语音识别 中英文献翻译
- 格式:doc
- 大小:148.00 KB
- 文档页数:14

美国科罗拉多州大学关于在噪声环境下对大量连续语音识别系统的改进---------噪声环境下说话声音的识别工作简介在本文中,我们报道美国科罗拉多州大学关于噪声环境下海军研究语音词汇系统方面的最新改进成果。
特别地,我们介绍在有限语音数据的前提下,为了了解不确定观察者和变化的环境的任务(或调查方法),我们必须在提高听觉和语言模式方面努力下工夫。
在大量连续词汇语音识别系统中,我们将展开MAPLR自适应方法研究。
它包括单个或多重最大可能线形回归。
当前噪声环境下语音识别系统使用了大量声音词汇识别的声音识别引擎。
这种引擎在美国科罗拉多州大学目前得到了飞速的发展,本系统在噪声环境下说话声音系统(SPINE-2)评价数据中单词错识率表现为30.5%,比起2001年的SPINE-2来,在相关词汇错识率减少16%。
1.介绍为获得噪声环境下的有活力的连续声音系统的声音,我们试图在艺术的领域做出计算和提出改善,这个工作有几方面的难点:依赖训练的有限数据工作;在训练和测试中各种各样的军事噪声存在;在每次识别适用性阶段中,不可想象的听觉溪流和有限数量的声音。
在2000年11月的SPIN-1和2001年11月SPIN-2中,海军研究词汇通过DARPT在工作上给了很大的帮助。
在2001年参加评估的种类有:SPIIBM,华盛顿大学,美国科罗拉多州大学,AT&T,奥瑞哥研究所,和梅隆卡内基大学。
它们中的许多先前已经报道了SPINE-1和SPLNE-2工作的结果。
在这方面的工作中不乏表现最好的系统.我们在特性和主模式中使用了自适应系统,同时也使用了被用于训练各种参数类型的多重声音平行理论(例如MFCC、PCP等)。
其中每种识别系统的输出通常通过一个假定的熔合的方法来结合。
这种方法能提供一个单独的结果,这个结果的错误率将比任何一个单独的识别系统的结果要低。
美国科罗拉多州大学参加了SPIN-2和SPIN-1的两次评估工作。
我们2001年11月的SPIN-2是美国科罗拉多州大学识别系统基础上第一次被命名为SONIC(大量连续语音识别系统)的。

语音识别技术综述The summarization of speech recognition张永双苏州大学苏州江苏摘要本文回顾了语音识别技术的发展历史,综述了语音识别系统的结构、分类及基本方法,分析了语音识别技术面临的问题及发展方向。
关键词:语音识别;特征;匹配AbstactThis article review the courses of speech recognition technology progress ,summarize the structure,classifications and basic methods of speech recognition system and analyze the direction and the issues which speech recognition technology development may confront with. Key words: speech recognition;character;matching引言语音识别技术就是让机器通过识别和理解过程把语音信号转变为相应的文本或命令的高技术。
语音识别是一门交叉学科,所涉及的领域有信号处理、模式识别、概率论和信息论、发声机理和听觉机理、人工智能等等,甚至还涉及到人的体态语言(如人民在说话时的表情手势等行为动作可帮助对方理解)。
其应用领域也非常广,例如相对于键盘输入方法的语音输入系统、可用于工业控制的语音控制系统及服务领域的智能对话查询系统,在信息高度化的今天,语音识别技术及其应用已成为信息社会不可或缺的重要组成部分。
1.语音识别技术的发展历史语音识别技术的研究开始二十世纪50年代。
1952年,AT&Tbell实验室的Davis等人成功研制出了世界上第一个能识别十个英文数字发音的实验系统:Audry系统。
60年代计算机的应用推动了语音识别技术的发展,提出两大重要研究成果:动态规划(Dynamic Planning,DP)和线性预测分析(Linear Predict,LP),其中后者较好的解决了语音信号产生模型的问题,对语音识别技术的发展产生了深远影响。

语音识别在计算机技术中,语音识别是指为了达到说话者发音而由计算机生成的功能,利用计算机识别人类语音的技术。
(例如,抄录讲话的文本,数据项;经营电子和机械设备;电话的自动化处理),是通过所谓的自然语言处理的计算机语音技术的一个重要元素。
通过计算机语音处理技术,来自语音发音系统的由人类创造的声音,包括肺,声带和舌头,通过接触,语音模式的变化在婴儿期、儿童学习认识有不同的模式,尽管由不同人的发音,例如,在音调,语气,强调,语调模式不同的发音相同的词或短语,大脑的认知能力,可以使人类实现这一非凡的能力。
在撰写本文时(2008年),我们可以重现,语音识别技术不只表现在有限程度的电脑能力上,在其他许多方面也是有用的。
语音识别技术的挑战古老的书写系统,要回溯到苏美尔人的六千年前。
他们可以将模拟录音通过留声机进行语音播放,直到1877年。
然而,由于与语音识别各种各样的问题,语音识别不得不等待着计算机的发展。
首先,演讲不是简单的口语文本——同样的道理,戴维斯很难捕捉到一个note-for-note曲作为乐谱。
人类所理解的词、短语或句子离散与清晰的边界实际上是将信号连续的流,而不是听起来: I went to the store yesterday昨天我去商店。
单词也可以混合,用Whadd ayawa吗?这代表着你想要做什么。
第二,没有一对一的声音和字母之间的相关性。
在英语,有略多于5个元音字母——a,e,i,o,u,有时y和w。
有超过二十多个不同的元音, 虽然,精确统计可以取决于演讲者的口音而定。
但相反的问题也会发生,在那里一个以上的信号能再现某一特定的声音。
字母C可以有相同的字母K的声音,如蛋糕,或作为字母S,如柑橘。
此外,说同一语言的人使用不相同的声音,即语言不同,他们的声音语音或模式的组织,有不同的口音。
例如“水”这个词,wadder可以显著watter,woader wattah等等。
每个人都有独特的音量——男人说话的时候,一般开的最低音,妇女和儿童具有更高的音高(虽然每个人都有广泛的变异和重叠)。
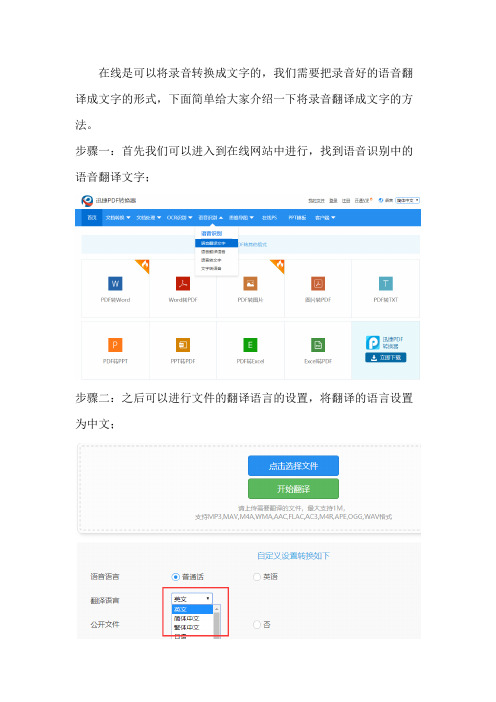
在线是可以将录音转换成文字的,我们需要把录音好的语音翻译成文字的形式,下面简单给大家介绍一下将录音翻译成文字的方法。
步骤一:首先我们可以进入到在线网站中进行,找到语音识别中的语音翻译文字;
步骤二:之后可以进行文件的翻译语言的设置,将翻译的语言设置为中文;
步骤三:设置好之后就可以进行添加文件了,点击选择文件进行添加
或是直接拖拽文件进行添加;
步骤四:语言文件添加文件完成之后就可以进行文件的翻译了,点击开始翻译即可;
步骤五:翻译的过程是需要一定的时间的,我们需要耐心的等待一段时间;
步骤六:等文件翻译完成之后就可以进行下载了,点击立即下载会弹出一个在下线的界面,我们可以将其下载到桌面上。
好了,语音翻译文字的方法就介绍到这了,希望可以帮助到大家。

语音和语音是可以进行翻译的,在有需要的时候我们需要将语音翻译成不同格式,那么我们是怎么进行在线翻译,下面就简单的介绍一下。
步骤一:语言在线翻译成语音的方法有很多种,我们可以进行文件的在线翻译,直接进入到在线网站中点击语音识别中的语音翻译语音;
步骤二:进入之后就可以进行文件的自定义,将文件的语言进行自定义好;
步骤三:之后就可以进行语音文件的选择,将语音文件选择到界面中;
步骤四:选择好文件之后就可以进行文件的翻译,点击开始翻译;
步骤五:翻译是需要一个等待的过程,我们需要耐心的等待一段时间;
步骤六:最后等语音文件翻译完成之后就可以进行在线下载。
好了,以上就是小编介绍的语音翻译语音了,希望可以帮助到大家。

录音转语音助手搭载了国际领先的语音识别、口语翻译引擎功能,以大量日常聊天对话语料为翻译基础,并通过APP与网络进行绑定,对时下热词新词进行及时更新,具有超强的易用性、稳定性、安全性等特点。
操作选用工具:在应用市场下载【录音转文字助手】
操作步骤:
第一步:首先我们在百度手机助手或者应用市场里面搜索:【录音转文字助手】找到以后进行下载并安装。
第二步:接着打开软件就可以看到【录音识别】、【文件识别】、【语音翻译】、【录音机】的四个功能,这里我们就举例说明下【语音翻译】。
第三步:点击橙色的【中文】按钮,开始说中文以后,下面就是翻译的英文。
第四步:点击蓝色的【English】按钮,开始说英文,就可以把你说的英语转成中文了。
以上就是语音翻译的操作步骤了,希望今天的教程能够帮助到有需要的小伙伴。
英语翻译分类(一)英语翻译分类1. 口译口译是指将一种语言的口头表达转化为另一种语言的口头表达的翻译形式。
口译可以分为同声传译和交替传译两种形式。
•同声传译:指在演讲会议等场合,即时将讲话者所说的内容翻译成另一种语言,并通过耳机传递给听众。
同声传译要求译员具备快速反应和较高的专业素养。
•交替传译:指讲话者说一段话后停顿,然后由译员将其翻译成另一种语言。
交替传译常用于小型会议、商务谈判等场合。
2. 笔译笔译是指将一种语言的书面表达转化为另一种语言的书面表达的翻译形式。
笔译涉及的领域广泛,常见的包括文学、学术、法律、商务等。
•文学翻译:将文学作品从原文翻译成另一种语言,保持原作的风格、特点和意境。
文学翻译要求译者不仅对语言文化有深入理解,还需要有较高的文学才能。
•学术翻译:将学术论文、研究报告等从一种语言翻译成另一种语言,保持原文的准确性和专业性。
学术翻译要求译者对相关学科领域有深入了解,并具备翻译学术文献的能力。
•法律翻译:将法律文件、法规条款等从一种语言翻译成另一种语言,保持法律意义的准确性和法律语言的规范性。
法律翻译要求译者熟悉法律专业术语和法律体系,具备良好的法律素养。
•商务翻译:将商务文件、商务谈判等从一种语言翻译成另一种语言,保持商务用语的准确性和商务文化的妥当性。
商务翻译要求译者具备商业常识和跨文化沟通技巧。
3. 机器翻译机器翻译是指使用计算机等自动化设备进行翻译的技术和方法。
机器翻译通过分析源语言和目标语言之间的句法结构和语义关系,自动将源语言的内容转化为目标语言。
机器翻译具有高效性和大规模处理能力,但仍面临语义理解和文化差异等挑战。
•统计机器翻译:基于大规模并行语料库的统计模型,通过计算句子的概率分布进行翻译。
统计机器翻译依赖大量的双语平行语料,准确性受限于语料库的质量和覆盖范围。
•神经机器翻译:基于神经网络模型的机器翻译,通过训练深度神经网络来建模源语言和目标语言之间的映射关系。
中英文资料外文翻译译文:改进型智能机器人的语音识别方法2、语音识别概述最近,由于其重大的理论意义和实用价值,语音识别已经受到越来越多的关注。
到现在为止,多数的语音识别是基于传统的线性系统理论,例如隐马尔可夫模型和动态时间规整技术。
随着语音识别的深度研究,研究者发现,语音信号是一个复杂的非线性过程,如果语音识别研究想要获得突破,那么就必须引进非线性系统理论方法。
最近,随着非线性系统理论的发展,如人工神经网络,混沌与分形,可能应用这些理论到语音识别中。
因此,本文的研究是在神经网络和混沌与分形理论的基础上介绍了语音识别的过程。
语音识别可以划分为独立发声式和非独立发声式两种。
非独立发声式是指发音模式是由单个人来进行训练,其对训练人命令的识别速度很快,但它对与其他人的指令识别速度很慢,或者不能识别。
独立发声式是指其发音模式是由不同年龄,不同性别,不同地域的人来进行训练,它能识别一个群体的指令。
一般地,由于用户不需要操作训练,独立发声式系统得到了更广泛的应用。
所以,在独立发声式系统中,从语音信号中提取语音特征是语音识别系统的一个基本问题。
语音识别包括训练和识别,我们可以把它看做一种模式化的识别任务。
通常地,语音信号可以看作为一段通过隐马尔可夫模型来表征的时间序列。
通过这些特征提取,语音信号被转化为特征向量并把它作为一种意见,在训练程序中,这些意见将反馈到HMM的模型参数估计中。
这些参数包括意见和他们响应状态所对应的概率密度函数,状态间的转移概率,等等。
经过参数估计以后,这个已训练模式就可以应用到识别任务当中。
输入信号将会被确认为造成词,其精确度是可以评估的。
整个过程如图一所示。
图1 语音识别系统的模块图3、理论与方法从语音信号中进行独立扬声器的特征提取是语音识别系统中的一个基本问题。
解决这个问题的最流行方法是应用线性预测倒谱系数和Mel频率倒谱系数。
这两种方法都是基于一种假设的线形程序,该假设认为说话者所拥有的语音特性是由于声道共振造成的。
中英文语音翻译Voice Translation between Chinese and English中英文语音翻译With the advancements in technology, voice translation has become increasingly popular and convenient. It allows individuals to communicate in different languages without the need for an interpreter or language proficiency. Voice translation can be especially helpful in situations where immediate translation is required, such as during business meetings or while traveling in a foreign country. In this article, we will discuss voice translation between Chinese and English, two widely spoken languages.随着技术的进步,语音翻译变得越来越受欢迎和方便。
它允许人们在不需要口译员或语言能力的情况下用不同的语言交流。
语音翻译在需要即时翻译的情况下非常有帮助,比如在商务会议上或在外国旅行时。
在本文中,我们将讨论中英文之间的语音翻译,这是两种广泛使用的语言。
Voice translation can be done through various methods, such as mobile applications or built-in features in smartphones. These applications use speech recognition technology to convert spoken words into text, and then translate the text into the desired language. They can also generate a voice output in the translated language, allowing for a seamless conversation between individuals speaking different languages.语音翻译可以通过多种方法实现,比如手机应用程序或智能手机的内置功能。
基于语音识别的智能翻译系统设计与实现智能翻译系统(Intelligent Translation System)是一种利用计算机技术实现语言之间翻译的系统。
目前,随着人工智能技术的快速发展,基于语音识别的智能翻译系统越来越受到人们的关注和重视。
本文将介绍基于语音识别的智能翻译系统的设计与实现。
一、引言在全球化背景下,人们的跨国交流日益频繁,语言沟通成为人们面临的一个重要问题。
传统的翻译方式存在诸多局限,因此研发一种快速、准确的智能翻译系统成为迫切需求。
基于语音识别的智能翻译系统利用语音识别技术实时转化语音为文本,并通过机器翻译技术将文本翻译成目标语言,从而实现语音和文字之间的无缝对接。
二、系统设计1. 语音输入用户通过话筒向系统输入待翻译的语音,系统利用语音识别技术将语音转化为文本。
常用的语音识别技术包括隐马尔可夫模型(Hidden Markov Model)和深度学习技术(如循环神经网络)。
2. 文本处理系统通过对用户输入的文本进行处理,包括分词、词性标注等步骤。
中文与英文等语言存在词序和语法结构的差异,因此对不同语种的文本进行适当的处理能够提高翻译的准确性。
3. 机器翻译系统利用机器翻译技术将源语言文本翻译成目标语言文本。
机器翻译技术主要有统计机器翻译和神经网络机器翻译两种。
统计机器翻译通过构建翻译模型和语言模型来进行翻译,而神经网络机器翻译则借助深度学习技术来实现。
4. 结果生成系统将翻译得到的目标语言文本通过语音合成技术转化为语音输出,让用户可以听到翻译结果。
语音合成技术主要有联合模型和参数生成两种方法。
三、系统实现为了实现基于语音识别的智能翻译系统,需要整合多种技术和算法。
以下是一个简单的系统实现步骤:1. 语音输入利用麦克风采集用户的语音输入,在输入过程中实时将语音转化为文本。
这一步可以借助开源的语音识别引擎(如CMU Sphinx)来实现。
2. 文本处理对用户输入的文本进行分词与词性标注,并根据需要进行句法分析。
Speech RecognitionVictor Zue, Ron Cole, & Wayne WardMIT Laboratory for Computer Science, Cambridge, Massachusetts, USAOregon Graduate Institute of Science & Technology, Portland, Oregon, USA Carnegie Mellon University, Pittsburgh, Pennsylvania, USA1 Defining the ProblemSpeech recognition is the process of converting an acoustic signal, captured by a microphone or a telephone, to a set of words. The recognized words can be the final results, as for applications such as commands & control, data entry, and document preparation. They can also serve as the input to further linguistic processing in order to achieve speech understanding, a subject covered in section.Speech recognition systems can be characterized by many parameters, some of the more important of which are shown in Figure. An isolated-word speech recognition system requires that the speaker pause briefly between words, whereas a continuous speech recognition system does not. Spontaneous, or extemporaneously generated, speech contains disfluencies, and is much more difficult to recognize than speech read from script. Some systems require speaker enrollment---a user must provide samples of his or her speech before using them, whereas other systems are said to be speaker-independent, in that no enrollment is necessary. Some of the other parameters depend on the specific task. Recognition is generally more difficult when vocabularies are large or have many similar-sounding words. When speech is produced in a sequence of words, language models or artificial grammars are used to restrict the combination of words.The simplest language model can be specified as a finite-state network, where the permissible words following each word are given explicitly. More general language models approximating natural language are specified in terms of a context-sensitive grammar.1One popular measure of the difficulty of the task, combining the vocabulary size and the language model, is perplexity, loosely defined as the geometric mean of the number of words that can follow a word after the language model has been applied (see section for a discussion of language modeling in general and perplexity in particular). Finally, there are some external parameters that can affect speech recognition system performance, including the characteristics of the environmental noise and the type and the placement of the microphone.Table: Typical parameters used to characterize the capability of speech recognition systems Speech recognition is a difficult problem, largely because of the many sources of variability associated with the signal. First, the acoustic realizations of phonemes, the smallest sound units of which words are composed, are highly dependent on the context in which they appear. These phonetic variabilities are exemplified by the acoustic differences of the phoneme,At word boundaries, contextual variations can be quite dramatic---making gas shortage sound like gash shortage in American English, and devo andare sound like devandare in Italian.Second, acoustic variabilities can result from changes in the environment as well as in the position and characteristics of the transducer. Third, within-speaker variabilities can result from changes in the speaker's physical and emotional state, speaking rate, or voice quality. Finally, differences in sociolinguistic background, dialect, and vocal tract size and shape can contribute to across-speaker variabilities.Figure shows the major components of a typical speech recognition system. The digitized speech signal is first transformed into a set of useful measurements or features at a fixed rate,typically once every 10--20 msec (see sectionsand 11.3 for signal representation and digital signal processing, respectively). These measurements are then used to search for the most likely word candidate, making use of constraints imposed by the acoustic, lexical, and language models. Throughout this process, training data are used to determine the values of the model parameters.Figure: Components of a typical speech recognition system.Speech recognition systems attempt to model the sources of variability described above in several ways. At the level of signal representation, researchers have developed representations that emphasize perceptually important speaker-independent features of the signal, and de-emphasize speaker-dependent characteristics. At the acoustic phonetic level, speaker variability is typically modeled using statistical techniques applied to large amounts of data. Speaker adaptation algorithms have also been developed that adapt speaker-independent acoustic models to those of the current speaker during system use, (see section). Effects of linguistic context at the acoustic phonetic level are typically handled by training separate models for phonemes in different contexts; this is called context dependent acoustic modeling.Word level variability can be handled by allowing alternate pronunciations of words in representations known as pronunciation networks. Common alternate pronunciations of words, as well as effects of dialect and accent are handled by allowing search algorithms to find alternate paths of phonemes through these networks. Statistical language models, based on estimates of the frequency of occurrence of word sequences, are often used to guide the search through the most probable sequence of words.The dominant recognition paradigm in the past fifteen years is known as hidden Markovmodels (HMM). An HMM is a doubly stochastic model, in which the generation of the underlying phoneme string and the frame-by-frame, surface acoustic realizations are both represented probabilistically as Markov processes, as discussed in sections,and 11.2. Neural networks have also been used to estimate the frame based scores; these scores are then integrated into HMM-based system architectures, in what has come to be known as hybrid systems, as described in section 11.5.An interesting feature of frame-based HMM systems is that speech segments are identified during the search process, rather than explicitly. An alternate approach is to first identify speech segments, then classify the segments and use the segment scores to recognize words. This approach has produced competitive recognition performance in several tasks.2 State of the ArtComments about the state-of-the-art need to be made in the context of specific applications which reflect the constraints on the task. Moreover, different technologies are sometimes appropriate for different tasks. For example, when the vocabulary is small, the entire word can be modeled as a single unit. Such an approach is not practical for large vocabularies, where word models must be built up from subword units.Performance of speech recognition systems is typically described in terms of word error rate E, defined as:where N is the total number of words in the test set, and S, I, and D are the total number of substitutions, insertions, and deletions, respectively.The past decade has witnessed significant progress in speech recognition technology. Word error rates continue to drop by a factor of 2 every two years. Substantial progress has been made in the basic technology, leading to the lowering of barriers to speaker independence, continuous speech, and large vocabularies. There are several factors that have contributed to this rapid progress. First, there is the coming of age of the HMM. HMM is powerful in that, with the availability of training data, the parameters of the model can be trained automatically to give optimal performance.Second, much effort has gone into the development of large speech corpora for systemdevelopment, training, and testing. Some of these corpora are designed for acoustic phonetic research, while others are highly task specific. Nowadays, it is not uncommon to have tens of thousands of sentences available for system training and testing. These corpora permit researchers to quantify the acoustic cues important for phonetic contrasts and to determine parameters of the recognizers in a statistically meaningful way. While many of these corpora (e.g., TIMIT, RM, ATIS, and WSJ; see section 12.3) were originally collected under the sponsorship of the U.S. Defense Advanced Research Projects Agency (ARPA) to spur human language technology development among its contractors, they have nevertheless gained world-wide acceptance (e.g., in Canada, France, Germany, Japan, and the U.K.) as standards on which to evaluate speech recognition.Third, progress has been brought about by the establishment of standards for performance evaluation. Only a decade ago, researchers trained and tested their systems using locally collected data, and had not been very careful in delineating training and testing sets. As a result, it was very difficult to compare performance across systems, and a system's performance typically degraded when it was presented with previously unseen data. The recent availability of a large body of data in the public domain, coupled with the specification of evaluation standards, has resulted in uniform documentation of test results, thus contributing to greater reliability in monitoring progress (corpus development activities and evaluation methodologies are summarized in chapters 12 and 13 respectively).Finally, advances in computer technology have also indirectly influenced our progress. The availability of fast computers with inexpensive mass storage capabilities has enabled researchers to run many large scale experiments in a short amount of time. This means that the elapsed time between an idea and its implementation and evaluation is greatly reduced. In fact, speech recognition systems with reasonable performance can now run in real time using high-end workstations without additional hardware---a feat unimaginable only a few years ago.One of the most popular, and potentially most useful tasks with low perplexity (PP=11) is the recognition of digits. For American English, speaker-independent recognition of digit strings spoken continuously and restricted to telephone bandwidth can achieve an error rate of 0.3% when the string length is known.One of the best known moderate-perplexity tasks is the 1,000-word so-called Resource Management (RM) task, in which inquiries can be made concerning various naval vessels in thePacific ocean. The best speaker-independent performance on the RM task is less than 4%, using a word-pair language model that constrains the possible words following a given word (PP=60). More recently, researchers have begun to address the issue of recognizing spontaneously generated speech. For example, in the Air Travel Information Service (ATIS) domain, word error rates of less than 3% has been reported for a vocabulary of nearly 2,000 words and a bigram language model with a perplexity of around 15.High perplexity tasks with a vocabulary of thousands of words are intended primarily for the dictation application. After working on isolated-word, speaker-dependent systems for many years, the community has since 1992 moved towards very-large-vocabulary (20,000 words and more), high-perplexity (PP≈200), speaker-independent, continuous speech recognition. The best system in 1994 achieved an error rate of 7.2% on read sentences drawn from North America business news.With the steady improvements in speech recognition performance, systems are now being deployed within telephone and cellular networks in many countries. Within the next few years, speech recognition will be pervasive in telephone networks around the world. There are tremendous forces driving the development of the technology; in many countries, touch tone penetration is low, and voice is the only option for controlling automated services. In voice dialing, for example, users can dial 10--20 telephone numbers by voice (e.g., call home) after having enrolled their voices by saying the words associated with telephone numbers. AT&T, on the other hand, has installed a call routing system using speaker-independent word-spotting technology that can detect a few key phrases (e.g., person to person, calling card) in sentences such as: I want to charge it to my calling card.At present, several very large vocabulary dictation systems are available for document generation. These systems generally require speakers to pause between words. Their performance can be further enhanced if one can apply constraints of the specific domain such as dictating medical reports.Even though much progress is being made, machines are a long way from recognizing conversational speech. Word recognition rates on telephone conversations in the Switchboard corpus are around 50%. It will be many years before unlimited vocabulary, speaker-independent continuous dictation capability is realized.3 Future DirectionsIn 1992, the U.S. National Science Foundation sponsored a workshop to identify the key research challenges in the area of human language technology, and the infrastructure needed to support the work. The key research challenges are summarized in. Research in the following areas for speech recognition were identified:Robustness:In a robust system, performance degrades gracefully (rather than catastrophically) as conditions become more different from those under which it was trained. Differences in channel characteristics and acoustic environment should receive particular attention.Portability:Portability refers to the goal of rapidly designing, developing and deploying systems for new applications. At present, systems tend to suffer significant degradation when moved to a new task. In order to return to peak performance, they must be trained on examples specific to the new task, which is time consuming and expensive.Adaptation:How can systems continuously adapt to changing conditions (new speakers, microphone, task, etc) and improve through use? Such adaptation can occur at many levels in systems, subword models, word pronunciations, language models, etc.Language Modeling:Current systems use statistical language models to help reduce the search space and resolve acoustic ambiguity. As vocabulary size grows and other constraints are relaxed to create more habitable systems, it will be increasingly important to get as much constraint as possible from language models; perhaps incorporating syntactic and semantic constraints that cannot be captured by purely statistical models.Confidence Measures:Most speech recognition systems assign scores to hypotheses for the purpose of rank ordering them. These scores do not provide a good indication of whether a hypothesis is correct or not, just that it is better than the other hypotheses. As we move to tasks that require actions, we need better methods to evaluate the absolute correctness of hypotheses.Out-of-Vocabulary Words:Systems are designed for use with a particular set of words, but system users may not know exactly which words are in the system vocabulary. This leads to a certain percentage of out-of-vocabulary words in natural conditions. Systems must have some method of detecting such out-of-vocabulary words, or they will end up mapping a word from the vocabulary onto the unknown word, causing an error.Spontaneous Speech:Systems that are deployed for real use must deal with a variety of spontaneous speech phenomena, such as filled pauses, false starts, hesitations, ungrammatical constructions and other common behaviors not found in read speech. Development on the ATIS task has resulted in progress in this area, but much work remains to be done.Prosody:Prosody refers to acoustic structure that extends over several segments or words. Stress, intonation, and rhythm convey important information for word recognition and the user's intentions (e.g., sarcasm, anger). Current systems do not capture prosodic structure. How to integrate prosodic information into the recognition architecture is a critical question that has not yet been answered.Modeling Dynamics:Systems assume a sequence of input frames which are treated as if they were independent. But it is known that perceptual cues for words and phonemes require the integration of features that reflect the movements of the articulators, which are dynamic in nature. How to model dynamics and incorporate this information into recognition systems is an unsolved problem.语音识别舒维都,罗恩科尔,韦恩沃德麻省理工学院计算机科学实验室,剑桥,马萨诸塞州,美国俄勒冈科学与技术学院,波特兰,俄勒冈州,美国卡耐基梅隆大学,匹兹堡,宾夕法尼亚州,美国一定义问题语音识别是指音频信号的转换过程,被电话或麦克风的所捕获的一系列的消息。