寻优;最后,使用PSO优化的SVM(PSO-SVM)分类模型识别了16种手势,并与未优化的SVM分类模型和遗传算法(GeneticAlgorithm,GA)优化的SVM分类模型进行对比,从而验证本文所提方法的准确性㊂1㊀SEMG数据采集方法分析1.1㊀实验数据采集受试者为实验室中3名男生和1名女生㊂受试者年龄在23 28岁,平均身高在170cm,均为右手使用者且无神经肌肉骨骼疾病㊂实验前24h内没有进行高强度运动并且身心舒适㊂用磨砂膏和75%酒精棉清洁右肢掌长肌㊁桡侧腕屈肌㊁尺侧腕屈肌㊁指伸肌㊁指浅屈肌和肱桡肌皮肤表面皮肤,减少皮肤阻抗干扰㊂通过Delsys无线肌电设备对6块肌肉的表面肌电信号同时进行采集㊂受试者端坐于试验台前,背部保持90ʎ,左手臂自然垂下㊂实验时,共采集16个手势动作,每个动作维持6s,休息4s,进行6次循环,重复以上动作直至4名受试者全部采集完成㊂1.2㊀信号预处理SEMG信号是由人体内神经肌肉系统产生的一种特别微弱的生物电信号㊂SEMG信号的电压幅度范围是0 5mV,频率范围是20 1000Hz,其主要能量集中在50 150Hz范围内㊂因此,首先设计陷波滤波去除原始信号中50Hz的工频干扰,再设计30 300Hz的巴特沃斯带通滤波器去除肌电信号中的基线漂移及其他噪声信号㊂图1分别为滤波前后的时域波形及频域振幅谱,较好地滤除了有效范围外的噪声信号㊂210-1-2-3102030405060幅度/10-4t /s(a)原始波形1.51.00.51002003004005006007008009001000频率/H z参考幅值/10-6(c)原始振幅图210-1-2-3102030405060幅度/10-4t /s(b)滤波后波形1.51.00.51002003004005006007008009001000频率/H z参考幅值/10-6(d)滤波后振幅图图1㊀肌电信号滤波图Fig.1㊀FilteringdiagramofSEMGsignal471智㊀能㊀计㊀算㊀机㊀与㊀应㊀用㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀第13卷㊀Copyright ©博看网. All Rights Reserved.1.3㊀特征提取为了能更全面地分析SEMG信号中所包含的信息,本文分别提取了肌电信号中的时域特征㊁频域特征和时频域特征三种特征模型㊂1.3.1㊀时域特征提取本文选用的时域特征有均方根值(RMS)和绝对平均值(ARV)㊂时域特征值的计算公式为:RMS=1NðNi=1x2i(1)ARV=1NðNi=1xi(2)㊀㊀其中,xi(i=1,2, ,N)是信号的时间序列㊂1.3.2㊀频域特征提取本文选用的频域特征是平均功率频率(MPF)和中值频率(MF)㊂频域特征值的计算公式为:MPF=ʏ¥0fˑPSDf()dfʏ¥0PSDf()df(3)MF=12ʏ¥0PSDf()df(4)㊀㊀其中,f是SEMG信号的频率,PSD(f)是SEMG信号的功率谱密度函数㊂1.3.3㊀时频域特征提取时频分析法可以对信号在时域和频域内的能量信号同时进行展现,这对于分析非平稳信号相当重要㊂其中,小波变换具有较好的准确性,本文采用小波变换计算时频域特征瞬时平均功率(IMPF)和瞬时中值频率(IMF),公式具体如下:IMPF=ʏf2f1fˑPSD(t,f)dfʏf2f1PSD(t,f)df(5)ʏIMFf1PSD(t,f)df=ʏf2IMFPSD(t,f)(6)㊀㊀其中,f是SEMG信号的频率,PSD(t,f)是频率和时间的二维函数㊂1.4㊀特征降维本文利用6通道SEMG信号,以此对36个维度的特征参数进行提取㊂高维数据由于存在很多冗余特征,使得实验过程中的计算量增多,并因此对分类器产生极大的影响㊂同时,在此过程会产生 过拟合 ㊁ 维数灾难 等系列问题,从而降低分类器的性能[14]㊂因此,本文中使用主成分分析法进行降维处理㊂对其步骤流程可做分述如下㊂(1)首先,将计算得到的特征值进行处理构建样本矩阵,样本矩阵通过m行n列的矩阵X表示,得到:X=x11x12 x1nx21x22 x2n︙︙⋱︙xm1xm2 xmnéëêêêêêùûúúúúú(7)㊀㊀(2)构建数据样本的协方差矩阵C=1m-1XTX,得到协方差矩阵:C=c11 c1n︙⋱︙cn1 cnnéëêêêêùûúúúú(8)㊀㊀(3)分解协方差矩阵C并计算协方差矩阵的特征值λ1ȡλ2ȡ ȡλn和特征向量a1,a2, ,an㊂(4)确定特征矩阵主成分的个数v并构建主成分矩阵:Ymˑv=XmˑnAnˑv(9)㊀㊀其中,Anˑv=[a1,a2, ,av],最后得到SEMG手势特征降维后的主成分特征Ymˑv㊂2㊀分类器设计2.1㊀支持向量机分类支持向量机(SVM)是基于统计学领域的VC维理论和结构风险学最小理论基础上的一种机器学习算法,常用于模式分类和非线性回归[15]㊂通常,通过将向量映射到高维空间,以此来解决输入量与输出量之间的非线性问题㊂同时,通过设定的核函数g,将输入空间利用非线性变换转变到高维空间,从而通过高维空间得到最优线性分类面㊂对于给定的训练样本集{(xi,yi)},i=1,2, ,n,xɪRn,yɪ(-1,1),设最优平面为ωTx+b=0,分类间隔为:γ=2 ω (10)㊀㊀判别模型为:f(x)=sign(ωTx+b)(11)㊀㊀若要找到最大间隔,即找到参数和使得最大,等价于最小化,因此求解问题最终转化为带约束的凸二次规划问题:minω,b12 ω 2+Cðni=1εi(12)s.t.㊀yi(ωTxi+b)ȡ1-εi571第7期王博,等:基于PSO-SVM的表面肌电信号多手势识别Copyright©博看网. All Rights Reserved.εi>0,i=1,2, ,n㊀㊀其中,εi=1-yi(ωTxi+b)为损失函数,C是惩罚参数,C的值与错误分类的惩罚程度成正比,其值越小,则惩罚程度越小;反之,惩罚程度越大㊂同时,利用凸优化理论,将约束问题通过引入的拉格朗日乘子法转化为无约束问题:㊀Lω,b,λ()=12 ω 2+Cðni=1εi-ðni=1μiεi-ðni=1λi(yi(ωxi+b)-1+εi)(13)λiȡ0,μiȡ0对于极大值㊁极小值及对偶问题,令∂L∂ω=0,∂L∂b=0,∂L∂ε=0,因此得到:ω=ðni=1λiyixiðni=1λiyi=0C=λi+μiìîíïïïïïï(14)㊀㊀因此,最终得到:minλ12ðnj=1ðni=1λiλjyjyixjxi-ðni=1λi(15)s.t.㊀ðni=1λiyi0ɤλiɤC2.2㊀粒子群优化算法粒子群优化算法(PSO)是一种设计无质量的粒子来模拟鸟群中的鸟不断迭代寻优来解决优化问题的方法[16]㊂粒子的速度和位置通过迭代进行更新,粒子群优化算法公式为:Vk+1id=ωVkid+c1r1pbestkid-xkid()+c2r2gbestkid-xkid()xk+1id=xkid+vk+1id{其中,ω表示惯量因子;d=1,2, ,D表示空间维数;i=1,2, ,n表示粒子数;k表示当前迭代次数;vkid表示第i个粒子在第k次迭代速度;xkid表示第i个粒子在第k次迭代位置;pbestkid表示第i个粒子的个体最优解;gbestkid表示第i个粒子的全局最优解;c1,c2表示学习因子;r1,r2表示随机数㊂空间中的粒子不断搜寻其自身的最优解,将自身最优解传递给其他粒子,在所有传递的个体最优解中寻找全局最优解,所有粒子根据自身最优解及全局最优解不断调整位置及速度㊂2.3㊀粒子群优化支持向量机为了使SVM能够对肌电信号特征进行快速精确地识别,通过PSO对SVM中分类识别影响最大的2个元素进行优化,即惩罚参数C和核函数半径参数g,将SVM结果中误差最小的一组惩罚参数和核函数半径参数用于预测分类㊂图2是PSO优化SVM的流程图㊂由图2可知,m个粒子在D维空间中不断更新运动速度及自身所处位置,通过反复迭代寻优得到SVM的最优参数㊂粒子群优化:更新全局最优个体更新速度更新位置根据S V M 参数形成初始种群计算适应度值形成新的种群是否满足条件交叉验证,得到最佳准确率作为适应度值返回输入参数训练S V M得到S V M 最优参数结束开始参数适应度值是否图2㊀PSO-SVM流程图Fig.2㊀PSO-SVMflowchart671智㊀能㊀计㊀算㊀机㊀与㊀应㊀用㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀第13卷㊀Copyright ©博看网. All Rights Reserved.㊀㊀PSO优化SVM主要包括初始化种群㊁寻找初始极值㊁迭代寻优等操作,其步骤为:(1)在D维空间中,随机对m个粒子进行初始化,即对SVM参数编码,形成初始种群㊂(2)初始化的种群输入到SVM分类器中,通过训练得到适应度值㊂(3)评估计算得到的粒子适应度值㊂(4)寻找全局最优参数,并判断是否满足终止条件㊂(5)若寻找得到的最优参数不满足终止条件,则更新迭代过程中的全局最优速度和全局最优位置,形成新的种群返回到步骤2继续计算;当结束条件得到满足时,通过将最优参数对SVM重新训练,并将其作为最终分类器对特征识别分类㊂㊀㊀通过上述PSO优化算法得到SVM中惩罚参数C和核函数半径g的最优解,对分类器进行训练和分类预测㊂3㊀实验结果分析实验将从2方面对所提出方法模型进行分析验证:(1)分别使用本文设计的算法模型与传统SVM模型㊁遗传算法优化SVM模型对相同的实验数据进行实验对比,验证模型的有效性㊂(2)为判断模型的识别性能,使用交叉验证,将训练样本与验证样本的数据来源分割开来用于实验,以评估方法的通用性,使用不同人的训练样本去验证其他人的测试样本㊂3.1㊀不同分类模型的对比分析将PCA降维后的特征矩阵按照5ʒ1的比例分类参与分类器的训练和验证,训练和测试的样本不重叠且从实验者中平均调取㊂测试结果如图3所示㊂表2是关于分类器识别性能在不同方法下的对比㊂实际类型预测类型16141210864220406080100120140160样本序号类型(a)SVM预测结果161412108642020406080100120140160测试集样本类别标签实际测试集分类预测测试集分类测试集的实际分类和预测分类图A c c u r a c y =94.375%(b)GA-SVM预测结果1009080706050400102030405060708090100最佳适应度平均适应度进化代数适应度(c)GA-SVM迭代次数161412108642020406080100120140160测试集样本类别标签实际测试集分类预测测试集分类测试集的实际分类和预测分类图A c c u r a c y =95.625%(d)PSO-SVM预测结果100908070605040最佳适应度平均适应度进化代数102030405060708090100适应度(e)PSO-SVM迭代次数图3㊀测试结果对比图Fig.3㊀Comparisontableofresultsofdifferentmodels771第7期王博,等:基于PSO-SVM的表面肌电信号多手势识别Copyright ©博看网. All Rights Reserved.表1㊀不同模型结果对比表Tab.1㊀Comparisontableofresultsofdifferentmodels实验方法平均迭代次数平均准确率/%SVM\87.500GA-SVM2691.320本文方法1194.253㊀㊀由上述实验结果可以得出分析如下,不同方法表现出不同的分类效果㊂其中,传统的SVM方法,分类效果易受到干扰,分类精度不高;GA-SVM虽然能够提高手势的识别精度,但在分类过程中需要经过31次的迭代才能够达到分类的效果;对于本文中的方法,不仅对手势识别的准确率保持最高,同时也大大缩减了算法的复杂度,极大地提高了运算处理效率,表现出较好的分类识别性能㊂3.2㊀不同数据源实验验证考虑模型的通用性,即模型中训练的数据是基于部分受试者肌电信号进行训练,但手势识别对其他受试者的肌电信号同样适用㊂同时,为了分析所提出的模型在相同被试和不同被试下的识别性能,实验设计了男女混合验证的方式以消除性别的影响,按照2位男性同学的肌电信号进行训练,另外2位同学的肌电信号用于识别㊂分别使用SVM和POS-SVM进行实验对比,验证本文中所提方法的有效性㊂得到的训练结果性能对比见表2㊂表2㊀不同数据源实验结果对比表Tab.2㊀Comparisontableofexperimentalresultsofdifferentdatasources分类模型平均准确率/%SVM82.23PSO-SVM90.64㊀㊀由表2中的结果可知:不同数据源的实验比同一数据源降低了3.61%,而SVM下降程度更高,也进一步说明了本文中所提出的优化方法具有较好的识别性㊂4㊀结束语为了提高多手势识别的精度,文中提出了基于PSO-SVM的识别方法㊂结果表明,通过肌电信号的陷波滤波和带通滤波进行预处理,并对其从时域㊁频域和时频域提取信号特征,再经过PCA降维后使用本文所构建的PSO-SVM分类模型对16种手势识别准确率达到94.253%,将其与未被优化的SVM模型和GA-SVM模型进行对比,可知其识别效果有非常明显的改善㊂后续可将PSO-SVM分类模型应用于机械运动控制㊁外骨骼控制等领域㊂参考文献[1]解迎刚,王全.基于视觉的动态手势识别研究综述[J].计算机工程与应用,2021,57(22):68-77.[2]梁旭,王卫群,侯增广,等.康复机器人的人机交互控制方法[J].中国科学:信息科学,2018,48(01):24-46.[3]赵诗琪,吴旭洲,张旭,等.利用表面肌电进行手势自动识别[J].西安交通大学学报,2020,54(09):149-156.[4]隋修武,牛佳宝,李昊天,等.基于NMF-SVM模型的上肢sEMG手势识别方法[J].计算机工程与应用,2020,56(17):161-166.[5]江茜,李沿宏,邹可,等.肌电信号多通道相关性特征手势识别方法[J/OL].计算机工程与应用:1-9[2022-03-07].https://kns.cnki.net/kcms/detail/11.2127.tp.20220303.2103.008.html.[6]LEONM,GUTIERREZJM,LEIJAL,etal.EMGpatternrecognitionusingSupportVectorMachinesclassifierformyoelectriccontrolpurposes[C]//2011PanAmericanHealthCareExchanges.RiodeJaneiro,Brazil:IEEE,2011.[7]LIANKY,CHIUCC,HONGYJ,etal.Wearablearmbandforrealtimehandgesturerecognition[C]//2017IEEEInternationalConferenceonSystems,Man,andCybernetics(SMC).Banff,AB,Canada:IEEE,2017:2992-2995.[8]石欣,朱家庆,秦鹏杰,等.基于改进能量核的下肢表面肌电信号特征提取方法[J].仪器仪表学报,2020,41(01):121-128.[9]梅武松,李忠新.基于手形和姿态的军用动态手势识别方法研究[J].兵器装备工程学报,2021,42(05):208-214.[10]来全宝,陶庆,胡玉舸,等.基于人工鱼群算法-极限学习机的多手势精准识别[J].工程设计学报,2021,28(06):671-678.[11]许留凯,张克勤,徐兆红,等.基于表面肌电信号能量核相图的卷积神经网络人体手势识别算法[J].生物医学工程学杂志,2021,38(04):621-629.[12]都明宇,鲍官军,杨庆华,等.基于改进支持向量机的人手动作模式识别方法[J].浙江大学学报(工学版),2018,52(07):1239-1246.[13]徐云,王福能.采用sEMG的手势识别用APSO/CS-SVM方法[J].电子测量与仪器学报,2020,34(07):1-7.[14]黄铉.特征降维技术的研究与进展[J].计算机科学,2018,45(S1):16-21,53.[15]王霞,董永权,于巧,等.结构化支持向量机研究综述[J].计算机工程与应用,2020,56(17):24-32.[16]冯茜,李擎,全威,等.多目标粒子群优化算法研究综述[J].工程科学学报,2021,43(06):745-753.871智㊀能㊀计㊀算㊀机㊀与㊀应㊀用㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀第13卷㊀Copyright©博看网. All Rights Reserved.。

红外线传感器技术在机器人控制中的使用方法随着科技的不断进步,机器人在工业、医疗、军事等领域的应用越来越广泛。
在机器人的控制系统中,传感器起着至关重要的作用,其中红外线传感器技术是一种常用且有效的方法。
红外线传感器通过感知周围的红外线信号,使机器人能够在各种环境中实现自主感知和导航。
本文将详细介绍红外线传感器在机器人控制中的使用方法及其优势。
一、红外线传感器的原理和分类红外线传感器是一种能够探测红外线辐射的设备。
它通过接收红外线信号并转换成电信号,进而实现对目标物体的检测与测量。
根据其探测距离和探测角度的不同,红外线传感器可以分为近距离红外线传感器和远距离红外线传感器两种类型。
近距离红外线传感器主要用于避障和检测物体的接近距离。
它可以通过红外线传感器发射器和接收器之间的时间差来计算物体与传感器的距离。
而远距离红外线传感器主要用于目标物体的远距离探测和测量,例如测距多少米以外的物体。
二、红外线传感器在机器人控制中的应用1. 避障功能在机器人的导航与移动中,避免碰撞是一项非常重要的任务。
红外线传感器通过感知周围的红外线信号,可以实现对障碍物的探测与测量。
机器人可以根据传感器的信号,调整自身的运动轨迹,从而避免与障碍物发生碰撞。
2. 环境监测除了避障功能,红外线传感器还可以用于机器人对环境的监测与感知。
例如,在火灾救援机器人中,红外线传感器可以感知到火焰辐射的红外线信号,从而实现机器人对火源的定位和监测。
3. 温度测量红外线传感器还可以用于测量目标物体的温度。
通过测量目标物体向传感器发出的红外线辐射的强度,可以准确地测量出目标物体的温度。
这在冶金、热成像等领域的应用非常广泛。
4. 手势识别利用红外线传感器,机器人还可以实现对人体手势的识别。
通过感知人体手势所发出的红外线信号的变化,机器人可以判断人体手势的动作,并作出相应的响应。
这在智能家居和人机交互等领域有很大的应用潜力。
三、红外线传感器在机器人控制中的优势1. 高精度红外线传感器可以实现对目标物体的高精度测量。

AI技术在机器人领域中的使用方法引言:人工智能(Artificial Intelligence,简称AI)是一项前沿技术,已经广泛应用于许多领域。
在机器人领域中,AI技术的应用不断推动着机器人的发展和进步。
本文将介绍一些AI技术在机器人领域中的使用方法,并探讨其在提高机器人性能、增强交互能力和开发更复杂任务方面的潜力。
一、AI技术在提高机器人性能方面的应用1. 机器学习算法机器学习算法作为AI技术的核心,可以通过对大量数据进行训练和学习,使机器人能够自动调整行为并优化自身性能。
例如,在导航方面,基于深度学习的算法可以使机器人从传感器数据中提取关键信息,并实时更新地图和路径规划,从而实现更准确和高效的导航。
2. 计算机视觉计算机视觉是指让计算机模拟和理解人类视觉系统的能力,通过图像或视频输入来分析和识别场景中的对象。
在机器人领域,计算机视觉可以帮助机器人实时感知环境,识别物体和人类姿态,并做出相应反应。
例如,智能机器人可以通过计算机视觉识别用户的手势,从而实现远程控制和交互。
3. 自然语言处理自然语言处理使得机器人能够理解和产生人类语言,促进了与人的自然交流。
通过使用深度学习技术构建自然语言模型,机器人可以准确地理解和回答问题、执行指令,并提供更加个性化的服务。
例如,在餐厅中,AI技术可以使机器人根据顾客的口味和喜好提供定制化的菜单推荐。
二、AI技术在增强交互能力方面的应用1. 情感识别情感识别是一种利用AI技术分析声音、图像等数据来判断情感状态的方法。
将情感识别技术应用于机器人领域,使得机器人能够识别用户的情绪并作出相应反馈。
这有助于提升机器人与用户之间的互动体验,并满足用户情感需求。
2. 社交智能社交智能是指让机器人具备社会认知和行为表现的能力,以更好地融入人类社交环境并与人类进行沟通。
通过结合自然语言处理、计算机视觉和情感识别等技术,机器人可以更好地理解并回应人的社交行为,从而增强与人的互动性。

大模型在机器人视觉中的应用
大模型在机器人视觉中的应用非常广泛。
随着深度学习技术的发展,大模型已经成为机器人视觉领域的关键技术之一。
大模型通过大量的数据训练,可以学习到各种复杂的特征和模式,从而提升机器人对图像的识别和理解能力。
在机器人视觉中,大模型主要应用于以下几个方面:
1. 目标检测和识别:大模型可以通过训练学习识别不同类型的物体,包括人、物体、人脸等。
在机器人视觉中,目标检测和识别是实现机器人自主导航、交互等的关键技术。
2. 场景理解:大模型可以对图像中的场景进行理解和分类,从而帮助机器人更好地理解周围环境。
例如,机器人可以通过对不同场景的分类,实现自主导航、智能巡航等功能。
3. 图像生成和增强:大模型可以通过生成对抗网络(GAN)等技术生成高
质量的图像,从而增强机器人的感知能力。
例如,机器人可以通过生成人脸图像,实现人脸识别等功能。
4. 姿态估计和动作预测:大模型可以对图像中的姿态进行估计,预测人体的动作和行为,从而帮助机器人更好地与人类交互。
例如,机器人可以通过对人类手势的识别和理解,实现手势控制等功能。
总之,大模型在机器人视觉中的应用非常广泛,可以提升机器人的感知和理解能力,从而使其更好地适应各种复杂的环境和任务。
随着深度学习技术的不断发展,大模型在机器人视觉领域的应用前景将更加广阔。
第13卷㊀第9期Vol.13No.9㊀㊀智㊀能㊀计㊀算㊀机㊀与㊀应㊀用IntelligentComputerandApplications㊀㊀2023年9月㊀Sep.2023㊀㊀㊀㊀㊀㊀文章编号:2095-2163(2023)09-0111-05中图分类号:TP391.41文献标志码:A基于注意力机制的动态手势识别方法黄㊀圣,茅㊀健(上海工程技术大学机械与汽车工程学院,上海201620)摘㊀要:实时识别动态手势是一项艰巨的任务,因为系统永远无法知道手势在视频流中何时或从何处开始和结束㊂由于其各种应用,许多研究人员一直致力于基于视觉的手势识别㊂提出了一种基于3D卷积神经网络(3D-CNN)和长短期记忆(LSTM)网络相结合的深度学习框架,整个架构同时融合了注意力机制(CBAM)㊂所提出的架构从视频序列输入中提取时空信息,同时避免大量计算㊂3D-CNN用于提取光谱和空间特征,然后将特征图像提供给注意力机制模块,在增强图像特定区域的表征能力的同时加强特征的表达,最后通过LSTM网络进行分类㊂实验结果表明,所提方法能很好地识别动态手势,识别率达到了95.58%,验证了所提方法的有效性和可能性㊂关键词:动态手势识别;3D卷积神经网络;注意力机制;长短期记忆法;人机交互DynamicgesturerecognitionmethodbasedonattentionmechanismHUANGSheng,MAOJian(SchoolofMechanicalandAutomotiveEngineering,ShanghaiUniversityofEngineeringScience,Shanghai201620,China)ʌAbstractɔRecognizingdynamicgesturesinreal-timeisadifficulttaskbecausethesystemcanneverknowwhenorwherethegesturesbeginandendinthevideostream.Duetoitsvariousapplications,manyresearchershavebeenworkingonvision-basedgesturerecognition.Thispaperproposesadeeplearningframeworkbasedonthecombinationof3DConvolutionalNeuralNetwork(3D-CNN)andLongShort-TermMemory(LSTM)network,andthewholearchitecturealsoincorporatestheAttentionMechanism(CBAM).Theproposedarchitectureextractsspatiotemporalinformationfromvideosequenceinputwhileavoidingcomputationallyintensive.3D-CNNisusedtoextractspectralandspatialfeatures,andthenprovidethefeatureimagetotheattentionmechanismmoduletoenhancetherepresentationabilityofspecificregionsoftheimagewhiletellingthemodelwhattopayattentionto,andfinallyclassifyitthroughtheLSTMnetwork.theexperimentalresultsshowthattheproposedmethodcanrecognizedynamicgestureswell,andtherecognitionratereaches95.82%,whichverifiestheeffectivenessoftheproposedmethod.andpossibility.ʌKeywordsɔdynamicgesturerecognition;3Dconvolutionalneuralnetwork;attentionmechanism;longshort-termmemorymethod;human-computerinteraction作者简介:黄㊀圣(1996-),男,硕士研究生,主要研究方向:智能控制㊁模式识别;茅㊀健(1972-),男,博士,教授,硕士生导师,主要研究方向:航空装备检测与控制㊁智能机器人㊂通讯作者:茅㊀健㊀㊀Email:jmao@sues.edu.cn收稿日期:2022-09-290㊀引㊀言人机交互系统是人与机器之间进行交流和信息传递的桥梁[1]㊂手势是人类有效表达自身想法的主要工具,其从简单到复杂的不同动作,使之能够与他人交流㊂随着科学技术的发展和人们对智能设备的应用需求的不断增加,通过机器识别肢体动作,成为研究热点之一[2]㊂学习时空特征对于人类手势或动作识别的性能稳定至关重要㊂Li等人[3]提出了一种具有注意力机制技术的三维卷积神经网络(3D-ConvNets),用于学习时空特征㊂该模型在特征的时空学习方面优于简单的2D-CNN㊂Hakim等人[4]提出使用3D-CNN模型和LSTM提取23个手势的时空特征,在分类阶段之后,将有限状态机(FSM)与3D-CNN㊁LSTM模型融合,以监督分类决策㊂从上述的研究中可以得出:时间信息和LSTM对于处理动态手势时获得准确的手势预测非常重要㊂因此,许多研究者开始利用混合模型来学习和进行动态手势识别任务[5]㊂近年来,注意力机制作为深度学习领域的重大突破,通过计算特征信息的重要程度并分配权重来增强模型对重要特征的关注度㊂对此,本文提出了一种基于注意力机制的动态手势识别方法,结合3D-CNN㊁CBAM和LSTM的混合模型使用,并在20BN-Jester数据集上进行实验㊂1㊀基础理论1.1㊀3D卷积神经网络(3D-CNN)在2DCNN中,卷积层执行2D卷积,从前一层特征图上的局部邻域中提取特征,应用加性偏差,结果通过sigmoid函数传递㊂卷积应用于2D特征图,仅从空间维度计算特征;当应用于视频分析问题时,需要捕获编码在多个连续帧中的运动信息,为此在CNN的卷积阶段执行3D卷积,以计算空间和时间维度的特征[6]㊂将多个连续帧堆叠在一起形成立方体,将该立方体与3D内核进行3D卷积㊂通过这种构造,卷积层中的特征图连接到前一层中的多个连续帧,从而捕获运动信息㊂形式上,第i层中第j个特征图上位置(x,y,z)的值由式(1)给出:vxyzij=tanh(bij+ðmðPi-1p=0ðQi-1q=0ðRi-1r=0wpqrijmv(x+p)(y+q)(z+r)(i-1)m)(1)式中:tanh是双曲正切函数,bij是该特征图的偏差,m是与当前特征图相连的第(i-1)层中特征图集上的索引数,wpqrijm是连接到前一层中第m个特征图内核的第(p,q,r)个值,Ri是3D内核沿时间维度的大小,Pi和Qi分别是内核的高度和宽度㊂在子采样层中,通过在前一层的特征图上对局部邻域进行池化,来降低特征图的分辨率,从而增强输入失真的不变性㊂可以通过以交替方式堆叠多层卷积和二次采样,来构建CNN架构,CNN的参数(如偏差bij和核权重wpqrijm)通常使用有监督或无监督方法来学习㊂因为核权重会在整个立方体中复制,3D卷积核只能从框架立方体中提取一种类型的特征㊂CNN的一般设计原则是通过从同一组较低级别的特征图生成多种类型的特征,来增加后期层的特征图数量㊂与2D卷积情况类似,可以通过将具有不同内核的多个3D卷积,应用到前一层的相同位置来实现[7]㊂1.2㊀长短时记忆网络(LSTM)长短期记忆网络(LSTM)是对神经网络的扩展㊂LSTM单元结构由输入门㊁输出门和遗忘门组成,其控制学习过程,内部结构如图1所示㊂这些门是在sigmoid函数的帮助下调整,以控制学习过程中的打开和关闭[8]㊂LSTM中的长期记忆称为细胞状态,负责控制上一个LSTM单元格状态的信息,如果遗忘门输出状态为0,则告诉单元门忘记信息,如果为1,则告诉单元门将其保持在单元状态㊂h tC th tt a n ht a n hC t-1h t-1x tf t i t o tC t~σσσ图1㊀LSTM网络单元Fig.1㊀LSTMnetworkunit㊀㊀LSTM单元内的学习过程如式(2) 式(7):ft=σ(Wf[ht-1,xt]+bf)(2)it=σ(Wi[ht-1,xt]+bi)(3)C t=tanh(WC[ht-1,xt]+bC)(4)Ct=zt∗Ct-1+it∗C t(5)ot=σ(Wo[ht-1,xt]+bo)(6)ht=ot+tanh(Ct)(7)㊀㊀其中,it是输入门;ft是遗忘门;ot是输出门;σ为sigmoid激活函数;xt为t时刻的输入向量;wx为相应门的权重;bx为相应门的偏差;ht为t时刻的隐藏层状态向量;Ct是t时刻LSTM单元的细胞状态㊂遗忘门经由激活函数,输出一个0 1之间的数值,1表示完全保留,0表示完全舍弃㊂输入门通过tanh层创建候选状态,经由激活函数同样输出0 1之间的数值,决定候选状态Ct需要存储多少信息㊂更新记忆单元将更新旧的细胞状态,将Ct-1更新为Ct,遗忘掉由ft确定的需要遗忘的信息,然后加上it∗Ct,确定新的记忆单元Ct㊂输出门将内部状态的信息传递给外部状态ht,经由激活函数层确定需要被传递出去的信息,将细胞状态通过tanh层进行处理并于输出门的输出相乘,最终外部状态会获取到输出门确定输出的那部分[9]㊂1.3㊀CBAM网络在人类视觉大脑皮层中,使用注意力机制能够更快捷㊁高效地分析复杂场景信息,后来这种机制被研究人员引入到计算机视觉中来提高性能㊂注意力在告诉网络模型该注意是什么的同时也增强图像特定区域的表征能力[10]㊂Woo等人[11]提出了一种结211智㊀能㊀计㊀算㊀机㊀与㊀应㊀用㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀第13卷㊀合空间(spatial)和通道(channel)的注意力机制模块,被称为CBAM,相较于单一的注意力机制,混合注意力机制显得更加全面㊂CBAM模块能够针对一张特征图从通道和空间两个维度上产生注意力特征图信息,经过自适应修正产生最后的特征图㊂㊀㊀如图2所示,通道注意力机制,通过特征内部之间的关系来获取最终的通道注意力值,特征图的每个通道都被视作一个特征检测器㊂通过同时采用平均池化和最大池化来压缩特征图的空间维度,实现更高效地计算通道注意力特征;将特征输入多层感知机(MLP)生成最终的通道注意力机制特征图Mc㊂综上,通道注意力计算公式总结为式(8):㊀㊀MC(F)=σ(MLP(AvgPool(F))+MLP(MaxPool(F)))=σ(W1(W0(Fcavg))+W1(W0(Fcmax)))㊀㊀其中,σ为sigmoid函数;W1㊁W0为MLP权重;Fcavg和Fcmax分别代表平均池化特征和最大池化特征㊂最大池化输入特征图F均值池化M L P通道注意力M c (F)图2㊀通道注意力模型Fig.2㊀Channelattentionmodel㊀㊀如图3所示,空间注意力机制是通过特征图空间内部的关系,来产生空间注意力特征图㊂为了计算空间注意力,首先在通道进行维度平均池化和最大池化,然后将其产生的特征图拼接起来,对拼接后的特征图中进行卷积操作,来产生空间注意力特征图Ms㊂最终实现过程如式(9):㊀Ms(F)=σ(f7ˑ7([AvgPool(F);MaxPool(F)]))=σ(f7ˑ7(Fcavg;Fcmax))(9)其中,σ为sigmoid函数,f7ˑ7为7ˑ7大小的卷积核㊂空间注意力M s(F )卷积输入特征图F ′[最大池化,均值池化]图3㊀空间注意力模型Fig.3㊀Spatialattentionmodel㊀㊀CBAM注意力机制模块结构如图4所示,其完整计算过程可以概括为如下公式:Fᶄ=MC(F) F(10)Fᵡ=MC(Fᶄ) Fᶄ(11)㊀㊀其中,F为输入特征图,Fᵡ为输出特征图㊂优化后的特征F ″空间注意力通道注意力输入特征图F图4㊀CBAM完整结构Fig.4㊀CBAMcompletestructure2㊀基于注意力机制的动态手势识别模型2.1㊀模型提出本文构建的是动态手势识别方法,数据集均为动态手势视频帧图像所组成的集合㊂由于数据采集环境不受限制,视频帧图像可能存在环境背景复杂㊁光线强弱等方面的问题,因此对模型的特征提取能力和抗干扰能力要求较高㊂传统卷积神经网络(CNN)模型虽然拥有较强的深层特征提取能力,但是空间信息特征提取能力不足,同时无法捕捉时间序列信息的前后关系㊂学习空间和时间特征的结合是动态手势分类的必要要求㊂为了实现这一点,本研究使用了5层3D-CNN模型,其可以通过保留视频帧的空间信息来提取时间特征㊂但是,仅仅使用3D-CNN模型进行动态手势识别还不足以从视频数据中学习长期的时空信息㊂LSTM作为RNN的改进体,使用了一种特定的学习机制,明确了信息中需要被记住㊁需要被更新以及需要被注意的那些部分,以一种非常精准的方式来传递记忆,有助于在更长的时间内追踪信息㊂基于此,本文将3D-CNN与LSTM结合,使模型可以从空间和时间两个维度提取特征,使提取到的特征更加全面并且更具有代表性㊂此外,在3D-CNN层后加入CBAM,这种融合网络不会影响信息传输,同时模型可以自动学习得到图像的空间特征和通道特征的重要程度,根据重要程度来增强有用特征,自适应校准特征图像的空间和通道信息㊂相比于未添加注意力机制模块的网络模型,添加CBAM注意力机制模块对整体的网络结构影响不大,同时网络可以学习图像中更加重要的空间特征和通道特征㊂2.2㊀模型结构基于注意力机制的动态手势识别模型主要由3D-CNN层㊁注意力层㊁LSTM层㊁Dropout层以及311第9期黄圣,等:基于注意力机制的动态手势识别方法Softmax层组成,模型结构如图5所示㊂C o n v3D-3?3?3?32M a x P o o l i n g-1?2?2C o n v3D-3?3?3?64M a x P o o l i n g-2?2?2C o n v3D-3?3?3?128M a x P o o l i n g-2?2?2C o n v3D-3?3?3?128C o n v3D-3?3?3?128M a x P o o l i n g-2?2?2A t t e n t i o n-CB A ML S T MD r o p o u tS o f t m a x图5㊀模型框架Fig.5㊀ModelFramework㊀㊀其中,3D-CNN层由5个三维卷积层㊁4个最大池化层组成,通过视频帧图像提取时空特征㊂每个3维卷积核大小均为3ˑ3ˑ3,考虑到更好的保留时间细节,将第一卷积层和第一池化层的步幅和池化大小设置为1ˑ2ˑ2,其余各层的步幅和池化大小设置为2ˑ2ˑ2㊂特征图分别设置有32㊁64㊁1283种不同的过滤深度㊂池化方式采用最大池化,用于保留主要特征信息㊂将3D-CNN层提取到的特征图直接输入注意力层,CBAM模块会根据输入的特征图,序列化的生成通道注意力机制特征图和空间注意力机制特征图,两种特征图信息与原特征图相乘进行自适应修正,产生最后的特征图㊂将最终提取到的特征输入LSTM层,获取序列特征间的长期依赖关系㊂在LSTM层后添加一个值为0.5的Dropout层,保证输出的稀疏性,然后使用Softmax函数计算概率结果,实现动态手势的分类识别㊂3㊀实验结果与分析3.1㊀运行环境本次实验环境的硬件配置为IntelCorei7-11800HCPU,显卡为NVIDIARTX3070㊂软件环境为64位Ubuntu20.04操作系统,深度学习框架PyTorch,Python版本为3.8.10㊂3.2㊀数据预处理实验使用20BN-Jester大规模真实数据集,该数据集由1376个不同的参与者在不同的约束环境中生成㊂其中包含约148092个3秒长的短视频片段,每个视频至少由27帧视频图像组成㊂由于时间及内存资源限制,这项工作仅使用了27个手势中的12个㊂在原始数据集中,视频序列具有不同的长度,从27帧到46帧不等㊂对于数据预处理,首先统一所有视频帧数,将每个视频片段统一为30帧视频图像来训练模型㊂对于每帧视频图像均调整为112ˑ112像素㊂整个数据集中包含12个类共计6000个样本,每个类有500个样本㊂数据集按照8ʒ2分为训练集和验证集,其中80%为训练集和20%为验证集㊂3.3㊀实验结果讨论为了证明本文方法的有效性,实验对比了LSTM网络㊁3D-CNN网络㊁3D-CNN-LSTM混合网络在同一数据集上的识别效果,各个方法的输入均为经过预处理后的数据集㊂LSTM方法其模型主要由3个LSTM层㊁1个全连接层和Softmax层组成,LSTM单元数为128,全连接层节点数为64;3D-CNN网络模型包含5个三维卷积层㊁4个最大池化层㊁一个全连接层和Softmax层;3D-CNN-LSTM混合网络模型包含5个三维卷积层㊁4个最大池化层㊁1个LSTM层㊁1个Dropout层和Softmax层,卷积核尺寸为3ˑ3ˑ3,LSTM单元数为128㊂㊀㊀测试集数据包含12个动态手势类,每个类别分别包含100个文件㊂表1显示了使用20BN-Jester数据集中12个类在准确率方面对提出的混合模型与其它模型的比较结果㊂表1㊀数据训练集和测试集实验结果Tab.1㊀Experimentalresultsofdatatrainingandtestingsets方法训练集准确率/%损失测试集准确率/%损失3D-CNN96.450.133788.080.4628LSTM94.020.281688.940.34273D-CNN+LSTM98.580.0322791.220.37893D-CNN+CBAM+LSTM97.280.0806195.580.1656㊀㊀其中,本文提出模型对于动态手势实现了95.58%的验证准确率,相比较于不包含注意力机制模块的模型,在准确率方向提高了4.36%;相比较于单一模型的动态手势识别方法,准确率都有明显提升,该模型在取自20BN-jester数据集中12个类上产生了良好的结果㊂㊀㊀如图6㊁图7所示,从模型精度和模型损失曲线来看,由于模型是从头开始训练的,因此本次设置了411智㊀能㊀计㊀算㊀机㊀与㊀应㊀用㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀㊀第13卷㊀100个epoch来达到所需要的损失㊂对于前5个epoch,精度上升明显,损失非常高㊂后来,经过10个epoch,模型达到了较高的准确率㊂经过100个epoch的训练,模型的验证准确率达到95.58%且损失达到0.1656㊂1.00.90.80.70.60.50.40.30.2a c c a v l _a c c1815222936435057647178859299图6㊀模型准确率Fig.6㊀Modelaccuracy1.61.41.21.00.80.60.40.20l o s s v a l _l o s s1815222936435057647178859299图7㊀模型lossFig.7㊀Modelloss㊀㊀在总共1200个视频剪辑中,有100个被归类为 向左滑动 手势㊂实际上,有98个视频片段属于向左滑动类,因此模型正确预测了98个片段,但有2个视频片段被预测为其他类别,因此该类别的识别准确率为98%㊂所有类别中相对简单的手势如 竖起大拇指 手势,其识别准确率为100%㊂同样对于所有剩余的类,分类结果显示在如图8所示的混沌矩阵中㊂S w i p e l e f tS w i p e r i g h t S w i p e u p S w i p e d o w nS l i d i n g t w o f i n g e r s d o w n S l i d i n g t w o f i n g e r s u p Z o o mi n w i t h f u l l h a n d Z o o mo u t w i t h f u l t h a n d Z o o mi n w i t h t w o f i g n e r s Z o o mo u t w i t h t w o f i n g e r sT h u m b s u p T h u m b d o w nS w i p e l e f tS w i p e r i g h t S w i p e u p s w i p e d o w n S l i d i n g t w o f i n g e r s d o w n S l i d i n g t w o f i n g e r s u p Z o o m i n w i t h f u l l h a n d Z o o m o u t w i t h f u l t h a n d Z o o m i n w i t h t w o f i g n e r s Z o o m o u t w i t h t w o f i n g e r s T h u m b s u p T h u m b d o w nP r e d i c t i o n10080604020图8㊀混沌矩阵Fig.8㊀Chaoticmatrix4㊀结束语本文提出了一种新的深度学习模型,该模型可以学习视频流中动态手势序列的时空特征㊂该模型由3D-CNN网络㊁LSTM网络和注意力机制网络组成,该网络在复杂的背景和照明条件下学习所有视频帧的空间和时间特征㊂在模型中,动态手势数据的特征由3维卷积神经网络(3D-CNN)自动提取;使用CBAM注意力机制网络增强特征关注度;使用长短期记忆(LSTM)网络来学习时间序列数据的相关优势;最后采用SoftMax分类器对动态手势进行分类㊂经在20BN-Jester数据集的一个子集上进行训练,与单一模型和不包含注意力机制的混合模型相比,所提出的组合模型提供了更好的结果,动态手势识别性能更好㊂为了实现该算法的实际应用,后续工作会对算法的效率进行分析和提高㊂参考文献[1]WANGT,LIY,HUJ,etal.Asurveyonvision-basedhandgesturerecognition[C]//SmartMultimedia:FirstInternationalConference,ICSM2018,Toulon,France,August24–26,2018,RevisedSelectedPapers.Cham:SpringerInternationalPublishing,2018:219-231.[2]FANGL,FUM,SUNS,etal.Overviewoffacerecognitionmethods[C]//SignalandInformationProcessing,NetworkingandComputers:Proceedingsofthe5thInternationalConferenceonSignalandInformationProcessing,NetworkingandComputers(ICSINC).SpringerSingapore,2019:22-31.[3]JUN,LI,XIANGLONG,etal.Spatio-temporaldeformable3DConvNetswithattentionforactionrecognition-ScienceDirect[J].Patternrecognition,2020,98:107037.[4]HakimNL,ShihTK,KasthuriArachchiSP,etal.Dynamichandgesturerecognitionusing3DCNNandLSTMwithFSMcontext-awaremodel[J].Sensors,2019,19(24):5429.[5]WANJ,LISZ,ZHAOY,etal.ChaLearnLookingatPeopleRGB-DIsolatedandContinuousDatasetsforGestureRecognition[C]//2016IEEEConferenceonComputerVisionandPatternRecognitionWorkshops(CVPRW).IEEE,2016:56-64.[6]梁正友,何景琳,孙宇.一种用于微表情自动识别的三维卷积神经网络进化方法[J].计算机科学,2020,47(8):227-232.[7]佘海龙,解山娟,邹静洁.标准分数降维的3D-CNN高光谱遥感图像分类[J].计算机工程与应用,2021,57(4):169-175.[8]谷学静,周自朋,郭宇承,等.基于CNN-LSTM混合模型的动态手势识别方法[J].计算机应用与软件,2021,38(11):205-209.[9]麻文刚,张亚东,郭进.基于LSTM与改进残差网络优化的异常流量检测方法[J].通信学报,2021,42(5):23-40.[10]王粉花,张强,黄超,等.融合双流三维卷积和注意力机制的动态手势识别[J].电子与信息学报,2021,43(5):1389-1396.[11]WOOS,PARKJ,LEEJY,etal.CBAM:ConvolutionalBlockAttentionModule[C]//EuropeanConferenceonComputerVision.Springer,Cham,2018:3-19.511第9期黄圣,等:基于注意力机制的动态手势识别方法。
机器人系统的组成1. 引言机器人系统是一种由人工智能技术驱动的自动化系统,能够模拟人类的行为和思维,并执行特定的任务。
机器人系统由多个组件组成,这些组件相互协作,以实现机器人的各种功能。
本文将详细介绍机器人系统的组成。
2. 传感器传感器是机器人系统的重要组成部分,用于感知和理解环境。
传感器收集来自外部世界的数据,并将其转化为机器人可识别的形式。
机器人系统常用的传感器包括:•视觉传感器:如摄像头和激光雷达,用于捕捉和识别图像、障碍物等。
•声音传感器:用于接收声音信号,并进行声音识别和语音交互。
•触觉传感器:如触摸传感器和力传感器,用于感知物体的触摸和压力。
•陀螺仪和加速度计:用于测量机器人的姿态和加速度。
•温度传感器和湿度传感器:用于测量环境的温度和湿度。
3. 执行器执行器是机器人系统的动力部分,用于控制机器人的动作。
执行器接收来自控制系统的指令,并将其转化为实际的动作。
常见的执行器包括:•电机和伺服驱动器:用于控制机器人的运动,如步态、手臂运动等。
•喷墨和打印头:用于实现机器人的打印和绘画功能。
•声音发生器:用于机器人的语音输出。
•手爪和夹具:用于机器人的抓取和操作。
4. 控制系统控制系统是机器人系统的”大脑”,负责决策和规划机器人的行为。
控制系统接收来自传感器的数据,并根据预定义的算法和规则,做出决策并发送指令给执行器。
控制系统的组成包括:•硬件控制:负责将传感器和执行器连接到控制系统中,并确保其正常运行。
•感知与感知处理:负责接收传感器数据,并对其进行处理和分析,以提取有用的信息,如图像识别、语音识别等。
•决策与规划:负责根据传感器数据和预定义的规则和算法,做出决策,并生成机器人的行为计划。
•学习与智能:负责机器人的学习和自适应能力,通过机器学习和深度学习等技术,实现机器人具备智能和适应性。
5. 人机交互界面人机交互界面是人与机器人进行交互的界面,使人能够与机器人进行信息的传递和交流。
人机交互界面可以采用多种形式,如:•触摸屏和显示器:通过触摸和显示屏上的图形界面,实现与机器人的交互。
机械手应用于自动化测试和手势模仿技术的研究摘要:伴随着人工智能的发展,计算机视觉技术的发展也是相当的迅速。
将计算机视觉技术与人机交互技术相结合,也是近年来研究的热点。
但是将计算机视觉技术与机械臂结合应用在应用程序的自动化测试研究相对较少且存在极大的提升空间。
因此,本文提出了一种基于机器人用户界面的自动化测试方法。
同时重点研究了基于Vicon进行手臂和手部的数据采集并传递给机器人实时模拟人体抓取物体的操作。
关键词:机械手;自动化测试;手势模仿技术引言本文提出了一种基于机器人用户界面的自动化测试方法。
本方法舍弃了自动化测试框架,转而采用一种新的方法。
首先,使用无线投屏技术取代传统的摄像头。
这不仅节省了测试成本而且降低了识别用户界面元素的难度。
其次,采用先进的光学字符识别技术从复杂的背景图像中准确定位出待点击的文本元素。
当需要对图像元素进行定位的时候,则采用归一化相关匹配算法进行定位。
最后将定位到的坐标传递给高精度的UR3机器人执行点击操作。
1 基于机器人的移动应用自动化测试无线投屏技术可以将移动设备的屏幕实时投影到计算机屏幕上。
OCR算法可以识别界面中的文本元素并返回识别出来的文本元素的坐标信息,归一化相关匹配算法可以识别界面中的图标元素并返回识别出来的图标元素的坐标信息。
工业机器人可以代替人体功能执行点击移动设备屏幕操作。
本文将计算机视觉算法与工业机器人相结合,提出了一种用户界面自动化测试系统。
1.1 用户界面元素检测检测应用程序界面上的元素信息可分为以下三个步骤。
首先,将移动设备屏幕投屏到计算机屏幕上。
然后,从计算机屏幕中检测出移动设备的屏幕。
最后,使用OCR算法和归一化相关匹配算法定位用户界面上的元素。
1.2 执行系统执行系统的组成是一台六轴机械臂和一支充电的电容式触控笔。
通过以上步骤获取元素的坐标,然后将坐标发送给机器人以执行点击操作。
在执行点击之前需要进行初始化。
初始化的目的是为了得到移动设备界面在计算机屏幕上的位置信息和界面的像素尺寸。