wordnetsimilarity介绍
- 格式:doc
- 大小:44.00 KB
- 文档页数:2

基于中文WordNet的中英文词语相似度计算吴思颖;吴扬扬【摘要】介绍一种基于中文WordNet的中英文词语相似度计算方法.在WordNet同义词集的上下位关系图中,引入了距离、密度、深度3个因素来估计同义词集之间的相似度,采用一个自适应的方案来解决候选同义词集组合的权重和取舍问题.实现了一个可以计算英-英、汉-英、汉-汉词语之间相似度的算法,所得结果比较符合人们对词语的理解.【期刊名称】《郑州大学学报(理学版)》【年(卷),期】2010(042)002【总页数】4页(P66-69)【关键词】中文WordNet;词语相似度;语义相似度【作者】吴思颖;吴扬扬【作者单位】华侨大学计算机科学与技术学院,福建,厦门,361021;华侨大学计算机科学与技术学院,福建,厦门,361021【正文语种】中文【中图分类】TP391Wo rdNet是按语义关系组织的,它使用同义词集合代表概念,词汇关系在词语之间体现,语义关系在概念之间体现,一个词语属于若干个同义词集,而一个同义词集又包含若干个词语.由于语义关系是一种词义之间的关系,而词义是用同义词集合来表示,因此很自然地把语义关系看作为同义词集合之间的关系. WordNet中词汇概念的语义关系主要包括上下位、同义、反义、整体和部分、蕴含、属性、致使等不同的语义关系.中文Wo rdNet建立在普林斯顿大学开发的英文Wo rdNet词典的原理基础上,实现了一个约118 000中文词和115 400同义词集的中文-中文词典的功能,是使用了现有的英-汉词典库对英文WordNet中的词进行手工翻译而得到的.它同样也具有同义词、同等词、泛词等在英-英词典中提供的功能.词语相似度的计算方法主要分为两类[1-2]:一类方法称为基于上下文的方法,它利用大规模的语料或词语定义,收集统计数据,来评估词汇语义相似度;另一类是利用词典中的关系和层次结构,如概念之间的上下位关系和同位关系来计算词语的相似度.文献[3]利用了同义词集在WordNet中的最短距离和这条路径的转向次数来计算词语的相似度;文献[4]引入了本体和语料库,以2个同义词集的公共子结点的范围和公共的信息来计算其相似度;文献[1]从WordNet中提取同义词并采取向量空间方法计算英语词语的相似度.但由于Wo rdNet词典的语言限制,它们都局限于英文词语的语义相似度分析.文献[5]讨论了义原的相似度计算方法、集合和特征结构的相似度计算方法,并在此基础上提出了利用《知网》进行词语相似度计算的算法.本文利用中文Wo rdNet,在Wo rdNet同义词集的上下位关系图中,引入了距离、密度、深度3个因素来估计同义词集之间的相似度,用一个自适应的方案来解决候选同义词集组合的权重和取舍问题,设计并实现了一个能计算英-英、英-汉、汉-汉词语之间相似度的算法,所得结果比较符合人们对词语的理解.要计算2个词语之间的相似度,首先需要分别查出这2个词语所属的所有同义词集,并两两组合计算其相似度,最后根据这些同义词集组合的相似度计算出2个词语之间的相似度.下面分别介绍同义词集和词语的相似度计算.在WordNet中,同义词集(synset)之间的上下位关系形成了一个图结构,每个synset有0个或若干个上位和下位synset.因此,基于以下原则来计算同义词集之间的相似度[6]:1)在上下位关系图中,任意2个synset结点的距离越远,语义相似度越小.2)图中结点所处的位置密度越高,说明该局部的词义划分越细,相似度越低.3)在上下位关系图中相同距离的2个synset结点,所处的层次越深,描述的事物越具体,因此相似度越大.引入距离因子、密度因子、深度因子来衡量同义词集之间的相似度.距离因子σ计算公式为其中,lenth为2个synset之间的距离,θ为阈值参数.距离越大,σ值就越小,当距离大于阈值θ时,距离因子为0.密度越大,语义相似度越低.密度的计算可从局部结点的个数入手,具体方法为:分别从2个当前结点出发向上走3层,每一层的结点个数分别记PN1,PN2,PN3.期间2个结点若相遇,则终止,并将其上层结点数计为0,最终计算局部结点个数PN为其中,PN1是当前结点所在层次的结点个数,PN2,PN3依次为其上层结点个数.则密度因子φ为PN值越大表示密度越大,密度因子越小,且PN≥1,使得0<φ≤1.此外,深度越深,语义相似度越大.深度因子ω的计算公式为其中,dep th为该节点的深度,Ed为整棵语义树中所有结点的平均深度.即当结点的深度大于均值时,其深度因子为正,否则为负.综合考虑距离、密度、深度3个因素,则2个同义词集之间的相似度为若sim>1,则取sim=1.-φ和-ω分别为2个词的密度因子和深度因子的均值;α和β分别为密度因子和深度因子的权重.由于每个词语有一个或多个词义(sense),即它属于若干个同义词集,因此采用如下步骤计算2个词语之间的相似度:1)用联合查询语句在中文Wo rdNet词典数据库的各个翻译版本中,查找出被比较的词(英文单词或中文词语)所有可能出现的同义词集的id.2)将中文单词所属同义词集的标识synset_id转换为对应的英文同义词集的synset_id.3)令词a有m个词义(属于m个同义词集),词b有n个词义,即a,b所属的同义词集有m×n对组合.计算这m×n对同义词集的相似度,并排序.4)从大到小排序后,第1对同义词集所占的比重最大,令其权重为ρ,则第2对同义词集所占的权重为剩余比重×ρ,以此类推.设置一个阈值参数δ(0<δ<1),计算过程中仅考虑所有组合的前百分比阈值,如δ=0.3,则仅计算所有同义词集组合相似度最大的前30%.在实际操作中,当同义词集组合个数较多时,常出现1对或前几对同义词集的相似度非常大,因此首对权重ρ不宜过大,否则将失去综合权衡的意义.为了能够综合考虑被选取的同义词集组合的影响力,考虑根据选取的同义词集组合的数量来调节各组合所占的权重.因此,提出了一个根据同义词集组合个数num自适应调节参数ρ的公式,使得ρ∈[0.5,0.9],即当入选的同义词集组合个数num越小,首对同义词集的权重ρ越高(最大0.9),而ρ值随num的增加而递减(最小0.5),计算公式为其中,num=m×n.根据上述方法,实现了一个基于中文WordNet的词语相似度计算程序模块.在实验中,根据多次尝试中取得的经验,将文中提到的几个参数设置如下:距离因子中的阈值参数θ=7;深度因子中所有结点的平均深度经计算得Ed=8.624 3;密度因子权重α=0.1;深度因子权重β=0.1;同义词集组合前百分比阈值δ=0.2,即取相似度最大的前20%的组合考虑.对于词语相似度计算结果的评价,最好是放到实际的系统中(如本课题后期研究的数据空间的进化将利用此结果数据模式进行匹配),观察不同的计算方法对系统性能的影响,在条件不许可的情况下采用人工判别的方法.对比了文献[5]中介绍的同样能计算中文词语相似度的基于《知网》的词汇语义相似度计算方法,对比结果如表1所示,方法1为文献[5]中介绍的方法,方法2为本文介绍的基于中文WordNet的相似度计算方法.对比表1结果,方法2的实验结果与人们的理解比较一致,方法1得到的相似度与人们的理解相对差别大一些.例如,方法1对“论文”、“文章”、“文献”这样词义接近的词汇的相似度估计相差巨大,因为方法1中计算词语相似度时采用了2个词之间各个概念相似度的最大值.而方法2计算结果中,“论文”与“文章”、“文献”的相似度比较接近,都在0.91以上,因为方法2对词语各个概念(同义词集)的各种组合采取了一种动态加权和的办法,能自适应地调整组合之间的权重.本算法的另一个独特之处是兼容中英文双语的相似度计算,表2给出另外一些测试结果.从实验结果可以看出,“父亲”和“father”同为正式用语,相似度高于“父亲”和“爸爸”,而同为口语的“爸爸”和“dad”也有较高的相似度;“中国”和“亚洲”的相似度高于“中国”和“欧洲”也是较为合理的;“猫”直接类属于“动物”,因此“猫”和“动物”的相似度大于“猫”和“狗”的相似度.总体上看,该方法得到的大部分结果是较为准确的.本文主要分析了中文WordNet的体系结构,根据影响词语相似度的距离、密度和深度3个因素,定义了完整的同义词集之间的相似度算法,并采用了自适应的方法对被查词语的同义词集组合进行了取舍和权重定义.最后,实现了一个计算中英文词语相似度的算法,并进行了实验.测试结果表明:本方法得到的结果与人工判别结果基本一致,比基于《知网》的词汇语义相似度计算方法更符合人们的理解.下一步研究将把词语相似度算法应用于数据空间管理系统的进化和检索中,使数据空间的查询结果更为准确有效.【相关文献】[1] 荀恩东,颜伟.基于语义网计算英语词语相似度[J].情报学报,2006,25(1):43-48.[2] Sebti A,Barfrous A A.A new wo rd sense similarity measure inWordNet[C]//Proceedingsof the International M ulticonference on Computer Science and Information Technology.Washinton D C:IEEE Computer Society,2008:369-373.[3] Hirst G,St-Onge D.Lexical chains as rep resentationsof context fo r the detection and correction of malap ropisms[M]// WordNet:an Electronic Lexical Database.Cambridge M A:M IT Press,1998.[4] Resnik ing information content to evaluate semantic similarity in ataxonomy[C]//Proceedingsof the 14th International Joint Conference on A rtificial Intelligence.San Francisco:Mo rgan Kaufmann Publishers Inc,1995:448-453.[5] 刘群,李素建.基于《知网》的词汇语义相似度计算[J].计算语言学及中文信息处理,2002,7(2):59.[6] 张承立,陈剑波,齐开悦.基于语义网的语义相似度算法改进[J].计算机工程与应用,2006,42(17):165-166.。

基于知网语义相关度计算的词义消歧方法
知网语义相关度计算(WordNet Similarity)是一种基于计算语言学原理来测量两个词语之间的相似程度的语义消歧方法。
它利用已有的计算语言学技术、例如WordNet(一种基于英文的信息网络)来实现消歧结果的计算。
知网语义相关度计算在语言处理中有着广泛的应用,不仅在自然语言处理领域中有着广泛使用,而且在机器学习和搜索引擎领域也有着重要的应用。
知网语义相关度计算的基本思想是将两个词语在语义上进行比较,求出它们之间的相似度。
首先,需要通过WordNet数据库中的词语的语义表示来构建出它们的语义概念树;其次,在概念树上求取它们的共同最大子概念;最后,计算它们的最大子概念的深度,或者在语义上的相似性。
为了更好地消歧词语之间的相似性,知网语义相关度计算还采用了一些其他技术,比如词汇相似性(Word Similarity)、语义相似性(Semantic Similarity)和句子相似性(Sentence Similarity)。
简而言之,知网语义相关度计算就是利用WordNet数据库中的词语的语义表示来估计两个词语之间的相似程度的一种消歧方法。
它利用计算语言学技术,比如WordNet数据库中的词语的语义表示、语义相似性、句子相似性等等,来实现相似性的计算。
在实际应用中,它可以帮助计算机更准确地理解人类语言,从而提高机器学习和搜索引擎的性能。
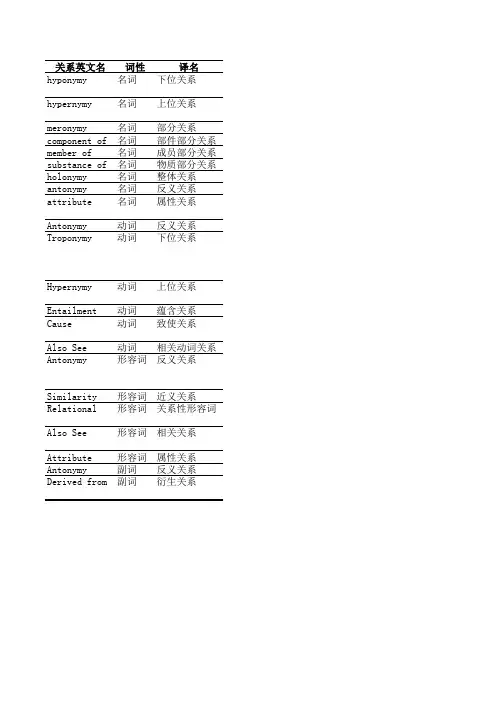
关系英文名词性译名hyponymy名词下位关系hypernymy名词上位关系meronymy名词部分关系component of名词部件部分关系member of名词成员部分关系substance of名词物质部分关系holonymy名词整体关系antonymy名词反义关系attribute名词属性关系Antonymy动词反义关系Troponymy动词下位关系Hypernymy动词上位关系Entailment动词蕴含关系Cause动词致使关系Also See动词相关动词关系Antonymy形容词反义关系Similarity形容词近义关系Relational形容词关系性形容词Also See形容词相关关系Attribute形容词属性关系Antonymy副词反义关系Derived from副词衍生关系含义或示例对应于概念关系的类别表示对某个类的细化,即如果X是一种Y,那么X是Y的下位词(hyponym)is kind of表示对多个具体实例的泛化,即如果X是一种Y,那么Y是X 的上位词(hypernym)is a generalization of如果X是Y的一部分,那么X是Y的部分词(meronym)is part of例如:“鸟嘴/翅膀-鸟”(beak/wing-bird)is component of 例如:“树木”和“森林”(tree-forest)is member of例如:“铝”和“飞机”(aluminum-plane)is substance of 如果X是Y的一部分,那么Y是X的整体词(holonym)contains parts 例如:“胜利-失败”(victory-defeat)opposite of用形容词来表达其值的名词,如“重量”是一个属性,它的值对应的形容词是“轻”和“重”attribute of代表了复杂的若干种语义关系。
如disappear与appear opposite of如果V1在某个特定语义维度表示了V2,那么V1是V2的下位词。



nltk计算词向量相似度
当使用 NLTK(自然语言处理工具包)计算词向量相似度时,可以使用其中的`word_similarity`函数来实现。
下面是一个示例代码,演示了如何使用 NLTK 计算词向量相似度:
```python
from nltk.corpus import wordnet
from nltk.metrics import word_similarity
# 定义两个词
word1 = "猫"
word2 = "狗"
# 计算词向量相似度
similarity = word_similarity(word1, word2)
# 打印相似度结果
print("相似度:", similarity)
```
在上述示例中,我们首先导入了`wordnet`和`word_similarity`模块。
然后,定义了两个要比较的词`word1`和`word2`。
接下来,使用`word_similarity`函数计算了这两个词的相似度,并将结果存储在`similarity`变量中。
最后,打印出相似度的结果。
需要注意的是,NLTK 的`word_similarity`函数基于 WordNet 词典来计算相似度,它考虑了词的语义关系和词汇层次结构。
然而,该函数仅适用于英文词汇。
如果你要处理其他语言或需要更高级的词向量相似度计算方法,可能需要使用其他的自然语言处理库或工具,如 GloVe、ELMo、BERT 等。
希望这个示例对你有帮助。
如果你有任何进一步的问题,请随时提问。


增加文档相似性的技巧要提高文档相似性的技巧文档相似性是指两个或多个文档之间的相似程度。
在处理文本数据、信息检索和自然语言处理等领域,了解和应用文档相似性是非常重要的。
提高文档相似性的技巧可以帮助我们更好地理解文本并进行相关任务。
下面将介绍一些提高文档相似性的技巧。
1. 词袋模型(Bag of Words, BoW)词袋模型是一种常用的文档相似性技巧。
它将文本表示为单词的集合,忽略了单词的顺序和语法结构。
通过计算文档中共同出现的单词的频率,可以判断文档之间的相似度。
词袋模型可以用于文本分类、信息检索和情感分析等任务。
2. 词嵌入(Word Embedding)词嵌入是将单词表示为连续向量的技术。
通过训练模型,可以将每个单词映射到一个向量空间中的点。
在向量空间中,语义相似的单词会被映射到相近的位置,从而更好地表示单词之间的相似性。
词嵌入可以用于计算文档之间的相似度,并进行相关的自然语言处理任务。
3. 余弦相似度(Cosine Similarity)余弦相似度是一种常用的度量文档相似性的方法。
它通过计算文档之间的向量夹角余弦值来度量它们的相似度。
余弦相似度取值范围为[-1, 1],值越接近1表示文档越相似,值越接近-1表示文档越不相似。
余弦相似度可以用于文本聚类、推荐系统和搜索引擎等任务。
4. TF-IDF(Term Frequency-Inverse Document Frequency)TF-IDF是一种常用的用于表示文档中单词重要性的方法。
它通过计算单词在文档中的频率和在语料库中的逆文档频率来计算单词的权重。
TF-IDF可以帮助我们更好地区分重要的单词和常见的单词,从而提高文档相似性的准确性。
5. 文档摘要(Document Summarization)文档摘要是将长文本压缩成简洁概括的过程。
通过提取文档的关键信息和重要内容,可以生成文档的摘要。
文档摘要可以帮助我们更好地理解文档内容,并提高文档相似性的准确性。

WordNet简介2008-01-05WordNet简介· 对于WordNet来说,10年后来清点清点得失似乎是合适的。
每个参与其事的研究人员都真诚地感受到它的缺点,并且他们从未觉得这是一个“完工”了的项目。
事实上,WordNet仍在继续发展中。
· "WordNet: An Electronic Lexical Database"一书分三部分,16章。
第一部分从第1章到第4章,前3章分别介绍WordNet中的名词,形容词,动词,第4章介绍WordNet的设计细节及相关软件的情况(这主要是由普林斯顿大学认知科学实验室的研究人员写的);第二部分和第三部分主要是由普林斯顿认知科学实验室之外的参加WordNet研究工作的研究人员撰写的。
第5章和第6章描述了WordNet的改进;第7章从形式化的概念分析的角度描述了WordNet;第8到第16章讨论了WordNet的各种不同应用。
(一)计算机与词库(computers and lexicon)· 一个人即使不接受把人脑比作计算机的隐喻,也一定同意,计算机提供了一个良好的模式演练场,通过它,人们可以测试各种关于人类认知能力的理论模型。
· 越来越多的人认识到,一个大的词库对自然语言理解,人工智能的各方面研究都具有重要的价值。
· 对大规模机器可读词典的需求同时也带来许多基础问题。
首先是如何构造这样一个词库,是手工编制还是机器自动生成?第二,词典中应包含什么样的信息?第三,词典应如何设计,即信息如何组织,以及用户如何访问?实际上,这些问题涉及到词典的编纂方法,词典的内容,词典的使用方式这一系列非常基础的问题。
(二)构造词库数据库(constructing the lexical database)· 构建词典的两种基本方式:自动获取 / 手工编制。
手工构建词典的优点之一是便于创建更为丰富的词条信息;其次是便于控制。

)作为一般词典的WordNet (WordNet as a dictionary)· WordNet跟传统的词典相似的地方是它给出了同义词集合的定义以及例句。
在同义词集合中包含对这些同义词的定义。
对一个同义词集合中的不同的词,分别给出适合的例句来加以区分。
(七)WordNet中的关系(relations in WordNet)·不同句法词类中的语义关系类型也不同,比如尽管名词都动词都是分层级组织词语之间的语义关系,但在名词中,上下位关系是hyponymy关系,而动词中是troponymy关系;动词中的entailment(继承)关系有些类似名词中的meronymy(整体部分)关系。
名词的meronymy关系下面还分出三种类型的子关系(见“WordNet 中的名词”部分)。
(八)网球问题(the tennis problem)· WordNet是基于同义性和反义(对义)性来描述词语和概念之间的各种语义关系类型的。
由于WordNet的注意力不是在文本和话语篇章水平上来描述词和概念的语义,因此WordNet中没有包含指示词语在特定的篇章话题领域的相关概念关系。
例如,WordNet中没有将racquet(网球拍)、 ball(球)、net(球网)等词语以一定方式联系到一起。
Roger Chaffin在一封私人信笺中,曾把这类问题称为“tennis problem”(网球问题),指的就是如何把racquet、ball、net、court game (场地比赛);或者把physician(内科医生)跟hospital(医院)联系到一起。
这对电子词典来说,是一个挑战。
已经有一些相关的研究工作在探索如何从WordNet 中包含的词汇和概念之间的语义关系,来推导出话题信息。
Hirst和St-Onge描述了一种所谓的“词汇链”(lexical chain)的应用方法。
“词汇链”是在基于名词的语义关系构成的上下文中的名词的序列。
Wordnet是一个词典。
每个词语(word)可能有多个不同的语义,对应不同的sense。
而每个不同的语义(sense)又可能对应多个词,如topic和subject在某些情况下是同义的,一个sense中的多个消除了多义性的词语叫做lemma。
例如,“publish”是一个word,它可能有多个sense:1. (39) print, publish -- (put into print; "The newspaper published the news of the royal couple's divorce"; "These news should not be printed")2. (14) publish, bring out, put out, issue, release -- (prepare and issue for public distribution or sale; "publish a magazine or newspaper")3. (4) publish, write -- (have (one's written work) issued for publication; "How many books did Georges Simenon write?"; "She published 25 books during her long career")在第一个sense中,print和publish都是lemma。
Sense 1括号内的数字39表示publish以sense 1在某外部语料中出现的次数。
显然,publish大多数时候以sense 1出现,很少以sense 3出现。
WordNet的具体用法NLTK是python的一个自然语言处理工具,其中提供了访问wordnet各种功能的函数。
词网WordNet研究1——之初始接触WordNet® is a large lexical database of English. Nouns, verbs, adjectives and adverbs are grouped into sets of cognitive synonyms (synsets), each expressing a distinct concept. Synsets are interlinked by means ofconceptual-semantic and lexical relations. The resulting network of meaningfully related words and concepts can be navigated with the browser. WordNet is also freely and publicly available for download. WordNet's structure makes it a useful tool for computational linguistics and natural language processing.WordNet是一个英语字典。
由于它包含了语义信息,所以有别于通常意义上的字典。
WordNet根据词条的意义将它们分组,每一个具有相同意义的字条组称为一个synset(同义词集合)。
WordNet为每一个synset提供了简短,概要的定义,并记录不同synset之间的语义关系。
在WordNet中,名词,动词,形容词和副词各自被组织成一个同义词的网络,每个同义词集合都代表一个基本的语义概念,并且这些集合之间也由各种关系连接。
(一个多义词将出现在它的每个意思的同义词集合中)。
在WordNet的第一版中(标记为1.x),四种不同词性的网络之间并无连接。
工学硕士学位论文汉英平行语料库的词义自动标注方法研究李壮哈尔滨工业大学2007年7月图内图书分类号:TP391.2国际图书分类号: 681.37工学硕士学位论文汉英平行语料库的词义自动标注方法研究硕士研究生:李壮导师:杨沐昀 副教授申请学位:工学硕士学科、专业:计算机科学与技术所在单位:计算机科学与技术学院答辩日期:2007年7月授予学位单位:哈尔滨工业大学Classified Index:TP391.2U.D.C.: 681.37A Dissertation for the Degree of M. Eng.RESEARCH ON AUTOMATIC WORD SENSE TAGGING IN CHINESE-ENGLISHPARALLEL CORPUSCandidate:Li ZhuangSupervisor:Associate Prof. Yang Muyun Academic Degree Applied for:Master of Engineering Specialty:Computer Science and Technology Date of Defence:July, 2007Degree-Conferring-Institution:Harbin Institute of Technology哈尔滨工业大学工学硕士学位论文摘要有指导词义消歧方法存在知识获取瓶颈问题,词义标注语料库的自动构建是减小此问题的最佳策略之一。
现有词义自动标注技术还存在很多不足之处,而双语平行语料库的出现为此项研究带来了新的前景。
本文以较大规模汉英平行语料库为基础,综合已有的词对齐和语义相似度计算等技术,研究词义标注方法,以获得满足一定精度的汉语和英语词义标注语料,从而解决有指导的词义消歧方法训练语料匮乏问题。
具体来说,本文在以下方面做了研究:首先,改进并实现了一种基于目标语译文集合的单语排歧算法。
Wordnet是一个WordNet是一个由普林斯顿大学认识科学实验室在心理学教授乔治·A·米勒的指导下建立和维护的英语字典。
在WordNet中,名词,动词,形容词和副词各自被组织成一个同义词的网络,每个同义词集合都代表一个基本的语义概念,一个多义词将出现在它的每个意思的同义词集合中。
WordNet是按语义关系组织的,其语义关系有以下几类:(1)同义关系。
WordNet最重要的关系就是词的同义关系,因为判断词这种关系的能力是在词汇矩阵中表达词义的先决条件。
Wordnet中根据替换原则定义同义词:如果两种表达方式在语言文本中相互替代而不改变其真值,则这两种表达就是同义的。
因而,WordNet分成名词,动词、形容词和副词几大类。
不同词类中的语义关系类型也不同。
比如尽管名词都动词都是分层级组织词语之间的语义关系,但在名词中,上下位关系是hyponymy关系,而动词中是troponymy关系;动词中的entailment(继承)关系有些类似名词中的meronymy (整体部分)关系。
名词的meronymy关系下面还分出三种类型的子关系(见“WordNet中的名词”部分)。
(2)反义关系。
反义词是一种词形间的词汇关系,而不是词义间的语义关系。
反义关系为WordNet中的形容词和副词提供了一种中心组织原则。
(3)上下位关系。
上下位关系具有某种限制,且是一种不对称的关系(Lyons,1977,v01.1),由下它只有唯一的上属关系,这就产生了一种层次语义结构,其中下位词位于其上属关系的下层。
下位词继承了它的上位词——更一般化概念的所有性质,并且至少增加一种属性,以区别它与它的上位词以及该上位词的其他下位词。
这种方法为WordNet中的名词提供了一种核心的组织原则。
在名词网络中,通过词语的上下位关系来计算词间的距离是WordNet 中简单常用的一种计算相似度方法。
(4)部分-整体关系(HASA)。
本文利用WordNet Similarity 工具包进行词义相似度的计算
以下十种相似度计算方法:
①Path方法
该方法主要依据Rada提出的基于最短路径的相似度度量方法[126],将两个词义概念在WordNet层次结构树上最短路径长度的倒数作为两者的相似度。
②Hso方法
该方法即Hirst与St-Onge所提出的基于词汇链的相似度计算方法[128],如2.4节公式
(2.5)所示。
两个词义概念之间的词汇链越长,发生的转向次数越多,则相似度越低。
③Lch方法
该方法由Leacock与Chodorow提出,其对Rada的最短路径方法作了改进,引入了两者在WordNet层次结构树上的深度,如公式(3.2)所示[172]。
其中,表示两个概念在WordNet层次结构树上最短路径的距离,D表示两者在WordNet 概念层次结构树中深度的较大值。
12 (, )dss
④Lesk方法
该方法即2.4节介绍的Lesk所提出的基于释义重叠的相似度计算方法,将两个词义概念的释义的重合词语数量作为两者的相似度[13]。
⑤Lin方法
Lin从信息论的角度来考虑词义概念的相似度,认为相似度取决于不同词义概念所包含信息的共有性(Commonality)和差别性(Difference)[136]。
该方法将相似度定义为公式(3.3):
其中c表示s1与s2在WordNet层次结构树上的最深父结点,P(s)表示任选一个词义概念属于类别s的概率。
⑥Jcn方法
该方法由Jiang和Conrath提出,将词义概念层次结构与语料统计数据结合,将基于最短路径的方法[126]和基于概念结点信息量[133]的方法融合,计算方法如2.4节公式(2.12)所示[135]。
⑦Random方法
该方法将随机生成数作为两个词义概念之间的相似度,仅作为一种基线对照方法。
⑧Resnik方法
该方法为由Resnik提出的基于概念结点信息量的相似度计算方法,根据两个概念所共有的最深父结点的信息量,衡量两者的相似度[133]。
计算方法如2.4节公式(2.9)所示。
⑨Wup方法
该方法是由Wu与Palmer提出的基于路径结构的相似度度量方法[173],综合考虑了
概念结点、共有父结点、根结点之间的路径关联情况,其计算方法如公式(3.4)所示。
将1 s 与2 s 的最深上层父概念记作s3 ,N1 表示由概念结点1 s 到达3 s 的
路径上的结点的数量;N2 表示由2 s 到达3 s 的路径上的结点的数量;N3 表示由3 s 到达
概念层次结构树的根结点的路径上的结点的数量。
⑩Vector_pairs方法
该方法是由Patwardhan与Pedersen提出的基于WordNet层次结构信息和语料库共现信息的相似度计算方法[138]。
对每个词义概念,根据语料库统计信息,得到其释义中词语的共现词语,为其构建释义向量(Gloss Vectors);根据不同词义的释义向量之间的余弦夹角衡量两者的词义相关度。
WordNet中的概念释义往往比较简短,包含的词语比较少;单纯依赖当前释义有时无法判断词义的相关度。
为了解决这一问题,该方法借助WordNet的语义结构关系,寻找与当前概念具有直接语义关系的概念的释义;利用这些关联概念的释义来作为当前概念的补充,以保证释义向量的维数足以判定相关度。
Patwardhan对多种不同词义相似度计算方法的效果进行考查,比较不同方法与人类判断(Human Judgement)的差异,发现Vector_pairs方法得到的相似度与人类判断最为接近;在SensEval-2数据集上的词义消歧实验也表明Vector_pairs方法的效果要优于其它方法[138]。
鉴于此,本章在后续实验中采用Vector_pairs方法来计算词义相似度。
在进行词义选择时,本文需要依次计算歧义词的词义与上下文消歧特征词的相似度,这需要解决词义(Sense)与词语(Word)的相似度计算问题。
参照Rada[126]和Resnik[133]的研究工作,本文利用公式(3.5)将其转换为词义与词义的相似度计算问题;取最相关的词义组合的相似度作为计算结果。
,s 表示某一词义,w表示某一词语,senses(w)表示词语w的词义集合。