如何使用httpwatch自动分析网页数据
- 格式:doc
- 大小:28.00 KB
- 文档页数:3

1、httpwatch由“-”号或者“+”组合在一起的分组上图可以看到httpwatch分为几组,每一组代表加载一个页面相关的组件,一些不属于任何组的则表示该组建是独立的,不属于任何页面2、httpwatch各列的意义httpwatch的说明文档对个列中都有明确的定义Started:表示请求一个文件的时间开始的时间距离第一个捕捉到日志的时间,比如说上图中的第二组记录,Started为00:00:12.127,也就是说距离记录第一组开始时间为00:00:12.127 Time Chart:这里是个时间图,表示该http请求各个状态所花费的时间Time :表示请求一个链接所花费的总时间Sent:表示发送一个http请求所发送http 头的大小Received:表示接送http请求返回数据的大小Result:result表示Request返回的状态码,比如请求成功则为200,404未找到页面,302重定向,403不允许访问,304文件未被修改(该状态的请求不会下载组建,但是仍然会向服务器发一个请求,确认Last-Modify的时间没修改),Cache则从浏览器缓存中读取(不会向服务器发请求)Method:httpRequest请求的方式,一般是Get或者PostType:请求文件类型URL:请求文件的链接5.1.3、新建规则过滤IP:指定来源IP或者目标IP等于某个IP:例:ip.src eq 192.168.1.107 or ip.dst eq 202.102.192.68或者模糊书写:ip.addr eq 202.102.192.68将能显示出源和目的等于该IP的会话;过滤端口:例:tcp.port eq 80或者tcp.port==80不区分源或者目的端口只要数据包包含有80端口都将被过滤;tcp.port eq 80 or udp.port eq 80多条件匹配,匹配TCP或者UDP端口为80的数据包,不区分源或者目的端口;tcp.dst port==80显示目的端口为80的数据包; tcp.src port==80显示源端口为80的数据包;tcp.port>=1and tcp.port<=80过滤显示TCP端口大于等于1小于等于80范围内的数据包;过滤协议:例:在Filter(过滤)框内直接输入tcp、udp、arp、icmp、http、smtp、ftp、dns、msnms、ip、ssl、oicq、bootp、等等;可直接过滤协议。
一概述:HttpWatch强大的网页数据分析工具.集成在Internet Explorer工具栏.包括网页摘要.Cookies管理.缓存管理.消息头发送/接受.字符查询.POST 数据和目录管理功能.报告输出HttpWatch 是一款能够收集并显示页页深层信息的软件。
它不用代理服务器或一些复杂的网络监控工具,就能够在显示网页同时显示网页请求和回应的日志信息。
甚至可以显示浏览器缓存和IE之间的交换信息。
集成在Internet Explorer工具栏。
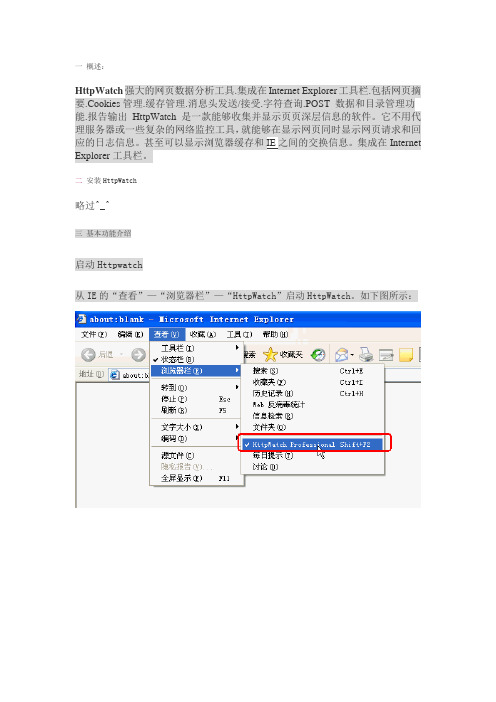
二安装HttpWatch略过^_^三基本功能介绍启动Httpwatch从IE的“查看”—“浏览器栏”—“HttpWatch”启动HttpWatch。
如下图所示:以下是HttpWatch程序界面以下用登录我的邮箱例子来展示Httpwatch:点击“Record”后,在IE打开需要录制的网址,,输入用户名,密码后完成登录操作1. 3.1 Overview(概要)表示选定某个信息显示其概要信息如上图红框所示:Result:200请求的URL是/external/closea_d.js,返回的Htpp状态代码结果200,表示成功;Resync URL Browser requested refresh if changed -/external/closea_d.js浏览器请求的URLStarted At 2008-Jan-04 09:21:09.422 (local time)请求开始时间(实际记录的是本机的时间)Connect Connect to IP address '218.107.55.86'请求的网址的IP地址Http Request Unconditional request sent for/external/closea_d.jsHttp请求,当浏览器向Web服务器发出请求时,它向服务器传递了一个数据块,也就是请求信息Http Response Headers and content returnedHttp响应,当浏览器接受到web服务器返回的信息时2. 3.2 Header(报头)表示从Web服务器发送和接受的报头信息;/a/p/main.htm?sid=UBDCcOJJDknBulMFzSJJipPzfR OMNqHO如上图红框所示:Http请求头发送信息Headers Sent valueRequest-Line GET /external/closea_d.js HTTP/1.1以上代码中“GET”代表请求方法,“closea_d.js”表示URI,“HTTP/1.1代表协议和协议的版本。


如何使用网站监控工具实时监测网站可用性和性能的教程和特点在当今数字化时代,网站已经成为企业和个人展示服务和产品的重要工具。
然而,网站的可用性和性能对确保用户体验至关重要。
为了及时了解网站运行情况并解决潜在的问题,使用网站监控工具是至关重要的。
本文将介绍如何使用网站监控工具来实时监测网站可用性和性能,并探讨其教程和特点。
一、什么是网站监控工具网站监控工具是一种软件或服务,用于监控和测量网站的可用性和性能。
它们定期检查网站是否可访问,并提供实时报告和警报,以便网站管理员能够及时采取行动。
这些工具不仅可以监测网站是否正常运行,还可以监测页面加载时间、响应时间和其他关键性能指标。
二、如何使用网站监控工具实时监测网站可用性和性能1. 选择合适的网站监控工具市场上有各种各样的网站监控工具可供选择,因此首先要根据自己的需求和预算选择适合的工具。
一些常用的网站监控工具包括Pingdom、UptimeRobot和Site24x7等。
2. 注册并设置监控一旦选择了合适的工具,就需要注册一个账户并设置要监控的网站。
通常,您需要提供您的网站URL、监控频率和其他相关信息。
此外,还可以设置警报方式,如电子邮件、短信或应用程序推送通知,以便及时获得网站异常的警报信息。
3. 监控网站可用性设置好监控后,工具将开始定期检查您的网站。
它们将模拟用户访问您的网站并检查是否能够正常加载和响应。
如果发现网站不可访问或响应时间过长,工具将发送警报通知您以便及时处理。
4. 监控网站性能除了监控可用性,网站监控工具还可以测量关键性能指标,如页面加载时间和响应时间。
这些指标能够帮助您了解网站的性能表现,并找出潜在的性能问题。
通过监控这些数据,您可以优化网站的速度和性能,提高用户体验。
5. 查看报告和分析数据网站监控工具通常提供详细的报告和分析数据,以帮助您更好地理解网站的运行情况。
您可以查看到达率、故障时间、响应时间等指标,并通过对数据进行分析来发现趋势和问题。

使用Python自动化网络数据抓取在当今数字化的时代,数据成为了一种极其宝贵的资源。
从市场分析、学术研究到日常的信息收集,我们常常需要从互联网上获取大量的数据。
手动收集这些数据不仅费时费力,而且效率低下。
这时候,使用 Python 进行自动化网络数据抓取就成为了一种非常有效的解决方案。
网络数据抓取,简单来说,就是通过程序自动从网页中提取我们需要的信息。
Python 拥有丰富的库和工具,使得这个过程变得相对简单和高效。
下面让我们逐步深入了解如何使用 Python 来实现这一目标。
首先,我们需要了解一些基本的概念和知识。
HTTP 协议是网络通信的基础,当我们在浏览器中输入一个网址时,浏览器实际上就是通过 HTTP 协议向服务器发送请求,并接收服务器返回的响应,其中包含了网页的 HTML 代码。
而我们的数据抓取就是基于这个过程。
在 Python 中,`requests`库是一个常用的用于发送 HTTP 请求的工具。
通过它,我们可以轻松地向指定的网址发送 GET 或 POST 请求,并获取响应的内容。
```pythonimport requestsresponse = requestsget('print(responsetext)```上述代码中,我们使用`requestsget()`方法向`https://`发送了一个 GET 请求,并将获取到的响应内容打印出来。
但这只是获取了整个网页的 HTML 代码,还不是我们最终需要的数据。
为了从 HTML 代码中提取出有用的数据,我们需要使用解析库,比如`BeautifulSoup` 。
```pythonfrom bs4 import BeautifulSouphtml_doc ="""<html><head><title>Example</title></head><body><p>Hello, World!</p><p>Another paragraph</p></body></html>"""soup = BeautifulSoup(html_doc, 'htmlparser')for p in soupfind_all('p'):print(ptext)```在上述代码中,我们首先创建了一个简单的 HTML 文档,然后使用`BeautifulSoup` 的`find_all()`方法找出所有的`<p>`标签,并打印出其中的文本内容。

1概述H ttpWatch强大的网页数据分析工具,集成在Internet Explorer工具栏,包括网页摘要、Cookies管理、缓存管理、消息头发送/接受、字符查询、POST 数据和目录管理功能、报告输出等功能。
H ttpWatch 是一款能够收集并显示页页深层信息的软件。
它不用代理服务器或一些复杂的网络监控工具,就能够在显示网页同时显示网页请求和回应的日志信息。
甚至可以显示浏览器缓存和IE之间的交换信息。
集成在Internet Explorer工具栏。
版本:HttpWatch Professional Edition2安装HttpWatch略过^_^3基本功能介绍启动Httpwatch从IE的“工具”—“HttpWatch Professional”启动HttpWatch(快捷键Shift+F2)。
如下图所示:以下是HttpWatch程序界面以下用登陆百度,搜索网页的例子来展示Httpwatch:HttpWatch点击“Record”后,在IE打开需要录制的网址, ,输入需要搜索的关键字后,点击“百度一下”,然后在点击HttpWatch的“Stop”后,录制的全部请求。
4菜单栏4.1Record(录制)点击“Record”按钮开始录制Http请求操作4.2Stop(停止)点击“Stop”按钮停止录制Http请求操作4.3Clear(清除)点击“Clear”按钮,清除所有录制HTTP请求log记录,如下图所示红框中内容:4.4View(视图)功能菜单说明Group by Page按照页面来分组Time Chart Column显示时间图表字段Select Columns...选择字段Summary汇总信息Properties属性信息Collapse All折叠全部Expand All展开全部Expand New Pages新页面展开Offset Timings时间偏移Local Time本地时间GMT/UTC格林尼治时间在页面中采用时间偏移Offset Timings withinPage4.5Summary(统计)点击“Summary”按钮,显示或隐藏所有请求信息汇总统计概述以下用httpwatch工具记录打开过程,Summary信息如下:4.5.1Network网络信息汇总,可以对选中的页面进行汇总,也可以对全部的请求进行汇总。
10.6 httpwatch 、wireshark等抓包工具应用
1) HTTPWATCH 抓包过程
这个软件适用于网页无法打开,视频网站观看视频卡,网页游戏卡、无法打开等网页类的问题。
首先,打开IE在工具兰中点击httpwatch打开软件。
打开软件后在网页下方会生成一个新的窗口。
按红色record按钮,开始抓包,抓包开始后打开要抓包的网页。
抓包开始后,在地址栏输入要抓包的网站网址,待网站完全打开后抓包完成。
视频抓包在视频播放几分钟后可以完成抓包。
点击“stop”完成抓包。
点击“save”,保存抓包结果
6.2 Wireshark抓包过程
wireshark是非常流行的网络封包分析软件,功能十分强大。
可以截取各种网络封包,显示网络封包的详细信息。
使用wireshark进行网络分析的人须了解网络协议,否则就看不懂wireshark了。
为了安全考虑,wireshark只能查看封包,而不能修改封包的内容,或者发送封包。
wireshark 启动界面如下:
Wireshark软件抓包:适用于无法正常连接网络的客户端类软件抓包,主要抓取经过网卡的数据包。
wireshark是捕获机器上的某一块网卡的网络包,当你的机器上有多块网卡的时候,你需要选择一个网卡。
软件打开后的界面是这样的,单击接口列表或左上角快捷按钮,选择网卡后开始抓包。
然后点击"开始"按钮, 开始抓包。
在软件开始抓包3-5分钟后可按“停止”按钮进行停止。
停止后单击“保存”按钮将抓包结果保存,抓包结束。
HTTP协议头部与Keep-Alive模式详解/home-space-uid-42237-do-blog-id-234552.html1、什么是Keep-Alive模式?我们知道HTTP协议采用“请求-应答”模式,当使用普通模式,即非KeepAlive模式时,每个请求/应答客户和服务器都要新建一个连接,完成之后立即断开连接(HTTP协议为无连接的协议);当使用Keep-Alive模式(又称持久连接、连接重用)时,Keep-Alive功能使客户端到服务器端的连接持续有效,当出现对服务器的后继请求时,Keep-Alive功能避免了建立或者重新建立连接。
http 1.0中默认是关闭的,需要在http头加入"Connection: Keep-Alive",才能启用Keep-Alive;http 1.1中默认启用Keep-Alive,如果加入"Connection: close ",才关闭。
目前大部分浏览器都是用http1.1协议,也就是说默认都会发起Keep-Alive的连接请求了,所以是否能完成一个完整的Keep- Alive连接就看服务器设置情况。
2、启用Keep-Alive的优点从上面的分析来看,启用Keep-Alive模式肯定更高效,性能更高。
因为避免了建立/释放连接的开销。
下面是RFC 2616上的总结:1.1.By opening and closing fewer TCP connections, CPU time is saved inrouters and hosts (clients, servers, proxies, gateways, tunnels, orcaches), and memory used for TCP protocol control blocks can besaved in hosts.2.HTTP requests and responses can be pipelined on a connection.Pipelining allows a client to make multiple requests without waitingfor each response, allowing a single TCP connection to be used muchmore efficiently, with much lower elapsed time.work congestion is reduced by reducing the number of packetscaused by TCP opens, and by allowing TCP sufficient time todetermine the congestion state of the network.tency on subsequent requests is reduced since there is no timespent in TCP's connection opening handshake.5.HTTP can evolve more gracefully, since errors can be reported withoutthe penalty of closing the TCP connection. Clients using futureversions of HTTP might optimistically try a new feature, but ifcommunicating with an older server, retry with old semantics afteran error is reported.RFC 2616(P47)还指出:单用户客户端与任何服务器或代理之间的连接数不应该超过2个。
测试内容:1、点击对话观察对话窗口加载的速度。
大概花费时长多少。
2、有掉消息的情况是否频繁。
最好有截图。
3、HttpWatch操作。
如下“关于HttpWatch”。
*4、有可能的话观察一下所有客服的360测量分析。
*5、在“开始”“运行”中输入“cmd”回车后,在黑窗口输入“tracert”回车。
如果第一行就是“Request time out”(就不用做后面的截图了。
)显示“complete”就可以把黑窗口截图下来。
-------------------------------------------------关于HttpWatch安装:1、将软件解压出来双击“httpwatchpro.exe”2、 License文件就是这个“httpwatch.lic”3、然后一路next就OK了,(除了安装路径可以改外不要改动其他选项。
)测试网站:1、打开IE(没有任何页面打开的情况)按shift+F2,屏幕下方出现httpwatch的主界面。
2、在打开主界面后点击“Record”,然后在IE地址栏输入网站,等到IE加载完成后20秒点击“stop”,再点击“Save”。
(这个.hwl文件需要发送给我们。
)测试对话:1、现在在刚才的页面点击对话,等对话窗口加载完成后。
把对话窗口的地址复制下来,然后把IE的缓存清除关闭浏览器。
2、打开IE按shift+F2再调出HttWatch的主界面,再点击“Record后把刚才的对话地址粘贴到地址栏中回车。
3、等待加载“完成”后20秒点击“stop”再点击“save”。
(这个.hwl文件同样需要发送给我们。
)。
众所周知,HttpWatch是强大的网页数据分析工具,通过httpwatch,我们很方便得抓取到http请求,统计出网页的加载时间等信息。
通过人工来观察比较费时费力,那么如何通过自动方式来获取这些信息并自动分析呢?通过httpwatch帮助文档可以看到,它提供了一些接口可以进行调用,支持的语言有C#, Javascript和Ruby,并且给出了example。
经过研究发现,使用Python语言也可以调用提供的接口,下面我就介绍一下怎么使用Python
语言来调用这些接口。
其实很简单,首先需要安装pywin32,安装完之后,参考帮助文档(帮助文档在安装目录有,里面列出了所有接口),下面根据帮助文档写出示例程序(程序在Python2.7、httpwatch6.0下调试通过):
# -*- coding: cp936 -*-
import win32com.client
# Create a new instance of HttpWatch in IE
control = win32com.client.Dispatch('HttpWatch.Controller')
# Open the IE browser
plugin = control.IE.New()
# Start Recording HTTP traffic
plugin.Log.EnableFilter(False)
plugin.Record()
# Goto to the URL and wait for the page to be loaded
plugin.GotoURL("")
# This method waits for a page to be fully loaded in the IE instance containing the specifiedpluginand is normally used after the GotoURL method.
control.Wait(plugin, -1)
# Stop recording HTTP
plugin.Stop()
Entries = plugin.Log.Pages.Item(0).Entries
summary = Entries.summary
# Get Response Header and print it
responsecount = Entries.Item(0).Response.Headers.Count print"Response Header: "
for i in range(responsecount):
print Entries.Item(0).Response.Headers.Item(i).Name +':',
print Entries.Item(0).Response.Headers.Item(i).Value
# Get Performance and print it
if plugin.Log.Pages.Count !=0:
print"Page Title: ",plugin.Log.Pages(0).Title
print"DNS Lookups (ms): ", summary.DNSLookUps
print"Total time to load page (secs):", summary.Time
print"DownloadedData:", summary.BytesReceived
print"HTTP compression savings(bytes):",
pressionSavedBytes
print"Number of round trips: ", summary.RoundTrips
print"Number of errors: ", summary.Errors.Count。