BP神经网络实例
- 格式:doc
- 大小:218.00 KB
- 文档页数:14



BP人工神经网络的基本原理模型与实例BP(Back Propagation)人工神经网络是一种常见的人工神经网络模型,其基本原理是模拟人脑神经元之间的连接和信息传递过程,通过学习和调整权重,来实现输入和输出之间的映射关系。
BP神经网络模型基本上由三层神经元组成:输入层、隐藏层和输出层。
每个神经元都与下一层的所有神经元连接,并通过带有权重的连接传递信息。
BP神经网络的训练基于误差的反向传播,即首先通过前向传播计算输出值,然后通过计算输出误差来更新连接权重,最后通过反向传播调整隐藏层和输入层的权重。
具体来说,BP神经网络的训练过程包括以下步骤:1.初始化连接权重:随机初始化输入层与隐藏层、隐藏层与输出层之间的连接权重。
2.前向传播:将输入向量喂给输入层,通过带有权重的连接传递到隐藏层和输出层,计算得到输出值。
3.计算输出误差:将期望输出值与实际输出值进行比较,计算得到输出误差。
4.反向传播:从输出层开始,将输出误差逆向传播到隐藏层和输入层,根据误差的贡献程度,调整连接权重。
5.更新权重:根据反向传播得到的误差梯度,使用梯度下降法或其他优化算法更新连接权重。
6.重复步骤2-5直到达到停止条件,如达到最大迭代次数或误差小于一些阈值。
BP神经网络的训练过程是一个迭代的过程,通过不断调整连接权重,逐渐减小输出误差,使网络能够更好地拟合输入与输出之间的映射关系。
下面以一个简单的实例来说明BP神经网络的应用:假设我们要建立一个三层BP神经网络来预测房价,输入为房屋面积和房间数,输出为价格。
我们训练集中包含一些房屋信息和对应的价格。
1.初始化连接权重:随机初始化输入层与隐藏层、隐藏层与输出层之间的连接权重。
2.前向传播:将输入的房屋面积和房间数喂给输入层,通过带有权重的连接传递到隐藏层和输出层,计算得到价格的预测值。
3.计算输出误差:将预测的价格与实际价格进行比较,计算得到输出误差。
4.反向传播:从输出层开始,将输出误差逆向传播到隐藏层和输入层,根据误差的贡献程度,调整连接权重。

BP神经网络模型第1节基本原理简介近年来全球性的神经网络研究热潮的再度兴起,不仅仅是因为神经科学本身取得了巨大的进展.更主要的原因在于发展新型计算机和人工智能新途径的迫切需要.迄今为止在需要人工智能解决的许多问题中,人脑远比计算机聪明的多,要开创具有智能的新一代计算机,就必须了解人脑,研究人脑神经网络系统信息处理的机制.另一方面,基于神经科学研究成果基础上发展出来的人工神经网络模型,反映了人脑功能的若干基本特性,开拓了神经网络用于计算机的新途径.它对传统的计算机结构和人工智能是一个有力的挑战,引起了各方面专家的极大关注.目前,已发展了几十种神经网络,例如Hopficld模型,Feldmann等的连接型网络模型,Hinton等的玻尔茨曼机模型,以及Rumelhart等的多层感知机模型和Kohonen的自组织网络模型等等。
在这众多神经网络模型中,应用最广泛的是多层感知机神经网络。
多层感知机神经网络的研究始于50年代,但一直进展不大。
直到1985年,Rumelhart等人提出了误差反向传递学习算法(即BP算),实现了Minsky的多层网络设想,如图34-1所示。
BP 算法不仅有输入层节点、输出层节点,还可有1个或多个隐含层节点。
对于输入信号,要先向前传播到隐含层节点,经作用函数后,再把隐节点的输出信号传播到输出节点,最后给出输出结果。
节点的作用的激励函数通常选取S 型函数,如Qx e x f /11)(-+=式中Q 为调整激励函数形式的Sigmoid 参数。
该算法的学习过程由正向传播和反向传播组成。
在正向传播过程中,输入信息从输入层经隐含层逐层处理,并传向输出层。
每一层神经元的状态只影响下一层神经输入层 中间层 输出层 图34-1 BP 神经网络模型元的状态。
如果输出层得不到期望的输出,则转入反向传播,将误差信号沿原来的连接通道返回,通过修改各层神经元的权值,使得误差信号最小。
社含有n 个节点的任意网络,各节点之特性为Sigmoid 型。




BP⼈⼯神经⽹络试验报告⼀学号:北京⼯商⼤学⼈⼯神经⽹络实验报告实验⼀基于BP算法的XX及Matlab实现院(系)专业学⽣姓名成绩指导教师2011年10⽉⼀、实验⽬的:1、熟悉MATLAB 中神经⽹络⼯具箱的使⽤⽅法;2、了解BP 神经⽹络各种优化算法的原理;3、掌握BP 神经⽹络各种优化算法的特点;4、掌握使⽤BP 神经⽹络各种优化算法解决实际问题的⽅法。
⼆、实验内容:1 案例背景1.1 BP 神经⽹络概述BP 神经⽹络是⼀种多层前馈神经⽹络,该⽹络的主要特点是信号前向传递,误差反向传播。
在前向传递中,输⼊信号从输⼊层经隐含层逐层处理,直⾄输出层。
每⼀层的神经元状态只影响下⼀层神经元状态。
如果输出层得不到期望输出,则转⼊反向传播,根据预测误差调整⽹络权值和阈值,从⽽使BP 神经⽹络预测输出不断逼近期望输出。
BP 神经⽹络的拓扑结构如图1.1所⽰。
图1.1 BP 神经⽹络拓扑结构图图1.1中1x ,2x , ……n x 是BP 神经⽹络的输⼊值1y ,2y , ……n y 是BP 神经的预测值,ij ω和jk ω为BP 神经⽹络权值。
从图1.1可以看出,BP 神经⽹络可以看成⼀个⾮线性函数,⽹络输⼊值和预测值分别为该函数的⾃变量和因变量。
当输⼊节点数为n ,输出节点数为m 时,BP 神经⽹络就表达了从n 个⾃变量到m 个因变量的函数映射关系。
BP 神经⽹络预测前⾸先要训练⽹络,通过训练使⽹络具有联想记忆和预测能⼒。
BP 神经⽹络的训练过程包括以下⼏个步骤。
步骤1:⽹络初始化。
根据系统输⼊输出序列()y x ,确定⽹络输⼊层节点数n 、隐含层节点数l ,输出层节点数m ,初始化输⼊层、隐含层和输出层神经元之间的连接权值ij ω和式中, l 为隐含层节点数; f 为隐含层激励函数,该函数有多种表达形式,本章所选函数为:步骤3:输出层输出计算。
根据隐含层输出H ,连接权值jk ω和阈值b ,计算BP 神经⽹络预测输出O 。


基于BP神经网络的短期负荷预测基于BP神经网络的短期负荷预测一、引言电力系统的短期负荷预测在电力行业中扮演着重要角色。
准确预测短期负荷有助于确保电力系统的稳定运行,合理安排电力资源,提高电力供应的可靠性和效率。
然而,由于负荷预测的复杂性和不确定性,传统的统计方法往往不能满足准确预测的要求。
随着计算机技术的快速发展,人工智能技术被广泛应用于负荷预测领域。
其中,基于BP神经网络的短期负荷预测方法因其较高的准确性和灵活性而备受关注。
本文旨在探讨基于BP神经网络的短期负荷预测原理及应用,并通过实例分析展示其优势和局限性。
二、基于BP神经网络的负荷预测原理BP神经网络(Backpropagation Neural Network)是一种具有反向传播算法的人工神经网络。
它由输入层、隐藏层和输出层组成,通过非线性映射将输入信号转换为输出信号。
在负荷预测中,输入层通常包含历史负荷数据和其它相关因素(如天气、季节等),输出层则是预测的负荷值。
具体而言,BP神经网络的预测过程可以分为以下几个步骤:1. 数据准备:将历史负荷数据进行预处理,包括归一化、滤波和特征提取等。
同时,对于相关因素的数据也需要进行同样的处理。
2. 网络搭建:确定神经网络的结构和参数设置。
隐藏层的节点数量和层数的选择是关键,过少会导致欠拟合,过多则可能引起过拟合。
3. 前向传播:将输入数据通过神经网络传递,计算每个神经元的输出。
此过程中,网络中的连接权重根据当前输入和人工设定的权重进行调整。
4. 反向传播:根据误差函数计算损失,并通过链式法则更新各层的权重。
该过程反复进行直到误差小于预设阈值。
5. 预测与评估:使用训练好的神经网络对新的输入数据进行预测,并评估预测结果的准确性。
常用评估指标包括均方根误差(RMSE)和平均绝对百分比误差(MAPE)等。
三、基于BP神经网络的负荷预测应用基于BP神经网络的短期负荷预测方法已在电力系统中得到广泛应用。
以下是几个典型的应用实例:1. 区域负荷预测:通过采集各个区域的历史负荷数据和相关影响因素,建立对应的BP神经网络模型,实现对区域负荷的短期预测。
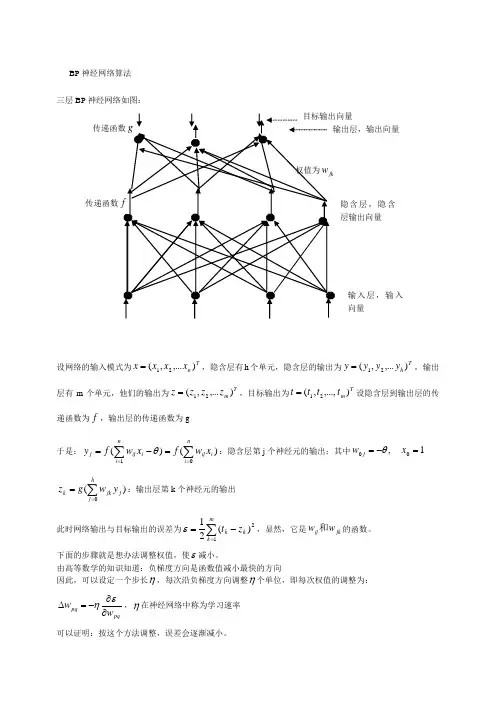
BP 神经网络算法 三层BP 神经网络如图:设网络的输入模式为Tn x x x x ),...,(21=,隐含层有h 个单元,隐含层的输出为Th y y y y ),...,(21=,输出层有m 个单元,他们的输出为Tm z z z z ),...,(21=,目标输出为Tm t t t t ),...,,(21=设隐含层到输出层的传递函数为f ,输出层的传递函数为g于是:)()(1∑∑===-=ni i ij ni iij j x w f xw f y θ:隐含层第j 个神经元的输出;其中1,00=-=x w j θ)(0∑==hj j jk k y w g z :输出层第k 个神经元的输出此时网络输出与目标输出的误差为∑=-=m k k k z t 12)(21ε,显然,它是jk ij w w 和的函数。
下面的步骤就是想办法调整权值,使ε减小。
由高等数学的知识知道:负梯度方向是函数值减小最快的方向因此,可以设定一个步长η,每次沿负梯度方向调整η个单位,即每次权值的调整为:pqpq w w ∂∂-=∆εη,η在神经网络中称为学习速率 可以证明:按这个方法调整,误差会逐渐减小。
隐含层,隐含层输出向量传递函数输入层,输入向量BP 神经网络(反向传播)的调整顺序为: 1)先调整隐含层到输出层的权值 设k v 为输出层第k 个神经元的输入∑==hj j jkk y wv 0-------复合函数偏导公式若取x e x f x g -+==11)()(,则)1()111(11)1()('2k k v v v v k z z ee e e u g kk k k -=+-+=+=---- 于是隐含层到输出层的权值调整迭代公式为: 2)从输入层到隐含层的权值调整迭代公式为: 其中j u 为隐含层第j 个神经元的输入:∑==ni i ijj x wu 0注意:隐含层第j 个神经元与输出层的各个神经元都有连接,即jy ∂∂ε涉及所有的权值ij w ,因此∑∑==--=∂∂∂∂∂-∂=∂∂m k jk k k k j k k k m k k k k j w u f z t y u u z z z t y 002)(')()(ε于是:因此从输入层到隐含层的权值调整迭代为公式为: 例:下表给出了某地区公路运力的历史统计数据,请建立相应的预测模型,并对给出的2010和2011年的数据,预测相应的公路客运量和货运量。
Python实现的三层BP神经⽹络算法⽰例本⽂实例讲述了Python实现的三层BP神经⽹络算法。
分享给⼤家供⼤家参考,具体如下:这是⼀个⾮常漂亮的三层反向传播神经⽹络的python实现,下⼀步我准备试着将其修改为多层BP神经⽹络。
下⾯是运⾏演⽰函数的截图,你会发现预测的结果很惊⼈!提⽰:运⾏演⽰函数的时候,可以尝试改变隐藏层的节点数,看节点数增加了,预测的精度会否提升import mathimport randomimport stringrandom.seed(0)# ⽣成区间[a, b)内的随机数def rand(a, b):return (b-a)*random.random() + a# ⽣成⼤⼩ I*J 的矩阵,默认零矩阵 (当然,亦可⽤ NumPy 提速)def makeMatrix(I, J, fill=0.0):m = []for i in range(I):m.append([fill]*J)return m# 函数 sigmoid,这⾥采⽤ tanh,因为看起来要⽐标准的 1/(1+e^-x) 漂亮些def sigmoid(x):return math.tanh(x)# 函数 sigmoid 的派⽣函数, 为了得到输出 (即:y)def dsigmoid(y):return 1.0 - y**2class NN:''' 三层反向传播神经⽹络 '''def __init__(self, ni, nh, no):# 输⼊层、隐藏层、输出层的节点(数)self.ni = ni + 1 # 增加⼀个偏差节点self.nh = nhself.no = no# 激活神经⽹络的所有节点(向量)self.ai = [1.0]*self.niself.ah = [1.0]*self.nhself.ao = [1.0]*self.no# 建⽴权重(矩阵)self.wi = makeMatrix(self.ni, self.nh)self.wo = makeMatrix(self.nh, self.no)# 设为随机值for i in range(self.ni):for j in range(self.nh):self.wi[i][j] = rand(-0.2, 0.2)for j in range(self.nh):for k in range(self.no):self.wo[j][k] = rand(-2.0, 2.0)# 最后建⽴动量因⼦(矩阵)self.ci = makeMatrix(self.ni, self.nh)self.co = makeMatrix(self.nh, self.no)def update(self, inputs):if len(inputs) != self.ni-1:raise ValueError('与输⼊层节点数不符!')# 激活输⼊层for i in range(self.ni-1):#self.ai[i] = sigmoid(inputs[i])self.ai[i] = inputs[i]# 激活隐藏层for j in range(self.nh):sum = 0.0for i in range(self.ni):sum = sum + self.ai[i] * self.wi[i][j]self.ah[j] = sigmoid(sum)# 激活输出层for k in range(self.no):sum = 0.0for j in range(self.nh):sum = sum + self.ah[j] * self.wo[j][k]self.ao[k] = sigmoid(sum)return self.ao[:]def backPropagate(self, targets, N, M):''' 反向传播 '''if len(targets) != self.no:raise ValueError('与输出层节点数不符!')# 计算输出层的误差output_deltas = [0.0] * self.nofor k in range(self.no):error = targets[k]-self.ao[k]output_deltas[k] = dsigmoid(self.ao[k]) * error# 计算隐藏层的误差hidden_deltas = [0.0] * self.nhfor j in range(self.nh):error = 0.0for k in range(self.no):error = error + output_deltas[k]*self.wo[j][k]hidden_deltas[j] = dsigmoid(self.ah[j]) * error# 更新输出层权重for j in range(self.nh):for k in range(self.no):change = output_deltas[k]*self.ah[j]self.wo[j][k] = self.wo[j][k] + N*change + M*self.co[j][k]self.co[j][k] = change#print(N*change, M*self.co[j][k])# 更新输⼊层权重for i in range(self.ni):for j in range(self.nh):change = hidden_deltas[j]*self.ai[i]self.wi[i][j] = self.wi[i][j] + N*change + M*self.ci[i][j]self.ci[i][j] = change# 计算误差error = 0.0for k in range(len(targets)):error = error + 0.5*(targets[k]-self.ao[k])**2return errordef test(self, patterns):for p in patterns:print(p[0], '->', self.update(p[0]))def weights(self):print('输⼊层权重:')for i in range(self.ni):print(self.wi[i])print()print('输出层权重:')for j in range(self.nh):print(self.wo[j])def train(self, patterns, iterations=1000, N=0.5, M=0.1):# N: 学习速率(learning rate)# M: 动量因⼦(momentum factor)for i in range(iterations):error = 0.0for p in patterns:inputs = p[0]targets = p[1]self.update(inputs)error = error + self.backPropagate(targets, N, M)if i % 100 == 0:print('误差 %-.5f' % error)def demo():# ⼀个演⽰:教神经⽹络学习逻辑异或(XOR)------------可以换成你⾃⼰的数据试试 pat = [[[0,0], [0]],[[0,1], [1]],[[1,0], [1]],[[1,1], [0]]]# 创建⼀个神经⽹络:输⼊层有两个节点、隐藏层有两个节点、输出层有⼀个节点 n = NN(2, 2, 1)# ⽤⼀些模式训练它n.train(pat)# 测试训练的成果(不要吃惊哦)n.test(pat)# 看看训练好的权重(当然可以考虑把训练好的权重持久化)#n.weights()if __name__ == '__main__':demo()更多关于Python相关内容感兴趣的读者可查看本站专题:《》、《》、《》、《》及《》希望本⽂所述对⼤家Python程序设计有所帮助。
BP神经网络的设计实例BP神经网络(Backpropagation Neural Network)是一种常用的人工神经网络方法,其具有在模式识别、分类、预测等领域具有较好的性能和应用广泛度。
本文将通过一个MATLAB编程的实例,详细介绍BP神经网络的设计过程。
首先,我们需要定义神经网络的结构。
一个BP神经网络的结构通常包括输入层、隐藏层和输出层。
输入层的节点数与输入数据的特征个数相对应,而输出层的节点数则根据具体问题的输出类别个数而定。
隐藏层的节点数一般根据经验确定,可以根据具体问题的复杂程度来调整。
接下来,我们需要初始化神经网络的参数。
这包括各个层之间的连接权重和阈值。
权重和阈值可以随机初始化,通常可以取一个较小的随机数范围,例如(-0.5,0.5)。
这里需要注意的是,随机初始化的权重和阈值如果过大或过小可能导致网络无法正常训练,进而影响预测结果。
然后,我们需要定义神经网络的激活函数。
激活函数通常是一个非线性函数,它的作用是为了引入非线性特征,增加神经网络的拟合能力。
常用的激活函数有sigmoid函数、tanh函数等。
在MATLAB中,可以通过内置函数sigmf和tansig来定义这些激活函数。
接着,我们需要定义神经网络的前向传播过程。
前向传播是指将输入数据通过神经网络,计算得到输出结果的过程。
具体操作可以按照以下步骤进行:1.输入数据进入输入层节点;2.将输入层节点的输出值乘以与隐藏层节点连接的权重矩阵,然后求和,此时得到隐藏层节点的输入值;3.将隐藏层节点的输入值通过激活函数进行激活,得到隐藏层节点的输出值;4.重复上述步骤,将隐藏层节点的输出值乘以与输出层节点连接的权重矩阵,然后求和,此时得到输出层节点的输入值;5.将输出层节点的输入值通过激活函数进行激活,得到输出层节点的输出值。
最后,我们需要定义神经网络的反向传播过程。
反向传播是为了根据输出误差来调整各个层之间的权重和阈值,使得预测结果更接近真实值。
⼈⼯智能实验报告-BP神经⽹络算法的简单实现⼈⼯神经⽹络是⼀种模仿⼈脑结构及其功能的信息处理系统,能提⾼⼈们对信息处理的智能化⽔平。
它是⼀门新兴的边缘和交叉学科,它在理论、模型、算法等⽅⾯⽐起以前有了较⼤的发展,但⾄今⽆根本性的突破,还有很多空⽩点需要努⼒探索和研究。
1⼈⼯神经⽹络研究背景神经⽹络的研究包括神经⽹络基本理论、⽹络学习算法、⽹络模型以及⽹络应⽤等⽅⾯。
其中⽐较热门的⼀个课题就是神经⽹络学习算法的研究。
近年来⼰研究出许多与神经⽹络模型相对应的神经⽹络学习算法,这些算法⼤致可以分为三类:有监督学习、⽆监督学习和增强学习。
在理论上和实际应⽤中都⽐较成熟的算法有以下三种:(1) 误差反向传播算法(Back Propagation,简称BP 算法);(2) 模拟退⽕算法;(3) 竞争学习算法。
⽬前为⽌,在训练多层前向神经⽹络的算法中,BP 算法是最有影响的算法之⼀。
但这种算法存在不少缺点,诸如收敛速度⽐较慢,或者只求得了局部极⼩点等等。
因此,近年来,国外许多专家对⽹络算法进⾏深⼊研究,提出了许多改进的⽅法。
主要有:(1) 增加动量法:在⽹络权值的调整公式中增加⼀动量项,该动量项对某⼀时刻的调整起阻尼作⽤。
它可以在误差曲⾯出现骤然起伏时,减⼩振荡的趋势,提⾼⽹络训练速度;(2) ⾃适应调节学习率:在训练中⾃适应地改变学习率,使其该⼤时增⼤,该⼩时减⼩。
使⽤动态学习率,从⽽加快算法的收敛速度;(3) 引⼊陡度因⼦:为了提⾼BP 算法的收敛速度,在权值调整进⼊误差曲⾯的平坦区时,引⼊陡度因⼦,设法压缩神经元的净输⼊,使权值调整脱离平坦区。
此外,很多国内的学者也做了不少有关⽹络算法改进⽅⾯的研究,并把改进的算法运⽤到实际中,取得了⼀定的成果:(1) 王晓敏等提出了⼀种基于改进的差分进化算法,利⽤差分进化算法的全局寻优能⼒,能够快速地得到BP 神经⽹络的权值,提⾼算法的速度;(2) 董国君等提出了⼀种基于随机退⽕机制的竞争层神经⽹络学习算法,该算法将竞争层神经⽹络的串⾏迭代模式改为随机优化模式,通过采⽤退⽕技术避免⽹络收敛到能量函数的局部极⼩点,从⽽得到全局最优值;(3) 赵青提出⼀种分层遗传算法与BP 算法相结合的前馈神经⽹络学习算法。
BP神经网络实例智能控制第一章BP神经网络基本原理一、BP神经网络基本概念1、人工神经网络人工神经网络ANN(Artificial Neural Network),是对人类大脑系统的一阶特性的一种描述。
简单地讲,它是一个数学模型,可以用电子线路来实现,也可以用计算机程序来模拟,是人工智能研究地一种方法。
近年来发展迅速并逐渐成熟的一种人工智能技术,其来源于对神经元细胞的模拟。
人工神经网络具有以下三个特点:信息分布表示,运算全局并行与局部操作,信息非线性处理。
由于这三个特点,使得由人工神经网络构成的分类器具有强大的数据拟和与泛化能力,因而广泛运用于模式识别与机器学习领域。
神经网络模式识别的过程分为两步:首先是学习过程,通过大量的训练样本,对网络进行训练,根据某种学习规则不断对连接权值进行调节,然后使网络具有某种期望的输出,这种输出就可以将训练样本正确分类到其所属类别中去,此时可以认为网络是学习到了输入数据或样本间的内在规律。
接下来是分类过程,应用前面学习过程所训练好的权值,对任意送入网络的样本进行分类。
人工神经网络模型各种各样,目前已有数十种。
他们从各个角度对生物神经系统的不同层次进行了描述和模拟。
代表模型有感知机、多层映射BP网、RBF 网络、HoPfiled模型、Boit~机等等。
虽然人工神经网络有很多模型,但按神经元的连接方式只有两种型态:没有反馈的前向网络和相互结合型网络。
前向网络是多层映射网络,每一层中的神经元只接受来自前一层神经元的信号,因此信号的传播是单方向的。
BP网络是这类网络中最典型的例子。
在相互结合型网络中,任意两个神经元都可能有连接,因此输入信号要在网络中往返传递,从某一初态开始,经过若干变化,渐渐趋于某一稳定状态或进入周期震荡等其它状态,这方面典型的网络有Hopfiled模型等。
12、BP 神经网络BP 算法是利用输出层的误差来估计输出层的直接前导层的误差,再用这个误差 估计更前一层的误差。
如此下去,就获得了所有其他各层的误差估计。
这样就形成了将输出端表现出的误差沿着与输入信号传送相反的方向逐级向网络的输入端传递的过程。
因此,人们就又将此算法称为向后传播算法,简称BP 算法。
如下图所示:算法过程为(1)设置各权值和阈值的初始值()[0]l ji w ,()[0](0,1,...,)l j l L θ=为小随机数。
(2)输入训练样本(),q q I d ,对每个样本进行(3)~(5)步。
(3)计算各个网络层的实际输出()()()(1)()()()l l l l l x f s f w x θ-==+(4)计算训练误差()()'()()()l l l j qj j j d x f s ∂=-,输出层1()'()(1)(1)1()l n l l l l j j kj k f s w +++=∂=∂∑,隐含层和输入层(5)修正权值和阈值(1)()()(1)()()[1][]([][1])l l l l l l ji ji j i ji ji w k w k x w k w k μη+-+=+∂+--(1)()()()()[1][]([][1])l l l l l j j j j j k k k k θθμηθθ++=+∂+--(6)当样本集中的所有样本都经历了(3)~(5)步后,即完成了 一个训练周期(Epoch ),计算性能指标1E=E Qq q =∑,其中()211E 2mq qj qj j d x ==-∑。
(7)如果性能指标满足精度要求,即E ε≤,那么训练结束,否则,转到(2),继续下一个训练周期。
ε是小的正数,根据实际情况而定,例如0.013、流程图根据BP 网络的算法,我们可得流程图如下。
第二章 BP 神经网络实例分析一、实例要求1、1()cos(),(0,2)f x x x π=∈取九个点来训练网络,然后得出拟合曲线。
2、2()sin(),(0,2)f x x x π=∈取适当数量训练点来训练网络,然后得出拟合曲线3、()3sin sin ,;,(10,10)x yf x y x y x y=⋅∈- 取11*11个点来训练网络,并用21*21个点测试拟合的曲面。
二、计算结果如下1、第一个函数:1()cos(),(0,2)f x x x π=∈(2)学习率为0.2,训练次数为3300时训练过程如学习曲线所示,圈圈为学习后产生的,折线为标准函数点连线。
检验过程如检验曲线所示,点序列为拟合曲线上的点,曲线为标准函数曲线。
误差曲线如右图所示。
(2)学习率为0.01,训练次数为3300时的曲线。
从函数1可以看出,学习率比较大时,曲线收敛比较快,可以比较快速达到精度要求。
但实际上,学习率比较大时(即收敛步长比较大),容易超出收敛边界,反而收敛导致不稳定,甚至发散。
2、第二个函数:2()sin(),(0,2)f x x x π=∈(1)学习率为0.2,样本点数为10,学习次数为5000时的曲线如下:(2)学习率为0.2,样本点数为30,学习次数为5000时的曲线如下:从函数2可以看出,样本点个数越多时,曲线精度越高。
但学习时间会有所增加。
3、第三个函数()3sin sin ,;,(10,10)x yf x y x y x y=⋅∈- 学习率为0.1,动量项学习率为0.05,训练次数为5000,训练样本数为11*11。
图形如下:附:程序源代码第一个和第二个函数的程序:%此BP网络为两层隐含层,每个隐含层4个节点。
输入输出各一层%输入层和输出层均采用恒等函数,隐含层采用S形函数clear all;close all;b=0.01; %精度要求a=0.2; %学习率c=2;Num=30; %训练样本数N=3300; %训练次数Nj=80; %检验样本数o0=rand(2,1); %输入层阈值o1=rand(4,1); %第一层隐含层阈值o2=rand(4,1); %第二层隐含层阈值o3=rand(1,1); %输出层阈值w1=rand(4,2); %输入信号为两个w2=rand(4,4); %第一层隐含层与第二层隐含层的权系数w3=rand(1,4); %第二层隐含层与输出层的权系数syms x y; %符号变量,用于两个输入值%fcn=cos(x); %被学习的函数fcn=abs(sin(x));x0=0:2*pi/(Num-1):2*pi; %输入的训练样本y0=0:2*pi/(Num-1):2*pi;x=x0;y=y0;X(1,:)=x0;X(2,:)=y0;yf=eval(fcn); %输出的训练样本x3=zeros(1,Num);time=0;for j=1:1:Nfor i=1:1:Num%前向计算:s1=w1*X(:,i)-o1;x1=1./(1+exp(-s1)); %第一层隐含层输出s2=w2*x1-o2;x2=1./(1+exp(-s2)); %第二层隐含层输出s3=w3*x2-o3;%x3=1./(1+exp(-s3)); %输出层输出x3(i)=s3;%反向计算:%e3=(yf(i)-x3)./(exp(s3)+2+exp(-s3)); %输出层误差e3=yf(i)-x3(i);e2=((w3)'*e3)./(exp(s2)+2+exp(-s2)); %第二层隐含层误差 e1=((w2)'*e2)./(exp(s1)+2+exp(-s1)); %第一层隐含层误差%权值和阈值修正w3=w3+a*e3*(x2)'; %权值修正w2=w2+a*e2*(x1)';w1=w1+a*e1*(X(:,i))';o3=o3-a*e3; %阈值修正o2=o2-a*e2;o1=o1-a*e1;endE(j)=0.5*((yf-x3)*(yf-x3)'); %方差time=time+1; %记录学习次数if E(j)<bbreakendend%检验m=0:2*pi/(Nj-1):2*pi;n=0:2*pi/(Nj-1):2*pi;x=m;y=n;ym=eval(fcn); %期望输出M(1,:)=x;M(2,:)=y;m3=zeros(1,Nj);for i=1:1:NjS1=w1*M(:,i)-o1;m1=1./(1+exp(-S1)); %第一层隐含层输出S2=w2*m1-o2;m2=1./(1+exp(-S2)); %第二层隐含层输出S3=w3*m2-o3;%m3(i)=1./(1+exp(-S3)); %输出层输出m3(i)=S3;endfigure(1);plot(m,ym,'g-');hold onplot(m,m3,'r.'); title('检验曲线');xlabel('x');ylabel('y=cos(x) ');figure(2);plot(x0,yf,'b-');hold onplot(x0,x3,'ro'); title('学习曲线');xlabel('x');ylabel('y=cos(x)');k=1:time;figure(3);plot(k,E); title('误差曲线');xlabel('训练次数');ylabel('误差值');第三个函数的程序%此BP网络为两层隐含层,每个隐含层10个节点。
输入输出各一层%输入层和输出层均采用恒等函数,隐含层采用S形函数clear all;close all;b=0.05; %精度要求a=0.1; %学习率c=0.05; %动量项学习率Num=11; %训练样本数N=5000; %训练次数Nj=21; %检验样本数o0=rand(2,1); %输入层阈值o1=rand(10,1); %第一层隐含层阈值o2=rand(10,1); %第二层隐含层阈值o3=rand(1,1); %输出层阈值w1=rand(10,2); %输入层与第一层隐含层的权系数w2=rand(10,10); %第一层隐含层与第二层隐含层的权系数w3=rand(1,10); %第二层隐含层与输出层的权系数o1_before=zeros(4,1); %用于存储前一次的阈值o2_before=zeros(4,1);o3_before=zeros(1,1);w1_before=zeros(4,2); %用于存储前一次的权值w2_before=zeros(4,4);w3_before=zeros(1,4);o1_next=zeros(4,1); %用于存储后一次的阈值o2_next=zeros(4,1);o3_next=zeros(1,1);w1_next=zeros(4,2); %用于存储后一次的权值w2_next=zeros(4,4);w3_next=zeros(1,4);[x0,y0]=meshgrid(-10:20/(Num-1)-0.001:10); %输入的训练样本yf=(sin(x0).*sin(y0))./(x0.*y0); %被学习的函数x3=zeros(Num,Num);time=0;E=zeros(1,N);for j=1:1:Nfor i=1:1:Numfor h=1:1:NumX=zeros(2,1);X(1,:)=x0(i,h);X(2,:)=y0(i,h);%前向计算:s1=w1*X-o1;x1=1./(1+exp(-s1)); %第一层隐含层输出s2=w2*x1-o2;x2=1./(1+exp(-s2)); %第二层隐含层输出s3=w3*x2-o3;%x3=1./(1+exp(-s3)); %输出层输出x3(i,h)=s3;%反向计算:%e3=(yf(i)-x3)./(exp(s3)+2+exp(-s3)); %输出层误差e3=yf(i)-x3(i);e2=((w3)'*e3)./(exp(s2)+2+exp(-s2)); %第二层隐含层误差 e1=((w2)'*e2)./(exp(s1)+2+exp(-s1)); %第一层隐含层误差 w3_next=w3+a*e3*(x2)'+c*(w3-w3_before); %权值修正w2_next=w2+a*e2*(x1)'+c*(w2-w2_before);w1_next=w1+a*e1*X'+c*(w1-w1_before);o3_next=o3-a*e3+c*(o3-o3_before); %阈值修正o2_next=o2-a*e2+c*(o2-o2_before);o1_next=o1-a*e1+c*(o1-o1_before);w1_before=w1;w2_before=w2;w3_before=w3;o1_before=o1;o2_before=o2;o3_before=o3;w1=w1_next;w2=w2_next;w3=w3_next;o1=o1_next;o2=o2_next;o3=o3_next;d=yf(i,h);y=x3(i,h);E(j)=E(j)+0.5*((d-y)^2); %方差endendtime=time+1; %记录学习次数if E(j)<bbreakendend%检验[m,n]=meshgrid(-10:(20/(Nj-1)-0.001):10);ym=(sin(m).*sin(n))./(m.*n);m3=zeros(Nj,Nj);for i=1:1:Njfor j=1:1:NjM=zeros(2,1);M(1,:)=m(i,j);M(2,:)=n(i,j);S1=w1*M-o1;m1=1./(1+exp(-S1)); %第一层隐含层输出S2=w2*m1-o2;m2=1./(1+exp(-S2)); %第二层隐含层输出S3=w3*m2-o3;m3(i,j)=S3; %输出层输出endendfigure(1);surf(x0,y0,yf);title('学习期望输出');grid on;figure(2);surf(x0,y0,x3);title('学习实际输出');grid on;figure(3);subplot(221);surf(m,n,ym);title('检验期望输出');grid on; subplot(222);surf(m,n,m3);title('检验实际输出');grid on;k=1:time;subplot(212);title('误差曲线');plot(k,E);。