多元统计分析对应分析
- 格式:doc
- 大小:302.50 KB
- 文档页数:8

多元统计分析——对应分析多元统计分析是指在研究中同时考虑两个或多个自变量对因变量的影响,并通过统计方法进行分析。
对应分析是多元统计分析的一种方法,用于确定两个或多个分类变量之间的关联性。
对应分析可以帮助人们理解变量之间的相关性,并提供用于可视化和解释数据的工具。
在本文中,我们将详细介绍对应分析的概念、原理、应用以及一些重要的注意事项。
对应分析的应用非常广泛。
它可以用于数据挖掘、市场研究、生态学、社会科学等领域。
在市场研究中,对应分析可以用于确定消费者对产品的喜好和需求,帮助企业调整产品定位和市场战略。
在生态学中,对应分析可以用于研究不同物种之间的相互作用,并帮助我们了解生态系统的结构和动态。
在社会科学中,对应分析可以用于研究不同社会群体之间的关系,例如分析不同年龄段人群的消费行为和购买偏好。
然而,对应分析也需要注意一些重要的事项。
首先,对应分析是一种描述性的分析方法,不能确定因果关系。
其次,对应分析对数据的分布假设了一定的要求,例如对称分布、线性关系等。
如果数据的分布不满足这些假设,结果可能会不准确。
最后,对应分析通常在两个分类变量之间进行,而不适用于连续变量或混合类型的变量。
在总结中,对应分析是多元统计分析的一种方法,用于确定两个或多个分类变量之间的关联性。
它可以帮助我们理解变量之间的相关性,并提供用于可视化和解释数据的工具。
对应分析有着广泛的应用领域,但也需要注意一些重要的事项。
通过理解对应分析的原理和应用,我们可以更好地利用这一方法来分析和解释数据。



对应分析方法与对应图解读方法——七种分析角度对应分析是一种多元统计分析技术,主要分析定性数据Category Data方法,也是强有力的数据图示化技术,当然也是强有力的市场研究分析技术。
这里主要介绍大家了解对应分析的基本方法,如何帮助探索数据,分析列联表和卡方的独立性检验,如何解释对应图,当然大家也可以看到如何用SPSS操作对应分析和对数据格式的要求!对应分析是一种数据分析技术,它能够帮助我们研究由定性变量构成的交互汇总表来揭示变量间的联系。
交互表的信息以图形的方式展示。
主要适用于有多个类别的定类变量,可以揭示同一个变量的各个类别之间的差异,以及不同变量各个类别之间的对应关系。
适用于两个或多个定类变量。
主要应用领域:概念发展(Concept Development)新产品开发 (New Product Development)市场细分 (Market Segmentation)竞争分析 (Competitive Analysis)广告研究 (Advertisement Research)主要回答以下问题:谁是我的用户?还有谁是我的用户?谁是我竞争对手的用户?相对于我的竞争对手的产品,我的产品的定位如何?与竞争对手有何差异?我还应该开发哪些新产品?对于我的新产品,我应该将目标指向哪些消费者?数据的格式要求对应分析数据的典型格式是列联表或交叉频数表。
常表示不同背景的消费者对若干产品或产品的属性的选择频率。
背景变量或属性变量可以并列使用或单独使用。
两个变量间——简单对应分析。
多个变量间——多元对应分析。
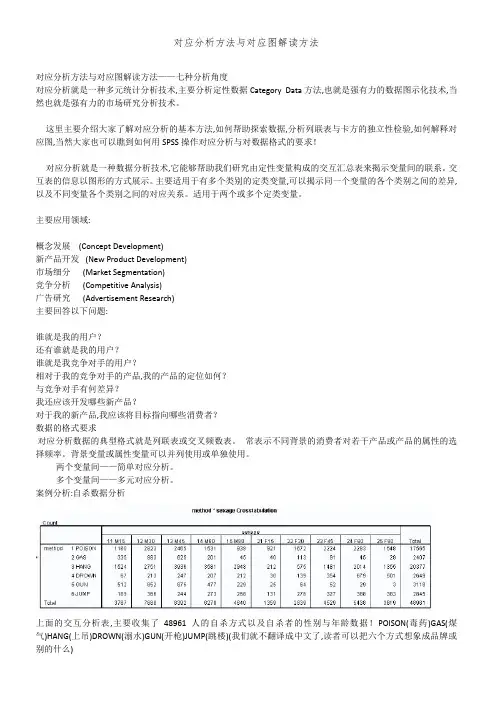
案例分析:自杀数据分析上面的交互分析表,主要收集了48961人的自杀方式以及自杀者的性别和年龄数据!POISON(毒药)GAS(煤气)HANG(上吊)DROWN(溺水)GUN(开枪)JUMP(跳楼)(我们就不翻译成中文了,读者可以把六个方式想象成品牌或别的什么)当然,我们拿到的最初原始数据可能是SPSS数据格式记录表,其中,性别取值1-male 2-female,年龄取值1-5,分别表示不同年龄段。


一、什么是多元统计分析❖多元统计分析是运用数理统计的方法来研究多变量(多指标)问题的理论和方法,是一元统计学的推广。
❖多元统计分析是研究多个随机变量之间相互依赖关系以及内在统计规律的一门统计学科。
二、多元统计分析的内容和方法❖1、简化数据结构(降维问题)将具有错综复杂关系的多个变量综合成数量较少且互不相关的变量,使研究问题得到简化但损失的信息又不太多。
(1)主成分分析(2)因子分析(3)对应分析等❖2、分类与判别(归类问题)对所考察的变量按相似程度进行分类。
(1)聚类分析:根据分析样本的各研究变量,将性质相似的样本归为一类的方法。
(2)判别分析:判别样本应属何种类型的统计方法。
例5:根据信息基础设施的发展状况,对世界20个国家和地区进行分类。
考察指标有6个:1、X1:每千居民拥有固定电话数目2、X2:每千人拥有移动电话数目3、X3:高峰时期每三分钟国际电话的成本4、X4:每千人拥有电脑的数目5、X5:每千人中电脑使用率6、X6:每千人中开通互联网的人数❖3、变量间的相互联系一是:分析一个或几个变量的变化是否依赖另一些变量的变化。
(回归分析)二是:两组变量间的相互关系(典型相关分析)❖4、多元数据的统计推断点估计参数估计区间估计统 u检验计参数 t检验推 F检验断假设相关与回归检验卡方检验非参秩和检验秩相关检验❖1、假设检验的基本原理小概率事件原理❖ 小概率思想是指小概率事件(P<0.01或P<0.05等)在一次试验中基本上不会发生。
反证法思想是先提出假设(检验假设H0),再用适当的统计方法确定假设成立的可能性大小,如可能性小,则认为假设不成立;反之,则认为假设成立。
❖ 2、假设检验的步骤 (1)提出一个原假设和备择假设❖ 例如:要对妇女的平均身高进行检验,可以先假设妇女身高的均值等于 160 cm (u=160cm )。
这种原假设也称为零假设( null hypothesis ),记为 H 0 。

对应分析方法与对应图解读方法——七种分析角度对应分析就是一种多元统计分析技术,主要分析定性数据Category Data方法,也就是强有力的数据图示化技术,当然也就是强有力的市场研究分析技术。
这里主要介绍大家了解对应分析的基本方法,如何帮助探索数据,分析列联表与卡方的独立性检验,如何解释对应图,当然大家也可以瞧到如何用SPSS操作对应分析与对数据格式的要求!对应分析就是一种数据分析技术,它能够帮助我们研究由定性变量构成的交互汇总表来揭示变量间的联系。
交互表的信息以图形的方式展示。
主要适用于有多个类别的定类变量,可以揭示同一个变量的各个类别之间的差异,以及不同变量各个类别之间的对应关系。
适用于两个或多个定类变量。
主要应用领域:概念发展(Concept Development)新产品开发(New Product Development)市场细分(Market Segmentation)竞争分析(Competitive Analysis)广告研究(Advertisement Research)主要回答以下问题:谁就是我的用户?还有谁就是我的用户?谁就是我竞争对手的用户?相对于我的竞争对手的产品,我的产品的定位如何?与竞争对手有何差异?我还应该开发哪些新产品?对于我的新产品,我应该将目标指向哪些消费者?数据的格式要求对应分析数据的典型格式就是列联表或交叉频数表。
常表示不同背景的消费者对若干产品或产品的属性的选择频率。
背景变量或属性变量可以并列使用或单独使用。
两个变量间——简单对应分析。
多个变量间——多元对应分析。
案例分析:自杀数据分析上面的交互分析表,主要收集了48961人的自杀方式以及自杀者的性别与年龄数据!POISON(毒药)GAS(煤气)HANG(上吊)DROWN(溺水)GUN(开枪)JUMP(跳楼)(我们就不翻译成中文了,读者可以把六个方式想象成品牌或别的什么)当然,我们拿到的最初原始数据可能就是SPSS数据格式记录表,其中,性别取值1-male 2-female,年龄取值1-5,分别表示不同年龄段。


对应分析法一、简介对应分析(Correspondence analysis)也称关联分析、R-Q型因子分析,是近年新发展起来的一种多元相依变量统计分析技术,是一种多元统计分析技术,主要分析定性数据的方法,也是强有力的数据图示化技术。
对应分析是一种数据分析技术,它能够帮助我们研究由定性变量构成的交互汇总表来揭示变量间的联系。
交互表的信息以图形的方式展示。
主要适用于有多个类别的定类变量,可以揭示同一个变量的各个类别之间的差异,以及不同变量各个类别之间的对应关系,适用于两个或多个定类变量。
对应分析是由法国人Benzenci于1970年提出的,起初在法国和日本最为流行,然后引入到美国。
对应分析法是在R型和Q型因子分析的基础上发展起来的一种多元统计分析方法,因此对应分析又称为R-Q型因子分析。
在因子分析中,如果研究的对象是样品,则需采用Q型因子分析;如果研究的对象是变量,则需采用R型因子分析。
但是,这两种分析方法往往是相互对立的,必须分别对样品和变量进行处理。
因此,因子分析对于分析样品的属性和样品之间的内在联系,就比较困难,因为样品的属性是变值,而样品却是固定的。
于是就产生了对应分析法。
对应分析就克服了上述缺点,它综合了R型和Q型因子分析的优点,并将它们统一起来使得由R型的分析结果很容易得到Q型的分析结果,这就克服了Q 型分析计算量大的困难;更重要的是可以把变量和样品的载荷反映在相同的公因子轴上,这样就把变量和样品联系起来便于解释和推断。
对应分析数据的典型格式是列联表或交叉频数表。
常表示不同背景的消费者对若干产品或产品的属性的选择频率。
背景变量或属性变量可以并列使用或单独使用。
两个变量间——简单对应分析;多个变量间——多元对应分析。
对应分析的基本思想是将一个联列表的行和列中各元素的比例结构以点的形式在较低维的空间中表示出来。
它最大特点是能把众多的样品和众多的变量同时作到同一张图解上,将样品的大类及其属性在图上直观而又明了地表示出来,具有直观性。

应用多元统计分析第8章 对应分析- 1-对应分析(Correspondence Analysis)是在因子分析的基础上发展起来的一种视觉化的数据分析方法,目的是通过定位点图直观地揭示样品和变量之间的内在联系。
R型因子分析是对变量(指标)进行因子分析,研究的是变量之间的相互关系;Q型因子分析是对样品作因子分析,研究的是样品之间的相互关系。
但无论是R型或Q型分析都不能很好地揭示变量和样品之间的双重关系。
而在许多领域错综复杂的多维数据分析中,经常需要同时考虑三种关系,即变量之间的关系、样品之间的关系以及变量与样品之间的交互关系。
法国学者苯参次(J.P.Benzecri)于1970年提出了对应分析方法,这个方法对原始数据采用适当的标度化处理,把R型和Q型分析结合起来,通过R型因子分析直接得到Q型因子分析的结果,同时把变量和样品反映到同一因子平面上,从而揭示所研究的样品和变量之间的内在联系。
在因子分析中,R型因子分析和Q型因子分析都是从分析观测数据矩阵出发的,它们是反映一个整体的不同侧面,因而它们之间一定存在内在联系。
对应分析就是通过某种特定的标准化变换后得到的对应变换矩阵Z将两者有机地结合起来。
具体地,就是首先给出变量的R型因子分析的协方差阵 和样品的Q型因子分析的协方差阵 。
由于矩阵 和 有相同的非零特征值,记为 ,如果 的对应于特征值 的标准化特征向量为 ,则容易证明, 的对应于同一特征值的标准化特征向量为当样本容量n很大时,直接计算矩阵 的特征向量会占用相当大的容量,也会大大降低计算速度。
利用上面关系式,很容易从 的特征向量得到 的特征向量。
并且由 的特征值和特征向量即可得到R 型因子分析的因子载荷阵A和Q型因子分析的因子载荷阵B,即有由于 和 具有相同的非零特征值,而这些特征值又是各个公因子的方差,因此设有p个变量的n个样品观测矩阵 ,这里要求所有元素 ,否则对所有数据同时加上一个适当的正数,以使它们满足以上要求。
多元统计分析实验报告表2-2 对应分析数据(老龄化数据)三、实验过程在spss16.0软件中,对表2-2数据做对应分析。
首先应对个案进行加权操作。
选择【Date】—【Weight Cases】,出现表3对话框。
选择frequency作为加权,如图3-1所示。
图3-1 加权个案对个案加权后,开始做对应分析。
选择【Analyze】—【Date Reduction】—【Corespondence Analysis】,会出现图3-2对话画框。
图3-2 对应分析对话框接下来对行变量和列变量进行设置。
将selfassess(自评健康状况)选入Row,作为行变量,并选择【Define Range】,填写范围后点击【Update】—【Continue】,如图3-3所示;按同样的步骤,将independence(生活自理能力)选入Column(列变量),并设置列变量,如图3-4所示;最终设置结果如图3-5所示。
图3-3 行变量设置图3-4 列变量设置图3-5 对应分析设置结果点击【OK】,便可得到对应分析结果。
四、实验过程表4-1为对应分析的版本信息。
图中显示为1.1版本。
表4-1 对应分析版本信息表4-2是列联表,列示了在各个水平下的人数。
表4-2 列联表表4-3为对应分析总述表。
表中显示了奇异值(Singular Value),第一个维度的奇异值为0.253,第二个维度的奇异值为0.125;惯量(Inertia)为特征根,就是奇异值的平方;Chi Square 值为212.593,是总样本数除以总的Inertia 觉原假设,认为两个随机变量不是相互独立的,本例中就是自评健康状况和生活自理能力不是相互独立的;贡献率(Accounted for)显示,第一个维度解释了总变异的80.4%,第二个维度解释了19.6%,两个维度解释了所有的变异;接下来依次为累计贡献率(Cumulative)、奇异值的方差(Standard Deviation)、奇异值的相关系数(Correlation)。
1. 目的不同:因子分析把诸多变量看成由对每一个变量都有作用的一些公共因子和仅对某一个变量有作用的特殊因子线性组合而成,因此就是要从数据中控查出对变量起解释作用的公共因子和特殊因子以及其组合系数;主成分分析只是从空间生成的角度寻找能解释诸多变量变异的绝大部分的几组彼此不相关的新变量(主成分)。
2. 线性表示方向不同:因子分析是把变量表示成各公因子的线性组合;而主成分分析中则是把主成分表示成各变量的线性组合。
3. 假设条件不同:主成分分析中不需要有假设;因子分析的假设包括:各个公共因子之间不相关,特殊因子之间不相关,公共因子和特殊因子之间不相关。
4. 提取主因子的方法不同:因子分析抽取主因子不仅有主成分法,还有极大似然法,主轴因子法,基于这些方法得到的结果也不同;主成分只能用主成分法抽取。
5. 主成分与因子的变化:当给定的协方差矩阵或者相关矩阵的特征值唯一时,主成分一般是固定的;而因子分析中因子不是固定的,可以旋转得到不同的因子。
6. 因子数量与主成分的数量:在因子分析中,因子个数需要分析者指定(SPSS根据一定的条件自动设定,只要是特征值大于1的因子主可进入分析),指定的因子数量不同而结果也不同;在主成分分析中,成分的数量是一定的,一般有几个变量就有几个主成分(只是主成分所解释的信息量不等)。
7. 功能:和主成分分析相比,由于因子分析可以使用旋转技术帮助解释因子,在解释方面更加有优势;而如果想把现有的变量变成少数几个新的变量(新的变量几乎带有原来所有变量的信息)来进入后续的分析,则可以使用主成分分析。
当然,这种情况也可以使用因子得分做到,所以这种区分不是绝对的。
1 、聚类分析基本原理:将个体(样品)或者对象(变量)按相似程度(距离远近)划分类别,使得同一类中的元素之间的相似性比其他类的元素的相似性更强。
目的在于使类间元素的同质性最大化和类与类间元素的异质性最大化。
常用聚类方法:系统聚类法,K-均值法,模糊聚类法,有序样品的聚类,分解法,加入法。
学生实验报告
学院:统计学院
课程名称:多元统计分析
专业班级:统计123班
姓名:叶常青
学号: 0124253
学生实验报告
一、实验目的及要求:
目的熟悉和掌握对应分析的原理和上机操作方法
内容及要求本次操作就父母与孩子的受教育程度的关系进行对应分析,分别对父亲与孩子和母亲与孩子的受教育程度做对应分析,最后再对输出结果进行详细的分析。
三、实验方法与步骤:
打开GSS93 subset .sav数据,对变量Degree与变量padeg和madeg进行对应分析,依次选择分析→降维…进入对应分析对话框,进行进行如下设置,便可输出想要的数据的:
四、实验结果与数据处理:
按照上述方法和步骤得出以下输出结果.
对父亲受教育程度与孩子受教育程度的关系进行分析如下:
表2
,
第二部分摘要给出了惯量,卡方值以及每一维度所解释的总惯量的百分比信息。
总惯量为0.189,卡方值为228.193 ,有关系式228.193=0.189*1205,由此可以清楚的看到总惯量和卡方的关系。
Sig.是假设卡方值为0成立的概率,它的值几乎为0说明列联表之间有较强的相关性。
表注表明的自由度为(5-1)*(5-1)=16。
惯量部分是四个公共因子分别解释总惯量的百
分比。
表4
第三部分的结果是在对应分析中点击Statistics按钮,进入Statistics对话框,选中Row profiles和Column profiles 交友程序运行所得到的。
表6
第四部分是概述行点和概述列点,是对列联表行与列各状态有关信息的概括. 其中质量是行与列的边缘概率,也就是PI 与PJ 。
惯量是每一行(列)与其重心的加权距离平方,可以看到II=IJ=0.189。
由概述行点表可知变量degree 的状态Less than HS 和Bachelor 在第一维度中贡献较大分别为0.399和0.406。
状态Less than HS 对第二维度贡献最大为0.416。
概述列表可知变量padeg 的状态LT High School 在第一维度贡献最大为0.432。
状态High School 对第二维度贡献最大为0.559。
第五部分是degree 各状态和paged 各状态同时在一张二维表上的投影. 由图可以看到父亲初中的教育程度、高中的教育程度与孩子的教育程度有较强的关联性。
表1
LT High School 169 286 25 37 23 540 High School 40 374 41 133 56 644 Junior College 2 13 6 15 5 41
Bachelor 3 33 11 34 15 96
Graduate 2 8 1 10 8 29
有效边际216 714 84 229 107 1350 第一部分是对应表,对应表是由原始数据按degree与padeg分类的列连表,可以看到总有效观测值为1350,而不是原始数据1500。
说明有效的观测数据有1350个,这是因为原始数据中有150个数据缺失。
第二部分是摘要表。
第二部分摘要给出了惯量,卡方值以及每一维度所解释的总惯量的百分比信息。
总惯量为0.189,卡方值为228.193 ,有关系式228.193=0.189*1205,由此可以清楚的看到总惯量和卡方的关系。
Sig.是假设卡方值为0成立的概率,它的值几乎为0说明列联表之间有较强的相关性。
表注表明的自由度为(5-1)*(5-1)=16。
惯量部分是四个公共因子分别解释总惯量的百分比。
.
第三部分是概述行点和概述列点,是对列联表行与列各状态有关信息的概括.由贡献部分可以看出 LT High School这一状态对第一维度的贡献最大.在表的最后维度部分对各状态特征值的贡献部分,看到除了Graduate外,其余各最高学历的特征值的分布大部分集中在第一维度上,说明第一维度反映了最高学历各状态大部分的差异.
把母亲受教育程度和子女受教育程度的各状态投影到同一张二维图上,如上图所示。
由图可以看到母亲受高中的教育程度和子女受初中,高中的教育程度有较强的关联性。
五、讨论与结论
通过对应分析可以大致了解父母亲受教育程度与孩子受教育程度的关系,并且实现了对应分析理论知识与实际操作的结合,此次试验的难点在于对输出数据的具体分析思维。
由以上所有分析我们可以大胆推断子女受教育程度与父母双方受教育程度有着密切的联系,父母受教育
程度很大的限制着子女的受教育水平。