语音编码基础知识
- 格式:ppt
- 大小:1.38 MB
- 文档页数:120

语音编码的基本方法
语音编码是将语音信号转换成数字形式以便于存储、传输和处理的过程。
以下是一些常见的语音编码方法:
1. 脉冲编码调制(PCM):
• PCM是一种最基本的语音编码方法,它将模拟语音信号在时间上均匀采样,并将每个样本的振幅量化为数字形式。
•采样率和量化位数是PCM中的两个重要参数,它们决定了数字表示的精度和数据量大小。
2. 自适应差分脉冲编码调制(ADPCM):
• ADPCM是一种通过对语音信号进行预测和差分编码来减小数据量的方法。
它利用前一个采样的信息来预测当前采样,并只编码预测误差。
•由于只需要编码误差,ADPCM相比于PCM可以实现更高的压缩比。
3. 线性预测编码(LPC):
• LPC是一种基于声道建模的编码方法,它假设语音信号是由声道和激励信号的组合产生的。
• LPC通过对语音信号进行分析,提取声道特征,并将其参数化以减小数据量。
4. 矢量量化:
•矢量量化是一种高效的无损压缩方法,通过将一组相邻的样本映射到一个矢量码本中的一个向量,从而减小数据量。
5. 变换编码:
•将语音信号通过某种变换(如傅立叶变换)转换到频域,然后对频域信息进行编码。
其中,MP3是一种常见的基于变换编码的方法。
6. 深度学习方法:
•近年来,深度学习技术在语音编码领域取得了显著进展。
循环神经网络(RNN)和卷积神经网络(CNN)等模型被用于语音特征提取和编码。
这些方法有各自的优点和适用场景,选择合适的编码方法通常取决于应用需求、带宽要求以及对音频质量的要求。

欧美及我国常用的语音编码技术1. 介绍在当今数字化时代,语音编码技术在通信、音频处理、语音识别等领域起着至关重要的作用。
欧美及我国都有各自常用的语音编码技术,本文将就这一主题进行深入探讨。
2. PCM编码PCM(Pulse Code Modulation)是一种最早期的语音编码技术,它将模拟信号转换为数字信号。
PCM编码的优点是精确度高,保真度好,但缺点是需要较大的数据传输速率。
在欧美,PCM编码仍然广泛应用于一些专业音频设备和通信系统中。
3. ADPCM编码ADPCM(Adaptive Differential Pulse Code Modulation)是一种自适应差分脉冲编码调制技术,它在PCM编码的基础上进一步压缩了数据量。
相较于PCM编码,ADPCM编码具有更高的压缩比,适用于一些需要节省带宽的场景。
在欧美,ADPCM编码被广泛应用于语音通信、无线通信等领域。
4. G.711编码G.711是国际电信联盟(ITU-T)制定的一种音频编码标准,它包括了μ-law和A-law两种编码方式。
G.711编码通过对声音进行采样和量化,实现了对语音的高效压缩和传输。
在我国,G.711编码是常用的语音编码技术之一,被广泛应用于各类通信系统和音频处理设备中。
5. G.729编码G.729是一种高压缩比的语音编码标准,它采用了先进的语音处理算法,实现了对语音信号的高效压缩和传输。
在欧美,G.729编码被广泛应用于语音通信和网络通信方式等领域。
6. Opus编码Opus是一种开放式、免专利的音频编码格式,它具有低延迟、高音质和高压缩比的特点。
Opus编码在欧美得到了广泛的应用,尤其是在互联网音频传输、实时语音通信等领域。
7. 总结欧美及我国常用的语音编码技术包括了PCM编码、ADPCM编码、G.711编码、G.729编码和Opus编码等多种标准和格式。
这些编码技术各具特点,适用于不同的场景和需求。
随着科技的不断进步和创新,相信未来还会有更多更先进的语音编码技术出现,为语音通信和音频处理领域带来更多的可能性。

5g通信的语音编码标准在5G通信系统中,语音编码技术是实现高效、可靠和低延迟语音传输的关键。
以下是关于5G通信的语音编码标准的主要内容:1. 音频编解码器标准在5G通信中,音频编解码器(Audio Coder)标准是实现语音信号的压缩和编码的核心技术。
目前,3GPP组织正在制定新一代的音频编解码器标准,称为3 (Low Complexity Communication Efficient Coding)。
该标准旨在提供低复杂度、高通信效率的音频编码方案,以适应5G通信的高速率、大带宽和低延迟的需求。
2. 语音传输协议标准5G通信系统需要提供低延迟、高可靠性的语音传输协议。
为了实现这一目标,一些新兴的语音传输协议正在被开发和应用。
其中最具代表性的两种技术是VoNR (Voice over New Radio)和VoLTE (Voice over LTE)。
这两种技术都旨在提供高效的语音传输方案,同时保证低延迟和高可靠性。
VoNR是一种基于5G NR(新无线电)技术的语音传输协议。
它利用5G的高速率和低延迟特性,实现在移动通信网络中传输语音和视频信号。
VoNR可以提供比传统VoLTE技术更高的频谱效率和更低的传输延迟,从而提供更好的语音通话体验。
VoLTE是一种基于LTE技术的语音传输协议。
它利用LTE的高速率和低延迟特性,实现在移动通信网络中传输语音信号。
VoLTE可以提供与VoNR相似的语音质量和低延迟性能,但需要在LTE网络中进行优化和部署。
3. 语音质量评估和测量标准为了确保5G通信中的语音质量,需要制定相应的语音质量评估和测量标准。
这些标准应该能够评估各种语音编码器和传输协议的性能,以确保它们能够提供高质量的语音传输。
例如,主观音质评估(Subjective音质Evaluation)和客观音质评估(Objective音质Evaluation)是两种常用的语音质量评估方法。
主观音质评估是通过人的听觉感受来评估音质的好坏,客观音质评估则是通过测量信号的客观指标如失真度、噪声水平等来评估音质。

了解电脑声音音频编解码和音效处理的基础知识在计算机中,声音是电信号的形式被处理和传输的。
对于从电子设备中发出的声音,电脑声音音频编解码和音效处理技术至关重要。
本文将介绍电脑声音音频编解码和音效处理的基础知识,包括它们的概念、作用以及常见的应用。
一、声音音频编解码的概念和作用1.1 概念声音编码是将声音信号转换为数字化的过程,而声音解码则是将数字化的声音信号还原为模拟声音信号。
在计算机中,声音信号是以数字的形式存在的,因此需要进行编码和解码的转换才能进行处理和传输。
1.2 作用声音音频编解码的作用是保证声音信号在计算机中的正确传输和处理。
编码过程将模拟声音信号转化为数字信号,方便计算机系统对其进行处理。
解码过程则将数字信号转化为模拟声音信号,使用户能够听到声音的输出。
二、常见的声音音频编解码技术2.1 PCM编解码PCM(Pulse Code Modulation)是一种经典的声音编解码技术,它将模拟声音信号通过采样和量化的方式转换为数字信号。
采样是指对模拟声音信号进行周期性的取样,而量化是指对取样后的信号进行数值化的处理。
PCM编解码的优点是处理简单,音质较好,被广泛应用于电话、录音和音乐制作等领域。
2.2 AAC编解码AAC(Advanced Audio Coding)是一种高级音频编解码技术,它能够提供更高的压缩比和更好的音质。
AAC编解码通过采用更高效的算法和更复杂的编码结构来实现对声音信号的压缩和还原。
AAC编解码在数字音频广播、数字电视和音乐播放器等领域得到了广泛应用。
2.3 MP3编解码MP3(MPEG-1 Audio Layer III)是一种流行的音频编解码技术,它能够在保证一定音质的前提下实现更高的压缩比。
MP3编解码通过去除声音信号中的冗余信息和不可听的频率成分来进行压缩。
尽管MP3编解码存在一定的音质损失,但其广泛应用于音乐压缩和在线音乐播放等领域。
三、音效处理的概念和常见技术3.1 概念音效处理是指对声音信号进行加工和改变,以达到特定的效果和目的。

语音编码技术是指将语音信号转换成数字信号的过程,以便于数字通信和存储。
欧美及我国常用的语音编码技术有很多种,每种技术都有其特点和适用场景。
在本文中,我将对欧美及我国常用的语音编码技术进行简要描述,并分析它们的优缺点和应用范围。
1. PCM(Pulse Code Modulation,脉冲编码调制)PCM是一种最基本的编码技术,它将模拟语音信号按照一定的采样频率和量化位数转换成数字信号。
PCM具有简单、成本低廉的优点,适用于通信和存储。
然而,PCM需要较高的带宽和存储空间,而且在传输过程中容易受到噪声和失真的影响。
2. ADPCM(Adaptive Differential Pulse Code Modulation,自适应差分脉冲编码调制)ADPCM是一种改进型的PCM技术,它通过差分编码和自适应量化实现了更高的压缩比和更好的抗噪能力。
ADPCM适用于语音通信和数字语音存储领域,可以有效地降低带宽和存储需求,提高语音质量。
3. CELP(Code Excited Linear Prediction,编码激励线性预测)CELP是一种基于语音产生模型的编码技术,它通过对语音信号的激励和线性预测参数进行编码,实现了更高的压缩比和更好的语音质量。
CELP适用于数字语音通信和存储,已经成为了现代语音编码的主流技术之一。
4. G.729G.729是一种窄带语音编码标准,它采用了多种高效的压缩算法和声学模型,实现了良好的语音质量和低码率。
G.729被广泛应用于IP通信方式和语音会议系统,能够在有限的带宽下实现优秀的语音通信效果。
5. AMR(Adaptive Multi-Rate,自适应多速率)AMR是一种自适应多速率语音编码技术,它可以根据网络条件和通信需求动态调整编码速率,实现了灵活的语音通信和存储。
AMR适用于移动通信和语音在线服务领域,能够提供高质量的语音体验。
以上是欧美及我国常用的几种语音编码技术,每种技术都有自己的特点和应用场景。

语音编码的基本方法语音编码是将语音信号转换为数字信号的过程,以便能够利用数字信号处理技术进行存储、传输、分析和合成。
语音编码的目标是尽可能减小存储和传输所需的比特率,同时尽量保持原始语音信号的质量。
下面将介绍语音编码的基本方法。
1.线性预测编码(LPC)线性预测编码(Linear Predictive Coding,LPC)是一种基于声道模型的语音编码方法。
该方法假设语音信号可以由线性滤波器和一个激励源合成。
LPC编码先通过线性预测分析,估计出语音信号的线性滤波器参数,然后将这些参数进行编码传输。
2.矢量量化矢量量化是一种有损数据压缩技术,也是常用的语音编码方法。
它将一组相关的样本(向量)映射到一组有限的离散码字中。
在语音编码中,矢量量化可以应用于线性预测编码的残差信号,以及其他一些语音特征参数的编码。
3.短时傅里叶变换编码(STFT)短时傅里叶变换编码(Short-Time Fourier Transform,STFT)是一种频域分析方法,常用于语音信号的编码。
STFT将语音信号分段进行傅里叶变换,将时域信号转换为频域信号,然后对频域信号进行编码传输。
4.频率对齐线性预测编码(FSLP)频率对齐线性预测编码(Frequency-Selective Linear Prediction,FSLP)是一种新型的语音编码方法。
它通过对语音信号进行预处理,将频率对齐后的语音信号分帧,然后利用线性预测分析得到每一帧的滤波器系数,并对这些系数进行编码传输。
5.自适应编码自适应编码是一种根据传输条件自动调整编码参数的方法。
最常见的自适应编码方法是可変速率编码(Variable Bit Rate,VBR)和可变码率编码(Adaptive Bit Rate,ABR)。
这些编码方法根据语音信号的特性和传输条件,动态调整编码参数,以尽可能减小比特率,并保持较高的语音质量。
除了上述几种基本方法,还有很多其他的语音编码技术,如无失真编码、人工神经网络编码等。

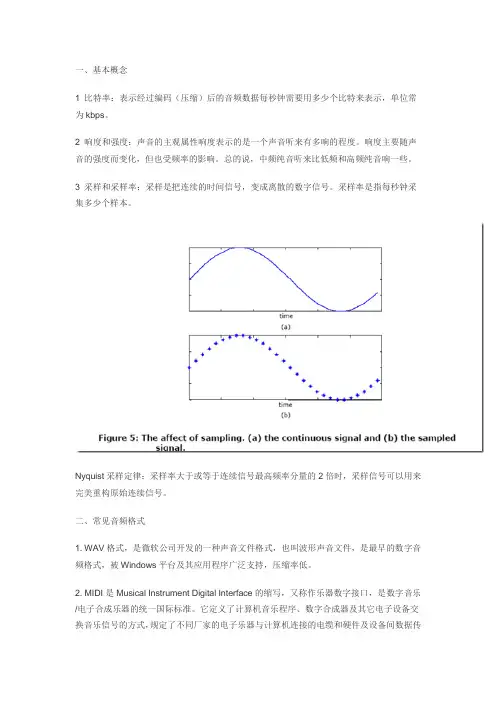
一、基本概念1 比特率:表示经过编码(压缩)后的音频数据每秒钟需要用多少个比特来表示,单位常为kbps。
2 响度和强度:声音的主观属性响度表示的是一个声音听来有多响的程度。
响度主要随声音的强度而变化,但也受频率的影响。
总的说,中频纯音听来比低频和高频纯音响一些。
3 采样和采样率:采样是把连续的时间信号,变成离散的数字信号。
采样率是指每秒钟采集多少个样本。
Nyquist采样定律:采样率大于或等于连续信号最高频率分量的2倍时,采样信号可以用来完美重构原始连续信号。
二、常见音频格式1. WAV格式,是微软公司开发的一种声音文件格式,也叫波形声音文件,是最早的数字音频格式,被Windows平台及其应用程序广泛支持,压缩率低。
2. MIDI是Musical Instrument Digital Interface的缩写,又称作乐器数字接口,是数字音乐/电子合成乐器的统一国际标准。
它定义了计算机音乐程序、数字合成器及其它电子设备交换音乐信号的方式,规定了不同厂家的电子乐器与计算机连接的电缆和硬件及设备间数据传输的协议,可以模拟多种乐器的声音。
MIDI文件就是MIDI格式的文件,在MIDI文件中存储的是一些指令。
把这些指令发送给声卡,由声卡按照指令将声音合成出来。
3. MP3全称是MPEG-1 Audio Layer 3,它在1992年合并至MPEG规范中。
MP3能够以高音质、低采样率对数字音频文件进行压缩。
应用最普遍。
4. MP3Pro是由瑞典Coding科技公司开发的,其中包含了两大技术:一是来自于Coding 科技公司所特有的解码技术,二是由MP3的专利持有者法国汤姆森多媒体公司和德国Fraunhofer集成电路协会共同研究的一项译码技术。
MP3Pro可以在基本不改变文件大小的情况下改善原先的MP3音乐音质。
它能够在用较低的比特率压缩音频文件的情况下,最大程度地保持压缩前的音质。
5. MP3Pro是由瑞典Coding科技公司开发的,其中包含了两大技术:一是来自于Coding 科技公司所特有的解码技术,二是由MP3的专利持有者法国汤姆森多媒体公司和德国Fraunhofer集成电路协会共同研究的一项译码技术。

语音信号处理的基础知识语音信号处理是一门涉及到声音录制、分析、编码、识别等多个学科的交叉领域,其在现代通信技术、人机交互等领域中发挥着重要作用。
本文将介绍语音信号处理的基础知识,包括语音的参数表示、语音的数字化、语音的编码和解码等方面。
一、语音的参数表示语音信号的参数表示是指将语音信号表示为具有物理意义的、易于处理的数学参数。
在语音信号的参数表示中,常用的方法包括时域参数和频域参数两种。
时域参数是指将语音信号分段,然后对每一段信号进行时域特征分析,将其表示为均值、方差、能量、过零率等参数。
时域参数的优点是对信号的采样率没有要求,因此对于不同采样率的语音信号都可以进行处理。
但是,时域参数的缺点是对于语音信号中的高频成分无法处理,因此无法反映语音信号的高频特性。
频域参数是指将语音信号进行傅里叶变换,将信号变换到频域后,对于每个频率分量进行幅度、相位等特征参数提取。
频域参数的优点在于可以反映语音信号的高频特性,因此在语音识别、声码器设计等方面有重要应用。
但是频域参数的缺点在于对于信号的采样率有一定要求,因此需要进行抽样和重构处理,这样会引入一定的误差。
二、语音的数字化语音的数字化是指将模拟语音信号转换为数字信号的过程,其目的在于便于存储和处理。
在数字化语音信号中,一般采用脉冲编码调制(PCM)技术进行采样和量化。
脉冲编码调制是一种通过改变脉冲宽度、位置和幅度等参数来表示信号的方法。
在语音数字化中,采用的是线性脉冲编码调制,即将模拟语音信号进行采样、量化后转换为数字信号。
采样是指将模拟信号在时间轴上离散化,量化是指将采样信号的振幅幅度量化为离散的数值。
采样和量化的具体实现可以采用多种算法,如最近邻量化、线性量化、对数量化和均衡限制量化等。
三、语音的编码和解码语音信号编码是指将语音信号转换为适合传输和存储的码流。
在语音信号编码中,常用的方法包括线性预测编码(LPC)、自适应差分编码(ADPCM)、快速傅里叶变换编码(FFT)、线性预测离散余弦变换编码(LPDCT)等。

了解电脑音频编码的基本知识在数字化时代,音频编码成为了我们日常生活中不可或缺的一部分。
无论是通过网络传输音乐、观看在线视频,还是使用移动设备收听音频,我们都离不开对音频编码的了解和应用。
本文将介绍电脑音频编码的基本知识,帮助读者更好地理解和应用音频编码技术。
一、什么是音频编码音频编码是将模拟声音信号转换为数字信号的过程。
在电脑音频编码中,声音信号被数字化并通过特定的编码算法转换为数字信号,以便于存储、传输和处理。
常见的音频编码格式包括MP3、AAC、FLAC等。
二、音频编码的原理音频编码的原理是将模拟的连续声音信号转换为数字化的离散信号。
这一过程包括两个主要步骤:采样和量化。
1. 采样采样是指对连续声音信号进行定时取样,将采样点的值转换为数字表示。
采样频率表示每秒钟采集的采样点数,常见的采样频率有44.1kHz、48kHz等。
较高的采样频率可以更精确地还原声音信号,但也会增加数据量。
2. 量化量化是将采样后得到的连续信号幅度变换为一系列离散的数值。
通过将连续信号的幅度分成若干个离散级别,并对每个采样点进行幅度的近似表示,从而将模拟信号转换为数字信号。
量化的位数决定了信号的精确度,常见的量化位数有8位、16位、24位等。
三、常见的音频编码格式1. MP3MP3是一种常见的音频编码格式,它可以在保持较高音质的同时,对音频数据进行较高的压缩比。
MP3格式通过利用人耳听觉的特性,去除冗余数据和听觉掩蔽效应,以降低数据量。
然而,由于MP3是有损压缩格式,会导致原始音频的一些细节损失。
2. AACAAC(Advanced Audio Coding)是一种相对较新的音频编码格式,被广泛应用于音乐、视频等领域。
与MP3相比,AAC可以提供更好的音频质量,同时具有更高的压缩效率。
由于AAC采用了更先进的编码算法,因此在相同比特率下,AAC的音质要优于MP3。
3. FLACFLAC(Free Lossless Audio Codec)是一种无损音频编码格式,它可以在不损失任何音质的前提下进行高效率的压缩。

声音编码的基本原理声音编码是指将声音信号转换为数字信号的过程。
在数字通信和数字储存应用中,声音编码起到了非常重要的作用,因为它可以将大量的声音数据压缩成较小的文件大小,并保持一定程度的音频质量。
声音编码的基本原理如下:1. 采样:声音编码的第一步是采样,即将连续的模拟声音信号转换成离散的数字信号。
采样过程中,根据奈奎斯特定理,采样频率必须高于声音信号的最高频率的两倍,这样才能完整地还原声音信号。
2. 量化:采样后得到的离散信号是连续的,需要将其转化为离散的数值。
量化过程中,将采样得到的每个时间点上的信号值映射到一系列离散的数值中。
通常使用的是均匀量化,即将连续的信号范围均匀分成若干个小区间,每个区间对应一个离散的数值。
3. 编码:量化后的离散信号是连续的,需要将其进一步编码为二进制数据。
编码的目的是用尽可能少的比特数来表示量化的离散信号。
常用的编码方法有脉冲编码调制(PCM)和差分编码(DPCM)等。
PCM将每个量化值转化为一个固定长度的二进制码,而DPCM则是根据连续样本之间的差异进行编码,从而减少数据存储量。
4. 压缩:编码后得到的数据仍然可能会较大,因此需要进一步进行压缩以减小文件大小。
压缩可以通过去除冗余信息、减少量化级数和使用压缩算法等方式来实现。
常见的音频压缩算法有MP3, AAC和OGG等。
5. 解码:接收端收到压缩的二进制数据后,需要解码还原为原始的数字信号。
解码过程是编码过程的逆过程,包括解压缩、解码和去量化等步骤。
解码后得到的数字信号经过数模转换即可还原为模拟声音信号。
声音编码的基本原理可以通过数学和信息理论来解释。
在声音编码过程中,由于人耳听觉系统的特性,可以利用人耳对声音的感知特点,将无关紧要的信号信息进行抑制或丢弃,从而达到压缩数据的目的。
同时,声音编码需要考虑到音频质量和文件大小的平衡,通过合理的编码算法和参数设置,可以在不损失太多音频质量的情况下达到较高的压缩率。
总结起来,声音编码的基本原理包括采样、量化、编码、压缩和解码等步骤。
常用的语音编码方法有常用的语音编码方法主要包括:PCM(脉冲编码调制)、ADPCM(自适应差分脉冲编码调制)、MP3(MPEG音频层3)、AAC(高级音频编码)、OPUS、GSM(全球系统移动通信)、ILBC(无损语音编码器)、G.722等。
1.PCM(脉冲编码调制)PCM是最常用的语音编码方法之一,将模拟语音信号采样后,通过量化和编码来数字化语音信号。
PCM编码质量较好,但占用存储空间较大。
2.ADPCM(自适应差分脉冲编码调制)ADPCM是对PCM的改进,通过预测和差分编码的方式来压缩语音数据。
ADPCM编码可以减小文件大小,但也会损失一定的音质。
3.MP3(MPEG音频层3)MP3是一种无损的音频压缩格式,通过删除人耳难以察觉的音频信号细节来减小文件大小。
MP3编码在音质和文件大小之间取得了平衡,成为广泛应用于音乐和语音传输的标准格式。
4.AAC(高级音频编码)AAC是一种高级音频编码方法,能够提供较好的音质和较小的文件大小。
AAC在广播、音乐和视频领域都有广泛应用。
5.OPUSOPUS是一种开放和免版权的音频编码格式,适用于广泛的应用场景,如实时通信、网络音频流传输等。
OPUS编码可以根据不同场景的需求,在音质和延迟之间做出灵活权衡。
6.GSM(全球系统移动通信)GSM编码是一种在移动通信领域广泛使用的语音编码方法,它通过移除语音频带中的高频和低频信息来实现数据压缩。
7.iLBC(无损语音编码器)iLBC是一种专为网络语音传输设计的编码格式,能够在高丢包环境下提供较好的语音质量。
8.G.722G.722是一种宽带语音编码方法,提供更好的语音质量和更宽的频带宽度,适用于音频和视频会议等高质量语音通信场景。
移动通信语音编码语音编码算法:主要有两大类:波形编码、声型(参量)编码1、波形编码:对语音波形进行抽样、量化、编码;典型的编码就是固定电话使用的PCM编码(8K抽样×8bit量化=64kbps);优点:话音质量好,MOS(Mean Opinion Score,主观平均得分)评级可达4.5分以上;缺点:编码速率较高,一般不小于16kbps,占用带宽资源多;2、声型(参量)编码:对人体喉咙发出的音调和噪声,以及口和舌的声学滤波效应建立模型(好High啊),将这些模型数据通过信道传输;优点:编码速率低(最低可以为2kbps),占用带宽资源少,频率资源相同的情况下,系统容量自然大一些;缺点:话音质量差,MOS评级有3.5分已经算不错了;为了兼顾系统容量和话音质量,移动通信系统一般采用混合编码。
各种无线制式采用的语音编码算法如下:GSM:FR(全速率编码,学名叫RPE - LTP(规则脉冲激励-长期预测编码),13Kbps)、EFR(增强型全速率,语音质量比FR好,13Kbps)、HR(半速率编码,使用它,GSM系统语音容量加倍,但是语音质量较差,6.5Kbps)WCDMA & TD:AMR(自适应-多速率编码,有8种语音速率,就好像一个懂8国语言的翻译家)目前采用的AMR语音编码8钟速率如下:12.2kbps(与GSM-EFR兼容),10.2kbps, 7.95kbps,7.40kbps,6.70kbps,5.90kbps, 5.15kbps, 4.75kbps其中:12.2kbps编码与GSM-EFR兼容;7.40kbps编码与美国标准IS-641(US-TDMA speech codec)兼容,不知道是不是兼容cdma2000的编码,请哪位C网高手澄清一下?6.70kbps编码与小灵通的PDC-EFR兼容,这主要是应日本运营商NTT DoCoMo的要求设计的(这个小日本的运营商在移动通信标准制定上有很大的影响力)可以看到,由于AMR语音算法与目前各种主流移动通信系统的编码兼容,所以非常利于设计多模终端。
语音编码的四个主要参量语音编码的四个主要参量是音素、基频、共振峰和增益。
这四个参量在语音编码中扮演着重要的角色,能够有效地捕捉和重建语音信号,以实现高质量的语音通信。
首先,音素是语音信号中的最小单位,是语言中不可分割的基本音素。
音素代表了语言中的不同音素类别,例如辅音和元音。
在语音编码中,音素的准确识别和编码对于实现高质量的语音通信至关重要。
音素编码技术能够将语音信号分解成一系列音素类别,然后将这些音素类别编码为数字或二进制数据,以便于存储和传输。
其次,基频是语音信号中的周期性变化,在语音编码中用于重建声调和语调信息。
基频代表了声音的音高,是声音波形中反复周期性变化的频率。
基频编码技术通过提取和编码语音信号中的基频信息,以实现重建原始声音的目的。
基频编码通常使用基于自相关或峰值跟踪等方法来估计和编码基频信息。
第三,共振峰是语音信号中的谐振频率,用于重建语音的清晰度和共鸣特性。
共振峰代表了声道系统的共鸣特性,通过声道滤波器对输入声音进行频率响应。
共振峰编码技术通过提取和编码语音信号中的共振峰信息,以实现重建原始声音的目的。
共振峰编码通常使用线性预测编码(LPC)等方法来估计和编码共振峰的位置和幅度。
最后,增益是语音信号中的能量或振幅级别,用于重建语音的音量和清晰度。
增益代表了声音的强度和能量水平,通常与语音的音量和响度相关。
增益编码技术通过提取和编码语音信号中的增益信息,以实现重建原始声音的目的。
增益编码通常使用自适应编码方法,如量化和编码器,以实现对增益数据的高效压缩和解压缩。
综上所述,音素、基频、共振峰和增益是语音编码中的四个主要参量。
它们分别代表了语言中的音素类别、声调和语调信息、共鸣特性以及音量和清晰度。
通过准确提取和编码这些参量,可以实现对语音信号的高效压缩和重建,从而实现高质量的语音通信。
各种语音编码标准,如G.711、G.729等,都基于这些参量和相应的编码算法,以满足不同的应用需求。
声音编码规则在音频处理中,声音的编码是非常重要的一环。
声音编码的规则主要包括采样率、位深度、声道数、压缩格式以及参数编码等方面。
下面将对这些问题进行详细的解释和阐述。
1. 采样率采样率是指在单位时间内对声音信号进行采样的次数。
采样率越高,声音的质量就越好,但同时需要的存储空间也越大。
常见的采样率有8000Hz、11025Hz、22050Hz、44100Hz等。
采样率的选择应根据声音的质量和存储空间的需求进行权衡。
2. 位深度位深度是指每个采样点所使用的二进制位数。
位深度越高,声音的质量就越好,但同时需要的存储空间也越大。
常见的位深度有8位、16位、24位、32位等。
位深度的选择应根据声音的质量和存储空间的需求进行权衡。
3. 声道数声道数是指声音信号的通道数量。
常见的声道数有单声道和立体声两种。
单声道只有一个通道,而立体声有两个通道,可以产生更好的空间效果。
声道数的选择应根据应用场景和效果需求进行选择。
4. 压缩格式压缩格式是指对声音信号进行压缩的方式。
压缩格式可以大大减少声音文件的存储空间,同时保持良好的声音质量。
常见的压缩格式有MP3、AAC、OGG等。
压缩格式的选择应根据应用场景和文件大小需求进行选择。
5. 参数编码参数编码是指对声音信号进行参数提取和编码的方式。
参数编码可以将声音信号转化为参数序列,如音高、振幅、频率等参数,从而实现对声音信号的描述和控制。
参数编码在语音识别、音乐信息检索等领域有着广泛的应用。
参数编码的选择应根据应用场景和计算资源需求进行选择。
总之,在声音编码时,需要根据应用场景、声音质量需求和存储空间等因素,综合考虑采样率、位深度、声道数、压缩格式和参数编码等因素,选择合适的声音编码规则,以达到良好的声音质量和存储效果。