Excel数据管理与图表分析 双因素方差分析
- 格式:doc
- 大小:164.48 KB
- 文档页数:4

统计学中的几个基本概念1、同质(homogeneity)与变异(variation)严格地讲,同质是指被研究指标的影响因素完全相同。
但在医学研究中,有些影响因素往往是难以控制的(如遗传、营养等),甚至是未知的。
所以,在统计学中常把同质理解为对研究指标影响较大的、可以控制的主要因素尽可能相同。
例如研究儿童的身高时,要求性别、年龄、民族、地区等影响身高较大的、易控制的因素要相同,而不易控制的遗传、营养等影响因素可以忽略。
同质基础上的个体差异称为变异。
如同性别、同年龄、同民族、同地区的健康儿童的身高、体重不尽相同。
事实上,客观世界充满了变异,生物医学领域更是如此。
哪里有变异,哪里就需要统计学。
若所研究的同质群体中所有个体一模一样,只需观察任一个体即可,无须进行统计研究。
2、总体(population)与样本(sample)任何统计研究都必须首先确定观察单位(observed unit),亦称个体(individual)。
观察单位是统计研究中最基本的单位,可以是一个人、一个家庭、一个地区、一个样品、一个采样点等。
总体是根据研究目的确定的同质观察单位的全体,或者说,是同质的所有观察单位某种观察值(变量值)的集合。
例如欲研究山东省2002年7岁健康男孩的身高,那么,观察对象是山东省2002年的7岁健康男孩,观察单位是每个7岁健康男孩,变量是身高,变量值(观察值)是身高测量值,则山东省2002年全体7岁健康男孩的身高值构成一个总体。
它的同质基础是同地区、同年份、同性别、同为健康儿童。
总体又分为有限总体(finite population)和无限总体(infinite population)。
有限总体是指在某特定的时间与空间范围内,同质研究对象的所有观察单位的某变量值的个数为有限个,如上例;无限总体是抽象的,无时间和空间的限制,观察单位数是无限的,如研究碘盐对缺碘性甲状腺病的防治效果,该总体的同质基础是缺碘性甲状腺病患者,同用碘盐防治;该总体应包括已使用和设想使用碘盐防治的所有缺碘性甲状腺病患者的防治效果,没有时间和空间范围的限制,因而观察单位数无限,该总体为无限总体。
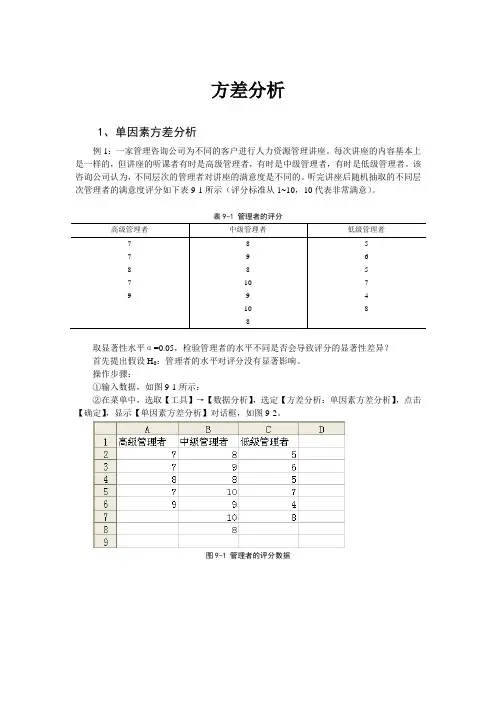
方差分析1、单因素方差分析例1:一家管理咨询公司为不同的客户进行人力资源管理讲座。
每次讲座的内容基本上是一样的,但讲座的听课者有时是高级管理者,有时是中级管理者,有时是低级管理者。
该咨询公司认为,不同层次的管理者对讲座的满意度是不同的。
听完讲座后随机抽取的不同层次管理者的满意度评分如下表9-1所示(评分标准从1~10,10代表非常满意)。
表9-1 管理者的评分高级管理者中级管理者低级管理者7 8 57 9 68 8 57 10 79 9 410 88取显著性水平α=0.05,检验管理者的水平不同是否会导致评分的显著性差异?首先提出假设H0:管理者的水平对评分没有显著影响。
操作步骤:①输入数据,如图9-1所示:②在菜单中,选取【工具】→【数据分析】,选定【方差分析:单因素方差分析】,点击【确定】,显示【单因素方差分析】对话框,如图9-2。
图9-1 管理者的评分数据图9-2 单因素方差分析对话框③在“输入区域”框输入数据矩阵(首坐标:尾坐标),可选为“A1:C8”,点选“标志位于第一行”,在“分组方式”框选定“列”,指定显著水平α=0.05,输出选项的输出区域可为工作表的任何位置,本例选择在I4处。
④点击【确定】,则得输出结果,如下图9-3所示。
图9-3 单因素方差分析结果图9-3是一个单因素方差分析结果的报告。
第一个表是有关各样本的一些描述统计量,它可以作为方差分析的参考信息。
第二个表是方差分析结果。
其中SS 表示平方和,df 为自由度,MS 表示均方,F 为检验的统计量,P-value 为用于检验的P 值,F crit 为给定α水平下的临界值。
从方差分析表可以看到,由于68232.375573.11=>=αF F ,所以拒绝原假设,即管理者的水平对评分的影响是显著的。
在进行决策时,可以直接利用方差分析表中的P 值与显著性水平α的值进行比较,若 P <α,则拒绝原假设;若P >α,则不能拒绝原假设。



EXCEL方差分析实例在Excel中进行方差分析可以使用数据分析工具包中的Anova: Single Factor分析工具。
下面我们使用一个实例来演示如何进行方差分析。
假设有一个实验,研究不同品牌汽车轮胎的寿命是否有差异。
我们随机选择了3个品牌的轮胎,每个品牌选择了10个样本。
寿命的数据如下所示:品牌1:500,510,505,495,485,490,500,495,505,500品牌2:490,485,480,495,500,495,505,500,510,495品牌3:505,500,495,490,485,500,500,495,500,505首先,将数据输入到Excel的工作表中。
在A列中输入"品牌1", "品牌2", "品牌3",在B列中分别输入对应品牌的寿命数据,共30个数据点。
然后,在Excel的菜单栏中选择"数据",点击"数据分析"按钮。
如果"数据分析"按钮没有显示,可以在Excel选项中打开数据分析工具包。
在"数据分析"对话框中选择"Anova:Single Factor",点击"确定"。
在"Anova: Single Factor"对话框中,将输入范围设置为包含我们的数据,即B1:B30。
选择"纵向位置"为第一列。
点击"确定"。
Excel将显示方差分析的结果。
在"Anova: Single Factor"结果窗口中,我们可以看到各个组的平均值、方差、观测次数等信息。
方差分析的结果也可以在工作表中显示。
在C1单元格中输入"组间平方和",在D1单元格中输入"组内平方和",在E1单元格中输入"总平方和",在F1单元格中输入"自由度组间",在G1单元格中输入"自由度组内",在H1单元格中输入"自由度总",在I1单元格中输入"组间均方",在J1单元格中输入"组内均方",在K1单元格中输入"F值",在L1单元格中输入"P值"。

第1章Excel统计分析功能概述1.1 Excel 2003新功能1.列表功能在Microsoft Office Excel 2003 中,可以在工作表中创建列表以将相关数据分组并对其进行操作。
Excel 2003既可以对现有数据创建列表,也可从空白区域创建列表。
在指定一个范围作为列表后,可以很容易地管理和分析独立于该列表外部其他数据的数据。
此外,可以通过与Microsoft Windows SharePoint Services 集成来与其他人共享包含在列表内的信息。
默认情况下,列表中每一列都已在标题行中启用了“自动筛选”,该功能可以快速筛选或排序数据。
与Microsoft Windows SharePoint Services集成Excel列表可以通过与Microsoft Windows SharePoint Services的无缝集成来对包含在列表内的信息进行协作。
可以通过发布列表来在SharePoint网站上基于Excel列表创建SharePoint列表。
如果选择将列表链接到SharePoint网站,则在同步该列表时,在Excel中对列表所做的任何更改都将反映在SharePoint网站上。
还可以使用Excel编辑现有的Microsoft Windows SharePoint Services 列表。
2.改进的统计函数在Excel 2003中,下列统计函数(包括四舍五入结果)的外观以及精确性都已增强:BINOMDIST、CHIINV、CONFIDENCE、CRITBINOM、DSTDEV、DSTDEVP、DV AR、DV ARP、FINV、FORECAST、GAMMAINV、GROWTH、HYPGEOMDIST、INTERCEPT、LINEST、LOGEST、LOGINV、LOGNORMDIST、NEGBINOMDIST、NORMDIST、NORMINV、NORMSDIST、NORMSINV、PEARSON、POISSON、RAND、RSQ、SLOPE、STDEV、STDEV A、STDEVP、STDEVPA、STEYX、TINV、TREND、V AR、V ARA、V ARP、V ARPA、ZTEST上述函数的计算结果可能与Excel以前版本中的结果有所不同。

双因素方差分析一、无交互作用下的方差分析设A 与B 是可能对试验结果有影响的两个因素,相互独立,无交互作用。
设在双因素各种水平的组合下进行试验或抽样,得数据结构如下表:表中每行的均值.i X (i=1,2,…r )是在因素A 的各个水平上试验结果的平均数;每列的均值jX .(j=1,2,…,n)是在因素B 的各种水平上试验的平均数。
以上数据的离差平方和分解形式为:SST=SSA+SSB+SSE (6.13) 上式中:∑∑-=2)(X X SST ij(6.14)∑-=∑∑-=2.2.)()(X X n X XSSA i i (6.15)∑-=∑∑-=2.2)()(X Xr X XSSB j j(6.16)∑+-∑-=2..)(X X X X SSE ji ij(6.17)SSA 表示的是因素A 的组间方差总和,SSB 是因素B 的组间方差总和,都是各因素在不同水平下各自均值差异引起的;SSE 仍是组内方差部分,由随机误差产生。
各个方差的自由度是:SST 的自由度为nr-1,SSA 的自由度为r-1,SSB 的自由度为n-1,SSE 的自由度为nr-r-n-1=(r-1)(n-1)。
各个方差对应的均方差是:对因素A 而言: 1-=r SSA MSA (6.18) 对因素B 而言: 1-=n SSB MSB (6.19)对随机误差项而言:1---=n r nr SSEMSE (6.20)我们得到检验因素A 与B 影响是否显著的统计量分别是:)]1)(1(,1[~---=n r r F MSE MSA F A (6.21))]1)(1(,1[~---=n r n F MSE MSBF B (6.22)【例6-2】某企业有三台不同型号的设备,生产同一产品,现有五名工人轮流在此三台设备上操作,记录下他们的日产量如下表。
试根据方差分析说明这三台设备之间和五名工人之间对日产量的影响是否显著?(α=0.05)。


Excel中的数据分析工具假设检验和方差分析Excel中的数据分析工具——假设检验和方差分析数据分析在现代社会中扮演着重要的角色,而Excel作为一款常用的办公软件,在数据分析方面具有强大的功能和工具。
本文将重点介绍Excel中的数据分析工具——假设检验和方差分析。
一、假设检验假设检验是一种统计方法,用于确定一个样本是否代表着整个总体的特征。
它通过对样本数据进行分析,来推断和判断总体的参数。
Excel提供了多种假设检验的方法,常用的有t检验和z检验。
1. t检验t检验用于对一个总体或两个总体的均值是否存在显著差异进行判断。
在Excel中,可以通过T.TEST()函数进行t检验的计算。
该函数的语法为:T.TEST(array1, array2, tails, type)。
其中,array1和array2分别表示两个样本的数据范围,tails表示尾部情况(单尾或双尾),type表示两个样本是否具有相等的方差。
2. z检验z检验用于判断一个样本均值和总体均值的显著性差异。
在Excel 中,可以通过Z.TEST()函数进行z检验的计算。
该函数的语法为:Z.TEST(array, x, sigma)。
其中,array表示样本数据范围,x表示总体均值的猜测值,sigma表示总体标准差。
二、方差分析方差分析是一种用于分析多个样本之间差异性的统计方法。
它可以用于判断一个因素是否对样本产生了显著影响。
Excel中提供了ANOVA()函数来进行方差分析的计算。
方差分析可以分为单因素方差分析和双因素方差分析两种情况。
1. 单因素方差分析单因素方差分析用于对一个因素(变量)的多个水平(组别)之间的差异进行比较。
在Excel中,可以通过使用ANOVA()函数进行单因素方差分析的计算。
该函数的语法为:ANOVA(data, group)。
其中,data表示包含多个组别数据的范围,group表示包含组别标识的范围。
2. 双因素方差分析双因素方差分析用于分析两个因素(变量)对样本数据的影响。

Excel在双因素等重复试验方差分析中的应用摘要:本论文旨在说明如何简单地将双因素等重复试验方差分析通过Excel软件来实现,使读者了解如何将数理统计同计算机技术相结合的一种方式。
关键词:方差分析、双因素等重复试验、Excel软件。
引言:方差分析是数理统计中的基本方法之一,是工农业生产和科学研究中分析数据的一种重要方法。
例如在化工生产过程中,众多因素会影响到产品的数量和质量,有些因素影响较大,有些较小,为了保证优质高产,就需要找出对产品数量和质量影响显著的因素,因此,就需要进行试验。
方差分析就是根据试验结果进行分析、推断各相关因素对试验结果的影响是否显著的有效方法,而往往实际需要分析的数据量庞大复杂,人工计算难以适应其速度、精度的要求,就需要引入计算机技术的辅助。
Excel是Microsoft Office家族中的一款应用软件,是一个功能多、技术先进、使用方便的表格式数据综合管理和分析系统,函数库丰富,制图功能较好,可以进行数据处理、统计分析和决策辅助。
将Excel软件应用于方差分析,将使得处理问题的数据规模和复杂性程度极大地提高,精度也更为准确,同时方便省时,结果直观了然。
而双因素等重复试验方差分析在几种简单类型的方差分析中稍微复杂些,计算量更大,更加有必要用Excel来处理。
原理:S E 称为误差平方和,S A 、S B 分别称为因素A 、因素B 的效应平方和,S A ⨯B称为A 、B 交互效应平方和。
S T ,S E ,S A ,S B ,S A ⨯B 的自由度依次为rst ﹣1,rs (t ﹣1),r ﹣1,s ﹣1,(r ﹣1)(s ﹣1)。
记T ...=111rsti j k X===∑∑∑ijk,T ij .=1tk X =∑ijk (i=1,2,…,r ;j=1,2,…,s ),T i ..=11stj k X ==∑∑ijk (i=1,2,…,r ),T .j .=11rti k X ==∑∑ijk (j=1,2,…,s )。
用excel进行方差分析的实验报告实验四:用excel进行方差分析的实验报告实验目的:学会在计算机上利用excel进行单因素方差分析和有交互的双因素分析以及无交互的双因素分析,实验背景:方差分析是从观测变量的方差入手,研究诸多控制变量中哪些变量是对观测变量有显著影响的变量。
一个复杂的事物,其中往往有许多因素互相制约又互相依存。
方差分析的目的是通过数据分析找出对该事物有显著影响的因素,各因素之间的交互作用,以及显著影响因素的最佳水平等。
方差分析是在可比较的数组中,把数据间的总的“变差”按各指定的变差来源进行分解的一种技术。
对变差的度量,采用离差平方和。
实验内容:实验(1):单因素方差分析条件:单因素方差分析是对成组设计的多个样本均数比较,所以对数据格式有特殊要求,因素的不同水平作为表格的列(或行),在不同水平下的重复次数作为行(或列)。
例1:以下数据来自2009年中国统计年鉴,各地区农村居民家庭平均每人生活消费支出,按不同项目分组的不同地区:其中,1代表生活消费支出合计,2代表食品,3代表衣着,4代表居住, 5代表家庭设施及服务, 6代表交通和通讯, 7代表文教娱乐用品及服务,8代表医疗保健, 9代表其他商品及服务各地区农村居民家庭平均每人生活消费支出 (2009年)单位:元地区项目地区生活消费食品衣着居住家庭设备交通和文教娱乐医疗保健其他品支出合计及服务通讯用品及服务及务地区 1 2 3 4 5 6 7 8北京8897.59 2808.92 654.36 1798.88 528 1132.09 960.41 867.87 14天津4273.15 1848.11 324.63 674.67 187.83 481.27 371.85 299.79 8河北3349.74 1195.65 217.82 796.62 170.4 350.92 263.53 289.27 6山西3304.76 1224.6 283.2 584.07 156.27 324.89 416.94 240.94 7内蒙古3968.42 1578.57 271.88 609.29 148.03 466.34 390.85 416.87 8辽宁4254.03 1563.33 335.93 793.91 185.5 416.41 437.79 409.64 11吉林3902.9 1371.12 286.97 737.07 168.36 355.99 376.76 511.5 9黑龙江4241.27 1331.07 345.69 946.84 161.03 427.35 496.42 434.25 9上海9804.37 3639.14 496.14 2102.96 480.62 1212.38 942.76 738.94 19江苏5804.45 2275.28 306.62 969.76 286.37 691.56 818.45 322.99 13浙江7731.7 2812.39 473.11 1488.95 374.31 968.17 843.34 609.07 16安徽3655.02 1494.19 203.37 813.12 229.66 302.23 312.05 227.1 福建5015.72 2304.14 291.72 821.21 260.68 570.24 421.69 219.02 12江西3532.66 1609.2 162.58 725.11 181.91 295.76 254.77 232.78 7山东4417.18 1618.66 265.59 945.81 273.77 533.55 399.95301.55河南3388.47 1220.36 225.64 875.83 203.81 310.11 234.01 242.87 7湖北3725.24 1668.35 195.45 702.62 229.32 307.22 281.68 236.31 10步骤:(1)、在excel的分析工具库中中选择“方差分析:单因素方差分析”指定相应的数据区域和显著性水平,点击“确定”后输出最终输出结果:表一方差分析:单因素方差分析SUMMARY组观测数求和平均方差列 1 32 129281.5 4040.048 3465440列 2 32 52249.75 1632.805 428309.6列 3 32 7951.16 248.4738 15408.02列 4 32 25251.6 789.1125 162323.1列 5 32 6519.28 203.7275 10263列 6 32 13547.29 423.3528 66285.85列 7 32 11279.63 352.4884 55136列 8 32 9809.81 306.5566 31281.44列 9 32 2716.05 84.87656 1665.067 表一是各组数据的描述统计指标。
Excel 数据管理与图表分析 双因素方差分析
在实际问题的研究中,有时需要考虑两个因素对实验结果的影响。
例如饮料销售,除了关心饮料颜色之外,还需要了解销售地区的不同是否影响销售量。
若把饮料的颜色看作影响销售量的因素A ,饮料的销售地区则是影响因素B 。
对因素A 和因素B 同时进行分析,就属于双因素方差分析的内容。
双因素方差分析的类型主要有两种,下面具体介绍其应用。
1.无重复双因素分析
无重复双因素分析是指在假设两个因素之间是相互独立、不存在任何关系的情况下,对其进行分析。
与单因素方差分析类似,在分析前需将试验数据按一定的格式输入工作表中。
例如,对
A 、
B 、
C 和
D 地区上半年和下半年的销售额进行统计,其数据信息如图13-6所示。
图13-6 创建表格 图13-7 设置无重复双因素参数
单击【分析】组中的【数据分析】按钮,在弹出的【数据分析】对话框中,选择【方差分析:无重复双因素分析】选项。
然后,在【方差分析:无重复双因素分析】对话框中,设置相关的参数,如图13-7所示。
其中,在【方差分析:无重复双因素分析】对话框中,各选项功能如下: ●
输入区域 输入无重复双因素分析的数据区域。
● 标志 启用该复选框,则生成的分析数据结果工作表中包含数据标志。
若禁用该复选框,则选择的分析数据中只能是数值类型,不能为文本类型,且生成的分析数据结果工作表中不包含数据标志。
●
α 显著性水平,一般输入0.05,即95%的置信度。
● 输出选项 输出无重复双因素分析数据的结果。
提 示 【方差分析:无重复双因素分析】对话框中的参数与【方差分析:单因素方差分
析】对话框中的参数相同。
单击【方差分析:无重复双因素分析】对话框中的【确定】按钮,即可得到如图13-8所示的方差分析结果。
创建
表格 选择
分析
结果
图13-8 无重复双因素方差分析
在生成的Sheet4无重复双因素方差分析工作表中,分为上下两部分。
其中,上部分为4个地区及上、下半年的计数、求和、平均和方差。
地区的方差是组内年份2个阶段销售额与其平均数之差的平方和除以自由度求得的,年份的方差是组内各地区销售额与其平均数之差的平方和除以自由度求得的。
例如:
A地区:[(B3-69.5)2+(C3-69.5)2]/(2-1)=180.5,以下3个地区均用此方法计算。
上半年:[(B3-120.75)2+(B4-120.75)2+(B5-120.75)2+(B6-120.75)2]/(4-1),下半年也运用此方法进行介绍。
下半部分为“方差分析”,它将影响销售额变动的因素分解为行(地区)、列(年份)和误差(随机误差)3项,下面分别介绍这些数值的计算方法。
●平方和
计算行和列的平方和,需要先计算其总平均数,然后以组平均数与总平均数相比求得其离差平方和,再乘以数据个数。
各地区年度总平均销售额:(D4+D5+D6+D7+D9+D10)/6=110.38
行平方和:[(D4-D12)2+(D5-D12)2+(D6-D12)2+(D7-D12)2]×2=15699
列平方和:[(D9-D12)2+(D10-D12)2)×4=861.13
随机误差平方和通常是由平方和总计减去行和列的平方和求得的。
其中,平方和总计是将“销售额”表格中的8个数据逐一与总平均数相比求得其离差,然后计算离差平方并算出合计,即误差==B19-B15-B16=5667.4。
●自由度
在统计学里,自由度(degree of freedom,df)是指当以样本的统计量来估计总体的参数时,样本中独立或能自由变化的数据的个数称为该统计量的自由度。
行自由度n-1=4-1=3
列自由度n-1=2-1=1
误差自由度为行与列自由度的乘积3×1=3。
总计的自由度n-1=8-1=7
●方差
样本中各数据与样本平均数的差的平方和的平均数叫做样本方差,下面介绍有关方差的计算。
行的方差=行平方和/行自由度=15699/3=5233.1
列的方差=列平方和/列自由度=861.13/1=861.13
误差的方差=误差平方和/误差自由度=5667.4/3=1889.1
●F统计量
F值是根据实验数据进行方差分析求出来的统计量。
F统计量等于方差除以误差方差。
行的F统计量=行方差/误差方差=5233.1/1889.1=2.7701
列的F统计量=列方差/误差方差=861.13/1889.1=0.4558
●F临界值
行按自由度N1=3,N2=3查显著性水平0.05的F分布表,得F临界值9.276628。
列按自由度N1=1,N2=3显显著性水平0.05的F分布表,得F临界值10.12796。
从上述的分析可以得出:列的F统计量远小于F临界值,说明年份是影响销售额的主要因素,行的F统计最也小于F临界值,说明地区是影响销售额的次要因素。
2.可重复双因素方差分析
可重复双因素方差分析假定两种因素的结合会产生出一种新的效应,这种效应又称交互作用。
每个因素必须重复取样至少两次以上,才能分析出来是否存在交互作用,即要进行“可重复”双因素方差分析。
例如,某商场对各商品区中不同的商品种类进行了统计,4个季度的销售量数据记录如图13-9所示。
由于该实例是对各商品区和商品种类两个变量因素进行分析;且在同一商品区和商品种类中,又包含4个季度的不同商品销售量,故可以使用可重复双因素方差分析的方法。
图13-9 创建表格
选择【数据】选项卡,单击【分析】组中的【数据分析】按钮,在弹出的【数据分析】对话框中,选择【可重复双因素分析】对话框。
然后,在弹出的【方差分析:可重复双因素分析】对话框中,设置【输入区域】为“$A$3:$E$15”;【每一样本的行数】为4,如图13-10所示。
设置
图13-10 设置可重复双因素分析参数
其中,在【方差分析:可重复双因素分析】对话框中,各选项功能如下:
●输入区域选择可重复双因素分析的数据区域。
●每一样本的行数输入创建可重复双因素分析数据的行数。
本例中,每个商品区中包含4个季
度的销售量数据,故输入数字4。
●α 著性水平,一般输入0.05,即95%的置信度。
●输出选项输出可重复双因素分析数据的结果。
单击【方差分析:可重复双因素分析】对话框中的【确定】按钮,即可得到如图13-11所示的数据分析结果。
图13-11 数据分析结果
提 示
可重复双因素方差分析与无重复双因素方差分析数据输入的区别在于对重复试验
数据的处理,可重复方差分析就是将重复试验的数据叠加起来。
可重复双因素方差分析的过程与前面讲述的无重复双因素方差分析的方法类似,这里不再介绍。
根据前面所讲述的知识,从图13-11中,可以看出样本(行)F 统计量(F )小于F 临界值(F crit ),且相差的值不大,说明商品区对销售量的影响不显著。
列的F 统计量小于F 临界值,且相差的值较大,说明商品种类对销售量有显著影响。
交互作用的F 统计量也小于F 临界值,且相差的值也较大,说明必须将商品区和商品种类两者很好的结合起来,才能吸引顾客消费。
分析
结果。