SPSS学习笔记之——协方差分析
- 格式:docx
- 大小:881.60 KB
- 文档页数:13

作业15:协方差分析data1502-score:研究3中教学方法(method)的效果差异,即最后成绩(final)的差异,把33个学生随机分为3组接受不同的教学方法,需要控制他们开始的学习成绩(beginning)。
分析3种教学方法的最后成绩有无差异?如果有差异,具体怎么差异的?控制他们开始的学习成绩(beginning),接受不同的教学方法的成绩差异;分析过程;方法一:结果输出:控制协变量后,组间SS=1782.747, 组间df=k-1=2,组内SS=3108.226,组内df=nk-k-1=29,F=8.137,只需看自变量或因素变量的F检验,说明控制初始重量后的增重在各饲料之间有差异(F=8.137, p=0.001)。
方法二:用协方差进行分析,分析过程;因变量increased中总SS=5139.515,被协变量解释的SS=248.542,那么未被解释的SS=4890.973,即协方差分析中因变量的总SS,事实上就是协方差分析表中组内SS 和组间SS之和:1 782.747+3108.226=4890.973。
包括了上次回归分析的残差RES_1:再计算因变量不考虑协变量影响是的组内SS,分析过程;结果输出:不考虑协变量影响时,因变量组内SS=3377,这时原文件中包括了本次方差分析时的残差RES_2:再计算剔除协变量的影响的因变量组内SS,分析过程;这时原文件中,包括了本次方差分析时的残差RES_3:再对RES_2和RES_3进行回归分析:结果输出:不考虑协变量影响的因变量组内SS=3377,被协变量解释的组内SS=269,未被协变量解释的组内SS=3108,到此可以得出:剔除协变量影响的因变量总SS=4890.973,剔除协变量影响的因变量组内SS=3108,剔除协变量影响的因变量组间SS=4890.973-3108=1782.747。
残差回归分析R ES_2=α+β̂∗R ES_3的估计系数-0.259,其中β̂的t检验跟上表中的F 检验一致,sig=0.112。

协方差分析当X为定类数据,Y为定量数据时,通常使用的是方差分析进行差异研究。
比如性别对于身高的差异。
X的个数为一个时,称之为单因素方差(很多时候也称方差分析);X为2个时则为双因素方差;X为3个时则称作三因素方差,依次下去。
当X超过1个时,统称为多因素方差,很多时候也统称为方差分析。
如果在方差分析过程中,会有干扰因素;比如“减肥方式”对于“减肥效果”的影响,年龄很可能是影响因素;同样的减肥方式,但不同年龄的群体,减肥效果却不一样;年龄就属于干扰项,因此在分析的时候需要把它纳入到考虑范畴中。
如果方差分析时需要考虑干扰项,此时就称之为协方差分析,而干扰项也称着“协变量”。
通常情况下,协变量是定量数据,比如本例中的年龄,协变量的个数不定,但一般情况下会很少,比如为1个,2个;原因在于协变量并非核心研究项,只是可能干扰到模型所以放到模型中;如果放入过多的协变量,反而会出现‘主次不分’,因此在进行协方差分析时,需要相对谨慎的放入干扰项(即协变量)。
在实验研究中,比如研究者测试某新药对于胆固醇水平是否有疗效;研究者共招募72名被试,分为A和B共两组,每组分别是36名,A组使用新药,B组使用普通药物;在实验前先测试72名被试的胆固醇水平,以及在实验3月之后再次测定胆固醇水平。
为测试新药是否有帮助,因此使用方差分析对比两组被试在3月后胆固醇水平的差异性;如果有差异具体差异是什么,通过差异去研究新药是否有帮助;在这里出现一个干扰项即实验前的胆固醇水平(实验前胆固醇水平肯定会影响实验后的胆固醇水平),因此需要将实验前的胆固醇水平纳入模型中,因此此处需要进行协方差分析。
特别提示:对于协方差分析,X是定类数据,Y是定量数据;协变量为定量数据;如果协变量是定类数据,可考虑将其纳入X即自变量中,也或者将协变量作虚拟变量处理;协变量为干扰项,但并非核心研究项;因此通常情况下只需要将其纳入模型中即可,并不需要过多的分析;协方差分析有一个重要的假设即“平行性检验”,如果交互项(即有*号项)的P值>0.05则说明平行,满足“平行性检验”,可进行分析。

SPSS 协方差分析的基本原理协方差分析是一种用于分析两个或两个以上变量之间关系的统计分析方法。
在SPSS 中,协方差分析用于评估变量之间的相关性以及它们如何随着时间或处理方式的变化而变化。
本文将介绍 SPSS 中协方差分析的基本原理及如何使用 SPSS 进行协方差分析。
协方差分析的基本概念协方差是用于测量两个变量之间线性关系的统计量。
如果两个变量存在正相关性,则它们的协方差将是正数;如果它们存在负相关性,则协方差将是负数;如果它们之间没有相关性,则协方差将是0。
协方差的计算公式如下:Cov(X, Y) = E[(X-E(X))(Y-E(Y))]其中,E(X) 和 E(Y) 分别是变量 X 和 Y 的期望值。
在 SPSS 中,我们可以使用协方差矩阵来查看多个变量之间的协方差。
协方差矩阵是一个 n x n 的矩阵,其中每一个元素是两个变量之间的协方差。
SPSS 中的协方差分析在 SPSS 中,使用协方差分析需要满足以下两个基本条件:1.至少有两个变量。
2.变量之间存在相关性。
首先,我们需要通过数据-选择数据进行数据输入。
然后,在分析-相关-协方差中,我们可以选择要分析的变量。
选择变量后,需要设置参数,如显示形式、统计量以及分析结果。
在选择协方差分析后,SPSS 会生成一个结果表格。
该表格包括了相关性系数、协方差和标准偏差等统计信息。
我们还可以使用 Scatterplot Matrix 查看多个变量之间关系的图像。
该图像显示了变量之间的散点图和相关性系数。
协方差分析是一种简单而有效的统计方法,用于分析多个变量之间的关系。
在SPSS 中,我们可以轻松地进行协方差分析,并获得有关变量之间相关性的详细信息。
本文介绍了协方差分析的基本原理和 SPSS 中的使用方法,希望本文能够帮助您更好地理解协方差分析的概念和应用。

⼿把⼿教你协⽅差分析的SPSS操作!⼀、问题与数据某研究将73例脑卒中患者随机分为现代理疗组(38例)和传统康复疗法组(35例)进⾏康复治疗,采⽤Fugl-Meyer运动功能评分法(FMA)分别记录治疗前、后的运动功能情况,部分数据如下。
试问现代理疗和传统康复治疗对脑卒中患者运动功能的改善是否有差异?⼆、对数据结构的分析整个数据资料涉及2组患者(共73例),每名患者有康复治疗前、后2个数据,测量指标为FMA 评分。
由于治疗前的FMA分数会对治疗后的FMA分数产⽣影响,因此在⽐较现代理疗和传统康复疗法对患者运动功能的改善情况时,应把治疗前的FMA评分作为协变量进⾏调整,若满⾜协⽅差分析的应⽤条件,可采⽤完全随机设计的协⽅差分析。
协⽅差分析可以控制混杂因素对处理效应的影响,提⾼假设检验的效能和分析结果的精度。
其应⽤条件包括:受试对象的观测指标满⾜独⽴性,各处理组的观测指标均来⾃正态分布总体,且⽅差相等。
需要控制的协变量(⾃变量)与观测指标(因变量)之间存在线性关系,且每个组⽤协变量(⾃变量)与观测指标(因变量)进⾏直线回归时,回归直线的斜率相同(即各组回归直线平⾏)。
协⽅差分析相关的假设检验1. 各组回归直线是否平⾏的假设检验;2. 各组观测指标⽅差是否相同的假设检验;3. 协变量(⾃变量)与观测指标(因变量)之间是否存在线性关系的假设检验;4. 控制协变量的影响后,各组调整的均数是否相等的假设检验。
三、SPSS分析⽅法1、数据录⼊SPSS(组别1=现代理疗组,组别2=传统康复疗法组,FMA1=治疗前FMA评分,FMA2=治疗后FMA 评分)2、选择Analyze→General Linear Model→Univariate3、选项设置A. 主对话框设置:选择观测指标(FMA2)到Dependent Variable窗⼝,组别变量到Fixed Factor(s)窗⼝,协变量(FMA1)到Covariate(s)窗⼝。
![6.5.3 协方差分析的应用举例_例说SPSS统计分析_[共5页]](https://uimg.taocdn.com/d8b08cde581b6bd97e19ea37.webp)
146 例说
SPSS 统计分析 6.5 协方差分析
6.5.1 协方差分析的基本原理
方差分析时,除了要分析的因素变量外,其他的因素条件都要求一致或者尽可能地保持不变,然而实际中这一点非常难控制。
例如,考虑药物对患者某个生化指标变化的影响,比较实验组与对照组的该指标变化均值是否有显著性差异,以确定药物的有效性;但现实中,患者病程的长短、年龄以及原指标水平等混杂因素对疗效都有影响。
在有这些混杂因素的情况下处理因素对指标的影响是否显著就有必要使用协方差分析。
协方差分析是将方差分析和回归分析结合起来的一种统计方法。
它通过回归分析剔除其他混杂因素对指标的影响,再通过方差分析来研究处理因素对指标影响的显著性。
在协方差分析中,这些混杂因素被称为协变量。
协变量要求是连续型的数值变量,且多个协变量之间相互独立并与因素没有交互影响。
6.5.2 协方差分析的基本操作
下面以SPSS 15为例,介绍协方差分析的基本操作流程。
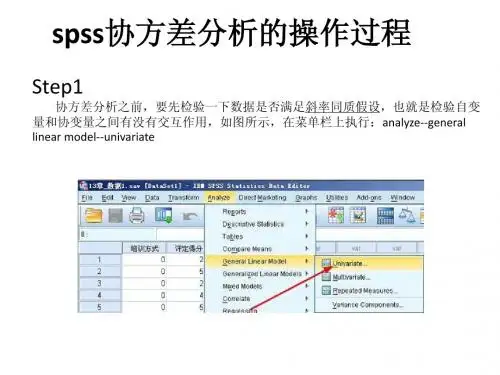
首先单击“Analyze ”下“General Linear Model ”中的“Univariate ”,指定因素变量到“Dependent ”框、影响因素到“
Fixed Factor(s)”
框和协变量到“
Covariate(s)”框;然后单击“Model ”按钮,定义方差分析的模型;再单击“Post Hoc ”按钮,定义各因素多重比较的检验方法。
具体如图6-19所示。
图6-19 协方差分析基本操作流程图
6.5.3 协方差分析的应用举例。

SPSS学习笔记---------------------------------------1. SPSS学习笔记之——常用统计方法的选择汇总2. SPSS学习笔记之——多因素方差分析3. SPSS学习笔记之——协方差分析4. SPSS学习笔记之——重复测量的多因素方差分析5.SPSS学习笔记之——二项Logistic回归分析6.SPSS学习笔记之——两配对样本的非参数检验(Wilcoxon符号秩检验)7.SPSS学习笔记之——两独立样本的非参数检验(Mann-Whitney U秩和检验)8.SPSS学习笔记之——多个独立样本的非参数检验(Cruskal-Wallis秩和检验)9.SPSS学习笔记之——生存分析的Cox回归模型(比例风险模型)10.SPSS学习笔记之——相关分析(Pearson、Spearman、卡方检验)11.SPSS学习笔记之——配对logistic回归分析12.SPSS学习笔记之——单样本非参数检验13.SPSS学习笔记之——ROC曲线14.SPSS学习笔记之——Kaplan-Meier生存分析15.SPSS学习笔记之——多相关样本的非参数检验(Friedman检验)16.R×C列联表(分类数据)的统计分析方法选择与SPSS实现17.SPSS学习笔记之——OR值与RR值----------------------------------------价SPSS学习笔记之——多因素方差分析问题:对小白鼠喂以三种不同的营养素,目的是了解不同营养素增重的效果。
采用随机区组设计方法,以窝别作为划分区组的特征,以消除遗传因素对体重增长的影响。
现将同品系同体重的24只小白鼠分为8个区组,每个区组3只小白鼠。
三周后体重增量结果(克)列于下表,问小白鼠经三种不同营养素喂养后所增体重有无差别?区组号营养素1营养素2营养素3150.1058.2064.50247.8048.5062.40353.1053.8058.60463.5064.2072.50571.2068.4079.30641.4045.7038.40761.9053.0051.20842.2039.8046.20SPSS软件版本:18.0中文版。

22.方差分析一、方差分析原理1.方差分析概述方差分析可用来研究多个分组的均值有无差异,其中分组是按影响因素的不同水平值组合进行划分的。
方差分析是对总变异进行分析。
看总变异是由哪些部分组成的,这些部分间的关系如何。
方差分析,是用来检验两个或两个以上均值间差别显著性(影响观察结果的因素:原因变量(列变量)的个数大于2,或分组变量(行变量)的个数大于1)。
一元时常用F检验(也称一元方差分析),多元时用多元方差分析(最常用Wilks' A检验)。
方差分析可用于:(1)完全随机设计(单因素)、随机区组设计(双因素)、析因设计、拉丁方设计和正交设计等资料;(2)可对两因素间交互作用差异进行显著性检验;(3)进行方差齐性检验。
要比较几组均值时,理论上抽得的几个样本,都假定来白正态总体,且有一个相同的方差,仅仅均值可以不相同。
还需假定每一个观察值都由若干部分累加而成,也即总的效果可分成若干部分,而每一部分都有一个特定的含义,称之谓效应的可加性。
所谓的方差是离均差平方和除以白由度,在方差分析中常简称为均方(Mean Square)。
2.基本思想基本思想是,将所有测量值上的总变异按照其变异的来源分解为多个部份,然后进行比较,评价由某种因素所引起的变异是否具有统计学意义。
根据效应的可加性,将总的离均差平方和分解成若干部分,每一部分都与某一种效应相对应,总白由度也被分成相应的各个部分,各部分的离均差平方除以各白的白由度得出各部分的均方,然后列出方差分析表算出F检验值,作出统计推断。
方差分析的关键是总离均差平方和的分解,分解越细致,各部分的含义就越明确,对各种效应的作用就越了解,统计推断就越准确。
效应项与试验设计或统计分析的目的有关,一般有:主效应(包括各种因素),交互影响项(因素间的多级交互影响),协变量(来白回归的变异项),等等。
当分析和确定了各个效应项S后,根据原始观察资料可计算出各个离均差平方和SS再根据相应的白由度df,由公式MS=SSdf,求出均方MS,最后由相应的均方,求出各个变异项的F值,F值实际上是两个均方之比值,通常情况下,分母的均方是误差项的均方。



多个自变量对一个因变量的影响(SPSS:协方差分析)协方差分析解决的问题:多个自变量(包括离散变量和连续变量)对一个因变量(连续数据)的影响。
自变量中的连续变量被作为协变量加以'控制'(控制变量)。
协方差分析可以在一定程度上排除非处理因素的影响,从而准确的获得处理因素的影响。
协方差分析的条件:除了满足一般的方差分析条件外,还需要满足'平行性检验'。
协方差分析是回归分析和方差分析的结合。
分析步骤包括两个部分:第一部分:平行性检验自变量与协变量的交互作用:P>0.05,满足平行性检验,满足协方差分析的条件;P≤0.05,不满足平行性检验,不满足协方差分析的条件。
第二部分:协方差分析案例:运动干预对高血压人群的治疗效果研究实验设计(简化版):选取54名高血压人群,随机分为3组,分别采用健身走、广场舞、太极拳运动干预。
干预时间为6个月。
实验前、实验后测试安静收缩压,差值形成变量'血压下降'。
已经统计检验过,实验前三组的收缩压基础值差异没有统计学意义。
统计分析思路说明:考虑到年龄可能对血压下降程度有较大影响,而年龄又是连续变量,因此把'年龄'作为'协变量'。
在研究运动干预对血压影响的同时,排除协变量'年龄'的影响,使结果更加准确。
协方差分析就是用于解决类似问题的。
自变量:锻炼项目协变量:年龄因变量:血压下降。
1 部分数据图12 平行性检验这是协方差分析的一个重要条件。
意思是:各组的协变量与因变量存在线性回归关系且斜率基本相同。
也就是回归直线近似平行。
可以先做一个散点图,初步探索平行性。
图2 散点图根据图2,三条回归直线近似平行,可以尝试采用协方差分析。
SPSS步骤:1)分析-一般线性模型-单变量图32)'血压下降'为'因变量';'组别'为'固定因子';'年龄'为'协变量'。
SPSS学习笔记3数据⽂件操作3.1⼀般操作1、数据排序2、数据⽂件分组3、数据⽂件合并对记录的合并对变量的合并4、数据⽂件转置5、变量取值的求秩求出变量取值在指定条件下的⼤⼩顺序,使得取值按照⼀定的顺序进⾏排列,秩就反映了取值在这个有序列⾥的位置信息。
6、变量值的重新编码可分为⽣成新变量和不⽣成新变量7、计算新变量3.2分类汇总按指定的分类变量对观测值量进⾏分组,然后计算各分组内的某些变量的描述统计量。
按性别、年龄分类,算出⾝⾼、体重的均值,并统计每个分类的个数。
3.3观测值的权重3.4数据⽂件的结构重组⼦公司与季度销售量问题横向结构:每个⼦公司⼀条观测值记录,包含它在4个季度纵向结构:每个⼦公司每个季度建⽴⼀条观测值4基本统计分析功能统计分析和建模之前,对数据进⾏描述性⼯作。
展现数据的基本统计指标。
4.1 OLAP:在线分析过程汇总变量:连续型变量分组变量:实例操作:设置变量间差异设置分组间差异:输⼊对选中的分组变量进⾏⽐较的第⼀个类别的取值输⼊对选中的分组变量进⾏⽐较的第⼆个类别的取值交互式操作:右键图表-编辑4.2 观测的摘要报告分析4.3 ⾏和列的摘要报告分析4.4.1 对分组变量的频数分析4.4.2 对连续变量的频数分析4.5 描述性统计分析主要⽤来对连续变量,可以将原始数据转换成标准Z分值(标准化数据)并存⼊当前数据集,标准化后的变量值没有度量衡的差异,更加易于⽐较。
4.6 探索性分析能够帮助⽤户决定选择何种统计⽅法进⾏数据建模,判断是否需要把数据转换成正态分布,以及是否需要做⾮参数统计。
4.7 列联表分析5均值⽐较和T检验能否⽤样本均值估计总体均数,两个变量均值接近的样本是否来⾃均值相同的总体。
两个样本某变量的均值不同,其差异是否具有统计意义,它能否说明总体之间存在的差异。
假设检验:|--参数检验(定量数据)|--单样本:T检验、Z检验|--双样本|--独⽴样本|--配对样本|--⾮参数检验(⾮定量数据)|--单样本:卡⽅检验、K-S检验、游程、⼆项式|--双样本|--独⽴样本|--配对样本对来⾃正态总体的两个样本进⾏均值⽐较,常⽤t⽅法,因⽅差是否相同⽽T公式不同对⽅差齐次性检验常使⽤F检验。
我们在实际工作中为了准确的分析问题,经常会收集多个变量,这些变量之前存在相互影响,导致分析的因素混杂,影响分析结果,为了获得准确的实验效应,我们需要控制其中一些影响因变量的变量,这些变量称为就协变量,带有协变量的方差分析称为协方差分析。
协方差分析的基本思想为:在进行方差分析之前,先用直线回归找出各组因变量与协变量之间的数量关系,求得假定协变量相等时的因变量值,然后以这个修正后的因变量值做方差分析,这样就有可以做到控制协变量对因变量产生的影响。
协方差分析有如下假定
1.协变量与因变量是线性关系
2.各组残差呈正态分布
3.各组回归线平行,斜率相等
其中第三点为协方差分析特有的平行性假定,实际上就是检验对于不同的自变量,协变量对因变量的影响是否相同,这点很重要,如果该假设不满足的话,说明自变量和协变量之间存在相互影响,而它们又同时都会对因变量产生影响,这样混杂起来我们就无法完全控制协变量了。
如果不满足平行性假定,需要对数据进行处理或者改用其他方法。
协方差分析在一般线性模型的三个子过程中都可以做,本例只有一个因变量,因此选择单变量分析—一般线性模型—单变量。
单因素协方差分析【详】-SPSS教程一、问题与数据某研究者拟分析两种药物对血脂浓度的影响,招募45位中年男性分为三组,第一组给以药物1治疗(为期6周),第二组给以药物2治疗(为期6周),第三组作为空白对照组。
研究者测量了每位研究对象接受干预前的总胆固醇浓度(TC1)和干预后的总胆固醇浓度(TC2),部分数据图1。
图1 部分数据二、对问题分析研究者想判断不同干预方法(group)对因变量(治疗后TC2)的影响,但是不能忽视协变量(治疗前TC1)对因变量的作用。
针对这种情况,我们可以使用单因素协方差分析,但需要先满足以下10项假设:假设1:因变量是连续变量。
假设2:自变量存在2个或多个分组。
假设3:协变量是连续变量。
假设4:各研究对象之间具有相互独立的观测值。
假设5:各组内协变量和因变量之间存在线性关系。
假设6:各组间协变量和因变量的回归直线平行。
假设7:各组内因变量的残差近似服从正态分布。
假设8:各组内因变量的残差方差齐。
假设9:各组间因变量的残差方差齐。
假设10:因变量没有显著异常值。
经分析,本研究数据满足假设1-4,那么应该如何检验假设5-10,并进行单因素协方差分析呢?三、SPSS操作3.1 检验假设5:各组内协变量和因变量之间存在线性关系为检验假设5,我们需要先绘制协变量与因变量在不同组内的散点图。
在主界面点击Graphs→Chart Builder,在Chart Builder对话框下,从Choose from 选择Scatter/Dot。
在中下部的8种图形中,选择“Grouped Scatter”,并拖拽到主对话框中。
如图2。
图2 Chart Builder将TC1、TC2和group变量分别拖拽到“X-Axis?”、“Y-Axis?”和“Set color”方框内。
如图3。
图3 Chart Builder在Element Properties框内点击Y-Axis1 (Point1),在Scale Range框内取消对Minimum的勾选。
SPSS操作—方差分析
一、概念
方差分析(ANOVA)法是统计学中一种用于检验三个或以上水平的均数差异的统计方法。
方差分析从表面上看是利用方差的大小,在一定的概率和显著水平下,比较多组数据的均值差异,确定数据的显著性。
一般来说,它用来检验有多自变量时的均数差异,其中包括一个或多个因素,每个因素又有两个或者多个水平。
二、SPSS操作步骤
1、打开SPSS软件,点击“文件”,选择“新建”,在弹出的界面中选择“数据集”,点击“确定”,新建一个数据集。
2、将所要分析的数据输入到数据集中,在“变量视图”中定义响应变量和自变量,并设置其变量类型,完成数据的输入。
3、点击“分析”,选择“统计”,在弹出的界面中选择“参数检验”,点击“F检验”,然后在窗口中选择因变量和自变量,完成基本的参数设置,点击“确定”,弹出方差分析窗口,点击“确定”,即可开始运行方差分析。
4、方差分析运行完毕后,在输出窗口中可以看到结果,包括方差分析汇总表和方差分析的结果等信息。
5、方差分析的结果主要包括拟合度指数、F值、绝对值、样本量、概率值、单组比较、多组比较等内容,在这里。
SPSS基础学习⽅差分析—协⽅差分析
⽬的:在多因素⽅差分析中我们提到“协变量“是⽤来控制其他变量与因⼦变量有关⽽且影响⽅差分析的⽬标变量的其他⼲扰因素。
注意点:在利⽤协⽅差分析的时候,我们先对这个变量进⾏分析。
案例分析:研究三中不同的饲料对⽣猪的体重增加的影响。
(数据来源:薛薇《统计分析与SPSS的应⽤》第六章)
⾸先,先对猪喂养前的体重进⾏⼀个散点图的绘制
步骤:图形—旧对话框—点状/散点
由图可知:变量之间呈现较为相似的线性关系,各斜率基本相同,所以喂养前的体重可以作为协变量参与协⽅差分析。
协⽅差分析的步骤:
分析—⼀般线性模型—单变量
关键截图:
结果分析:
由协变量的图:
没有协变量的图:
分析:我们可以清楚地的看出SL的变差由1238.375减少为227.615,这就是剔除了喂养前体重的影响造成的,因此不能忽略”猪喂养前的体重“。
参考书籍:
薛薇《统计分析与SPSS的应⽤》第五版
吴骏《SPSS统计分析从零开始》。
1、分析原理
协方差分析是回归分析与方差分析的结合。
在作两组和多组均数之间的比较前,用直线回归的方法找出各组因变量Y与协变量X之间的数量关系,求得在假定X相等时的修正均数,然后用方差分析比较修正均数之间的差别。
要求X与Y的线性关系在各组均成立,且在各组间回归系数近似相等,即回归直线平行;X的取值范围不宜过大,否则修正均数的差值在回归直线的延长线上,不能确定是否仍然满足平行性和线性关系的条件,协方差分析的结论可能不正确。
对于协变量的概念,可以简单的理解为连续变量,多数情况下,连续变量都要作为协变量处理。
2、问题
欲了解成年人体重正常者与超重者的血清胆固醇是否不同。
而胆固醇含量与年龄有关,资料见下表。
数据视图:
先要分析两组中年龄与胆固醇是否有线性关系,且比较回归洗漱是否相等,比较粗略的做法是画散点图,选择菜单:图形-》旧对话框-》散点图,如图:
进入图形对话框:
将胆固醇、年龄、组分别选入Y轴、X轴、设置标记:
点击确定开始画图
可以看出,大致呈直线关系。
更为精确的作法是检验年龄与分组之间是否存在交互作用,即年龄的作用是否受分组的影响。
接下来开始协方差分析,首先进入菜单:
进入对话框
将胆固醇选入“因变量”,组选入“固定因子”,年龄选入“协变量”,见图:
点击右边“模型”按钮,在“构建项”下拉菜单中选择“主效应”,将“组”和“年龄”选入右边框中,然后在“构建项”下拉菜单中选择“交互”,同时选中“组”和“年龄”,一并选入右边的框中,见图:
点击“继续”按钮回到“单变量”主界面:
单击“选项”按钮,进入如下对话框:
选中“描述性分析”:
点击“继续”按钮回到主界面,单击“确定”即可。
4、结果解读
这是各组的描述性统计分析。
这是主要的统计分析结果,一个典型的方差分析表,解释一下:
1、表格的第一行“校正模型”是对模型的检验,零假设是“模型中所有的因素对因变量均无影响”(这里包括分组、年龄及他们的交互作用),其P<0.001,拒绝零假设,说明存在对因变量有影响的因素。
2、表格的第二行是回归分析的常数项,通常无实际意义。
3、表格的第三行、第四行是对组和年龄的检验,P均<0.05,有统计学意义,说明分组和年龄对胆固醇的影响均有统计学意义。
4、表格的第五行是对分组和年龄的交互作用的检验,其P=0.935>0.05,说明分组和年龄无交互作用,也就是说,年龄对胆固醇的影响不随分组的不同而不同,这也是协方差分析的基本条件之一。
这里是满足的。