java解析XML详解
- 格式:doc
- 大小:207.00 KB
- 文档页数:15

学习:Dom4j1、DOM4J简介DOM4J是 出品的一个开源XML 解析包。
DOM4J应用于Java 平台,采用了Java 集合框架并完全支持DOM,SAX 和JAXP。
DOM4J 使用起来非常简单。
只要你了解基本的XML-DOM 模型,就能使用。
Dom:把整个文档作为一个对象。
DOM4J 最大的特色是使用大量的接口。
它的主要接口都在org.dom4j里面定义:接口之间的继承关系如下:interface ng.Cloneableinterface org.dom4j.Nodeinterface org.dom4j.Attributeinterface org.dom4j.Branchinterface org.dom4j.Documentinterface org.dom4j.Elementinterface org.dom4j.CharacterDatainterface org.dom4j.CDATAinterface mentinterface org.dom4j.Textinterface org.dom4j.DocumentTypeinterface org.dom4j.Entityinterface org.dom4j.ProcessingInstruction2、XML文档操作12.1、读取XML文档:读写XML文档主要依赖于org.dom4j.io包,有DOMReader和SAXReader两种方式。
因为利用了相同的接口,它们的调用方式是一样的。
public static Docum ent load(String filenam e) {Document docum ent =null;try {SAXReader saxReader = new SAXReader();docum ent =saxReader.read(new File(filename)); //读取XML文件,获得docum ent 对象} catch (Exception ex) {ex.printStackTrace();}return docum ent;}或public static Docum ent load(URL url) {Document docum ent =null;try {SAXReader saxReader = new SAXReader();docum ent =saxReader.read(url); //读取XML文件,获得docum ent对象} catch (Exception ex) {ex.printStackTrace();}return docum ent;}//读取指定的xml文件之后返回一个Document对象,这个对象代表了整个XML文档,用于各种Do m运算。

java如何解析http请求返回的xml报⽂xml报⽂解析⽅法有很多种,此处采⽤dom4j的⽅法。
dom4j的jar包下载地址:https://dom4j.github.io/#1、request.getInputStream()和new SAXReader().read(输⼊流):返回的报⽂如下:<?xml version="1.0" encoding="UTF-8"?><CreateAccessKeyResponse> <CreateAccessKeyResult> <AccessKey> <UserName>aaa</UserName> <AccessKeyId>2019dfc6ab5fe433f10c</AccessKeyId> <Status>Active</Status> <IsPrimary>false</IsPrimary> <SecretAccessKey>a14aeb3ac35b835d5ec4507d5667a353c77ceedc</SecretAccessKey></AccessKey></CreateAccessKeyResult></CreateAccessKeyResponse>获取参数AccessKeyId的值:import org.dom4j.Document;import org.dom4j.Element;import org.dom4j.io.SAXReader;HttpURLConnection conn = create_AccessKey(); //create_AccessKey为⾃⼰写的http请求⽅法// 从request中取得输⼊流InputStream inputStream = conn.getInputStream();// 读取输⼊流SAXReader reader = new SAXReader();Document document = reader.read(inputStream);// 得到xml根元素Element root = document.getRootElement();String AK = root.element("CreateAccessKeyResult").element("AccessKey").element("AccessKeyId").getTextTrim();System.out.println("AccessKeyId="+AK+"\n");2、⽤dom4j读取xml⽂件中的参数:public void readXml() throws DocumentException, FileNotFoundException, IOException {String xml =System.getProperty("user.dir")+File.separator+"src"+File.separator+"test"+File.separator+"java"+File.separator+"http"+File.separator+"config.xml"; File xmlFile = new File(xml);SAXReader reader = new SAXReader();try {Document document = reader.read(xmlFile);Element root = document.getRootElement();AK = root.element("ak").getTextTrim();SK = root.element("sk").getTextTrim();} catch (Exception e) {e.printStackTrace();}}config.xml的内容如下:<?xml version="1.0" encoding="UTF-8"?><configuration> <ak>0d34d3db4bab560d343c</ak> <sk>a52628cb22b5a12642dd907075df6996b4c8a7b1</sk></configuration>。

java中xml进⾏报⽂发送和解析操作利⽤OKhttp⽹络框架,进⾏Maven项⽬管理//报⽂发送<dependency><groupId>com.squareup.okhttp3</groupId><artifactId>okhttp</artifactId><version>3.8.0</version></dependency>//报⽂解析<dependency><groupId>xom</groupId><artifactId>xom</artifactId><version>1.2.5</version></dependency>报⽂⽰例<STUDENT><AGE>18</AGE><NAME><XING>赵</XING><MING>明⽟</MING></NAME><NAME><XING>沙</XING><MING>明德</MING></NAME></STUDENT>报⽂拼接StringBuffer strBuff = new StringBuffer();strBuff.append("<STUDENT>");strBuff.append("<AGE>18</AGE>");strBuff.append("<NAME>");strBuff.append("<XING>赵</XING>");strBuff.append("<MING>明⽟</MING>");strBuff.append("</NAME>");strBuff.append("<NAME>");strBuff.append("<XING>沙</XING>");strBuff.append("<MING>明德</MING>");strBuff.append("</NAME>");strBuff.append("</STUDENT>");String xmlStr = strBuff.toString;报⽂发送,post请求接⼝调⽤,xmlStr为xml格式请求参数体public String postXml(String xmlStr){//可改变请求参数体编码GBK/UTF-8RequestBody body= RequestBody.create(MediaType.parse("application/xml;charset=GBK"), xmlStr);//url为接⼝地址Request requestOk = new Request.Builder().url("http://192.168.0.103:8007").post(body).build();//⽹络请求OkHttpClient client = new OkHttpClient.Builder().retryOnConnectionFailure(true).build();//可⼿动设置连接时长OkHttpClient client = new OkHttpClient().newBuilder().connectTimeout(60000, LISECONDS).readTimeout(60000, LISECONDS).build();//获取处理结果Response response = null;try {response = client.newCall(requestOk).execute();} catch (IOException e) {e.printStackTrace();}//获取响应String jsonString = response.body().string();return jsonString;}报⽂解析,进⾏实体解析//STUDENT为XML最⼤节点JAXBContext context = JAXBContext.newInstance(STUDENT.class);Unmarshaller unmarshaller = context.createUnmarshaller();//jsonString为报⽂响应STUDENT student = (STUDENT)unmarshaller.unmarshal(new StringReader(jsonString));实体类//XmlRootElement注解是将类与XML元素进⾏映射,XML节点与属性⼤⼩写保持⼀致@XmlRootElement(name ="STUDENT")public class STUDENT implements Serializable {private String AGE;private List<NAME> NAME;public String getAGE() {return AGE;}public void setAGE(String AGE) {this.AGE = AGE;}public List<NAME> getNAME() {return NAME;}public void setNAME(List<NAME> NAME) { = NAME;}@Overridepublic String toString() {return "Cccc{" +"AGE='" + AGE + '\'' +", NAME=" + NAME +'}';}}补充知识:Java发送内容为xml格式请求并解析返回json结果封装成静态请求⽅法:import java.io.BufferedReader;import java.io.IOException;import java.io.InputStreamReader;import java.io.OutputStreamWriter;import .ConnectException;import .MalformedURLException;import .URL;import .URLConnection;/*** 发送HTTP的⼀种⽅法* GaoLiang*/public class HttpSendUtil {public static String xmlPost(String urlStr, String xmlInfo) {try {URL url = new URL(urlStr);URLConnection con = url.openConnection();con.setDoOutput(true);// con.setRequestProperty("Pragma:", "no-cache");// con.setRequestProperty("Cache-Control", "no-cache");// ⼀定要设置报⽂格式,否则发送失败con.setRequestProperty("Content-Type", "text/xml");OutputStreamWriter out = null;try {out = new OutputStreamWriter(con.getOutputStream());} catch (ConnectException e) {// e.printStackTrace();return "Connection refused";}// System.out.println("urlStr=" + urlStr);// System.out.println("xmlInfo=" + xmlInfo);out.write(new String(xmlInfo.getBytes("ISO-8859-1")));out.flush();out.close();BufferedReader br = new BufferedReader(new InputStreamReader(con.getInputStream()));StringBuilder stringBuilder = new StringBuilder();String line = "";for (line = br.readLine(); line != null; line = br.readLine()) {// System.out.println(line);stringBuilder.append(line);}return stringBuilder.toString();} catch (MalformedURLException e) {e.printStackTrace();} catch (IOException e) {e.printStackTrace();}return null;}在外部调⽤静态⽅法:// 请求的xml服务地址String url = url;// 请求参数由于是⼿动拼写的参数很长看起来也不美观就不放了(⼿动哭脸)String param = "" ;// 发送请求调⽤上⾯的静态⽅法String ret = xmlPost(url,param);// 得到的是xml格式的返回结果但是⾥⾯的“<”,“>”都是“<”,“>”显⽰所以就需要解析,具体解析见下表ret = ret.replaceAll("<", "<");ret = ret.replaceAll(">", ">");ret = ret.replaceAll("&", "&");ret = ret.replaceAll(""", "\"");ret = ret.replaceAll("'", "\'");// 因为接⼝最终要返回的是json格式所以还要把想要的值取出来解析成String// 解析拿到节点⾥想要的值Document document = DocumentHelper.parseText(ret);// 根节点这⾥不⼀定要和根节点取⼀样的名字可⾃定义这么写是⽅便理解Element root = document.getRootElement();// root节点下的⼦节点Element business = root.element("business");//解析完取到business节点下的值String healthCode = business.getStringValue();// 拼接返回值Map<String,Object> thisResult = new HashMap();thisResult.put("healthCode",healthCode);resultList.add(thisResult);// 统⼀返回值Map<String,Object> returnset = new HashMap<>();xml解析五种格式:补充⼀下:xml返回结果类似于这样<?xml version="1.0" encoding="utf-8" ?><Root><business>我想要的值:healthCode</business ></Root>最后,由于时间⽐较匆忙,⼜没有接触过xml格式请求,确实折磨了我⼀阵⼦时间,搜了好多⼤神写的博客,最终整理出⾃⼰的。

JavaXML解析的四种⽅法(连载)1. xml简介 XML:指可扩展标记语⾔, Extensible Markup Language;类似HTML。
XML的设计宗旨是传输数据,⽽⾮显⽰数据。
⼀个xml⽂档实例:1 <?xml version="1.0" encoding="UTF-8"?>2 <company name="Tencent" address="深圳市南⼭区">3 <department deptNo="001" name="development">4 <employee id="devHead" position="minister">许刚</employee>5 <employee position="developer">⼯程师A</employee>6 </department>7 <department deptNo="002" name="education">8 <employee position="minister" telephone="1234567">申林</employee>9 <employee position="trainee">实习⽣A</employee>10 </department>11 </company> 第⼀⾏是 XML 声明。
它定义 XML 的版本 (1.0) 和所使⽤的编码. 下⼀⾏描述⽂档的根元素:<company>开始,该根元素具有2个属性“name”,"address"。

文章标题:深入探讨Java XML解析器的使用方法与技巧一、引言:解析XML在Java中的重要性XML作为一种可扩展的标记语言,被广泛应用于数据交换和存储的场景中。
在Java开发中,对XML的解析是一项非常常见的任务,它涉及到从XML文档中提取数据、修改数据以及创建新的XML文档等方面。
对于Java开发者来说,掌握XML解析器的使用方法与技巧是非常重要的。
二、Java中常见的XML解析器介绍在Java中,常见的XML解析器主要包括DOM解析器、SAX解析器和StAX解析器。
下面将针对这三种解析器进行详细介绍,并分别分析它们的优缺点和适用场景。
1. DOM解析器DOM(Document Object Model)解析器将整个XML文档解析成内存中的一个树形结构,因此适合于对XML文档进行随机访问和修改。
但是,由于DOM解析器需要将整个文档加载到内存中,对于大型XML文档来说,可能会占用过多的内存,因此不适合对大型XML文档进行解析。
2. SAX解析器SAX(Simple API for XML)解析器是一种基于事件驱动的解析器,它逐行解析XML文档,只在遇到标签开始、标签结束和文本内容时触发相应的事件,从而大大减小了内存开销。
SAX解析器适合用于对大型XML文档进行顺序读取和简单处理。
3. StAX解析器StAX(Streaming API for XML)解析器是一种基于迭代器的解析器,它允许开发者以类似流的方式读写XML文档,同时也支持部分随机访问功能。
由于StAX解析器结合了DOM和SAX解析器的优点,因此在某些场景下可以取得很好的效果。
三、Java中使用XML解析器的常见场景和技巧1. 选择合适的解析器在实际开发中,选择合适的解析器非常重要。
如果需要对XML文档进行较为复杂的处理,并且内存资源充足,那么可以选择DOM解析器;如果需要对大型XML文档进行顺序读取和简单处理,那么可以选择SAX解析器;如果需要兼顾随机访问和内存占用的平衡,那么可以选择StAX解析器。

Java动态⽣成和解析xml⽂件步骤详解⾸先声明,这个地⽅是利⽤dom4j进⾏解析和⽣成,需要⽤到dom4j的jar包,所以⾸先需要我们获取jar包:<dependency><groupId>dom4j</groupId><artifactId>dom4j</artifactId><version>1.6.1</version></dependency>⽣成xml⽂件代码案列:package day12;import java.io.FileOutputStream;import java.util.ArrayList;import java.util.List;import org.dom4j.Document;import org.dom4j.DocumentHelper;import org.dom4j.Element;import org.dom4j.io.OutputFormat;import org.dom4j.io.XMLWriter;/*** 写出XML⽂档*/public class WriteXmlDemo {public static void main(String[] args) {List<Emp> empList = new ArrayList<Emp>();empList.add(new Emp(1,"张三",22,"男",3000));empList.add(new Emp(2,"李四",23,"⼥",4000));empList.add(new Emp(3,"王五",24,"男",5000));empList.add(new Emp(4,"赵六",25,"⼥",6000));empList.add(new Emp(5,"钱七",26,"男",7000));empList.add(new Emp(6,"传奇",21,"男",8000));/** 写出XML⽂档的⼤致步骤* 1.创建空⽩⽂档对象Document* 2.向该⽂档中添加根元素* 3.按照规定的XML⽂档结构从根元素开始,逐级添加⼦元素,已完成该结构* 4.创建XMLWriter* 5.将Document对象写出成XML⽂档* 6.将XMLWriter关闭*///1Document doc = DocumentHelper.createDocument();/** 2.Element addElement(String name)* Document提供的该⽅法是⽤来向当前⽂档中添加给定名字的根元素。

java xml标签详解在Java中处理XML通常涉及XML文档和它们之间的结构、元素、属性和文本。
在XML文档中,元素是内容的边界,而属性是附加到元素上的键值对。
以下是一些基本的XML标签概念:1.元素(Element): XML元素是由开始标签、结束标签(有些元素可能没有结束标签)和元素之间的内容组成的。
例如,<name>John Doe</name>。
2.开始标签(Start Tag): 开始标签用于标记元素的开始,例如<name>。
3.结束标签(End Tag): 结束标签用于标记元素的结束,并使用/符号来表示。
例如</name>。
4.空元素(Empty Element): 空元素只有一个开始标签,没有结束标签。
例如<br/>。
5.属性(Attribute): 属性是附加到元素上的键值对。
它们在开始标签中定义,由键值对的形式出现(key="value")。
例如<element attribute="value">。
6.文本(Text): 文本是元素之间的内容,例如<name>John Doe</name>中的 "John Doe"。
7.命名空间(Namespace): 命名空间用于区分具有相同名称的元素或属性。
它们通常在开始标签中定义,例如<element xmlns="namespaceURI">。
8.CDATA(Character Data): CDATA用于包含可能被解析为XML标记的文本。
例如,如果您有一个包含大量HTML的XML元素,您可以使用CDATA来避免HTML被解析为XML。
示例:<![CDATA[Some text <em>more text</em>]]>。

java使⽤document解析xml⽂件准备⼯作:1创建java⼯程2创建xml⽂档。
完成后看下⾯代码:import org.w3c.dom.*;import javax.xml.parsers.DocumentBuilder;import javax.xml.parsers.DocumentBuilderFactory;public class Main {public static void main(String[] args) throws Exception {//创建⼀个⽂档解析器⼯⼚DocumentBuilderFactory fac= DocumentBuilderFactory.newInstance();//⽤上⾯的⼯⼚创建⼀个⽂档解析器DocumentBuilder builder=fac.newDocumentBuilder();//⽤上⾯的⽂档解析器解析⼀个⽂件放到document对象⾥Document doc=builder.parse("src/server.xml");//获取⽂档中节点名称为Listener的所有节点,并返回⼀个节点集合NodeList listenerList=doc.getElementsByTagName("Listener");System.out.println("⼀共有"+listenerList.getLength()+"个节点");//遍历整个集合(把所有标签名为Listener的节点⼀个⼀个拿出来for (int i=0;i<listenerList.getLength();i++){System.out.println("===========这是第"+(i+1)+"个listener节点的开始:===========");//把集合⾥的每⼀个listener节点分别拿出来Node node=listenerList.item(i);//再把上⼀个节点中的所有属性拿出来NamedNodeMap nodeMap= node.getAttributes();System.out.println("第"+(i+1)+"个节点⼀共有"+nodeMap.getLength()+"个属性");//遍历所有属性for(int j=0;j<nodeMap.getLength();j++){Node node1=nodeMap.item(j);System.out.println("第"+(j+1)+"个属性的名称是"+node1.getNodeName());System.out.println("第"+(j+1)+"个属性的值是"+node1.getNodeValue());}//获取节点的所有⼦节点,注意会把所有换⾏符也解析为⼦节点NodeList childNode=node.getChildNodes();//遍历所有⼦节点for(int k=0;k<childNode.getLength();k++){if(childNode.item(k).getNodeType()==Node.ELEMENT_NODE){//这个过滤条件是只将标签节点保留(换⾏符的节点就删去)}System.out.println("===========这是第"+(i+1)+"个节点的结束:===========");}}}为了⽅便记忆,在这⾥拆解⼀下。

java解析xml的4种⽅式的优缺点对⽐及实现详解⼀、介绍及优缺点分析DOM(Document Object Model)DOM是⽤与平台和语⾔⽆关的⽅式表⽰XML⽂档的官⽅W3C标准。
DOM是以层次结构组织的节点或信息⽚断的集合。
这个层次结构允许开发⼈员在树中寻找特定信息。
分析该结构通常需要加载整个⽂档和构造层次结构,然后才能做任何⼯作。
由于它是基于信息层次的,因⽽DOM被认为是基于树或基于对象的。
【优点】①允许应⽤程序对数据和结构做出更改。
②访问是双向的,可以在任何时候在树中上下导航,获取和操作任意部分的数据。
整个⽂档树在内存中,便于操作;⽀持删除、修改、重新排列等多种功能【缺点】①通常需要加载整个XML⽂档来构造层次结构,消耗资源⼤。
将整个⽂档调⼊内存(包括⽆⽤的节点),浪费时间和空间;使⽤场合:⼀旦解析了⽂档还需多次访问这些数据;硬件资源充⾜(内存、CPU)SAX(Simple API for XML)SAX处理的优点⾮常类似于流媒体的优点。
分析能够⽴即开始,⽽不是等待所有的数据被处理。
⽽且,由于应⽤程序只是在读取数据时检查数据,因此不需要将数据存储在内存中。
这对于⼤型⽂档来说是个巨⼤的优点。
事实上,应⽤程序甚⾄不必解析整个⽂档;它可以在某个条件得到满⾜时停⽌解析。
⼀般来说,SAX还⽐它的替代者DOM快许多。
选择DOM还是选择SAX?对于需要⾃⼰编写代码来处理XML⽂档的开发⼈员来说,选择DOM还是SAX解析模型是⼀个⾮常重要的设计决策。
DOM采⽤建⽴树形结构的⽅式访问XML⽂档,⽽SAX采⽤的是事件模型。
DOM解析器把XML⽂档转化为⼀个包含其内容的树,并可以对树进⾏遍历。
⽤DOM解析模型的优点是编程容易,开发⼈员只需要调⽤建树的指令,然后利⽤navigation APIs访问所需的树节点来完成任务。
可以很容易的添加和修改树中的元素。
然⽽由于使⽤DOM解析器的时候需要处理整个XML⽂档,所以对性能和内存的要求⽐较⾼,尤其是遇到很⼤的XML⽂件的时候。
在Java中使⽤xpath对xml解析个⼈博客地址:xpath是⼀门在xml⽂档中查找信息的语⾔。
xpath⽤于在XML⽂档中通过元素和属性进⾏导航。
它的返回值可能是节点,节点集合,⽂本,以及节点和⽂本的混合等。
在学习本⽂档之前应该对XML的节点,元素,属性,⽂本,处理指令,注释,根节点,命名空间以及节点关系有⼀定的了解以及对xpath也有了解。
XML学习地址:xpath基本语法学习地址:xpath官⽅⽂档:https:///cvc4tEIGy5EvS访问密码 9d16本⽂主要介绍:Java中使⽤xpath操作对xml操作。
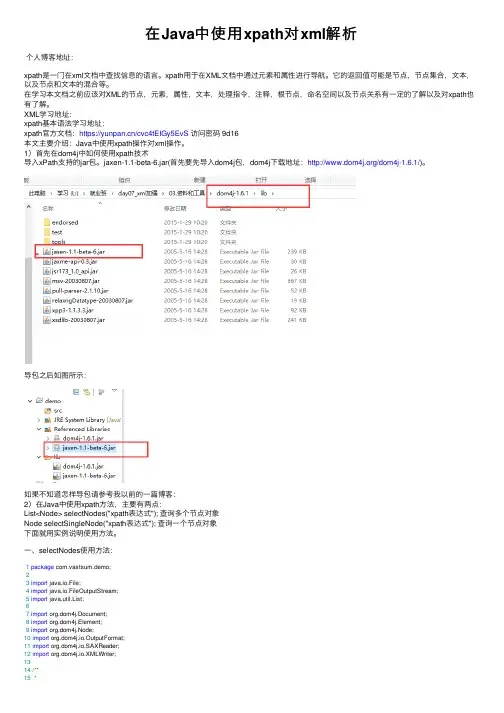
1)⾸先在dom4j中如何使⽤xpath技术导⼊xPath⽀持的jar包。
jaxen-1.1-beta-6.jar(⾸先要先导⼊dom4j包,dom4j下载地址:/dom4j-1.6.1/)。
导包之后如图所⽰:如果不知道怎样导包请参考我以前的⼀篇博客:2)在Java中使⽤xpath⽅法,主要有两点:List<Node> selectNodes("xpath表达式"); 查询多个节点对象Node selectSingleNode("xpath表达式"); 查询⼀个节点对象下⾯就⽤实例说明使⽤⽅法。
⼀、selectNodes使⽤⽅法:1package com.vastsum.demo;23import java.io.File;4import java.io.FileOutputStream;5import java.util.List;67import org.dom4j.Document;8import org.dom4j.Element;9import org.dom4j.Node;10import org.dom4j.io.OutputFormat;11import org.dom4j.io.SAXReader;12import org.dom4j.io.XMLWriter;1314/**15 *16 * @author shutu00817 *selectNode的使⽤⽅法18*/19public class xpathDemo {2021public static void main(String[] args) throws Exception {2223 Document doc = new SAXReader().read(new File("./src/contact.xml"));2425/**26 * @param xpath 表⽰xpath语法变量27*/28 String xpath="";2930/**31 * 1. / 绝对路径表⽰从xml的根位置开始或⼦元素(⼀个层次结构)32*/33 xpath = "/contactList";34 xpath = "/contactList/contact";3536/**37 * 2. // 相对路径表⽰不分任何层次结构的选择元素。

java 会计档案xml解析在当今数字化时代,会计领域的信息处理变得越来越重要。
随着企业数量的增长和财务数据的复杂性,需要一种高效、可靠的方式来处理会计档案。
XML(可扩展标记语言)作为一种常用的数据交换格式,被广泛应用于会计领域。
Java作为一种强大而灵活的编程语言,提供了许多工具和库来解析和处理XML文件。
在会计档案XML解析中,Java的优势得到了充分的发挥。
下面将介绍一些主要的Java XML解析库和技术,以及它们在会计档案处理中的应用。
1. DOM(文档对象模型)解析DOM解析器将整个XML文档加载到内存中,并构建一个树形结构,以便于对文档进行操作。
在会计档案XML解析中,DOM解析器可以方便地遍历XML文档的节点,提取和修改数据。
然而,由于DOM解析器将整个文档加载到内存中,对于大型XML文件来说,内存消耗较大。
2. SAX(简单API for XML)解析SAX解析器以事件驱动的方式逐行读取XML文档,并触发相应的事件。
在会计档案XML解析中,SAX解析器可以高效地处理大型XML文件,因为它不需要将整个文档加载到内存中。
通过实现SAX 解析器的回调函数,可以在遍历过程中处理和提取数据。
3. JAXB(Java体系结构的XML绑定)解析JAXB是Java提供的一种用于将XML文档与Java对象之间进行转换的技术。
在会计档案XML解析中,可以使用JAXB将XML文档映射到Java对象上,从而方便地进行数据操作和处理。
JAXB提供了注解和配置文件来定义XML文档和Java对象之间的映射关系。
除了上述的XML解析库和技术,还有其他一些Java工具和库,如JDOM、Xerces和StAX等,也可以用于会计档案XML解析。
根据具体的需求和项目要求,可以选择合适的解析方式。
在实际应用中,会计档案XML解析的过程可能涉及到数据验证、数据转换、数据存储等多个环节。
因此,除了XML解析技术外,还需要结合其他相关的Java技术和数据库技术来完成整个处理流程。
java xml格式返回报文解析Java中可以使用多种方式解析XML格式的返回报文,常见的方式有DOM解析、SAX解析以及基于XML绑定技术的解析。
每种方式都有不同的特点和适用场景,下面将详细介绍这三种解析方式。
1. DOM解析:DOM(Document Object Model)解析是将整个XML文档加载到内存中,构建成一个树形结构,并提供API来操作这个树。
DOM解析提供了许多API,可以通过节点遍历和搜索、属性读取和设置、节点创建和删除等方式来处理XML文档。
DOM解析适用于对XML文档进行多次读写操作,如增删改查等复杂的操作。
使用Java的DOM解析,可以通过以下几个步骤实现:1)使用DocumentBuilderFactory创建一个DocumentBuilder对象。
2)调用DocumentBuilder的parse方法,传入XML文件的输入流,将XML文档解析为一个Document对象。
3)通过Document对象可以获取XML文档的根元素,从而开始对XML文档进行遍历和操作。
DOM解析的优点是能够将整个XML文档加载到内存中,便于操作和修改。
但是对于较大的XML文件,DOM解析会消耗大量的内存空间。
2. SAX解析:SAX(Simple API for XML)解析是一种基于事件驱动的解析方式,它逐行读取XML文档并触发相应的事件,应用程序根据事件的发生来处理XML文档。
SAX解析的特点是速度快、内存消耗小,适用于对XML文档进行单次顺序读取的操作。
使用Java的SAX解析,可以通过以下几个步骤实现:1)定义一个继承自DefaultHandler的处理器类,重写相应的事件回调方法。
2)使用SAXParserFactory创建一个SAXParser对象。
3)调用SAXParser的parse方法,传入XML文件的输入流和处理器对象,开始解析XML文档。
SAX解析的优点是速度快,内存消耗小,适用于大型XML文件的解析。
javax.xml用法javax.xml是Java语言中用于处理XML(可扩展标记语言)的标准扩展。
它提供了一组类和接口,用于解析、生成和操作XML文档。
下面从多个角度来介绍javax.xml的用法:1. XML解析,javax.xml提供了许多类和接口,如DocumentBuilder和XPath,可以用于解析XML文档。
你可以使用DocumentBuilder来将XML文档解析为DOM(文档对象模型)树,然后使用XPath来查询和操作DOM树中的元素和属性。
2. XML生成,除了解析外,javax.xml还提供了一些类和接口,如Transformer和XMLStreamWriter,用于生成XML文档。
你可以使用Transformer将DOM树转换为XML文档,也可以使用XMLStreamWriter来以流的方式生成XML文档。
3. 数据绑定,javax.xml.bind包提供了将Java对象与XML文档相互转换的功能。
你可以使用注解来标记Java类,然后使用JAXBContext和Unmarshaller/Marshaller来实现Java对象与XML文档之间的转换。
4. 验证,javax.xml.validation包中的类和接口可以用于对XML文档进行验证。
你可以使用Schema来定义XML文档的结构,并使用Validator来验证XML文档是否符合指定的结构。
5. Web服务,javax.xml.ws包提供了用于开发基于XML的Web 服务的API。
你可以使用其中的类和接口来创建、发布和调用基于XML的Web服务。
总之,javax.xml提供了丰富的功能和API,用于处理XML文档和开发基于XML的应用程序。
通过使用这些类和接口,你可以轻松地解析、生成、操作和验证XML文档,以及开发基于XML的Web服务。
希望这些信息能够帮助你更好地理解javax.xml的用法。
java读取xml⽂件以及Jsoup解析xml基本介绍xml基本语法:1.xml⽂档的后缀名为.xml2.xml第⼀⾏必须定义为⽂档声明3.xml⽂档有且仅有⼀个根标签4.属性值必须使⽤引号(单双都可以)引起来5.标签必须正确关闭6.xml标签名区分⼤⼩写组成部分1.⽂档声明格式:<?xml 属性列表 ?>version:版本号(必须); encoding:编码格式; standalone:是否独⽴取值:yes,no2.标签:名称⾃定义,并且按照规则3.属性:id属性值唯⼀4.⽂本:CDATA区:在该区域中的数据会被原样展⽰,格式:<![CDATA[ 数据 ]]>约束:规定xml⽂档的书写规则dtd:简单的约束技术schema:复杂的约束技术DTD:内部dtd:将约束规则定义在xml⽂档中;外部dtd:将约束定义在外部dtd⽂件中外部dtd:本地:<! DOCTYPE 根标签名 SYSTEM "dtd⽂件的位置">⽹络:<! DOCTYPE 根标签名 PUBLIC "dtd⽂件名字" "dtd⽂件的位置URL">java解析xml⽂件的⼏种⽅法解析xml有两种形式,其分别为:1. DOM:将标记语⾔⽂档⼀次性加载进内存,在内存中形成⼀颗dom树优点:操作⽅便,可以对⽂档进⾏CRUD(增删改查)的所有操作缺点:占内存2. SAX:逐⾏读取,基于事件驱动优点:不占内存缺点:只能读取以下⾯这个简单的xml⽂件的解析为例,具体内容参考https:///xmldom/dom_parser.asp<?xml version="1.0" encoding="UTF-8"?><peoples><people number="1"><name id="zs">张三</name><age>12</age></people><people><name>李四</name><age>15</age></people></peoples>第⼀种,使⽤DOM对xml进⾏解析import org.w3c.dom.Document;import org.w3c.dom.Element;import org.w3c.dom.NodeList;import java.io.File;import javax.xml.parsers.DocumentBuilder;import javax.xml.parsers.DocumentBuilderFactory;public class testXml {public static void main(String[] args) {try{File xml = new File("test/test.xml");DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();DocumentBuilder builder = factory.newDocumentBuilder();Document doc = builder.parse(xml);NodeList list = doc.getElementsByTagName("people");for(int i=0;i<list.getLength();i++){Element e = (Element)list.item(i);System.out.println("姓名:"+e.getElementsByTagName("name").item(0).getFirstChild().getNodeValue()+"年龄:"+e.getElementsByTagName("age").item(0).getFirstChild().getNodeValue());}}catch (Exception e){e.printStackTrace();}}}第⼆种形式,DOM4J进⾏解析import java.io.*;import java.util.*;import org.dom4j.*;import org.dom4j.io.*;public class testDOM4J {public static void main(String[] args) {try{File f = new File("test/test.xml");SAXReader reader = new SAXReader();Document doc = reader.read(f);Element root = doc.getRootElement();Element n;for (Iterator i=root.elementIterator("people");i.hasNext();) {n = (Element) i.next();System.out.println("姓名:"+n.elementText("name")+" 年龄:"+n.elementText("age"));}}catch(Exception e){e.printStackTrace();}}}第三种形式,JDOM进⾏解析import java.util.*;import org.jdom2.*;import org.jdom2.input.*;import java.io.File;public class testJDOM {public static void main(String[] args) {try{File f = new File("test/test.xml");SAXBuilder builder = new SAXBuilder();Document doc = builder.build(f);Element e = doc.getRootElement();List li = e.getChildren();Element temp;for(int i=0;i<li.size();i++){temp = (Element) li.get(i);System.out.println("姓名:"+temp.getChild("name").getText()+" 年龄:"+temp.getChild("age").getText());}}catch (Exception e){e.printStackTrace();}}}Jsoup是⼀款Java 的HTML解析器,可直接解析某个URL地址、HTML、XML⽂本内容。
Java解析XML的四种方法概序XML现在已经成为一种通用的数据交换格式,它的平台无关性,语言无关性,系统无关性,给数据集成与交互带来了极大的方便。
XML文件解析方法XML在不同的语言里解析方式都是一样的,只不过实现的语法不同而已。
基本的解析方式有两种,一种叫SAX,另一种叫DOM。
SAX是基于事件流的解析,DOM是基于XML文档树结构的解析。
假设我们XML的内容和结构如下:<?xml version="1.0" encoding="UTF-8"?><employees><employee><name>ddviplinux</name><sex>m</sex><age>30</age></employee></employees>本文实现DOM与SAX的XML文档生成与解析。
首先定义一个操作XML文档的接口XmlDocument 它定义了XML文档的建立与解析的接口。
package com.alisoft.facepay.framework.bean;/**** @author hongliang.dinghl* 定义XML文档建立与解析的接口*/public interface XmlDocument {/*** 建立XML文档* @param fileName 文件全路径名称*/public void createXml(String fileName);/*** 解析XML文档* @param fileName 文件全路径名称*/public void parserXml(String fileName);}1.DOM生成和解析XML文档为 XML 文档的已解析版本定义了一组接口。
解析器读入整个文档,然后构建一个驻留内存的树结构,然后代码就可以使用 DOM 接口来操作这个树结构。
一、概述随着互联网的不断发展,各种Web服务也愈发普及,而这些Web服务通常都是通过HTTP协议来进行通信的。
在Web服务之间进行通信时,数据的传递通常采用XML格式,而Java作为一种常用的编程语言,在处理XML格式数据时也是非常常见的。
二、XML格式返回报文解析的重要性1. XML格式返回报文在Web服务中的应用在Web服务中,XML格式的返回报文被广泛应用于数据的传输和交换。
而对于接收到的XML格式返回报文,需要进行解析和处理,才能够得到其中的有用信息。
2. Java在XML解析中的重要性在Java中,有许多用于解析XML格式数据的工具和库,比如DOM、SAX、JAXB等。
正确地使用这些工具和库,可以高效地对XML格式返回报文进行解析,从而获取其中的数据。
三、Java中XML格式返回报文解析的方法1. 使用DOM进行XML解析DOM(Document Object Model)是一种基于树形结构的XML解析模型,它将整个XML文档作为一个树形结构加载到内存中,并提供了一系列的API来操作这个树形结构。
通过使用DOM,可以方便地对XML格式返回报文进行遍历和操作,获取其中的数据。
2. 使用SAX进行XML解析SAX(Simple API for XML)是一种基于事件驱动的XML解析模型,它以事件驱动的方式逐行扫描XML文档,并触发相应的事件进行解析。
相比DOM,SAX在解析大型XML文档时占用的内存较少,因此性能更优。
通过使用SAX,可以高效地对XML格式返回报文进行解析,获取其中的数据。
3. 使用JAXB进行XML解析JAXB(Java Architecture for XML Binding)是一种将XML数据转换为Java对象的技术,它通过注解和Java类的映射关系,实现了XML数据的自动绑定和解析。
通过使用JAXB,可以将XML格式返回报文直接映射为Java对象,从而方便地进行数据操作和处理。
在Java中解析XML字符串可以使用多种方法,其中最常见的是使用Java内置的DOM、SAX和StAX API。
1.DOM解析器DOM解析器将XML文档转换为树形结构,并允许您通过编程方式遍历和操作该树形结构。
以下是一个简单的示例,演示如何使用DOM解析器解析XML字符串:java复制代码import javax.xml.parsers.DocumentBuilderFactory;import javax.xml.parsers.DocumentBuilder;import org.w3c.dom.Document;import org.w3c.dom.Element;import org.w3c.dom.NodeList;public class DOMExample {public static void main(String[] args)throws Exception {String xmlString = "<root><element>text</element></root>";DocumentBuilderFactory factory =DocumentBuilderFactory.newInstance();DocumentBuilder builder = factory.newDocumentBuilder();Document document = builder.parse(new InputSource(newStringReader(xmlString)));document.getDocumentElement().normalize();System.out.println("Root element: " +document.getDocumentElement().getNodeName());NodeList nodeList = document.getElementsByTagName("element");for (int i = 0; i < nodeList.getLength(); i++) {Element element = (Element) nodeList.item(i);System.out.println("Element: " + element.getTextContent());}}}2.SAX解析器SAX解析器是一种基于事件的解析器,它按顺序读取XML文档,并在读取每个元素时触发事件。
详解Java解析XML的四种方法XML现在已经成为一种通用的数据交换格式,它的平台无关性,语言无关性,系统无关性,给数据集成与交互带来了极大的方便。
对于XML本身的语法知识与技术细节,需要阅读相关的技术文献,这里面包括的内容有DOM(Document Object Model),DTD(Document Type Definition),SAX(Simple API for XML),XSD(Xml Schema Definition),XSLT(Extensible Stylesheet Language Transformations),具体可参阅w3c官方网站文档获取更多信息。
XML在不同的语言里解析方式都是一样的,只不过实现的语法不同而已。
基本的解析方式有两种,一种叫SAX,另一种叫DOM。
SAX是基于事件流的解析,DOM是基于XML文档树结构的解析。
假设我们XML的内容和结构如下:<?xml version="1.0" encoding="UTF-8"?><employees><employee><name>ddviplinux</name><sex>m</sex><age>30</age></employee></employees>本文使用JAVA语言来实现DOM与SAX的XML文档生成与解析。
首先定义一个操作XML文档的接口XmlDocument 它定义了XML文档的建立与解析的接口。
package com.alisoft.facepay.framework.bean;/**** @author hongliang.dinghl* 定义XML文档建立与解析的接口*/public interface XmlDocument {/*** 建立XML文档* @param fileName 文件全路径名称*/public void createXml(String fileName);/*** 解析XML文档* @param fileName 文件全路径名称*/public void parserXml(String fileName);}1. DOM生成和解析XML文档为 XML 文档的已解析版本定义了一组接口。
解析器读入整个文档,然后构建一个驻留内存的树结构,然后代码就可以使用 DOM 接口来操作这个树结构。
优点:整个文档树在内存中,便于操作;支持删除、修改、重新排列等多种功能;缺点:将整个文档调入内存(包括无用的节点),浪费时间和空间;使用场合:一旦解析了文档还需多次访问这些数据;硬件资源充足(内存、CPU)。
import java.io.FileInputStream;import java.io.FileNotFoundException;import java.io.FileOutputStream;import java.io.IOException;import java.io.InputStream;import java.io.PrintWriter;import javax.xml.parsers.DocumentBuilder;import javax.xml.parsers.DocumentBuilderFactory;import javax.xml.parsers.ParserConfigurationException;import javax.xml.transform.OutputKeys;import javax.xml.transform.Transformer;import javax.xml.transform.TransformerConfigurationException;import javax.xml.transform.TransformerException;import javax.xml.transform.TransformerFactory;import javax.xml.transform.dom.DOMSource;import javax.xml.transform.stream.StreamResult;import org.w3c.dom.Document;import org.w3c.dom.Element;import org.w3c.dom.Node;import org.w3c.dom.NodeList;import org.xml.sax.SAXException;/**** @author hongliang.dinghl* DOM生成与解析XML文档*/public class DomDemo implements XmlDocument {private Document document;private String fileName;public void init() {try {DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();DocumentBuilder builder = factory.newDocumentBuilder();this.document = builder.newDocument();} catch (ParserConfigurationException e) {System.out.println(e.getMessage());}}public void createXml(String fileName) {Element root = this.document.createElement("employees");this.document.appendChild(root);Element employee = this.document.createElement("employee");Element name = this.document.createElement("name");name.appendChild(this.document.createTextNode("丁宏亮"));employee.appendChild(name);Element sex = this.document.createElement("sex");sex.appendChild(this.document.createTextNode("m"));employee.appendChild(sex);Element age = this.document.createElement("age");age.appendChild(this.document.createTextNode("30"));employee.appendChild(age);root.appendChild(employee);TransformerFactory tf = TransformerFactory.newInstance();try {Transformer transformer = tf.newTransformer();DOMSource source = new DOMSource(document);transformer.setOutputProperty(OutputKeys.ENCODING, "gb2312");transformer.setOutputProperty(OutputKeys.INDENT, "yes");PrintWriter pw = new PrintWriter(new FileOutputStream(fileName));StreamResult result = new StreamResult(pw);transformer.transform(source, result);System.out.println("生成XML文件成功!");} catch (TransformerConfigurationException e) {System.out.println(e.getMessage());} catch (IllegalArgumentException e) {System.out.println(e.getMessage());} catch (FileNotFoundException e) {System.out.println(e.getMessage());} catch (TransformerException e) {System.out.println(e.getMessage());}}public void parserXml(String fileName) {try {DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();DocumentBuilder db = dbf.newDocumentBuilder();Document document = db.parse(fileName);NodeList employees = document.getChildNodes();for (int i = 0; i < employees.getLength(); i++) {Node employee = employees.item(i);NodeList employeeInfo = employee.getChildNodes();for (int j = 0; j < employeeInfo.getLength(); j++) {Node node = employeeInfo.item(j);NodeList employeeMeta = node.getChildNodes();for (int k = 0; k < employeeMeta.getLength(); k++) {System.out.println(employeeMeta.item(k).getNodeName()+ ":" + employeeMeta.item(k).getTextContent());}}}System.out.println("解析完毕");} catch (FileNotFoundException e) {System.out.println(e.getMessage());} catch (ParserConfigurationException e) {System.out.println(e.getMessage());} catch (SAXException e) {System.out.println(e.getMessage());} catch (IOException e) {System.out.println(e.getMessage());}}}2. SAX生成和解析XML文档为解决DOM的问题,出现了SAX。