自适应滤波LMS算法及RLS算法及其仿真
- 格式:doc
- 大小:413.70 KB
- 文档页数:18

自适应滤波第1章绪论 (1)1.1自适应滤波理论发展过程 (1)1.2自适应滤波发展前景 (2)1.2.1小波变换与自适应滤波 (2)1.2.2模糊神经网络与自适应滤波 (3)第2章线性自适应滤波理论 (4)2.1最小均方自适应滤波器 (4)2.1.1最速下降算法 (4)2.1.2最小均方算法 (6)2.2递归最小二乘自适应滤波器 (7)第3章仿真 (12)3.1基于LMS算法的MATLAB仿真 (12)3.2基于RLS算法的MATLAB仿真 (15)组别:第二小组组员:黄亚明李存龙杨振第1章绪论从连续的(或离散的)输入数据中滤除噪声和干扰以提取有用信息的过程称为滤波。
相应的装置称为滤波器。
实际上,一个滤波器可以看成是一个系统,这个系统的目的是为了从含有噪声的数据中提取人们感兴趣的、或者希望得到的有用信号,即期望信号。
滤波器可分为线性滤波器和非线性滤波器两种。
当滤波器的输出为输入的线性函数时,该滤波器称为线性滤波器,当滤波器的输出为输入的非线性函数时,该滤波器就称为非线性滤波器。
自适应滤波器是在不知道输入过程的统计特性时,或是输入过程的统计特性发生变化时,能够自动调整自己的参数,以满足某种最佳准则要求的滤波器。
1.1自适应滤波理论发展过程自适应技术与最优化理论有着密切的系。
自适应算法中的最速下降算法以及最小二乘算法最初都是用来解决有/无约束条件的极值优化问题的。
1942年维纳(Wiener)研究了基于最小均方误差(MMSE)准则的在可加性噪声中信号的最佳滤波问题。
并利用Wiener.Hopf方程给出了对连续信号情况的最佳解。
基于这~准则的最佳滤波器称为维纳滤波器。
20世纪60年代初,卡尔曼(Kalman)突破和发展了经典滤波理论,在时间域上提出了状态空间方法,提出了一套便于在计算机上实现的递推滤波算法,并且适用于非平稳过程的滤波和多变量系统的滤波,克服了维纳(Wiener)滤波理论的局限性,并获得了广泛的应用。


RLS和LMS自适应算法分析RLS(Recursive Least Squares)自适应算法和LMS(Least Mean Squares)自适应算法是常见的自适应滤波算法,在信号处理、通信系统等领域有广泛应用。
本文将对这两种算法进行详细分析比较,并对它们的优缺点进行评价。
首先,我们先介绍一下这两种算法的基本原理。
RLS算法是一种递归估计算法,通过估计系统的权值并逐步修正的方式逼近期望响应。
根据最小二乘估计准则,RLS算法通过最小化滤波器输出与期望响应之间的均方误差来更新权值。
该算法以过去的输入和期望响应作为参考,通过不断修正权值,逼近最佳解。
常用的RLS算法有全选信号算法、选择性部分信号退化算法等。
LMS算法则是一种基于梯度下降的迭代算法,通过不断修正权值,使得滤波器输出的均方误差逐渐减小。
该算法的优势在于计算简单、适合实时应用。
LMS算法通过使用当前输入和期望响应对滤波器权值进行更新,更新步长由算法的学习速率参数确定,步长过大会导致算法发散,步长过小会降低收敛速度。
接下来,我们以几方面来分析比较这两种算法。
1.性能比较:在滤波效果方面,RLS算法由于基于历史输入和期望响应进行计算,能够更好地估计权值,提高滤波性能。
而LMS算法则在计算简单、实现容易的基础上,性能相对较差。
在噪声较大的环境下,RLS算法的性能相对更为优秀。
2.计算复杂度:RLS算法需要存储历史输入和期望响应,并进行矩阵运算,因此计算复杂度较高。
而LMS算法只需要存储当前输入和期望响应,并进行简单的乘法和加法运算,计算复杂度较低。
在资源受限的环境下,LMS算法更加适用。
3.收敛速度:RLS算法在每次迭代时都通过递归方式重新计算权值,因此收敛速度较快。
而LMS算法只通过当前输入和期望响应更新权值,因此收敛速度较慢。
在需要快速适应的应用场景下,RLS算法更为适合。
4.算法稳定性:由于RLS算法需要存储历史输入和期望响应,内存消耗较大。

基于LMS和RLS算法的自适应滤波器仿真自适应滤波器是一种可以自动调整其权重参数来适应不断变化的信号环境的滤波器。
常用的自适应滤波算法包括最小均方(LMS)和最小二乘(RLS)算法。
本文将对基于LMS和RLS算法的自适应滤波器进行仿真,并分析其性能和特点。
首先,介绍LMS算法。
LMS算法是一种基于梯度下降的自适应滤波算法。
其权重更新规则为:w(n+1)=w(n)+μ*e(n)*x(n),其中w(n)为当前时刻的权重,μ为步长(学习速率),e(n)为当前时刻的误差,x(n)为输入信号。
通过不断迭代和更新权重,LMS算法可以使滤波器的输出误差逐渐减小,从而逼近期望的输出。
接下来,进行LMS自适应滤波器的仿真实验。
考虑一个声纳系统的自适应滤波器,输入信号x(n)为声波信号,输出信号y(n)为接收到的声纳信号,期望输出信号d(n)为理想的声纳信号。
根据LMS算法,可以通过以下步骤进行仿真实验:1.初始化权重w(n)为零向量;2.读取输入信号x(n)和期望输出信号d(n);3.计算当前时刻的滤波器输出y(n)=w^T(n)*x(n),其中^T表示矩阵的转置;4.计算当前时刻的误差e(n)=d(n)-y(n);5.更新权重w(n+1)=w(n)+μ*e(n)*x(n);6.重复步骤2-5,直到滤波器的输出误差满足预设条件或达到最大迭代次数。
然后,介绍RLS算法。
RLS算法是一种递推最小二乘的自适应滤波算法。
其基本思想是通过不断迭代更新滤波器的权重,使得滤波器的输出误差的二范数最小化。
RLS算法具有较好的收敛性和稳定性。
接下来,进行RLS自适应滤波器的仿真实验。
基于声纳系统的例子,RLS算法的步骤如下:1.初始化滤波器权重w(n)为一个较小的正数矩阵,初始化误差协方差矩阵P(n)为一个较大的正数矩阵;2.读取输入信号x(n)和期望输出信号d(n);3.计算增益矩阵K(n)=P(n-1)*x(n)/(λ+x^T(n)*P(n-1)*x(n)),其中λ为一个正则化参数;4.计算当前时刻的滤波器输出y(n)=w^T(n)*x(n);5.计算当前时刻的误差e(n)=d(n)-y(n);6.更新滤波器权重w(n+1)=w(n)+K(n)*e(n);7.更新误差协方差矩阵P(n)=(1/λ)*(P(n-1)-K(n)*x^T(n)*P(n-1));8.重复步骤2-7,直到滤波器的输出误差满足预设条件或达到最大迭代次数。

自适应滤波LMS与RLS的matlab 实现MATLAB 仿真实现LMS 和RLS 算法的二阶AR 模型及仿真结果分析一、题目概述:二阶AR 模型如图1a 所示,可以如下差分方程表示:)()()2()1()()(21n d n v n x a n x a n v n x +=----= (1)图1a其中,v(n)是均值为0、方差为0.965的高斯白噪声序列。
a 1,a 2为描述性参数,.95,0,195.021=-=a a 设x(-1)=x(-2)=0,权值w 1(0)=w 2(0)=0,μ=0.04①推导最优滤波权值(理论分析一下)。
②按此参数设置,由计算机仿真模拟权值收敛曲线并画出,改变步长在此模拟权值变化规律。
③对仿真结果进行说明。
④应用RLS 算法再次模拟最优滤波权值。
解答思路:(1)高斯白噪声用normrnd函数产生均值为0、方差为0.965的正态分布随机1*N矩阵来实现。
随后的产生的信号用题目中的二阶AR模型根据公式(1)产生,激励源是之前产生的高斯白噪声。
(2)信号长度N取为2000点,用以观察滤波器权值变化从而估计滤波器系数,得到其收敛值。
(3)仿真时分别仿真了单次LMS算法和RLS算法下的收敛性能以及100次取平均后的LMS和RLS算法的收敛性能,以便更好的比较观察二者的特性。
(4)在用不同的分别取3个不同的μ值仿真LMS算法时,μ值分别取为0.001,0.003,0.006;用3个不同的λ值仿真RLS算法时λ值分别取为1,0.98,0.94,从而分析不同步长因子、不同遗忘因子对相应算法收敛效果的影响。
二、算法简介上式越旧的数据对()n ε的影响越小。
通过计算推导得到系数的迭代方程为:w (n )=w (n −1)+k (n )e ∗(n) (5)式(5)中,增量k(n)和误差e ∗(n)计算公式如下:(n 1)x(n)k(n)(n)T(n 1)x(n)T T x λ-=+- (6)e ∗(n )=d ∗(n )−x T (n )∗w(n −1)(7) 式(6)中T(n)= R̂−1(n ),也就是当前时刻自相关矩阵的逆。

自适应滤波第1章绪论 (1)1.1自适应滤波理论发展过程 (1)1. 2自适应滤波发展前景 (2)1. 2. 1小波变换与自适应滤波 (2)1. 2. 2模糊神经网络与自适应滤波 (3)第2章线性自适应滤波理论 (4)2. 1最小均方自适应滤波器 (4)2. 1. 1最速下降算法 (4)2.1.2最小均方算法 (6)2. 2递归最小二乘自适应滤波器 (7)第3章仿真 (12)3.1基于LMS算法的MATLAB仿真 (12)3.2基于RLS算法的MATLAB仿真 (15)组别: 第二小组组员: 黄亚明李存龙杨振第1章绪论从连续的(或离散的)输入数据中滤除噪声和干扰以提取有用信息的过程称为滤波。
相应的装置称为滤波器。
实际上, 一个滤波器可以看成是一个系统, 这个系统的目的是为了从含有噪声的数据中提取人们感兴趣的、或者希望得到的有用信号, 即期望信号。
滤波器可分为线性滤波器和非线性滤波器两种。
当滤波器的输出为输入的线性函数时, 该滤波器称为线性滤波器, 当滤波器的输出为输入的非线性函数时, 该滤波器就称为非线性滤波器。
自适应滤波器是在不知道输入过程的统计特性时, 或是输入过程的统计特性发生变化时, 能够自动调整自己的参数, 以满足某种最佳准则要求的滤波器。
1. 1自适应滤波理论发展过程自适应技术与最优化理论有着密切的系。
自适应算法中的最速下降算法以及最小二乘算法最初都是用来解决有/无约束条件的极值优化问题的。
1942年维纳(Wiener)研究了基于最小均方误差(MMSE)准则的在可加性噪声中信号的最佳滤波问题。
并利用Wiener. Hopf方程给出了对连续信号情况的最佳解。
基于这~准则的最佳滤波器称为维纳滤波器。
20世纪60年代初, 卡尔曼(Kalman)突破和发展了经典滤波理论, 在时间域上提出了状态空间方法, 提出了一套便于在计算机上实现的递推滤波算法, 并且适用于非平稳过程的滤波和多变量系统的滤波, 克服了维纳(Wiener)滤波理论的局限性, 并获得了广泛的应用。

基于LMS和RLS算法的自适应FIR滤波器仿真一、自适应滤波原理自适应滤波器是指利用前一时刻的结果,自动调节当前时刻的滤波器参数,以适应信号和噪声未知或随机变化的特性,得到有效的输出,主要由参数可调的数字滤波器和自适应算法两部分组成,如图1.1所示图1.1 自适应滤波器原理图x(n)称为输入信号,y(n)称为输出信号,d(n)称为期望信号或者训练信号,e(n)为误差僖号,其中,e(n)=d(n)-y(n),自适应滤波器的系数(权值)根据误差信号e(n),通过一定的自适应算法不断的进行更新,以达到使滤波器实际输出y(n)与期望响应d(n)之间的均方误差最小。
二、自适应算法自适应算法中使用最广的是下降算法,下降算法的实现方式有两种:自适应梯度算法和自适应高斯-牛顿算法。
自适应高斯-牛顿算法包括RLS算法及其改进型,自适应梯度算法的典型例子即是LMS算法[1]。
1.LMS算法最陡下降算法不需要知道误差特性曲面的先验知识,其算法就能收敛到最佳维纳解,且与起始条件无关。
但是最陡下降算法的主要限制是它需要准确测得每次迭代的梯度矢量,这妨碍了它的应用。
为了减少计算复杂度和缩短自适应收敛时间许多学者对这方面的新算法进行了研究。
1960年,美国斯坦福大学的Windrow等提出了最小均方(LMS)算法,这是一种用瞬时值估计梯度矢量的方法,即2[()]()2()()()e n n e n x n w n ∧∂∇==-∂ 可见,这种瞬时估计法是无偏的,因为它的期望值E[)(n ∇∧]确实等于矢量)(n ∇。
所以,按照自适应滤波器滤波系数矢量的变化与梯度矢量估计的方向之间的关系,可以先写出LMS 算法的公式如下:1(1)()[()]()()()2w n w n n w n e n x n μμ∧∧∧∧+=+-∇=+ 将式e(n)=d(n)-y(n)和e(n)=d(n)-w H x(n)代入到上式中,可得到(1)()()[()()()][()()]()()()HH w n w n x n d n w n x n I x n x n w n x n d n μμμ∧∧∧∧+=+-=-+图2.1 自适应LMS 算法信号流图由上式可以得到自适应LMS 算法的信号流图,这是一个具有反馈形式的模型,如图2-1所示。

LMS和RLS算法应用及仿真分析
LMS算法(Least Mean Squares)是一种基于梯度下降策略的机器学
习算法,它主要应用于解决系统辨识、信号分类和数据拟合等问题。
LMS
算法是一种收敛率较高的优化算法,由于其算法简单、快速,因此在工业
中被广泛应用。
基本原理:LMS算法的基本原理是进行参数更新,以最小化残差平方
和(RSS)作为目标函数,从而改善结果的稳定性和准确性。
LMS算法的
另一个重要思想是,在学习过程中每次迭代都仅使用当前一个输入和相应
的输出。
因此,该算法不需要获得训练样本数据的完整集合,可以仅仅从
一个训练样本中获得有限的信息,并通过这种限定的信息进行迭代。
LMS算法的算法步骤:
(1)初始化参数θ;
(2)给定一个输入样本xn,根据当前的参数θ计算出预测输出ŷn;
(3)根据已知的真实输出dn,计算出当前的残差en;
(4)根据梯度下降法更新参数θ;
(5)重复2~4步,直到达到目标函数的收敛性。
仿真分析:
首先,使用Matlab仿真模拟LMS算法,以模拟实际的系统辨识任务。
RLS 自适应算法分析及仿真RLS 自适应算法是为了设计自适应的横向滤波器把最小二乘法推广为一种自适应算法。
使得在已知n-1时刻横向滤波器抽头系数的情况吓,能够通过简单的更新,求出n 时刻的滤波器抽头权系数。
这样一种自适应的最小二乘法称为递推最小二乘法,简称RLS 算法。
RLS 自适应算法使用的确定性线性回归模型Kalman 滤波算法的一种特殊的无激励的状态空间模型。
一、RLS 算法步骤:步骤一:初始化:(0)0w =,1(0)P I δ-=,其中δ是一个很小的值。
步骤二:更新: n=1,2,……()()(1)()H e n d n w n u n =--(1)()()()(1)()H P n u n k n u n P n u n λ-=+- 1()[(1)()()(1)]H P n P n k n u n P n λ=---*()(1)()()w n w n k n e n =-+其中,11(0)(0)P R I δ--==,δ是一个很小的正数。
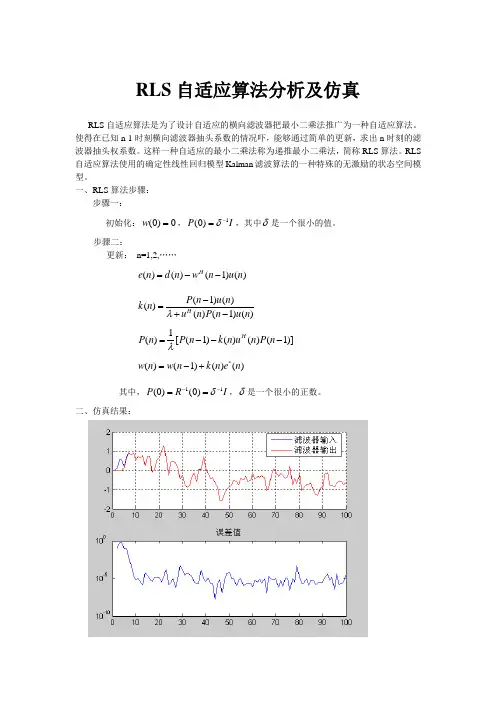
二、仿真结果:从上图可以看出RLS滤波的跟踪性能是比较好的,滤波器的输入与输出在初始值之后几乎重合。
由于RLS存在自适应更新过程,因此其效果比LMS更好。
由下图可以看出,其RLS算法误差是具有收敛性的,收敛结果与δ密切相关,δ在取值为1的时候严重影响RLS算法的收敛速度及结果。
三、仿真程序:clear allclcM=5;%权系数个数N=100;%数据点数n=1:N;wn=0.36*randn(1,N);vn=randn(1,N);d(1)=0;for n=2:Nd(n)=0.8*d(n-1)+wn(n); %期望响应enduu=d+vn;w=zeros(M,1);P=0.05*eye(M,M);q=0.1; %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%for n=M:N;u=uu(n:-1:n-M+1)' ;e(n)=d(n)-w'*u;k=P*u*inv(q+u'*P*u);P=(1/q)*(P-k*u'*P);w=w+k*e(n);out(n)=w'*u;end %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%subplot(211)t=1:N;hold on;plot(d(t));hold on;plot(out(t),'r');grid onlegend('滤波器输入','滤波器输出')subplot(212)semilogy(abs(out-d));title('误差值')。

LMS 和RLS 算法应用及仿真分析摘要:本文采用MATLAB 软件对LMS 和RLS 两种自适应均衡算法在回波抵消器中的应用进行仿真,分析收敛步长μ、抽头w 、遗忘因子λ 等参数对回波抵消器性能的影响,并对两种算法下的性能做出比较。
关键词:LMS ;RLS ;自适应;回波抵消1 引言进入90 年代后期,通过网络拨打长途电话即IP 电话开始盛行,由于发话端到受话端的延迟达100ms 以上,而人耳对大于50ms 的回声就能辨别出来,因此IP 电话的回声严重影响通话效果。
如何消除回声成为非常重要的问题,回波抵消器就是一个自适应辨识系统,它通过特定的算法辨识未知的目标系统,即回声路径。
本文采用LMS 和RLS 算法实现回波抵消,并对收敛步长μ、抽头w 、遗忘因子λ 等相关参数对回波抵消性能的影响进行了仿真分析,从而为一种通用的回波抵消技术的实际应用提供理论参考。
回波抵消算法原理图如图1 所示。
图1 回波抵消算法原理图 2 LMS 和RLS 算法概述最陡下降法(LMS )和递归最小二乘算法(RLS )是自适应滤波最常用,也是最基本的两种算法。
下面分别对LMS 和RLS 两种算法原理做简单介绍。
2.1 LMS 算法设J(n)是n 时刻均方误差,J(n+1)是n+1 时刻的均方误差,W(n)、W(n+1)分别是n 、n+1时刻M 维抽头权向量011()[()()...()]T M W n w n w n w n -= (1)为使J(n+1)<J(n) (2)W(n)必须按J(n)的负方向变化即(1)()W n W n J μ→→→+=-∇ (μ>0) (3)最后以U (n )*e (n )瞬时值代替统计平均,得到抽头权向量迭代式 *(1)()()()W n W n U n e n μ→→+=- (4)式中U(n)式n 时刻的输入向量[u(n) u(n-1) u(n-2)···u(n-M+1)]。

RLS 和LMS 自适应算法分析摘要:本文主要介绍了自适应滤波的两种算法:最小均方(LMS, Least Mean Squares)和递推最小二乘(RLS, Recursive Least Squares)两种基本自适应算法。
我们对这两种基本的算法进行了原理介绍,并进行了Matlab 仿真。
通过仿真结果,我们对两种自适应算法进行了性能分析,并对其进行了比较。
用Matlab 求出了LMS 自适应算法的权系数,及其学习过程曲线,和RLS 自适应权系数算法的学习过程。
关键词:自适应滤波、LMS 、RLS 、Matlab 仿真Abstract: this article mainly introduces two kinds of adaptive filtering algorithms: Least Mean square (LMS), further Mean Squares) and Recursive Least Squares (RLS, Recursive further Squares) two basic adaptive algorithm. Our algorithms of these two basic principle is introduced, and Matlab simulation. Through the simulation results, we have two kinds of adaptive algorithm performance analysis, and carries on the comparison. Matlab calculate the weight coefficient of the LMS adaptive algorithm, and its learning curve, and the RLS adaptive weight coefficient algorithm of the learning process.Keywords:, LMS and RLS adaptive filter, the Matlab simulation课题简介:零均值、单位方差的白噪声通过一个二阶自回归模型产生的AR 过程。
RLS和LMS自适应算法分析RLS (Recursive Least Squares) 和 LMS (Least Mean Squares) 是两种常见的自适应滤波算法。
它们在信号处理、通信系统和自适应控制等领域得到广泛应用。
本文将对这两种算法进行分析比较。
首先,我们来看看RLS算法。
RLS算法使用最小均方误差准则来自适应调整滤波器系数。
它利用递归方式计算出均方误差的最小值。
RLS算法基于Wiener-Hopf方程,通过解析方法来计算最优系数。
这种方法计算量较大,但是提供了更好的性能。
RLS算法根据观测数据和期望输出之间的误差信号来不断调整滤波器的权重,并且在递归过程中更新这些权重。
相比于LMS算法,RLS算法具有更快的收敛速度和更高的精度。
但是,RLS 算法也存在一些问题,比如计算复杂度高、存储要求大以及对噪声和系统不确定性敏感。
接下来,我们来看看LMS算法。
LMS算法是一种基于随机梯度下降的自适应算法。
在LMS算法中,滤波器的系数通过逐步调整以减小误差标准差。
LMS算法利用误差信号和输入信号之间的乘积来更新滤波器系数。
这种算法简单易于实现,计算复杂度低,并且对存储要求不高。
LMS算法适用于非平稳环境下的自适应滤波问题。
然而,LMS算法的收敛速度较慢,需要一定的迭代次数才能达到最优解,而且对于高阶滤波器,可能存在稳定性问题。
此外,LMS算法对输入信号的统计特性有一定的要求。
综上所述,RLS算法和LMS算法都是常见的自适应滤波算法,它们在不同的应用领域有不同的适用性和特点。
RLS算法在计算复杂度和存储要求上较高,但是具有更快的收敛速度和更高的精度。
LMS算法计算复杂度低,存储要求小,但是收敛速度较慢。
一般情况下,对于较小的系统和较简单的滤波器,可以使用LMS算法,而对于复杂的系统和高阶滤波器,可以使用RLS算法。
在实际应用中,需要根据具体的要求和约束来选择合适的算法。
此外,还可以根据实时计算需求和系统资源限制等因素,对RLS 和LMS算法进行优化和改进,如考虑快速RLS算法和正则化LMS算法等。
论文第三章LMS和RLS自适应滤波器的仿真实现与比较自适应滤波器是一种能够根据输入信号的特性自动调整其滤波器性能的滤波器。
LMS(最小均方)和RLS(递归最小二乘)是两种常用的自适应滤波器算法。
本文将对这两种算法进行仿真实现,并对其性能进行比较。
首先,我们实现了LMS自适应滤波器的仿真。
LMS自适应滤波器通过不断调整滤波器系数来最小化预测误差的均方误差。
在仿真中,我们生成了一个包含噪声的信号作为输入信号,并设置了一个期望的滤波器响应。
然后,我们使用LMS算法来自适应调整滤波器的系数,使其逼近期望的响应。
最后,我们比较了实际和期望的滤波器响应,并计算了均方误差。
接下来,我们实现了RLS自适应滤波器的仿真。
RLS自适应滤波器使用递归最小二乘算法来调整滤波器的系数。
在仿真中,我们同样生成了一个包含噪声的输入信号,并设置一个期望的滤波器响应。
然后,我们使用RLS算法来递归地更新滤波器的系数,使其逼近期望的响应。
最后,我们比较了实际和期望的滤波器响应,并计算了均方误差。
在比较LMS和RLS自适应滤波器的性能时,我们主要关注以下几个方面:收敛速度、稳定性和计算复杂度。
收敛速度是指自适应滤波器达到期望的响应所需要的时间。
稳定性是指自适应滤波器在逼近期望的响应时是否会出现不稳定的情况。
计算复杂度是指实现自适应滤波器算法所需要的计算量。
根据我们的仿真结果,我们可以得出以下结论:LMS自适应滤波器的收敛速度较快,但在达到期望的响应后可能会出现振荡的情况,所以在实际应用中需要设置合适的步长参数来平衡收敛速度和稳定性。
RLS自适应滤波器的收敛速度较慢,但在达到期望的响应后相对稳定,不容易出现振荡的情况。
然而,RLS算法的计算复杂度较高,需要大量的计算资源。
总的来说,LMS和RLS自适应滤波器都有各自的优势和劣势。
在实际应用中,我们需要根据具体的需求来选择合适的自适应滤波器算法。
如果追求较快的收敛速度和较低的计算复杂度,可以选择LMS算法;如果追求较稳定的滤波器性能并且有充足的计算资源,可以选择RLS算法。
基于LMS算法与RLS算法的自适应滤波徐艳;李静【期刊名称】《电子设计工程》【年(卷),期】2012(020)012【摘要】The theory and technology of adaptive signal processing have become popular in filtering and canceling noise field. This article mainly talks about the theory of adaptive filtering and steps of the arithmetic based on LMS&RLS.Emulations successfully showed the theory by MATLAB in this paper.%自适应信号处理的理论和技术已经成为人们常用滤波和去噪技术。
文中讲述了自适应滤波的原理以及LMS算法和RLS算法两种基本自适应算法的原理及步骤。
并用MATLAB分别对两种算法进行了自适应滤波仿真和实现。
【总页数】4页(P49-51,54)【作者】徐艳;李静【作者单位】长安大学信息工程学院,陕西西安710064;长安大学信息工程学院,陕西西安710064【正文语种】中文【中图分类】TP312【相关文献】1.基于LMS算法与RLS算法自适应滤波及仿真分析 [J], 马国栋;阎树田;贺成柱;杨晨2.基于RLS算法的自适应抗干扰工频通信滤波器的设计与实现 [J], 徐婷;通旭明3.基于qF-LMS算法的自适应滤波器与FPGA实现 [J], 丁泽锋; 白路阳; 杨炜毅; 王艳芬4.基于LMS算法的自适应滤波器性能分析 [J], 刘建涛;席闯;姜海洋5.基于RLS算法的有源滤波器自适应基波检测方法(英文) [J], 姜孝华;金济;Ale Emedi因版权原因,仅展示原文概要,查看原文内容请购买。
LMS和RLS算法应用及仿真分析LMS(最小均方)算法和RLS(递归最小二乘)算法是两种经典的自适应滤波算法,广泛应用于各种实际场景中。
本文将介绍LMS和RLS算法的原理及其在实际应用场景中的应用,并进行仿真分析。
首先,我们来介绍LMS算法。
LMS算法是一种基于梯度下降法的自适应滤波算法,在信号处理中经常应用于滤波、降噪、系统辨识等领域。
其基本原理是通过不断调整滤波器的权值,使得滤波器的输出与期望输出之间的均方误差最小化。
LMS算法的核心是权值更新公式:w(n+1)=w(n)+μe(n)x(n),其中w(n)表示第n次迭代的权值向量,μ为步长因子,e(n)为滤波器输出与期望输出之差,x(n)为输入信号。
LMS算法具有简单、易实现的特点,但收敛速度较慢,对信号的统计特性较为敏感。
LMS算法在实际应用中有着广泛的应用。
以自适应滤波为例,LMS算法可以用于消除信号中的噪声,提高信号的质量。
在通信系统中,LMS算法可以应用于自适应均衡,解决信道等效时延导致的传输误差问题。
除此之外,LMS算法还可以用于系统辨识、自适应控制等领域。
接下来,我们来介绍RLS算法。
RLS算法是一种基于递归最小二乘法的自适应滤波算法,广泛应用于信号处理、自适应滤波、波束形成等领域。
与LMS算法相比,RLS算法具有更快的收敛速度和更好的稳定性。
其核心思想是通过递归计算逆相关矩阵,从而得到滤波器的最优权值。
RLS算法的权值更新公式可以表示为:w(n+1)=w(n)+K(n)e(n),其中K(n)为滤波器的增益向量,e(n)为滤波器输出与期望输出之差。
不同于LMS算法,RLS算法的步长因子时刻变化,可以根据需要进行调整,从而实现最优的权值更新。
RLS算法在实际应用中也有着广泛的应用。
例如,在通信系统中,RLS算法可以用于波束形成,提高信号的接收效果。
在自适应滤波中,RLS算法可以用于降低信号中的噪声。
此外,在自适应控制领域,RLS算法可以用于模型辨识、参数估计等问题。
自适应滤波LMS算法及RLS算法及其仿真1.引言2.自适应滤波LMS算法LMS(Least Mean Square)算法是一种最小均方误差准则的自适应滤波算法。
其基本原理是通过不断调整滤波器的权值,使得输出信号的均方误差最小化。
LMS算法的迭代公式可以表示为:w(n+1)=w(n)+μ*e(n)*x(n)其中,w(n)为滤波器的权值向量,μ为步长因子,e(n)为误差信号,x(n)为输入信号。
通过迭代更新权值,LMS算法逐渐收敛,实现了自适应滤波。
3.RLS算法RLS(Recursive Least Square)算法是一种递归最小二乘法的自适应滤波算法。
相比于LMS算法,RLS算法具有更好的收敛性能和适应性。
RLS算法基于最小二乘准则,通过递归式地计算滤波器权值矩阵,不断优化滤波器的性能。
迭代公式可以表示为:P(n)=(P(n-1)-P(n-1)*x(n)*x(n)'*P(n-1)/(λ+x(n)'*P(n-1)*x(n))) K(n)=P(n)*x(n)/(λ+x(n)'*P(n)*x(n))w(n+1)=w(n)+K(n)*e(n)其中,P(n)为滤波器的协方差矩阵,K(n)为最优权值,λ为遗忘因子(用于控制算法的收敛速度),e(n)为误差信号。
4.仿真实验为了验证LMS算法和RLS算法的性能,我们进行了一组仿真实验。
假设输入信号为一个正弦信号,噪声为高斯白噪声。
我们分别使用LMS和RLS算法对输入信号进行自适应滤波,比较其输出信号和原始信号的均方误差。
在仿真中,我们设置了相同的滤波器长度和步长因子,比较LMS和RLS算法的收敛速度和输出质量。
实验结果表明,相对于LMS算法,RLS 算法在相同条件下具有更快的收敛速度和更低的均方误差。
这验证了RLS 算法在自适应滤波中的优越性。
5.结论本文介绍了自适应滤波LMS算法和RLS算法的原理及其在仿真中的应用。
实验结果表明,相对于LMS算法,RLS算法具有更好的收敛性能和适应性。
自适应滤波第1章绪论 (1)1.1自适应滤波理论发展过程 (1)1.2自适应滤波发展前景 (2)1.2.1小波变换与自适应滤波 (2)1.2.2模糊神经网络与自适应滤波 (3)第2章线性自适应滤波理论 (4)2.1最小均方自适应滤波器 (4)2.1.1最速下降算法 (4)2.1.2最小均方算法 (6)2.2递归最小二乘自适应滤波器 (7)第3章仿真 (12)3.1基于LMS算法的MATLAB仿真 (12)3.2基于RLS算法的MATLAB仿真 (15)组别:第二小组组员:黄亚明李存龙杨振第1章绪论从连续的(或离散的)输入数据中滤除噪声和干扰以提取有用信息的过程称为滤波。
相应的装置称为滤波器。
实际上,一个滤波器可以看成是一个系统,这个系统的目的是为了从含有噪声的数据中提取人们感兴趣的、或者希望得到的有用信号,即期望信号。
滤波器可分为线性滤波器和非线性滤波器两种。
当滤波器的输出为输入的线性函数时,该滤波器称为线性滤波器,当滤波器的输出为输入的非线性函数时,该滤波器就称为非线性滤波器。
自适应滤波器是在不知道输入过程的统计特性时,或是输入过程的统计特性发生变化时,能够自动调整自己的参数,以满足某种最佳准则要求的滤波器。
1.1自适应滤波理论发展过程自适应技术与最优化理论有着密切的系。
自适应算法中的最速下降算法以及最小二乘算法最初都是用来解决有/无约束条件的极值优化问题的。
1942年维纳(Wiener)研究了基于最小均方误差(MMSE)准则的在可加性噪声中信号的最佳滤波问题。
并利用Wiener.Hopf方程给出了对连续信号情况的最佳解。
基于这~准则的最佳滤波器称为维纳滤波器。
20世纪60年代初,卡尔曼(Kalman)突破和发展了经典滤波理论,在时间域上提出了状态空间方法,提出了一套便于在计算机上实现的递推滤波算法,并且适用于非平稳过程的滤波和多变量系统的滤波,克服了维纳(Wiener)滤波理论的局限性,并获得了广泛的应用。
这种基于MMSE准则的对于动态系统的离散形式递推算法即卡尔曼滤波算法。
这两种算法都为自适应算法奠定了基础。
从频域上的谱分析方法到时域上的状态空间分析方法的变革,也标志着现代控制理论的诞生。
最优滤波理论是现代控制论的重要组成部分。
在控制论的文献中,最优滤波理论也叫做Kalman滤波理论或者状态估计理论。
从应用观点来看,Kalman滤波的缺点和局限性是应用Kalman滤波时要求知道系统的数学模型和噪声统计这两种先验知识。
然而在绝大多数实际应用问题中,它们是不知道的,或者是近似知道的,也或者是部分知道的。
应用不精确或者错误的模型和噪声统计设计Kalman滤波器将使滤波器性能变坏,导致大的状态估计误差,甚至使滤波发散。
为了解决这个矛盾,产生了自适应滤波。
最早的自适应滤波算法是最小JY(LMS)算法。
它成为横向滤波器的一种简单而有效的算法。
实际上,LMS算法是一种随机梯度算法,它在相对于抽头权值的误差信号平方幅度的梯度方向上迭代调整每个抽头权值。
1996年Hassibi等人证明了LMS算法在H。
准则下为最佳,从而在理论上证明了LMS算法具有孥实性。
自Widrow等人1976年提出LMs自适应滤波算法以来,经过30多年的迅速发展,已经使这一理论成果成功的应用到通信、系统辨识、信号处理和自适应控制等领域,为自适应滤波开辟了新的发展方向。
在各种自适应滤波算法中,LMS算法因为其简单、计算量小、稳定性好和易于实现而得到了广泛应用。
这种算法中,固定步长因子μ对算法的性能有决定性的影响。
若μ较小时,算法收敛速度慢,并且为得到满意的结果需要很多的采样数据,但稳态失调误差较小:当“较大时,该算法收敛速度快,但稳态失调误差变大,并有可能使算法发散。
收敛速度与稳态失调误差是不可兼得的两个指标。
以往的文献对LMS算法的性能和改进算法已经做出了相当多的研究,并且至今仍然是一个重要的研究课题。
另一类重要的自适应算法是最小二乘(LS)算法。
LS算法早在1795年就由高斯提出来了,但LS算法存在运算量大等缺点,因而在自适应滤波中一般采用其递推形式——递推最小二乘(RLS)算法,这是一种通过递推方式寻求最佳解的算法,复杂度比直接LS算法小,因而获得了广泛应用。
1994年Sayed和Kailath建立了Kalman滤波和RLS算法之间的对应关系,证明了RLS算法事实上是Kalman滤波器的一种特例,从而使人们对RLS算法有了进一步的理解,而且Kalman滤波的大量研究成果可应用于自适应滤波处理。
这对自适应滤波技术起到了重要的推动作用。
基本上,现有的参考文献都是基于这两种算法进行改进的。
而这两种算法又可以简单的用以下语句来描述:LMS:(抽头权向量更新值)=(老的抽头权向量值)+(学习速率)(抽头输出向量)(误差信号)RLS:(状态递推值)=(旧的状态值)+(卡尔曼增益)(新息向量)以往的研究多集中在线性滤波方面,非线性滤波理论还有待于进一步的研究开发。
1.2自适应滤波发展前景现代信号处理理论为自适应滤波技术的发展提供了广阔的空间。
尤其是小波技术和人工智能理论的发展,更是推动和加快了自适应滤波技术的前进。
1.2.1小波变换与自适应滤波小波变换是由法国地球物理学家Morlet于80年代初在分析地球物理信号时作为~种信号分析的数学工具提出来的。
通俗地讲,小波是一种短期波。
在积分变换中,小波作为核函数的用法大体与傅立叶分析中的正弦和余弦函数或与沃耳什(Walsh)分析中的沃耳什函数的用法相同。
目前,小波分析主要用于信号处理、图像压缩、次能带编码、医学显像、数据压缩、地震分析、消除噪声数据、计算机图像、声音合成等领域。
小波变换的基本特点是多分辨率或多标度的观点,目的是“既要看到森林(信号的概貌),又要看到树木(信号的细节)”。
借助于小波的精辟理论,自适应滤波技术有了新的发展方向,这也引起了信号处理领域许多学者专家的浓厚兴趣和热切关注。
基于小波变换的自适应滤波技术是未来自适应滤波发展的方向之一,有着广阔的应用前景。
目前还有许多问题亟待解决,例如不同形式的小波滤波器的滤波效果研究;在时变信号滤波方面的应用研究以及对于失调噪声的滤波等等。
1.2.2模糊神经网络与自适应滤波神经网络作为一种新的计算方法,已经引起了人们广泛的研究兴趣。
神经网络可以认为是一种由许多称为“神经元”(neuron)的基本计算单元通过广泛的连接所组成的网络。
它是在现代神经科学研究成果的基础上提出来的,反映了人脑功能的基本特征。
网络的信息处理由神经元之间的相互作用来实现,网络的学习与识别决定于各神经元之间联接权系数的动态变化过程。
人工神经网络是模仿和延伸人脑认知功能的新型智能信息处理系统,由于神经元本身具有高度自适应性,因而由大量神经元组成的神经网络具有自学习性、自组织性、巨量并行性、存储分布性、结构可变性等特点,能解决常规信息处理方法难以解决或无法解决的问题。
模糊技术也是现代智能理论的一个重要方面。
利用模糊技术我们可以很容易的将人们熟悉的语言描述应用到自动控制或信号处理中来,然而,模糊理论与神经网络都存在着各自的优缺点。
模糊逻辑和神经网络在许多方面具有关联性和互补性。
它们的交叉研究正是基于二者互补性和关联性的结合。
首先,两者具有互补性。
一方面,模糊技术的特长在于模糊推理能力,容易进行高阶的信息处理。
将模糊技术引入神经网络,可以大大拓宽神经网络处理信息的范围和能力,使其不仅能够处理精确信息,也能够处理模糊信息或其它不精确信息,不仅能够实现精确性联想及映射,也能够实现不精确性联想及映射,特别是模糊联想和模糊映射。
另一方面,神经网络在自学习和自动模式识别方面有极强的优势,采取神经网络技术进行模糊信息处理,则使得模糊规则的自动提取及隶属函数的全自动生成有可能得以解决。
其次,两者具有关联性,有许多共同点。
它们都着眼于模拟人的思维,都是为了处理实际中不确定性、不精确性等引起的系统难以控制等问题。
两者在形式上有不少相似之处,其信息都是分布式存储于其结构之中,从而都具有好的容错能力。
不管是神经网络还是模糊逻辑,都不需要建立数学模型,只需根据输入的采样数据去获取所需的结论,也就是模型无关估计器。
另外,神经网络的映射功能早已得到证明。
近年来,Kosko、L。
X.Wang等证明了模糊系统能以任意精度逼近紧密集上的实连续函数,这也说明了二者之间有着密切的关系。
因此,将两者融合在一起的模糊神经网络可以有效的克服两者的缺点,提高整个网络的性能。
譬如;神经网络可以降低透明程度,使它们更接近于模糊系统;而模糊系统可以提高自适应性,更接近于神经网络。
神经网络与模糊神经网络有力的推动了自适应滤波技术,特别是非线性自适应滤波技术的发展。
事实上,一个神经网络或模糊神经网络本身就可以看作是一个自适应滤波器。
第2章线性自适应滤波理论线性自适应滤波理论比非线性自适应滤波理论发展的比较早、比较成熟。
这里只重点介绍基本的最小均方(LMS)年tl 最小二乘(LS)自适应滤波器。
2.1最小均方自适应滤波器本节所讨论的LMS 算法是应用最广泛的一类算法,从理论体系上来看,最优化方法中的最速下降法是随机梯度信息处理的一种递归算法,在误差性能未知的情况下,它可以寻求误差曲面的最小点,可为平稳随机条件下的LMS 算法提供若干启发性思路,并且是分析算法性能的重要基础。
2.1.1最速下降算法最速下降法是一种不用求矩阵逆来解正规方程组的方法。
它通过递推方式寻求加权矢量的最佳值。
虽然在自适应滤波中很少直接使用最速下泽算法,但它构成了其它自适应算法、特别是LMS 算法的基础。
图2.1表示一个横向滤波器。
图2.1横向滤波器输入矢量为[]()(,(1),...,(1)Tx n x n x n x n M =--+(2-1)加权矢量(即滤波器参数矢量)为 []011()(),(),...,()TM w n w n w n w n -= (2—2)滤波器输出为()()()()()∑==+-=m i T i n x n w i n x n w n y 11 (2—3)利用图2-1中输出信号y(n)与期望信号的d(n)的关系,误差序列e(n)可以写成:e(n)=d(n)-y(n) (2—4)自适应滤波器就是根据误差序列8(行)按照某种准则和算法对其系数w(n)进行调整,最终使自适应滤波器的目标(代价)函数达到最小,即最佳滤波状态。
按照均方误差(MSE)准则所定义的目标函数是F(e(n))=ξ(n)=E[e2(n)=E[d2(n)-2d(n)y(n)+y2(n)] (2-5) 将式(2—3)代入上式,得到ξ(n)=E[d2(n)-2E[d(n)w T(n)x(n)] +E[w T(n)x(n)x T(n)w(n)] (2-6)固定滤波器系数,则目标函数(2.6)可写为ξ(n)= ξ=E[d2(n)]-2w T p+w T w (2.7)式中,R=E[x(n)x T (n)是输入信号的自相关矩阵;P=E[d(n)x(n)]是期望信号与输入信号的互相关矢量。