Nginx源代码分析
- 格式:docx
- 大小:226.48 KB
- 文档页数:18

nginx 源码编译
nginx是一个流行的开源Web服务器,广泛用于构建高性能、可扩展的Web应用程序。
在某些特定的情况下需要对nginx进行定制化的编译,即修改源代码后进行编译。
下面是nginx源码编译的步骤:
1. 下载nginx源码。
2.安装编译工具。
进行编译需要GCC编译器和一些相关的编译工具,可以通过以下命令在Linux系统上安装:
```。
sudo apt-get install build-essential。
```。
3.配置编译参数。
进入nginx源码目录,执行以下命令进行编译参数配置:
```。
```。
4.编译。
配置好编译参数后,直接执行以下命令开始编译:
```。
make。
make install。
```。
make命令会编译nginx源码,make install命令会将编译完成的文件安装到指定目录。
5. 运行nginx。
编译完成后,可以使用以下命令启动nginx:
```。
/usr/local/nginx/sbin/nginx。
```。
至此,就完成了nginx源码编译的过程。
其中,可以根据实际需求调整编译参数。

Nginx 源码分析:ngx_array、ngx_list基本数据结构应该说大家对这四个数据结构相当熟悉了,因此我们一并将它们进行分析,瞧一瞧nginx是如何实现它们的。
在此篇之前,我们已经对nginx 内存池(pool)进行了分析,在此基础上来理解ngnix对它们的实现将变得非常简单,特别是内存池(pool)中的ngx_palloc 函数在这四个结构中多次用到,若不清楚想了解原理的可以看看我前面写的文章,它返回的是在内存池分配好空间了的首地址。
一、ngx_array 数组:struct ngx_array_s {void *elts;ngx_uint_t nelts;size_t size;ngx_uint_t nalloc;ngx_pool_t *pool;};参数说明:elts为array数组中元素的首地址,nelts数组中已分配的元素个数,size每个元素大小,nalloc数组容量,pool其所在的内存池。
能够支持五种函数操作:创建数组:ngx_array_create(ngx_pool_t *p, ngx_uint_t n, size_t size);数组初始化:ngx_array_init(ngx_array_t *array, ngx_pool_t *pool, ngx_uint_t n, size_t size) 数组注销:ngx_array_destroy(ngx_array_t *a);添加一个数组元素:ngx_array_push(ngx_array_t *a);添加n个数组元素:ngx_array_push_n(ngx_array_t *a, ngx_uint_t n);ngx_array_create和ngx_array_init,代码比较简明就不多说了,值得注意的是两者之间的差别,ngx_array_init使用情形是已经存在了ngx_array_t的结构体,而ngx_array_create则从零开始建起,贴出代码:View Code重点介绍下ngx_array_push函数View Code代码里面主要就是if和else的逻辑关系,可解释为以下几种情形:第一,如果array当前已分配的元素个数小于最大分配个数,那么用数组元素首地址a->elts 计算出分配元素的首地址,并返回结果。

Nginx源码分析--模块module解析执⾏nginx.conf配置⽂件流程分析⼀ 搭建nginx服务器时,主要的配置⽂件 nginx.conf 是部署和维护服务器⼈员经常要使⽤到的⽂件,⾥⾯进⾏了许多服务器参数的设置。
那么nginx 以模块 module为⾻架的设计下是如何运⽤模块 module来解析并执⾏nginx.conf配置⽂件下的指令的呢?在探究源码之前,需要对nginx下的模块 module 有个基本的认知(详情参考前⾯的博⽂ )同时也要对nginx中常⽤到的⼀些结构有个基本的了解如:内存池pool 管理相关的函数、ngx_string 的基本结构等(详情参考前⾯的博⽂),若不然看代码的时候可能不能很明晰其中的意思,本⽂着重探究的是解析执⾏的流程。
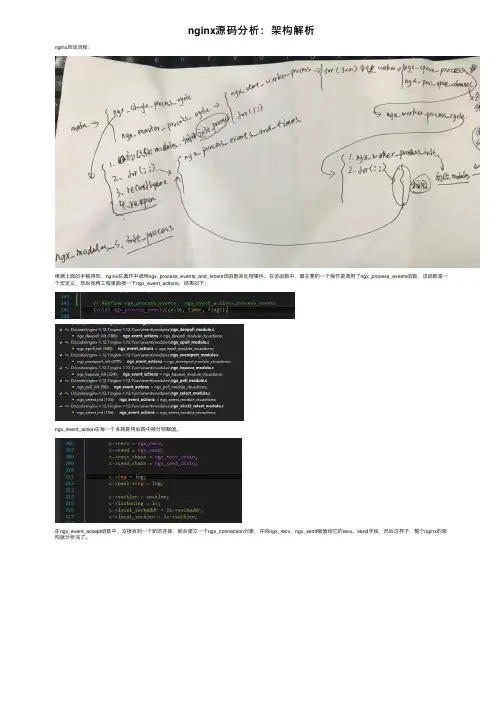
1、从main函数说起。
Nginx的main函数在nginx.c⽂件中(本⽂使⽤release-1.3.0版本源码,200⾏),因为是主函数其中涉及到了许许多多的功能模块的初始化等内容,我们只关注我们需要的部分。
看到326⾏:ngx_max_module = 0;for (i = 0; ngx_modules[i]; i++) {ngx_modules[i]->index = ngx_max_module++;} cycle = ngx_init_cycle(&init_cycle); 可以看出来,这⾥对 ngx_modules (中有介绍)进⾏了索引编号,并且计算得到模块的总数 ngx_max_module。
然后,对cycle进⾏初始化,跳转到 ngx_init_cycle中。
对于cycle 这个变量是nginx的核⼼变量,可以说模块机制都是围绕它进⾏的,⾥⾯的参数⽐较复杂涉及到的内容⼗分多,本⽂并不详细对它讨论,可以将其看作是⼀个核⼼资源库。
2、ngx_init_cycle 函数 这个函数在⽂件ngx_cycle.c中(43⾏),这个函数是nginx初始化中最重要的函数之⼀,⾥⾯涉及到与cycle变量相关的初始化⼯作,看到第188⾏cycle->conf_ctx = ngx_pcalloc(pool, ngx_max_module *sizeof(void *)); 这⾥获取了 ngx_max_module 个指针空间,⽤来保存每个模块的配置信息,从cycle 变量的字段conf_ctx 命名中就可以知道,ctx 为context 上下⽂的缩写。

Nginx源码分析- Nginx启动以及IOCP模型本文档针对Nginx1.11.7版本,分析Windows下的相关代码,虽然服务器可能用Linux更多,但是windows平台下的代码也基本相似,另外windows的IOCP完成端口,异步IO模型非常优秀,很值得一看。
Nginx启动曾经有朋友问我,面对一个大项目的源代码,应该从何读起呢?我给他举了一个例子,我们学校大一大二是在紫金港校区,到了大三搬到玉泉校区,但是大一的时候也会有时候有事情要去玉泉办。
偶尔会去玉泉,但是玉泉校区不熟悉,于是跟着百度地图或者跟着学长走。
因为是办事情,所以一般也就是局部走走,比如在学院办公楼里面走走。
等到大三刚来到玉泉,会发现,即使是自己以前来过几次,也觉得这个校区完全陌生,甚至以前来过的地方,也显得格外生疏。
但是当我们真正在玉泉校区开始学习生活了,每天从寝室走到教室大多就是一条路,教超就是另一条路,这两条主要的路走几遍之后,有时候顺路去旁边的小路看看,于是慢慢也熟悉了这个新的校区。
源代码的阅读又何尝不是这样呢,如果没有一条主要的路线,总是局部看看,浅尝辄止不说,还不容易把握整体的结构。
各模块之间的依赖也容易理不清。
如果有一条比较主干的线路,去读源代码,整体结构和思路也会变得明晰起来。
当然我也是持这种看法:博客、文章的作者,写文章的思路作者自己是清楚的,读者却不一定能看得到;而且大家写东西都难免会有疏漏。
看别人写的源码分析指引等等,用一种比较极端的话来说,是一种自我满足,觉得自己很快学到了很多源码级别的知识,但是其实想想,学习乎,更重要的是学习能力的锻炼,通过源码的学习,学习过程中自己结合自己情况的思考,甚至结合社会哲学的思考,以及读源码之后带来的收益,自己在平时使用框架、库的时候,出了问题的解决思路,翻阅别人源码来找到bug的能力。
如果只是单单看别人写的源码分析,与写代码的时候只去抄抄现成的代码,某种程度上是有一定相似性的。

nginx性能分析和全⾯调优Nginx全能解析及性能调优nginx 是⼀个轻量级的、基于http的、⾼性能的反向代理的服务器和静态web服务器。
正向代理和反向代理不管是正向代理还是反向代理都是基于客户端来说的。
正向代理特点正向代理是对客户端的代理正向代理是架设在客户端的主机客户端在使⽤正向代理服务器时是要知道访问的⽬标服务的地址案例隐藏真正的访问者向服务端隐藏真正的访问者。
对于服务端来说,真正的访问者时代理服务器。
起到了隐藏客户端的作⽤。
例如:实际⽣活中的短信轰炸,你根本不知道是谁给你发的短信;ddos攻击也是这个原理,使⽤很多‘⾁鸡’机器来攻击我们的服务器,我们⽆法查找真正的攻击源。
FQ由于很多复杂的原因,导致服务器A不能直接访问服务器B,但是服务器C可以访问服务器B,⽽服务器A⼜可以访问服务器C;这时,服务器C作为服务起A的代理服务器对B进⾏访问。
⽬前的FQ软件就是使⽤这个原理。
提速同上原理⼀样,服务器A访问服务器B速度过慢,⽽服务器C访问服务器B很快,服务器A访问服务器C很快。
则使⽤代理服务器提⾼效率。
缓存增加客户端缓存,减少对服务器的请求资源的压⼒。
例如maven的nexus就是⼀个典型的客户端缓存例⼦。
授权例如,在公司中,需要对员⼯电脑进⾏外⽹监控授权,则也是使⽤这种客户端正向代理服务器。
反向代理特点反向代理是对服务端的代理反向代理是架设在服务端的主机客户端端访问的时候不知道真正服务主机的地址案例保护隐藏真正的服务客户端只能访问服务端代理服务器,⽽真正的服务端是不能直接访问的,保护了服务端。
分布式路由根据客户端不同的请求,将请求路由到不同的服务端去。
负载均衡服务端均摊客户端的请求,保证服务端的⾼可⽤。
动静分离例如图⽚、静态页⾯、css、js等,都为静态资源,将其放到对应⽬录下,客户端加载静态资源时,就不会请求到服务端,⽽只会将动态资源的请求发送到服务端,减轻服务端的压⼒。
数据缓存反向代理同正向代理⼀样具有数据缓存的功能,都是为了减少服务端的压⼒。

nginx-0.8.38源码探秘先推荐几个研究nginx源码的好网址:/kenbinzhang/category/603177.aspx/p/nginxsrp/wiki/NginxCodeReview/langwan/blog/category/%D4%B4%C2%EB%B7%D6%CE%F6网上分析nginx源码的文章很多,但感觉分析的不够具体和完整,而且都是比较老的nginx版本。
本源码分析基于nginx-0.8.38版本,力求做到更具体和更完整,这是一种自我学习,希望和对此有兴趣的朋友一起探讨,有不正确的地方,也请各位指正。
那么一切从main开始吧!ngx_get_options函数是main调用的第一个函数,比较简单,它负责分析命令行参数,将相应的值赋给对应的全局变量,其中:1.ngx_prefix表示nginx的路径前缀,默认为/usr/local/nginx;2.ngx_conf_file表示nginx配置文件的路径,默认为/usr/local/nginx/conf/nginx.conf;3.ngx_test_config表示是否开启测试配置文件,如配置文件的语法是否正确,配置文件是否可正确打开。
ngx_time_init函数格式化nginx的日志时间,包括ngx_cached_err_log_time,ngx_cached_http_time,ngx_cached_http_log_time,ngx_cached_time。
主要操作在ngx_time_update 内,先获取系统当前时间,与之前保存的时间比较(注意slot),如果已经过时,则将时间重新更新,ngx_cached_time总是指向当前时间的cached_time。
最后还使用了内存屏障ngx_memory_barrier,确保读写顺序。
ngx_log_init函数初始日志结构,主要是对ngx_log变量操作。
初始log 级别为NGX_LOG_NOTICE。

Nginx中upstream模块源码分析2011-10-18/2011/07/nginx-upstream-src-1/一、nginx的upstream目前支持负载均衡方式的分配 (1)1、RR(默认) (1)2、ip_hash (1)3、fair(第三方) (1)4、url_hash(第三方) (2)二、RR策略 (2)2.1 初始化upstream (2)2.2 具体的RR策略 (3)三、Ip_hash策略 (4)3.1 Ip_hash和RR 的策略有两点不同 (5)3.2 RR策略回顾 (5)3.3 ip_hash策略内容 (5)四、ip_hash 模块分析 (6)五、RR模块分析 (10)一、nginx的upstream目前支持负载均衡方式的分配1、RR(默认)每个请求按时间顺序逐一分配到不同的后端服务器,假如后端服务器down掉,能自动剔除。
例如:upstream tomcats {server 10.1.1.107:88 max_fails=3 fail_timeout=3s weight=9;server 10.1.1.132:80 max_fails=3 fail_timeout=3s weight=9;}2、ip_hash每个请求按访问ip的hash结果分配,这样每个访客固定访问一个后端服务器,可以解决session的题目。
例如:upstream tomcats {ip_hash;server 10.1.1.107:88;server 10.1.1.132:80;}3、fair(第三方)按后端服务器的响应时间来分配请求,响应时间短的优先分配。
4、url_hash(第三方)按访问url的hash结果来分配请求,使每个url定向到同一个后端服务器,后端服务器为缓存时比较有效。
下面,我们针对RR和ip_hash的负载均衡策略进行分析。
由于每一种负载均衡策略都是在upstream的框架中使用,upstream控制总的工作流程,负载均衡策略仅仅提供选择或开释server的函数,所以,我们在分析RR时结合upstream(ngx_http_upstream.c)。

NGINX源码分析——概览⼀、概况Nginx可以开启多个进程,每个进程拥有最⼤上限128个⼦线程以及⼀定的可⽤连接数。
最⼤客户端连接数等于进程数与连接数的乘积,连接是在主进程中初始化的,⼀开始所有连接处于空闲状态。
每⼀个客户端请求进来以后会通过事件处理机制,在Linux是Epoll,在FreeBSD下是KQueue放到空闲的连接⾥。
如果设置了线程数,那么被填充的连接会在⼦线程中处理,否则会在主线程中依次处理。
如果解析出是动态脚本请求,会根据fast-cgi的设置访问php-cgi进程,php进程数量的多少依据php-fpm.conf中max_children的设置。
因此Nginx的动态请求能⼒不仅仅依靠Nginx本⾝的设置,还要调试php-fpm。
从源代码级别上看nginx由以下⼏个元素组成:1. worker(进程)2. thread(线程)3. connection(连接)4. event(事件)5. module(模块)6. pool(内存池)7. cycle(全局设置)8. log(⽇志)⼆、MAIN函数整个程序从main()开始算,代码更详细的内容,可以查看两外⼀篇⽂章:ngx_max_module = 0;for (i = 0; ngx_modules[i]; i++) {ngx_modules[i]->index = ngx_max_module++;}这⼏句⽐较关键,对加载的模块点⼀下数,看有多少个。
ngx_modules并不是在原代码中被赋值的,你先执⾏⼀下./configure命令⽣成⽤于编译的make环境。
在根⽬录会多出来⼀个⽂件夹objs,找到ngx_modules.c⽂件,默认情况下nginx会加载⼤约40个模块,的确不少,如果你不需要那个模块尽量还是去掉好⼀些。
接下来⽐较重要的函数是 ngx_init_cycle(),这个函数初始化系统的配置以及⽹络连接等,如果是多进程⽅式加载的会继续调⽤ngx_master_process_cycle(),这是main函数中调⽤的最关键的两个函数。

Nginx源码分析:3张图看懂启动及进程⼯作原理编者按:⾼可⽤架构分享及传播在架构领域具有典型意义的⽂章,本⽂由陈科在⾼可⽤架构群分享。
转载请注明来⾃⾼可⽤架构公众号「ArchNotes」。
导读:很多⼯程师及架构师都希望了解及掌握⾼性能服务器开发,阅读优秀源代码是⼀种有效的⽅式,nginx 是业界知名的⾼性能 Web 服务器实现,如何有效的阅读及理解 nginx?本⽂⽤图解的⽅式帮助⼤家来更好的阅读及理解 nginx 关键环节的实现。
陈科,⼗年⾏业从业经验,曾在浙江电信、阿⾥巴巴、华为、五⼋同城任开发⼯程及架构师等职,⽬前负责河狸家后端架构和运维。
博客地址:/wiki/doku.php图⼀:nginx 启动及内存申请过程分析任何程序都离不开启动和配置解析。
ngx 的代码离不开 ngx_cycle_s 和 ngx_pool_s 这两个核⼼数据结构,所以我们在启动之前先来分析下。
内存申请过程分为 3 步1. 假如申请的内存⼩于当前块剩余的空间,则直接在当前块中分配。
2. 假如当前块空间不⾜,则调⽤ ngx_palloc_block 分配⼀个新块然后把新块链接到 d.next中,然后分配数据。
3. 假如申请的⼤⼩⼤于当前块的最⼤值,则直接调⽤ ngx_palloc_large 分配⼀个⼤块,并且链接到 pool→large 链表中内存分配过程图解如下(图⽚来⾃⽹络)为了更好理解上⾯的图,可以参看⽂末附 2 的⼏个数据结构:ngx_pool_s 及 ngx_cycle_s。
知道了这两个核⼼数据结构之后,我们正式进⼊ main 函数,main 函数执⾏过程如下调⽤ ngx_get_options() 解析命令参数;调⽤ ngx_time_init() 初始化并更新时间,如全局变量ngx_cached_time;调⽤ ngx_log_init() 初始化⽇志,如初始化全局变量 ngx_prefix,打开⽇志⽂件ngx_log_file.fd;清零全局变量 ngx_cycle,并为 ngx_cycle.pool 创建⼤⼩为 1024B 的内存池;调⽤ ngx_save_argv() 保存命令⾏参数⾄全局变量 ngx_os_argv、ngx_argc、ngx_argv 中;调⽤ ngx_os_init() 初始化系统相关变量,如内存页⾯⼤⼩ ngx_pagesize , ngx_cacheline_size ,最⼤连接数 ngx_max_sockets 等;调⽤ ngx_crc32_table_init() 初始化 CRC 表 ( 后续的 CRC 校验通过查表进⾏,效率⾼ );调⽤ ngx_add_inherited_sockets() 继承 sockets:解析环境变量 NGINX_VAR = 'NGINX' 中的 sockets,并保存⾄ ngx_cycle.listening 数组;设置 ngx_inherited = 1;调⽤ ngx_set_inherited_sockets() 逐⼀对 ngx_cycle.listening 数组中的 sockets 进⾏设置;初始化每个 module 的 index,并计算 ngx_max_module;调⽤ ngx_init_cycle() 进⾏初始化;该初始化主要对 ngx_cycle 结构进⾏;若有信号,则进⼊ ngx_signal_process() 处理;调⽤ ngx_init_signals() 初始化信号;主要完成信号处理程序的注册;若⽆继承 sockets,且设置了守护进程标识,则调⽤ ngx_daemon() 创建守护进程;调⽤ ngx_create_pidfile() 创建进程记录⽂件;( ⾮ NGX_PROCESS_MASTER = 1 进程,不创建该⽂件 )进⼊进程主循环;若为 NGX_PROCESS_SINGLE=1模式,则调⽤ ngx_single_process_cycle() 进⼊进程循环;否则为 master-worker 模式,调⽤ ngx_master_process_cycle() 进⼊进程循环;在 main 函数执⾏过程中,有⼀个⾮常重要的函数 ngx_init_cycle,这个阶段做了什么呢?下⾯分析 ngx_init_cycle,初始化过程:1. 更新 timezone 和 time2. 创建内存池3. 给 cycle 指针分配内存4. 保存安装路径,配置⽂件,启动参数等5. 初始化打开⽂件句柄6. 初始化共享内存7. 初始化连接队列8. 保存 hostname9. 调⽤各 NGX_CORE_MODULE 的 create_conf ⽅法10. 解析配置⽂件11. 调⽤各NGX_CORE_MODULE的init_conf⽅法12. 打开新的⽂件句柄13. 创建共享内存15. 创建socket进⾏监听16. 调⽤各模块的init_module图⼆:master 进程⼯作原理及⼯作⼯程以下过程都在ngx_master_process_cycle 函数中进⾏,启动过程:1. 暂时阻塞所有 ngx 需要处理的信号2. 设置进程名称3. 启动⼯作进程4. 启动cache管理进程5. 进⼊循环开始处理相关信号master 进程⼯作过程1. 设置 work 进程退出等待时间2. 挂起,等待新的信号来临3. 更新时间4. 如果有 worker 进程因为 SIGCHLD 信号退出了,则重启 worker 进程5. master 进程退出。

Nginx源代码分析1.Nginx代码的目录和结构nginx的源码目录结构层次明确,从自动编译脚本到各级的源码,层次都很清晰,是一个大型服务端软件构建的一个范例。
以下是源码目录结构说明:├─auto 自动编译安装相关目录│├─cc 针对各种编译器进行相应的编译配置目录,包括Gcc、Ccc等│├─lib 程序依赖的各种库,包括md5,openssl,pcre等│├─os 针对不同操作系统所做的编译配置目录│└─types├─conf 相关配置文件等目录,包括nginx的配置文件、fcgi相关的配置等├─contrib├─html index.html└─src 源码目录├─core 核心源码目录,包括定义常用数据结构、体系结构实现等├─event 封装的事件系统源码目录├─http http服务器实现目录├─mail 邮件代码服务器实现目录├─misc 该目录当前版本只包含google perftools包└─os nginx对各操作系统下的函数进行封装以及实现核心调用的目录。
2.基本数据结构2.1.简单的数据类型在core/ngx_config.h 目录里面定义了基本的数据类型的映射,大部分都映射到c语言自身的数据类型。
typedef intptr_t ngx_int_t;typedef uintptr_t ngx_uint_t;typedef intptr_t ngx_flag_t;其中ngx_int_t,nginx_flag_t,都映射为intptr_t;ngx_uint_t映射为uintptr_t。
这两个类型在/usr/include/stdint.h的定义为:/* Types for `void *' pointers. */#if __WORDSIZE == 64# ifndef __intptr_t_definedtypedef long int intptr_t;# define __intptr_t_defined# endiftypedef unsigned long int uintptr_t;#else# ifndef __intptr_t_definedtypedef int intptr_t;# define __intptr_t_defined# endiftypedef unsigned int uintptr_t;#endif所以基本的操作和整形/指针类型的操作类似。
nginx源码分析nginx源码分析(1)- 缘起nginx是一个开源的高性能web服务器系统,事件驱动的请求处理方式和极其苛刻的资源使用方式,使得nginx成为名副其实的高性能服务器。
nginx的源码质量也相当高,作者“家酿”了许多代码,自造了不少轮子,诸如内存池、缓冲区、字符串、链表、红黑树等经典数据结构,事件驱动模型,http解析,各种子处理模块,甚至是自动编译脚本都是作者根据自己的理解写出来的,也正因为这样,才使得nginx比其他的web服务器更加高效。
nginx 的代码相当精巧和紧凑,虽然全部代码仅有10万行,但功能毫不逊色于几十万行的apache。
不过各个部分之间耦合的比较厉害,很难把其中某个部分的实现拆出来使用。
对于这样一个中大型的复杂系统源码进行分析,是有一定的难度的,刚开始也很难找到下手的入口,所以做这样的事情就必须首先明确目标和计划。
最初决定做这件事情是为了给自己一些挑战,让生活更有意思。
但看了几天之后,觉得这件事情不该这么简单看待,这里面有太多吸引人的东西了,值得有计划的系统学习和分析。
首先这个系统中几乎涵盖了实现高性能服务器的各种必杀技,epoll、kqueue、master-workers、pool、 buffer… …,也涵盖了很多web服务开发方面的技术,ssi、ssl、proxy、gzip、regex、load balancing、reconfiguration、hot code swapping… …,还有一些常用的精巧的数据结构实现,所有的东西很主流;其次是一流的代码组织结构和干净简洁的代码风格,尤其是整个系统的命名恰到好处,可读性相当高,很kiss,这种风格值得学习和模仿;第三是通过阅读源码可以感受到作者严谨的作风和卓越的能力,可以给自己增加动力,树立榜样的力量。
另一方面,要达到这些目标难度很高,必须要制定详细的计划和采取一定有效的方法。
对于这么大的一个系统,想一口气知晓全部的细节是不可能的,并且nginx 各个部分的实现之间关系紧密, 不可能做到窥一斑而知全身,合适的做法似乎应该是从main开始,先了解nginx的启动过程的顺序,然后进行问题分解,再逐个重点分析每一个重要的部分。
Nginx原理代码分析事件驱动模型是Nginx的核心设计理念之一、与传统的多线程和多进程模型不同,Nginx使用了基于事件驱动的方式来处理请求。
它使用一个主进程来监听和接受客户端请求,然后将请求分发给工作进程进行处理。
这种模型可以避免线程或进程间的切换开销,从而提高服务器的性能。
在代码级别上,Nginx通过epoll或select等I/O多路复用技术来实现事件驱动。
通过将所有的请求和连接都注册到一个事件循环中,当有事件发生时,通过回调函数来处理。
这种方式可以有效地利用系统资源,同时避免了线程或进程的切换开销。
多进程模型是Nginx另一个重要的设计理念。
Nginx使用了多个工作进程来处理请求,每个工作进程独立运行,并且互不影响。
这样可以保证高并发情况下的稳定性。
在代码层面上,Nginx使用了fork函数来创建子进程,并且使用共享内存来实现进程间的通信。
工作流程是Nginx的实际执行过程。
当Nginx启动时,它首先会读取并解析配置文件,然后根据配置文件中的指令进行相应的初始化操作。
接着,Nginx会创建主进程和工作进程,并且设置好工作进程的个数。
主进程负责监听和接受客户端的连接请求,然后将请求分发给工作进程。
工作进程处理请求并响应给客户端。
整个过程中,Nginx会通过各种模块来实现不同的功能,比如HTTP模块、代理模块等。
在代码级别上,Nginx使用了基于事件的驱动循环来处理请求。
通过调用epoll_wait或select等函数,Nginx可以监听事件的发生,并且根据事件的类型调用相应的回调函数进行处理。
这些回调函数通常包括连接的建立和关闭、数据的读取和写入等操作。
通过这种方式,Nginx可以高效地处理大量的并发请求。
总结来说,Nginx的原理和代码分析主要涉及事件驱动、多进程模型和工作流程。
通过深入了解这些方面,可以更好地理解Nginx的工作原理,并且在实际开发中更好地应用和优化Nginx。
nginx源码分析Nginx是一个高性能的Web服务器和反向代理服务器,其源码非常庞大,而且涉及的知识领域非常广泛。
在这篇文章中,我将分析Nginx的源码,主要着重于其核心功能和结构。
首先,我们需要了解Nginx的主要结构。
Nginx的源代码包含了很多模块,每个模块都有特定的功能。
比如,核心模块负责处理HTTP/HTTPS请求,事件模块负责处理I/O事件,反向代理模块负责处理反向代理请求等。
这些模块之间相互独立,可以按需启用和禁用。
Nginx的事件驱动模型是其高性能的关键之一、Nginx使用了多路复用技术,通过一个或多个工作进程处理所有请求。
这些工作进程通过事件驱动调度任务,当有新的连接或数据到达时触发相关的事件,并由对应的模块处理。
这种事件驱动模型避免了线程之间的频繁切换,提高了服务器的并发处理能力。
Nginx的HTTP请求处理涉及到请求的解析和响应的生成。
首先,Nginx接收到HTTP请求后,根据请求的头部信息进行解析,提取出请求的URI、请求方法、请求参数等信息。
然后,Nginx根据请求的URI匹配到相应的location和对应的指令。
根据这些指令,Nginx会对请求进行处理,比如读取文件、反向代理、重定向等。
最后,Nginx生成响应的头部和内容,并返回给客户端。
在Nginx的源码中,我们可以看到各种数据结构和算法的应用。
比如,Nginx使用哈希表来快速查找location和指令的匹配关系。
Nginx还使用链表和队列来管理请求和连接。
这些数据结构和算法的应用使得Nginx的性能得到了很大的提升。
Nginx的源码中还有很多优化技巧和特殊处理。
比如,Nginx使用池内存管理,减少了内存分配和释放的次数,提高了性能。
Nginx还使用了零拷贝技术,避免了数据在用户态和内核态之间的复制,提高了网络传输效率。
此外,Nginx还实现了动态加载模块的功能,可以在不停机的情况下加载和卸载模块,提高了服务器的灵活性。
nginx源码编译时常见错误解决⽅法最近在研究nginx源码,准备对源码进⾏调试,需要'-g'选项编译nginx,便于使⽤GDB调试nginx。
编译源码的过程中发现很多问题,决定进⾏⼀番梳理。
编译环境:###Ubuntu20.04&gcc--version 9.3.0###nginx源码版本:nginx-1.12.0编译nginx所需要的库及版本号:pcre-8.37openssl-1.1.0hzlib-1.2.11配置命令:./configure --prefix=/home/zyz/nginx1.12.0/ --with-http_ssl_module --with-http_stub_status_module --with-pcre=/home/zyz/pcre-8.37/ --with-openssl=/home/zyz/openssl-1.1.0h/ --with-zlib=/home/zyz/zlib-1.2.11/编译命令:make报错:make -f objs/Makefilemake[1]: Entering directory '/home/zyz/nginx-1.12.0'cd ../pcre-8.37/ \&& if [ -f Makefile ]; then make distclean; fi \&& CC="cc" CFLAGS="-O2 -fomit-frame-pointer -pipe " \./configure --disable-shared/bin/sh -3: permission deny解决⽅法:经过⼀番分析发现是pcre-8.37 和openssl-1.1.0h库中的configure⽂件和config⽂件默认⽆执⾏权限,果断进⼊两个库⽂件夹,执⾏chmod 777 configure ; chmod 777 config于是乎make,开始⼤量编译...过了⼀会⼉,⼜报了另外⼀个错误!src/core/ngx_murmurhash.c: In function ‘ngx_murmur_hash2’:src/core/ngx_murmurhash.c:37:11: error: this statement may fall through [-Werror=implicit-fallthrough=]37 | h ^= data[2] << 16;| ~~^~~~~~~~~~~~~~~~src/core/ngx_murmurhash.c:38:5: note: here38 | case 2:| ^~~~src/core/ngx_murmurhash.c:39:11: error: this statement may fall through [-Werror=implicit-fallthrough=]39 | h ^= data[1] << 8;| ~~^~~~~~~~~~~~~~~src/core/ngx_murmurhash.c:40:5: note: here40 | case 1:| ^~~~cc1: all warnings being treated as errorsmake[1]: *** [objs/Makefile:482:objs/src/core/ngx_murmurhash.o] 错误 1make[1]: 离开⽬录“/home/zyz/nginx-1.12.0”make: *** [Makefile:8:build] 错误 2解决⽅法:进⼊objs/Makefile,打开Makefile⽂件将编译选项中的CFLAGS = -pipe -O -W -Wall -Wpointer-arith -Wno-unused-parameter -werror -g中的“-werror"删除。
nginx源码编译nginx是基于C语言和模块化插件的Web服务器软件,其源代码是开放的。
用户可以根据需要下载源代码后进行编译,以生成用户需要的可执行文件。
以下是nginx源码编译的步骤:1. 安装必需的依赖库。
在进行nginx源码编译之前,需要安装一些必需的依赖库。
比如,使用yum批量安装以下依赖库:```yum install -y gcc-c++ pcre pcre-devel zlib zlib-devel openssl openssl-devel```2. 下载nginx源码到本地。
可以从官网下载最新版的nginx源码压缩包,然后解压到本地。
3. 进入nginx源码目录。
使用cd命令进入nginx源码目录。
4. 执行configure脚本。
运行configure脚本以生成Makefile文件和编译参数。
```./configure --prefix=/usr/local/nginx```上述命令中,--prefix参数指定了nginx安装路径。
如果需要指定其他参数,可以参考官方文档进行配置。
5. 执行make命令。
运行make命令编译nginx源码。
注意:编译时间可能会比较长。
```make```6. 执行make install命令。
运行make install命令将nginx安装到指定的目录。
```make install```7. 验证安装结果。
完成以上步骤后,可以使用whereis命令验证nginx是否已经成功安装。
```whereis nginx```如果返回nginx的安装路径,则说明安装成功。
以上是基础的nginx源码编译流程,对于高级使用和优化的问题,需要用户按照实际需求进行相关的配置和编译操作。
Nginx源代码分析1.Nginx代码的目录和结构nginx的源码目录结构层次明确,从自动编译脚本到各级的源码,层次都很清晰,是一个大型服务端软件构建的一个范例。
以下是源码目录结构说明:├─auto 自动编译安装相关目录│├─cc 针对各种编译器进行相应的编译配置目录,包括Gcc、Ccc等│├─lib 程序依赖的各种库,包括md5,openssl,pcre等│├─os 针对不同操作系统所做的编译配置目录│└─types├─conf 相关配置文件等目录,包括nginx的配置文件、fcgi相关的配置等├─contrib├─html index.html└─src 源码目录├─core 核心源码目录,包括定义常用数据结构、体系结构实现等├─event 封装的事件系统源码目录├─http http服务器实现目录├─mail 邮件代码服务器实现目录├─misc 该目录当前版本只包含google perftools包└─os nginx对各操作系统下的函数进行封装以及实现核心调用的目录。
2.基本数据结构2.1.简单的数据类型在core/ngx_config.h 目录里面定义了基本的数据类型的映射,大部分都映射到c语言自身的数据类型。
typedef intptr_t ngx_int_t;typedef uintptr_t ngx_uint_t;typedef intptr_t ngx_flag_t;其中ngx_int_t,nginx_flag_t,都映射为intptr_t;ngx_uint_t映射为uintptr_t。
这两个类型在/usr/include/stdint.h的定义为:/* Types for `void *' pointers. */#if __WORDSIZE == 64# ifndef __intptr_t_definedtypedef long int intptr_t;# define __intptr_t_defined# endiftypedef unsigned long int uintptr_t;#else# ifndef __intptr_t_definedtypedef int intptr_t;# define __intptr_t_defined# endiftypedef unsigned int uintptr_t;#endif所以基本的操作和整形/指针类型的操作类似。
2.2.字符串的数据类型nginx对c语言的字符串类型进行了简单的封装,core/ngx_string.h/c里面包含这些封装的内容。
其中定义了ngx_str_t,ngx_keyval_t,ngx_variable_value_t这几个基础类型的定义如下:typedef struct{size_t len;u_char *data;} ngx_str_t;typedef struct{ngx_str_t key;ngx_str_t value;} ngx_keyval_t;typedef struct{unsigned len:28;unsigned valid:1;unsigned no_cacheable:1;unsigned not_found:1;unsigned escape:1;u_char *data;} ngx_variable_value_t;可以看出ngx_str_t 在原有的uchar* 的基础上加入的字符串长度的附加信息,初始化使用ngx_string宏进行,他的定义为:#define ngx_string(str){sizeof(str)-1,(u_char *) str }2.3.内存分配相关(1)系统功能封装内存相关的操作主要在os/unix/ngx_alloc.{h,c} 和core/ngx_palloc.{h,c} 下。
其中os/unix/ngx_alloc.{h,c} 封装了最基本的内存分配函数,是对c原有的malloc/free/memalign 等原有的函数的封装,对应的函数为:∙ngx_alloc 使用malloc分配内存空间∙ngx_calloc 使用malloc分配内存空间,并且将空间内容初始化为0∙ngx_memalign 返回基于一个指定的alignment大小的数值为对齐基数的空间∙ngx_free 对内存的释放操作(2)Nginx的内存池为了方便系统模块对内存的使用,方便内存的管理,nginx自己实现了进程池的机制来进行内存的分配和释放,首先nginx会在特定的生命周期帮你统一建立内存池,当需要进行内存分配的时候统一通过内存池中的内存进行分配,最后nginx会在适当的时候释放内存池的资源,开发者只要在需要的时候对内存进行申请即可,不用过多考虑内存的释放等问题,大大提高了开发的效率。
内存池的主要结构为://ngx_palloc.hstruct ngx_pool_s {ngx_pool_data_t d;size_t max;ngx_pool_t *current;ngx_chain_t *chain;ngx_pool_large_t *large;ngx_pool_cleanup_t *cleanup;ngx_log_t *log;};//ngx_core.htypedef struct ngx_pool_s ngx_pool_t;typedef struct ngx_chain_s ngx_chain_t;下面解释一下主要的几个操作:// 创建内存池ngx_pool_t *ngx_create_pool(size_t size, ngx_log_t *log);大致的过程是创建使用ngx_alloc 分配一个size大小的空间, 然后将 ngx_pool_t* 指向这个空间,并且初始化里面的成员, 其中p->st=(u_char *) p +sizeof(ngx_pool_t);// 初始指向ngx_pool_t 结构体后面p->d.end=(u_char *) p + size;// 整个结构的结尾后面p->max =(size < NGX_MAX_ALLOC_FROM_POOL)? size : NGX_MAX_ALLOC_FROM_POOL;// 最大不超过NGX_MAX_ALLOC_FROM_POOL,也就是getpagesize()-1 大小其他大都设置为null或者0// 销毁内存池void ngx_destroy_pool(ngx_pool_t *pool);遍历链表,所有释放内存,其中如果注册了clenup(也是一个链表结构),会一次调用clenup 的handler 进行清理。
// 重置内存池void ngx_reset_pool(ngx_pool_t *pool);释放所有large段内存,并且将d->last指针重新指向ngx_pool_t 结构之后(和创建时一样)// 从内存池里分配内存void*ngx_palloc(ngx_pool_t *pool, size_t size);void*ngx_pnalloc(ngx_pool_t *pool, size_t size);void*ngx_pcalloc(ngx_pool_t *pool, size_t size);void*ngx_pmemalign(ngx_pool_t *pool, size_t size, size_t alignment);ngx_palloc的过程一般为,首先判断待分配的内存是否大于pool->max的大小,如果大于则使用ngx_palloc_large 在large 链表里分配一段内存并返回,如果小于测尝试从链表的pool->current 开始遍历链表,尝试找出一个可以分配的内存,当链表里的任何一个节点都无法分配内存的时候,就调用ngx_palloc_block 生成链表里一个新的节点,并在新的节点里分配内存并返回,同时,还会将pool->current 指针指向新的位置(从链表里面pool->d.failed小于等于4的节点里找出),其他几个函数也基本上为ngx_palloc 的变种,实现方式大同小异// 释放指定的内存ngx_int_t ngx_pfree(ngx_pool_t *pool,void*p);这个操作只有在内存在large链表里注册的内存在会被真正释放,如果分配的是普通的内存,则会在destory_pool的时候统一释放.// 注册cleanup回叫函数(结构体)ngx_pool_cleanup_t *ngx_pool_cleanup_add(ngx_pool_t *p, size_t size);这个过程和我们之前经常使用的有些区别,他首先在传入的内存池中分配这个结构的空间(包括data段),然后将为结构体分配的空间返回,通过操作返回的ngx_pool_cleanup_t结构来添加回叫的实现。
(这个过程在nginx里面出现的比较多,也就是xxxx_add 操作通常不是实际的添加操作,而是分配空间并返回一个指针,后续我们还要通过操作指针指向的空间来实现所谓的add)2.4.Nginx的基本容器(1)ngx_array对应的文件为core/ngx_array.{c|h}ngx_array是nginx内部封装的使用ngx_pool_t对内存池进行分配的数组容器,其中的数据是在一整片内存区中连续存放的。
更新数组时只能在尾部压入1个或多个元素。
数组的实现结构为:struct ngx_array_s {void*elts;ngx_uint_t nelts;size_t size;ngx_uint_t nalloc;ngx_pool_t *pool;};其中elts 为具体的数据区域的指针,nelts 为数组实际包含的元素数量,size为数组单个元素的大小,nalloc为数组容器预先(或者重新)分配的内存大小,pool 为分配基于的内存池常用的操作有:// 创建一个新的数组容器ngx_array_t *ngx_array_create(ngx_pool_t *p, ngx_uint_t n, size_t size);// 销毁数组容器void ngx_array_destroy(ngx_array_t *a);// 将新的元素加入数组容器void*ngx_array_push(ngx_array_t *a);void*ngx_array_push_n(ngx_array_t *a, ngx_uint_t n);//返回n个元素的指针这里需要注意的是,和之前的ngx_pool_cleanup_add一样,ngx_array_push 只是进行内存分配的操作,我们需要对返回的指针指向的地址进行赋值等操作来实现实际数组值的添加。