(完整word版)单因素重复测量设计
- 格式:doc
- 大小:92.51 KB
- 文档页数:3




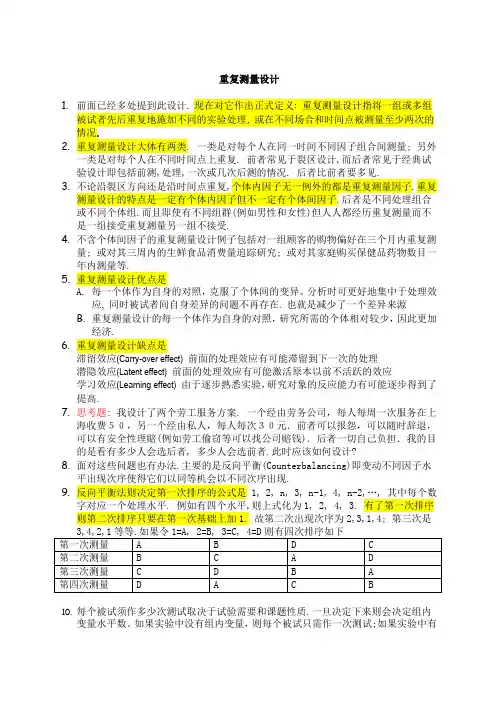
重复测量设计1.前面已经多处提到此设计. 现在对它作出正式定义: 重复测量设计指将一组或多组被试者先后重复地施加不同的实验处理, 或在不同场合和时间点被测量至少两次的情况.2.重复测量设计大体有两类. 一类是对每个人在同一时间不同因子组合间测量; 另外一类是对每个人在不同时间点上重复. 前者常见于裂区设计,而后者常见于经典试验设计即包括前测,处理,一次或几次后测的情况. 后者比前者要多见.3.不论沿裂区方向还是沿时间点重复,个体内因子无一例外的都是重复测量因子.重复测量设计的特点是一定有个体内因子但不一定有个体间因子.后者是不同处理组合或不同个体组.而且即使有不同组群(例如男性和女性)但人人都经历重复测量而不是一组接受重复测量另一组不接受.4.不含个体间因子的重复测量设计例子包括对一组顾客的购物偏好在三个月内重复测量; 或对其三周内的生鲜食品消费量追踪研究; 或对其家庭购买保健品药物数目一年内测量等.5.重复测量设计优点是A.每一个体作为自身的对照,克服了个体间的变异。
分析时可更好地集中于处理效应, 同时被试者间自身差异的问题不再存在. 也就是减少了一个差异来源B.重复测量设计的每一个体作为自身的对照,研究所需的个体相对较少,因此更加经济.6.重复测量设计缺点是滞留效应(Carry-over effect) 前面的处理效应有可能滞留到下一次的处理潜隐效应(Latent effect) 前面的处理效应有可能激活原本以前不活跃的效应学习效应(Learning effect) 由于逐步熟悉实验,研究对象的反应能力有可能逐步得到了提高.7.思考题: 我设计了两个劳工服务方案. 一个经由劳务公司,每人每周一次服务在上海收费50,另一个经由私人,每人每次30元.前者可以报怨,可以随时辞退,可以有安全性理赔(例如劳工偷窃等可以找公司赔钱).后者一切自己负担.我的目的是看有多少人会选后者, 多少人会选前者.此时应该如何设计?8.面对这些问题也有办法.主要的是反向平衡(Counterbalancing)即变动不同因子水平出现次序使得它们以同等机会以不同次序出现.9.反向平衡法则决定第一次排序的公式是 1, 2, n, 3, n-1, 4, n-2,…, 其中每个数字对应一个处理水平. 例如有四个水平,则上式化为1, 2, 4, 3. 有了第一次排序则第二次排序只要在第一次基础上加1. 故第二次出现次序为2,3,1,4; 第三次是10.每个被试须作多少次测试取决于试验需要和课题性质.一旦决定下来则会决定组内变量水平数。





单因素重复测量结果报告一、单因素重复测量结果报告嘿,宝子们!今天咱们来唠唠单因素重复测量结果报告这事儿哈。
单因素重复测量呢,就像是你反复去看同一个东西,但是每次看可能都有不同的结果。
比如说你每天早上看自己的体重(当然这有点扎心啦,哈哈),这就是一种单因素(体重这个因素)的重复测量。
那这个结果报告呢,首先要讲清楚我们到底测量的是什么单因素。
就像刚刚说的体重,那在正经的研究里,可能是某个药物对病人某个症状的影响,这个症状就是我们的单因素啦。
我们得把这个因素描述得特别清楚,让看报告的人一下子就明白。
然后呢,测量的对象是谁呀?是一群大学生,还是特定的病人群体呢?这也得好好说。
如果是大学生,是哪个专业的,男生还是女生多,年龄大概是多少范围。
这些信息就像是给这个报告打基础的砖头,缺了可不行。
接下来就是具体的测量过程啦。
用了啥仪器,或者啥方法去测量的呢?要是用仪器,仪器的精度咋样,是不是很先进的那种,还是比较常规的。
方法呢,是问卷调查,还是实际的测试,比如说测量人的反应速度,是用那种按按钮的反应测试仪器,还是靠人工观察记录。
再说说测量的时间间隔。
是每天测一次,还是每周,甚至每个月呢?这个时间间隔可重要了。
比如说你研究植物的生长,每天测量和每周测量可能得到的结果趋势就不太一样呢。
结果部分那可就是重头戏啦。
我们得把每次测量得到的数据都列出来,可不能偷懒哦。
要是数据太多,做个表格多好呀,清晰又明了。
而且不能光列数据,还要分析这些数据的变化趋势。
是逐渐上升,还是下降,或者是波动很大呢?如果波动大,那为啥呢?是因为测量过程中有啥干扰因素,还是这个单因素本身就很不稳定呢?还有误差分析也不能少。
毕竟测量不可能是完美无缺的,总会有一些误差。
误差是怎么产生的呢?是测量仪器本身的问题,还是人为操作不当呢?比如说测量长度的时候,尺子刻度有点模糊,那这就可能造成误差啦。
最后呢,根据这个结果我们能得出啥结论呀?这个结论得跟我们最开始的研究目的挂钩。

单因素重复测量实验设计例子《单因素重复测量实验设计,就像一场有趣的冒险!》嘿,朋友们!今天我要和你们聊聊单因素重复测量实验设计这个听起来有点专业,但实际超级有意思的东西哦!你想啊,这单因素重复测量实验设计就像是我们在生活中玩的一个闯关游戏。
我们有个关键的因素,就好比那游戏里的大魔王,然后我们一遍又一遍地去挑战它,看它在不同情况下会有啥反应。
比如说,我曾经参与过一个关于口味偏好的实验。
这不就是单因素重复测量嘛!我们就研究一种新零食的味道,让参与者一次又一次地品尝,然后问他们的感觉。
嘿,这就像一场味觉的冒险!想象一下,参与者们就像勇敢的探险家,每次品尝都是一次新的挑战。
有时候他们会皱着眉头,仿佛在说:“哎呀,这次味道咋不一样啦!”有时候又会眼睛放光,好像在说:“哇塞,这次超好吃!”而我们这些搞实验的人呢,就像是背后的大导演,观察着他们的一举一动,记录下每一个有趣的反应。
而且啊,这种实验设计还有个好处,就是能让我们更深入地了解那个因素的影响。
就像挖宝藏一样,越挖越深,发现的宝贝也就越多。
可能一开始我们只看到了表面的一点点,但经过反复测量,哇哦,各种细节都浮现出来啦!当然啦,这过程中也会有一些小插曲。
比如有时候参与者会偷偷瞄我们的表情,想从我们这儿找答案,哈哈,那场面可太逗了!还有的时候,他们可能会因为吃太多次同一个东西而有点腻了,但还是得坚持完成实验,那表情真的是又好笑又让人心疼。
不过总的来说,单因素重复测量实验设计真的是一次充满乐趣和探索的旅程。
它让我们能在一个特定的领域里深入挖掘,不断发现新的东西。
就像打开了一扇神秘的门,里面有着无尽的惊喜等待着我们去探索。
所以啊,如果你还没尝试过这种实验设计,不妨去试试。
说不定你也会像我一样,爱上这场有趣的冒险,在探索的道路上发现许多意想不到的精彩呢!怎么样,准备好开启你的单因素重复测量实验之旅了吗?哈哈,让我们一起出发吧!。
单因素重复测量广义估计方程全文共四篇示例,供读者参考第一篇示例:单因素重复测量广义估计方程是一种统计方法,用于分析实验数据中单个因素下多个重复测量值的变化情况。
在实验设计中,为了消除其他因素对实验结果的影响,常常会进行重复测量,以便获取更为准确的数据。
在单因素实验中,研究者通常会对同一组对象或样本进行多次测量,比如一组实验对象在不同时间点的观测值或者在不同条件下的反应值。
这些重复测量值可能会受到多种因素的影响,比如测量误差、实验条件变化等。
为了从这些数据中提取有用的信息,需要利用统计的方法来建立估计方程。
单因素重复测量广义估计方程的建立需要考虑多个因素,其中最重要的是测量误差和实验因素的影响。
在实际数据分析中,可以利用方差分析的方法来确定实验因素对观测值的影响程度,以及测量误差的大小。
基于这些分析结果,可以建立广义估计方程,用于预测实验因素对观测值的影响。
在实际应用中,单因素重复测量广义估计方程可以用于多个领域,比如医学、生物学、工程等。
比如在药物疗效评价中,可以利用该方法来分析不同时间点下药物对疾病的影响;在工程领域可以通过实验数据的多次测量来评估不同因素对产品质量的影响。
单因素重复测量广义估计方程是一种高效的统计方法,可以帮助研究者从实验数据中获取更为准确和全面的信息。
单因素重复测量广义估计方程是一种重要的统计方法,可以帮助研究者从实验数据中提取有用的信息。
在建立该方程时,需要考虑多个因素的影响,包括实验因素和测量误差。
通过该方法的应用,可以更好地理解实验数据中的变化规律,为进一步研究提供重要参考。
希望更多的研究者能够了解并应用单因素重复测量广义估计方程,以推动相关领域的发展和进步。
【2000字】第二篇示例:单因素重复测量广义估计方程是统计学中一个重要的概念,它被广泛应用于各个领域的数据分析中。
单因素重复测量设计是实验设计中一种常见的设计方式,通过对同一组实验单位进行多次测量来分析因变量与自变量之间的关系。
单因素重复测量实验设计一、单因素重复测量实验设计的基本特点在单因素完全随机实验中,组内变异实际上是由两部分组成的:实验中测量误差引起的变异和未控制的无关变量带来变异,其中订是被试个体差异带来的变异。
减少误差变异的一个方法是控制个体差异引起的无关变量,达到这个目标的途径之一是使用随机区组设计,而控制个体差异的一个更有效的方法是重复测量实验设计,也叫被试内设计。
在一个非重复测量实验设计,或被试间设计中,例如我们在前面介绍的完全随机设计、随机区组设计和拉丁方设计中,一个共同的特点是实验中每个被试仅接受一个处理水平,被试的个体差异带来的变异混杂在误差变异中。
重复测量实验设计的基本方法是:实验中每个被试接受所有的处理水平。
这种实验设计的目的是利用被试自己做控制,使被试各方面特点在所有的处理中保持恒定,以最大限度地控制由被试的个体差异带来的变异。
使用重复测量设计的前提是研究者必须事先假设,当若干处理水平连续实施给同一被试时,被试接受前面的处理对接受后面的处理没有长期影响。
重复测量设计在有些情况下是不合适的,当处理的实施对被试有长期影响时,如学习、记忆效应,不能使用重复测设计。
例如,在一个教学研究中,要比较两种教学方法对学生学习成绩的影响。
我们不可能使用同一班学生先后接受两种教学方法,然后比较它们对学生学习成绩的影响,因为前一种教法的教学不可避免地对学生接受后一种教法的教学产生影响。
在心理与教育研究中,许多实验处理会对被试产生学习、记忆效应,因此使用重复测量设计要特别谨慎。
另外,顺序效应也是重复设计中应特别注意的问题。
被度连续接受处理时,练习、疲劳等效应是难免的,因此重复测量设计中需要考虑平衡顺序效应的问题。
与完全随机和随机区组设计非常不同的是,重复测量实验设计使用少量的被试,它们的图解比较如下:(a(b(c图2-4-1 单因素完全随机、随机区组、复重测量实验设计中分配被试的比较从三个图的比较中可以看出,在同样的有一个自变量、自变量有4个水平的实验中,完全随机设计使用16个随机选择的被试,随机区组设计使用4组、每组4个同质被试,因此也是16个被试,而重复测量设计仅用4个被试,每个被试接受所有的实验处理。
单因素重复测量实验设计
一、单因素重复测量实验设计的基本特点
在单因素完全随机实验中,组内变异实际上是由两部分组成的:实验中测量误差引起的变异和未控制的无关变量带来变异,其中订是被试个体差异带来的变异。
减少误差变异的一个方法是控制个体差异引起的无关变量,达到这个目标的途径之一是使用随机区组设计,而控制个体差异的一个更有效的方法是重复测量实验设计,也叫被试内设计。
在一个非重复测量实验设计,或被试间设计中,例如我们在前面介绍的完全随机设计、随机区组设计和拉丁方设计中,一个共同的特点是实验中每个被试仅接受一个处理水平,被试的个体差异带来的变异混杂在误差变异中。
重复测量实验设计的基本方法是:实验中每个被试接受所有的处理水平。
这种实验设计的目的是利用被试自己做控制,使被试各方面特点在所有的处理中保持恒定,以最大限度地控制由被试的个体差异带来的变异。
使用重复测量设计的前提是研究者必须事先假设,当若干处理水平连续实施给同一被试时,被试接受前面的处理对接受后面的处理没有长期影响。
重复测量设计在有些情况下是不合适的,当处理的实施对被试有长期影响时,如学习、记忆效应,不能使用重复测设计。
例如,在一个教学研究中,要比较两种教学方法对学生学习成绩的影响。
我们不可能使用同一班学生先后接受两种教学方法,然后比较它们对学生学习成绩的影响,因为前一种教法的教学不可避免地对学生接受后一种教法的教学产生影响。
在心理与教育研究中,许多实验处理会对被试产生学习、记忆效应,因此使用重复测量设计要特别谨慎。
另外,顺序效应也是重复设计中应特别注意的问题。
被度连续接受处理时,练习、疲劳等效应是难免的,因此重复测量设计中需要考虑平衡顺序效应的问题。
与完全随机和随机区组设计非常不同的是,重复测量实验设计使用少量的被试,它们的图解比较如下:
(a
(b
(c
图2-4-1 单因素完全随机、随机区组、复重
测量实验设计中分配被试的比较
从三个图的比较中可以看出,在同样的有一个自变量、自变量有4个水平的实验中,完全随机设计使用16个随机选择的被试,随机区组设计使用4组、每组4个同质被试,因此也是16个被试,而重复测量设计仅用4个被试,每个被试接受所有的实验处理。
二、单因素重复测量实验设计与计算举例
(一)研究的问题与实验设计
我们继续以4种文章的生字密度对学生阅读理解的影响的研究为例。
为了更好地控制被试变量,研究者仅用8名被试,每个被试阅读4篇生字密度不同的文章,并测他们各篇文章的阅读理解分数。
选择使用重复测量实验设计是由于研究者假设,当实验安排合适时,被试阅读一篇文章举对阅读另一篇文章产生影响。
但是,在这种实验设计中,疲劳效应和顺序效应是必须考虑的。
为了减少疲劳效应,研究者决定将4篇文章在下午分4次施测。
平衡顺序效应的方式有两种:以随机顺序实施4种生字密度的文章,或以拉丁方实施4 区组区组区组区组被试1 被试2 被试3 被试4
(二)实验数据及其计算
单因素重复测量实验数据的列表,计算与单因素随机区组实验的完全相同,只是在平方和的分解释上有所不同。
单因素重复测量实验中,总平方和首先被分为被试间平方和与被试内平方和,然后再分解被试内平方和为处理效应和误差变异。
1.计算表
表2-4-1 单因素重复测量实验的计算表
2.11
36202.000p
n ij
i j Y
===++⋅⋅⋅⋅⋅⋅=∑∑
2
2
11
()(202)[]1275.125(8)(4)
p
n ij j j Y Y np
=====∑∑
()
21
2211
(
)
22
1
2
[](3)(6)1544.000(35)(31)[]1465.250
8(8)n
ij i p
n i j Y p
j Y
AS ij
A n
======++⋅⋅⋅⋅⋅=∑==++=∑∑∑
L L
()
21(
)
22
1(24)(29)[]1301.0004(4)n
ij j
Y p
j
s P
==∑==++=∑
L L
3.平方和的分解与计算
(1)平方和分解模式:
()(2)[][]268.875[][]25.875243.000[][]190.125
52.875
SS SS SS SS SSA SS AS Y S Y SS SS SSA A Y SS SS SS SSA =+=++=-==-==-==-==--=总变异被试间被试内被试间残差总变异被试间被试内总变异被试间残差总变异被试间平方和计算:
SS SS SS
4.方差分析表及结果的解释
方差分析表中可以看出,实验中的自变量——生字密度的效应是统计显著的(F(3,21)=25.17,P<.01=,自变量的F检验的误差项是Mse=2.518。
方差分析表中还有一项“被试间变异”(SS被试间=25.875),这部分变异带有所有被试之间个体差异引起的变异。
由于从总变异中分离出了被试间变异,因此与完全随机实验相比,重复测量实验中提高了实验处理的F检验的敏感性。
5.
图2-4-3 单因素重复测量实验设计的平方和与自由度的分解
6.对平方和分解与计算的一些解释
SS总变异——在重复测量实验中,总变异应首先分解为被试间的平方和和被试内平方和。
SS被试间——被试间平方和,即总变异中所有由被试的个体差异引起的变异。
SS被试内——被试内平方和包括同一被试在接受不同实验处理时产生的变异(被试内因素的处理效应),以及偶然因素引起的实验误差。
在单因素重复测量实验设计中,被试内平方和被分解为两部分:A因素的处理效应和误差变异。
SS残差——重复测量实验中的残差变异与随机区组实验中的残差性质相同,重复测量实验方差分析中残差的计算是先从总变异中减去被试间平方和,然后再减去处理效应。
由于事先从总变异中分离出了所有的由被试个体差异带来的变异,重复测量实验中的SS残差一般很小。