基因本体数据库与GO富集分析
- 格式:pptx
- 大小:1.51 MB
- 文档页数:19


基因本体论(go)功能注释 gene ontologyannotation基因本体论(Gene Ontology,简称GO)是一种用来描述基因功能的标准化系统。
GO的功能注释则是使用GO术语为基因或蛋白质序列进行注释,帮助科学家理解生物体内基因的功能和相互关系。
本文将介绍基因本体论(GO)的概念和作用,以及基因本体论功能注释的流程和应用。
一、基因本体论(GO)的概念和作用基因本体论(GO)是一种标准化的词汇系统,用于描述基因和蛋白质的功能、过程和组件。
GO包含三个主要的本体:分子功能(Molecular Function)、生物过程(Biological Process)和细胞组件(Cellular Component)。
每个本体都包含一系列术语和相应的定义,科学家可以根据这些术语和定义来描述基因的功能。
基因本体论的作用是帮助科学家对基因和蛋白质进行分类和理解。
通过将基因和蛋白质注释到GO术语上,科学家可以更准确地了解它们的功能、参与的生物过程以及位于细胞的哪个组件。
这对于研究基因的功能以及疾病的发生和发展有着至关重要的意义。
二、基因本体论功能注释的流程基因本体论功能注释是指将基因或蛋白质序列与基因本体论术语进行关联的过程。
下面是一般的基因本体论功能注释流程:1.数据预处理:获取待注释基因或蛋白质的序列数据,排除冗余数据和噪音数据。
2.基因本体论术语获取:从基因本体论数据库中获取相应的术语,包括分子功能、生物过程和细胞组件。
3.序列比对:将待注释的基因或蛋白质序列与已知序列进行比对,找出相似序列。
4.注释:根据序列比对的结果,将相似序列的注释信息转移到待注释序列上。
5.术语关联:根据注释信息,将待注释基因或蛋白质与相应的基因本体论术语进行关联。
6.结果验证:对注释结果进行验证和统计分析,评估注释的准确性和可靠性。
三、基因本体论功能注释的应用基因本体论功能注释在生命科学研究中有着广泛的应用。
以下是一些常见的应用领域:1.基因功能研究:通过注释基因的功能,科学家可以更好地理解基因在细胞中的作用,从而揭示生物体内复杂的生物过程。


gene ontology enrichment analysis基因本体富集分析(gene ontology enrichment analysis)是一种用来分析不同基因集间的差异性的方法,可以帮助研究人员识别出与某些生物学过程相关的基因及其功能。
本文将分步骤阐述常见的基因本体富集分析流程。
第一步:选取适当的基因集和背景集在进行基因本体富集分析前,需要确定一个需要研究的基因集,通常该集合由已有的基因测序数据得出。
接着,我们需要选择一个与研究对象相关的背景基因集,通常情况下,背景基因集就是研究对象中未包含的整体基因。
第二步:统计基因本体类别首先,我们需要对已确定的基因集进行注释,将其与已知的基因本体(GO term)进行匹配。
GO term是由一些标准化语言描述的基因功能和生物过程,包含三个主要分类:分子功能、细胞组成和生物过程。
从生物学的角度看,GO term能够帮助我们更好的了解基因之间的相互关系和作用,同时还能够对相关生物学过程进行分类和统计。
统计每个基因本体分类中包含的基因数,并对其进行比较。
如果一个基因本体类别中包含的基因数量显著多于在整个背景基因集中出现该类别的概率,则表明该类别在基因集中富集(enrichment)了。
第三步:确定显著性水平在第二步中,我们可以得到一堆基因本体富集的结果,但是,是否这些结果是有意义的需要通过设定显著性水平来判断。
显著性水平可以表示为P值、FDR或Benjamini/Hochberg等纠正方法。
依据统计方法的不同,显著性水平的数值也不同,最常用的是P值。
P值越小,差异性越显著。
第四步:结果展示和分析在最后一步中,我们需要对富集分析的结果进行展示和分析。
通常情况下,一个基因在多个基因本体类别间都可以分类,为了避免过度解释结果,我们通常会选择多重比较校正或者Bonferroni校正技术来控制假阳性率。
根据结果,我们可以进一步探索基因在不同基因本体分类中所具有的功能以及对不同生物过程的影响。

go analysis of up-regulated genes in ko
在基因表达分析中,对上调基因进行GO(基因本体论)分析是一种常见的手段。
上调基因是指在特定条件下,其表达水平相对于对照或基准条件有所增加的基因。
在GO分析中,首先需要准备目的基因文件,这个文件包含差异表达信息,如果使用工具自带的背景基因文件,那么目的基因文件的基因ID类型需要与背景基因文件一致。
然后,选择“使用文件”按钮上传目的基因和背景基因文件,如果是自己准备的背景基因文件则无此限制,只需目的基因id与背景基因id一致即可。
接下来,选择是否包含log2FC列,这是表示差异倍数取对数后的值。
物种选择也很重要,根据分析需求选择正确的物种。
最后,点击提交按钮,等待分析完成。
此外,GO富集分析的结果通常包括气泡图、条形图、富集圈图等,这些结果可以帮助理解上调基因在生物学过程中的角色。
对于KEGG 富集分析,其结果还可以在KEGG通路图上体现,比如红色表示上调,
绿色表示下调。
总之,通过GO和KEGG富集分析,可以对上调基因进行深入的功能和通路分析,从而更好地理解基因表达变化的生物学意义。
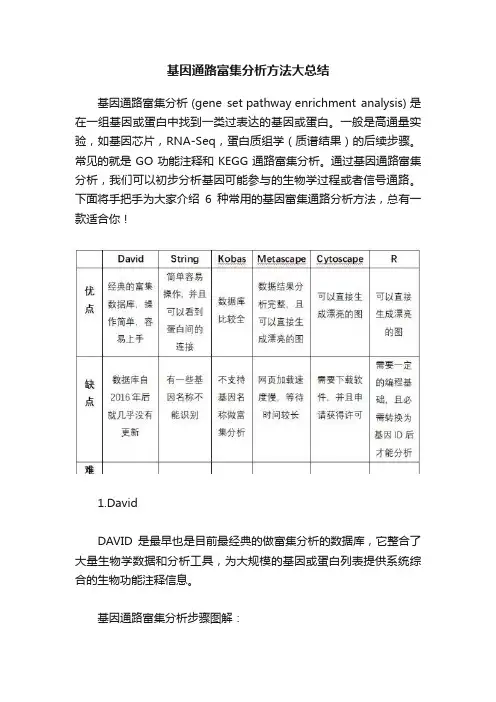
基因通路富集分析方法大总结基因通路富集分析 (gene set pathway enrichment analysis) 是在一组基因或蛋白中找到一类过表达的基因或蛋白。
一般是高通量实验,如基因芯片,RNA-Seq,蛋白质组学(质谱结果)的后续步骤。
常见的就是GO功能注释和KEGG通路富集分析。
通过基因通路富集分析,我们可以初步分析基因可能参与的生物学过程或者信号通路。
下面将手把手为大家介绍6种常用的基因富集通路分析方法,总有一款适合你!1.DavidDAVID是最早也是目前最经典的做富集分析的数据库,它整合了大量生物学数据和分析工具,为大规模的基因或蛋白列表提供系统综合的生物功能注释信息。
基因通路富集分析步骤图解:第一步:打开网址,点击Functional Annotation。
第二步:输入基因集,选择输入类型第三步:选择物种,查看结果(包括GO和KEGG通路结果)2.StringString数据库是瑞士苏黎世大学构建的一个搜寻蛋白质之间相互作用的数据库。
既包括蛋白质之间的直接物理相互作用,也包括蛋白质之间的间接功能相关性。
它除了包含有实验数据、从PubMed摘要中挖掘的结果和综合其他数据库数据外,还有利用生物信息学的方法预测的结果。
基因通路富集分析步骤图解:第一步:打开网站,输入基因列表和选择物种;第二步:选择数据库内对应基因名称;第三步:结果下载-包括Go和KEGG通路。
(如有需要还可以下载蛋白连接的结果)4.KobasKobas是北京大学开发的用于注释和鉴定富集途径和疾病的数据库基因通路富集分析步骤图解:第一步:打开网站,选择Gene-list Enrichment第二步:选择输入类型,物种,输入基因列表,选择数据库,后可分析下载数据。
5.MetascapeMetascape是近年来新兴的富集分析数据,数据不仅更新快,其覆盖面也相当广泛。
从数据库种类来说,Metascape整合了GO、KEGG、UniProt和DrugBank等多个权威的数据资源,使其不仅能完成通路富集和生物过程注释,还能做基因相关的蛋白质网络分析和涉及到的药物分析,致力于为科研工作者提供每个基因全面而详细的信息。

利用agriGO网络服务进行GO富集分析苏震,徐文英,杜舟,周鑫1.分析目的随着生命科学的发展,越来越多的基因功能被实验验证或者预测推导,但如何规范地注释这些基因是一个难题。
基因本体论(Gene Ontology,GO)是一个在生物信息学领域中广泛使用的本体,应用于基因的功能注释和富集化分析。
GO是一个国际标准化的基因功能分类体系,提供了一套动态更新的标准词汇表,由Gene Ontology组织(/)开发并且维护。
并且,GO是对基因属性特征的客观描述,独立于任何物种或者细胞类型。
因此,我们利用GO,可以对不同物种、不同细胞类型下的基因功能进行规范的描述,避免了沟通上的不便,也可以将隐藏在文献中的基因功能信息更加有效地提取出来。
在动植物功能基因组的研究中,高通量技术的使用产生了海量的组学数据,比如在不同发育期、不同逆境处理下的转录组数据集可以多至上千个表达谱,如何分析和解释这些数据成为摆在生物学家面前的一个难题,而使用GO对基因功能注释进行富集分析,是一套较好的解决方案。
agriGO(GO Analysis Toolkit and Database for Agricultural Community)是一个专注农业物种(以植物物种为主)的GO功能注释与分析的网络数据库与在线分析平台。
agriGO采用的是一套具有完整结构的控制词汇集,使得对该系统可以更好地用于统计和运算,为生物信息学、生物统计学的研究带来了很大的便利。
2.分析工具Gene Ontology富集分析工具agriGO,网址:/agriGO//agriGOv2/参考文献:Zhou Du, Xin Zhou, Yi Ling, Zhenhai Zhang, and Zhen Su. (2010) agriGO: a GO analysis toolkit for the agricultural community. Nucleic Acids Research 38: W64-W70.Tian Tian, Yue Liu, Hengyu Yan, Qi You, Xin Yi, Zhou Du, Wenying Xu, Zhen Su; (2017) agriGO v2.0: a GO analysis toolkit for the agricultural community, 2017 update. Nucleic Acids Research. doi: 10.1093/nar/gkx3823.操作步骤采用agriGO平台提供的实例,练习agriGO中主要的分析工具(见/agriGO/analysis.php):Singular Enrichment Analysis (SEA) 、Parametric Analysis of Gene Set Enrichment (PAGE) 和Cross comparison of SEA (SEACOMPARE)。


转录组学研究的生物信息学方法随着高通量测序技术的发展,转录组学研究在生物学研究中越来越受到重视。
转录组学研究是指对特定组织或细胞中所有转录本的RNA序列进行分析,以了解基因表达和调控的机制。
转录组学研究需要大量的生物学和计算机科学知识,其中生物信息学方法在数据预处理、基因差异表达分析等方面起着至关重要的作用。
一、数据质控和预处理在进行转录组学研究之前,需要对产生的原始数据进行质量控制和预处理。
这是保证后续分析结果准确性和可靠性的重要步骤。
数据质控包括检查测序数据的质量指标、去除低质量的序列、去除接头序列、去除未知碱基N和剪切读长等。
预处理的过程包括将清洗后的序列比对到参考基因组、利用软件进行转录本拼接、估计基因表达水平和归一化表达矩阵。
二、基因差异表达分析基因差异表达分析是转录组学研究的重要任务之一。
通过比较在两个或多个不同条件下的组织或细胞中的基因表达差异,可以确定哪些基因在特定条件下受到调控。
基因差异表达分析通常包括以下几个步骤:1. 基因定量:将各个样品中基因的表达量数量化。
这个过程中,需要将清洗后的碱基序列比对到一个已知的基因组或转录本组装。
基因表达量的定量可以用TPM(每百万个转录本)或FPKM(每百万个外显子组)进行度量。
2. 差异表达基因的标准化:标准化的目标是将不同样品的基因表达矩阵统一。
这个过程中可以考虑去除一些不需要的变量,例如测序深度、性别、批次效应等,以提高数据准确性。
3. 基因差异表达分析:通过比较在不同条件下的基因差异表达水平,确定在差异条件下基因表达的变化。
常见的方法包括T检验、方差分析、DEseq2、edgeR、limma等方法。
4. 实验验证:基因差异表达的结果需要进行实验验证,确保结果的准确性。
三、基因富集分析基因富集分析是对一组差异表达的基因进行进一步的功能注释和生物学意义解释的分析。
在转录组学研究中,基因富集分析可以通过GO富集分析、KEGG富集分析等方法进行。

go和kegg的标准
基因本体论(Gene Ontology,GO)是一个国际标准化的基因功能分类体系,旨在建立一个适用于各种物种的、对基因和蛋白功能进行限定和描述的,并能随着研究不断深入而更新的语义词汇标准。
这个体系的基本单位是词条(term),每个词条都对应一个属性。
京都基因与基因组百科全书(Kyoto Encyclopedia of Genes and Genomes,KEGG)是一个整合了基因组、化学和系统功能信息的综合数据库。
KEGG下属4个大类和17个子数据库,其中有一个数据库叫做KEGG Pathway,专门存储不同物种中基因通路的信息。
总的来说,GO和KEGG都是重要的生物信息学数据库,它们各自都有自己的标准,这些标准有助于科学家更好地理解和注释基因的功能。
几种常用的基因功能分析方法和工具(转自新浪博客)一、GO分类法最先出现的芯片数据基因功能分析法是GO分类法。
Gene Ontology(GO,即基因本体论)数据库是一个较大的公开的生物分类学网络资源的一部分,它包含38675 个Entrez Gene 注释基因中的17348个,并把它们的功能分为三类:分子功能,生物学过程和细胞组分。
在每一个分类中,都提供一个描述功能信息的分级结构。
这样,GO中每一个分类术语都以一种被称为定向非循环图表(DAGs)的结构组织起来。
研究者可以通过GO分类号和各种GO 数据库相关分析工具将分类与具体基因联系起来,从而对这个基因的功能进行描述。
在芯片的数据分析中,研究者可以找出哪些变化基因属于一个共同的GO功能分支,并用统计学方法检定结果是否具有统计学意义,从而得出变化基因主要参与了哪些生物功能。
EASE(Expressing Analysis Systematic Explorer)是比较早的用于芯片功能分析的网络平台。
由美国国立卫生研究院(NIH)的研究人员开发。
研究者可以用多种不同的格式将芯片中得到的基因导入EASE 进行分析,EASE会找出这一系列的基因都存在于哪些GO分类中。
其最主要特点是提供了一些统计学选项以判断得到的GO分类是否符合统计学标准。
EASE能进行的统计学检验主要包括Fisher 精确概率检验,或是对Fisher精确概率检验进行了修饰的EASE 得分(EASE score)。
由于进行统计学检验的GO分类的数量很多,所以EASE采取了一系列方法对“多重检验”的结果进行校正。
这些方法包括弗朗尼校正法(Bonferroni),本杰明假阳性率法(Benjamini falsediscovery rate)和靴带法(bootstraping)。
同年出现的基于GO分类的芯片基因功能分析平台还有底特律韦恩大学开发的Onto-Express。
2002年,挪威大学和乌普萨拉大学联合推出的Rosetta 系统将GO分类与基因表达数据相联系,引入了“最小决定法则”(minimal decision rules)的概念。
DAVID进⾏GOKEGG功能富集分析何为功能富集分析?功能富集分析是将基因或者蛋⽩列表分成多个部分,即将⼀堆基因进⾏分类,⽽这⾥的分类标准往往是按照基因的功能来限定的。
换句话说,就是把⼀个基因列表中,具有相似功能的基因放到⼀起,并和⽣物学表型关联起来。
何为GO和KEGG?为了解决将基因按照功能进⾏分类的问题,科学家们开发了很多基因功能注释数据库,。
这其中⽐较有名的⼀个就是Gene Ontology(基因本体论,GO)和Kyoto Encyclopedia of Genes and Genomes(京都基因与基因组百科全书,KEGG)。
其中,GO是基因本体论联合会建⽴的⼀个数据库,旨在建⽴⼀个适⽤于各种物种的、对基因和蛋⽩功能进⾏限定和描述的、并能够随着研究不断深⼊⽽更新的语义词汇标准。
GO注释分为三⼤类:分⼦⽣物学功能(Molecular Function,MF)、⽣物学过程(Biological Process,BP)和细胞学组分(Cellular Components,CC),通过这三个功能⼤类,对⼀个基因的功能进⾏多⽅⾯的限定和描述。
⽽KEGG,⼤多数⼈会将其当做⼀个基因通路(Pathway)的数据库,其实KEGG的功能远不⽌于此。
KEGG是⼀个整合了基因组、化学和系统功能信息的综合数据库。
KEGG下属4个⼤类和17个⼦数据库,⽽其中有⼀个数据库叫做 KEGG Pathway,专门存储不同物种中基因通路的信息,也是⽤的最多的⼀个,久⽽久之,KEGG被⼤家当做⼀个通路数据库了。
下⾯两个图展⽰了GO和KEGG Pathway的⾯貌。
如何做功能富集分析?做功能富集分析的算法有很多,能够做功能富集分析的⼯具也⾮常多,见下⾯的列表Funrich 也可以做功能富集分析以上的⼯具中,DAVID最为常⽤也最为权威。
DAVID是由美国Leidos⽣物医学研究公司的LHRI团队开发的⼀个在线基因注释及功能富集⽹站(https:///)使⽤DAVID做功能富集分析第⼀步打开DAVID官⽹:https:///点击左侧功能菜单:Functional Annotation进⼊到如下的页⾯中,页⾯中的红框中就是进⾏分析所⽤的主要操作区域。
go富集结果解读
Go富集结果解读包括对Go注释、p值和富集指数的解读。
Go注释提供了被实验偏重编码的功能类别信息,可以解读出差异基因在GO term的富集程度,颜色越深富集越显著,红色最显著,黄色次之,无色代表富集不显著。
P值表示Go注释与实验结果之间的相关性,用于判断基因功能注释与实验结果的相关性程度。
P值越小,表示基因功能注释与实验结果的相关性越大。
富集指数表示比预期要多多少倍的基因被实验验证,可以反映基因功能的显著性程度。
富集指数越大,表示实验验证的基因数量比预期的要多,基因功能显著性越高。
在解读Go富集结果时,应考虑P值和富集指数,以确定哪些Go注释是真正与实验结果相关的,并且可以更好地理解和解释实验结果。
同时,也要关注显著富集的低层级Go term,以便具体而详尽的解释生物学问题。
需要注意的是,Go富集分析的统计假设并不能完全代基因功能的重要程度,要结合生物学问题、结合基因的功能注释,才能判断其中的基因变化是否有重要的生物学意义。
两种方法进行差异基因GO富集分析差异基因GO富集分析登录AriGO2.0网站首页,点击Analysis tool:选择物种名,这里我们选择十字花科Brassicaceae的拟南芥Arabidopsis thaliana:将第一次实验找到的最显著差异的250个基因名,粘贴到Query list中,点击Submit:等待分析:得到分析结果:随后我们将生物过程、细胞组成和分子功能三种图导出(从左至右依次对应),从中我们可以看到这些差异基因参与响应了哪些生物学过程或是参与哪些生物学功能:点开分子功能图中右下角的Peroxidase activity框,可以看到基因参与这个过程具体的内容:根据上面的图片,我们可以得到一个结论:重金属离子及氯化钠产生离子的胁迫会促进拟南芥植物细胞加速代谢并提高其过氧化物酶、还原酶和水解酶等的活性,在反应上与氧胁迫类似。
在页面下方,可以看到差异基因富集的具体信息:基于topGO包本地GO分析双击example.R文件,将路径重新更改:选择国内镜像(我选择的Lanzhou):首先进行准备工作,将# install dependency package、# load funtion for GO analysis和#read differential genes information步骤完成,查看diff_geneFile确认其导入情况:随后进行#extrct differential genes name与#GO analysis:进行#extract GO result与#save GO result步骤:分别输入View(biological_Process)、View(molecular_Function)和View(cellular_Component)以查看富集图与富集数据:Biological Process(20个term的富集):Molecular Function(20个term的富集):Cellular Component(20个term的富集):导出GO的富集图:在文件夹中也可以看到已导出的格式为csv的BP、MF、CC富集表格:综上,通过对表格的观察,我们可以发现:相比于正常情况,在重金属盐离子与NaCl盐离子的胁迫下,拟南芥细胞中与离子运输、细胞代谢和氧化、水解、还原等酶类产生相关的生物学过程都有较大的变化。
非模式基因GO富集分析:以玉米为例使用OrgDb模式生物做什么都简单,非模式生物则很多缺少注释,没有注释你就没法做,只能是借助于各种软件比如blastgo,自己跑电子注释。
但今天要讲的不是这种情况,很多物种还是有注释的,只是你有时候不知道该去那里下载,或者你有数据,却不知道该怎么用!很多的软件都是针对模式生物的,或者针对某一些类型的非模式生物,能够支持多种非模式生物,能够支持用户自己的注释文件的软件相对来讲,就非常少有了,然而clusterProfiler就是这类少有的软件之一。
获得OrgDb今天要讲的是通过OrgDb来做GO分析,这是clusterProfiler的enrichGO函数所支持的背景注释,Bioconductor自带20个OrgDb 可供使用,多半是模式生物,难道我们要做的物种不在这20个里面就不行了吗?显然不是的,clusterProfiler能支持的物种我自己都数不过来。
我们可以通过AnnotationHub在线检索并抓取OrgDb,比如这里以玉米为例:> require(AnnotationHub)> hub query(hub, 'zea')AnnotationHub with 2 records# snapshotDate(): 2017-04-25 # $dataprovider: Inparanoid8, ftp:///gene/DATA/# $species: Gibberella zeae, Zea mays# $rdataclass: Inparanoid8Db, OrgDb# additional mcols(): taxonomyid, genome, description,# coordinate_1_based, maintainer, rdatadateadded, preparerclass, tags,# rdatapath, sourceurl, sourcetype # retrieve records with, e.g., 'object[['AH10514']]' title AH10514 | hom.Gibberella_zeae.inp8.sqlite AH55736 | org.Zea_mays.eg.sqlite通过检索,org.Zea_mays.eg.sqlite就是我们所要的OrgDb,可以通过相应的accession number, AH55736抓取文件,并存入了maize对象中,它包含了51097个基因的注释:> maize length(keys(maize))[1] 51097这个OrgDb,包含有以下一些注释信息:> columns(maize) [1] 'ACCNUM' 'ALIAS' 'CHR' 'ENTREZID' 'EVIDENCE' [6] 'EVIDENCEALL' 'GENENAME' 'GID' 'GO' 'GOALL' [11] 'ONTOLOGY' 'ONTOLOGYALL' 'PMID' 'REFSEQ' 'SYMBOL' [16] 'UNIGENE'转换ID我们可以使用bitr来转换ID,甚至于直接检索GO注释:> require(clusterProfiler)> bitr(keys(maize)[1], 'ENTREZID', c('REFSEQ', 'GO', 'ONTOLOGY'), maize) ENTREZID REFSEQ GO ONTOLOGY1 541612 XP_008648268.1 GO:0009507 CC2 541612 XP_008648268.1 GO:0051537 MF3 541612 XP_008648268.1 GO:0009055 MF4 541612 XP_008648268.1 GO:0046872 MF5 541612 XP_008648268.1 GO:0022900 BP6 541612 NP_001104837.2 GO:0009507 CC7 541612 NP_001104837.2 GO:0051537 MF8 541612 NP_001104837.2 GO:0009055 MF9 541612 NP_001104837.2 GO:0046872 MF10 541612 NP_001104837.2 GO:0022900 BP11 541612 XM_008650046.2 GO:0009507 CC12 541612 XM_008650046.2 GO:0051537 MF13 541612 XM_008650046.2 GO:0009055 MF14 541612 XM_008650046.2 GO:0046872 MF15 541612 XM_008650046.2 GO:0022900 BP16 541612 NM_001111367.2 GO:0009507 CC17 541612 NM_001111367.2GO:0051537 MF18 541612 NM_001111367.2 GO:0009055 MF19 541612 NM_001111367.2 GO:0046872 MF20 541612 NM_001111367.2 GO:0022900 BPGO富集分析> sample_genes head(sample_genes)[1] '541612' '541613' '541614' '541615' '541617' '541618'这里我只是简单地使用ID列表中前100个ENTREZ基因ID,也可以使用其它的ID,通过借助于bitr进行转换,或者通过给enrichGO 指定ID类型(keyType参数)。
gene ontology基因本体论(gene ontology)的建立现今的生物学家们浪费了太多的时间和精力在搜寻生物信息上。
这种情况归结为生物学上定义混乱的原因:不光是精确的计算机难以搜寻到这些随时间和人为多重因素而随机改变的定义,即使是完全由人手动处理也无法完成。
举个例子来说,如果需要找到一个用于制抗生素的药物靶点,你可能想找到所有的和细菌蛋白质合成相关的基因产物,特别是那些和人中蛋白质合成组分显著不同的。
但如果一个数据库描述这些基因产物为“翻译类”,而另一个描述其为“蛋白质合成类”,那么这无疑对于计算机来说是难以区分这两个在字面上相差甚远却在功能上相一致的定义。
Gene Ontology (GO)项目正是为了能够使对各种数据库中基因产物功能描述相一致的努力结果。
这个项目最初是由1988年对三个模式生物数据库的整合开始:: FlyBase (果蝇数据库Drosophila),t Saccharomyces Genome Database (酵母基因组数据库SGD) and the Mouse Genome Database (小鼠基因组数据库MGD)。
从那开始,GO不断发展扩大,现在已包含数十个动物、植物、微生物的数据库。
Gene Ontology(GO)包含了基因参与的生物过程,所处的细胞位置,发挥的分子功能三方面功能信息,并将概念粗细不同的功能概念组织成DAG(有向无环图)的结构。
Gene Ontology是一个使用有控制的词汇表和严格定义的概念关系,以有向无环图的形式统一表示各物种的基因功能分类体系,从而较全面地概括了基因的功能信息,纠正了传统功能分类体系中常见的维度混淆问题。
在基因表达谱分析中,GO常用于提供基因功能分类标签和基因功能研究的背景知识。
利用GO的知识体系和结构特点,旨在发掘与基因差异表达现象关联的单个特征基因功能类或多个特征功能类的组合。
根据GO的知识体系,使用“功能类”(或者叫做“功能模块”)这一概念具有以下优点:我们认为,单个基因的表达情况的改变不足以反映特定功能/通路的整体变化情况。