第11章 因子分析和对应分析
- 格式:ppt
- 大小:145.50 KB
- 文档页数:4


SPSS因子分析与对应分析SPSS(Statistical Product and Service Solutions)是一种广泛应用于社会科学领域的统计分析软件,它提供了多种功能和方法来帮助研究者对数据进行分析。
因子分析和对应分析是SPSS中两种常用的统计方法,用于数据的维度缩减和模式识别,下面将详细介绍这两种方法。
1. 因子分析(Factor Analysis):因子分析是一种用于理解数据结构、推断变量之间的关系,以及确定数据中的潜在因素的统计方法。
这一方法旨在将大量变量缩减为较少的维度,并发现潜在的(或不可观察的)因子。
这些因子通常用于解释数据中的共变异。
在SPSS中,进行因子分析的主要步骤包括:数据准备、可行性检验、提取因子、旋转因子和解释因子。
以下是这些步骤的详细说明:-数据准备:确保数据的正确性和合适性。
选择合适的变量,将不适合进行因子分析的变量进行筛选或删除缺失数据。
- 可行性检验:使用Kaiser-Meyer-Olkin(KMO)测度和Bartlett's球数检验来评估因子分析的适用性。
若KMO值大于0.6且Bartlett's球数检验具有统计显著性,则可以进行因子分析。
-提取因子:使用主成分分析或最大似然法等方法,将数据转化为较少的维度。
确定提取的因子数量和数据的维度。
- 旋转因子:使用方差旋转方法(如Varimax)或最大似然法等,使得因子与原始变量之间具有更好的解释性。
-解释因子:根据旋转后的因子载荷矩阵,解释因子的含义并建立因子模型。
2. 对应分析(Correspondence Analysis):对应分析是一种多变量数据分析方法,用于探索分析观察数据的关联性和差异性,特别是在分类数据分析中非常有用。
这一方法可以绘制两个或多个变量之间的关系图,帮助研究者理解变量之间的关联模式和因素。
在SPSS中,进行对应分析的主要步骤包括:数据准备、计算表格、计算相关系数、计算标准化残差、选择模型和解释结果。

第十一章 多元分析:主成分分析与因子分析引言主成分分析和因子分析在多元分析框架内是数据结构分析技术,与第六章的多元回归、第七章的多变量协整一起是多变量分析中广泛使用的技术。
它们不同于多元回归。
回归的目标是识别外生变量与内生变量的关系,而在主成分分析和因子分析情形下,仅确定内生变量间的结构关系。
它们也不像协整,变量间不需要平稳性。
在金融、社会科学或其它领域,通常需要识别多变量结构的特征,其有两个特征是被子广泛关心的:1. 多变量结构中的波动性。
2. 变量间的相关或共线性。
在结构的整体变化中,通常是一些变量起产生主要的影响,而其它变量仅有次要的或不显著的影响。
困难的是要了解哪些变量能被确定在这个结构中和它在结构中应怎样度量。
例如,如果两个变量是完全相关的,则不需要第二个变量,它不会带来进一步的信息。
这类似多元回归的共线问题。
在一般情况下,包含哪个变量,剔除哪个变量并不是很清楚的,我们需要有能够程序化的有效方法来识别带有最可用信息的变量或变量组合。
主成分分析(PCA )是分析多变量结构波动时有用的技术。
因子分析(F A )在分析多变量结构变量的相关时很有用。
两者都依赖于方差/协方差矩阵,因为这个矩阵在一定范围内包含了变量间有用的全部信息。
因此在一定范围内,两者是重复的或相互补充的。
在这章,我们将方差/协方差矩阵记为C 。
尽管PCA 和F A 都利用方差/协方差矩阵,但它们不同于第四章和第九章中的均值—方差分析。
均值—方差分析度量了一组变量的总体变异性,而没有特别指明一部分变量对总变异性的贡献。
PCA 识别和排序了部分变量在总变异性中的贡献,每个部分变量称为“主成分”。
它识别了部分变量间组成的协方差的强度,每个主成分对总的变异性的贡献,并根据部分变量组的方差进行排序。
使用PCA ,数据内的总体变异性由特征值之和(它等于C矩阵主对角线上元素之和,也称为迹)度量,成分(变量的线性组合)的选择是依次序减少特征值,直到满足总变异性的一个足够大的比例。






第8讲因子分析与对应分析因子分析和对应分析是多元统计分析的两个重要方法,可以用于探索和解释多个变量之间的关系。
本文将详细介绍因子分析与对应分析的原理、应用以及在研究中的注意事项。
一、因子分析1.概念与原理因子分析是一种用于降维和检验构念的统计方法,通过分析变量之间的共同变异性,将一组相关变量归纳为几个相互独立的因子。
通过因子分析,可以减少变量的数量,提取出变量集合的共同因素,并进一步应用这些因子进行研究。
2.过程与步骤因子分析的步骤主要包括:确定因子数量、提取因子、旋转因子和解释因子。
首先,需要根据研究的目的和理论基础确定因子的数量;然后,通过主成分分析、最大似然法等方法提取因子;接着,对提取的因子进行旋转,以便更好地解释因子的含义;最后,根据提取和旋转的因子来解释因子的含义和解释力,进行结果的解释。
3.应用与示例因子分析可以应用于研究心理学、社会学、经济学等多个领域。
例如,在心理学中,可以通过因子分析提取出代表不同人格特征的因子,从而研究不同因素对人格的影响。
在市场研究中,可以通过因子分析分析顾客对不同产品特征的偏好,从而为产品定位和市场推广提供参考。
二、对应分析1.概念与原理对应分析是一种描绘和解释两个或多个表格之间关系的统计方法,通过计算表格中元素之间的关联性,找出表格之间的对应关系。
对应分析基于数学原理,可以识别表格中的模式和趋势,并提供对表格元素之间关系的可视化展示。
2.过程与步骤对应分析的过程主要包括:计算对应坐标、分析对应方向和解释对应结果。
首先,通过降维技术(如主成分分析)计算表格中每个元素的对应坐标,即将高维表格转化为低维坐标。
其次,通过对应方向的分析,找出表格之间的对应关系。
最后,根据对应结果,解释表格之间的关联性和趋势。
3.应用与示例对应分析可以应用于研究多个变量之间的关系,如消费者对产品特征的偏好、不同地区的经济发展等。
例如,在市场研究中,可以通过对应分析识别消费者对不同产品特征的偏好,并据此进行市场推广策略。

第十一章因子分析地理模型因子分析因子分析的主要应用1、寻求基本结构、简化观测系统给定一组变量或观测数据,我们要问,变量的维数是否一定需要这么多,是否存在一个子集,特别是一个加权子集,来解释整个问题。
通常采用因子分析法将为数不多的变量减少为几个新因子,以再现它们之间的内在联系。
2、用于分类,将变量或样本进行分类,根据因子得分值,在因子轴所构成的空间中进行分类处理。
因子分析与主成分分析的区别第一节因子分析法的数学模型因子分析的结果完全的因子解因子分析的基本问题是用变量之间的相关系数来决定因子载荷。
因子模型的求解过程如下:设原始数据矩阵为:X =p表示变量数,n表示样本数。
将原始数据进行标准化变换:x ij-x ix ij’=(I=1,2,…p;j=1,2,…n)经标准化变换后的数据,其均值为0,方差为1,这样相关矩阵R和协方差矩阵S完全一样,这里相关矩阵:R=X*X’(为方便计,假定标准化处理后的矩阵仍记为X)。
求解R矩阵的特征方程|R=λI|=0,记特征值为λ1>λ2…>λp>=0,特征向量矩阵为U,这样有关系:R=U U’U为正交矩阵,并且满足U’U=UU’=I令F=U’X,则得FF’=F为主因子阵,并且Fα=U’Xα(α=1,2…n),即每一个Fα为第α个样品主因子观测值。
在因子分析中,通常只选m(m<p)其中主因子。
根据变量的相关选出第一主因子F1,使其在各变量的公共因子方差中所占的方差贡献最大。
R型的因子模型为X1=α11F1+α12F2+…+α1m F m +α1ε 1 X2=α21F1+α22F2+…+α2m F m +α2ε 2 … …X P=αP1F1+αP2F2+…+αPm F m +αmεm在因子模型中2、αij叫因子载荷,它是第I个变量在第j个主因子上的负荷,或者叫第I个变量在第j 个主因子上的权,它反映了第I个变量在第j个主因子上的相对重要性。
如果把x i看成m 维因子空间上的一个向量,则αij表示x i在坐标轴F j上的投影。
因子分析及对应分析因子分析(Factor Analysis)是一种常用的多变量分析方法,用于确定一组观测变量之间的共同因子。
通过因子分析,我们可以找到描述数据变异的较少的变量,从而简化分析和解释数据。
对应分析(Correspondence Analysis)则是一种用于分析分类数据的多元统计方法,能够捕捉各个分类变量之间的关联关系。
因子分析可以用于降维分析,即从原有的一组变量中提取出少数几个“主要成分”来代表原有的变量。
在因子分析中,我们需要先建立起一个数学模型,假设原始的变量与一组不可观测的因子之间存在一种线性关系。
这些因子是一些无法直接测量的潜在变量,但是它们可以通过观测到的一组变量来间接地描述。
通过因子分析,我们可以求得这些潜在因子的权重系数,以及每个观测变量与这些因子之间的相关系数。
然后,我们可以根据这些相关系数来解释原始变量与潜在因子之间的关联关系。
对应分析作为一种非参数的方法,对变数之间的关联关系进行了很好的可视化,并提供了一种直观的方法来分析分类变量之间的关系。
在对应分析中,我们将分类变量转换为数值变量,并绘制一个二维平面,使得各个分类变量之间的距离反映它们之间的相关程度。
通过对应分析,我们可以发现分类变量之间的关联关系,甚至可以发现隐藏在数据背后的一些结构。
对应分析和因子分析的应用领域非常广泛。
在社会科学研究中,因子分析经常用于测量社会心理和个人意识等难以直接观察的潜在因子。
例如,在教育研究中,我们可以通过因子分析来寻找能够解释学生学习成绩差异的潜在因素,以此来改进教育方法和策略。
在市场研究中,因子分析可以用于挖掘消费者之间的共同偏好,从而更好地进行市场定位和产品设计。
对应分析在数据可视化和数据挖掘领域也有广泛的应用。
在信息检索中,对应分析可以用于分析两个文本集合之间的关联关系,从而提高文档的效果。
在社交网络分析中,对应分析可以用于研究用户之间的社交关系和行为模式,通过对用户数据的可视化,可以更好地理解和预测用户的行为。
第十一章因子分析11.1 主要功能11.2 实例操作11.1 主要功能多元分析处理的是多指标的问题。
由于指标太多,使得分析的复杂性增加。
观察指标的增加本来是为了使研究过程趋于完整,但反过来说,为使研究结果清晰明了而一味增加观察指标又让人陷入混乱不清。
由于在实际工作中,指标间经常具备一定的相关性,故人们希望用较少的指标代替原来较多的指标,但依然能反映原有的全部信息,于是就产生了主成分分析、对应分析、典型相关分析和因子分析等方法。
调用Data Reduction菜单的Factor过程命令项,可对多指标或多因素资料进行因子分析。
因子分析的基本目的就是用少数几个因子去描述许多指标或因素之间的联系,即将相关比较密切的几个变量归在同一类中,每一类变量就成为一个因子(之所以称其为因子,是因为它是不可观测的,即不是具体的变量,这与上一章的聚类分析不同),以较少的几个因子反映原资料的大部分信息。
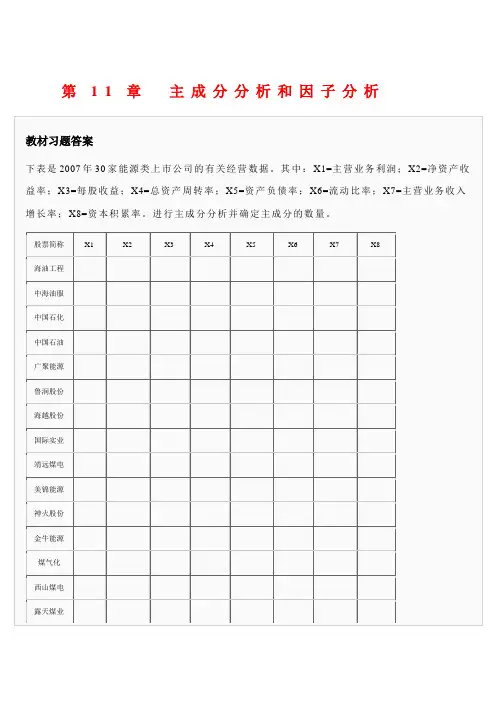
返回目录返回全书目录11.2 实例操作[例11-1]下表资料为25名健康人的7项生化检验结果,7项生化检验指标依次命名为X1至X7,请对该资料进行因子分析。
11.2.1 数据准备激活数据管理窗口,定义变量名:分别为X1、X2、X3、X4、X5、X6、X7,按顺序输入相应数值,建立数据库,结果见图11.1。
图11.1 原始数据的输入11.2.2 统计分析激活Statistics 菜单选Data Reduction 的Factor...命令项,弹出Factor Analysis 对话框(图11.2)。
在对话框左侧的变量列表中选变量X1至X7,点击 钮使之进入Variables 框。
图11.2 因子分析对话框点击Descriptives...钮,弹出Factor Analysis:Descriptives对话框(图11.3),在Statistics中选Univariate descriptives项要求输出各变量的均数与标准差,在Correlation Matrix栏内选Coefficients项要求计算相关系数矩阵,并选KMO and Bartlett’s test of sphericity项,要求对相关系数矩阵进行统计学检验。