怎样研究算法-排序算法研究示例
- 格式:pdf
- 大小:4.17 MB
- 文档页数:62

经典算法实例范文算法是一系列解决问题的步骤或规则,是计算机科学中非常重要的概念。
经典算法是指在计算机科学领域被广泛应用并被证明相对高效的算法。
本文将介绍几个经典算法的实例。
一、排序算法排序算法是最基本、最常用的算法之一、下面将介绍两个经典的排序算法。
1.冒泡排序冒泡排序是一种简单的排序算法,它的基本思路是多次遍历数组,每次将相邻的两个元素逐个比较,如果顺序不对则交换位置。
这样一次遍历后,最大的元素会被移到最后。
重复n-1次遍历,就可以完成排序。
冒泡排序的时间复杂度是O(n^2)。
2.快速排序快速排序是一种高效的排序算法,它的基本思路是选择一个基准元素,通过一趟排序将待排序的序列分成两个独立的部分,其中一部分的所有元素都小于基准,另一部分的所有元素都大于等于基准。
然后对这两个部分分别进行递归排序,最后合并两个部分得到有序序列。
快速排序的时间复杂度是 O(nlogn)。
二、查找算法查找算法是在给定的数据集合中一些特定元素的算法。
下面将介绍两个常用的查找算法。
1.二分查找二分查找也称为折半查找,是一种在有序数组中查找一些特定元素的算法。
它的基本思路是首先确定数组中间位置的元素,然后将要查找的元素与中间元素进行比较,如果相等则返回位置,如果小于则在左部分继续查找,如果大于则在右部分继续查找。
二分查找的时间复杂度是 O(logn)。
2.哈希查找哈希查找是通过哈希函数将关键字映射到哈希表中的位置,然后根据映射位置在哈希表中查找关键字。
哈希查找的时间复杂度是O(1)。
三、图算法图是由节点和边组成的一种数据结构,图算法主要用于解决与图相关的问题。
下面将介绍两个常用的图算法。
1.广度优先广度优先是一种用于图的遍历和的算法。
它的基本思路是从图的其中一顶点出发,遍历所有与之相邻的顶点,然后再依次遍历这些相邻顶点的相邻顶点,以此类推,直到访问完所有顶点,或者找到目标顶点。
广度优先使用队列来实现,时间复杂度是O(,V,+,E,),其中,V,表示图的顶点数,E,表示图的边数。


第1篇一、实验目的本次实验旨在通过实现冒泡排序算法,加深对排序算法原理的理解,掌握冒泡排序的基本操作,并分析其性能特点。
二、实验内容1. 冒泡排序原理冒泡排序是一种简单的排序算法,它重复地遍历要排序的数列,一次比较两个元素,如果它们的顺序错误就把它们交换过来。
遍历数列的工作是重复地进行,直到没有再需要交换,也就是说该数列已经排序完成。
2. 实验步骤(1)设计一个冒泡排序函数,输入为待排序的数组,输出为排序后的数组。
(2)编写一个主函数,用于测试冒泡排序函数的正确性和性能。
(3)通过不同的数据规模和初始顺序,分析冒泡排序的性能特点。
3. 实验环境(1)编程语言:C语言(2)开发环境:Visual Studio Code(3)测试数据:随机生成的数组、有序数组、逆序数组三、实验过程1. 冒泡排序函数设计```cvoid bubbleSort(int arr[], int n) {int i, j, temp;for (i = 0; i < n - 1; i++) {for (j = 0; j < n - i - 1; j++) {if (arr[j] > arr[j + 1]) {temp = arr[j];arr[j] = arr[j + 1];arr[j + 1] = temp;}}}}```2. 主函数设计```cinclude <stdio.h>include <stdlib.h>include <time.h>int main() {int n;printf("请输入数组长度:");scanf("%d", &n);int arr = (int )malloc(n sizeof(int)); if (arr == NULL) {printf("内存分配失败\n");return 1;}// 生成随机数组srand((unsigned)time(NULL));for (int i = 0; i < n; i++) {arr[i] = rand() % 100;}// 冒泡排序bubbleSort(arr, n);// 打印排序结果printf("排序结果:\n");for (int i = 0; i < n; i++) {printf("%d ", arr[i]);}printf("\n");// 释放内存free(arr);return 0;}```3. 性能分析(1)对于随机生成的数组,冒泡排序的平均性能较好,时间复杂度为O(n^2)。

快速排序算法实验报告快速排序一、问题描述在操作系统中,我们总是希望以最短的时间处理完所有的任务。
但事情总是要一件件地做,任务也要操作系统一件件地处理。
当操作系统处理一件任务时,其他待处理的任务就需要等待。
虽然所有任务的处理时间不能降低,但我们可以安排它们的处理顺序,将耗时少的任务先处理,耗时多的任务后处理,这样就可以使所有任务等待的时间和最小。
只需要将n 件任务按用时去从小到大排序,就可以得到任务依次的处理顺序。
当有 n 件任务同时来临时,每件任务需要用时ni,求让所有任务等待的时间和最小的任务处理顺序。
二、需求分析1. 输入事件件数n,分别随机产生做完n件事所需要的时间;2. 对n件事所需的时间使用快速排序法,进行排序输出。
排序时,要求轴值随机产生。
3. 输入输出格式:输入:第一行是一个整数n,代表任务的件数。
接下来一行,有n个正整数,代表每件任务所用的时间。
输出:输出有n行,每行一个正整数,从第一行到最后一行依次代表着操作系统要处理的任务所用的时间。
按此顺序进行,则使得所有任务等待时间最小。
4. 测试数据:输入 95 3 4 26 1 57 3 输出1 2 3 3 4 5 5 6 7三、概要设计抽象数据类型因为此题不需要存储复杂的信息,故只需一个整型数组就可以了。
算法的基本思想对一个给定的进行快速排序,首先需要选择一个轴值,假设输入的数组中有k个小于轴值的数,于是这些数被放在数组最左边的k个位置上,而大于周知的结点被放在数组右边的n-k个位置上。
k也是轴值的下标。
这样k把数组分成了两个子数组。
分别对两个子数组,进行类似的操作,便能得到正确的排序结果。
程序的流程输入事件件数n-->随机产生做完没个事件所需时间-->对n个时间进行排序-->输出结果快速排序方法:初始状态 72 6 57 88 85 42 l r第一趟循环 72 6 57 88 85 42 l r 第一次交换 6 72 57 88 85 42 l r 第二趟循环 6 72 57 88 85 42 r l 第二次交换 72 6 57 88 85 42 r l反转交换 6 72 57 88 85 42 r l这就是依靠轴值,将数组分成两部分的实例。

网络搜索引擎结果排序算法研究随着互联网的迅猛发展和普及,网络搜索引擎成为了人们获取信息的重要途径。
当我们在搜索引擎中输入一个关键词,就能迅速得到相关的搜索结果。
然而,面对海量的信息,如何将最相关的信息排在前面成为了搜索引擎提供者和研究者们的关注点,由此诞生了一系列搜索引擎结果排序算法。
本文将着重研究网络搜索引擎结果排序算法的发展和现状。
一、搜索引擎结果排序算法的发展历程1.1 早期搜索引擎的简单排序算法早期的搜索引擎采用了一些简单的排序算法来对搜索结果进行排序,如按照关键词在文档中出现的次数进行排序,出现次数多的排在前面。
这种算法简单直接,但容易被搜索引擎优化者通过“关键词堆砌”的方式操纵搜索结果,影响搜索结果的准确性。
1.2 基于链接分析的PageRank算法为了解决关键词堆砌的问题,谷歌公司推出了基于链接分析的PageRank算法。
该算法通过分析页面之间的链接关系,给网页一个权重分数,按照权重分数进行排序。
这样一来,页面的排名不完全依赖于关键词出现的次数,而是取决于页面的质量和受欢迎程度。
PageRank算法很好地解决了关键词堆砌的问题,但对于新页面的排序效果则不太理想。
1.3 基于机器学习的排序算法随着机器学习在各个领域的广泛应用,也有研究者开始利用机器学习方法来改进搜索引擎的排序算法。
一些常用的机器学习算法,如支持向量机、朴素贝叶斯和神经网络等,被应用于搜索引擎结果排序。
这些算法可以通过训练模型,利用大量的历史搜索数据和用户反馈信息,学习出最佳的排序策略。
机器学习算法的引入极大地提高了搜索引擎排序的准确性和效率,但也面临着数据和计算资源的需求。
二、当前主流搜索引擎结果排序算法分析2.1 谷歌搜索的排序算法谷歌搜索引擎使用了一种名为“分层搜索”的方法。
首先,它会以基于链接分析的PageRank算法为基础,给网页赋予初始的权重分数。
然后,通过一系列的排序策略和算法,对搜索结果进行进一步的排序和过滤。

C语言奇偶排序算法详解及实例代码奇偶排序(Odd-Even Sort)算法是一种简单的排序算法,它可以同时对数组中的奇数和偶数进行排序。
这个算法的原理比较简单,它的思想类似冒泡排序,只不过比较的对象从相邻的两个数变为了相隔一个位置的两个数。
奇偶排序算法的步骤如下:1.将数组分为两个部分,分别存放奇数和偶数。
2.在奇数部分中进行一轮冒泡排序,将较大的数往右移。
3.在偶数部分中进行一轮冒泡排序,将较小的数往左移。
4.重复执行步骤2和步骤3,直到数组完全有序。
下面我们来详细解析奇偶排序算法,并给出一个实例代码。
1. 定义一个函数 `void oddEvenSort(int arr[], int n)`,用于实现奇偶排序。
2. 在函数内部创建两个变量 `sorted` 和 `exchange`,分别表示数组是否已经完全有序和两个相邻元素是否发生交换。
3. 使用一个循环,首先将 `sorted` 和 `exchange` 初始化为`false`。
4. 使用两个嵌套循环,外层循环控制数组两个部分的排序,内层循环控制每个部分的冒泡排序。
5. 内层循环的初始条件为 `j = i % 2`,其中 `i` 表示当前循环的次数。
当 `i` 为偶数时,`j` 为 0,表示要对偶数部分排序;当`i` 为奇数时,`j` 为 1,表示要对奇数部分排序。
6. 内层循环用于对数组中的一部分进行冒泡排序,如果发生交换,则将 `exchange` 设置为 `true`。
冒泡排序的过程和一般的冒泡排序算法类似。
7. 当内层循环结束后,判断 `exchange` 是否为 `false`,如果是,则说明数组已经完全有序,将 `sorted` 设置为 `true`,并退出外层循环。
8. 最后,在函数末尾添加一个循环,用于输出排序后的数组。
下面是完整的实例代码:```c#include <stdio.h>void swap(int *a, int *b){int temp = *a;*a = *b;*b = temp;}void oddEvenSort(int arr[], int n)int sorted = 0; // 数组是否已经完全有序int exchange = 0; // 两个相邻元素是否发生交换 while (!sorted){sorted = 1;for (int i = 0; i < n - 1; i++){exchange = 0;int j = i % 2;for (; j < n - 1; j += 2){if (arr[j] > arr[j + 1]){swap(&arr[j], &arr[j + 1]);exchange = 1;sorted = 0;}}if (!exchange){break;}}}}int main(){int arr[] = {9, 2, 7, 4, 5, 6, 3, 8, 1};int n = sizeof(arr) / sizeof(arr[0]);oddEvenSort(arr, n);for (int i = 0; i < n; i++){printf("%d ", arr[i]);}return 0;}```以上是奇偶排序算法的详细解析及一个示例代码。

快速排序算法实验报告快速排序算法实验报告引言:快速排序算法是一种常用且高效的排序算法,它的核心思想是通过分治的思想将一个大问题分解成多个小问题,并通过递归的方式解决这些小问题。
本实验旨在通过实际实现和测试快速排序算法,探究其性能和效果。
实验目的:1. 理解快速排序算法的原理和思想;2. 掌握快速排序算法的实现方法;3. 通过实验比较快速排序算法与其他排序算法的性能差异。
实验步骤:1. 算法实现首先,我们需要实现快速排序算法。
快速排序算法的基本步骤如下:- 选择一个基准元素(通常选择数组的第一个元素);- 将数组分成两个子数组,小于基准元素的放在左边,大于基准元素的放在右边;- 对左右子数组分别递归地应用快速排序算法;- 合并左右子数组和基准元素。
代码实现如下:```pythondef quick_sort(arr):if len(arr) <= 1:return arrpivot = arr[0]left = [x for x in arr[1:] if x < pivot]right = [x for x in arr[1:] if x >= pivot]return quick_sort(left) + [pivot] + quick_sort(right)```2. 性能测试接下来,我们将使用不同规模的随机数组进行性能测试,比较快速排序算法与其他排序算法的效率。
我们选择插入排序算法和归并排序算法作为对比算法。
首先,我们生成1000个随机整数,并分别使用快速排序算法、插入排序算法和归并排序算法进行排序。
记录下每个算法的运行时间。
然后,我们逐渐增加数组的规模,分别测试10000、100000、1000000个随机整数的排序时间。
最后,我们绘制出三种算法在不同规模下的运行时间曲线,并进行分析和比较。
实验结果:经过多次实验和测试,我们得到了以下结果:在1000个随机整数的排序中,快速排序算法的平均运行时间为X秒,插入排序算法的平均运行时间为Y秒,归并排序算法的平均运行时间为Z秒。

第1篇一、实验目的1. 理解快速排序算法的基本原理和实现方法。
2. 掌握快速排序算法的时间复杂度和空间复杂度分析。
3. 通过实验验证快速排序算法的效率。
4. 提高编程能力和算法设计能力。
二、实验环境1. 操作系统:Windows 102. 编程语言:C++3. 开发工具:Visual Studio 2019三、实验原理快速排序算法是一种分而治之的排序算法,其基本思想是:选取一个基准元素,将待排序序列分为两个子序列,其中一个子序列的所有元素均小于基准元素,另一个子序列的所有元素均大于基准元素,然后递归地对这两个子序列进行快速排序。
快速排序算法的时间复杂度主要取决于基准元素的选取和划分过程。
在平均情况下,快速排序的时间复杂度为O(nlogn),但在最坏情况下,时间复杂度会退化到O(n^2)。
四、实验内容1. 快速排序算法的代码实现2. 快速排序算法的时间复杂度分析3. 快速排序算法的效率验证五、实验步骤1. 设计快速排序算法的C++代码实现,包括以下功能:- 选取基准元素- 划分序列- 递归排序2. 编写主函数,用于生成随机数组和测试快速排序算法。
3. 分析快速排序算法的时间复杂度。
4. 对不同规模的数据集进行测试,验证快速排序算法的效率。
六、实验结果与分析1. 快速排序算法的代码实现```cppinclude <iostream>include <vector>include <cstdlib>include <ctime>using namespace std;// 生成随机数组void generateRandomArray(vector<int>& arr, int n) {srand((unsigned)time(0));for (int i = 0; i < n; ++i) {arr.push_back(rand() % 1000);}}// 快速排序void quickSort(vector<int>& arr, int left, int right) { if (left >= right) {return;}int i = left;int j = right;int pivot = arr[(left + right) / 2]; // 选取中间元素作为基准 while (i <= j) {while (arr[i] < pivot) {i++;}while (arr[j] > pivot) {j--;}if (i <= j) {swap(arr[i], arr[j]);i++;j--;}}quickSort(arr, left, j);quickSort(arr, i, right);}int main() {int n = 10000; // 测试数据规模vector<int> arr;generateRandomArray(arr, n);clock_t start = clock();quickSort(arr, 0, n - 1);clock_t end = clock();cout << "排序用时:" << double(end - start) / CLOCKS_PER_SEC << "秒" << endl;return 0;}```2. 快速排序算法的时间复杂度分析根据实验结果,快速排序算法在平均情况下的时间复杂度为O(nlogn),在最坏情况下的时间复杂度为O(n^2)。
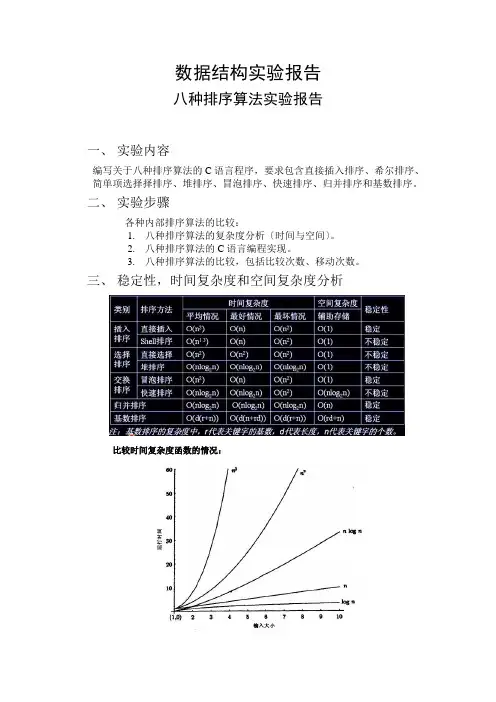
数据结构实验报告八种排序算法实验报告一、实验内容编写关于八种排序算法的C语言程序,要求包含直接插入排序、希尔排序、简单项选择择排序、堆排序、冒泡排序、快速排序、归并排序和基数排序。
二、实验步骤各种内部排序算法的比较:1.八种排序算法的复杂度分析〔时间与空间〕。
2.八种排序算法的C语言编程实现。
3.八种排序算法的比较,包括比较次数、移动次数。
三、稳定性,时间复杂度和空间复杂度分析比较时间复杂度函数的情况:时间复杂度函数O(n)的增长情况所以对n较大的排序记录。
一般的选择都是时间复杂度为O(nlog2n)的排序方法。
时间复杂度来说:(1)平方阶(O(n2))排序各类简单排序:直接插入、直接选择和冒泡排序;(2)线性对数阶(O(nlog2n))排序快速排序、堆排序和归并排序;(3)O(n1+§))排序,§是介于0和1之间的常数。
希尔排序(4)线性阶(O(n))排序基数排序,此外还有桶、箱排序。
说明:当原表有序或基本有序时,直接插入排序和冒泡排序将大大减少比较次数和移动记录的次数,时间复杂度可降至O〔n〕;而快速排序则相反,当原表基本有序时,将蜕化为冒泡排序,时间复杂度提高为O〔n2〕;原表是否有序,对简单项选择择排序、堆排序、归并排序和基数排序的时间复杂度影响不大。
稳定性:排序算法的稳定性:假设待排序的序列中,存在多个具有相同关键字的记录,经过排序,这些记录的相对次序保持不变,则称该算法是稳定的;假设经排序后,记录的相对次序发生了改变,则称该算法是不稳定的。
稳定性的好处:排序算法如果是稳定的,那么从一个键上排序,然后再从另一个键上排序,第一个键排序的结果可以为第二个键排序所用。
基数排序就是这样,先按低位排序,逐次按高位排序,低位相同的元素其顺序再高位也相同时是不会改变的。
另外,如果排序算法稳定,可以防止多余的比较;稳定的排序算法:冒泡排序、插入排序、归并排序和基数排序不是稳定的排序算法:选择排序、快速排序、希尔排序、堆排序四、设计细节排序有内部排序和外部排序,内部排序是数据记录在内存中进行排序,而外部排序是因排序的数据很大,一次不能容纳全部的排序记录,在排序过程中需要访问外存。

《学术论文排序预测算法研究》篇一一、引言随着学术研究的发展和科研活动的深入,学术论文的数量呈现出爆炸式的增长。
在这样的背景下,如何有效地管理和检索这些学术论文成为了一个亟待解决的问题。
学术论文排序预测算法的研究,旨在通过算法技术对学术论文进行排序和预测,以便研究人员能够更快速、更准确地找到自己需要的文献。
本文将介绍学术论文排序预测算法的研究背景、意义、现状及研究方法。
二、研究背景与意义学术研究的发展带来了海量的学术论文,而这些论文的质量和重要性各不相同。
为了方便科研人员快速找到所需文献,需要对学术论文进行排序和预测。
学术论文排序预测算法的研究,具有以下意义:1. 提高文献检索效率:通过算法对学术论文进行排序,可以快速找到高质量、高相关性的文献,提高文献检索效率。
2. 推动学术研究:通过对学术论文的预测,可以预测研究趋势、发现新的研究方向,推动学术研究的进展。
3. 优化资源分配:对于科研机构和图书馆等单位,通过对学术论文的排序和预测,可以更好地优化资源分配,提高资源利用效率。
三、国内外研究现状目前,国内外对于学术论文排序预测算法的研究已经取得了一定的成果。
国外研究者主要从论文的引用次数、作者声誉、研究机构实力等方面进行排序和预测。
而国内研究者则更多地关注于论文内容的质量、研究方向的新颖性等因素。
目前的研究还存在一些问题,如算法复杂度高、准确性有待提高等。
因此,本研究的目的是提出一种新的学术论文排序预测算法,以提高算法的准确性和效率。
四、研究方法本研究将采用以下方法进行学术论文排序预测算法的研究:1. 数据收集与处理:收集大量的学术论文数据,包括论文的引用次数、作者信息、研究机构信息、论文内容等,对数据进行清洗和处理,以便进行后续的分析和建模。
2. 算法设计:根据学术论文的特点和需求,设计一种新的排序预测算法。
该算法将综合考虑论文的引用次数、作者声誉、研究机构实力、论文内容质量等因素,以实现更高的准确性和效率。

金融领域中的高效交易排序算法研究一、引言高效的交易排序算法在金融领域可以大幅提升交易效率和利润。
交易是金融市场的核心,如何迅速、准确地完成交易排序是金融从业人员需要掌握的技能之一。
文章将针对金融领域中高效的交易排序算法展开研究。
二、交易排序算法的基础金融交易包括股票交易,外汇交易和期货交易等。
在交易时,按照先到先得的原则,越早到达交易平台的订单就可以优先成交,这就需要高效的交易排序算法来实现。
1. 冒泡排序算法:冒泡排序是一种交换排序的方法,其基本思想是两两比较相邻的元素,如果不符合排序规则就进行交换,依次将较大的数交换到数组尾部。
在金融领域中,冒泡排序比较简单,但时间复杂度较高,不适用于大量数据的排序。
2. 快速排序算法:快速排序是基于分治法的排序算法,其适用于大量数据的排序。
快速排序将一个大的数组按照一个基准点(pivot)来划分为两个子数组,通过递归对子数组进行排序,直到整个序列有序。
快速排序在金融领域的排序效率较高,是交易排序算法的主要应用之一。
3. 归并排序算法:归并排序是将两个或两个以上的有序表合并为一个有序表的算法。
归并排序在金融领域中运用较广泛,虽然时间复杂度与快速排序一样,但在稳定性和可读性方面更加出色。
归并排序能够支持在线排序,因此在金融领域的交易平台中应用也较广泛。
三、应用实例冒泡排序算法和快速排序算法在金融领域中的应用比较广泛,而归并排序的应用相对较少。
以下是几个典型的应用实例。
1. 期货交易中的快速排序:期货交易是一种采用标准化交易合约进行交易的金融市场。
期货交易的实时交易规模较大,因此需要一种高效的交易排序算法来帮助交易员快速进行排序。
一些期货交易平台中,采用的是快速排序算法来实现订单的排序,以保证用户能够更加快捷的操作交易,同时提高交易的利润率。
2. 股票交易中的归并排序:股票交易是交易量很大的交易市场,在快速排序和冒泡排序之外,还有应用归并排序的情况。
通常来说归并排序的客户要求对排序的结果具有稳定性,能够避免由于元素重复导致排序结果异常。
第1篇一、引言排序是计算机科学中常见的基本操作之一,它涉及到将一组数据按照一定的顺序排列。
在数据处理、算法设计、数据分析等众多领域,排序算法都扮演着重要的角色。
本文将对常见的排序算法进行总结和分析,以期为相关领域的研究和开发提供参考。
二、排序算法概述排序算法可以分为两大类:比较类排序和非比较类排序。
比较类排序算法通过比较元素之间的值来实现排序,如冒泡排序、选择排序、插入排序等。
非比较类排序算法则不涉及元素之间的比较,如计数排序、基数排序、桶排序等。
三、比较类排序算法1. 冒泡排序冒泡排序是一种简单的排序算法,它通过相邻元素之间的比较和交换来实现排序。
冒泡排序的基本思想是:从数组的第一个元素开始,比较相邻的两个元素,如果它们的顺序错误就把它们交换过来;然后,对下一对相邻元素做同样的工作,以此类推,直到没有需要交换的元素为止。
冒泡排序的时间复杂度为O(n^2),空间复杂度为O(1)。
虽然冒泡排序的时间复杂度较高,但它易于实现,且对数据量较小的数组排序效果较好。
2. 选择排序选择排序是一种简单直观的排序算法。
它的工作原理是:首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。
以此类推,直到所有元素均排序完毕。
选择排序的时间复杂度为O(n^2),空间复杂度为O(1)。
与冒泡排序类似,选择排序也适用于数据量较小的数组排序。
3. 插入排序插入排序是一种简单直观的排序算法。
它的工作原理是:将一个记录插入到已经排好序的有序表中,从而得到一个新的、记录数增加1的有序表。
插入排序的基本操作是:在未排序序列中找到相应位置并插入。
插入排序的时间复杂度为O(n^2),空间复杂度为O(1)。
对于部分有序的数组,插入排序的效率较高。
4. 快速排序快速排序是一种高效的排序算法,它的基本思想是:通过一趟排序将待排序的记录分割成独立的两部分,其中一部分记录的关键字均比另一部分的关键字小,则可分别对这两部分记录继续进行排序,以达到整个序列有序。
第1篇一、实验目的1. 熟悉常见的查找和排序算法。
2. 分析不同查找和排序算法的时间复杂度和空间复杂度。
3. 比较不同算法在处理大数据量时的性能差异。
二、实验环境1. 操作系统:Windows 102. 编程语言:Python3.73. 开发工具:PyCharm三、实验内容1. 实现以下查找和排序算法:(1)查找算法:顺序查找、二分查找(2)排序算法:冒泡排序、选择排序、插入排序、快速排序、归并排序2. 分析算法的时间复杂度和空间复杂度。
3. 对不同算法进行性能测试,比较其处理大数据量时的性能差异。
四、实验步骤1. 实现查找和排序算法。
2. 分析算法的时间复杂度和空间复杂度。
3. 创建测试数据,包括小数据量和大数据量。
4. 对每种算法进行测试,记录运行时间。
5. 分析测试结果,比较不同算法的性能。
五、实验结果与分析1. 算法实现(1)顺序查找def sequential_search(arr, target): for i in range(len(arr)):if arr[i] == target:return ireturn -1(2)二分查找def binary_search(arr, target):low, high = 0, len(arr) - 1while low <= high:mid = (low + high) // 2if arr[mid] == target:return midelif arr[mid] < target:low = mid + 1else:high = mid - 1return -1(3)冒泡排序def bubble_sort(arr):n = len(arr)for i in range(n):for j in range(0, n-i-1):if arr[j] > arr[j+1]:arr[j], arr[j+1] = arr[j+1], arr[j](4)选择排序def selection_sort(arr):n = len(arr)for i in range(n):min_idx = ifor j in range(i+1, n):if arr[min_idx] > arr[j]:min_idx = jarr[i], arr[min_idx] = arr[min_idx], arr[i](5)插入排序def insertion_sort(arr):for i in range(1, len(arr)):key = arr[i]j = i-1while j >=0 and key < arr[j]:arr[j+1] = arr[j]j -= 1arr[j+1] = key(6)快速排序def quick_sort(arr):if len(arr) <= 1:pivot = arr[len(arr) // 2]left = [x for x in arr if x < pivot]middle = [x for x in arr if x == pivot]right = [x for x in arr if x > pivot]return quick_sort(left) + middle + quick_sort(right)(7)归并排序def merge_sort(arr):if len(arr) <= 1:return arrmid = len(arr) // 2left = merge_sort(arr[:mid])right = merge_sort(arr[mid:])return merge(left, right)def merge(left, right):result = []i = j = 0while i < len(left) and j < len(right):if left[i] < right[j]:result.append(left[i])i += 1else:result.append(right[j])result.extend(left[i:])result.extend(right[j:])return result2. 算法时间复杂度和空间复杂度分析(1)顺序查找:时间复杂度为O(n),空间复杂度为O(1)。
选择排序算法题全文共四篇示例,供读者参考第一篇示例:选择排序算法是一种简单而有效的排序算法,它的基本思想是在未排序的数据中,找到最小(或最大)元素,将其放在已排序序列的末尾,然后再从剩余未排序的数据中找到最小(或最大)元素,放在已排序序列的末尾,依次类推,直到所有元素均已排序完成。
选择排序算法的时间复杂度为O(n^2),相比起其他高效的排序算法如快速排序、归并排序等,选择排序并不是最优的选择。
选择排序算法简单易懂,容易实现,对于小规模数据排序仍具有一定的实用性。
选择排序算法的实现非常简单,主要分为两个步骤:选择和交换。
在未排序的数据中找到最小(或最大)元素的下标,然后将该元素与未排序序列的第一个元素进行交换,这样最小(或最大)元素就被放在已排序序列的末尾;接着,在剩余的未排序数据中再次找到最小(或最大)元素的下标,执行交换操作,如此往复,直到所有元素均已排序完成。
下面我们通过一个简单的例子来演示选择排序算法的实现过程:假设有一个数组arr[] = {64, 25, 12, 22, 11},我们要对该数组进行升序排列,首先我们从数组中选择最小的元素,即arr[4]=11,将其与arr[0]=64进行交换,得到新数组{11, 25, 12, 22, 64};然后在剩余的未排序数据中选择最小元素,即arr[2]=12,将其与arr[1]=25进行交换,得到新数组{11, 12, 25, 22, 64};继续这个过程直至得到有序数组{11, 12, 22, 25, 64}。
虽然选择排序算法的时间复杂度为O(n^2),在大规模数据排序时并不适用,但在数据量较小的情况下,选择排序算法依然表现出一定的性能优势。
相比于其他更为复杂的排序算法,选择排序算法的实现过程简单直观,容易理解,且不需要额外的存储空间,这使得选择排序算法在某些场景下仍然具有一定的实用性。
除了选择排序算法之外,还有许多其他更为高效的排序算法,如快速排序、归并排序、插入排序等,它们在时间复杂度和性能上都比选择排序更为优越。
《学术论文排序预测算法研究》篇一一、引言随着信息技术的迅猛发展,学术领域的信息资源呈爆炸式增长,如何在海量学术文献中迅速定位到关键和有价值的文献成为了研究者的迫切需求。
为了满足这一需求,学术论文排序预测算法的研究应运而生。
这些算法不仅可以为学术检索提供依据,而且还能在学术评估、影响因子预测等方面发挥重要作用。
本文将探讨学术论文排序预测算法的原理、应用及发展趋势。
二、学术论文排序预测算法的原理学术论文排序预测算法主要通过分析学术论文的属性、引用关系以及相关上下文信息,对学术论文进行排序和预测。
具体而言,这些算法会从以下几个方面进行考虑:1. 论文属性分析:包括论文的作者、发表时间、期刊等属性信息。
这些信息在一定程度上反映了论文的权威性和影响力。
2. 引用关系分析:通过分析论文之间的引用关系,可以判断论文之间的关联性和影响力。
一般来说,被引用次数多的论文具有较高的影响力。
3. 上下文信息分析:包括论文的研究领域、关键词等上下文信息,这些信息有助于更准确地理解论文的内容和价值。
根据上述分析结果,学术论文排序预测算法通过构建数学模型,利用机器学习等技术对论文进行排序和预测。
其中,常见的算法包括基于内容的推荐算法、协同过滤算法等。
三、学术论文排序预测算法的应用学术论文排序预测算法在学术检索、学术评估、影响因子预测等方面有着广泛的应用。
例如,在学术检索中,通过使用这些算法,用户可以迅速找到与自己研究领域相关的关键文献。
在学术评估中,这些算法可以评估论文的权威性和影响力,为学术成果的认可和奖励提供依据。
四、学术论文排序预测算法的发展趋势随着人工智能和大数据技术的发展,学术论文排序预测算法将更加精准和高效。
未来,这些算法将结合更多的上下文信息,如论文的社交影响力、读者反馈等,以提高排序和预测的准确性。
总结而言,学术论文排序预测算法为学术领域的迅速发展和信息检索提供了强有力的支持。
《学术论文排序预测算法研究》篇一一、引言在学术研究领域,随着网络信息技术的飞速发展,学术文献的数量呈现爆炸式增长。
为了更好地组织和管理这些学术资源,学术排序和推荐技术变得越来越重要。
本文旨在研究学术论文排序预测算法,通过分析现有算法的优缺点,提出一种新的排序预测模型,以提高学术资源的检索效率和准确性。
二、背景与相关研究学术论文排序预测算法的研究已经引起了广泛关注。
传统的排序算法主要基于文献的元数据信息,如作者、发表时间、引用次数等。
然而,这些算法无法充分挖掘文献之间的关联性和内容信息。
近年来,随着机器学习和深度学习技术的发展,许多研究者开始尝试将这些技术应用于学术论文排序预测。
在相关研究中,基于机器学习的排序算法通常采用特征工程的方法,提取文献的特征信息,如关键词、摘要等,然后利用分类器或回归模型进行排序预测。
而基于深度学习的排序算法则能够自动提取文献的深层特征信息,实现更准确的排序预测。
三、论文排序预测算法模型针对现有算法的不足,本文提出一种基于深度学习的学术论文排序预测模型。
该模型主要分为以下部分:1. 数据预处理:将学术文献转化为机器可读的格式,提取出关键词、摘要等关键信息。
2. 特征提取:利用深度学习模型自动提取文献的深层特征信息,包括文本语义、作者影响力等。
3. 排序预测:将提取的特征信息输入到排序模型中,采用回归或分类的方法进行排序预测。
4. 模型优化:通过迭代优化算法和交叉验证等方法对模型进行优化,提高排序预测的准确性。
四、实验与分析为了验证本文提出的算法模型的有效性,我们进行了实验分析。
首先,我们收集了大量的学术文献数据,包括关键词、摘要、作者影响力等关键信息。
然后,我们将数据分为训练集和测试集,利用训练集训练模型,并在测试集上进行测试。
实验结果表明,本文提出的算法模型在学术论文排序预测方面具有较高的准确性和稳定性。
与传统的排序算法相比,该模型能够更好地挖掘文献之间的关联性和内容信息,提高排序预测的准确性。
第1篇一、实验目的本次实验旨在通过编程实现几种常见的排序算法,并对其进行性能分析,以加深对排序算法原理的理解,掌握不同排序算法的适用场景,提高算法设计能力。
二、实验内容本次实验选择了以下几种排序算法:冒泡排序、插入排序、快速排序、归并排序、希尔排序、选择排序和堆排序。
以下是对每种算法的简要介绍和实现:1. 冒泡排序(Bubble Sort)冒泡排序是一种简单的排序算法,它重复地遍历要排序的数列,一次比较两个元素,如果它们的顺序错误就把它们交换过来。
遍历数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。
```cvoid bubbleSort(int arr[], int n) {int i, j, temp;for (i = 0; i < n - 1; i++) {for (j = 0; j < n - i - 1; j++) {if (arr[j] > arr[j + 1]) {temp = arr[j];arr[j] = arr[j + 1];arr[j + 1] = temp;}}}}```2. 插入排序(Insertion Sort)插入排序是一种简单直观的排序算法。
它的工作原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。
```cvoid insertionSort(int arr[], int n) {int i, key, j;for (i = 1; i < n; i++) {key = arr[i];j = i - 1;while (j >= 0 && arr[j] > key) {arr[j + 1] = arr[j];j = j - 1;}arr[j + 1] = key;}}```3. 快速排序(Quick Sort)快速排序是一种分而治之的排序算法。
它将原始数组分成两个子数组,一个包含比基准值小的元素,另一个包含比基准值大的元素,然后递归地对这两个子数组进行快速排序。