编译原理分知识点习题-语法制导和翻译
- 格式:doc
- 大小:55.50 KB
- 文档页数:25









第五章语法制导翻译及中间代码生成5.1说明属性文法与属性翻译文法有何异同?5.2考虑下面的属性文法:Z →sXattribution:Z.a=X.c;X.b=X.a;Z.p=X.b;Z →t Xattribution:X.b=X.d;Z.a=X.b;X →uattribution:X.d=1;X.c=X.d;X →Vattribuion:X.c=2;X.d=X.c;(1) 上述文法中的属性哪些是继承的?哪些是综合的?(2) 上述文法中的属性依赖是否出现了循环?5.3为什么说S属性文法一定是L属性文法?反之结论亦正确吗?5.4将下列中缀式改写为逆波兰式。
(1) -A*(B+C)↑(D-E)(2) ((a*d+c)/d+e)*f+g(3) a+x≤4∨(C∧d*3)(4) a∨b∧c+d*e↑f(5) s=0; i=1;while (i<=100) {s+=i*i; i++;}5.5将下列后缀式改写为中缀式。
(1) abc*+(2) abc-*cd+e/-(3) abc+≤a0>∧ab+0≠a0∧∨(4) ab<p1 BZ xab-c↑= p2 BR gh=↑↑p1p25.6设已给文法G[E]:E →E+T | -T | TT →T*F | FF →P ↑F | PP →(E) | i试设计一个递归下降分析器,要求此分析器在语法分析过程中,将所分析的符号串翻译成后缀式。
5.7设已给布尔表达式文法G[Z]:Z →EE →T{∨T}T →F{∧F}F → F | (E) | b试设计一个递归下降分析器,它把由G[Z]所描述的布尔表达式翻译为四元式序列。
5.8(1) 利用54节所给的属性翻译文法将赋值语句:X=A*(B+C)+D翻译成四元式序列,给出语法制导的翻译过程。
(2) 利用55节所给的属性翻译文法将布尔表达式:A∧(B∨(C∨D F))翻译成四元式序列,给出语法制导的翻译过程。
(3) 利用56节所给的属性翻译文法将语句:while A<C∧B>0 doif A=1 then C∶=C+1else while A<=D do A∶=A+2翻译成四元式序列,给出语法制导的翻译过程。

《编译原理》课程复习资料一、判断题:1.一个上下文无关文法的开始符,可以是终结符或非终结符。
[ ]2.一个句型的直接短语是唯一的。
[ ]3.已经证明文法的二义性是可判定的。
[ ]4.每个基本块可用一个DAG表示。
[ ]5.每个过程的活动记录的体积在编译时可静态确定。
[ ]6.2型文法一定是3 型文法。
[ ]7.一个句型一定句子。
[ ]8.算符优先分析法每次都是对句柄进行归约。
[ ]9.采用三元式实现三地址代码时,不利于对中间代码进行优化。
[ ]10.编译过程中,语法分析器的任务是分析单词是怎样构成的。
[ ]11.一个优先表一定存在相应的优先函数。
[ ]12.目标代码生成时,应考虑如何充分利用计算机的寄存器的问题。
[ ]13.递归下降分析法是一种自下而上分析法。
[ ]14.并不是每个文法都能改写成 LL(1)文法。
[ ]15.每个基本块只有一个入口和一个出口。
[ ]16.一个 LL(1)文法一定是无二义的。
[ ]17.逆波兰法表示的表达试亦称前缀式。
[ ]18.目标代码生成时,应考虑如何充分利用计算机的寄存器的问题。
[ ]19.正规文法产生的语言都可以用上下文无关文法来描述。
[ ]20.一个优先表一定存在相应的优先函数。
[ ]21.3型文法一定是2 型文法。
[ ]22.如果一个文法存在某个句子对应两棵不同的语法树,则文法是二义性的。
[ ]二、填空题:1. 称为规范推导。
2.编译过程可分为,,,和五个阶段。
3.如果一个文法存在某个句子对应两棵不同的语法树,则称这个文法是。
4.从功能上说,程序语言的语句大体可分为语句和语句两大类。
5.语法分析器的输入是,其输出是。
6.扫描器的任务是从中识别出一个个。
7.符号表中的信息栏中登记了每个名字的有关的性质,如等等。
8.一个过程相应的DISPLAY表的内容为。
9.一个句型的最左直接短语称为句型的。
10.常用的两种动态存贮分配办法是动态分配和动态分配。
编译原理试题库* ? 一.名词解释: 1)前缀答:前缀——是指符号串任意首部。
2)可归前缀答:可归前缀——是指规范句型的一个前缀,这种前缀包含句柄且不含句柄之后的任何符号。
3)活前缀答:活前缀——规范句型的一个前缀,这种前缀不含句柄之后的任何符号。
或给定文法规范句型的可归前缀的任意首部。
4)简单短语答:简单短语——设G[Z]是给定文法,w=xuy ∈V +,为该文法的句型,如果满足下面两个条件:① Z xUy ;② U ?u ;则称句型xuy 中的子串u 是句型xuy 的简单短语。
5)扫描遍答:扫描遍——指编译程序对源程序或中间代码程序从头到尾扫描一次。
6)句柄答:句柄——给定句型中的最左简单短语就是句柄。
7)句型答:句型——设G 是一个给定的文法,S 是文法的开始符号,如果S x(其中x ∈V *),则称x 是文法的一个句型。
8)句子答:句子——设G 是一个给定的文法,S 是文法的开始符号,如果S x (其中x ∈V T *),则称x 是文法的一个句子。
9)非终结符答:非终结符—出现在文法产生式的左部且能派生出符号或符号串的那些符号称为非终结符号。
10)终结符答:终结符——出现在文法产生式的右部且不能派生出符号或符号串的那些符号称为终结符号。
11)属性文法答:一个属性文法形式的定义为一个三元组AG ,AG=(G ,V ,E )。
其中G 为一个上下文无关文法;V 为属性的有穷集;E 为一组语义规则。
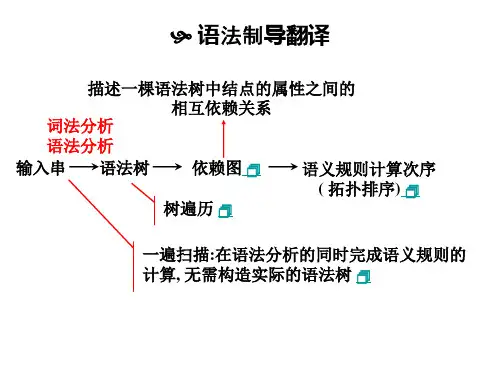
12)语法制导翻译答:语法制导翻译——语法制导翻译就是在语法分析的过程中,当进行推导或归约时同步完成附加在所使用的产生式上的语义规则描述的动作,从而实现语义处理。
13)后缀式答:后缀式——一种把运算量(操作数)写在前面,把算符写在后面(后缀)的表示法。
14)短语答:短语——设G[Z]是给定文法,w=xuy ∈V +,为该文法的句型,如果满足下面两个条件:① Z xUy ;② U u ;则称句型xuy 中的子串u 是句型xuy 的短语。
中间语言与语法制导翻译重点与难点重点:语法制导翻译的基本思想,属性文法,翻译模式,说明语句的翻译方案。
三地址码,各种语句的目标代码结构、属性文法与翻译模式。
难点:属性的意义,对综合属性,继承属性,固有属性的理解,属性计算,怎么通过属性来表达翻译。
布尔表达式的翻译,对各种语句的目标代码结构、属性文法与翻译模式的理解。
基本要求掌握语法制导翻译的基本思想,属性文法,综合属性,继承属性,固有属性,属性计算,S_属性文法,L_属性文法,说明语句的翻译方案,翻译模式、属性文法的实现掌握中间语言与语义分析的基本概念;熟练掌握语法(结构)树、三地址代码、赋值与控制语句的翻译、说明语句的翻译;掌握组合数据说明的翻译、过程调用翻译。
例题解析例1 给定文法 E --> T { R.i := T.p }R { E.p := R.s }R --> addopT { R1.i := mknode( addop.val, R.i, T.p ) }R { R.s := R1.s }R --> { R.s := R1.s }T --> ( E ) { T.p := E.p }T --> id { T.p := mkleaf( id, id.entry ) }T --> num { T.p := mkleaf( num, num.val ) }(1) 指出文法中的各非终结符具有哪些综合属性和哪些继承属性⑵画出按本翻译模式处理表达式 a + 20 + ( b - 10 ) 时所生成的语法树【解】(1)E的综合属性 p,R的继承属性i,综合属性s;T的综合属性p(2) 处理表达式 a + 20 + ( b - 10 ) 时所生成的语法树如下+(ID, a) +(NUM, 20) -( ID, b) (NUM, 10)例2 定义一个计算器的属性文法,完成一个输入表达式值的计算和显示,【解】计算器的文法L → EE → E1 + T | TT → T1 * F | FF → ( E ) | digit引进属性val,计算器的属性文法:L → E print( E.val )(L的虚属性)E → E1 + T E.val := E1.val + T.valE → T E.val := T.valT → T1 * F T.val := T1.val * F.valT → F T.val := F.valF → ( E ) F.val := E.valF → digit F.val := digit.lexvallexval 是单词 digit 的属性例3给出对输入串6-3 3*5+4 的分析树与属性计算【解】3*5+4 的分析树与属性计算例4定义一个说明语句的属性文法【解】说明语句的文法D → T LT → intT → realL → L1,idL → id要解决的问题:记录标识符的类型和类型信息传递方法:引进属性type,和in,用T.type记录类型信息,并传给L.in, 说明语句的属性文法如下:D → T L L.in := T.typeT → int T.type := ‘integer’T → real T.type := ‘real’L → L1,id L1.in := L.inaddtype( id.entry, L.in ) L → id addtype( id.entry, L.in )entry 单词 id 的属性addtype 在符号表中为变量填加类型信息例5 给出输入串real id1,id2,id3 的分析树和属性计算例6 设下列文法生成变量的类型说明D → id LL → , id L | : TT → integer | real试构造一个翻译模式,把每个标识符的类型存入符号表。
1.一般情况下,为什么语义分析部分仅产生中间代码解答:一般情况下,语义分析部分仅产生中间代码,其原因是:可使难点分解,分别解决。
可对语义分析产生的中间代码进行优化,以产生高效率的目标代码。
语义分析通常与机器无关,目标代码往往与机器有关。
把语义分析与目标代码生成分开,可让一个语义分析程序适用于多个目标代码生成程序。
2.(湖北省高等教育自学考试)什么是语法制导翻译为什么把这种方法叫语法制导翻译解答:所谓语法制导翻译,是指在语法规则的制导下,通过计算语义规则,完成对输入符号串的翻译。
由于使用属性文法时把语法规则和语义规则分开,但在使用语法规则进行推导或规约的同时又使用这些语义规则来知道翻译与最终产生目标代码,所以称为语法制导翻译。
3.给出将附值语句翻译成四元式的语法制导定义,允许右部表达式含有加法、乘法、取负、括号运算。
生成赋值语句X:=B*(C+D)+A 的四元式。
解答:赋值语句的自下而上的语法制导翻译过程描述为:规则语义动作(1)A::=i:=E {GEN (:=,,__,ENTRY(i) ) }(2)E::=E1+E2 {:=NEWTEMP;GEN(+,, ,}(3)E::= E1*E2 { :=NEWTEMP;GEN(*,, ,}(4)E::=-E1 { :=NEWTEMP;GEN(@,,__,}(5)E::=(E1) {:= }(6)E::=i {:= ENTRY(i) }生成的赋值语句X:=B*(C+D)+A的四元式为:(+,C,D,T1)(*,B,T1,T2)(+,T2,A,T3)(:=,T3,_,X)4.给出将布尔表达式翻译成四元式的语法制导定义。
解答:布尔表达式的语义子程序为:规则语义动作(1) E::=I {:=null;:=NXQ;GEN (Jez , ENTRY(i), __,0) }(2) E::= i1 rop i2 { :=null;:=NXQ;GEN (Jnrop,ENTRY(i1), ENTRY(i2),0)}(3) E::= (E1) {:=, :=; }(4) E::= ¬ E1 { :=NXQ;GEN ( J, __, __, 0); BP , NXQ);}(5) E A::=E1∧ { if =nullthen begin::=NXQ;GEN ( J, __, __, 0)End;BP ( , NXQ );:=null; := }(6) E ::= E A E2 {if ≠nullthen beginBP , NXQ);:=nullEnd:=; }(7) E0::=E1∨ { if :=nullthen begin:=NXQ;GEN ( J, __, __, 0)End;:=;BP ,NXG);}(8) E::=E0E2 { if ≠nullthen:=MERG,Else beginBP ,NXQ);:=End;:=}其中:NXQ指示器指向下一个将要形成但尚未形成的四元式的地址(编号),初值为1,每当执行GEN一次,NXQ自动加1。
GEN是一个语义过程,该过程把四元式加入四元式表区中。
和分别表示E所对应的四元式需回填“真”、“假”出口的四元式地址所构成的链。
MERG(P1,P2)为一函数,把以P1和P2为链首的两个链合二为一作为函数值,回送合并后的链首。
BP(P,t)为一语义过程,BP是BACKPATCH的缩写。
这是一“回填”过程,它把以P为链首所链接的每个四元式的第四区段都填为t。
Jrop是根据关系运算符rop定义的条件转移。
5.试写出PASCAL循环语句for I:=1 to N do S 的语义程序,假定该语句的文法为F1::= for i:= 1 to NS::= F1 do S1解答:根据题设文法,for语句的语义子程序为:F1::= for i:= 1 to N {:=entry (i); GEN(:=, ‘1’ ,__,;Final:=newtemp; GEN( :=,, __,final);:=NXQ; :=NXQ ;GEN( J>, ,final,0)}S::= F1 do S1{BACKPATCH ,NXQ); GEN (+,, ‘1’,;GEN (J, _, _,; BACKPATCH ,NXQ)}6.写出条件赋值语句i :=if B then E1 else E2的语义子程序。
其中B是布尔表达式,E1和E2是算术表达式,i代表与E1、E2类型相同的左部变量。
按写出的语义子程序生成条件赋值语句Z:=if A>C then x+y else x-y+的四元式序列。
解答:按条件赋值语句的语义给出该语句的文法如下:A1::=i:=A2::=A1 if B thenA3::=A2 E1 elseS::=A3 E2相应的语义子程序为:(1) A1::=i:= {:=entry (i) }(2) A2::=A1 if B then {BP , NXQ); :=; :=}(3) A3::=A2 E1 else {GEN (:=,, _,; :=NXQ;GEN ( J, _, _,0 );BP,NXQ);:=} (4) S::=A3E2 {GEN (:=,, _,;BP,NXQ) }按上述语义子程序,条件赋值语句Z:=if A>C then x+y else x-y+的四元式序列为:(1) ( J>,A,C, (3))(2) ( J ,(4) (:=,T1, _,Z)(7) (+,T2,,T3)(8) (:=,T3, _,Z)(9)7.写出编译PASCAL语言repeat语句repeatS1; S2; …; Snuntil E;的语义子程序.其中E是条件表达式.解答:PASCAL的repeat语句的文法为:R1→repeatL→S|L s SL s→L;R2→R1L untilS→R2E于是repeat语句各产生式的语义子程序为: R1→repeat {:=NXQ}L→S {:=}L s→L; {BACKPATCH ,NXQ)}L→L s S1 {:=}R2→R1L until {:=; BACKPATCH ,NXQ) }S→R2E {BACKPATCH , ; :=}8.为便于填写被说明的名字的性质,试修改下面关于变量类型说明的文法,并给出相应的语义动作。
待修改的类型说明文法为:D→namelist integer|namelistnamelist→i,namelist|i解答:(1)为便于填写名字的属性,将上述文法修改为:D→namelist,D1D→i integerD→i realnamelist→namelist1,inamelist→i于是,相应的语义动作为:D→i integer {FILL (ENTRY (i) , int ); :=int }D→i real {FILL (ENTRY (i) ,real ); :=real }D→namelist,D1 {for 队列的每一项 P do FILL (P,;:= }namelist→i {建立一个队列, 它只包含一项ENTRY (i) }namelist→namelist1,i {把ENTRY(i)排在的末端;:= }注意:其中FILL(P,A)是一语义过程,其功能是把属性A添进P 所指向的符号表入口的有关区段。
语义变量用以记录说明语句所规定的属性。
(2)若类型说明的文法为:D→namelist integerD→namelist realnamelist→namelist1,inamelist→i相应的语义动作为:D→namelist integer {for 队列的每一项P do FILL(P,int);}D→namelist real {for 队列的每一项P do FILL(P,real);}namelist→i {建立一个队列它只包含一项ENTRY(i) }namelist→namelist1,i {把ENTRY(i)排在的末端;:= }9.(中国科学院计算所1996年)某些语言允许给出名字表的一个属性表,也允许声明嵌在另一个声明里面,下面文法抽象这个问题:D →attrlist namelist|attrlist(D)Namelist→id,namelist|idAttrlist→A attrlist|AA →decimal|fixed|float|realD → attrlist (D) 的含义是:在括号中的声明提到的所有名字有attrlist中给出的属性,而不管声明嵌套多少层。
写一个翻译方案,它将每个名字的属性添入符号表。
解答:相应的翻译方案为:D’ →{=0; }DD →attrlist{=+; }namelistD →attrlist{=+; }(D1)Namelist →id{addattr ,; }Namelist →id,{=; }namelist1{addattr ,; }attrlist →A attrlist1 {= +1; }attrlist →A {=1; }10.写出翻译过程调用语句的语义子程序。
要求生成的四元式序列在转子指令之前的参数四元式par按反序出现(即和实在参数的顺序相反),在此情况下翻译过程调用语句时是否需要语义变量(队列)QUEUE呢解答:为使过程调用语句的语义子程序产生的参数四元式par按反序出现,过程调用语句的文法为:S →call i (arglist)Arglist →EArglist →arglist1,E按照该文法,语法制导翻译程序将不需要语义变量队列QUEUE,但需要一个语义变量栈STACK,用以实现按反序记录每个实在参数的地址。
翻译过程调用语句的语义子程序为:arglist →E {建立一个栈,它只包含一个项 }arglist →arglist1,E {把压入栈;:= }S →call i (arglist) {WHILE ≠null doBegin把栈顶上托出去,并放入P元中;GEN(par, _, _,P)End;GEN(call, _, _,ENTRY(i)) }11.(中国科学院计算所1994)设有文法G[S]:S::=(L)|aL::=L,S|S给此文法配上语义动作子程序(或者说为此文法写一个语法制导定义),它输出配对括号的个数,如对于句子(a,(a,)),输出是2。
解答:加入新的开始符号’S’和规则S’::=S,得到增广文法。
语法制导定义如下:S’::=S {print ; }S::=(L) {:=+1; }S::=a {:=0; }L::=L1,S {:=+; }L::=S {:=; }12.(中国科学院软件所1999)文法G[S]的产生式如下:S::= (L)|aL::= L,S|S试写出一个语法制导定义,它输出配对括号个数。