北航 计算理论 第二章 计算模型
- 格式:pptx
- 大小:237.72 KB
- 文档页数:50
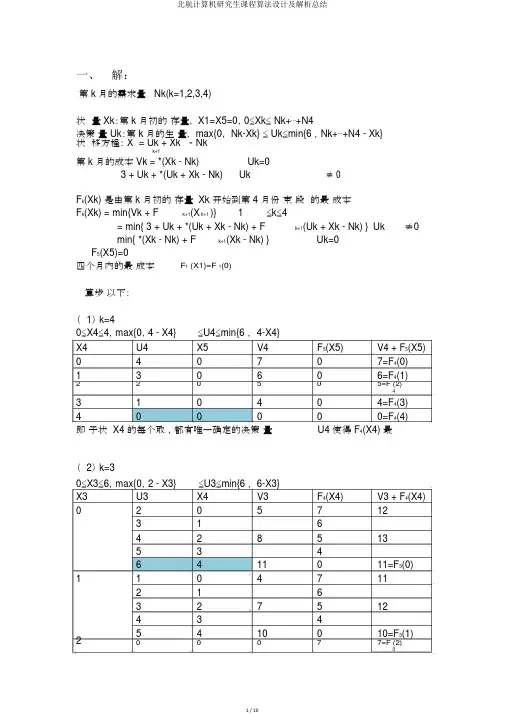
一、解:第 k 月的需求量 Nk(k=1,2,3,4)状量 Xk:第 k 月初的存量, X1=X5=0,0≤Xk≤ Nk+⋯+N4决策量 Uk:第 k 月的生量, max{0, Nk-Xk} ≤ Uk≤min{6 ,Nk+⋯+N4 - Xk}状移方程: X = Uk + Xk – Nkk+1第 k 月的成本 Vk = *(Xk - Nk) Uk=03 + Uk + *(Uk + Xk - Nk) Uk ≠ 0F k(Xk) 是由第 k 月初的存量 Xk 开始到第 4 月份束段的最成本F k(Xk) = min{Vk + F k+1(X k+1 )}1≤k≤4= min{ 3 + Uk + *(Uk + Xk - Nk) + F k+1(Uk + Xk - Nk) }Uk≠0min{ *(Xk - Nk) + F k+1(Xk - Nk) }Uk=0F5(X5)=0四个月内的最成本F1 (X1)=F 1(0)算步以下:(1) k=40≤X4≤4,max{0,4 - X4}≤U4≤min{6,4-X4}X4 U4 X5 V4 F5(X5) V4 + F5(X5)0 4 0 7 0 7=F4(0)1 3 0 6 0 6=F4(1)2 2 0 5 0 5=F (2)43 1 04 0 4=F4(3)4 0 0 0 0 0=F4(4)即于状 X4 的每个取,都有唯一确定的决策量U4 使得 F4(X4) 最(2) k=30≤X3≤6,max{0,2 - X3} ≤U3≤min{6 , 6-X3}X3 U3 X4 V3 F4(X4) V3 + F4(X4) 0 2 0 5 7 123 1 64 2 85 135 3 46 4 11 0 11=F3(0)1 1 0 4 7 112 1 63 2 7 5 124 3 42 5 4 10 0 10=F3(1) 0 0 0 7 7=F (2)31 1 62 2 6 5 113 3 43 4 4 9 0 90 1 6 =F (3)31 2 5 5 102 3 44 3 4 8 0 80 2 1 5 6=F (4)31 3 42 4 7 0 75 0 3 4 =F3 (5)1 4 6 0 66 0 4 3 0 2=F3(6)(3) k=2 时0≤X2≤9,max{0,3 - X2}≤U2≤min{6,9-X2}X2 U2 X3 V2 F3(X3) V2 + F 3(X3) 0 3 0 6 11 174 1 105 2 9 7 16=F (0)26 3 171 2 0 5 11 163 1 104 2 8 7 15=F2(1)5 3 166 4 11 6 172 1 0 4 11 152 1 103 2 7 7 14=F (2)24 3 155 4 106 166 5 173 0 0 0 11 11=F (3)21 1 102 2 6 7 133 3 144 4 9 6 155 5 166 6 12 2 144 0 1 10 =F (4)21 2 5 7 132 3 133 4 8 6 144 5 155 6 11 2 135 0 2 1 7 8=F (5)21 3 122 4 7 6 133 5 144 6 10 2 126 0 3 8=F (6)21 4 6 6 122 5 133 6 9 2 117 0 4 2 6 8=F (7)21 5 122 6 8 2 108 0 5 8=F2(8)9 1 6 7 2 90 6 3 2 5=F (9)2(4) k=1X1=0,max{0,2} ≤U1≤min{6 , 11}X1 U1 X2 V1 F2(X2) V1 + F2(X2) 0 2 0 5 16 213 1 154 2 8 14 225 3 11 =F1 (0)6 4 11由以上算可得, 4 个月的最成本 F (0) = ( 千元 )1从 k=1 回溯,可得最果中各段的状量Xk 和决策量 Uk 以下表:月份 k 量 Uk 月初存量 Xk 需求量 Nk 每个月成本Vk1 5 0 22 03 3 03 6 0 2 114 0 4 4 0二、解:1、变量设定段 k:已遍 k 个点, k=1,2 ⋯ 6,7 。



6种计算模型计算模型是计算机科学中的一个重要概念,它是描述计算过程的数学模型。
在计算机科学中,有许多种不同的计算模型,每种模型都有自己的特点和适用范围。
在本文中,我们将介绍6种常见的计算模型。
1.有限自动机:有限自动机是一种描述有限状态机的计算模型。
它由一组有限状态、一组输入符号和一组状态转移函数组成。
有限自动机适用于描述简单的计算过程,如正则表达式匹配和字符串处理等。
2.图灵机:图灵机是由英国数学家艾伦·图灵提出的一种抽象计算模型。
图灵机包括一个无限长的纸带和一个可以读写移动的头部。
图灵机可以模拟任何计算过程,因此被认为是一种通用的计算模型。
mbda演算:Lambda演算是一种基于函数定义的计算模型。
它使用匿名函数和函数应用来描述计算过程。
Lambda演算是函数式编程语言的理论基础,它具有优雅简洁的数学形式。
4.递归函数:递归函数是一种递归定义的计算模型。
它使用函数自身的调用来描述计算过程,递归函数适用于描述递归结构的计算问题,如树形结构的遍历和分治算法等。
5.数据流模型:数据流模型是一种描述并行计算的计算模型。
它使用数据流图来描述计算过程,将计算分解成一系列数据流操作。
数据流模型适用于描述流式计算和并行计算等。
6.并发模型:并发模型是一种描述并发计算的计算模型。
它使用并发控制结构来描述计算过程,将计算分解成多个并发执行的任务。
并发模型适用于描述多任务调度和并发通信等。
这些计算模型各具特点,在不同的计算问题中有不同的应用。
了解和掌握这些计算模型有助于我们更好地理解计算过程和设计高效的算法。
希望本文对你有所帮助。

2计算理论与计算模型计算理论和计算模型是计算机科学中非常重要的概念,它们对计算机科学的发展和应用产生了深远的影响。
计算理论是研究计算问题的基础理论,包括了算法、复杂性理论、计算复杂度理论等内容;而计算模型是描述计算机的抽象模型,包括了有限自动机、图灵机、lambda演算等多种模型。
在这篇文章中,我们将探讨计算理论和计算模型之间的关系,以及它们在计算机科学领域中的应用。
首先,让我们来看看计算理论和计算模型之间的关系。
计算理论是研究计算问题的数学理论,主要包括了算法的设计和分析、计算复杂性的研究等内容。
算法是一种解决问题的步骤序列,其设计和分析是计算理论的核心内容之一、通过研究算法,我们可以了解到如何高效地解决各种不同的计算问题,从而提高计算机科学的效率和实用性。
另一方面,计算模型是描述计算机的抽象模型,用来帮助我们理解计算机是如何进行计算的。
常见的计算模型包括了有限自动机、图灵机、lambda演算等。
有限自动机是一种具有有限个状态和转移规则的抽象计算模型,用来描述自动控制系统的行为。
而图灵机是英国数学家图灵提出的一种理论计算模型,它可以模拟任何计算问题的解决过程。
lambda演算则是由数学家艾伦·图灵和斯蒂芬·科尔尼(Stephen Cole Kleene)提出的一种基于λ演算符号的计算模型,用来描述函数式编程语言的计算过程。
计算理论和计算模型之间有着密切的关系。
计算理论提供了研究计算问题的基础理论,而计算模型则帮助我们理解计算机是如何进行计算的。
通过研究计算理论和计算模型,我们可以更好地理解计算机科学中的各种重要概念和理论,为计算机科学的发展和应用奠定了坚实的基础。
在计算机科学领域中,计算理论和计算模型有着广泛的应用。
在算法设计和分析方面,计算理论提供了许多重要的方法和技术,如分治法、动态规划、贪心算法等,用来解决各种不同的计算问题。
在计算复杂性理论方面,计算理论帮助我们理解计算问题的困难程度,并提出了许多重要的结论,如P=NP问题、NP完全问题等。


2计算理论与计算模型计算理论与计算模型是计算机科学中的重要理论基础,它研究计算的基本原理、能力和限制等问题。
在计算机科学的发展过程中,计算理论和计算模型起到了桥梁和纽带的作用,不仅推动了计算机科学的发展,也对计算机科学中的其他分支学科产生了深远的影响。
计算理论主要研究计算的数学和逻辑基础,它关注计算过程、算法和问题,以及计算的可行性和有效性等内容。
计算理论的主要内容包括图灵机模型、可计算性理论、形式语言与自动机理论、复杂性理论等。
计算模型指的是对计算过程的抽象和形式化描述。
计算模型旨在研究不同计算机系统之间的共性和异同,帮助人们更好地理解计算过程的本质。
常见的计算模型有图灵机、有限自动机、带状态机等。
图灵机模型是计算理论和计算模型的核心之一,它由英国数学家图灵于1936年提出。
图灵机模型使用一个带有无限长纸带的虚拟机器,通过读写和移动机器头来模拟计算过程。
图灵机模型具有简单、通用和可计算的特点,被广泛用于计算理论和计算机科学的研究。
可计算性理论是计算理论中的一个重要分支,它研究了哪些问题可以通过算法和计算过程进行求解,以及哪些问题是无法通过算法求解的。
可计算性理论的核心是判定问题的可计算性,即确定一些问题是否存在一个算法可以解决它。
可计算性理论的代表性工作是图灵的停机问题,即判断一些图灵机是否能在有限步骤内终止。
图灵证明了停机问题是不可判定的,也就是说无法通过一个算法来解决停机问题。
形式语言与自动机理论是计算机科学中的另一个重要分支,它研究了形式语言的定义、生成和识别等问题,以及自动机的建模和分析方法。
形式语言是用于描述计算机科学中的计算过程和问题的一种工具,而自动机则是用于模拟和分析这些计算过程和问题的一种抽象模型。
形式语言与自动机理论不仅在编程语言的设计和解析中有重要应用,还在计算过程的理论分析中起到了重要的作用。
复杂性理论是计算理论和计算模型中的一个重要研究方向,它研究问题的复杂性与计算资源之间的关系,以及不同计算模型和算法的效率和可行性。




用分支定界算法求以下问题:某公司于乙城市的销售点急需一批成品,该公司成品生产基地在甲城市。
甲城市与乙城市之间共有n 座城市,互相以公路连通。
甲城市、乙城市以及其它各城市之间的公路连通情况及每段公路的长度由矩阵M1 给出。
每段公路均由地方政府收取不同额度的养路费等费用,具体数额由矩阵M2 给出。
请给出在需付养路费总额不超过1500 的情况下,该公司货车运送其产品从甲城市到乙城市的最短运送路线。
具体数据参见文件:m1.txt: 各城市之间的公路连通情况及每段公路的长度矩阵(有向图); 甲城市为城市Num.1,乙城市为城市Num.50。
m2.txt: 每段公路收取的费用矩阵(非对称)。
思想:利用Floyd算法的基本方法求解。
程序实现流程说明:1.将m1.txt和m2.txt的数据读入两个50×50的数组。
2.用Floyd算法求出所有点对之间的最短路径长度和最小费用。
3.建立一个堆栈,初始化该堆栈。
4.取出栈顶的结点,检查它的相邻的所有结点,确定下一个当前最优路径上的结点,被扩展的结点依次加入堆栈中。
在检查的过程中,如果发现超出最短路径长度或者最小费用,则进行”剪枝”,然后回溯。
5.找到一个解后,保存改解,然后重复步骤4。
6.重复步骤4、5,直到堆栈为空,当前保存的解即为最优解。
时间复杂度分析:Floyd算法的时间复杂度为3O N,N为所有城市的个数。
()该算法的时间复杂度等于DFS的时间复杂度,即O(N+E)。
其中,E为所有城市构成的有向连通图的边的总数。
但是因为采用了剪枝,会使实际运行情况的比较次数远小于E。
求解结果:算法所得结果:甲乙之间最短路线长度是:464最短路线收取的费用是:1448最短路径是:1 3 8 11 15 21 23 26 32 37 39 45 47 50C源代码(注意把m1.txt与m2.txt放到与源代码相同的目录下,下面代码可直接复制运行):#include<stdlib.h>#include<stdio.h>#include<time.h>#include<string.h>#define N 50#define MAX 52void input(int a[N][N],int b[N][N]);void Floyd(int d[N][N]);void fenzhi(int m1[N][N],int m2[N][N],int mindist[N][N],int mincost[N][N]);int visited[N],bestPath[N];void main(){clock_t start,finish;double duration;int i,j,mindist[N][N],mincost[N][N],m1[N][N],m2[N][N]; /* m1[N][N]和m2[N][N]分别代表题目所给的距离矩阵和代价矩阵*/// int visited[N],bestPath[N];FILE *fp,*fw;// system("cls");time_t ttime;time(&ttime);printf("%s",ctime(&ttime));start=clock();for(i=0;i<N;i++){visited[i]=0;bestPath[i]=0;}fp=fopen("m1.txt","r"); /* 把文件中的距离矩阵m1读入数组mindist[N][N] */if(fp==NULL){printf("can not open file\n");return;}for(i=0;i<N;i++)for(j=0;j<N;j++)fscanf(fp,"%d",&mindist[i][j]);fclose(fp); /* 距离矩阵m1读入完毕*/fp=fopen("m2.txt","r"); /* 把文件中的代价矩阵m2读入数组mincost[N][N] */if(fp==NULL){printf("can not open file\n");return;}for(i=0;i<N;i++)for(j=0;j<N;j++)fscanf(fp,"%d",&mincost[i][j]);fclose(fp); /* 代价矩阵m2读入完毕*/input(m1,mindist); /* mindist[N][N]赋值给m1[N][N],m1[N][N]代表题目中的距离矩阵*/input(m2,mincost); /* mincost[N][N]赋值给m2[N][N],m2[N][N]代表题目中的代价矩阵*/for(i=0;i<N;i++) /* 把矩阵mindist[i][i]和mincost[i][i]的对角元素分别初始化,表明城市到自身不连通,代价为0 */{mindist[i][i]=9999;mincost[i][i]=0;}Floyd(mindist); /* 用弗洛伊德算法求任意两城市之间的最短距离,结果存储在数组mindist[N][N]中*//*fw=fopen("1.txt","w");for(i=0;i<N;i++){for(j=0;j<N;j++)fprintf(fw,"%4d ",mindist[i][j]);fprintf(fw,"\n");}fclose(fw);// getchar();//*/Floyd(mincost); /* 用弗洛伊德算法求任意两城市之间的最小代价,结果存储在数组mincost[N][N]中*//*fw=fopen("2.txt","w");for(i=0;i<N;i++){for(j=0;j<N;j++)fprintf(fw,"%4d ",mincost[i][j]);fprintf(fw,"\n");}fclose(fw);// getchar();//*/fenzhi(m1,m2,mindist,mincost); /* 调用分支定界的实现函数,寻找出所有的可行路径并依次输出*/finish=clock();duration = (double)(finish - start) / CLOCKS_PER_SEC;printf( "%f seconds\n", duration );//*/}void Floyd(int d[N][N]) /* 弗洛伊德算法的实现函数*/{int v,w,u,i;for(u=0;u<N;u++){for(v=0;v<N;v++){for(w=0;w<N;w++)if(d[v][u]+d[u][w]<d[v][w]){//printf("v,w,u,d[v][u],d[u][w],d[v][w] %d %d %d %d %d %d",v+1,w+1,u+1,d[v][u],d[u][w],d[v][ w]);getchar();d[v][w]=d[v][u]+d[u][w];}}}}void input(int a[N][N],int b[N][N]) /* 把矩阵b赋值给矩阵a */{int i,j;for(i=0;i<N;i++)for(j=0;j<N;j++)a[i][j]=b[i][j];}void fenzhi(int m1[N][N],int m2[N][N],int mindist[N][N],int mincost[N][N]){int stack[MAX],depth=0,next,i,j; /* 定义栈,depth表示栈顶指针;next指向每次遍历时当前所处城市的上一个已经遍历的城市*/int bestLength,shortestDist,minimumCost,distBound=9999,costBound=9999;int cur,currentDist=0,currentCost=0; /* cur指向当前所处城市,currentDist和currentCost分别表示从甲城市到当前所处城市的最短距离和最小代价,currentDist和currentCost初值为0表示从甲城市出发开始深度优先搜索*/stack[depth]=0; /* 对栈进行初始化*/stack[depth+1]=0;visited[0]=1; /* visited[0]=1用来标识从甲城市开始出发进行遍历,甲城市已被访问*/while(depth>=0) /* 表示遍历开始和结束条件,开始时从甲城市出发,栈空,depth=0;结束时遍历完毕,所有节点均被出栈,故栈也为空,depth=0 *//* 整个while()循环体用来实现从当前的城市中寻找一个邻近的城市*/{cur=stack[depth]; /* 取栈顶节点赋值给cur,表示当前访问到第cur号城市*/ next=stack[depth+1]; /* next指向当前所处城市的上一个已经遍历的城市*/for(i=next+1;i<N;i++) /* 试探当前所处城市的每一个相邻城市*/{if((currentCost+mincost[cur][N-1]>costBound)||(currentDist+mindist[cur][N-1]>=distBound)){ /* 所试探的城市满足剪枝条件,进行剪枝*///printf("here1 %d %d %d %d %d %d %d\n",cur,currentCost,mincost[cur][49],costBound,curre ntDist,mindist[cur][49],distBound); getchar();//printf("%d %d %d %d %d %d",cur,i,m1[cur][i],currentCost,mincost[cur][49],costBound); getchar();continue;}if(m1[cur][i]==9999) continue; /* 所试探的城市不连通*/if(visited[i]==1) continue; /* 所试探的城市已被访问*/if(i<N) break; /* 所试探的城市满足访问条件,找到新的可行城市,终止for循环*/ }if(i==N) /* 判断for循环是否是由于搜索完所有城市而终止的,如果是(i==N),进行回溯*/{// printf("here");getchar();depth--;currentDist-=m1[stack[depth]][stack[depth+1]];currentCost-=m2[stack[depth]][stack[depth+1]];visited[stack[depth+1]]=0;}else /* i!=N,表示for循环的终止是由于寻找到了当前城市的一个可行的邻近城市*/{//printf("%d %d %d %d %d %d\n",cur,i,m1[stack[depth]][i],m2[stack[depth]][i],currentCost,curre ntDist);//getchar();currentDist+=m1[stack[depth]][i]; /* 把从当前所处城市到所找到的可行城市的距离加入currentDist */currentCost+=m2[stack[depth]][i]; /* 把从当前所处城市到所找到的可行城市的代价加入currentCost */depth++; /* 所找到的可行城市进栈*/stack[depth]=i; /* 更新栈顶指针,指向所找到的可行城市*/stack[depth+1]=0;visited[i]=1; /* 修改所找到的城市的访问标志*/if(i==N-1) /* i==N-1表示访问到了乙城市,完成了所有城市的一次搜索,找到一条通路*/{// printf("here\n");for(j=0;j<=depth;j++) /* 保存当前找到的通路所经过的所有节点*/ bestPath[j]=stack[j];bestLength=depth; /* 保存当前找到的通路所经过的所有节点的节点数*/shortestDist=currentDist; /* 保存当前找到的通路的距离之和*/minimumCost=currentCost; /* 保存当前找到的通路的代价之和*///costBound=currentCost;distBound=currentDist; /* 更新剪枝的路径边界,如果以后所找到的通路路径之和大于目前通路的路径之和,就剪枝*/if(minimumCost>1500) continue; /* 如果当前找到的通路的代价之和大于1500,则放弃这条通路*/printf("最短路径:%3d,路径代价:%3d,所经历的节点数目:%3d,所经历的节点如下:\n",shortestDist,minimumCost,bestLength+1); /* 输出找到的通路的结果*/bestPath[bestLength]=49;for(i=0;i<=bestLength;i++) /* 输出所找到的通路所经过的具体的节点*/ printf("%3d ",bestPath[i]+1);(完整word版)北航研究生算法设计与分析Assignment_2 printf("\n");depth--; /* 连续弹出栈顶的两个值,进行回溯,开始寻找新的可行的通路*/currentDist-=m1[stack[depth]][stack[depth+1]];currentCost-=m2[stack[depth]][stack[depth+1]];visited[stack[depth+1]]=0;depth--;currentDist-=m1[stack[depth]][stack[depth+1]];currentCost-=m2[stack[depth]][stack[depth+1]];visited[stack[depth+1]]=0;// getchar();}}}}。
计算模型基础知识点总结计算模型是计算机科学领域的一个重要分支,它研究如何使用数学模型和算法来描述和解决实际的计算问题。
在计算模型的研究中,人们首先需要明确问题的描述和目标,然后设计合适的数据结构和算法来解决这些问题,并进行理论分析和实际实验来验证算法的可行性和有效性。
在这篇文章中,我将总结计算模型的基础知识点,包括计算模型的基本概念、常见的数据结构和算法、以及计算模型在实际应用中的一些典型问题和解决方法。
1. 计算模型的基本概念计算模型是描述和研究计算问题和算法的一种抽象框架,它包括输入、输出、数据结构、算法、复杂性分析和应用等内容。
在计算模型中,输入是描述问题的描述信息,输出是描述问题的解决结果,数据结构是描述问题的信息组织形式,算法是描述问题的解决步骤,复杂性分析是描述算法的效率和资源消耗,应用是描述算法的实际应用场景。
在计算模型的研究中,常见的数据结构包括数组、链表、栈、队列、树、图等,常见的算法包括排序、搜索、动态规划、贪心算法、回溯算法、分治算法、图算法等。
2. 常见的数据结构和算法在计算模型的研究中,数据结构是描述问题的信息组织形式,它包括线性结构和非线性结构。
线性结构包括数组、链表、栈、队列等,非线性结构包括树、图等。
算法是描述问题的解决步骤,它包括排序、搜索、动态规划、贪心算法、回溯算法、分治算法、图算法等。
常见的数据结构包括数组、链表、栈、队列、树、图等。
数组是由相同类型的元素组成的有序集合,它可以按照下标随机访问元素;链表是由节点组成的一种动态数据结构,它可以在任意位置插入和删除元素;栈是一种后进先出的线性数据结构,它可以用于程序调用栈和表达式求值;队列是一种先进先出的线性数据结构,它可以用于任务调度和广度优先搜索;树是一种节点组成的层次结构,它可以用于文件系统和数据库索引;图是由节点和边组成的一种动态数据结构,它可以用于网络和路径搜索。
常见的算法包括排序、搜索、动态规划、贪心算法、回溯算法、分治算法、图算法等。