基于DSP的连续数字语音识别系统的实现
- 格式:pdf
- 大小:167.86 KB
- 文档页数:4

基于定点DSP处理芯片的语音信号的识别近年来,高性能数字信号处理芯片DSP(Digital Signal Process)技术的迅速发展,为语音识别的实时实现提供了可能,其中,AD 公司的数字信号处理芯片以其良好的性价比和代码的可移植性被广泛地应用于各个领域。
因此,我们采用AD 公司的定点DSP 处理芯片ADSP2181 实现了语音信号的识别。
1 语音识别的基本过程根据实际中的应用不同,语音识别系统可以分为:特定人与非特定人的识别、独立词与连续词的识别、小词汇量与大词汇量以及无限词汇量的识别。
但无论那种语音识别系统,其基本原理和处理方法都大体类似。
一个典型的语音识别系统的原理图如图1 所示。
语音识别过程主要包括语音信号的预处理、特征提取、模式匹配几个部分。
预处理包括预滤波、采样和量化、加窗、端点检测、预加重等过程。
语音信号识别最重要的一环就是特征参数提取。
提取的特征参数必须满足以下的要求:(1)提取的特征参数能有效地代表语音特征,具有很好的区分性;(2)各阶参数之间有良好的独立性;(3)特征参数要计算方便,最好有高效的算法,以保证语音识别的实时实现。
在训练阶段,将特征参数进行一定的处理后,为每个词条建立一个模型,保存为模板库。
在识别阶段,语音信号经过相同的通道得到语音特征参数,生成测试模板,与参考模板进行匹配,将匹配分数最高的参考模板作为识别结果。
同时,还可以在很多先验知识的帮助下,提高识别的准确率。
2 系统的硬件结构2.1 ADSP2181 的特点AD 公司的DSP 处理芯片ADSP2181 是一种16b 的定点DSP 芯片,他内部存储空间大、运算功能强、接口能力强。
有以下的主要特点:(1)采用哈佛结构,外接16.67MHz 晶振,指令周期为30ns,指令速度为33MI/s,所有指令单周期执行;(2)片内集成了80 kB 的存储器:16 kB 字的(24b)的程序存储器和16kB 字(16b) 的数据存储器;(3)内部有3 个独立的计算单元:算术逻辑单元(ALU)、乘累加器。

基于D S P的语音处理系统的设计The Standardization Office was revised on the afternoon of December 13, 2020Cadence SPB基于DSP的语音处理系统的设计摘要近年来,随着DSP技术的普及和低价格、高性能DSP芯片的出现,DSP已越来越多地被广大的工程师所接受越来越广泛地被应用于各个领域,并且已日益显示出其巨大的优越性。
DSP是利用专门或通用的数字信号处理芯片,以数字计算的方法对信号进行处理,具有处理速度快、灵活、精确、抗干扰能力强、体积小及可靠性高等优点,满足了对信号快速、精确、实时处理及控制的要求。
本次设计基于TLV320AIC23和TMS320VC5416两种芯片设计并实现了一种语音录音、语音编码、语音解码、语音处理和回放的系统。
通过软件和硬件结合对该系统进行设计,使本次设计的语音处理系统具有强大的数据处理能力并配有灵活的接口电路,可以作为一种语音信号处理算法研究和实时实现的通用平台,对语音编码在DSP上的实时实现进行了简单的研究,从而掌握了算法移植的一般流程,为能够在高速DSP硬件平台设计及系统应用开发方面取得成功奠定基础。
关键词:DSP;数据采集; TLV320AIC23;TMS320VC5416。
目录摘要 I 第1章绪论 1 DSP的发展及应用 1 语音信号处理系统概述 2 第2章 DSP芯片介绍 3 TLV320AIC23简介 3 TMS320VC5416简介 3 第3章系统设计 4 系统硬件设计 4 系统结构框图 4 DSP处理器 5 A/D电路 5 D/A电路 7 系统软件设计 10 TMS320VC5416初始化 10 TLV320AIC23初始化 10 第4章总结 11 参考文献 12 致谢 13 附录 14 第1章绪论近年来,在数字信号处理领域有着绝对优势的DSP技术得到了迅速发展,不仅在通信计算机领域大显身手,并已逐渐渗透到人们日常消费领域。

基于DSP的语音识别技术设计与实现随着科技的发展,语音识别技术正在得到广泛的应用。
它可以实现智能音响、智能家居等场景下的语音交互,并且可以应用于医疗、教育、广播电视等多个行业。
其中,基于DSP的语音识别技术更是成为这些领域的核心技术之一。
本文将探讨基于DSP的语音识别技术的设计与实现,希望能够对相关工程师和爱好者提供帮助。
一、DSP技术基础DSP技术(数字信号处理)是指利用数字信号处理器对数字信号进行处理的技术。
它可以处理语音信号、图像信号、视频信号等多种数值信号类型。
而在语音识别技术中,DSP技术主要用于语音信号的前端处理,包括信号滤波、降噪、增益等,以提高信号的质量和准确性。
DSP技术的实现需要掌握多项计算机技能,如DSP芯片的选型、DSP编程技术(C语言、汇编语言等)、DSP算法的掌握等。
因此,在选取DSP芯片之前,需要充分了解DSP技术的特点和应用场景。
常用的DSP芯片有TI(德州仪器)、ADI(模拟设备公司)等,各有特点和适用范围。
二、语音信号前端处理DSP技术在语音识别中的作用主要在于对语音信号进行前端处理。
语音信号包含了大量的噪声和杂音,因此需要进行降噪和信号增益来提高信号的质量。
接下来,我们将详细介绍语音信号的前端处理方法。
1. 语音信号采集语音传感器通常采用麦克风,根据具体应用场景不同,可选择不同类型的麦克风。
对于智能音响等应用场景,常采用阵列麦克风,以提高语音采集的质量。
采集时需要设置合适的采样率和采样深度,以保证质量。
一般采样率为8、16、32kHz 等,采样深度可为12、16、24、32位等。
2. 语音信号滤波语音信号中包含了大量的噪声和杂音,需要进行滤波处理。
常用的语音信号滤波方式有数字滤波器和模拟滤波器。
其中,数字滤波器是基于DSP技术实现的,模拟滤波器是基于模拟电路的。
根据实际需求,可选择不同的滤波方式。
3. 语音信号降噪语音信号中的噪声是影响语音识别准确性的主要因素之一,因此需要对语音信号进行降噪处理。


邮局订阅号:82-946360元/年技术创新DSP开发与应用《PLC技术应用200例》您的论文得到两院院士关注基于DSP的语音处理和识别系统的实现RealizationofSpeechProcessingandRecognitionSystemBasedonDigitalSignalProcessor(河北工程大学)王社国魏艳娜董爱荣WANGSHEGUOWEIYANNADONGAIRONG摘要:设计并实现了一种嵌入式语音处理和识别系统,核心处理器是TMS320VC5402,语音接口芯片是TLV320AIC10,软件模块包括语音的端点检测、特征参数提取、模板训练、测试识别等。
系统使用定点DSP实现了浮点DSP运算,提高了预算的精度,扩大了信号处理的动态范围。
试验结果表明,该系统对孤立词特定人识别率为98%,系统体积小、成本低、可扩展性好,方便应用于许多特定场合,如:声控玩具,门禁控制等。
有很好的市场前景。
关键词:TMS320VC5402;语音处理;语音识别中图分类号:TN912.34文献标识码:BAbstract:Anembeddedspeechprocessingandrecognitionsystemisdesignedandrealizedinthispaper.Itshardware’sprocessorisTMS320VC5402andspeechinterfacechipisTLV320AIC10.Speechrecognitionsystem’ssoftwareconsistsofseveralmodulessuchasendpointdetection,featurecoefficientextraction,trainingofspeechrecognitionreferencedvectors,etc.Thesystemrealizesfloat-pointoperationonfixed-pointdigitalsignalprocessor,ithashigherprecisionincalculationandwidersignalprocessingdynamicrangecomparingtofixed-pointrealizationscheme.Theexperimentconfirmsthatitsspeechrecognitionaccuracyreaches98percentforspecialpersonandsmallvocabulary.Thissystemhassmallscale,lowcostandhighcapabilityofexpanding.Itisveryconvenientforsomespecialsituations,suchasthespeechcontrollingtoys,gatingsystemetc.Ithasmuchmarketpotential.Keywords:TMS320VC5402,speechprocessing,speechrecognition文章编号:1008-0570(2007)08-2-0179-03引言DSP是利用专门或通用的数字信号处理芯片,以数字计算的方法对信号进行处理,具有处理速度快、灵活、精确、抗干扰能力强、体积小及可靠性高等优点,满足了对信号快速、精确、实时处理及控制的要求。

基于DSP的语音采集与处理系统的设计与实现程武,物理与电子信息学院摘要:本文介绍了一种基于TMS320C5402的语音采集与处理系统的设计与实现, 采用TLC320AD50作为语音CODEC模块的核心器件,利用TMS320C5402对采集到的语音信号进行FIR滤波,该系统具有较强的数据处理能力和灵活的接口电路,能够满足语音信号滤波的要求,可以扩展为语音信号处理的通用平台。
关键字:语音采集; FIR滤波器; TMS320C5402Design and Implementation of Speech Signal Acquisitionand Processing System Based on DSPCheng Wu,The College of Physics and Electronic InformationAbstract: The design of speech signal acquisition and processing system is introduced in this paper. TLC320AD50 is used as the core voice CODEC module device in this system and TMS320C5402 is used as FIR filter. The system has high performance signal processing ability and is equipped with flexible inter facing circuit. It can satisfy the requirement for speech signal processing and can be used as a universal platform in the study of audio processing.Key words: Speech Signal Acquisition; FIR Filter; TMS320C54021引言语音处理是数字信号处理最活跃的研究方向之一~在IP电话和多媒体通信中得到广泛应用。

基于DSP的语音采集与回音效果的系统实现数字技术的应用几乎已经渗透到现代科技的每一个角落,而数字音频技术则是应用最广泛的领域之一。
现在大量的数字音频设备已相当成熟,利用软件在已有的硬件平台上实现不同的功能已成为一种趋势,软件编程的灵活性给很多设备增加不同的功能提供了方便。
和其它数字系统一样,DSP系统具有许多模拟系统所不具备的优点,如灵活、可编程,支持时分复用,易于模块化设计,可重复使用,可靠性高等。
随着DSP技术的发展,以DSP为内核的设备越来越多。
基于DSP技术的开发应用正在成为数字时代应用技术领域的潮流。
在实际生活中,当声源遇到物体时一般会发生反射,反射的声波和声源声波一起传输,听者会发现反射声波部分比声源声波慢一些从而形成回音。
而现在,在已知一个数字音源后,也可以利用计算机,以数字方式通过计算来模拟回声效应。
简单地讲。
就是在原声音流中叠加延迟一段时间后的声流来实现回音效果。
如此产生的回音,我们称之为数字回音。
1 主要器件介绍本设计选用的TLV320AIC23是TI公司生产的一款高性能的多媒体数字语音编解码器,它的内部ADC和DAC转换模块带有完整的数字滤波器,其数据传输宽度可以是16位、20位、24位和32位,采样频率范围为8~96 kHz,并可通过控制接口来编辑该器件的控制寄存器,同时可支持SPI和I2C两种控制模式。
TLV320AIC23的控制模式由MODEM管脚决定,本系统选用I2C模式。
TMS320VC5509A是TI公司C5000 DSP系列中的新一代产品。
该DSP对C54X 有很好的继承性。
并与C54x源代码兼容,从而有效地保护用户在软件上的投资。
TMS320VC5509A功耗低、成本低,并可在有限的功率条件下保持最好的性能。
2 系统方案设计2.1 系统工作原理该回音系统中的I2C接口模块由串行数据SDA和串行时钟SCL组成,SDA 和SCL均为双向接口。
连接在同一总线上的I2C设备可以工作在多主线工作模式下。

Computer Knowledge and Technology 电脑知识与技术第5卷第23期(2009年8月)本栏目责任编辑:唐一东人工智能及识别技术基于DSP 的语音识别的设计与实现张文婷(宁波大红鹰学院,浙江宁波315175)摘要:该系统选用了TI 公司的TMS320VC5402作为处理器芯片,选择对小词汇量语音识别系统进行研究。
实现小词汇量的语音识别主要包括以下三个方面的工作:端点检测、特征提取和模式匹配。
在端点检测中,通过对过零率和短时能量参数的检测来判断起始点和结束点,去掉噪声,从而提取出语音信号数据。
在特征提取中,首先对语音信号进行分帧、然后计算每帧语音信号的特征参数,该文采用线性预测倒谱参数作为特征参数,这些特征参数组成特征矢量,从而构成语音模板。
在模式匹配中,采用了动态时间归整方法,将测试模板与参考模板进行匹配,比较两者之间的失真,得出识别判决的依据。
关键词:DSP ;语音识别;DTW ;LPCC ;端点检测中图分类号:TN912.34文献标识码:A 文章编号:1009-3044(2009)23-6512-02The Application of the Speech Recognition System Based on DSPZHANG Wen-ting(Ningbo Da Hong-ying institution,Ningbo 315175,China)Abstract:For this,the s ystem selected TI's TMS320VC5402DSP to realize the speech recognition system of small -vocabulary.The small-vocabulary phonetic recognition includes three following respects:starting &ending point measuring,eigenvalue extracting and mode matching.Starting &ending point can be detected through zero rate and energy parameter .By detecting starting and ending point of speech waveform,we can remove the noise from the process of extracting the pronunciation signal data.In eigenvalue extracting,the pro -nunciation signal is divide into some framed signals,then,calculate every frame characteristic parameter,these characteristics made up the characteristic vector and formed the pronunciation template.In mode matching,adopting DTW (Dynamic Time Warping )method,made testing template matches with reference template in a perticular mode,and then,by campared distortion between them to obtain adjudge -ment result.Key words:DSP;Phonetic recognition;DTW;LPCC;the extreme point measuring1DSP 语音信号处理板的硬件设计本文选择了小词汇量、非特定人、孤立词识别方案,采用TMS320C5402DSP 芯片及外围接口与存储芯片,设计了一个语音识别系统。
481 概述伴随科技进步,语音识别系统在越来越多的领域得到了广泛的应用。
本文主要是研究基于DSP的特定人、小词汇量语音识别系统,提出更为优化和快速计算的算法,采用DSP芯片TMS320VC5509A 控制和TLV320AD50对原始语音进行采样和A/D转换,目的是研究出能识别人话的机器,通过接受人话口呼命令,掌握人发出的指令,从而做出指令要求的反映。
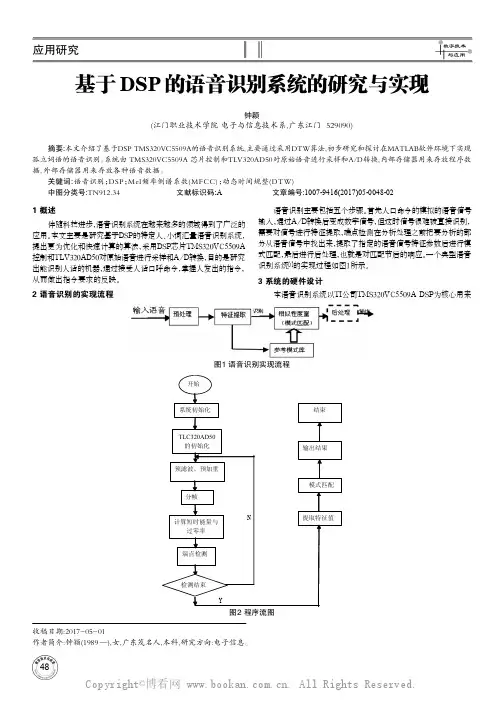
2 语音识别的实现流程语音识别主要包括五个步骤。
首先人口命令的模拟的语音信号输入,通过A/D转换后变成数字信号,但这时信号很难被直接识别,需要对信号进行特征提取,端点检测在分析处理之前把要分析的部分从语音信号中找出来,提取了指定的语音信号特征参数后进行模式匹配,最后进行后处理,也就是对匹配节后的响应。
一个典型语音识别系统[1]的实现过程如图1所示。
3 系统的硬件设计本语音识别系统以TI公司TMS320VC5509A DSP为核心用来收稿日期:2017-05-01作者简介:钟颖(1989—),女,广东茂名人,本科,研究方向:电子信息。
基于DSP 的语音识别系统的研究与实现钟颖(江门职业技术学院 电子与信息技术系,广东江门 529090)摘要:本文介绍了基于DSP TMS320VC5509A的语音识别系统,主要通过采用DTW算法,初步研究和探讨在MATLAB软件环境下实现孤立词语的语音识别。
系统由 TMS320VC5509A 芯片控制和TLV320AD50对原始语音进行采样和A/D转换,内部存储器用来存放程序数据,外部存储器用来存放各种语音数据。
关键词:语音识别;DSP;Mel频率倒谱系数(MFCC);动态时间规整(DTW)中图分类号:TN912.34文献标识码:A 文章编号:1007-9416(2017)05-0048-02图2 程序流图图1 语音识别实现流程49处理各种数据和程序,对原始语音进行采样和A/D转换,程序寄存在内部存储器,语音数据寄存在外部存储器。


基于DSP的机器人语言识别及控制系统设计摘要:随着科技的快速发展和人工智能的兴起,机器人技术在日常生活和工业领域中扮演着越来越重要的角色。
人们对机器人的交互性和智能化要求也越来越高。
其中,机器人的语言识别和控制是实现人机交互的重要环节。
因此,基于DSP的机器人语言识别及控制系统的研究具有重要的现实意义。
本研究旨在设计和实现一种基于DSP的机器人语言识别及控制系统,以提升机器人的交互能力和智能化水平。
本研究的意义在于提升机器人的语言交互能力,进一步拓展机器人的应用领域。
同时,研究成果对于推动人工智能技术的发展,促进人机交互的进步具有重要意义。
关键词:DSP;机器人;语言识别;控制系统设计一、控制系统框架和架构如图一所示,基于DSP的机器人语言识别及控制系统设计主要分为两个部分:基于DSP的语音采集和识别部分以及基于FPGA的机器人动作控制部分。
图1系统原理框架图在语音采集和识别部分,首先使用麦克风或其他音频设备对人的语音信号进行采集。
采集到的语音信号经过预处理,包括去噪、滤波和增益控制等处理,以保证语音信号的质量。
接着,通过DSP芯片对语音信号进行进一步处理,将其二值化,即将连续的语音信号转化为数字化的信号。
DSP芯片利用数字信号处理算法,对语音信号进行特征提取和模式匹配,实现语音识别的功能。
通过与预先设定的语音指令进行比对和判断,DSP芯片能够确定用户的意图,并输出相应的动作指令。
在机器人动作控制部分,动作指令由DSP芯片输出后,进一步被传输到FPGA 芯片。
FPGA芯片根据动作指令的内容,生成相应的时序逻辑控制信号。
这些信号通过与步进电机及其驱动电路连接,控制机器人的运动。
例如,如果动作指令是向前移动,FPGA芯片会产生相应的控制信号,使步进电机按照预定的步进顺序完成机器人的前进动作。
通过FPGA的灵活性和高速计算能力,可以实现对机器人动作的精确控制。
基于DSP的语音采集和识别部分以及基于FPGA的机器人动作控制部分相互配合,形成一个完整的机器人语言识别及控制系统。
收稿日期:2007-08-24;修回日期:2007-10-15。
基金项目::陕西省科学技术研究发展计划项目(2005k04-G23)。
作者简介:杨永超(1982-),男,陕西西安人,硕士研究生,主要研究方向:DSP 及数字语音处理; 付中华(1977-),男,湖北十堰人,副教授,主要研究方向:语音信号处理、数字音频信号处理、多媒体信号压缩与编解码; 蒋冬梅(1973-),女,河南永城人,副教授,博士,主要研究方向:语音识别、语音压缩、模式识别。
文章编号:1001-9081(2008)02-0491-03基于DSP 的实时语音检测的设计与实现杨永超,付中华,蒋冬梅(西北工业大学计算机学院,西安710072)(yyc821103@s ohu .com )摘 要:提出了一种基于DSP 的实时语音检测的方法,通过设置中断服务程序实现DSP 与DMA 的并行处理,采用双缓冲加一缓冲的方法保持语音连续性,利用短时能量状态转换图的方法对语音进行检测及存储,最后利用自制控制板实现程序控制和状态显示。
实验结果表明,检测的语音数据和标注的语音数据相比较平均正确率可达94.98%,有效地实现了语音的实时处理。
关键词:数字信号处理器;中断服务程序;语音检测;短时能量中图分类号:TP912.11 文献标志码:AD esi gn and i m plem en t a ti on of rea l 2ti m e vo i ce acti v ity detecti on ba sed on D SPY ANG Yong 2chao,F U Zhong 2hua,J I A NG Dong 2mei(School of Co m puter Science,N orthw estern Polytechnical U niversity,X i πan Shanxi 710072,China )Abstract:I n this paper,a method of Real 2ti m e Voice Activity Detecti on (VAD )based on DSP was p r oposed .After configuring I nterrup t Service Routine (I SR ),the audi o data was saved thr ough parallel p r ocessing of DSP and DMA based on the method of Short 2ter m energy state 2s witch p r ocess .A contr ol board was designed t o i m p le ment p r ogra m contr ol functi on .Experi m ental result shows that the data of st orage account for 94.98%of the marked in the DSP syste m,s o as t o realize the real ti m e p r ocessing of voice .Key words:DSP;I nterrup t Service Routine (I S R );Voice Activity Detecti on (VAD );short 2ter m energy0 引言语音检测是语音分析、语音合成和语音识别中的一个重要环节。
基于DSP的家居空调语音识别控制系统的设计实现【摘要】语音识别技术使家用电器的控制更加人性化,本文设计并实现了一种基于DSP的家居空调语音识别控制系统。
硬件核心处理器是TMS320VC5402,软件模块包括端点检测、MFCC求取、模板训练和改进的DTW算法。
实验结果表明,该系统对空调控制命令的识别率达94%以上,具有功耗小、性能稳定、运算精度高等优点,具有较大的市场应用价值。
【关键词】语音识别;TMS320VC5402DSP;Mel频率倒谱参数MFCC:DTW 算法1.引言近年来,家居空调的语音智能控制已经成为一个非常活跃的研究领域,语音识别技术作为一种重要的人机交互手段,辅助甚至取代传统的遥控器,在智能控制领域有着广阔的发展前景。
语音识别是机器通过识别和理解过程把语音信号转变为相应的文件或命令的技术。
随着DSP技术的快速发展及性能不断完善,基于DSP的语音识别算法得到了实现,并且在费用、功耗、速度、精确度和体积等方面有着PC机所不具备的优势,具有广阔的应用前景。
2.语音识别的基本原理语音识别的过程是一个模式匹配的过程。
首先根据语音特点建立语音模型,模型通常由声学模型和语言模型两部分组成,分别对应于语音到半音节概率的计算和半音节到字概率的计算。
对输入的语音信号进行预处理后提取所需的语音特征,在此基础上建立语音识别所需的模板。
在识别过程中,根据语音识别的整体模型,将输入的语音特征与已有的语音模板进行比较,找出最佳匹配对象作为识别结果。
一般的语音处理流程如图1所示。
图1 语音识别系统的处理流程图3.系统的硬件设计通过对系统功能分析,最终确定系统由语音采集与输出模块、语音处理模块、程序数据存储器FLASH模块、数据存储器SRAM模块、系统时序逻辑控制CPLD 模块、JTAG接口模块等组成,设计的框图如图2所示。
图2 语音识别系统的硬件结构框图(1)语音采集与输出模块。
该模块由高性能的立体声音频Codec芯片TLV320AIC23B来完成。
一种数字语音通信系统的DSP实现一种数字语音通信系统的DSP实现一种数字语音通信系统的DSP实现2007-01-20电子通信论文一种数字语音通信系统的DSP实现摘要:介绍了一种甚低频低码率数字通信系统的实现方案,该方案中的软件采用混合编程的方法,硬件则用DSP实现,文章给出了整个系统的DSP软硬件调试方法,并通过调试结果表明该方案具有很好的可行性和实时性。
关键词:软件无线电;DSP;混合编程1引言现代通信系统已不断由模拟体制向数字化体制过渡,并越来越倾向于采用“软件无线电”的设计方案。
即通过构造通用的硬件平台,以使各种相关的通信任务能够用软件完成,从而构成一个具有高度灵活性、开放性的通信系统。
现代的DSP通用处理器为实现这一方案提供了极大的便利。
软件无线电的设计思想是:用一个通用、标准、模块化的硬件平台为依托,然后通过软件编程来实现无线电台的各种功能,从而取代基于硬件、面向用途的电台设计方法。
功能的软件化实现势必要求减少功能单一、灵活性差的硬件电路,尤其是减少模拟环节,并把数字化处理?A/D、D/A?尽量靠近天线。
软件无线电强调体系结构的开放性和全面可编程性。
它通过软件的更新来改变硬件的配置结构,从而实现新的功能。
软件无线电一般采用标准的、高性能的开放式总线结构,此结构利于硬件模块地不断升级和扩展。
本文介绍一种利用TMS320C31浮点型DSP芯片为核心来设计并实现甚低频低码率数字化语音通信系统的方法。
这种通信系统是以DSP硬件为平台,并用硬件来实现系统的.外围功能,而用软件来实现核心部分的数字化处理,从而完成整个系统的正常通信工作。
2DSP硬件平台本通信系统的主要功能是实现语音的数字化传输,其系统功能图如图1所示。
具体工作过程如下:整个通信系统分为两大部分,其工作状态转换由外附的MCU控制。
在发送时,语音通过克麦风之后进入语音压缩板进行采样量化及数字化压缩,压缩后的比特流从串口送入DSP内进行调制,调制信号依次通过信道DAC、平滑滤波和功放,然后发送出去;在接收时,前置放大部分送来的信号再经过一次放大之后送往信道AD转换器,转换的数据FIFO通过中断方式送给DSP进行解调,在DSP内解调之后的数据仍然通过串口送往语音压缩板解压后经扬声器输出。