OpenCV学习笔记(18)双目测距与三维重建的OpenCV实现问题集锦(三)立体匹配与视差计算
- 格式:pdf
- 大小:886.41 KB
- 文档页数:11

一、概述双目视觉是一种通过两个摄像头拍摄同一场景来获取深度信息的技术,它在计算机视觉领域有着广泛的应用。
在双目视觉中,图像识别、匹配和三维重建是其中的关键环节。
OpenCV是一个开源的计算机视觉库,提供了丰富的图像处理和计算机视觉算法。
本文将介绍使用OpenCV实现双目视觉三维重建的代码,帮助读者快速上手这一技术。
二、环境准备在开始编写双目视觉三维重建代码之前,我们需要准备好相应的开发环境。
首先确保已经安装了OpenCV库,可以通过冠方全球信息站或者包管理工具进行安装。
需要准备两个摄像头,保证两个摄像头的焦距、畸变参数等校准信息。
确保安装了C++或者Python的开发环境,以便编写和运行代码。
三、双目视觉图像获取1. 初始化摄像头在代码中需要初始化两个相机,并设置相应的参数,例如分辨率、曝光时间、白平衡等。
可以使用OpenCV提供的方法来实现这一步骤。
2. 同步获取图像由于双目视觉需要同时获取两个摄像头的图像,所以我们需要确保两个摄像头的图像获取是同步的。
可以通过多线程或者硬件同步的方式来实现图像的同步获取。
四、双目视觉图像预处理1. 图像校准由于摄像头的畸变等因素会影响后续的视图匹配和三维重建结果,因此需要对图像进行校准。
可以使用OpenCV提供的摄像头校准工具来获取相机的内参和外参,通过这些参数对图像进行去畸变处理。
2. 图像匹配在获取到双目图像之后,需要对这两个图像进行特征提取和匹配。
可以使用SIFT、SURF等特征提取算法来提取图像的关键点,并使用特征匹配算法(例如FLANN或者暴力匹配)来进行图像匹配。
五、立体匹配1. 视差计算在进行图像匹配之后,我们可以通过计算视差来获取场景中不同物体的深度信息。
OpenCV提供了多种视差计算算法,例如BM、SGBM 等,可以根据实际情况选择适合的算法。
2. 深度图生成通过视差计算得到的视差图可以进一步转换为深度图,从而得到场景中每个像素点的深度信息。

中文摘要中文摘要随着工业自动化的高速发展,机器人等智能设备在工业生产中的应用日渐广泛。
对周边环境的感知是设备智能化的一项重要研究内容,目前,获取周边三维环境信息的主要技术途径以激光雷达和双目相机为主,与超声波传感器、激光雷达相比,双目相机具有获取信息丰富,价格低廉,精度高的特点,通常应用于实时测距、三维形貌恢复、缺陷诊断等领域。
智能设备在实际作业时,对周围的三维环境进行精确的三维重建有助于实际作业的安全有效进行,本文基于深度学习算法,对双目视觉系统的三维重建进行研究。
本文的主要研究内容有:(1)研究了当前摄像头标定的主流方法,对其具体算法实现进行了分析,通过对双目相机进行标定得到相机的内参数和外参数,基于相机的内外参数实现图像矫正、三维重建工作。
(2)对相机的成像和畸变原理进行分析和研究,对采集图像进行滤波、自适应伽马变换与去畸变处理,提高双目相机采集图像的质量。
(3)对双目视觉中最关键的算法——立体匹配算法进行研究,为了解决传统立体匹配算法匹配精度较低,误匹配区域较大的问题,本文基于深度学习算法,利用2D卷积神经网络对双目相机获取的左、右图进行匹配代价提取,并利用3D卷积神经网络对聚合后的匹配代价进行特征总结和匹配差异学习。
将立体匹配问题转化为一个有监督的机器学习问题,在KIIT2015数据集上训练一个端到端的神经网络模型,该卷积神经网络直接使用双目相机获取的左右两图作输入,直接输出预测的视差图。
(4)通过相机内外参数及立体匹配视差图得到周围环境的三维点云信息,并通过阈值分割算法提取特定工作范围内的稠密点云数据。
(5)搭建了综合实验平台,与其它算法的立体匹配效果进行对比,并对比标准雷达测距数据计算本文算法的精确度,验证了本文算法的有效性。
关键词:双目视觉;立体匹配;深度学习;三维重建I基于深度学习的双目视觉三维重建IIABSTRACTABSTRACTWith the rapid development of industrial automation,smart devices such as robots are increasingly used in industrial production.Perception of the surrounding environment is an important research content of device intelligence.At present,we mainly obtain three-dimensional information of the surrounding environment through lidar and binocular pared with ultrasonic sensors and lidar,binocular cameras obtain It is more abundant,the price is lower,and the accuracy is higher.It is usually used in real-time ranging, three-dimensional shape restoration,defect diagnosis and other fields.During the actual operation of the smart device,accurate3D reconstruction of the surrounding3D environment is helpful for the safe and effective operation of the actual operation.Based on the deep learning algorithm,this paper studies the3D reconstruction of the binocular vision system. The main research contents of this article are:(1)This paper studies the current mainstream camera calibration methods,analyzes its specific algorithm implementation,obtains the camera's internal and external parameters by calibrating the binocular camera,and implements image correction and3D reconstruction based on the camera's internal and external parameters.(2)This paper analyzes and studies the imaging and distortion principles of the camera, and filters,adaptive gamma transforms,and distorts the collected images to improve the quality of the images captured by the binocular camera.(3)This paper studies the most critical algorithm in binocular vision-stereo matching algorithm.In order to solve the problems of low matching accuracy and large mismatching area of traditional stereo matching algorithms,this paper uses a2D convolution neural network to extract the matching cost of the left and right images obtained by the binocular camera based on deep learning algorithms,and uses3D The product neural network performs feature summarization and matching difference learning on the aggregated matching costs. Turn the stereo matching problem into a supervised machine learning problem.Train an end-to-end neural network model on the KIIT2015dataset.The convolutional neural network directly uses the left and right images obtained by the binocular camera as input,and directly output the predicted Disparity map.(4)Obtain the three-dimensional point cloud information of the surrounding environmentIII基于深度学习的双目视觉三维重建through the internal and external parameters of the camera and the stereo matching disparity map,and extract the dense point cloud data within a specific working range through the threshold segmentation algorithm.(5)A comprehensive experimental platform was built to compare the stereo matching effect with other algorithms,and to compare the accuracy of the algorithm in this paper with standard radar ranging data to verify the effectiveness of the algorithm in this paper.Key words:Binocular vision;stereo matching;deep learning;3D reconstructionIV目录目录第一章绪论 (1)1.1课题的研究背景及意义 (1)1.2国内外研究现状 (1)1.3论文主要内容及工作 (5)第二章相机标定及图像预处理 (7)2.1单目相机数学模型 (7)2.2双目相机数学模型 (9)2.3双目相机的标定 (11)2.3.1张正友标定法 (11)2.3.2立体标定 (13)2.3.2畸变参数估计 (14)2.4双目极线矫正 (15)2.5图像预处理 (17)2.5.1图像去噪 (18)2.5.1伽马变换 (18)2.6本章小结 (20)第三章基于深度学习的立体匹配 (21)3.1传统立体匹配算法的基本理论 (21)3.2基于深度学习的立体匹配发展 (23)3.2.1深度学习的基本原理 (23)3.2.2mc-cnn与GC-net (27)3.3基于W-net的立体匹配 (29)3.3.1残差结构与通道注意模块介绍 (29)3.3.2W-ne2D模块(2D卷积网络部分) (31)3.3.3Cost Value模块(代价聚合部分) (33)3.3.4W-net3D模块(3D卷积网络部分) (34)3.3.5Prob模块(视差预测部分) (36)3.3.6数据集的选择 (37)3.3.7损失函数的选择 (37)V基于深度学习的双目视觉三维重建3.3.8权值初始化及优化算法 (38)3.3.9网络结构说明 (39)3.4本章小结 (40)第四章基于视差图的三维重建 (41)4.1整体视差图的三维点云 (41)4.2视差图处理 (44)4.3点云滤波处理 (47)4.4本章小结 (48)第五章基于双目相机的三维点云重建算法与平台的实现 (49)5.1Pytorch、Opencv、Qt简介 (49)5.2平台开发环境 (49)5.3算法流程与实验结果分析 (50)5.4本章小结 (58)第六章总结与展望 (59)参考文献 (61)致谢 (65)附录 (67)VI第一章绪论第一章绪论1.1课题的研究背景及意义计算机视觉的任务是赋予计算机“自然视觉”的能力,使计算机对输入的图像(视频)进行处理,实现对图像中内容的表达和理解。

学习笔记:使⽤opencv做双⽬测距(相机标定+⽴体匹配+测距).最近在做双⽬测距,觉得有必要记录点东西,所以我的第⼀篇博客就这么诞⽣啦~双⽬测距属于⽴体视觉这⼀块,我觉得应该有很多⼈踩过这个坑了,但⽹上的资料依旧是云⾥雾⾥的,要么是理论讲⼀⼤堆,最后发现还不知道怎么做,要么就是直接代码⼀贴,让你懵逼。
所以今天我想做的,是尽量给⼤家⼀个明确的阐述,并且能够上⼿做出来。
⼀、标定⾸先我们要对摄像头做标定,具体的公式推导在learning opencv中有详细的解释,这⾥顺带提⼀句,这本书虽然确实⽼,但有些理论、算法类的东西⾥⾯还是讲的很不错的,必要的时候可以去看看。
Q1:为什么要做摄像头标定?A: 标定的⽬的是为了消除畸变以及得到内外参数矩阵,内参数矩阵可以理解为焦距相关,它是⼀个从平⾯到像素的转换,焦距不变它就不变,所以确定以后就可以重复使⽤,⽽外参数矩阵反映的是摄像机坐标系与世界坐标系的转换,⾄于畸变参数,⼀般也包含在内参数矩阵中。
从作⽤上来看,内参数矩阵是为了得到镜头的信息,并消除畸变,使得到的图像更为准确,外参数矩阵是为了得到相机相对于世界坐标的联系,是为了最终的测距。
ps1:关于畸变,⼤家可以看到⾃⼰摄像头的拍摄的画⾯,在看矩形物体的时候,边⾓处会有明显的畸变现象,⽽矫正的⽬的就是修复这个。
ps2:我们知道双⽬测距的时候两个相机需要平⾏放置,但事实上这个是很难做到的,所以就需要⽴体校正得到两个相机之间的旋转平移矩阵,也就是外参数矩阵。
Q2:如何做摄像头的标定?A:这⾥可以直接⽤opencv⾥⾯的sample,在opencv/sources/sample/cpp⾥⾯,有个calibration.cpp的⽂件,这是单⽬的标定,是可以直接编译使⽤的,这⾥要注意⼏点:1.棋盘棋盘也就是标定板是要预先打印好的,你打印的棋盘的样式决定了后⾯参数的填写,具体要求也不是很严谨,清晰能⽤就⾏。
之所⽤棋盘是因为他检测⾓点很⽅便,and..你没得选。

opencv的双目立体校正函数-回复OpenCV(开源计算机视觉库)提供了一系列功能强大的函数,用于处理双目立体视觉任务。
其中一个关键函数是双目立体校正函数(stereoRectify),它在立体视觉中用于消除摄像机畸变并将两个摄像机的图像校正到一个共同的平面上。
本文将从头开始一步一步解释这个函数的操作。
第一步:导入必要的库和模块首先,需要导入OpenCV库和其他需要的库和模块。
在Python中,可以使用以下代码导入这些库:pythonimport cv2import numpy as np第二步:定义相机参数和视差参数在进行双目立体校正之前,需要定义每个摄像机的参数和视差参数。
这些参数包括相机内参、相机畸变系数、旋转矩阵和投影矩阵等。
为了简化说明,我们这里使用一个简化的示例参数:python# 相机内参cameraMatrix1 = np.eye(3)cameraMatrix2 = np.eye(3)# 相机畸变系数distCoeffs1 = np.zeros((5, 1))distCoeffs2 = np.zeros((5, 1))# 至关重要的矩阵R = np.eye(3)T = np.zeros((3, 1))这些参数是根据相机特性和摄像机标定过程获得的。
在实际应用中,应根据具体情况相应地设置这些参数。
第三步:计算校正变换矩阵通过使用上述相机参数和视差参数,可以计算出双目立体校正所需的校正变换矩阵。
校正变换矩阵将两个摄像机的图像校正到一个共同的平面上。
在OpenCV中,可以使用以下代码计算校正变换矩阵:python# 计算校正变换矩阵及其逆矩阵rectifyScale = 1 # 校正后图像的缩放因子R1, R2, P1, P2, Q, validPixROI1, validPixROI2 =cv2.stereoRectify(cameraMatrix1, distCoeffs1, cameraMatrix2, distCoeffs2, imageSize, R, T, rectifyScale)在上述代码中,imageSize是输入图像的大小。

基于双目线结构光的三维重建及其关键技术研究基于双目线结构光的三维重建是一种常见的三维重建方法,在计算机视觉和图像处理领域有广泛应用。
本文将探讨双目线结构光三维重建的基本原理和关键技术。
一、基本原理双目线结构光的三维重建基于以下原理:通过投射具有特定空间编码的光线,利用摄像机捕捉图像,并对图像进行处理和分析,可以推断出场景中物体的三维形状和深度信息。
二、关键技术1. 双目成像双目成像是双目线结构光重建的基础。
通过使用两个物理上分开的相机,可以获取场景的不同视角,从而获得更多的信息,提高重建的精度和稳定性。
2. 线结构光投影线结构光投影是双目线结构光重建的核心技术。
通过投射特定编码的结构光,可以在场景中形成一系列光条或光带,从而在摄像机中产生对应的图像。
这样,可以通过分析图像中结构光的失真或形状变化,来推断物体表面的深度信息。
3. 结构光编码结构光编码是双目线结构光重建的重要组成部分。
通过在结构光中引入编码,可以增加光条或光带的区分度,从而提高重建的精度。
常见的编码方法包括灰度编码、正弦编码、校正编码等。
4. 影像获取与处理双目线结构光重建需要获取并处理图像数据。
影像获取涉及到摄像机的标定、同步和触发等技术,以确保双目系统的准确性和稳定性。
影像处理包括去噪、校准、纹理映射等步骤,以提取出有效的结构光信息,并进行后续的三维重建处理。
5. 三维重建算法三维重建算法是双目线结构光重建的核心内容。
常见的算法包括三角测量、立体匹配、点云拼接等。
这些算法通过分析不同视角的结构光图像,通过匹配和计算来推断物体的三维形状和深度信息。
6. 点云处理与可视化三维重建通常最终呈现为点云模型。
点云处理涉及到点云滤波、配准、分割等技术,以去除噪声、合并重叠点云、提取物体表面等。
点云可视化则将点云数据以直观的形式呈现,便于人们观察和理解。
综上所述,基于双目线结构光的三维重建是一种常见的三维重建方法。
它利用投射特定编码的结构光,结合双目成像和影像处理技术,通过分析图像中的结构光信息,推断物体的三维形状和深度信息。

双目视觉的目标三维重建matlab
双目视觉的目标三维重建是一个复杂的过程,它涉及到许多步骤,包括相机标定、立体匹配、深度估计和三维重建。
以下是一个简化的双目视觉的目标三维重建的Matlab实现步骤:
1. 相机标定:首先,我们需要知道相机的内部参数(例如焦距和主点坐标)和外部参数(例如旋转矩阵和平移向量)。
这些参数通常通过标定过程获得。
在Matlab中,可以使用`calibrateCamera`函数进行相机标定。
2. 立体匹配:立体匹配是确定左右两幅图像中对应像素点的过程。
这可以通过使用诸如SGBM(Semi-Global Block Matching)等算法来完成。
在Matlab中,可以使用`stereoMatch`函数进行立体匹配。
3. 深度估计:一旦我们有了立体匹配的结果,就可以估计像素点的深度。
深度通常由视差和相机参数计算得出。
在Matlab中,可以使用
`depthFromDisparity`函数根据立体匹配结果计算深度。
4. 三维重建:最后,我们可以使用深度信息将像素点转换到三维空间中,从而得到目标的三维模型。
这通常涉及到一些几何变换和插值操作。
在Matlab中,可以使用`projective2DCoordinates`函数将像素坐标转换为三维空间中的坐标。
以上步骤只是一个基本的流程,实际应用中可能需要进行更复杂的处理,例如处理遮挡、噪声、光照变化等问题。
注意:以上步骤可能需要根据实际项目需求进行调整和优化,并且需要具备一定的计算机视觉和Matlab编程基础才能理解和实现。
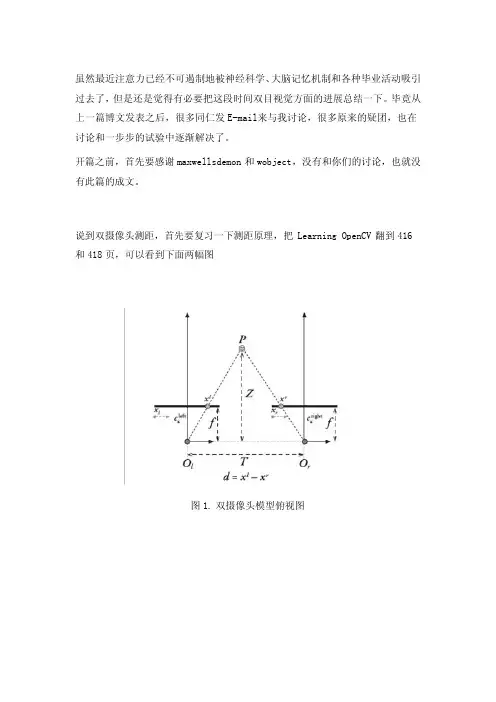
虽然最近注意力已经不可遏制地被神经科学、大脑记忆机制和各种毕业活动吸引过去了,但是还是觉得有必要把这段时间双目视觉方面的进展总结一下。
毕竟从上一篇博文发表之后,很多同仁发E-mail来与我讨论,很多原来的疑团,也在讨论和一步步的试验中逐渐解决了。
开篇之前,首先要感谢maxwellsdemon和wobject,没有和你们的讨论,也就没有此篇的成文。
说到双摄像头测距,首先要复习一下测距原理,把Learning OpenCV翻到416和418页,可以看到下面两幅图图1. 双摄像头模型俯视图图2, 双摄像头模型立体视图图1解释了双摄像头测距的原理,书中Z的公式如下:在OpenCV中,f的量纲是像素点,Tx的量纲由定标棋盘格的实际尺寸和用户输入值确定,一般总是设成毫米,当然为了精度提高也可以设置为0.1毫米量级,d=xl-xr的量纲也是像素点。
因此分子分母约去,z的量纲与Tx相同图2解释了双摄像头获取空间中某点三维坐标的原理。
可以看到,实际的坐标计算利用的都是相似三角形的原理,其表达式就如同Q矩阵所示。
空间中某点的三维坐标就是(X/W, Y/W, Z/W)。
因此,为了精确地求得某个点在三维空间里的距离,我们需要获得的参数有焦距f、视差d、摄像头中心距Tx。
如果还需要获得X坐标和Y坐标的话,那么还需要额外知道左右像平面的坐标系与立体坐标系中原点的偏移cx 和cy。
其中f, Tx, cx和cy可以通过立体标定获得初始值,并通过立体校准优化,使得两个摄像头在数学上完全平行放置,并且左右摄像头的cx , cy和f相同(也就是实现图2中左右视图完全平行对准的理想形式)。
而立体匹配所做的工作,就是在之前的基础上,求取最后一个变量:视差d(这个d一般需要达到亚像素精度)。
从而最终完成求一个点三维坐标所需要的准备工作。
在清楚了上述原理之后,我们也就知道了,所有的这几步:标定、校准和匹配,都是围绕着如何更精确地获得f, d, Tx, cx 和cy而设计的。


opencv双目视差计算全文共四篇示例,供读者参考第一篇示例:双目视差计算是通过两个摄像头同时拍摄同一场景,然后根据两个图像之间的视差来计算物体的深度信息。
视差是指由于物体在不同位置出现在两个摄像头的画面中而产生的位置差异,通过测量这种位置差异可以推断物体距离和深度信息。
双目视差计算的原理是根据两张图片的对应像素点之间的位置差异来计算物体的深度信息。
当两张图片之间的视差越大时,物体离摄像头的距离就越近;反之,当两张图片之间的视差越小时,物体离摄像头的距离就越远。
在OpenCV中,双目视差计算主要通过立体匹配算法来实现。
立体匹配算法是将两幅图像中的像素进行匹配,找出它们之间的对应关系,然后根据匹配后的像素点之间的位置差异来计算深度信息。
常用的立体匹配算法包括局部块匹配、全局块匹配、Semi-Global Block Matching(SGBM)等。
这些算法都可以在OpenCV中找到相应的实现函数,方便我们进行双目视差计算的应用开发。
双目视差计算在机器人导航、自动驾驶、三维重建等领域都有着广泛的应用。
在机器人导航中,通过双目视差计算可以实现对环境中障碍物的检测和避障;在自动驾驶中,可以实现对道路情况的实时监测和智能决策;在三维重建中,可以实现对物体形状和结构的精确还原。
双目视差计算的应用将极大地提高计算机视觉系统的性能和效率,为人工智能技术的发展提供重要支持。
双目视差计算虽然开发应用广泛,但是在实际应用中依然存在一些挑战和难题。
双目摄像头的安装和校准是非常关键的一步,需要保证两个摄像头的视场相同、成像质量一致,否则会影响视差计算的准确性。
双目视差计算的算法选择和参数调优也会影响计算结果的准确性和稳定性,需要根据具体的应用场景来选择适合的算法和参数设置。
双目视差计算对计算资源的要求较高,需要较大的计算能力和存储空间来支持大规模的图像处理和深度计算。
双目视差计算作为计算机视觉领域的重要研究方向,借助OpenCV等计算机视觉库的支持,可以帮助我们实现对物体深度信息的精确测量和计算。

双目摄像头三维重建技术的应用研究随着科技的不断发展,各种高新技术开始被广泛应用于我们的生产和生活中。
其中,双目摄像头三维重建技术是一个十分有趣的技术,该技术可以通过记录物体在不同角度下的图像来生成三维模型,具有广泛的应用前景。
在本文中,我们将探讨双目摄像头三维重建技术的应用研究。
一、双目摄像头三维重建技术的原理双目摄像头三维重建技术是一种基于三角测量原理的技术。
其原理是通过左右两个摄像头同时拍摄同一物体的两幅图像,并利用三角测量技术推算出物体的三维坐标信息,最终构建出物体的三维模型。
具体来说,双目摄像头拍摄的两幅图像中,同一物体在两幅图像中的位置存在差异,这种差异可以被称为“视差”。
通过对视差的计算,便可以确定物体的三维坐标。
二、双目摄像头三维重建技术的应用1、虚拟现实技术虚拟现实技术是一种基于计算机图形学、虚拟场景模拟、人机交互等技术制造出类似真实世界的虚拟环境的技术。
双目摄像头三维重建技术可以为虚拟现实技术提供完美的三维模型,可以更加准确地模拟现实场景,且用户可以从不同的视角欣赏场景。
2、医疗领域双目摄像头三维重建技术可以为医生提供非常准确的患者信息,比如精确的脑部图像等。
医生们可以通过这种技术更好地观察和分析病症的情况,制定更为精准的治疗方案。
3、建筑设计在建筑设计领域,利用双目摄像头三维重建技术可以为建筑师和设计师提供准确的建筑物三维模型,更好地辅助他们的设计、改进和沟通。
4、文化遗产保护对于文化遗产的保护,双目摄像头三维重建技术可以提供非常强大的支持。
通过利用该技术记录文化遗产物体的三维模型,可以实现文物数字化保护,同时,也可以为研究人员提供更为精准的文物信息。
三、双目摄像头三维重建技术的优势与不足1、优势(1)记录的三维模型非常精准,可以提供更为真实的模拟场景。
(2)相比传统的三维模型技术,双目摄像头三维重建技术可以得到更加真实和清晰的物体图像。
(3)该技术可以应用于多个领域,并且具有非常广泛的应用前景。

opencv双目标定双目相机是指一种拥有两个摄像头的相机系统,它们被安装在相对固定的位置上,模拟人眼的视觉系统的工作原理,从而可以实时捕捉和测量目标的三维结构和运动信息。
为了实现有效的三维视觉分析和计算机视觉任务,需要进行相机标定,即确定相机的内参和外参。
OpenCV是一个开源的计算机视觉库,提供了一系列用于相机标定的函数和工具。
下面将介绍如何使用OpenCV进行双目相机标定。
双目相机标定的步骤如下:1. 收集标定板图像,标定板是一个已知尺寸的棋盘格,通过拍摄不同姿态的标定板图像可以得到相机的内参和外参。
要注意的是,标定板要尽量填满整个图像空间,并且要保证标定板的图案清晰可见。
2. 在OpenCV中使用`cv::findChessboardCorners`函数寻找标定板的角点坐标。
该函数会返回标定板角点的像素坐标。
3. 使用`cv::calibrateCamera`函数进行内参标定,该函数会返回相机的内参矩阵和失真系数。
同时,还可以使用`cv::undistort`函数进行图像的去畸变操作。
4. 利用标定板角点的像素坐标和相应的三维世界坐标,使用`cv::stereoCalibrate`函数进行外参标定,该函数会返回两个相机之间的旋转矩阵和平移向量。
5. 对于双目图像,可以使用`cv::stereoRectify`函数进行图像的校正操作,使得两个相机的光轴平行,并且水平排布。
6. 校正后的图像可以用于立体视觉匹配和三维重建等任务。
对于立体视觉匹配,可以使用OpenCV中的`cv::StereoBM`和`cv::StereoSGBM`等函数进行视差图像的计算。
对于三维重建,可以根据得到的内参、外参和视差信息,利用三角测量等方法得到物体的三维坐标。
双目相机标定是计算机视觉中重要的一步,可以为后续的三维分析任务提供准确的视角和距离信息。
通过OpenCV提供的函数和工具,可以方便地进行双目相机标定,并且得到准确的内参、外参和视差信息,从而实现更精确的三维视觉分析。
双目测距算法
双目测距算法是一种利用双目相机系统来测量目标距离的方法。
其基本原理是利用目标点在左右两幅视图上成像的横向坐标直接存在的差异(即视差)与目标点到成像平面的距离Z存在着反比例的关系。
在双目视觉系统中,两个相机被放置在同一个平面上,并且它们之间的距离是已知的。
通过计算同一目标点在两个相机中的视差,可以确定目标点在三维空间中的位置。
具体来说,双目视觉系统中的两个相机通过镜头将目标点投影到各自的成像平面上。
由于两个相机之间的距离是已知的,因此可以通过计算同一目标点在两个相机中的视差来计算目标点到成像平面的距离Z。
在实际应用中,双目视觉系统需要经过标定和校准,以确定相机的内部参数(如焦距、光心位置等)和外部参数(如相机的旋转和平移矩阵)。
这些参数可以帮助准确地计算出目标点的三维位置。
需要注意的是,双目视觉系统中的视差计算需要考虑到相机的畸变、光照条件、目标点的特征等因素。
因此,在实际应用中,需要根据具体情况进行适当的优化和调整。
以上是双目测距算法的基本原理和步骤。
opencv 双目拼接摄像机原理OpenCV是一个广泛应用于计算机视觉和图像处理领域的开源库,提供了丰富的函数和工具,用于处理图像和视频数据。
其中,双目拼接摄像机是OpenCV中的一个重要应用,可以实现对双目图像的获取、处理和拼接,从而提供更加全面和立体的视觉信息。
双目摄像机由两个摄像头组成,分别称为左摄像头和右摄像头。
通过将这两个摄像头安装在一定的距离上,并使其朝向同一个方向,可以模拟人类的双眼观察。
左右摄像头分别捕获到的图像称为左图像和右图像,通过对这两个图像的处理和拼接,可以得到一个更加立体和全面的视觉效果。
在进行双目拼接之前,需要先进行双目标定。
双目标定是指通过对摄像机进行标定,获取到摄像机的内外参数,从而确定两个摄像头之间的几何关系。
这个过程通常需要使用特殊标定板,通过对标定板在不同位置和角度下的图像进行分析和计算,得到摄像机的参数。
双目摄像机的标定主要涉及到两个方面的参数:内参数和外参数。
内参数是指摄像机的焦距、主点坐标等与摄像机自身有关的参数,而外参数是指两个摄像头之间的相对位置和姿态等与摄像机之间几何关系有关的参数。
通过标定,可以得到摄像机的内参数矩阵和外参数矩阵,这些参数将在后续的图像处理中起到重要作用。
在进行双目拼接时,首先需要对左右图像进行特征提取和匹配。
特征提取是指从图像中提取出具有独特性质的特征点,这些特征点通常具有较强的鲁棒性,可以在不同图像中进行匹配。
常用的特征提取算法包括SIFT、SURF和ORB等。
特征匹配是指将左右图像中的特征点进行对应,即找到在两幅图像中具有相同或相似特征的点对。
常用的特征匹配算法包括基于距离的匹配和基于几何关系的匹配等。
在完成特征提取和匹配之后,可以通过计算视差图来估计左右图像之间的视差信息。
视差是指左右图像中对应点之间的水平像素差,可以用来表示物体的距离。
视差图可以通过计算左右图像中特征点之间的像素差来得到,常用的视差计算算法包括基于块匹配的SAD (Sum of Absolute Differences)和SSD(Sum of Squared Differences)等。
双目视觉三维重构公式双目视觉三维重构是通过两个视觉传感器(相机)捕捉到的两幅图像来恢复物体的三维结构。
在这个过程中,我们需要使用一些公式和算法来计算深度、距离和位置等信息。
下面将介绍一些常用的双目视觉三维重构的公式和算法。
1.三角测量法三角测量法是双目视觉三维重构中最基本的方法之一、它使用两个相机捕捉的图像中的特征点来计算物体的三维坐标。
设相机1的坐标为(x1,y1),相机2的坐标为(x2,y2),相机的内参矩阵为K1,K2,投影矩阵为P1,P2、则可以使用下面的公式计算物体在空间中的坐标(X,Y,Z):X=(x1-c1)*Z/f1Y=(y1-c2)*Z/f2其中,f1和f2是相机的焦距,c1和c2是相机的光心坐标。
同时,Z 可以通过视差(disparity)来计算:Z = B * f1 / disparity其中,B是两个相机之间的基线距离。
2.立体匹配算法立体匹配算法用于计算两幅图像中特征点对应的视差值(disparity),从而计算物体的深度和距离。
常用的立体匹配算法有基于均值滤波(Mean Filter)的方法、基于半全局优化(Semi-Global Matching)的方法和基于深度图优化(Depth Map Refinement)的方法等。
以基于均值滤波的方法为例,可以使用下面的公式计算视差值(disparity):disparity = min,I1(x1 + d, y1) - I2(x2, y2)其中,(x1,y1)是相机1中的特征点坐标,(x2,y2)是相机2中的对应特征点坐标,d是范围内的一个偏移量,I1和I2分别是相机1和相机2中的图像亮度。
3.深度图优化算法深度图优化算法用于处理立体匹配算法中存在的误差和不完整性。
常用的深度图优化算法有图割(Graph Cut)算法、动态规划(Dynamic Programming)算法和随机采样一致性(Random Sample Consensus)算法等。
双目相机根据深度信息计算三维坐标的方
法
双目相机根据深度信息计算三维坐标的方法主要基于双目视觉原理。
双目视觉的基本原理是,通过两个相机从稍微不同的角度观察同一个物体,获得该物体在两个相机图像平面上的成像点,然后根据这两个成像点以及相机之间的相对位置关系,计算出该物体在三维空间中的坐标。
具体步骤如下:
1. 相机标定:首先需要对两个相机进行标定,获得相机的内参(包括焦距、主点坐标等)和外参(包括旋转矩阵和平移矩阵),这些参数是后续计算的基础。
2. 获取对应点:对于双目相机拍摄的两幅图像,需要找到图像中的对应点,即同一物体在两个相机图像中的成像点。
这通常通过特征匹配算法实现,如SIFT、SURF等。
3. 计算视差:视差是指同一物体在两个相机图像中的水平距离。
根据对应点的坐标,可以计算出视差。
4. 根据视差和相机参数计算三维坐标:根据视差、相机内参和外参,可以计算出物体在三维空间中的坐标。
具体公式如下:
X = (u - cx1) * Z / f * (T / d)
Y = (v - cy1) * Z / f
Z = f * T / d
其中,(X, Y, Z)是物体在三维空间中的坐标,(u, v)是物体在左相机图像中的坐标,(cx1, cy1)是左相机的主点坐标,f是相机的焦距,T是两个相机之间的水平距离(即基线距离),d是视差。
需要注意的是,上述方法假设物体在相机的光心连线上,如果物体不在该连线上,则需要进行更复杂的计算。
此外,为了提高计算精度和鲁棒性,还可以采用一些优化算法,如最小二乘法、迭代最近点算法等。
双目测距原理
双目测距原理是一种通过两个相邻安装的摄像头来实现三维测距的方法。
其基本原理是通过计算同一目标在两个摄像头中的位置差异来推算目标与摄像头的距离。
在双目测距系统中,首先需要进行视差计算。
视差是指同一目标在两个摄像头中的像素偏移量,可以通过在图像上找到对应的特征点来计算。
特征点可以是目标的边缘、角点等等。
接下来,需要进行坐标转换。
由于两个摄像头之间存在一定的基线距离,可以根据几何关系将视差转换为目标与摄像头之间的实际距离。
通过已知的摄像头参数和基线距离,可以建立起像素坐标和实际距离之间的映射关系。
最后,通过解算得到的像素坐标和实际距离之间的映射关系,可以对任意目标在摄像头中的距离进行测量。
这个过程可以通过计算机视觉算法和数学模型来完成,常见的方法有视差图法、三角测距法等等。
总之,双目测距原理基于对同一目标在两个相邻摄像头中的位置差异进行分析和计算,从而实现对目标与摄像头之间距离的测量。
这种方法在机器人导航、交通监控等领域有着广泛的应用。
双目视觉测距原理一、引言双目视觉测距是一种通过两个摄像头来获取深度信息的技术,它广泛应用于机器人、无人驾驶、AR/VR等领域。
本文将详细介绍双目视觉测距的原理。
二、基本原理双目视觉测距是基于三角测量原理实现的。
两个摄像头之间的距离已知,通过对同一个物体在两个视野中的像素坐标进行计算,可以得到该物体在空间中的位置。
三、立体匹配立体匹配是双目视觉测距中最关键的环节。
它指的是将左右两个图像中对应点进行匹配,找到它们之间的对应关系。
这个过程需要解决以下问题:1. 视差:左右眼看到同一个物体时,由于两个眼睛之间的距离不同,所以它们所看到的图像有所不同。
这种差异就是视差。
通过计算视差可以得到物体与摄像头之间的距离。
2. 匹配:如何找到左右图像中对应点?这需要考虑到光照、纹理等因素。
3. 多解性:当存在多个物体时,如何避免匹配出错?四、视差计算视差计算是双目视觉测距的核心。
它通过计算两个图像中对应点之间的像素差异来得到物体与摄像头之间的距离。
1. BM算法:BM算法是一种基于区域匹配的方法。
它将图像分成若干个小块,然后在每个小块内进行匹配。
这种方法适用于纹理丰富的场景。
2. SGM算法:SGM算法是一种快速而准确的立体匹配算法。
它将左右图像中的每个像素都看作一个节点,然后通过动态规划来求解最优路径。
3. CNN算法:近年来,深度学习技术在双目视觉测距中得到了广泛应用。
通过训练神经网络,可以实现更加准确和稳定的立体匹配。
五、误差分析双目视觉测距存在着多种误差,包括:1. 视差误差:由于光照、纹理等因素的影响,视差计算存在误差。
2. 系统误差:由于摄像头本身存在畸变等问题,会导致系统误差。
3. 运动误差:当物体或摄像头发生运动时,会导致视差计算出现误差。
六、应用场景双目视觉测距广泛应用于机器人、无人驾驶、AR/VR等领域。
具体应用场景包括:1. 机器人导航:通过双目视觉测距可以实现机器人的自主导航。
2. 无人驾驶:双目视觉测距可以用于无人车辆的障碍物检测和避障。