计算机模拟_排队论
- 格式:doc
- 大小:43.66 KB
- 文档页数:8

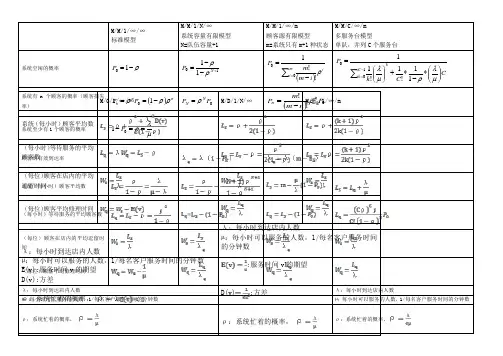
几种典型的排队模型(1)M/M/1/∞/∞/FCFS 单服务台排队模型系统的稳态概率n P01P ρ=-,/1ρλμ=<为服务强度;(1)n n P ρρ=-。
系统运行指标a.系统中的平均顾客数(队长期望值)0.s n i L n P λμλ∞===-∑;b.系统中排队等待服务的平均顾客数(排队长期望值)0(1).q n i L n P ρλμλ∞==-=-∑; c.系统中顾客停留时间的期望值1[]s W E W μλ==-; d.队列中顾客等待时间的期望值 1q s W W ρμμλ=-=-。
(2) M/M/1/N/∞/FCFS 单服务台排队模型系统的稳态概率n P011,11N P ρρρ+-=≠-; 11,1n n N P n N ρρρ+-=<- 系统运行指标 a .系统中的平均顾客数(队长期望值)11(1)11N s N N L ρρρρ+++=--- b .系统中排队等待服务的平均顾客数(排队长期望值)0(1)q s L L P =--c .系统中顾客停留时间的期望值0(1)s s L W P μ=- d .队列中顾客等待时间的期望值 。
1q s W W μ=-(3) M/M/1/∞/m/FCFS (或M/M/1/m/m/FCFS )单服务台排队模型系统的稳态概率n P001!()()!m i i P m m i λμ==-∑; 0!(),1()!n n m P P n m m n λμ=≤≤- 系统运行指标 a .系统中的平均顾客数(队长期望值)0(1)s L m P μλ=-- b .系统中排队等待服务的平均顾客数(排队长期望值) 00()(1)(1)q s L m P L P λμλ+=--=-- c .系统中顾客停留时间的期望值 01(1)s m W P μλ=-- d .队列中顾客等待时间的期望值1q s W W μ=-(4) M/M/c/∞/∞/FCFS 单服务台排队模型系统的稳态概率n P 100111[()()!!1c k c k P k c λλμρμ-==+-∑; 001(),!1(),!n n n n c P n c n P P n c c cλμλμ-⎧≤⎪⎪=⎨⎪>⎪⎩ 系统运行指标a .系统中的平均顾客数(队长期望值):s q L L λμ=+ b .系统中排队等待服务的平均顾客数(排队长期望值):021()(1)!(1)c q n n c c L n P P c ρρρ∞=+=-=-∑ c .系统中顾客停留时间的期望值:s s L W λ=d .队列中顾客等待时间的期望值: q q L W λ=[典型例题精解]例1:在某单人理发馆,顾客到达为普阿松流,平均到达间隔为20分钟,理发时间服从负指数分布,平均时间为15分钟。

排队论模型随机服务系统理论是研究由顾客、服务机构及其排队现象所构成的一种排队系统的理论,又称排队论。
排队现象是一种经常遇见的非常熟悉的现象,例如:顾客到自选商场购物、乘客乘电梯上班、汽车通过收费站等。
随机服务系统模型已广泛应用于各种管理系统,如生产管理、库存管理、商业服务、交通运输、银行业务、医疗服务、计算机设计与性能估价,等等。
随机服务系统模拟,如存储系统模拟类似,就是利用计算机对一个客观复杂的随机服务系统的结构和行为进行动态模拟,以获得系统或过程的反映其本质特征的数量指标结果,进而预测、分析或估价该系统的行为效果,为决策者提供决策依据。
排队论模型及其在医院管理中的作用每当某项服务的现有需求超过提供该项服务的现有能力时,排队就会发生。
排队论就是对排队进行数学研究的理论。
在医院系统内,“三长一短”的现象是司空见惯的。
由于病人到达时间的随机性或诊治病人所需时间的随机性,排队几乎是不可避免的。
但如何合理安排医护人员及医疗设备,使病人排队等待的时间尽可能减少,是本文所要介绍的。
一、医院系统的排队过程模型医院是一个复杂的系统,病人在医院中的排队过程也是很复杂的。
如图1中每一个箭头所指的方框都是一个服务机构,都可构成一个排队系统,可见图2。
图1 医院系统的多级排队过程模型二、排队系统的组成和特征一般的排队系统都有三个基本组成部分:1. 输入过程其特征有:顾客源(病人源)的组成是有限的或无限的;顾客单个到来或成批到来;到达的间隔时间是确定的或随机的;顾客的到来是相互独立或有关联的;顾客相继到达的间隔时间分布和所含参数(如期望值、方差等)都与时间无关或有关。
2. 排队规则其特征是对排队等候顾客进行服务的次序有下列规则:先到先服务,后到先服务,有优先权的服务(如医院对于病情严重的患者给予优先治疗,在此不做一般性的讨论),随机服务等;还有具体排队(如在候诊室)和抽象排队(如预约排队)。
排队的列数还分单列和多列。
3. 服务机构其特征有:一个或多个服务员;服务时间也分确定的和随机的;服务时间的分布与时间有关或无关。

第1篇一、实验背景排队论是运筹学的一个重要分支,主要研究在服务系统中顾客的等待时间和服务效率等问题。
在现实生活中,排队现象无处不在,如银行、医院、超市、餐厅等。
通过对排队问题的研究,可以帮助我们优化服务系统,提高顾客满意度,降低运营成本。
本实验旨在通过模拟排队系统,探究排队论在实际问题中的应用。
二、实验目的1. 理解排队论的基本概念和原理。
2. 掌握排队模型的建立方法。
3. 熟悉排队系统参数的估计和调整。
4. 分析排队系统的性能指标,如平均等待时间、服务效率等。
5. 培养运用排队论解决实际问题的能力。
三、实验内容1. 建立排队模型本实验以银行排队系统为例,建立M/M/1排队模型。
该模型假设顾客到达服从泊松分布,服务时间服从负指数分布,服务台数量为1。
2. 参数估计根据实际数据,估计排队系统参数。
假设顾客到达率为λ=2(人/分钟),服务时间为μ=5(分钟/人)。
3. 模拟排队系统使用计算机模拟排队系统,记录顾客到达、等待、服务、离开等过程。
4. 性能分析分析排队系统的性能指标,如平均等待时间、服务效率、顾客满意度等。
四、实验步骤1. 初始化参数设置顾客到达率λ、服务时间μ、服务台数量n。
2. 生成顾客到达序列根据泊松分布生成顾客到达序列。
3. 模拟排队过程(1)当服务台空闲时,允许顾客进入队列。
(2)当顾客进入队列后,开始计时,等待服务。
(3)当服务台服务完毕,顾客离开,开始下一个顾客的服务。
4. 统计性能指标记录顾客等待时间、服务时间、顾客满意度等数据。
5. 分析结果根据实验数据,分析排队系统的性能,并提出优化建议。
五、实验结果与分析1. 平均等待时间根据模拟结果,平均等待时间为2.5分钟。
2. 服务效率服务效率为80%,即每分钟处理0.8个顾客。
3. 顾客满意度根据模拟结果,顾客满意度为85%。
4. 优化建议(1)增加服务台数量,提高服务效率。
(2)优化顾客到达率,降低顾客等待时间。
(3)调整服务时间,缩短顾客等待时间。


用蒙特卡洛法实现对排队等待问题的计算机模拟蒙特卡洛(MonteCarlo)法,或称统计试验法、计算机随机模拟方法,起源于美国在第一次世界大战进研制原子弹的“曼哈顿计划”。
该计划的主持人之一、数学家冯·诺伊曼用驰名世界的赌城—摩纳哥的MonteCarlo—来命名这种方法,为它蒙上了一层神秘色彩。
一、蒙特卡洛法的基本思想及其应用MonteCarlo方法是一种基于“随机数”,采用统计抽样方法,近似求解数学问题或物理问题的过程。
把统计模拟法用于数值计算已有200多年的历史,最早是法国数学家蒲丰(1707-1788)。
他进行了著名的“蒲丰投针实验”,早以此来求圆周率π的近似值。
本世纪40年代,随着电子计算机的出现,特别是近年来高速电子计算机的出现,使得用数学方法在计算机上大量、快速地模拟这样的试验成为可能。
统计试验法通常用来研究概率过程,研究问题时常涉及下列一些与随机因素有关的概率,如各类概率等,一般来说,建立描述过程的复杂的概率模型是不成问题的,但用数学方法研究与分析这些模型是却很困难,问题的维数(即变量的个数)可能高达数百甚至数千。
对这类问题,难度随维数的增加呈指数增长,这就是所谓的“维数的灾难”(Co urse Dimensionality)。
传统的数值方法难以对付(即使使用速度最快的计算机),甚至达到了无法进行的地步。
因此,唯一可取的研究方法是统计实验法。
统计模拟(蒙特卡洛法),在系统工程中的应用日益广泛,据国外有关文献报道其应用领域大致有:1.航空运输排队,机场设计等;2.港口设计,泊位研究等;3.消防车或救护车的布局和调派;4.城市公共汽车作业调度;5.出租汽车调度计划;- 1 -6.铁路货运调度计划;7.加油站、停车场等设计;8.售票所布局;9.存储模拟,仓库布局等;10.设备维修计划;11.生产过程的安排;12.工厂的单件、小批生产的作业计划;13.销售预测;二、排队或等待问题的分析在日常生活中,我们每天都会遇到各种各样的排队。

排队论模型排队系统模型的根本组成局部效劳系统由效劳机构和效劳对象〔顾客〕构成。
如果效劳对象到来的时刻和对他效劳的时间〔即占用效劳系统的时间〕都是随机的,则这个效劳系统称为派对系统。
图1为一最简单的排队系统模型。
排队系统包括三个组成局部:输入过程、排队规则和效劳机构。
输入过程对于排队系统,顾客到达时输入。
输入过程考察的是顾客到达效劳系统的规律。
它可以用一定时间顾客到达数或前后两个顾客相继到达的间隔时间来描述,一般分为确定型和随机型两种。
例如,在生产线上加工的零件按规定的间隔时间依次到达加工地点,定期运行的班车、班机等都属于确定型输入。
随机型的输入是指在时间t 顾客到达数 n 〔t 〕服从一定的随机分布。
如服从泊松分布,则在时间t 到达n 个顾客的概率为其中λ>0为一常数。
令第i 个顾客到达的时刻为Τi(i=1,2,…),Τ0≡0,并令ti=Τi-Τi-1,则相继到达的顾客的间隔时间ti 是相互独立同分布的,其分布函数为负指数分布,即式中λ为单位时间顾客期望到达数,称为平均到达率;1/λ为平均间隔时间。
在排队论中,讨论的输入过程主要是随机型的。
排队规则排队规则分为等待制、消失制和混合制三种。
1, 等候制顾客到达后,如果效劳机构已经占满,当允许顾客等待时,再到的顾客便排队等待。
常见的有以下几种排队方式:(1) 先到先效劳 这是最普遍的情形。
例如:医院候诊的患者。
(2) 后到先效劳 许多存储系统中运用这种规则,例如:加工钢板总是先从上面取来加工。
A(t)=1-t e λ- , t ≥0 0 , t<0(3) 随即效劳 当一名顾客承受效劳完毕离去时,随机的从等候的顾客中选择一名进展效劳,等待中的每位顾客被选中的概率是相等的。
例如订票效劳。
(4) 优先效劳 对于不同的顾客,规定不同的优先权,具备较高优先权的顾客,优先承受效劳。
例如;急诊病人、加急电报等。
2, 消失制当效劳机构已全部占满时,再到的顾客不能进入效劳系统,顾客自动消失。


基于计算机仿真的排队系统优化问题研究一、本文概述随着信息技术的快速发展和广泛应用,排队系统在各种实际场景中的应用越来越普遍,如银行、医院、商场、交通等各个领域。
然而,传统的排队系统往往存在效率不高等待时间长、服务质量不稳定等问题,这些问题不仅影响了服务效率,也降低了客户满意度。
因此,如何优化排队系统,提高服务效率和质量,成为了当前研究的热点之一。
基于计算机仿真的排队系统优化问题研究,旨在通过计算机仿真技术,对排队系统的运行过程进行模拟和分析,发现系统存在的问题和瓶颈,进而提出有效的优化策略。
本文首先介绍了排队系统的基本概念和分类,分析了传统排队系统存在的问题和挑战。
然后,详细介绍了计算机仿真技术在排队系统优化中的应用,包括仿真模型的建立、仿真实验的设计和实施、仿真结果的分析和评估等方面。
接着,本文重点探讨了基于计算机仿真的排队系统优化策略,包括服务流程优化、资源配置优化、排队规则优化等方面,并通过案例分析和实验验证,证明了这些优化策略的有效性和可行性。
本文的研究不仅有助于解决传统排队系统存在的问题,提高服务效率和质量,也有助于推动计算机仿真技术在排队系统优化中的广泛应用和发展。
本文的研究方法和成果也可以为其他领域的系统优化问题提供借鉴和参考。
二、排队系统理论基础排队系统,也称为随机服务系统,是一种广泛存在于现实生活中的数学模型。
这种模型通常描述顾客到达服务机构,等待并接受服务的过程。
排队系统理论的核心在于分析并优化这种服务过程的效率。
在计算机仿真领域,通过模拟排队系统的运行过程,可以深入理解其内部机制,为优化系统性能提供理论支持。
排队系统主要由三个基本部分构成:输入过程、排队规则和服务机构。
输入过程描述了顾客到达服务系统的规律,常见的输入过程包括定长输入、泊松输入等。
排队规则决定了顾客在系统中的等待和服务顺序,常见的有先到先服务(FCFS)、最短作业优先(SJF)等。
服务机构则负责为顾客提供服务,其服务能力通常受到多种因素的影响,如服务速度、服务人员数量等。

计算机网络的排队论模型计算机网络的排队论模型是一种理论模型,用于研究计算机网络中传输数据时产生的排队现象和性能表现。
排队论模型可以帮助我们理解计算机网络中的数据传输过程,优化网络性能,提高网络的吞吐量和响应速度。
在本文中,我们将介绍计算机网络排队论模型的基本概念、分类和应用。
一、排队论模型的基本概念1.1 排队系统排队系统是指在一个服务设施之前等待服务的顾客队列。
在计算机网络中,排队系统可以看作是数据包在网络节点之间传输时产生的排队现象。
排队系统包括输入过程、服务机构和排队规则。
1.2 排队论模型排队论模型是对排队系统进行数学建模和分析的方法。
排队论模型通常包括顾客到达过程、服务时间分布、队列容量和服务规则等因素。
排队论模型可以帮助我们预测排队系统的性能表现,如平均等待时间、系统繁忙度和响应时间等指标。
二、排队论模型的分类2.1 M/M/1排队模型M/M/1排队模型是最简单的排队论模型之一,其中"M"代表顾客到达过程和服务时间满足指数分布,"1"代表只有一个服务设施。
M/M/1排队模型可以用来分析单一服务节点的性能表现,如平均等待时间和系统繁忙度等指标。
2.2 M/M/C排队模型M/M/C排队模型是相对复杂一些的排队论模型,其中"C"代表有C个服务设施。
M/M/C排队模型可以用来分析多个服务节点的性能表现,如系统的吞吐量和响应时间等指标。
2.3 其他排队模型除了M/M/1和M/M/C排队模型,还有很多其他类型的排队论模型,如M/M/∞排队模型、M/G/1排队模型和多类别排队模型等。
每种排队模型都有其独特的特点和适用范围,可以根据实际情况选择合适的模型进行性能分析。
三、计算机网络排队论模型的应用3.1 网络流量建模计算机网络排队论模型可以用来建模网络中的数据传输过程,分析网络节点的繁忙度和数据包的平均等待时间。
通过对网络流量进行建模,可以优化网络拓扑结构、改进路由算法和提高网络性能。

排队模型之港口系统本文通过排队论和蒙特卡洛方法解决了生产系统的效率问题,通过对工具到达时间和服务时间的计算机拟合,将基本模型确定在//1M M排队模型,通过对此基本模型的分析和改进,在概率论相关理论的基础之上使用计算机模拟仿真(蒙特卡洛法)对生产系统的整个运行过程进行模拟,得出最后的结论。
好。
关键词:问题提出:一个带有船只卸货设备的小港口,任何时间仅能为一艘船只卸货。
船只进港是为了卸货,响铃两艘船到达的时间间隔在15分钟到145分钟变化。
一艘船只卸货的时间有所卸货物的类型决定,在15分钟到90分钟之间变化。
那么,每艘船只在港口的平均时间和最长时间是多少?若一艘船只的等待时间是从到达到开始卸货的时间,每艘船只的平均等待时间和最长等待时间是多少?卸货设备空闲时间的百分比是多少?船只排队最长的长度是多少?问题分析:排队论:排队论(Queuing Theory) ,是研究系统随机聚散现象和随机服务系统工作过程的数学理论和方法,又称随机服务系统理论,为运筹学的一个分支。
本题研究的是生产系统的效率问题,可以将磨损的工具认为顾客,将打磨机当做服务系统。
【1】M M:较为经典的一种排队论模式,按照前面的Kendall记号定义,//1前面的M代表顾客(工具)到达时间服从泊松分布,后面的M则表示服务时间服从负指数分布,1为仅有一个打磨机。
蒙特卡洛方法:蒙特卡洛法蒙特卡洛(Monte Carlo)方法,或称计算机随机模拟方法,是一种基于“随机数”的计算方法。
这一方法源于美国在第一次世界大战进研制原子弹的“曼哈顿计划”。
该计划的主持人之一、数学家冯·诺伊曼用驰名世界的赌城—摩纳哥的Monte Carlo—来命名这种方法,为它蒙上了一层神秘色彩。
(2)排队论研究的基本问题1.排队系统的统计推断:即判断一个给定的排队系统符合于哪种模型,以便根据排队理论进行研究。
2.系统性态问题:即研究各种排队系统的概率规律性,主要研究队长分布、等待时间分布和忙期分布等统计指标,包括了瞬态和稳态两种情形。
当排队系统的到达间隔时间和服务时间的概率分布很复杂时,或不能用公式给出时,那么就不能用解析法求解。
这就需用随机模拟法求解,现举例说明。
例 1 设某仓库前有一卸货场,货车一般是夜间到达,白天卸货,每天只能卸货2车,若一天内到达数超过2车,那么就推迟到次日卸货。
根据表3所示的数据,货车到达数的概率分布(相对频率)平均为1.5车/天,求每天推迟卸货的平均车数。
解服从指数分布(这是定长服务时间)。
随机模拟法首先要求事件能按历史的概率分布规律出现。
模拟时产生的随机数与事件的对应关系如表4。
表 4 到达车数的概率及其对应的随机数我们用 a1 表示产生的随机数,a2 表示到达的车数,a3 表示需要卸货车数,a4表示实际卸货车数,a5 表示推迟卸货车数。
编写程序如下:clearrand('state',sum(100*clock));n=50000;m=2a1=rand(n,1);a2=a1; %a2初始化a2(find(a1<0.23))=0;a2(find(0.23<=a1&a1<0.53))=1;a2(find(0.53<=a1&a1<0.83))=2;a2(find(0.83<=a1&a1<0.93),1)=3;a2(find(0.93<=a1&a1<0.98),1)=4;a2(find(a1>=0.98))=5;a3=zeros(n,1);a4=zeros(n,1);a5=zeros(n,1); %a2初始化a3(1)=a2(1);if a3(1)<=ma4(1)=a3(1);a5(1)=0;elsea4(1)=m;a5(1)=a2(1)-m;endfor i=2:na3(i)=a2(i)+a5(i-1);if a3(i)<=ma4(i)=a3(i);a5(i)=0;elsea4(i)=m;a5(i)=a3(i)-m;endenda=[a1,a2,a3,a4,a5];sum(a)/nm =2ans =0.4985 1.4909 2.3782 1.4909 0.8874例2银行计划安置自动取款机,已知A型机的价格是B型机的2倍,而A型机的性能—平均服务率也是B型机的2倍,问应该购置1台 A 型机还是2台 B 型机。
为了通过模拟回答这类问题,作如下具体假设,顾客平均每分钟到达1位, A 型机的平均服务时间为0.9分钟,B 型机为1.8分钟,顾客到达间隔和服务时间都服从指数分布,2台B型机采取M/M/2模型(排一队),用前100名顾客(第 1 位顾客到达时取款机前为空)的平均等待时间为指标,对A型机和B型机分别作1000次模拟,进行比较。
理论上已经得到,A型机和B型机前100名顾客的平均等待时间分别为μ1(100)=4.13,μ2(100)=3.70,即 B 型机优。
对于M/M/1模型,记第k位顾客的到达时刻为ck,离开时刻为gk,等待时间为wk,它们很容易根据已有的到达间隔ik和服务时间sk按照以下的递推关系得到(w1 = 0,设c1,g1已知):ck=ck−1+ik,gk=max(ck,gk−1)+ sk,wk=max(0,gk−1− ck), k=2,3,L。
在模拟A型机时,用cspan表示到达间隔时间,sspan表示服务时间,ctime表示到达时间,gtime表示离开时间,wtime表示等待时间。
我们总共模拟了m次,每次n个顾客。
程序如下:ticrand('state',sum(100*clock));n=100;m=1000;mu1=1;mu2=0.9;for j=1:mcspan=exprnd(mu1,1,n);sspan=exprnd(mu2,1,n);ctime(1)=cspan(1);gtime(1)=ctime(1)+sspan(1);wtime(1)=0;for i=2:nctime(i)=ctime(i-1)+cspan(i);gtime(i)=max(ctime(i),gtime(i-1))+sspan(i);wtime(i)=max(0,gtime(i-1)-ctime(i));endresult1(j)=sum(wtime)/n;endresult_1=sum(result1)/mtocresult_1 =4.0467Elapsed time is 0.445770 seconds.类似地,模拟B型机的程序如下:ticrand('state',sum(100*clock));n=100;m=1000;mu1=1;mu2=1.8;for j=1:mcspan=exprnd(mu1,1,n);sspan=exprnd(mu2,1,n);ctime(1)=cspan(1);ctime(2)=ctime(1)+cspan(2);gtime(1:2)=ctime(1:2)+sspan(1:2);wtime(1:2)=0;flag=gtime(1:2);for i=3:nctime(i)=ctime(i-1)+cspan(i);gtime(i)=max(ctime(i),min(flag))+sspan(i);wtime(i)=max(0,min(flag)-ctime(i));flag=[max(flag),gtime(i)];endresult2(j)=sum(wtime)/n;endresult_2=sum(result2)/mtocresult_2 =3.7368Elapsed time is 1.453880 seconds.可以用下面的程序与上面的程序比较了解编程的效率问题。
ticclearrand('state',sum(100*clock));n=100;m=1000;mu1=1;mu2=0.9;for j=1:mctime(1)=exprnd(mu1);gtime(1)=ctime(1)+exprnd(mu2);wtime(1)=0;for i=2:nctime(i)=ctime(i-1)+exprnd(mu1);gtime(i)=max(ctime(i),gtime(i-1))+exprnd(mu2);wtime(i)=max(0,gtime(i-1)-ctime(i));endresult(j)=sum(wtime)/n;endresult=sum(result)/mtocresult =4.2162Elapsed time is 3.854620 seconds.黄河小浪底调水调沙问题5.1 问题的提出2004年6月至7月黄河进行了第三次调水调沙试验,特别是首次由小浪底、三门峡和万家寨三大水库联合调度,采用接力式防洪预泄放水,形成人造洪峰进行调沙试验获得成功。
整个试验期为20多天,小浪底从6月19日开始预泄放水,直到7月13日恢复正常供水结束。
小浪底水利工程按设计拦沙量为75.5 亿m3,在这之前,小浪底共积泥沙达14.15亿t。
这次调水调沙试验一个重要目的就是由小浪底上游的三门峡和万家寨水库泄洪,在小浪底形成人造洪峰,冲刷小浪底库区沉积的泥沙,在小浪底水库开闸泄洪以后,从6月27日开始三门峡水库和万家寨水库陆续开闸放水,人造洪峰于29日先后到达小浪底,7月3日达到最大流量2700m3/s,使小浪底水库的排沙量也不断地增加。
表7是由小浪底观测站从6月29日到7月10日检测到的试验数据。
表 7 观测数据(1)给出估计任意时刻的排沙量及总排沙量的方法;(2)确定排沙量与水流量的关系。
5.2 模型的建立与求解已知给定的观测时刻是等间距的,以6月29日零时刻开始计时,则各次观测时刻(离开始时刻6月29日零时刻的时间)分别为ti =3600(12i−4),i=1,2,L,24,其中计时单位为秒。
第1次观测的时刻t1=28800,最后一次观测的时刻t24=1022400 。
记第i(i= 1,2,L,24)次观测时水流量为vi,含沙量为ci,则第i次观测时的排沙量为yi=ci*vi 。
有关的数据见表8。
对于问题(1),根据所给问题的试验数据,要计算任意时刻的排沙量,就要确定出排沙量随时间变化的规律,可以通过插值来实现。
考虑到实际中的排沙量应该是时间的连续函数,为了提高模型的精度,我们采用三次样条函数进行插值。
利用 MATLAB 函数,求出三次样条函数,得到排沙量y=y(t)与时间的关系,然后进行积分,就可以得到总的排沙量最后求得总的排沙量为1.844 ×109 t,计算的 Matlab 程序如下:clc,clearload data.txt %data.txt 按照原始数据格式把水流量和排沙量排成4行12列liu=data([1,3],:);liu=liu';liu=liu(:);sha=data([2,4],:);sha=sha';sha=sha(:);y=sha.*liu;y=y';i=1:24;t=(12*i-4)*3600;t1=t(1);t2=t(end);pp=csape(t,y);xsh=pp.coefs %求得插值多项式的系数矩阵,每一行是一个区间上多项式的系数。
TL=quadl(@(tt)ppval(pp,tt),t1,t2)也可以利用 3 次 B 样条函数进行插值,求得总的排沙量也为1.844 ×109 t,,计算的 Matlab 程序如下:clc,clearload data.txt %data.txt 按照原始数据格式把水流量和排沙量排成4行12列liu=data([1,3],:);liu=liu';liu=liu(:);sha=data([2,4],:);sha=sha';sha=sha(:);y=sha.*liu;y=y';i=1:24;t=(12*i-4)*3600;t1=t(1);t2=t(end);pp=spapi(4,t,y) %三次 B 样条pp2=fn2fm(pp,'pp') %把 B 样条函数转化为 pp 格式TL=quadl(@(tt)fnval(pp,tt),t1,t2)对于问题(2),研究排沙量与水量的关系,从试验数据可以看出,开始排沙量是随着水流量的增加而增长,而后是随着水流量的减少而减少。
显然,变化规律并非是线性的关系,为此,把问题分为两部分,从开始水流量增加到最大值 2720m3/s(即增长的过程)为第一阶段,从水流量的最大值到结束为第二阶段,分别来研究水流量与排沙量的关系。
画出排沙量与水流量的散点图。
画散点图的程序如下:load data.txtliu=data([1,3],:); liu=liu';liu=liu(:);sha=data([2,4],:); sha=sha';sha=sha(:);y=sha.*liu;subplot(1,2,1), plot(liu(1:11),y(1:11),'*')subplot(1,2,2), plot(liu(12:24),y(12:24),'*')从散点图可以看出,第一阶段基本上是线性关系,第二阶段准备依次用二次、三次、四次曲线来拟合,看哪一个模型的剩余标准差小就选取哪一个模型。