聚类分析方法在我国空气污染区域划分中的应用
- 格式:doc
- 大小:1.32 MB
- 文档页数:32

基于聚类算法的空气质量监测与预测研究一、引言空气质量的监测与预测对于人们的生活和健康至关重要。
然而,由于空气质量受多种因素影响,如气候、污染物排放等,其变化极具复杂性和时变性。
为了更好地监测和预测空气质量,研究者不断探索各种方法和技术。
聚类算法作为一种无监督学习方法,能够将相似的数据划分为不同的类别,为空气质量监测和预测提供了一种新的思路。
二、聚类算法简介聚类算法是一种无监督学习算法,旨在将相似的数据或样本划分为不同的类别或簇。
常见的聚类算法包括K-means算法、层次聚类算法等。
这些算法通过计算样本之间的相似度或距离,将相似的样本归为同一类,以期在此基础上发现数据的内在结构和规律。
三、空气质量监测数据的聚类分析为了实现对空气质量的监测与预测,我们首先需要采集和整理大量的空气质量数据。
这些数据通常包括空气中各种污染物的含量、气象条件等。
对于这些数据,我们可以应用聚类算法进行分析。
以K-means算法为例,我们可以将监测到的空气质量数据作为输入,通过计算样本之间的相似度,将相似的样本归为一类。
聚类的结果能够反映出不同地区或时间段空气质量的差异性。
通过进一步分析聚类结果,我们可以了解不同类别的特征与规律,有助于对污染源进行定位和改善。
四、基于聚类算法的空气质量预测除了对空气质量数据进行分析,聚类算法还可以应用于空气质量预测。
通过对历史空气质量数据的聚类分析,我们可以找出相似的历史数据,根据这些数据来预测未来的空气质量。
一种常见的方法是使用K-means算法对历史数据进行聚类,然后通过分析每个类别之间的变化趋势,来预测未来的空气质量。
例如,如果某个类别的空气质量一直保持稳定,并且其他类别的空气质量逐渐改善,那么我们可以预测该地区的空气质量将继续保持良好。
这些预测结果对于政府决策者和公众来说具有重要意义,可以指导他们制定相应的空气污染治理和健康保护措施。
五、聚类算法在空气质量监测与预测中的应用案例聚类算法在空气质量监测与预测中已经得到了广泛应用,并取得了一些积极的成果。

环境保护与循环经济基于聚类分析的北京市空气质量时空分布研究金仁浩曾国静王莎(北京物资学院信息学院,北京101149)摘要:对北京市空气质量时空分布的研究已比较丰富,但仍缺少对北京市不同区域大气污染物变化相似性的研究。
在分析北京市2018年空气污染物时空分布特征的基础上,得出污染物浓度在空间上呈现出北低南高的趋势,自然因素是造成该趋势的主要原因。
分别从污染物浓度值和空气质量等级天数2个角度对北京市的大气监测站点进行聚类分析,根据2种聚类结果进行了交叉类分析,并对北京市空气质量的治理提出相应的建议。
关键词:空气质量;PM2.5;时空分布;聚类分析;北京市Abstract:Researches on spatial and temporal distribution of Beijing air quality is relatively rich,but few cover the similarity of air pollutants in Beijing different regions.Based on the analysis of the spatial and temporal distribution of Beijing air pollutants in2018,a trend of low in the north and high in the south is concluded.The natural environment is the main reasons for this trend.This paper also segments Beijing atmospheric monitoring stations in tenns of pollutant concentration value and air quality grade days respectively,and makes cross cluster analysis according to the two clustering results.By summarizing the results,this paper also puts forward corresponding suggestions on Beijing air quality control.Key words:air quality;PM25;spatial and temporal distribution;clustering analysis;Beijing中图分类号:X823文献标识码:A文章编号:1674-1021(2021)01-0068-051引言北京地区的空气质量问题一直受到中央和当地政府及居民的高度关注,北京冬季较容易出现的雾霾天气,不仅影响居民的正常出行,更对民众身体健康造成威胁。


基于聚类分析法的空气质量分析摘要:本文利用聚类分析法研究深圳市各区的空气质量问题,就主要污染物so2、no2、pm10、co和o3等进行分析,得到各污染物含量之间的关系,以及其相关性程度,从中找到污染程度相当的主要地区,结合其地理位置,从而判断其主要污染源,对同一类地区用相同的方法进行集中治理。
关键词:聚类分析空气质量集中治理污染源based on clustering analysis of air quality analysiswang shuai(college of mechanical engineering, south east university, nanjing, 211189)abstract: this paper make use of cluster analysis method to study the district shenzhen city air quality problem, the main pollutant so2, no2 and pm10 readings - which were taken, co and o3 undertake an analysis, get the relationship between the content of each pollutant, and the correlation degree, find the main area is polluted, combined with its geographical position to judge the main pollution sources, to the same kind of area with the same method for centralized management.keywords: clustering analysis; air quality; centralized management; pollution sources;中图分类号:q938.1+4文献标识码: a 文章编号:由于空气的扩散作用,导致对空气环境的治理有一定的盲目性,不能做到对症下药,导致效果不佳。

中国各城市空气质量聚类和判别分析摘要中国经济的快速增长导致环境污染不断加重,其中空气污染与人类的健康密切相关。
结合全国74个城市的空气污染物浓度数据对各城市进行聚类分析,分类方法包括等价关系法和Kmeans分析两种方法。
结果表明,海口是全国空气质量最好的城市,石家庄和邢台是全国空气质量最差的城市,而武汉、成都和乌鲁木齐的空气质量与北京最为接近。
关键词聚类分析空气质量等价关系Kmeans1. 介绍随着中国经济的高速发展和工业化、城市化进程的加快,能源的消耗速度也不断提高。
中国的工业发展大量依赖煤炭、石油等化石燃料,其燃烧产生的废气严重污染空气,导致中国各地区空气质量不断下降。
90年代初期,中国的500个城市当中,达到国家空气质量I级标准的仅占1%;此外,近年来的数据显示,暴露于未达标空气中的城市人口占统计城市人口的三分之二[1]。
城市的空气污染对人体健康构成极大威胁,研究表明,即便暴露于污染物密度较低的空气中也会提高慢性呼吸系统的发病率以及多种癌症的患病概率[2]。
因此,有必要对全国各大城市的空气质量进行数据收集和分析,确定不同城市的污染程度及相互之间的关系,为相关部门制定政策提供有力的数据支撑。
城市的空气污染程度主要受经济发展水平影响,但二者不是呈简单的倒U型曲线关系,不同的污染物与经济水平之间有不同的关系[3],因此需要对各种污染物进行综合分析和评价。
而目前对环境进行综合评价的方法包括模糊数学法、距离判别法和物元分析法[4],本文即采取其中的模糊数学法对全国74个主要城市的空气污染数据进行聚类和判别分析,以研究目前中国各大城市的空气污染水平和特点。
2. 原始数据及聚类分析方法本文所用到的城市空气污染数据来自环保部相关统计数据[5],参见表1。
为了便于分析,选取空气污染指标中量纲相同的三个指标进行考察,分别是SO2浓度、NO2浓度和PM2.5浓度。
采用两种聚类分析方法对这74个城市进行分类,分别是等价关系法和Kmeans分类方法。

对我国主要城市空气质量的聚类分析摘要本文应用多元统计分析中聚类分析理论,使用SPSS17.0软件和spss13.0对我国主要城市的空气质量进行了聚类分析,将31个城市按照空气质量的类型分为了四类。
在此基础上,对这些城市的空气质量归属进行了回报判别,结果令人满意。
1引言大气环境质量评价是环境质量评价的一项重要内容。
对空气环境质量的充分认识对我国社会的可持续发展具有现实的指导意义。
在多元统计分析中,常常使用聚类分析和判别分析来解决样本的分类问题。
在事先不知道应将样品或指标分为几类、怎么分类的情况下,可以使用聚类分析根据样本或指标的相似程度,将样本或指标归组分类。
聚类分析的基本思想是:在样品之间定义距离,在变量之间定义相似系数,距离或相似系数代表样品或者变量之间的相似程度。
按相似程度的大小,将样品逐一归类,关系密切的类聚集到一个小的分类单位,然后逐步扩大,使得关系疏远的聚合到一个大的分类单位,直到所有的样品都聚集完毕,形成一个表示亲疏关系的谱系图,依次按照某些要求对样品进行分类。
一般地,根据分类对象的不同,聚类分析可以分为Q型和R型两大类。
Q型聚类分析是对样本进行分类处理,R型聚类分析是对变量进行分类处理。
[2]判别分析也是一种数据的分析方法。
在事先已经建立了样品分类,需要将新样本归入到已知分类的样本组中时,就可以使用判别分析。
本文以4种空气质量指标为变量,采用系统聚类分析Ward方法(离差平方和法),对我国31个主要城市的空气质量类型进行了聚类。
并在此基础上,对这些城市的空气质量归属进行了回报判别。
从结果来看,比较圆满地完成了预定目标。
2聚类分析和主要城市空气质量类型的划分2.1指标的选取本文选取了全国31个城市的2008年的四项空气质量指标作为对空气质量类型划分的依据,所选数据全部来自《中国统计年鉴》,具体见下表。
主要城市空气质量指标 (2008年)单位:毫克/立方米城市空气质量达到及可吸入颗粒物二氧化硫二氧化氮好于二级的天数(天)北京0.123 0.036 0.049 274 天津0.088 0.061 0.041 322 石家庄0.116 0.046 0.031 301 太原0.094 0.073 0.021 303 呼和浩特0.070 0.049 0.045 340 沈阳0.118 0.059 0.037 323 长春0.096 0.030 0.038 342 哈尔滨0.102 0.043 0.055 308 上海0.084 0.051 0.056 328 南京0.098 0.054 0.053 322 杭州0.110 0.052 0.053 301 合肥0.134 0.022 0.025 257 福州0.071 0.023 0.046 354 南昌0.083 0.050 0.036 344 济南0.126 0.052 0.022 295 郑州0.094 0.060 0.047 325 武汉0.113 0.051 0.054 294 长沙0.097 0.053 0.043 329广州0.071 0.046 0.056 345 南宁0.056 0.040 0.044 352 海口0.043 0.009 0.017 366 重庆0.106 0.063 0.043 297 成都0.111 0.049 0.052 319 贵阳0.082 0.064 0.023 347 昆明0.067 0.051 0.039 366 拉萨0.051 0.005 0.024 353 西安0.113 0.050 0.044 301 兰州0.132 0.070 0.054 268 西宁0.118 0.029 0.030 296 银川0.084 0.049 0.021 330 乌鲁木齐0.145 0.105 0.065 261表2Rescaled Distance Cluster CombineC A S E 0 5 10 15 20 25Label Num +---------+---------+---------+---------+---------+11 -+27 -+3 -+4 -+15 -+29 -+17 -+-----+22 -+ |8 -+ |9 -+ +-------------+18 -+ | |30 -+ | |2 -+-----+ |10 -+ |6 -+ +---------------------------+16 -+ | |23 -+ | |21 -+---+ | |25 -+ | | |13 -+ +---------------+ |26 -+ | |20 -+---+ |5 -+ |7 -+ |14 -+ |19 -+ |24 -+ |12 -+ |31 -+-----------------------------------------------+1 -+28 -+表 3类型城市第一类合肥,兰州,太原,呼和浩特,郑州,银川,长沙,上海,成都第二类南京,广州,乌鲁木齐,石家庄,杭州,武汉,长春,贵阳第三类拉萨,重庆,南昌,西安,海口,哈尔滨,沈阳,济南,南宁,昆明第四类天津,西宁,福州,北京从图1,2中可以看出,全国31个城市可以分为四种空气质量类型,如表3所示。

我国主要城市空气质量面板数据聚类分析作者:罗国梁来源:《现代商贸工业》2014年第07期摘要:我国的空气质量问题牵动着千千万万老百姓的心,为了深入了解全国31个重要城市的空气质量和空气污染方面的差异,根据地方的不同,制定不同的污染防范和治理措施,了解各地的环保态势和水平,运用面板数据的聚类分析方法对全国31个省会城市的从2006到2012年的空气质量达到及好于二级的天数,以及可吸入颗粒物这两个指标的地区差异进行实证分析。
关键词:城市空气质量;面板数据;聚类分析中图分类号:F2文献标识码:A文章编号:16723198(2014)070008021引言自从改革开发以来,我国的经济发展取得了显著的进步。
但是,经济的发展也带来了一系列隐患,其中最重要的一条就是环境问题。
目前,我国乃至全世界的环境污染问题都十分的严峻。
最近,环境污染重最引人关注的一项就是空气质量问题。
PM2.5、雾霾等等已经成为经常挂在嘴边的话语。
今年我国空气质量标准的重新修订,特别把PM25纳入监测内容,并已经开始在多个试点城市开始运作,加强了政策实施的力度和强度,体现了国家对空气污染的高度关注。
尽管我国政府制定并不断完善了法律法规体系,使环境保护取得了一定的进展。
但环境形势非常严峻的状况仍然没有太多的改变,发达国家用了百年时间完成了工业化,相比之下我国完成现代化的时间非常之短,这也不可避免的引起环境污染在我国近20多年来集中出现,呈现复合型、结构型、压缩型的特点。
表现为许多城市空气污染严重,雾霾出现频繁,主要污染物的大量排放量超过了环境承载能力,等诸多大气环境问题。
由此我们可以认识到,污染的防治不仅仅是一个环境问题而且是重大的经济和政策问题,是一个关系到国计民生的问题。
为了深入的了解全国各大城市空气污染的差异,更好的把握防治空气污染的力度,本文应用单指标面板数据的聚类分析方法对全国31个主要城市从2006到2012年的空气质量达到及好于二级的天数,以及可吸入颗粒物这两个指标的地区差异进行实证分析。
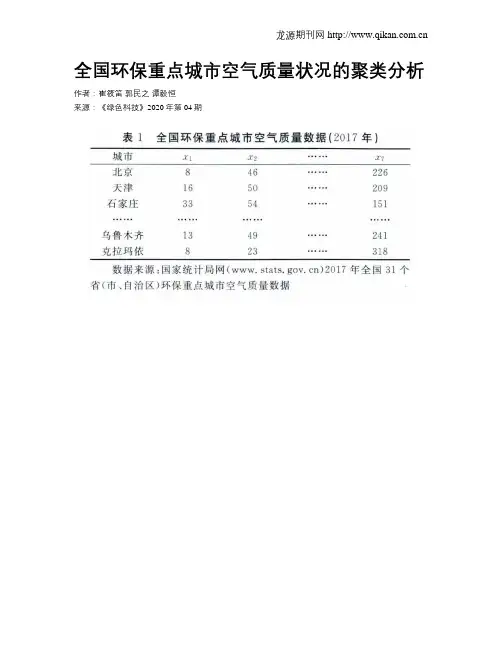
全国环保重点城市空气质量状况的聚类分析作者:崔筱笛郭民之谭毅恒来源:《绿色科技》2020年第04期摘要:利用全国113个环保重点城市2017年的空气质量数据进行了聚类分析,以期对全国城市空气质量分布状况有一个总体性的直观把握。
在综合考虑聚类个数和类间区分度的情况下把这113个城市聚为9类,按空气质量达到及好于二级的天数这一指标进行排序并将空气质量最优、中等和最差三类城市在中国地图上进行标注。
结果表明:这些环保重点城市空气质量分布状况具有明显的区城性,空气污染严重城市主要集中在华北和西北地区,南方城市的空气质量整体好于北方。
最后分析了各类城市空气污染的成因和地域特征并时如何改善城市空气质量提出了治理建议,以供参考。
关键词:城市空气质量;聚类分析;区城特征;治理建议中图分类号:0212.4 文献标识码:A 文章编号:1674-9944(2020)04-0001-041 引言空气质量的好坏与人们的健康水平息息相关。
随着社会经济的发展,我国城镇化与工业化的步伐不断加快,空气污染问题日益凸显,雾霾天气越来越常见,已经对社会大众的身体健康和生产生活带来严重的影响。
到目前为止,已经有不少学者对我国城市空气质量的现状及相关问题进行过研究。
余晓美等[1]对全国31个环保重点城市空气质量进行动态特征分析,选取2014~2016年共36个月空气质量指数(AQI)作变化速度曲线和平均变化速度曲线图,具有相似AQI曲线的城市聚为一类,空气质量呈现“三阶段”季节性周期,区域差异明显,且发现空气质量改善过程呈现“类马太效应”;宋加梅[2]对55个主要城市的空气质量数据进行因子分析,根据排名对城市进行分类,总结这些城市空气污染的现状并提出改善建议;姜磊等[3]运用空间滞后模型探究城市化发展与空气质量之间的关系,发现空气污染存在明显的空间溢出效应。
本文根据六项国家空气质量主要监测指标,对2017年全国113个环保重点城市空气质量进行聚类分析,研究这些环保重点城市空气质量类属现状、污染分布区域特征和影响因素,并提出治理对策和建议。

系统聚类方法对大气污染地区的划分高胜云;王拥兵;张丽霞【摘要】当前国内经济快速发展的同时带来了环境质量下降等问题,地区间发展落脚点不同,受到的大气污染程度不同.从主要的大气污染监控物PM2.5、PM10、一氧化碳、二氧化碳、臭氧和二氧化硫6个方面构建大气污染地区分类的聚类评价指标体系,建立地区分类的聚类分析模型.并以北京、上海、海口、西安、佛山、酒泉、拉萨和重庆8个城市为例,应用评价指标的数据进行聚类分析,根据聚类结果提出具有针对性的环境保护建议.【期刊名称】《西昌学院学报(自然科学版)》【年(卷),期】2019(033)002【总页数】4页(P70-73)【关键词】大气污染;地区分类;系统聚类分析;环境保护【作者】高胜云;王拥兵;张丽霞【作者单位】安庆师范大学数学与计算科学学院,安徽安庆 246133;安庆师范大学数学与计算科学学院,安徽安庆 246133;安庆师范大学数学与计算科学学院,安徽安庆 246133【正文语种】中文【中图分类】X8230 引言随着第三次工业革命的快速发展,环境保护与大气污染成为了热门话题[1]。
在我国不同地区的发展速度和发展重点不相同,大气污染物含量造成的环境影响存在差异。
从国内的大气污染现状来看,国内各城市的大气污染呈现较为明显的复合型污染特征[2]。
目前全国各地环境监测站的常规监测就有二氧化硫、氮氧化物、一氧化碳、可吸入颗粒物和细颗粒物等物质[3]。
严峻的环境污染现状已经逐渐成为制约地区经济可持续发展的主要障碍,过度排放的工业“三废”、生活垃圾、汽车尾气和化肥农药等污染物使得环境日趋恶化。
聚类分析方法是统计学理论中重要的方法之一,是按照某一标准来对样本点进行分类,从而能够对样本数据进行分析判断,提供针对性的意见和决策。
文献[4-6]中举例分析了多种聚类方法,并对它们的优缺点进行比较,当样本的性质不同时,不同的聚类方法对聚类结果产生的影响不同。
为分析大气污染物的地区划分问题,需要提取各地区常规监测物质数据。

聚类分析方法在我国空气污染区域划分中的应用安徽大学笪婷婷、邹委员、武锦摘要随着我国工业化进一步的发展,人们的生活也进一步的提高。
伴随着经济的发展,环境也受到了一定的影响,国家也相应的提出了人与自然和谐相处的可持续发展战略。
本文基于国家的政策,考虑工业化过程中城市空气的污染情况,提出相应的合理建议,从而使工业化过程中我们的环境也能受到更好的保护!聚类分析是目前最有前景的数据分析方法之一,它不仅能作为一个独立的工具来获得数据分布的情况,观察每一个簇的特点,还能集中地对某些特定的簇作进一步的分析。
对空气污染区域划分的聚类分析,不仅能合理的分析我国各地区空气污染的情况,还可以对我们工业化发展的伟大蓝图提出我们瀚渺的建议,维护我们广大城市居民的切身利益!本文首先对几种聚类方法进行了介绍和比较,然后在对我国空气污染现状分析中,运用了系统聚类分析方法。
首先,我们采用了组内连接聚类分析方法对我国的空气污染区域按照污染程度的不同进行了划分;其次,我们又采用了中位数聚类分析法对我国的空气污染区域按照不同地区的废气处理情况进行了划分;最后我们又采用了质心聚类分析法对各污染区域按年度的不同进行划分。
我们用所选的三种数据进行聚类,产生的七个类是在整体上是一致的。
这就表明,空气污染程度与废气处理的力度是成正相关的。
为了说明系统聚类分析方法在我国空气污染区域划分中的合理性,我们又采用了k-means方法进行聚类,所得的聚类结果与运用系统聚类法的结果相似。
从而进一步说明分类的合理性。
根据聚类结果,我们提出了一些相关的防治空气污染的建议。
相关部门应该按照污染地区的分类有针对性的制定相关策略,因地制宜,对污染程度相近的地区采用合理的方式进行治理。
关键词:聚类方法;系统聚类法;中位数聚类分析;组内连接聚类分析;质心聚类分析The Application of Cluster Method in Air PollutionRegional Division of Our CountryAbstractWith the further development of the industry in our country, people have undergone general improvement. However, the environment is accordingly suffering some attack from the progress of economy. The government has launched the strategy of sustainable development in order to build harmonious relationship between human and nature. Based on the policy of our government, taking the pollution in urban area into consideration, our article gives some corresponding advices to protect our environment in the industrialization.Cluster method is one of the most promising methods in data analysis. Not only can it act as an independent tool to obtain the information of data distribution and observation of the characteristics of each cluster, but also do further analysis for some particular clusters. Using the cluster method in the analysis of division for polluted urban area, we can do reasonable analysis and get acquaintance of condition of air pollution in different places. Our trivial recommendations will be come up for the blue sky of our industry development and safeguarding the vital interests of the city dwellers.At the beginning of this paper, more than one kind of cluster method will be introduced and compared in this paper. Furthermore, systematic cluster methods will be applied in the division of the current air pollution circumstances. Firstly, we use team linked cluster method to divide regions according to the pollution degree. Secondly, we use median cluster method in accordance with the pollutant disposal of different areas. Lastly, we use centroid cluster method by judging the annual condition of air pollution. We cluster these three kinds of data, finding that seven categories we produce are accordant on the whole, which suggests that pollution degree is positively related to the strength we depose.To illustrate the rationality of systematic cluster method applied in air pollution regional division, we utilize k-means to cluster. To our happiness, the result we obtain is quite similar to that of systematic cluster method, which shows the rationality.According to the clustering results, we put forward some relevant suggestions for the prevention and control of air pollution. Relevant departments should formulate relevant strategies based on the classification of pollution areas, and take suitable measures for local conditions. Also we should depose the pollution in similar levels in a reasonable way. Keywords: : cluster system clustering method; median cluster analysis; connection cluster analysis within the group; a centroid cluster analysis一.研究背景我国经济的快速增长,工业化、城市化的发展使得GDP年增长率达到8%~9%。

系统聚类分析法在大气污染中的应用大气污染是目前全球所面临的严峻问题之一。
为了更好地了解大气污染的来源和变化趋势,科学家们使用了多种方法进行研究和分析。
其中,系统聚类分析法被广泛应用于大气污染的研究中,以帮助我们更好地理解和应对这一问题。
系统聚类分析法是一种将个体或样本根据其特征进行分类的方法。
它通过比较不同个体之间的相似性或差异性来识别和分类样本。
在大气污染的研究中,系统聚类分析法可以帮助我们找到不同地点或时间点上的空气质量类似的群体,从而更好地了解大气污染的空间和时间分布规律。
首先,系统聚类分析法可以通过对大气污染指标进行聚类,揭示不同污染物之间的相互关系。
例如,我们可以将不同地点或时间点上的颗粒物浓度、二氧化硫浓度、臭氧浓度等大气污染指标进行聚类分析,找出它们之间的相似性和差异性。
这有助于我们确定不同污染物之间的关联性,理解它们的来源和转化过程,从而采取相应的控制措施。
其次,系统聚类分析法还可以帮助我们划分大气污染的空间和时间群体。
通过聚类分析,我们可以将相似的地点或时间点划分到同一类别中,从而更好地研究这些类别的污染特征和影响因素。
例如,我们可以将城市内部不同区域的空气质量进行聚类,发现相似的污染源和控制需求。
同时,聚类分析还可以揭示季节性和年际变化等时间尺度上的污染模式,为相关政策的制定和实施提供科学依据。
此外,系统聚类分析法还可以帮助我们识别和比较不同污染源的贡献程度。
通过将大气污染数据进行聚类分析,我们可以确定不同污染源对污染物浓度的影响,并评估它们的贡献程度。
这对于制定和优化源控制策略非常关键,有助于减少大气污染的程度和影响。
综上所述,系统聚类分析法在大气污染研究中的应用非常广泛。
它通过对大气污染指标的聚类分析,帮助我们了解不同污染物之间的关系、划分空间和时间群体,以及评估不同污染源的贡献程度。
这为制定和优化大气污染防治策略提供了重要的科学依据。
随着技术的不断进步,系统聚类分析法在大气污染研究中的应用还将进一步发展壮大,为我们更好地应对大气污染问题提供更有力的支持。
聚类算法在空气污染预测中的应用研究一、引言空气污染是当今社会面临的重要问题之一,它已经成为威胁公众健康和环境品质的主要因素。
随着技术的发展和科技水平的提高,利用机器学习算法和大数据分析技术对污染进行预测和控制已经成为一种有效的方法。
聚类算法作为一种常用的机器学习算法,在空气污染的预测中得到了广泛的应用。
二、聚类算法概述聚类算法是一种无监督学习算法,在数据挖掘、图像分析、模式识别等领域中得到了广泛的应用。
它是一种根据相似度或距离度量,在数据集中找到相似样本并将它们归为一类的算法。
聚类算法可以分为基于层次的聚类算法和基于划分的聚类算法两类。
基于层次的聚类算法通常分为自底向上和自顶向下两种。
自底向上的层次聚类算法从每个数据点开始,通过逐步合并相邻的簇来构建完整的聚类树。
自顶向下的层次聚类算法从整个数据集开始,逐步地分裂簇,直到每个簇只包含一个数据点。
基于划分的聚类算法通常基于中心点、密度或近邻的概念来进行聚类。
其中最常见的聚类算法是K-means算法,它将数据点划分为K个簇,以最小化簇内的方差和簇间距离。
三、聚类算法在空气污染预测中的应用1. 聚类算法用于空气质量指数的预测空气质量指数(AQI)是一种标准化的系统,用于描述空气质量的级别和健康影响程度。
聚类算法可以帮助识别关键的环境因素并将它们归为一类,以预测AQI的级别和趋势。
例如,一项针对北京市AQI的聚类分析研究表明,温度和湿度是预测AQI的最重要因素之一,而风速、降雨和大气压力等因素则次之。
2. 聚类算法用于评估空气污染源聚类算法也可以用于评估污染源。
例如,一项对上海市大气污染物的来源分析研究表明,聚类算法可以将大气污染源划分为城市污染、工业污染、机动车尾气和天然源等四类。
这些信息可以帮助制定针对性的污染控制方案。
3. 聚类算法用于预测空气污染事件聚类算法还可以用于预测空气污染事件。
例如,针对湖北省武汉市PM2.5浓度的聚类分析研究表明,经过聚类处理的数据可以预测PM2.5浓度的空间分布和趋势,从而提前预警污染事件。
我国主要城市空气质量面板数据聚类分析我国的空气质量问题牵动着千千万万老百姓的心,为了深入了解全国31个重要城市的空气质量和空气污染方面的差异,根据地方的不同,制定不同的污染防范和治理措施,了解各地的环保态势和水平,运用面板数据的聚类分析方法对全国31个省会城市的从2006到2012年的空气质量达到及好于二级的天数,以及可吸入颗粒物这两个指标的地区差异进行实证分析。
标签:城市空气质量;面板数据;聚类分析1引言自从改革开发以来,我国的经济发展取得了显著的进步。
但是,经济的发展也带来了一系列隐患,其中最重要的一条就是环境问题。
目前,我国乃至全世界的环境污染问题都十分的严峻。
最近,环境污染重最引人关注的一项就是空气质量问题。
PM2.5、雾霾等等已经成为经常挂在嘴边的话语。
今年我国空气质量标准的重新修订,特别把PM25纳入监测内容,并已经开始在多个试点城市开始运作,加强了政策实施的力度和强度,体现了国家对空气污染的高度关注。
尽管我国政府制定并不断完善了法律法规体系,使环境保护取得了一定的进展。
但环境形势非常严峻的状况仍然没有太多的改变,发达国家用了百年时间完成了工业化,相比之下我国完成现代化的时间非常之短,这也不可避免的引起环境污染在我国近20多年来集中出现,呈现复合型、结构型、压缩型的特点。
表现为许多城市空气污染严重,雾霾出现频繁,主要污染物的大量排放量超过了环境承载能力,等诸多大气环境问题。
由此我们可以认识到,污染的防治不仅仅是一个环境问题而且是重大的经济和政策问题,是一个关系到国计民生的问题。
为了深入的了解全国各大城市空气污染的差异,更好的把握防治空气污染的力度,本文应用单指标面板数据的聚类分析方法对全国31个主要城市从2006到2012年的空气质量达到及好于二级的天数,以及可吸入颗粒物这两个指标的地区差异进行实证分析。
2单指标面板数据的聚类分析计量经济学模型在分析经济问题的时候只是利用了时间序列或者截面数据中的二维数据的信息,例如使用一个或者若干经济指标的时间序列建模或不同样本的横截面数据建模。
监测数据的聚类分析及其在环境监测中的应用近年来,全球的环境问题日益凸显,环境监测的重要性也随之日益增加。
环境监测不仅要求数据的准确性和可靠性,同时有时还需要将环境监测数据进行一定的聚类分析,以便更好地了解环境状况,发现环境问题并及时解决。
本文将对监测数据的聚类分析方法进行简要介绍,并探讨其在环境监测中的应用。
一、监测数据的聚类分析方法1. 基本概念聚类分析是一种数据分析方法,主要用于将数据集中的对象分成不同的组。
聚类算法可以划分为基于距离的聚类和基于密度的聚类。
基于距离的聚类方法主要考虑元素之间的距离,如K-means算法和层次聚类算法;基于密度的聚类方法则基于数据点之间的密度关系,如DBSCAN算法。
2. 常用算法(1) K-means算法K-means算法是一种基于距离的聚类算法,它将数据点分成K个类,并且每个数据点只属于其中一个类。
K-means算法通过不断迭代来优化聚类结果,直到满足一定的停止条件。
该算法通常会依赖于初始随机聚类中心的选取,因此对于不同的数据和初始点的选取结果也可能存在显著差异。
(2) 层次聚类算法层次聚类算法采用自底向上或自顶向下的方法建立一个层次结构,通常可以用树状图表示。
层次聚类算法又可分为凝聚型和分离型两种。
凝聚型聚类从单独的数据点开始构建簇,不断合并最相似的两个簇,而分离型聚类则先将所有数据点划分为一个大簇,然后通过分裂不相似的小簇来构建层次结构。
(3) DBSCAN算法DBSCAN算法是一种基于密度的聚类算法,它将图中密度相同或更高的点划分到同一簇中,并将低密度区域视为噪声。
相比于基于距离的聚类算法,DBSCAN算法可以适应不规则形状的分布。
此外,它还可以自动确定聚类簇的数量,避免K-means算法需要预先确定聚类数的问题。
二、聚类分析在环境监测中的应用1. 空气污染监测空气污染是环境监测中一个重要的领域。
在复杂的城市环境中,空气污染物的类型和浓度十分复杂,因此需要对空气质量监测的数据进行聚类分析,以此来快速定位并解决空气质量问题。
基于K-means聚类分析法的肇庆市干季PM2.5污染天气分型研究基于K-means聚类分析法的肇庆市干季PM2.5污染天气分型研究摘要:随着环境污染的日益加重,空气质量成为了人们关注的重要议题之一。
本研究以广东省肇庆市为例,利用K-means聚类分析法对肇庆市干季期间的PM2.5污染天气进行了分型研究。
通过统计和分析肇庆市2019年至2021年干季期间的气象和空气质量监测数据,本研究将PM2.5污染天气划分为四类,并对每一类进行了详细分析和讨论。
结果表明,肇庆市干季期间的PM2.5污染天气主要呈现为稳定型、秋霾型、冬霾型和局部污染型,不同类型的污染天气与气象因素和大气环流有着密切的关系。
本研究为肇庆市及其他类似地区采取有效的空气污染治理措施提供了科学依据。
关键词:K-means聚类分析法;肇庆市;干季;PM2.5;空气污染第一章引言1.1 研究背景和意义近年来,随着工业化和城市化的快速发展,空气质量问题引起了社会的广泛关注。
尤其是细颗粒物(PM2.5)的污染对人们的健康和生活质量产生了严重影响。
肇庆市作为广东省内重要的工商业城市,面临着严峻的空气污染问题。
研究肇庆市干季期间PM2.5污染天气的分型,对于制定针对性的污染防治措施具有重要意义。
1.2 研究目的和内容本研究旨在通过K-means聚类分析法对肇庆市干季期间的PM2.5污染天气进行分类和分析,以揭示不同类型的污染天气背后的气象因素和大气环流特征,为肇庆市及相关地区的空气污染治理提供科学依据。
第二章数据与方法2.1 数据来源本研究所使用的数据主要包括肇庆市2019年至2021年干季期间的气象数据和空气质量监测数据。
气象数据包括温度、湿度、风速、风向等参数,空气质量监测数据包括PM2.5浓度等指标。
2.2 方法介绍本研究采用K-means聚类分析法对肇庆市干季期间的PM2.5污染天气进行分类。
K-means聚类是一种常用的聚类分析方法,它将样本数据划分为K个类别,使得同一类别内的样本相似度较高,不同类别之间的样本相似度较低。
空气污染监测数据挖掘和预测方法研究近年来,随着工业化的发展和城市化进程的加速,空气污染问题越来越受到人们的关注。
为了更好地掌握和解决空气污染问题,空气污染监测数据的挖掘和预测方法研究愈来愈受到广泛关注。
一、空气污染监测数据挖掘技术监测数据挖掘技术是针对空气污染监测数据,运用机器学习、人工智能等技术手段,通过对大数据的挖掘和分析,为环保部门提供更加科学合理的决策依据。
这种技术可以用于空气质量预测、环境监测、生态环境评估等领域。
在挖掘空气污染监测数据方面,有以下几种技术:1、聚类分析聚类分析是一种非监督学习方法,即没有先验知识的情况下,通过对样本的聚类来发现其规律性和特征。
对于空气监测数据,可以利用聚类分析来挖掘处于同一区域或者同一环保站点的监测数据,进而分析不同地点之间的差异和规律,帮助决策者制定相应的环境保护政策。
2、分类分析分类分析是一种有监督学习方法,即利用已有标注的监测数据进行分析预测。
对于空气监测数据,可以利用分类分析方法将监测数据进行分类,比如可以针对不同季节、不同区域、不同监测站点进行分类,以此来找出监测数据之间的相关性和特征,为预测和规划提供参考。
3、关联分析关联分析是通过挖掘数据集中项与项之间的关系,寻找最有可能同时出现的频繁项集合,从而发现数据集中的相关性等本质特征的一种方法。
应用到空气污染监测数据中,可以通过关联分析方法挖掘不同污染物质之间的关系,以此来推测出一个污染物质是否会影响到另一个污染物质的含量,进而掌握污染物质在空气中的传播情况。
二、空气污染预测技术空气污染监测是基于数据挖掘技术得到的结果,预测是基于现有污染数据来预估未来污染发展趋势。
这里我们谈论一下空气污染预测的方法中,重要的颗粒物PM2.5污染物预测。
PM2.5是指大气中直径小于或等于2.5微米的颗粒物,其危害性最高,但预测比气体污染预测要难得多。
当前,预测PM2.5污染物的方法主要有以下两种:1、统计模型法统计模型法是基于现有数据,使用统计方法来建立预测模型,预测目标值。
聚类分析方法在我国空气污染区域划分中的应用安徽大学笪婷婷、邹委员、武锦摘要随着我国工业化进一步的发展,人们的生活也进一步的提高。
伴随着经济的发展,环境也受到了一定的影响,国家也相应的提出了人与自然和谐相处的可持续发展战略。
本文基于国家的政策,考虑工业化过程中城市空气的污染情况,提出相应的合理建议,从而使工业化过程中我们的环境也能受到更好的保护!聚类分析是目前最有前景的数据分析方法之一,它不仅能作为一个独立的工具来获得数据分布的情况,观察每一个簇的特点,还能集中地对某些特定的簇作进一步的分析。
对空气污染区域划分的聚类分析,不仅能合理的分析我国各地区空气污染的情况,还可以对我们工业化发展的伟大蓝图提出我们瀚渺的建议,维护我们广大城市居民的切身利益!本文首先对几种聚类方法进行了介绍和比较,然后在对我国空气污染现状分析中,运用了系统聚类分析方法。
首先,我们采用了组内连接聚类分析方法对我国的空气污染区域按照污染程度的不同进行了划分;其次,我们又采用了中位数聚类分析法对我国的空气污染区域按照不同地区的废气处理情况进行了划分;最后我们又采用了质心聚类分析法对各污染区域按年度的不同进行划分。
我们用所选的三种数据进行聚类,产生的七个类是在整体上是一致的。
这就表明,空气污染程度与废气处理的力度是成正相关的。
为了说明系统聚类分析方法在我国空气污染区域划分中的合理性,我们又采用了k-means方法进行聚类,所得的聚类结果与运用系统聚类法的结果相似。
从而进一步说明分类的合理性。
根据聚类结果,我们提出了一些相关的防治空气污染的建议。
相关部门应该按照污染地区的分类有针对性的制定相关策略,因地制宜,对污染程度相近的地区采用合理的方式进行治理。
关键词:聚类方法;系统聚类法;中位数聚类分析;组内连接聚类分析;质心聚类分析The Application of Cluster Method in Air Pollution RegionalDivision of Our CountryAbstractWith the further development of the industry in our country, people have undergone general improvement. However, the environment is accordingly suffering some attack from the progress of economy. The government has launched the strategy of sustainable development in order to build harmonious relationship between human and nature. Based on the policy of our government, taking the pollution in urban area into consideration, our article gives some corresponding advices to protect our environment in the industrialization.Cluster method is one of the most promising methods in data analysis. Not only can it act as an independent tool to obtain the information of data distribution and observation of the characteristics of each cluster, but also do further analysis for some particular clusters. Using the cluster method in the analysis of division for polluted urban area, we can do reasonable analysis and get acquaintance of condition of air pollution in different places. Our trivial recommendations will be come up for the blue sky of our industry development and safeguarding the vital interests of the city dwellers.At the beginning of this paper, more than one kind of cluster method will be introduced and compared in this paper. Furthermore, systematic cluster methods will be applied in the division of the current air pollution circumstances. Firstly, we use team linked cluster method to divide regions according to the pollution degree. Secondly, we use median cluster method in accordance with the pollutant disposal of different areas. Lastly, we use centroid cluster method by judging the annual condition of air pollution. We cluster these three kinds of data, finding that seven categories we produce are accordant on the whole, which suggests that pollution degree is positively related to the strength we depose.To illustrate the rationality of systematic cluster method applied in air pollution regional division, we utilize k-means to cluster. To our happiness, the result we obtain is quite similar to that of systematic cluster method, which shows the rationality.According to the clustering results, we put forward some relevant suggestions for the prevention and control of air pollution. Relevant departments should formulate relevant strategies based on the classification of pollution areas, and take suitable measures for local conditions. Also we should depose the pollution in similar levels in a reasonable way.Keywords: : cluster system clustering method; median cluster analysis; connection cluster analysis within the group; a centroid cluster analysis一.研究背景我国经济的快速增长,工业化、城市化的发展使得GDP年增长率达到8%~9%。
改革开放以来,我国的城市化进程加快,城市人口比例从1978年的18%增加到2000年的34%,这一时期的增长速度是世界平均增长速度的3倍。
20世纪末,经济的剧增使得我国成为世界上第二大能源消费国,能源的消耗已成为我国空气污染的主要来源。
我国的总能源消耗已经从1978年的571万吨标准煤增加到2002年的15亿吨标准煤,其中作为主要能源的燃煤占总能源消耗的60%以上。
燃煤是空气污染物产生的重要原因。
此外,随着汽车消费量的快速增加,燃油消耗年平均增长达6%,使得空气的污染物浓度不断上升。
我国的空气污染状况不容乐观。
(一)导致空气污染的原因造成我国空气污染的原因是非常多的,但纵观所有的污染成因,以下原因应该是最具有普遍性的。
城市人口爆炸性增长。
城市强大的经济活力,丰富的物质文化条件和就业机会,对农村人口有具大的吸引力,进入20世纪以来,人口城市化加速发展,城市人口急剧增长。
我国城市化虽然起步较晚,但城市人口增加速度却十分惊人,例如1980年我国城市人口有 1.3亿,占全国总人数的13.6%;1990年增加到近3亿,占全国总人口的 26.2%。
城市个数由1983年的289个,到1993年增到570个,几乎增加了一倍,而城市人口大于100万的大型城市就有42个之多。
我国大城市人口密度平均每平方公里 1万人以上,是郊区人口平均密度的22-96倍。
城市中人口数量巨大的工矿企业,单位面积上具有高投资、高能耗的特点。
由于城市处于高密度、超负荷运转状态,因此城市空气、水、土地及一切基础工程设施都承受着超载的负担,引起了一系列环境问题。
城市空气污染、缺电、缺水,城市环境脏、乱、差。
不同地区能源消耗类型又决定了不同地区污染的差异。
空气污染可以按照能源消耗的不同分为煤烟型、石油型、扬尘型和复合型等。
煤烟型污染的特征是空气污染物中总悬浮颗粒物和二氧化硫所占的比例较大;石油型污染主要是来自石油燃烧、石油化工和汽车尾气产生的二次污染,发达国家多属此类污染,污染严重时可形成光化学烟雾,并在5-9月浓度较高,我国甘肃省兰州市就是属于这种类型;扬尘型污染是以二次扬尘、建筑垃圾扬尘、机动车污染以及沙尘天气所造成的总悬浮颗粒物污染为主的非燃煤粉尘污染;以石油型污染、二次扬尘、建筑扬尘及机动车排放污染为代表的污染称为复合型污染,此类污染是以煤烟型污染为主导的,主要形成于煤烟型污染向石油型污染转化的工业发达城市,有煤烟型污染与石油型污染的共同特征。