第八课 SPSS logistic回归分析
- 格式:ppt
- 大小:1.34 MB
- 文档页数:84


多因素logistic回归分析spssLogistic回归分析是一种用来研究影响离散变量的因素的方法,该方法的输出是一个logistic模型,这一模型可以用于预测变量的值,即预测该变量的值有多高的概率会取各种可能的取值。
简言之,logistic回归分析的主要目的是把客观的结果(例如,是否改变某个政策,是否感染某种疾病等)变成可预测的离散变量,以便分析影响客观结果的各种因素。
Spss可以提供多因素logistic回归分析,这种分析可用于识别影响离散变量(例如,是否改变某个政策,是否感染某种疾病等)的多个因素之间的关联。
该分析需要有一个组合变量作为自变量,以及一个离散变量作为因变量。
例如,如果您要研究性别和年龄两个因素如何影响某种疾病的发生率,那么性别和年龄两个因素就是组合变量,而疾病的发生率则是因变量。
1.建立变量和分类(上述示例中需要建立性别和年龄两个变量,以及分类变量的可能的取值)。
2.执行logistic回归分析。
打开spss,并在“分析”菜单中打开多元分析,然后点击“逻辑回归”,并选择您要研究的变量和分类。
3.生成回归模型和检验其统计学意义。
在spss中,您可以使用类似“回归系数”之类的描述性统计学方法来估算回归模型,并可以使用“p-值”来判断回归模型中各变量的统计学意义。
4.Interpret模型。
根据p值判断各变量的统计学意义,进而分析影响离散变量的多个因素之间的关联。
四、总结Logistic回归分析是一种用来研究影响离散变量的因素的方法,spss可以提供多因素logistic回归分析,这种分析可用于识别影响离散变量的多个因素之间的关联,spss中步骤:建立变量和分类,执行logistic回归分析,生成回归模型和检验其统计学意义,Interpret模型。
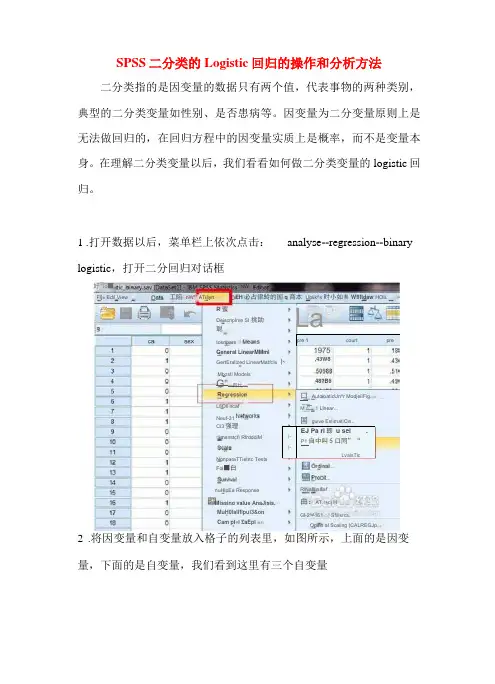
SPSS 二分类的Logistic 回归的操作和分析方法二分类指的是因变量的数据只有两个值,代表事物的两种类别, 典型的二分类变量如性别、是否患病等。
因变量为二分变量原则上是 无法做回归的,在回归方程中的因变量实质上是概率,而不是变量本 身。
在理解二分类变量以后,我们看看如何做二分类变量的logistic 回归。
1 .打开数据以后,菜单栏上依次点击: analyse --regression --binary logistic ,打开二分回归对话框2 .将因变量和自变量放入格子的列表里,如图所示,上面的是因变 量,下面的是自变量,我们看到这里有三个自变量pre 1courtpre卜 卜EJ Pa ri 即 u sei.P1自中叫5口同”“LvaisTic好 Io ■网 □N W□imsnstcri RfrdddiMNonparaTTietrtc Tests Foi ■白MuH0lalfflpul3&on Deiscriplrve SI 挑助聪LfiOli ncaf - Neuf-31 nuHlpEa ResponseMissing value AnaJisis. EH 必占律蛉的国q 商本 Ublik^s 时小如M Wflftdaw HOI LFl[« Edi! View工陷 nW"" ATiilyrtCam pl«i £aEpl 骷与Opsin al Scaling (CALREGJp..R 蜜GertEralized LinearMatfcIs 卜 Mbosti ModelsRlNafllin&af .曲:AT.r+ci HC] 2^^161;! Sfiiisrcs.tosnpareGeneral LinearMMml 48?B6Ci3强理 G"一四忙—一 3 La,43W8口 AutoioaticUn^r ModjeliFig..M 二1 Linear...国 guive EslirnatiCin...C>ep«n (lferit3 .设置回归方法,这里选择最简单的方法:enter ,它指的是将所有的 变量一次纳入到方程。
SPSS中logistics回归分析哑变量设置及结果解读
SPSS中logistics回分析哑变量设置及结果解读
⼀、SPSS 两分类logistics回归分析:分析—回归—⼆元logistic
⼆、在进⾏回归分析时,如果要分析的变量为分类变量(尤其是⽆序多分类变量)
时,通常会将原始的多分类变量转化为哑变量,通过构建回归模型,每⼀个哑变量都能得出⼀个估计的回归系数,从⽽使得回归的结果更易于解释,更具有实际意义。
在SPSS中的实现过程如下:
默认的参考值为最后⼀个,即:赋值最⼤的数;如果想要更改将第⼀个作为参照则需要点击:“第⼀个(F)” –“变化量(H)”,
如下图:出现“x7(指⽰符(first))”时,则说明x7变量是以第⼀个(最⼩的)作为参照。
三、结果:
在输出结果中有“分类变量编码”,即展⽰了分类变量设置为哑变量的编码;
最后结果中,需对照“分类变量编码”进⾏结果解释,在“⽅程中变量” 的“铂种类(1)”则代表的是“顺铂”相对于“其他”的OR值是0.483;“铂种类(2)”则代表的是“奥沙利铂”相对于“其他”的OR值是0.852;…… “肝功能(1)”则代表肝功能异常相对于正常
的OR是3.634。

Logistic回归主要分为三类,一种是因变量为二分类得logistic回归,这种回归叫做二项logistic回归,一种是因变量为无序多分类得logistic回归,比如倾向于选择哪种产品,这种回归叫做多项logistic回归。
还有一种是因变量为有序多分类的logistic回归,比如病重的程度是高,中,低呀等等,这种回归也叫累积logistic回归,或者序次logistic回归。
二值logistic回归:选择分析——回归——二元logistic,打开主面板,因变量勾选你的二分类变量,这个没有什么疑问,然后看下边写着一个协变量。
有没有很奇怪什么叫做协变量?在二元logistic回归里边可以认为协变量类似于自变量,或者就是自变量。
把你的自变量选到协变量的框框里边。
细心的朋友会发现,在指向协变量的那个箭头下边,还有一个小小的按钮,标着a*b,这个按钮的作用是用来选择交互项的。
我们知道,有时候两个变量合在一起会产生新的效应,比如年龄和结婚次数综合在一起,会对健康程度有一个新的影响,这时候,我们就认为两者有交互效应。
那么我们为了模型的准确,就把这个交互效应也选到模型里去。
我们在右边的那个框框里选择变量a,按住ctrl,在选择变量b,那么我们就同时选住这两个变量了,然后点那个a*b的按钮,这样,一个新的名字很长的变量就出现在协变量的框框里了,就是我们的交互作用的变量。
然后在下边有一个方法的下拉菜单。
默认的是进入,就是强迫所有选择的变量都进入到模型里边。
除去进入法以外,还有三种向前法,三种向后法。
一般默认进入就可以了,如果做出来的模型有变量的p值不合格,就用其他方法在做。
再下边的选择变量则是用来选择你的个案的。
一般也不用管它。
选好主面板以后,单击分类(右上角),打开分类对话框。
在这个对话框里边,左边的协变量的框框里边有你选好的自变量,右边写着分类协变量的框框则是空白的。
你要把协变量里边的字符型变量和分类变量选到分类协变量里边去(系统会自动生成哑变量来方便分析,什么事哑变量具体参照前文)。


如何用spss17.0进行二元和多元logistic回归分析一、二元logistic回归分析二元logistic回归分析的前提为因变量是可以转化为0、1的二分变量,如:死亡或者生存,男性或者女性,有或无,Yes或No,是或否的情况。
下面以医学中不同类型脑梗塞与年龄和性别之间的相互关系来进行二元logistic回归分析。
(一)数据准备和SPSS选项设置第一步,原始数据的转化:如图1-1所示,其中脑梗塞可以分为ICAS、ECAS和NCAS三种,但现在我们仅考虑性别和年龄与ICAS的关系,因此将分组数据ICAS、ECAS和NCAS转化为1、0分类,是ICAS赋值为1,否赋值为0。
年龄为数值变量,可直接输入到spss中,而性别需要转化为(1、0)分类变量输入到spss当中,假设男性为1,女性为0,但在后续分析中系统会将1,0置换(下面还会介绍),因此为方便期间我们这里先将男女赋值置换,即男性为“0”,女性为“1”。
图1-1第二步:打开“二值Logistic 回归分析”对话框:沿着主菜单的“分析(Analyze)→回归(Regression)→二元logistic (Binary Logistic)”的路径(图1-2)打开二值Logistic 回归分析选项框(图1-3)。
如图1-3左侧对话框中有许多变量,但在单因素方差分析中与ICAS 显著相关的为性别、年龄、有无高血压,有无糖尿病等(P<0.05),因此我们这里选择以性别和年龄为例进行分析。
在图1-3中,因为我们要分析性别和年龄与ICAS的相关程度,因此将ICAS选入因变量(Dependent)中,而将性别和年龄选入协变量(Covariates)框中,在协变量下方的“方法(Method)”一栏中,共有七个选项。
采用第一种方法,即系统默认的强迫回归方法(进入“Enter”)。
接下来我们将对分类(Categorical),保存(Save),选项(Options)按照如图1-4、1-5、1-6中所示进行设置。

SPSS作业8:二项Logistic回归分析为研究和预测某商品消费特点和趋势,收集到以往胡消费数据。
数据项包括是否购买,性别,年龄和收入水平。
这里采用Logistic回归的方法,是否购买作为被解释变量(0/1二值变量),其余各变量为解释变量,且其中性别和收入水平为品质变量,年龄为定距变量。
变量选择采用Enter方法,性别以男为参照类,收入以低收入为参照类。
(一)基本操作:(1)选择菜单Analyze-Regression-Binary Logistic;(2)选择是否购买作为被解释变量到Dependent框中,选其余各变量为解释变量到Covariates框中,采用Enter方法,结果如下:消费的二项Logistic分析结果(一)(强制进入策略). 专业专注.分析:上表显示了对品质变量产生虚拟变量的情况,产生的虚拟变量命名为原变量名(编码)。
可以看到,对收入生成了两个虚拟变量名为Income (1)和Income(2),分别表示是否中收入和是否高收入,两变量均为0时表示低收入;对性别生成了一个虚拟变量名为Gedder(1),表示是否女,取值为0时表示为男。
. 专业专注.消费的二项Logistic分析结果(二)(强制进入策略)Block 0: Beginning Block分析:上表显示了Logistic分析初始阶段(第零步)方程中只有常数项时的错判矩阵。
可以看到:269人中实际没购买且模型预测正确,正确率为. 专业专注.100%;162人中实际购买了但模型均预测错误,正确率为0%。
模型总的预测正确率为62.4%。
消费的二项Logistic分析结果(三)(强制进入策略)分析:上表显示了方程中只有常数项时的回归系数方面的指标,各数据项的含义依次为回归系数,回归系数标准误差,Wald检验统计量的观测值,自由度,Wald检验统计量的概率p值,发生比。
由于此时模型中未包含任何解释变量,因此该表没有实际意义。

如何⽤SPSS做logistic回归分析解读如何⽤spss17.0进⾏⼆元和多元logistic回归分析⼀、⼆元logistic回归分析⼆元logistic回归分析的前提为因变量是可以转化为0、1的⼆分变量,如:死亡或者⽣存,男性或者⼥性,有或⽆,Yes或No,是或否的情况。
下⾯以医学中不同类型脑梗塞与年龄和性别之间的相互关系来进⾏⼆元logistic回归分析。
(⼀)数据准备和SPSS选项设置第⼀步,原始数据的转化:如图1-1所⽰,其中脑梗塞可以分为ICAS、ECAS和NCAS三种,但现在我们仅考虑性别和年龄与ICAS的关系,因此将分组数据ICAS、ECAS和NCAS转化为1、0分类,是ICAS 赋值为1,否赋值为0。
年龄为数值变量,可直接输⼊到spss中,⽽性别需要转化为(1、0)分类变量输⼊到spss当中,假设男性为1,⼥性为0,但在后续分析中系统会将1,0置换(下⾯还会介绍),因此为⽅便期间我们这⾥先将男⼥赋值置换,即男性为“0”,⼥性为“1”。
图1-1第⼆步:打开“⼆值Logistic回归分析”对话框:沿着主菜单的“分析(Analyze)→回归(Regression)→⼆元logistic(Binary Logistic)”的路径(图1-2)打开⼆值Logistic 回归分析选项框(图1-3)。
如图1-3左侧对话框中有许多变量,但在单因素⽅差分析中与ICAS 显著相关的为性别、年龄、有⽆⾼⾎压,有⽆糖尿病等(P<0.05),因此我们这⾥选择以性别和年龄为例进⾏分析。
在图1-3中,因为我们要分析性别和年龄与ICAS的相关程度,因此将ICAS选⼊因变量(Dependent)中,⽽将性别和年龄选⼊协变量(Covariates)框中,在协变量下⽅的“⽅法(Method)”⼀栏中,共有七个选项。
采⽤第⼀种⽅法,即系统默认的强迫回归⽅法(进⼊“Enter”)。
接下来我们将对分类(Categorical),保存(Save),选项(Options)按照如图1-4、1-5、1-6中所⽰进⾏设置。

SPSS配对调查资料的条件 Logistic 回归分析(1:1或1:n)1. 1:1 病例对照研究的基本概念在管理工作中,我们也经常要开展对照调查。
例如为什么有的人患了胃癌,有的人却不会患胃癌?如果在同一居住地选取同性别、年龄相差仅±2 岁的健康人作对照调查,调查他们与患胃癌有关的各种影响因素,这就是医学上很常用的所谓“1:1 病例对照研究”。
病例对照研究资料常用条件Logistic 回归分析。
条件Logistic 回归模型(conditional logistic regression model,CLRM),下称CLRM 模型。
2. 条件Logistic 回归模型的一个实例某地在肿瘤防治健康教育、社区干预工作中做了一项调查,内容是三种生活因素与胃癌发病的关系。
调查的三种生活因素取值见表 11-6。
请拟合条件Logistic 回归模型,说明胃癌发病的主要危险因素。
表 11-6 三种生活因素与胃癌发病关系的取值------------------------------------------------------------------------------------------ 变量名取值范围------------------------------------------------------------------------------------------ X1 (不良生活习惯) 0,1,2,3,4 表示程度(0 表示无,4 表示很多)X2 (喜吃卤食和盐腌食物) 0,1,2,3,4 表示程度(0 表示不吃,4 表示喜欢吃、吃很多) X3 (精神状况) 0 表示差,1 表示好------------------------------------------------------------------------------------------表 11-7 50 对胃癌病例(S=1)与对照(S=0)三种生活习惯调查结果------------------------------------------------------------------------------------------ 病例对照病例对照-----------------------------------------------------------------------------No S X1 X2 X3 No S X1 X2 X3 No S X1 X2 X3 No S X1 X2 X3------------------------------------------------------------------------------------------1 12 4 0 1 03 1 0 26 1 2 2 0 26 0 1 1 02 13 2 1 2 0 0 1 0 27 1 2 0 1 27 0 0 2 13 1 3 0 0 3 0 2 0 1 28 1 1 1 1 28 0 3 0 14 1 3 0 0 4 0 2 0 1 29 1 2 0 1 29 0 4 0 05 1 3 0 1 5 0 0 0 0 30 1 3 1 0 30 0 0 2 16 1 2 2 0 6 0 0 1 0 31 1 1 0 1 31 0 0 0 07 1 3 1 0 7 0 2 1 0 32 1 4 2 1 32 0 1 0 18 1 3 0 0 8 0 2 0 0 33 1 4 0 1 33 0 2 0 19 1 2 2 0 9 0 1 0 1 34 1 2 0 1 34 0 0 0 110 1 1 0 0 10 0 2 0 0 35 1 1 2 0 35 0 2 0 111 1 3 0 0 11 0 0 1 1 36 1 2 0 0 36 0 2 0 112 1 3 4 0 12 0 3 2 0 37 1 0 1 1 37 0 1 1 013 1 1 1 1 13 0 2 0 0 38 1 0 0 1 38 0 4 0 014 1 2 2 1 14 0 0 2 1 39 1 3 0 1 39 0 0 1 015 1 2 3 0 15 0 2 0 0 40 1 2 0 1 40 0 3 0 116 1 2 4 1 16 0 0 0 1 41 1 2 0 0 41 0 1 0 117 1 1 1 0 17 0 0 1 1 42 1 3 0 1 42 0 0 0 118 1 1 3 1 18 0 0 0 1 43 1 2 1 1 43 0 0 0 019 1 3 4 1 19 0 2 0 0 44 1 2 0 1 44 0 1 0 020 1 0 2 0 20 0 0 0 0 45 1 1 1 1 45 0 0 0 121 1 3 2 1 21 0 3 1 0 46 1 0 1 1 46 0 0 0 022 1 1 0 0 22 0 2 0 1 47 1 2 1 0 47 0 0 0 023 1 3 0 0 23 0 2 2 0 48 1 2 0 1 48 0 1 1 024 1 1 1 1 24 0 0 1 1 49 1 1 2 1 49 0 0 0 125 1 1 2 0 25 0 2 0 0 50 1 2 0 1 50 0 0 3 1------------------------------------------------------------------------------------------- 3. 条件Logistic 回归模型的拟合原理与方法本例以 SPSS 软件包来拟合 CLRM 模型。
第8 章利用SPSS 进行Logistic 回归分析现实中的很多现象可以划分为两种可能,或者归结为两种状态,这两种状态分别用0和1 表示。
如果我们采用多个因素对0-1 表示的某种现象进行因果关系解释,就可能应用到logistic 回归。
Logistic 回归分为二值logistic 回归和多值logistic 回归两类。
首先用实例讲述二值logistic 回归,然后进一步说明多值logistic 回归。
在阅读这部分内容之前,最好先看看有关SPSS 软件操作技术的教科书。
§8.1 二值logistic 回归8.1.1 数据准备和选项设置我们研究2005 年影响中国各地区城市化水平的经济地理因素。
城市化水平用城镇人口比重表征,影响因素包括人均GDP、第二产业产值比重、第三产业产值比重以及地理位置。
地理位置为名义变量,中国各地区被分别划分到三大地带:东部地带、中部地带和西部地带。
我们用各地区的地带分类代表地理位置。
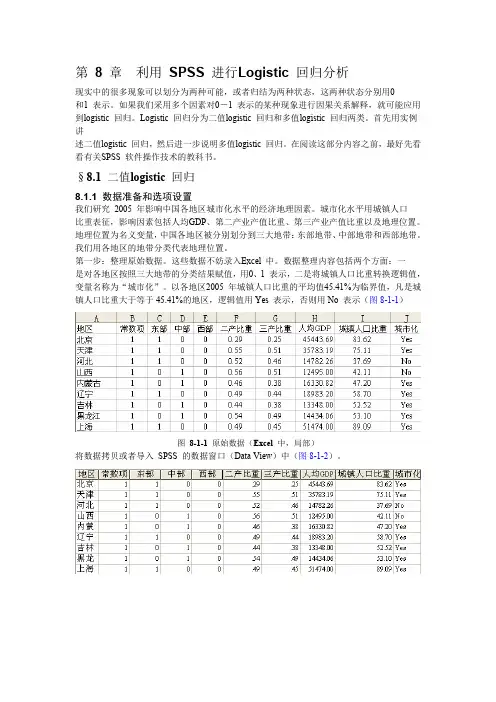
第一步:整理原始数据。
这些数据不妨录入Excel 中。
数据整理内容包括两个方面:一是对各地区按照三大地带的分类结果赋值,用0、1 表示,二是将城镇人口比重转换逻辑值,变量名称为“城市化”。
以各地区2005 年城镇人口比重的平均值45.41%为临界值,凡是城镇人口比重大于等于45.41%的地区,逻辑值用Yes 表示,否则用No 表示(图8-1-1)图8-1-1 原始数据(Excel 中,局部)将数据拷贝或者导入SPSS 的数据窗口(Data View)中(图8-1-2)。
图8-1-2 中国31 个地区的数据(SPSS 中,局部)第二步:打开“聚类分析”对话框。
沿着主菜单的“Analyze→Regression→Binary Logistic K”的路径(图8-1-3)打开二值Logistic 回归分析选项框(图8-1-4)。
图8-1-3 打开二值Logistic 回归分析对话框的路径对数据进行多次拟合试验,结果表明,像二产比重、三产比重等对城市化水平影响不显著。
如何用spss实现配比的条件logistics回归分析孙大鹏sundapeng87@仅以此篇献给那些专注于使用spss而不会使用sas、R、epiinfo 等统计软件的同志,spss是大家用的非常广泛的统计工具,它的数据管理非常直观,但是有一点就是它的回归分析中没有条件logistics回归分析模块。
而这个分析模块在后三个软件中可以轻松实现。
下面就给大家介绍一下如何使用spss进行条件logistics回归分析。
原理就是利用生存分析中的cox回归模型。
一、变量准备。
(一)首先我们准备好的数据应该有个因变量y,为0,1格式的,0代表对照或未发病,1代表病例或已发病。
(二)我们要分析的自变量x1,x2,一般为二分类变量,1或0,是否。
当然也可以是多组的分类变量,这个比较麻烦(一般不推荐,后面结果分析会说一下)。
(三)分组变量标注分组的代码group。
假设1:4配比,这5个个案为一组,共用一个group号。
(四)Cox回归模型,需要一个time的生存时间变量,这个变量我们这样设置,首先有个因变量y,为0,1格式的,计算time=2-y。
这样子就是设置成病例生存时间为1,对照生存时间为2。
病例发病对照不发病,对照的生存时间必然要长于病例。
数据见附件1二、操作步骤(一)数据导入spss。
不会的回家自己学去。
(二)分析----生存函数----Cox回归打开对话框(三)选取变量,第一时间选入time变量;第二个状态选入y 即病例和对照,定义事件为为1;协变量选择X,你要分析的因素方法选择向前条件分层选择group;重要选项中可以设置计算可信区间(四)结果判读Sig 为P值;B为系数;Exp(B)为OR值,后面为OR值可信区间三、关于x为分类变量,并且为多组时的问题(一)需要对协变量设置分类,选择第一个后,记得要点击更改。
如果选入变量,分类按钮为灰色,这是请点击分层的变量,移出再移入,分类按钮就变换过来了。
(二)这个样子就可以计算分析了,但是结果的显示数据正确,但是结果表格OR值和X分类变量的对应关系混乱。
如何用spss17.0进行二元和多元logis tic回归分析一、二元logis tic回归分析二元logis tic回归分析的前提为因变量是可以转化为0、1的二分变量,如:死亡或者生存,男性或者女性,有或无,Yes或No,是或否的情况。
下面以医学中不同类型脑梗塞与年龄和性别之间的相互关系来进行二元logist ic回归分析。
(一)数据准备和SP SS选项设置第一步,原始数据的转化:如图1-1所示,其中脑梗塞可以分为ICAS、ECAS和NC AS三种,但现在我们仅考虑性别和年龄与ICAS的关系,因此将分组数据ICAS、ECAS和NC AS转化为1、0分类,是ICAS赋值为1,否赋值为0。
年龄为数值变量,可直接输入到s pss中,而性别需要转化为(1、0)分类变量输入到spss当中,假设男性为1,女性为0,但在后续分析中系统会将1,0置换(下面还会介绍),因此为方便期间我们这里先将男女赋值置换,即男性为“0”,女性为“1”。
图1-1第二步:打开“二值Logis tic 回归分析”对话框:沿着主菜单的“分析(Analyze)→回归(Regress ion)→二元logis tic (BinaryLogisti c)”的路径(图1-2)打开二值Log istic回归分析选项框(图1-3)。
如图1-3左侧对话框中有许多变量,但在单因素方差分析中与IC AS 显著相关的为性别、年龄、有无高血压,有无糖尿病等(P<0.05),因此我们这里选择以性别和年龄为例进行分析。
在图1-3中,因为我们要分析性别和年龄与ICAS的相关程度,因此将ICAS选入因变量(Depende nt)中,而将性别和年龄选入协变量(Covaria tes)框中,在协变量下方的“方法(Method)”一栏中,共有七个选项。
利用SPSS进行Logistic回归分析第8章利用SPSS进行Logistic回归分析现实中的很多现象可以划分为两种可能,或者归结为两种状态,这两种状态分别用0和1表示。
如果我们采用多个因素对0-1表示的某种现象进行因果关系解释,就可能应用到logistic回归。
Logistic回归分为二值logistic回归和多值logistic回归两类。
首先用实例讲述二值logistic回归,然后进一步说明多值logistic回归。
在阅读这部分内容之前,最好先看看有关SPSS软件操作技术的教科书。
§8.1 二值logistic回归8.1.1 数据准备和选项设置我们研究2005年影响中国各地区城市化水平的经济地理因素。
城市化水平用城镇人口比重表征,影响因素包括人均GDP、第二产业产值比重、第三产业产值比重以及地理位置。
地理位置为名义变量,中国各地区被分别划分到三大地带:东部地带、中部地带和西部地带。
我们用各地区的地带分类代表地理位置。
第一步:整理原始数据。
这些数据不妨录入Excel中。
数据整理内容包括两个方面:一是对各地区按照三大地带的分类结果赋值,用0、1表示,二是将城镇人口比重转换逻辑值,变量名称为“城市化”。
以各地区2005年城镇人口比重的平均值45.41%为临界值,凡是城镇人口比重大于等于45.41%的地区,逻辑值用Yes表示,否则用No表示(图8-1-1)。
图8-1-1 原始数据(Excel中,局部)将数据拷贝或者导入SPSS的数据窗口(Data View)中(图8-1-2)。
图8-1-2 中国31个地区的数据(SPSS中,局部)第二步:打开“聚类分析”对话框。
沿着主菜单的“Analyze→Regression→Binary LogisticK”的路径(图8-1-3)打开二值Logistic回归分析选项框(图8-1-4)。
图8-1-3 打开二值Logistic回归分析对话框的路径对数据进行多次拟合试验,结果表明,像二产比重、三产比重等对城市化水平影响不显著。