SQL Server中模式、数据库、表之间的关系
- 格式:doc
- 大小:40.00 KB
- 文档页数:2

SQL试题数据库基础与应⽤课程针对性训练⼀、单项选择题,1.域是实体中相应属性的( A. 取值范围)。
2.把保存关系定义的关系称为对应数据库的( B. 元关系)。
3.在⼀个关系R中,若存在X→Y和X→Z,则存在X→(Y,Z),称此为函数依赖的(C. 合并性)规则。
4. 设⼀个关系为R(A,B,C,D,E,F),它的最⼩函数依赖集为FD={A→B,A→C,D→E,D→F},则该关系的候选码为(D. (A,D))。
5.在SQL中,对基本表进⾏插⼊和修改记录的命令为(D. insert和update)。
6.Access2000数据库是(C.关系)型数据库。
7.如果字段内容为声⾳⽂件,可将此字段定义为(C.OLE对象)类型。
8.在建交叉表查询的过程中,最多可以选择(B.3)个⾏标题字段。
9.若要退出Microsoft Acces s,则应使⽤的操作是(C.Quit)。
10.显⽰包含警告信息或其他信息的消息框,应该使⽤的操作是(D.MsgBox)。
1.设D1,D2和D3域的基数分别为2,3和4,则D1?D2?D3的元组数为(B. 24 )。
2.若⼀个关系为R(学⽣号,姓名,性别,年龄),则(A. 学⽣号)适合作为该关系的主码。
3.设⼀个集合A={3,4,5,6,7},集合B={1,3,5,7,9},则A和B的并集中包含有(C. 7)个元素。
4. 在⼀个关系R中,若存在X→(Y,Z),则也隐含存在X→Y和X→Z,称此为函数依赖的(B. 分解性)规则。
5.在SQL的查询语句中,order by选项实现对结果表的(D. 排序)功能。
6.Access2000数据库⽂件的扩展名是(D.mdb)。
7.在下⾯所给的属性中,(D.⾝份证号码)属性适宜作为主关键字。
8.下列(C .)图标是Access中表对象的标志。
9.Access中包含有(B.10)种数据类型。
10.可以通过Internet进⾏数据发布的对象是(D.数据访问页)。

sql操作数据库(3)--外键约束、数据库表之间的关系、三⼤范式、多表查询、事务外键约束在新表中添加外键约束语法: constraint 外键约束名称 foreign key(外键的字段名称) references 主表表名(主键字段名)在已有表中添加外键约束:alter table 从表表名 add constraints 外键约束名称 foreign key(外键的字段名称) references 主表表名(主键字段名)删除外键语法: alter table 从表表名 drop foreign key 外键名称;级联操作:注意:在从表中,修改关联主表中不存在的数据,是不合法的在主表中,删除从表中已经存在的主表信息,是不合法的。
直接删除主表(从表中有记录数据关联) 会包删除失败。
概念:在修改或者删除主表的主键时,同时它会更新或者删除从表中的外键值,这种动作我们称之为级联操作。
语法:更新级联 on update cascade 级联更新只能是创建表的时候创建级联关系。
当更新主表中的主键,从表中的外键字段会同步更新。
删除级联 on delete cascade 级联删除当删除主表中的主键时,从表中的含有该字段的记录值会同步删除。
操作:-- 给从表student添加级联操作create table student(s_id int PRIMARY key ,s_name VARCHAR(10) not null,s_c_id int,-- constraint 外键约束名称 foreign key(外键的字段名称) references 主表表名(主键字段名)CONSTRAINT stu_cour_id FOREIGN key(s_c_id) REFERENCES course(c_id) -- 给s_c_id 添加外键约束ON UPDATE CASCADE ON DELETE CASCADE)insert into student VALUE(1,'⼩孙',1),(2,'⼩王',2),(3,'⼩刘',4);insert into student VALUE(4,'⼩司马',1),(5,'⼩赵',1),(6,'⼩钱',1);-- 查询学⽣表中的记录select * from student;-- 级联操作。


数据库之表与表之间的关系表1 foreign key 表2则表1的多条记录对应表2的⼀条记录,即多对⼀利⽤foreign key的原理我们可以制作两张表的多对多,⼀对⼀关系多对多:表1的多条记录可以对应表2的⼀条记录表2的多条记录也可以对应表1的⼀条记录⼀对⼀:表1的⼀条记录唯⼀对应表2的⼀条记录,反之亦然分析时,我们先从按照上⾯的基本原理去套,然后再翻译成真实的意义,就很好理解了1、先确⽴关系2、找到多的⼀⽅,吧关联字段写在多的⼀⽅⼀、多对⼀或者⼀对多(左边表的多条记录对应右边表的唯⼀⼀条记录)需要注意的:1.先建被关联的表,保证被关联表的字段必须唯⼀。
2.在创建关联表,关联字段⼀定保证是要有重复的。
其实上⼀篇博客已经举了⼀个多对⼀关系的⼩例⼦了,那我们在⽤另⼀个⼩例⼦来回顾⼀下。
这是⼀个书和出版社的⼀个例⼦,书要关联出版社(多个书可以是⼀个出版社,⼀个出版社也可以有好多书)。
谁关联谁就是谁要按照谁的标准。
书要关联出版社被关联的表create table press(id int primary key auto_increment,name char(20));关联的表create table book(book_id int primary key auto_increment,book_name varchar(20),book_price int,press_id int,constraint Fk_pressid_id foreign key(press_id) references press(id)on delete cascadeon update cascade);插记录insert into press(name) values('新华出版社'),('海燕出版社'),('摆渡出版社'),('⼤众出版社');insert into book(book_name,book_price,press_id) values('Python爬⾍',100,1),('Linux',80,1),('操作系统',70,2),('数学',50,2),('英语',103,3),('⽹页设计',22,3);运⾏结果截图:⼆、⼀对⼀例⼦⼀:⽤户和管理员(只有管理员才可以登录,⼀个管理员对应⼀个⽤户)管理员关联⽤户===========例⼦⼀:⽤户表和管理员表=========先建被关联的表create table user(id int primary key auto_increment, #主键⾃增name char(10));在建关联表create table admin(id int primary key auto_increment,user_id int unique,password varchar(16),foreign key(user_id) references user(id)on delete cascadeon update cascade);insert into user(name) values('susan1'),('susan2'),('susan3'),('susan4'),('susan5'),('susan6');insert into admin(user_id,password) values(4,'sds156'),(2,'531561'),(6,'f3swe');运⾏结果截图:例⼦⼆:学⽣表和客户表========例⼦⼆:学⽣表和客户表=========create table customer(id int primary key auto_increment,name varchar(10),qq int unique,phone int unique);create table student1(sid int primary key auto_increment,course char(20),class_time time,cid int unique,foreign key(cid) references customer(id)on delete cascadeon update cascade);insert into customer(name,qq,phone) values('⼩⼩',13564521,11111111),('嘻哈',14758254,22222222),('王维',44545522,33333333),('胡军',545875212,4444444),('李希',145578543,5555555),('李迪',754254653,8888888),('艾哈',74545145,8712547),('啧啧',11147752,7777777);insert into student1(course,class_time,cid) values('python','08:30:00',3),('python','08:30:00',4),('linux','08:30:00',1),('linux','08:30:00',7);运⾏结果截图:三、多对多(多条记录对应多条记录)书和作者(我们可以再创建⼀张表,⽤来存book和author两张表的关系)要把book_id和author_id设置成联合唯⼀联合唯⼀:unique(book_id,author_id)联合主键:alter table t1 add primary key(id,avg)多对多:⼀个作者可以写多本书,⼀本书也可以有多个作者,双向的⼀对多,即多对多 关联⽅式:foreign key+⼀张新的表========书和作者,另外在建⼀张表来存书和作者的关系#被关联的create table book1(id int primary key auto_increment,name varchar(10),price float(3,2));#========被关联的create table author(id int primary key auto_increment,name char(5));#========关联的create table author2book(id int primary key auto_increment,book_id int not null,author_id int not null,unique(book_id,author_id),foreign key(book_id) references book1(id)on delete cascadeon update cascade,foreign key(author_id) references author(id)on delete cascadeon update cascade);#========插⼊记录insert into book1(name,price) values('九阳神功',9.9),('葵花宝典',9.5),('辟邪剑谱',5),insert into author(name) values('egon'),('e1'),('e2'),('e3'),('e4'); insert into author2book(book_id,author_id) values(1,1),(1,4),(2,1),(2,5),(3,2),(3,3),(3,4),(4,5);多对多关系举例⽤户表,⽤户组,主机表-- ⽤户组create table user (id int primary key auto_increment,username varchar(20) not null,password varchar(50) not null);insert into user(username,password) values('egon','123'),('root',147),('alex',123),('haiyan',123),('yan',123);-- ⽤户组表create table usergroup(id int primary key auto_increment,groupname varchar(20) not null unique);insert into usergroup(groupname) values('IT'),('Sale'),('Finance'),('boss');-- 建⽴user和usergroup的关系表create table user2usergroup(id int not NULL UNIQUE au to_increment,user_id int not null,group_id int not NULL,PRIMARY KEY(user_id,group_id),foreign key(user_id) references user(id)ON DELETE CASCADEon UPDATE CASCADE ,foreign key(group_id) references usergroup(id)ON DELETE CASCADEon UPDATE CASCADE);insert into user2usergroup(user_id,group_id) values(1,1), (1,2),(1,3),(1,4),(2,4),(3,4);-- 主机表CREATE TABLE host(id int primary key auto_increment,ip CHAR(15) not NULL UNIQUE DEFAULT '127.0.0.1' );insert into host(ip) values('172.16.45.2'),('172.16.31.10'),('172.16.45.3'),('172.16.31.11'),('172.10.45.3'),('172.10.45.4'),('172.10.45.5'),('192.168.1.20'),('192.168.1.21'),('192.168.1.22'),('192.168.2.23'),('192.168.2.223'),('192.168.2.24'),('192.168.3.22'),('192.168.3.23'),('192.168.3.24');-- 业务线表create table business(id int primary key auto_increment,business varchar(20) not null unique);insert into business(business) values('轻松贷'),('随便花'),('⼤富翁'),('穷⼀⽣');-- 建⽴host和business关系表CREATE TABLE host2business(id int not null unique auto_increment,host_id int not null ,business_id int not NULL ,PRIMARY KEY(host_id,business_id),foreign key(host_id) references host(id),FOREIGN KEY(business_id) REFERENCES business(id));insert into host2business(host_id,business_id) values (1,1),(1,2),(1,3),(2,2),(2,3),(3,4);-- 建⽴user和host的关系create table user2host(id int not null unique auto_increment,user_id int not null,host_id int not null,primary key(user_id,host_id),foreign key(user_id) references user(id),foreign key(host_id) references host(id));insert into user2host(user_id,host_id) values(1,1), (1,2),(1,3),(1,4),(1,5),(1,6),(1,7),(1,8),(1,9),(1,10),(1,11),(1,12),(1,13),(1,14),(1,15),(1,16),(2,2),(2,3), (2,4), (2,5), (3,10), (3,11), (3,12);练习。

sqlserver 模式的概念SQL Server模式的概念是指在SQL Server数据库中用于组织和管理对象的逻辑容器。
模式提供了一种将对象进行分类和组织的方式,使得数据库中的对象能够更加清晰地被理解和管理。
本文将详细介绍SQL Server模式的概念以及其在数据库中的作用和用法。
一、什么是SQL Server模式?SQL Server模式是一种用于组织和管理数据库对象(如表、视图、存储过程等)的逻辑容器。
它定义了对象的命名空间,可以将数据库中的对象按照一定的规则进行分类和组织,使得数据库结构更加清晰和易于管理。
二、SQL Server模式的作用是什么?1. 分类和组织对象:模式可以按照功能、部门、业务流程等方式对数据库中的对象进行分类和组织,使得对象之间的关系更加清晰明了,方便开发人员和管理员理解和管理数据库。
2. 数据隔离:不同模式下的对象之间具有隔离性,可以避免对象之间的冲突和干扰。
例如,一个模式下的用户不能直接访问另一个模式下的对象,只能通过权限控制来实现访问。
3. 管理权限:模式可以用于管理对象的权限。
通过为模式分配权限,可以控制用户对模式下对象的访问权限和操作权限,保证数据的安全性和完整性。
4. 提高查询效率:模式可以用于优化查询性能。
通过将相关的对象放在同一个模式下,可以减少查询时的表扫描次数,提高查询效率。
三、SQL Server模式的用法有哪些?1. 创建模式:可以通过CREATE SCHEMA语句来创建模式。
例如,CREATE SCHEMA [SchemaName];这将在当前数据库中创建一个名为SchemaName的模式。
2. 为模式分配权限:可以使用GRANT和DENY语句为模式分配或撤销权限。
例如,GRANT SELECT ON SCHEMA::[SchemaName] TO [UserName];这将给用户UserName授予对SchemaName模式下对象的SELECT权限。

22春“计算机网络技术”专业《数据库应用技术》离线作业-满分答案1. 在表单设计中,经常会用到一些特定的关键字、属性和事件。
下列各项中属于属性的是( )A.ThisB.ThisFormC.CaptionD.Click参考答案:C2. 索引可以保证数据的唯一性。
( )A.错误B.正确参考答案:A3. 关系模式R中若没有非主属性,则( )A.R属于2NF但不一定属于3NFB.R属于3NF但不一定属于BCNFC.R属于BCNF但不一定属于4NFD.R属于4NF参考答案:B4. SQL的标准库函数COUNT,SUM,AVG,MAX与MIN等,不允许在其中的命令是( )A.GROUP......HAVINGB.WHERE参考答案:B5. SQL语言具有( )的功能A.数据定义、数据操纵、数据控制B.数据定义、关系规范化、数据操纵C.数据定义、关系规范化、数据控制D.关系规范化、数据操纵、数据控制参考答案:A6. 向stu2表中插入dname=铁掌帮的学生,该语句为Insert into stu where dname=‘铁掌帮’。
( )T.对F.错参考答案:F7. 在SQL Server中,给SQL Server引擎提供了一个对象接口的是( )。
A.SQL服务管理器B.分布式管理对象参考答案:A8. 使用SQL语句设置外键约束,语法为:CONSTRAINT constraint_name PRIMARY KEY。
( ) T.对F.错参考答案:F9. 数据流图和数据字典,属于数据库系统设计中的结构设计阶段。
( )A.正确B.错误参考答案:B10. 在SQL语句中,表达式“工资BETWEEN 1200 AND 1250”的含义是( )。
A.工资>1220 AND 工资B.工资>1220 OR 工资C.工资>=1220 AND 工资D.工资>=1220 OR 工资<=1250参考答案:C11. 关系数据库中,实现表与表之间的联系是通过( )A.实体完整性规则B.参照完整性规则C.用户自定义的完整性D.值域参考答案:B12. 数据库的完整性是指数据的( )。

sqlserver数据库表结构SQL Server数据库表结构详解一、用户表(user)用户表是一个常见的数据库表结构,用于存储系统中的用户信息。
该表通常包含以下字段:1. 用户ID(user_id):用于唯一标识每个用户的ID,通常为自增长的整数类型。
2. 用户名(username):用户的登录名,通常为字符串类型,长度限制根据具体需求而定。
3. 密码(password):用户的登录密码,通常为加密后的字符串类型。
4. 姓名(name):用户的真实姓名,通常为字符串类型。
5. 性别(gender):用户的性别,通常为枚举类型,如男、女等。
6. 手机号(phone):用户的手机号码,通常为字符串类型,长度限制根据具体需求而定。
7. 邮箱(email):用户的电子邮箱地址,通常为字符串类型,长度限制根据具体需求而定。
二、订单表(order)订单表用于存储用户的订单信息,包含以下字段:1. 订单ID(order_id):用于唯一标识每个订单的ID,通常为自增长的整数类型。
2. 用户ID(user_id):关联用户表的用户ID,表示该订单属于哪个用户。
3. 订单编号(order_number):订单的编号,通常为字符串类型,长度限制根据具体需求而定。
4. 下单时间(create_time):订单的创建时间,通常为日期时间类型。
5. 订单金额(amount):订单的总金额,通常为浮点数类型,表示订单应付的金额。
6. 支付状态(payment_status):订单的支付状态,通常为枚举类型,如未支付、已支付等。
三、商品表(product)商品表用于存储系统中的商品信息,包含以下字段:1. 商品ID(product_id):用于唯一标识每个商品的ID,通常为自增长的整数类型。
2. 商品名称(product_name):商品的名称,通常为字符串类型,长度限制根据具体需求而定。
3. 商品价格(price):商品的价格,通常为浮点数类型,表示商品的单价。

习题答案第一章习题答案一、选择题1.下列关于数据库技术的描述,错误的是( B )A.数据库中不但需要保存数据,而且还需要保存数据之间的关联关系B.由于数据是存储在磁盘上的,因此用户在访问数据库数据时需要知道数据的存储位置C.数据库中数据存储结构的变化不会影响到应用程序D.数据库中的数据具有较小的数据冗余2.数据库系统中将数据分为三个模式,从而提供了数据的独立性,下列关于数据逻辑独立性的说法,正确的是( C )A. 当内模式发生变化时,模式可以不变B. 当内模式发生变化时,应用程序可以不变C. 当模式发生变化时,应用程序可以不变D. 当模式发生变化时,内模式可以不变3.下列关于用文件管理数据的说法,错误的是( D )A.用文件管理数据,难以提供应用程序对数据的独立性B.当存储数据的文件名发生变化时,必须修改访问数据文件的应用程序C.用文件存储数据的方式难以实现数据访问的安全控制D.将相关的数据存储在一个文件中,有利于用户对数据进行分类,因此也可以加快用户操作数据的效率4.数据库管理系统是数据库系统的核心,它负责有效地组织、存储和管理数据,它位于用户和操作系统之间,属于( A )A.系统软件B.工具软件C.应用软件D.数据软件5.下列模式中,用于描述单个用户数据视图的是( C )A.内模式B.概念模式C.外模式D.存储模式6.在数据库系统中,数据库管理系统和操作系统之间的关系是( D )A.相互调用B.数据库管理系统调用操作系统C.操作系统调用数据库管理系统D.并发运行7.数据库系统的物理独立性是指( C )A.不会因为数据的变化而影响应用程序B.不会因为数据存储结构的变化而影响应用程序C.不会因为数据存储策略的变化而影响数据的存储结构D.不会因为数据逻辑结构的变化而影响应用程序8.下列关于数据库管理系统的说法,错误的是( C )A.数据库管理系统与操作系统有关,操作系统的类型决定了能够运行的数据库管理系统的类型B.数据库管理系统对数据库文件的访问必须经过操作系统实现才能实现C.数据库应用程序可以不经过数据库管理系统而直接读取数据库文件D.数据库管理系统对用户隐藏了数据库文件的存放位置和文件名9.数据库系统是由若干部分组成的。
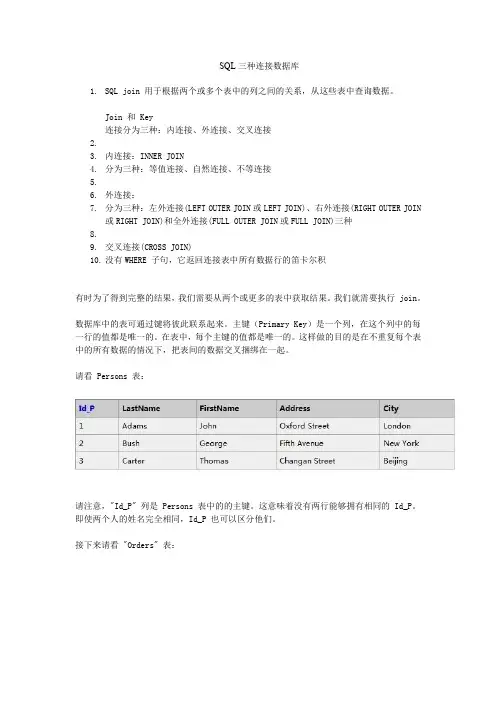
SQL三种连接数据库1.SQL join 用于根据两个或多个表中的列之间的关系,从这些表中查询数据。
Join 和 Key连接分为三种:内连接、外连接、交叉连接2.3.内连接:INNER JOIN4.分为三种:等值连接、自然连接、不等连接5.6.外连接:7.分为三种:左外连接(LEFT OUTER JOIN或LEFT JOIN)、右外连接(RIGHT OUTER JOIN或RIGHT JOIN)和全外连接(FULL OUTER JOIN或FULL JOIN)三种8.9.交叉连接(CROSS JOIN)10.没有WHERE 子句,它返回连接表中所有数据行的笛卡尔积有时为了得到完整的结果,我们需要从两个或更多的表中获取结果。
我们就需要执行 join。
数据库中的表可通过键将彼此联系起来。
主键(Primary Key)是一个列,在这个列中的每一行的值都是唯一的。
在表中,每个主键的值都是唯一的。
这样做的目的是在不重复每个表中的所有数据的情况下,把表间的数据交叉捆绑在一起。
请看 Persons 表:请注意,"Id_P" 列是 Persons 表中的的主键。
这意味着没有两行能够拥有相同的 Id_P。
即使两个人的姓名完全相同,Id_P 也可以区分他们。
接下来请看 "Orders" 表:请注意,"Id_O" 列是 Orders 表中的的主键,同时,"Orders" 表中的 "Id_P" 列用于引用"Persons" 表中的人,而无需使用他们的确切姓名。
请留意,"Id_P" 列把上面的两个表联系了起来。
不同的 SQL JOIN下面列出了您可以使用的 JOIN 类型,以及它们之间的差异。
* JOIN: 如果表中有至少一个匹配,则返回行* LEFT JOIN: 即使右表中没有匹配,也从左表返回所有的行* RIGHT JOIN: 即使左表中没有匹配,也从右表返回所有的行* FULL JOIN: 只要其中一个表中存在匹配,就返回行SQL INNER JOIN 关键字在表中存在至少一个匹配时,INNER JOIN 关键字返回行。

数据库和表之间的关系数据库:数据库即数据的仓库。
在数据库中提供了专门的管理系统。
对数据库中的数据进⾏集中的控制和管理。
能⾼效的对数据库进⾏存储、检索。
关系型数据库:关系模型把世界看作是由实体(Entity)和联系(Relationship)组成的。
关系模型数据库是⼀种以表做为实体,以主键和外键关系作为联系的⼀种数据库结构。
在关系数据库中,相类似的实体被存⼊表中。
表(table)是关系型数据库的核⼼单元,它是数据存储的地⽅。
关系数据库管理系统:关系型数据库只是⼀个保存数据的容器,⼤多数数据库依靠⼀个称为数据库管理系统(DatabaseManagement System,简称DBMS)的软件来管理数据库中数据。
数据库管理系统的分类:本地数据库管理系统数据库服务器管理系统。
⼀对⼀关系:关系模型:⼀条主表记录对应⼀条从表记录。
同时⼀条从表记录对应⼀条主表记录对象模型:⼀个类包含另⼀个类的对象,⽽另⼀个类包含该类的对象Class Man private Code code class Code provate private Man man公民表公民编号姓名⽣⽇1Xx Xxxx-xx-xx⾝份表公民编号⾝份证号1Xxxxxxx⼀对⼀关系是⽐较少见的关系类型。
很多数据库也很少包含⼀对⼀关系主键:这就是主键:主键是唯⼀标识⼀条记录,不能有重复的,不允许为空。
特点:主键的两个特点不可以重复、不能为空。
外键:在关系型数据库中,外建(ForergnKey)是⽤来表达表和表之间关联关系的列。
这就是外键:表的外键是另⼀表的主键,外键可以有重复的,可以是空值⼀对多关系:关系模型:⼀条主表记录对应多条从表记录。
同时⼀条从表记录对应⼀条主表记录对象模型:⼀个类包含另⼀个类的集合,⽽另⼀个类包含该类的对象Class Man{ private List<Room> roomlist; class Room{ private Man man,公民表公民编号姓名⽣⽇1房间表房间编号房间地址公民编号11我们通常把⼀对多关系中,” 多边”的表称为从表,把”⼀边”的表称为主表。

sqlserver 几种关联方式SQL Server是一个关系数据库管理系统,提供了多种关联方式用于连接不同表中的数据。
以下是几种常见的关联方式:1. 内连接(Inner Join):内连接返回两个表中匹配的行。
通过指定一个共同的列或表达式来比较两个表,并只返回满足条件的行。
内连接使用关键字"INNER JOIN"来实现。
内连接可用于组合多个表中的数据,例如从"学生"表和"成绩"表中选择学生姓名和成绩:sqlSELECT 学生.姓名, 成绩.分数FROM 学生INNER JOIN 成绩ON 学生.学号= 成绩.学号;2. 左连接(Left Join):左连接返回左表中的所有行和右表中满足条件的行。
如果在右表中没有匹配的行,则返回NULL。
左连接使用关键字"LEFT JOIN"来实现。
左连接可用于显示所有学生及其对应的成绩,包括没有成绩的学生:sqlSELECT 学生.姓名, 成绩.分数FROM 学生LEFT JOIN 成绩ON 学生.学号= 成绩.学号;3. 右连接(Right Join):右连接与左连接相反,返回右表中的所有行和左表中满足条件的行。
如果在左表中没有匹配的行,则返回NULL。
右连接使用关键字"RIGHT JOIN"来实现。
右连接可用于显示所有成绩及其对应的学生,包括没有学生的成绩:sqlSELECT 学生.姓名, 成绩.分数FROM 学生RIGHT JOIN 成绩ON 学生.学号= 成绩.学号;4. 全连接(Full Join):全连接返回左表和右表中的所有行,如果在任一表中没有匹配的行,则返回NULL。
全连接使用关键字"FULL JOIN"来实现。
全连接可用于显示所有学生及其对应的成绩,同时显示没有学生的成绩和没有成绩的学生:sqlSELECT 学生.姓名, 成绩.分数FROM 学生FULL JOIN 成绩ON 学生.学号= 成绩.学号;5. 自连接(Self Join):自连接指的是在同一个表中进行连接操作。
综合练习题1.从关系中挑选出指定的属性组成新关系的运算称为()。
A.选择 B.互换 C.连接 D.投影2.在下列有关关系的陈述中,错误的是( )。
A.表中任意两行的值不能相同 B.表中任意两列的值不能相同C.行在表中的次序无关紧要D.列在表中的次序无关紧要3.在关系中,关系的键由( )。
A.多个任意属性组成 B.至多由一个属性组成C.一个或多个其值能唯一识别该关系中任何元组的属性组成D.以上都不是4. SQL Server中,数据库的主数据文献的扩展名是( )。
A. DBFB. LDF C.MDF D. NDF5.在数据库设计阶段中,下列属于概念设计阶段的描述工具的是( )。
A.ER图 B. PAD图 C.程序流程图 D.DFD图 6.数据库的并发操作会引起数据不一致的问题是 ( )。
A.丢失更新 B.数据独立性会提升C.非法用户的使用D.增加数据冗余度7. 关系数据模型的三个组成部分中,不包括( )。
A.数据约束条件B.数据结构 C.数据操作 D.数据恢复8.下列四项中说法不正确的是( )。
A.数据库减少了数据冗余 B.数据库中的数据能够共享C.数据库防止了一切数据的重复D.数据库具备较高的数据独立性9.企业中有多个部门和多名职工,每个职工只能属于一个部门,一个部门能够有多名职工,从职工到部门的联系类型是( )A. 多对一B.一对一C. 多对多 D.一对多10.用于数据库恢复的重要文献是( )。
A.备注文献B.日志文献C.数据库文献D.索引文献11.怎样结构出一个适宜的关系模型是( )重要处理的问题。
A.需求分析阶段 B.概念设计阶段C.逻辑设计阶段 D.物理设计阶段12.若事务T对数据A加上S锁,则其他事务对数据A( B )A.可加X锁 B.可加S锁 C.可加X锁和S锁 D.不能加任何锁 13.一个关系中的主键不能取空值属于( )规则。
A.参考完整性B.实体完整性C.自定义完整性 D.约束 14.在视图上不能完成的操作是(C)A.更新视图B.查询C.在视图上定义新的基本表 D.在视图上定义新视图15.要确保数据库的数据独立性,需要修改的是( )A.三层模式之间的两种映射 B.模式与内模式 C.模式与外模式 D.三层模式16.若事务T对数据A加上X锁,则其他事务对数据A(D )A.可加X锁B.可加S锁C.可加X锁和S锁D.不能加任何锁17.下列说法正确的是( )A.存储过程在创建时即在服务器上进行编译B. 触发器不是存储过程C. 创建索引是为了简化查询操作D. 以上都不正确18.SQL语言中,下列哪个子句是对数据进行分组( C )A.order by B.having C.group by D.where19.数据库系统的三级模式是指( )。
SQL Server中模式(schema)、数据库(database)、表(table)、用户(user)之间的关系数据库的初学者往往会对关系型数据库模式(schema)、数据库(database)、表(table)、用户(user)之间感到迷惘,总感觉他们的关系千丝万缕,但又不知道他们的联系和区别在哪里,对一些问题往往说不出个所以然来。
下面,我们就以SQL Server为核心,对其模式(schema)、数据库(database)、表(table)、用户(user)之间的关系展开讨论。
首先,我们先弄清楚什么是模式。
先明确一点,SQL Server中模式(schema)这个概念是在2005的版本里才提出来的,因此SQL Server2000不支持模式这个概念(本人曾在此处吃过亏)。
模式又称架构,架构的定义是形成单个命名空间的数据库实体的集合。
命名空间是一个集合,其中每个元素的名称都是唯一的。
在这里,我们可以将架构看成一个存放数据库中对象的一个容器。
上面的文字描述过于晦涩,举个简单的例子,平时要在电脑硬盘存放东西时,我们不会把所有的东西都存在一个文件夹里,而是会把不同的文件按照某一个标准分门别类,放到不同的文件夹里。
而在数据库中,起到这个作用的就是架构,数据库对象(表、视图、存储过程,触发器等)按照一定的标准,存放在不同的架构里。
有过java编程经验的同学都知道,命名空间名其实就是文件夹名,因此我们非常明确一点:一个对象只能属于一个架构,就像一个文件只能存放于一个文件夹中一样。
与文件夹不同的是,架构是不能嵌套的,如此而已。
因此,架构的好处非常明显——便于管理。
那么,现在我们来看看用户和模式(schema,即架构)有什么关系。
通过上面的分析,我们知道,一个架构可以容纳多个数据库对象,但并不是所有的用户都能访问某一个架构里的内容的,这就是所谓的权限。
看下面一张表:通过这张表,我们可以看出,用户1可以访问架构1和架构3,用户2可以访问架构1和架构2,以此类推。
数据库表与表之间的关系
表与表之间的关系有三种:⼀对⼀、⼀对多、多对多
1. ⼀对⼀
⼀张表的⼀条记录⼀定只能与另外⼀张表的⼀条记录进⾏对应;反之亦然。
⼀个常⽤表中的⼀条记录,永远只能在⼀张不常⽤表中匹配⼀条记录;反过来,⼀个不常⽤表中的⼀条记录在常⽤表中也只能匹配⼀条记录:⼀对⼀关系。
在实际的开发中应⽤不多,因为⼀对⼀可以创建成⼀张表。
建表原则:
外键唯⼀:主表的主键和从表的外键(唯⼀),形成主外键关系,外键唯⼀。
外键是主键:主表的主键和从表的外键,形成主外键关系。
2. ⼀对多
⼀张表中有⼀条记录可以对应另外⼀张表中的多条记录;但是反过来,另外⼀张表的⼀条记录只能对应第⼀张表的⼀条记录。
建表原则:
在“多”的⼀⽅创建⼀个字段,字段作为外键指向“⼀”的⼀⽅的主键。
3. 多对多
第⼀张表中的⼀条记录能够对应第⼆张表中的多条记录;同时第⼆张表中的⼀条记录也能对应第⼀张表中的多条记录。
中间表与⽼师表形成⼀对多的关系,⽽且中间表是“多”的⼀⽅,维护了能够唯⼀找到“⼀”表的关系;同样的,学⽣表与中间表也形成了⼀对多的关系。
⽼师找学⽣:⽼师表-中间表-学⽣表
学⽣赵⽼师:学⽣表-中间表-⽼师表
建表原则:
创建第三张表,中间表⾄少两个字段,分别作为外键指向各⾃⼀⽅的主键。
第一章数据库基础1数据库系统:是由数据库及其管理软件组成的系统,常常把数据库有关的硬件和软件系统成为数据库系统2.数据库:数据库就是数据的仓库,由表、关系以及操作对象组成3.数据:是描述事物的符号记录(数字、文字、图形、图像、声音等)4.数据库的作用存储大量数据,方便检索和访问保持数据信息的一致、完整共享和安全通过组合分析,产生新的有用信息5.数据库经历的三个阶段及特点1)人工管理阶段: 数据不保存;使用应用程序管理数据;数据不共享;数据不具有独立性。
2)文件系统阶段:数据可以长期保存;由文件系统管理数据;共享性差,数据冗余大;数据独立性差。
3)数据库系统阶段:数据结构化;数据共享性高;数据独立性强;数据粒度小;独立的数据操作界面;统一管理和控制6.数据模型的分类层次模型网络模型关系模型7.E-R图三个主要部分1)1.实体集:在E-R图中用长方形来表示实体集,实体是实体集的成员。
2) 联系:在E-R图中用菱形来表示联系,联系与其涉及的实体集之间以直线连接,并在直线端部标上联系的种类, (1:1,1:N,M:N)。
3) 属性:在E-R图中用椭圆形来表示实体集和联系的属性,对于主键码的属性,在属性名下划一横线。
8.绘制E-R图所需的图形1) 长方形框----实体集(考虑问题的对象)2) 菱形框----联系(实体集间联系)3) 椭圆形框----实体集和联系的属性4) 直线----连接相关的联系和实体,并可标上联系的种类9.E-R图设计原则:真实性;避免冗余;简单性10.三大范式第一范式:在关系模型中的每一个具体关系R中,如果每个属性都是不可再分的,则称关系(R)属于第一范式(1NF)第二范式:如果关系模式R属于第一范式,且每一个非主属性都完全依赖于主码,则称关系R是属于第二范式的第三范式:如果关系模式R为2NF,并且R中的每个非主属性不传递依赖于R的主码,则称关系R是属于第三范式的第二章数据库的安装1.常见的数据库类型:Access、SQL server2000、2005、2008,Oracle数据库等2.数据库管理员的工作是:配置数据库服务器环境;管理数据库的逻辑对象结构;配置数据库的对象权限;制定数据库的性能优化策略;数据库的备份还原策略;数据库的异构协同结构3.SQL Server 2008 的版本Express 适用于无连接的客户端或独立应用程序Workgroup 适用于工作组或分支机构操作的数据库Standard 部门级应用程序的数据库服务器Enterprise 高度可伸缩和高度可用的企业级数据库Developer Enterprise 版,但是只授予开发和测试用许可Web 供托管公司提供低成本、高伸缩的托管服务,只收取低廉的每月许可费Mobile 用于智能手持式设备的精简数据库12.掌握SQL Server 2008数据库的安装与卸载第三章数据库的管理1.T-SQL语言分类DDL(数据定义语言)-create(创建)-alter (修改)-drop (删除)DQL(数据查询语言)-inter(插入)-update(更新)DML(数据操作语言)-select(查询)DCL(数据控制语言)-revoke(撤销)-deny(拒绝)-grant(同意、授权)2.数据库文件主数据文件(.mdf):一个数据库有且只有一个辅助数据文件(.ndf):根据需要自由选择,当数据库很大时,可以选择多个日志文件(.ldf):用于存储恢复数据库所需的事务日志信息3.掌握数据库的创建及修改(图形化及代码)修改数据库包括:扩展、收缩、分离附加、删除4.语法1)修改数据库名Alter database 原数据库名Modify name =新数据库名例子:【例】将数据库book的名字改为booksalter database bookmodify name=books2)修改文件属性Alter database 数据库名Modify file(name='逻辑名',size=修改后的大小,maxsize=修改后的大小,filegrowth=修改后的大小)Go例子:把初始大小由原来5mb增大为12mbalter database booksmodify file(name='book_data',size=12mb)go3)添加日志文件Alter database 数据库名Add log file(name= ‘逻辑名’,filename = ‘文件的存放路径’,size=日志文件的初始大小,maxsize=日志文件的最大大小,filegrowth=日志文件的增长方式)Go例子:【例】向shop数据库中添加一个日志文件alter database shopadd log file(name='shop_log2',filename ='c:\shop_log2.ldf',size=10mb, maxsize=20mb,filegrowth=10%)go4)删除空文件Alter database 数据库名Remove file 文件的逻辑名例子: 删除文件shop_data2 alterdatabase shop removefile shop_data24)添加辅助数据文件alter database 数据库名add file(name=‘逻辑名’,filename=‘文件存放的路径’,size=初始大小,maxsixe=最大大小,filegrowth=增长方式)Go例子:向数据库shop中添加一个辅助数据文件alter database shopadd file(name='shop_data3',filename='c:\shop_data3.ndf',size=5mb,maxsize=10mb,filegrowth=10%)go5)创建/删除数据库Create database 数据库名on primary( --数据文件name=‘逻辑名’,filename=‘文件的存放路径’,size=数据文件的初始大小,maxsize=数据文件的最大大小,filegrowth=文件的增长方式 )log on ( --日志文件name=‘逻辑名’,filename=‘文件的存放路径’,size=数据文件的初始大小,maxsize=数据文件的最大大小,filegrowth=文件的增长方式 )go例子:创建一个名为book的数据库,其初始值大小为5MB,最大大小为 50MB,允许数据库自动增长,增长方式是按10%比例增长;日志文件初始为2MB,最大可增长到5MB,按1MB增长。
sql server 表依赖关系
在SQLServer中,表依赖关系是指一个对象依赖于另一个对象的关系。
特别是,当一个对象引用另一个对象时,这个依赖就被建立了。
依赖关系可以是通过建立引用关系或定义外键等方式建立的。
在SQL Server中,表之间的依赖可以是以下几种类型:
1. 引用关系:一个表引用了另一个表的列或对象。
2. 外键依赖:一个表参照了另一个表的主键或唯一键来定义一个外键。
3. 数据库对象依赖:一个表与其他的数据库对象(如存储过程、视图、函数等)建立了依赖关系。
4. 联接关系:一个表与其他表通过联接建立了依赖关系。
在SQL Server中,我们可以通过以下方式来查找表之间的依赖关系:
1. 使用SQL Server Management Studio中的“Object Explorer”窗口,选择“Object Dependencies”选项卡,然后选择要查询的对象。
2. 使用系统函数和视图:sys.sql_expression_dependencies、sys.sql_dependencies和sys.sql_dependent_objects等系统视图和函数可以用来查询依赖关系。
3. 使用第三方工具:一些第三方工具如Red-Gate SQL Dependency Tracker等可以帮助我们更方便地查询依赖关系。
总之,了解表之间的依赖关系是SQL Server管理和维护数据库
的重要一环。
通过了解这些依赖关系,我们可以更好地进行数据库设计、优化和维护工作。
三、填空题(每空1分,共20分)1.数据库系统具有数据的___外模式____、__模式_____和内模式三级模式结构。
2.SQL Server 2000局部变量名字必须以____@、_____开头,而全局变量名字必须以______@@___开头。
3.语句select ascii('D'), char(67) 的执行结果是:___68______和__C_______。
68、C",24.语句 select lower('Beautiful') , rtrim('我心中的太阳 ') 的执行结果是:_beautiful____和___我心中的太阳_____。
5.选择运算是根据某些条件对关系做_ 水平__分割;投影是根据某些条件对关系做____垂直"__分割。
"6.关系运算主要有___选择___、__投影__和连接。
7.完整性约束包括__实体__完整性、_域____性、参照完整性和用户定义完整性。
8.在SQL Server 2000中,数据库对象包括__表__、___视图__、触发器、过程、列、索引、约束、规则、默认和用户自定义的数据类型等。
9.语句 select day('2004-4-6'), len('我们快放假了.') 的执行结果是:___6______和____7____。
10.语句select round(13.4321,2), round(13.4567,3)的执行结果是:__13.4300_______和____13.4570_____。
11.完整性约束包括____域___完整性、__实体____完整性、参照完整性和用户定义完整性。
12.T-SQL 语言中,有__算术__运算、字符串连接运算、比较运算和__逻辑__运算。
13.语句 select upper('beautiful') , ltrim(' 我心中的太阳') 的执行结果是: ______ BEAUTIFUL __和__我心中的太阳___。
SQL Server中模式(schema)、数据库(database)、表(table)、
用户(user)之间的关系
数据库的初学者往往会对关系型数据库模式(schema)、数据库(database)、表(table)、用户(user)之间感到迷惘,总感觉他们的关系千丝万缕,但又不
知道他们的联系和区别在哪里,对一些问题往往说不出个所以然来。
下面,我们就以SQL Server为核心,对其模式(schema)、数据库(database)、表(table)、用户(user)之间的关系展开讨论。
首先,我们先弄清楚什么是模式。
先明确一点,SQL Server中模式(schema)这个概念是在2005的版本里才提出来的,因此SQL Server2000不支持模式这个概念(本人曾在此处吃过亏)。
模式又称架构,架构的定义是形成单个命名空间的数据库实体的集合。
命名空间是一个集合,其中每个元素的名称都是唯一的。
在这里,我们可以将架构看成一个存放数据库中对象的一个容器。
上面的文字描述过于晦涩,举个简单的例子,平时要在电脑硬盘存放东西时,我们不会把所有的东西都存在一个文件夹里,而是会把不同的文件按照某一个标准分门别类,放到不同的文件夹里。
而在数据库中,起到这个作用的就是架构,数据库对象(表、视图、存储过程,触发器等)按照一定的标准,存放在不同的架构里。
有过java编程经验的同学都知道,命名空间名其实就是文件夹名,因此我们非常明确一点:一个对象只能属于一个架构,就像一个文件只能存放于一个文件夹中一样。
与文件夹不同的是,架构是不能嵌套的,如此而已。
因此,架构的好处非常明显——便于管理。
那么,现在我们来看看用户和模式(schema,即架构)有什么关系。
通过上面的分析,我们知道,一个架构可以容纳多个数据库对象,但并不是所有的用户都能访问某一个架构里的内容的,这就是所谓的权限。
看下面一张表:
通过这张表,我们可以看出,用户1可以访问架构1和架构3,用户2可以访问架构1和架构2,以此类推。
在sql server2000中,用户和架构是不分离的,到了2005才分离。
其实2000中的用户和架构概念就是为用户分配固定的模式,即如下表:
综合上面所述,用户和构架的关系是多对多的——一个架构可以对应多个用户,一个用户也可以对应多个架构。
现在,我们来讨论一下,数据库(database)和模式(schema)有什么关系。
举个很浅显的例子,我们可以可以把数据库看作是一个大仓库,仓库分了很多很多的房间,Schema就是其中的房间,一个Schema代表一个房间,于是乎,在不同的房间里,我们可以放不同的东西——有的放食物,有的放衣物……而这些不同的东西,就对应着我们数据库里的对象。
因此,我们可以看到,数据库与模式时一对多的关系。
总结一下,其实我们的数据库就是一个数据的大仓库,而里面创建了很多很多模式,分别放着不同的数据库对象(包括表),而访问不同的模式需要有不同的权限,于是,不同的用户就有不同的访问权限来访问某个模式里的数据库对象。
参考资料:
/2009-01/1231832216105719.html
/2009-01/1231832308105720.html
/u/20081226/23/d1570ce9-e183-453c-90ec-c6c0f297d8ff.html。