SNP及检测技术
- 格式:doc
- 大小:184.50 KB
- 文档页数:73

snp原理
SNP(Single Nucleotide Polymorphism,单核苷酸多态性)是指在基因组中,一个单个核苷酸的改变而导致的遗传变异。
它是人类基因组中最常见的遗传变异形式,约占所有遗传变异的90%。
SNP的形成可以由DNA复制错误、环境因素、突变等多种原因引起。
在人类基因组中,SNP通常被广泛分布并遵循一个特定的模式。
SNP的检测可以通过多种方法进行,例如DNA测序技术。
在SNP分析中,通常会选择一小段与某个基因或疾病相关的DNA序列进行测序,然后比较不同样本之间的差异。
如果在比较样本之间发现了SNP,就可以推断某个基因组中的SNP 可能与特定的性状、疾病或药物反应相关。
SNP的研究对于了解基因组的差异、个体间的遗传变异以及疾病的发生机制都非常重要。
通过大规模SNP分析,可以发现某些SNP与特定疾病的易感性之间存在关联,从而帮助研究人员更好地了解疾病的遗传基础。
此外,SNP也可以用于个体基因组的鉴定和个性化医疗的发展。
总的来说,SNP是一种常见的遗传变异形式,可以通过多种方法进行检测。
它在基因组研究中具有重要意义,有助于揭示基因与性状、疾病、药物反应等之间的关系。


蜜蜂序列组装分析及SNP位点检测蜜蜂是我们非常熟悉的昆虫之一,也是非常重要的生态系统组成部分。
在蜜蜂的研究中,基因组学技术也越来越受到关注和应用。
本文将介绍蜜蜂基因组组装和SNP位点分析的相关内容。
一、蜜蜂基因组组装基因组组装是将测序数据转换为完整的基因组序列的过程。
蜜蜂基因组组装的过程和其他生物物种的基因组组装类似,但由于其基因组大小较小,组装过程相对较容易。
蜜蜂基因组组装的第一步是建立一个高质量的基因组序列库。
这包括用不同的方法制备高质量的DNA样品、建立测序文库并进行高通量测序等。
蜜蜂的基因组测序是高度复杂的过程,需要通过多个测序平台(如Illumina HiSeq、PacBio等)进行组合。
在获得测序数据后,需要对数据进行预处理,如去除低质量序列、去除冗余序列、纠正测序错误等。
然后,将这些清洗后的序列通过不同的软件进行组装,并利用其他评估工具对组装质量进行评估。
最终的基因组序列可以通过验证和加工来达到最终的精度。
二、SNP位点检测SNP(single nucleotide polymorphism)是指基因组中的单个碱基差异。
SNP是生物基因组中最常见的组成成分之一,也是进化研究和基因组组装等生物信息学研究中广泛应用的工具之一。
在蜜蜂研究中,SNP位点分析可以帮助我们了解种群群体、家系和探测基因功能等。
SNP位点检测的步骤包括:(1)基因组序列和基因序列的比对;(2)确立SNP位点;(3)SNP位点筛选和统计;(4)SNP位点功能分析。
首先,需要将测序数据比对到参考基因组序列上,然后使用SNP检测软件如SAMtools、GATK等,通过生物统计学方法筛选SNP位点。
接下来,使用过滤器将SNP位点进行分组和筛选,去除无效SNP位点,比如低质量位点。
最终,SNP位点的功能分析可以通过注释工具进行。
这包括检测SNP位点是否对蛋白质编码区域有影响、是否为突变位点等。
三、应用和展望蜜蜂基因组组装和SNP位点检测技术对于我们了解蜜蜂适应性进化、抗逆性、基因结构和基因功能都有着重要的意义。

SNP分子标记的原理及应用解读SNP(Single Nucleotide Polymorphism,单核苷酸多态性)是指个体间在DNA序列中存在的单个碱基差异。
SNP是最常见的遗传变异形式,它在基因组中广泛存在,可以用来研究个体之间的遗传差异。
SNP分子标记技术通过检测SNP位点上的碱基差异,可以用来研究生物个体的遗传相关性、种群结构、物种起源、适应性以及疾病的遗传风险等。
SNP分子标记的原理是基于PCR(聚合酶链反应)技术,在PCR反应中引入荧光标记的引物来扩增感兴趣的SNP位点。
SNP位点上的碱基差异会导致引物与模板DNA序列的匹配性不同,从而影响PCR反应的效率和产物的数量。
这种差异可以通过凝胶电泳或者高通量测序等方法来检测。
1.遗传研究:SNP是人类基因组中最常见的遗传变异形式,可以用来研究个体之间的遗传差异。
通过分析SNP位点上的碱基差异,可以确定个体之间的亲缘关系、种群的遗传结构以及物种的起源演化等。
2.遗传性疾病的研究:SNP位点与许多遗传性疾病之间存在关联。
通过分析SNP位点上的碱基差异,可以确定个体对一些疾病的易感性风险,进而进行早期预防和干预。
3.个体化药物治疗:个体的基因差异可以影响药物的代谢和疗效。
通过分析SNP位点上的碱基差异,可以预测个体对一些药物的反应,进而实现个体化的药物治疗。
4.农业育种:SNP分子标记可用于农作物和家畜等的品种鉴定、个体选择和育种进展的监测等。
通过分析SNP位点上的碱基差异,可以选择具有优良特性的个体进行育种,提高农作物和家畜的产量和品质。
除了以上几个应用领域,SNP分子标记还可以应用于环境研究、种群遗传分析、疾病的诊断和预后、区域起源和扩散等方面。
由于其高度可重复性、高通量性和成本效益等特点,SNP分子标记已成为现代生命科学研究的重要工具之一、随着高通量测序技术的不断发展,SNP分子标记技术还将进一步发展和应用。

人类基因组研究中的SNP分析随着现代科技的快速发展,人类已经进入了基因组时代。
在这个时代里,基因组研究是关键的一环,因此,人类基因组研究已成为当前热门科学研究领域。
SNP是人类基因组研究中非常重要的一种基因类型,其全称为“单核苷酸多态性”(Single nucleotide polymorphisms),是指基因组DNA序列上的单个核苷酸发生突变的现象。
这些突变可能会对个体的遗传特征、代谢和疾病易感性产生影响,因此,SNP分析被广泛应用于人类基因组的研究。
SNP分析的意义SNP分析作为一种高效而有效的基因分析方法,其应用范围非常广泛。
除了帮助人们更好地了解人类基因组的不同特征外,SNP分析也可以被应用于以下领域:1. 遗传病研究基因突变是遗传病发生的原因之一,而SNP的变异也可能引起明显的遗传病症状。
SNP分析可以帮助科学家更好地了解这些突变与遗传病之间的关系,从而提供更有效的治疗方法。
2. 药物研究SNP分析在药物研究过程中也可以发挥重要作用。
因为不同人群人体内的代谢和反应机制是不一样的,因此,在开发新药物的过程中,SNP分析可以提供更全面的信息,从而提高药物的效率和安全性。
3. 个性化医疗随着SNP分析的应用越来越广泛,越来越多的医疗机构开始使用它来提供更精准的治疗方案。
根据患者的基因信息,医生可以制定更适合个人的治疗方法,从而提高治疗效果和疗效持续时间。
SNP分析的方法SNP分析的方法有很多,其中最常见的两种方法是Sanger测序和芯片技术。
1. Sanger测序Sanger测序是SNP分析的传统方法,之所以广泛应用,是因为它是一种基于荧光技术的自动测序方法。
Sanger测序的具体原理如下:首先,将DNA样本与引物一起反应,通过PCR技术扩增目标基因区域。
然后,将PCR产物分离并富集,通过荧光标记的引物在ABI 3730 DNA自动测序仪上进行自动测序。
最后,通过电脑软件将测序结果转化为DNA碱基序列。
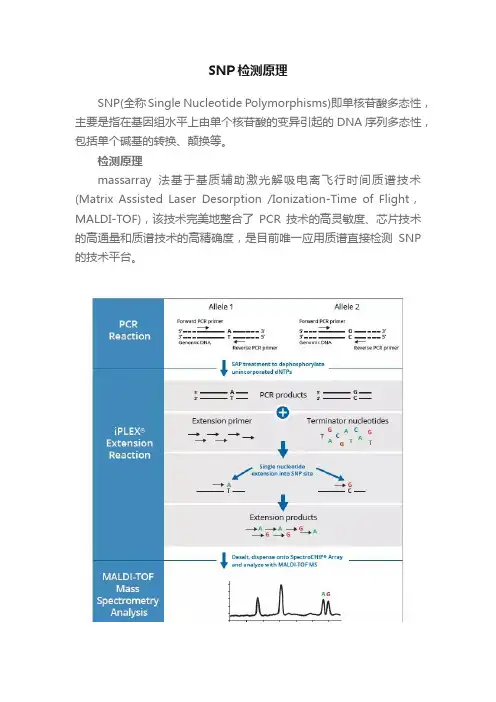

1定义:单核苷酸多态性( single nucleotide polymorphism,SNP),主若是指在基因组水平上由单个核苷酸的变异所惹起的 DNA 序列多态性。
它是人类可遗传的变异中最常有的一种。
占全部已知多态性的 90%以上。
SNP 在人类基因组中宽泛存在,平均每 500~1000 个碱基对中就有1 个,预计其总数可达 300 万个甚至更多。
SNP 所表现的多态性只波及到单个碱基的变异,这类变异可由单个碱基的变换(transition)或颠换(transversion)所惹起,也可由碱基的插入或缺失所致。
但平时所说的 SNP 其实不包括后两种情况。
单核苷酸多态性( SNP)是指在基因组上单个核苷酸的变异,包括置换、颠换、缺失和插入。
所谓变换是指同型碱基之间的变换 ,如嘌呤与嘌呤 ( G2A) 、嘧啶与嘧啶( T2C) 间的取代 ;所谓颠换是指发生在嘌呤与嘧啶 (A2T 、A2C 、C2G、G2T) 之间的取代。
从理论上来看每一个 SNP 位点都能够有 4 种不同的变异形式,但实质上发生的只有两种,即变换和颠换,两者之比为 2:1。
SNP 在 CG 序列上出现最为频频,而且多是C 变换为 T ,原因是 CG 中的 C 常为甲基化的,自觉地脱氨后即成为胸腺嘧啶。
一般而言, SNP 是指变异频率大于 1 %的单核苷酸变异。
在人类基因组中大体每 1000 个碱基就有一个 SNP ,人类基因组上的 SNP 总量大体是 3 ×106个。
依照排列组合原理 ,SNP 一共能够有 6 种取代情况,即 A/ G、 A/ T 、A/ C 、C/ G、C/ T 和 G/ T ,但事实上 ,变换的发生频率占多数 ,而且是 C2T 变换为主 ,其原因是 Cp G 的 C 是甲基化的 ,简单自觉脱氨基形成胸腺嘧啶T , Cp G 也所以变为突变热点。
理论上讲,SNP 既可能是二等位多态性,也可能是3 个或4 个等位多态性,但实质上,后两者特别少见,几乎能够忽略。

SNP芯片的原理及应用1. 引言单核苷酸多态性(Single Nucleotide Polymorphism,SNP)是基因组中最常见的变异形式,它在人类疾病的研究中起着重要的作用。
SNP芯片是一种高通量基因分型技术,可以用来检测个体基因组中的上万个SNP位点。
本文将介绍SNP芯片的原理以及其在各个领域的应用。
2. SNP芯片的原理SNP芯片是一种将DNA序列多态性引入到DNA芯片上的高通量基因分型工具。
其基本原理如下:1.选择SNP位点:根据研究目的和基因组数据库的数据,选择与感兴趣的生物学过程或疾病相关的SNP位点。
2.设计引物:根据选择的SNP位点序列设计引物,通常采用探针杂交的方式。
引物的设计需要考虑SNP的位点和碱基对应情况。
3.制备芯片:将设计好的引物固定在芯片表面上,并将每个SNP位点的引物排列成阵列状,以便同时检测多个SNP位点。
4.样品准备:从被检测的个体中提取DNA样品,并使用PCR扩增目标SNP位点的DNA片段。
5.杂交:将扩增好的DNA样品加入到芯片上,利用引物与样品中相应DNA片段的互补序列形成特异性的杂交。
6.洗涤:通过洗涤过程去除未结合的DNA片段,使只有与芯片上相应引物杂交的DNA片段留在芯片上。
7.形成芯片图像:利用特定的扫描仪扫描芯片,根据芯片上不同位置的荧光信号强度来分析每个SNP位点上的基因型。
3. SNP芯片的应用SNP芯片在各个领域的应用非常广泛,下面列举了几个典型的应用示例:3.1. 人类遗传疾病研究SNP芯片在人类遗传疾病研究中发挥着重要作用。
通过比较病例组和对照组的SNP芯片数据,可以发现与疾病相关的SNP位点,进而研究疾病的致病机制和发展规律。
例如,在癌症研究中,SNP芯片常用于寻找与癌症发生和进展相关的遗传变异。
3.2. 农业育种SNP芯片在农业育种中的应用越来越广泛。
农业科学家可以利用SNP芯片分析大量的植物或动物个体,筛选出具有优良基因型的品种或个体,从而加快优质农产品的培育速度。

snp芯片SNP芯片(Single Nucleotide Polymorphism chips)是一种高通量基因分型技术,目前广泛应用于基因组学研究和个体遗传变异的检测。
SNP芯片可以同时检测数千至数百万个单核苷酸多态性位点,从而快速、精准地分析个体间的遗传差异。
SNP(Single Nucleotide Polymorphism)是指基因组中单个核苷酸发生变异的位置。
它们是人类遗传变异中最常见的形式,每个人的基因组中大约有数百万个SNP。
通过对SNP的识别和分析,可以研究个体之间的遗传差异,并且了解这些差异与健康、疾病以及药物反应等方面的关系。
SNP芯片是通过DNA芯片技术实现SNP的检测和分析。
其基本原理是将经过特定设计的探针固定在芯片上,探针可以与特定的SNP序列互相匹配。
然后,样本DNA经过扩增和标记处理,与芯片上的探针进行杂交,并通过荧光等方式进行信号检测。
根据信号的强度,可以确定每个位点上的SNP类型。
SNP芯片的优势在于高通量、高准确性和高效率。
相比传统的基因分型方法,SNP芯片可以同时分析大量SNP位点,大大提高了研究效率。
同时,SNP芯片的准确性也非常高,可以达到99%以上。
此外,SNP芯片还具有良好的可重复性和可比性,可以在不同实验室之间进行数据交流和共享。
SNP芯片广泛应用于基因组学研究、人类遗传学和药物研发等领域。
在基因组学研究中,SNP芯片可以用于遗传关联研究,寻找与疾病或性状相关的SNP位点。
在人类遗传学中,SNP芯片可以用于研究不同人群之间的遗传差异,了解人类种群演化和迁移的历史。
在药物研发中,SNP芯片可以用于个体化药物治疗的研究,根据个体的遗传信息优化药物方案,提高疗效和减少副作用。
然而,SNP芯片也存在一些局限性。
首先,SNP芯片只能检测已知的SNP位点,对于未知或罕见的变异无法检测。
其次,SNP芯片无法检测复杂的遗传变异,如插入缺失、倒位等结构变异。
此外,SNP芯片的解读和分析需要复杂的生物信息学算法和数据库支持,对研究人员的专业水平提出了要求。


一大类是以单链构象多态性(SSCP) 、变性梯度凝胶电泳(DDGE) 、酶切扩增多态性序列(CAPS) 、等位基因特异性PCR (allele-specific PCR,AS-PCR)等为代表的以凝胶电泳为基础的传统经典的检测方法另一大类是以直接测序DNA芯片变性、高效液相色谱(DHPLC)、质谱检测技术高分辨率溶解曲线(HRM)等为代表的高通量自动化程度较高的检测方法。
1.单链构象多态性(SSCP)方法的原理是PCR扩增的DNA片段在变性剂条件下,通过高温处理使双链DNA扩增片段解旋并且维持单链状态,进一步进行非变性聚丙烯酰胺凝胶电泳。
由于DNA单链的空间构象决定着其迁移率,相同长度的DNA单链,若某单个碱基存在差异,则形成迥然不同的空间构象,就会显示出带型的差异(多态型) 。
优点:该方法简便灵敏快速成本低缺点:PCR-SSCP适用于小的DNA片段,长度小于500 bp,如果DNA片段太长,DNA单链很难形成稳定发夹结构。
但是该方法只能对突变进行较为粗略地检测,不能确定突变的具体位置和类型;而且对电泳条件的要求非常严格。
2.变性梯度凝胶电泳(DDGE)在DNA序列中,4种碱基的组成和排列存在差异,致使不同序列的DNA双链有着不同的解旋温度当DNA分子在含浓度梯度变性剂的聚丙烯酰胺凝胶中进行电泳时,由于解旋的状况与其序列高度相关,使得不同DNA片段形成相互分开的条带。
DGGE利用双链DNA分子在含有一定浓度梯度变性剂的凝胶中进行电泳时,由于存在突变的双链DNA分子和不存在突变的双链DNA分子在不同的部位解旋而区分即使只有一个碱基对的不同,两个双链DNA分子在不同的时间发生部分解旋,随之形成有差异的电泳条带。
由于存在突变DNA片段和正常DNA 片段的Tm值有差异,从而发生迥然不同的解旋行为,TGGE通过设置温度梯度在聚丙烯酰胺凝胶电泳中分离DNA差异片段。
优点:DGGE能够检测长达1 kb的DNA片段,若SNP恰好出现在发生部分解旋的DNA区域内,其检出率可以高达100%,特别是100~500 bp长度的片段。
SNP的检测方法(直接测序法与PCR-SSCP)人类基因组中存在着广泛的多态性,最简单的多态形式是发生在基因组中的单个核苷酸的替代,即单核苷酸多态性(single nucleotide polymorphisms, SNPs)。
S NP通常是一种二等位基因的(biallelic),即二态的遗传变异,SNP的数量大、分布广,在组成人类基因组的30亿个碱基中,平均每1000个就有一个SNP。
SNP作为第三代遗传标记,在复杂疾病的基因定位、关联分析、个体疾病易感性分析与药物基因组学的研究中发挥着愈来愈重要的作用。
1.直接测序法进行SNP分析在所有SNP的检测方法中,对欲检测片段进行直接扩增、测序是最为准确的方法。
通常情况下,纯合型SNP位点的测序峰为单一峰型,而杂合型SNP位点的测序峰为套峰,因而很容易将其区分开来。
通过直接测序方法进行SNP检测的检出率接近100%。
2. PCR-SSCP方法单链构象多态性分析(single-strand conformation polymorphism,SSCP)是一种简单、高效地检测DNA或RNA序列中点突变的技术,由于实验成本较低,也是一种目前较为常用的方法。
检测原理:单链DNA片段呈复杂的空间折叠构象,这种立体结构主要是由其内部碱基配对等分子内相互作用力来维持的,当有一个碱基发生改变时,会或多或少地影响其空间构象,使构象发生改变,空间构象有差异的单链DNA分子在聚丙烯酰胺凝胶中受排阻大小不同。
因此,通过非变性聚丙烯酰胺凝胶电泳(PAGE),可以非常敏锐地将构象上有差异的分子分离开。
需要注意的问题:A.PCR-SSCP只能作为一种突变检测方法,要最后确定突变的位置和类型,还需进一步测序。
B.由于SSCP是依据点突变引起单链DNA分子立体构象的改变来实现电泳分离的,这样就可能会出现当某些位置的点突变对单链DNA分子立体构象的改变不起作用或作用很小时,再加上其他条件的影响,使聚丙烯酰胺凝胶电泳无法分辨造成漏检。
SNP分析及其在遗传学中应用情况简介单核苷酸多态性(Single Nucleotide Polymorphism,SNP)是人类基因组中最常见的遗传变异形式之一。
SNP分析是研究个体之间以及不同种群之间遗传差异的有力工具。
随着高通量测序技术和生物信息学的发展,SNP分析已经成为遗传学研究中的一个重要领域,为我们理解基因变异与疾病风险、药物反应以及个体差异等提供了深入的了解。
SNP分析技术SNP分析的主要技术包括SNP芯片和基于测序的方法。
SNP芯片利用微阵列技术在一块芯片上同时检测大量的SNP位点。
而基于测序的方法则通过对个体基因组的全面测序来获取SNP信息。
两种方法各有优劣势,选择合适的方法应根据研究目的和预算来决定。
SNP在人类遗传学中的应用1. 疾病风险预测SNP与疾病之间存在密切的关联。
通过大规模SNP关联研究(Genome-wide Association Study,GWAS),研究人员已经发现了大量与疾病相关的SNP位点。
这些位点可以用来预测个体患病的风险,对疾病的早期筛查以及制定个性化的治疗方案具有重要意义。
2. 遗传进化研究SNP分析可以帮助我们了解人类和其他物种的遗传演化历程。
通过比较不同种群之间的SNP差异,研究人员可以揭示人类迁徙历史、种群形成以及适应性进化等重要信息。
此外,SNP还能用于研究个体之间的近交程度以及人类的远亲关系。
3. 药物反应预测个体对药物的反应存在很大的差异,这主要受遗传变异的影响。
SNP分析可以帮助我们预测个体对特定药物的反应情况,从而指导临床用药。
例如,根据某些特定的SNP位点,可以预测患者是否对某种药物具有耐药性,以及药物代谢速度的快慢。
4. 父权鉴定和犯罪侦查SNP分析可以利用个体之间的基因型差异来进行父权鉴定和犯罪侦查。
通过比较孩子和母亲、孩子和潜在父亲之间的SNP位点,可以确定孩子的生物学父亲。
此外,对犯罪现场的DNA样本与嫌疑人DNA样本进行SNP分析,还可以帮助警方追踪犯罪嫌疑人。
玉米品种鉴定技术规程一、引言玉米是我国重要的粮食作物之一,而对于玉米的种质资源鉴定与保护具有重要意义。
传统的玉米品种鉴定方法往往依赖于形态学特征和遗传学性状,但这些方法存在一定的局限性,因此迫切需要引入新的鉴定技术,其中snp 分子标记法是一种全基因组基础的玉米品种鉴定技术,具有高通量、高分辨率和高灵敏度等特点,能够有效地解决传统鉴定方法存在的问题。
本文即将介绍玉米品种鉴定技术规程中的snp 分子标记法。
二、snp 分子标记法的基本原理snp (single nucleotide polymorphisms)是一种常见的DNA序列变异类型,是基因组中地位较为稳定的核苷酸多态性,是DNA分子在个体间存在的一种常见差异。
snp 分子标记法通过检测DNA序列中snp位点的变异情况,从而进行玉米品种的鉴定。
其基本原理包括:通过PCR技术扩增目标DNA片段,然后对扩增产物进行SNP位点检测,并通过测序、杂交或其他方法判断样品间的差异,最终进行品种鉴定。
三、snp 分子标记法在玉米品种鉴定中的应用1. 样品的DNA提取在进行snp 分子标记法鉴定之前,需要进行样品的DNA提取工作。
通常可以采用CTAB法、硅胶柱法、磁珠法等方法进行DNA提取,确保所提取的DNA质量和纯度适合于后续的PCR扩增和序列检测。
2. PCR扩增PCR扩增是snp 分子标记法的关键步骤之一,可以选择合适的引物设计,按照PCR扩增的优化条件进行反应,扩增目标DNA片段。
在PCR扩增中,需要注意反应体系的准确配制、反应条件的控制和PCR 产物的纯化等工作。
3. SNP位点检测在获得PCR产物之后,需要进行SNP位点的检测工作。
可以通过测序、引物延伸、核酸芯片或者其他方法进行SNP位点的检测,从而确定样品间的差异情况。
4. 数据分析与鉴定结果获得SNP位点的检测数据之后,需要进行数据分析工作,可以利用生物信息学软件或其他统计学方法进行数据的处理和分析,最终得出品种鉴定的结果。
SNP分子标记的原理及应用概述单核苷酸多态性(SNP)是一种常见的基因组变异,它在基因组中占据重要地位。
SNP作为一种重要的分子标记,具有许多应用。
本文将从SNP的基本原理开始介绍,然后探讨SNP分子标记在遗传研究、医学诊断、农业育种等领域的应用。
SNP的原理SNP是指在基因组中单个核苷酸处发生的变异。
这些变异可以导致个体间的遗传差异,可能与疾病易感性、药物反应性、表型特征等相关。
SNP的形成有多种机制,包括突变、重组、等位基因演化等。
SNP的检测方法SNP的检测可以采用多种方法,其中最常用的方法包括:1.基于PCR的方法:通过特异性引物扩增目标SNP区域,并使用限制性内切酶或测序等技术进行检测。
2.基于芯片的方法:利用芯片上固定的DNA探针与样品DNA杂交,通过检测信号强度来确定SNP的基因型。
3.基于测序的方法:利用高通量测序技术对样品DNA进行测序,通过分析碱基对应位置碱基的差异来确定SNP。
4.基于大规模变异分析的方法:利用高通量基因分型技术,如SNP芯片、全基因组关联研究等,进行全基因组范围的SNP检测。
SNP分子标记的应用遗传研究SNP分子标记在遗传研究中发挥着重要的作用。
它可以用于构建遗传连锁图谱、进行群体遗传结构分析以及进行复杂疾病的关联分析。
通过分析SNP与特定性状的关系,可以探索人类遗传变异与疾病发生发展的相关性。
医学诊断SNP分子标记在医学诊断中具有潜在的应用。
通过分析个体SNP的基因型,可以帮助预测个体对某些药物的反应性以及易感性疾病的风险。
此外,SNP分子标记也可以用于亲子鉴定以及疾病致病基因的筛查。
农业育种SNP分子标记在农业育种中被广泛应用。
通过分析作物或家畜的SNP基因型,可以鉴定优良品种、预测物种的遗传背景、进行种质资源保护和遗传改良。
SNP分子标记的应用可以有效提高育种工作的效率和准确性。
DNA人身鉴定SNP分子标记在人身鉴定领域也起到了重要作用。
通过对个体的SNP基因型进行分析,可以确定个体的遗传信息,用于刑事侦破、亲子关系鉴定以及基因地理学研究等方面。
1定义: 单核苷酸多态性(single nucleotide polymorphism,SNP),主要是指在基因组水平上由单个核苷酸的变异所引起的DNA序列多态性。它是人类可遗传的变异中最常见的一种。占所有已知多态性的90%以上。SNP在人类基因组中广泛存在,平均每500~1000个碱基对中就有1个,估计其总数可达300万个甚至更多。SNP所表现的多态性只涉及到单个碱基的变异,这种变异可由单个碱基的转换(transition)或颠换(transversion)所引起,也可由碱基的插入或缺失所致。但通常所说的SNP并不包括后两种情况。单核苷酸多态性(SNP)是指在基因组上单个核苷酸的变异,包括置换、颠换、缺失和插入。所谓转换是指同型碱基之间的转换,如嘌呤与嘌呤( G2A) 、嘧啶与嘧啶( T2C) 间的替换;所谓颠换是指发生在嘌呤与嘧啶(A2T、A2C、C2G、G2T) 之间的替换。从理论上来看每一个SNP 位点都可以有4 种不同的变异形式,但实际上发生的只有两种,即转换和颠换,二者之比为2:1。SNP 在CG序列上出现最为频繁,而且多是C转换为T ,原因是CG中的C 常为甲基化的,自发地脱氨后即成为胸腺嘧啶。一般而言,SNP 是指变异频率大于1 %的单核苷酸变异。在人类基因组中大概每1000 个碱基就有一个SNP ,人类基因组上的SNP 总量大概是3 ×106 个。依据排列组合原理,SNP 一共可以有6种替换情况,即A/ G、A/ T、A/ C、C/ G、C/ T 和G/ T ,但事实上,转换的发生频率占多数,而且是C2T 转换为主,其原因是Cp G的C 是甲基化的,容易自发脱氨基形成胸腺嘧啶T , Cp G 也因此变为突变热点。理论上讲,SNP既可能是二等位多态性,也可能是3个或4个等位多态性,但实际上,后两者非常少见,几乎可以忽略。因此,通常所说的SNP都是二等位多态性的。这种变异可能是转换(C T,在其互补链上则为G A),也可能是颠换(C A,G T,C G,A T)。转换的发生率总是明显高于其它几种变异,具有转换型变异的SNP约占2/3,其它几种变异的发生几率相似。Wang等的研究也证明了这一点。转换的几率高,可能是因为CpG二核苷酸上的胞嘧啶残基是人类基因组中最易发生突变的位点,其中大多数是甲基化的,可自发地脱去氨基而形成胸腺嘧啶。
SNP 在动物基因组中分布广泛,每一个核苷酸发生突变的概率大约为10 - 9 。由于选择压力,SNP在单个基因、整个基因组中以及种群间的分布是不均匀的。SNP 在非编码区中要多于编码区,而且在编码区也是非同义突变(有氨基酸序列的改变) 的频率比其他方式突变的频率低得多[4 ] 。而基因间,同一种基因中的编码SNP (coding SNP ,cSNP) 的数目也不相同,可从0~29 个不等。多项研究同时发现不同种族间SNPs 的数目也是不同的,非洲人群及非裔种族中SNPs 数量最多,而其他种群的SNPs 要少得多,因此通过比较亚群间等位基因的频率将有助于阐明种族的结构和进化。
在基因组DNA中,任何碱基均有可能发生变异,因此SNP既有可能在基因序列内,也有可能在基因以外的非编码序列上。总的来说,位于编码区内的SNP(coding SNP,cSNP)比较少,因为在外显子内,其变异率仅及周围序列的1/5.但它在遗传性疾病研究中却具有重要意义,因此cSNP的研究更受关注。
从对生物的遗传性状的影响上来看,cSNP又可分为2种:一种是同义cSNP(synonymous cSNP),即SNP所致的编码序列的改变并不影响其所翻译的蛋白质的氨基酸序列,突变碱基与未突变碱基的含义相同;另一种是非同义cSNP(non-synonymous cSNP),指碱基序列的改变可使以其为蓝本翻译的蛋白质序列发生改变,从而影响了蛋白质的功能。这种改变常是导致生物性状改变的直接原因。cSNP中约有一半为非同义cSNP。
先形成的SNP在人群中常有更高的频率,后形成的SNP所占的比率较低。各地各民族人群中特定SNP并非一定都存在,其所占比率也不尽相同,但大约有85%应是共通的。
2.SNP自身的特性: 1)SNP数量多,分布广泛。据估计,人类基因组中每1000个核苷酸就有一个SNP,人类30亿碱基中共有300万以上的SNPs.SNP 遍布于整个人类基因组中,根据SNP在基因中的位置,可分为基因编码区SNPs(Coding-region SNPs,cSNPs)、基因周边SNPs(Perigenic SNPs,pSNPs)以及基因间SNPs(Intergenic SNPs,iSNPs)等三类。
2) SNP适于快速、规模化筛查。组成DNA的碱基虽然有4种,但SNP一般只有两种碱基组成,所以它是一种二态的标记,即二等位基因(biallelic)。 由于SNP的二态性,非此即彼,在基因组筛选中SNPs往往只需+/-的分析,而不用分析片段的长度,这就利于发展自动化技术筛选或检测SNPs。
3) SNP等位基因频率的容易估计。采用混和样本估算等位基因的频率是种高效快速的策略。该策略的原理是:首先选择参考样本制作标准曲线,然后将待测的混和样本与标准曲线进行比较,根据所得信号的比例确定混和样本中各种等位基因的频率。
4) 易于基因分型。SNPs 的二态性,也有利于对其进行基因分型。对SNP进行基因分型包括三方面的内容:(1)鉴别基因型所采用的化学反应,常用的技术手段包括:DNA分子杂交、引物延伸、等位基因特异的寡核苷酸连接反应、侧翼探针切割反应以及基于这些方法的变通技术;(2)完成这些化学反应所采用的模式,包括液相反应、固相支持物上进行的反应以及二者皆有的反应。(3)化学反应结束后,需要应用生物技术系统检测反应结果。
绝大多数疾病的发生与环境因素和遗传因素的综合作用有关,通常认为是在个体具有遗传易感性的基础上,环境有害因素作用而导致疾病。不同群体和个体对疾病的易感性、抵抗性以及其他生物学性状(如对药物的反应性等)有差别,其遗传学基础是人类基因组DNA 序列的变异性, 其中最常见的是SNP.易感基因的特点是基因的变异本身并不直接导致疾病的发生,而只造成机体患病的潜在危险性增加,一旦外界有害因素介入, 即可导致疾病发生。另外在药物治疗中,易感基因的变异造成药物对机体的疗效和副作用不同。
随着人类基因组计划的进展,人们愈来愈相信基因组中的SNP 有助于解释个体的表型差异、不同群体和个体对疾病,特别是对复杂疾病的易感性以及对各种药物的耐受性和对环境因子的反应。因此, 寻找和研究SNP 已成为人类基因组计划的内容和目标之一。
多态性与突变的区别 1、多态性是一个群体概念,多态性指这个差异占群体的1%以上。否则就叫突变(小于1%)
2、SNP是多态性中的一种,只是进一步限定了差异只是单碱基。 3、SNP一般来说,是全部体细胞一样的基因型(除开嵌合体)。 4、突变一般不是一个个体全部细胞的变化。 5、如果突变发生在生殖细胞,则可以遗传,但是只要这个突变群没有达到总群体的1%,它就只是一个突变株/系。达到了1%就是多态性了。
常用数据库: Human Gene Mutation Database (HGMD) // http://www.uwcm.ac.uk/uwcm/mg/hgmd0.html // The Genome Database (GD) //http://www.gdb.org //Database of Single Nuleotide Polymorphisms (dbSNP) // http://www.ncbi.nlm.nih.gov/SNP/ //Human Genome Variation Database (HGVbase) //http://hgvbase.cgb.ki.se/ //The Snp Consortium, LTD.(TSC) //http://snp.cshl.org/ //www.hapmap.org
3.SNP现有检测技术 人们对SNP 的研究方法进行了许多探索和改进。SNP 分析技术按其研究对象主要分为两大类,即: ①对未知SNP 进行分析,即找寻未知的SNP 或确定某一未知SNP 与某遗传病的关系。检测未知SNP 有许多种方法可以使用,如温度梯度凝胶电泳( TGGE) 、变性梯度凝胶电泳(DGGE) 、单链构象多态性(SSCP) 、变性的高效液相色谱检测(DHPLC) 、限制性片段长度多态性(RFL P) 、随机扩增多态性DNA(RAPD) 等,但这些方法只能发现含有SNP 的DNA 链,不能确知突变的位置和碱基类别,要想做到这一点,必须对那些含有SNP 的DNA 链进行测序。②对已知SNP 进行分析,即对不同群体SNP遗传多样性检测或在临床上对已知致病基因的遗传病进行基因诊断。筛查已知SNP 的方法有等位基因特异寡核苷酸片段分析(ASO) 、突变错配扩增检验(MAMA) 、基因芯片技术(gene chips) 等。由于人类基因工程的带动,许多物种都已开始了基因组的项目,并建立了大量数据库,比较这些来自不同实验室不同个体的序列, 就可以检测到 SNP。 SNP位点信息已知的情况下, 选择SNP的GENOTYPING的方法,主要根据你的经费情况设计,我分别给你分析一下现状:
A、一般实验室: 经费一般, 仪器不具备时, 最多用的是以下两种方法:
1、 基于PCR的方法,也叫AS-PCR, (ALLELE-SPECIFIC PCR)的办法。 主要原理是利用引物在扩增时3'端相对高的BASE要求,进行设计。这个方法是最便宜的, 不需要酶切, 一次PCR就可以得到GENOTYPING的信息。 缺点: PCR对于3'端的特异性在不同退火温度时有出入, 所以退火温度的摸索很关键,否则假阳性扩增是很容易的。另外, 内参照的设置也很重要,这个东西还是很有意思的。 而且,所使用的引物位置无法人为调整,只能放在SNP的5'段。
2、基于酶切分型。 依靠限制性内切酶的忠贞性进行单SNP的分型。 SNP突变与否, 可能影响某个酶识别位点的存在或消失。 通过酶切产物的电泳条带,判断SNP的突变的情况, 即纯和, 野生纯和,和杂和子。 当没有直接可利用的酶切位点时,可以采用突变引物中个别BASE,从而凑成切点的设计,也叫做RG-PCR, restriction site generation PCR。
B、有经费的实验室的方法: