系统部署及集群配置(正式)
- 格式:doc
- 大小:3.33 MB
- 文档页数:24

集群的配置步骤一、搭建集群环境的准备工作在开始配置集群之前,我们需要先进行一些准备工作。
首先,确保所有服务器都已经正确连接到网络,并且能够相互通信。
其次,确保每台服务器上已经安装了操作系统,并且操作系统版本一致。
最后,确保每台服务器上已经安装了必要的软件和工具,例如SSH、Java等。
二、创建集群的主节点1.选择一台服务器作为集群的主节点,将其IP地址记录下来。
2.登录到主节点服务器上,安装并配置集群管理软件,例如Hadoop、Kubernetes等。
3.根据集群管理软件的要求,配置主节点的相关参数,例如集群名称、端口号等。
4.启动集群管理软件,确保主节点能够正常运行。
三、添加集群的工作节点1.选择一台或多台服务器作为集群的工作节点,将其IP地址记录下来。
2.登录到工作节点服务器上,安装并配置集群管理软件,确保与主节点的版本一致。
3.根据集群管理软件的要求,配置工作节点的相关参数,例如主节点的IP地址、端口号等。
4.启动集群管理软件,确保工作节点能够正常连接到主节点。
四、测试集群的连接和通信1.在主节点服务器上,使用集群管理软件提供的命令行工具,测试与工作节点的连接和通信。
例如,可以使用Hadoop的hdfs命令测试与工作节点的文件系统的连接。
2.确保主节点能够正确访问工作节点的资源,并且能够将任务分配给工作节点进行处理。
五、配置集群的资源管理1.根据集群管理软件的要求,配置集群的资源管理策略。
例如,可以设置工作节点的CPU和内存的分配比例,以及任务的调度算法等。
2.确保集群能够合理分配资源,并且能够根据需要动态调整资源的分配。
六、监控和管理集群1.安装并配置集群的监控和管理工具,例如Ganglia、Zabbix等。
2.确保监控和管理工具能够正常运行,并能够及时发现和处理集群中的故障和问题。
3.定期对集群进行巡检和维护,确保集群的稳定和可靠性。
七、优化集群的性能1.根据实际情况,对集群的各项参数进行调优,以提高集群的性能和效率。
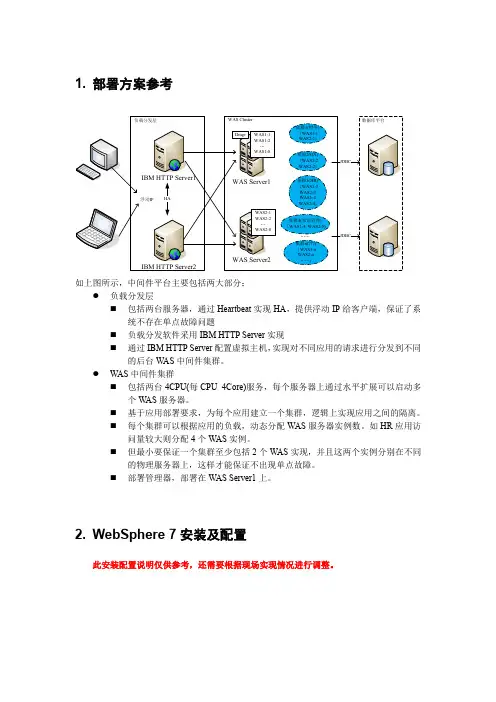
1. 部署方案参考如上图所示,中间件平台主要包括两大部分:●负载分发层⏹包括两台服务器,通过Heartbeat实现HA,提供浮动IP给客户端,保证了系统不存在单点故障问题⏹负载分发软件采用IBM HTTP Server实现⏹通过IBM HTTP Server配置虚拟主机,实现对不同应用的请求进行分发到不同的后台W AS中间件集群。
●WAS中间件集群⏹包括两台4CPU(每CPU 4Core)服务,每个服务器上通过水平扩展可以启动多个W AS服务器。
⏹基于应用部署要求,为每个应用建立一个集群,逻辑上实现应用之间的隔离。
⏹每个集群可以根据应用的负载,动态分配WAS服务器实例数。
如HR应用访问量较大则分配4个WAS实例。
⏹但最小要保证一个集群至少包括2个W AS实现,并且这两个实例分别在不同的物理服务器上,这样才能保证不出现单点故障。
⏹部署管理器,部署在WAS Server1上。
2. WebSphere 7安装及配置此安装配置说明仅供参考,还需要根据现场实现情况进行调整。
2.1.WAS安装一、四台服务器拓朴结构四台机器IP地址,名称与安装内容其中DM控制台管理用户admin,口令两个web服务器的管理用户也是admin,口令二、安装后验收http://**.**.**.**:9060/ibm/console可打开应用服务器主机的控制管理台,管理用户admin,口令******服务器->集群下建有应用集群服务器->应用服务器下建有两个WEB服务节点共有五个,分别是一个控制节点(一个dmgr节点),两个受控节点(两个app节点),两个非受控节点(两个web节点)集群下各受控节点已同步,并启动服务;两个WEB服务已生成插件、传播插件并启动。
在DMGR控制管理台可直接控制两个WEB的启动与停止。
三、安装前系统检查✓群集安装时,确认所有机子的日期要一致✓确认磁盘空间足够两个应用服务器的安装文件放在/was_install两个WEB服务器的安装文件放在/http_install安装目录都是安装于默认的/opt目录下两个应用服务器安装后生成目录/opt/IBM/WebServer/AppServer两个WEB服务器安装后生成目录/opt/IBM/HTTPServer两个WEB服务器的目录/opt/IBM/HTTPServer/plugins放有插件✓确认管理域之内的所有的机器主机名和ip地址相互能够ping通在安装前,要确保四台机的/etc/hosts文件里面增加四台机的ip与主机名,修改如下**.**.**.1 app1**.**.**.2 app2**.**.**.3 web1**.**.**.4 web2(对于初次安装系统后的主机,因为没有在HOSTS文件中增加此类记录,会导致安装失败,现象是安装后生成的profiles不完整,并且startManager.sh执行失败,启动不了管理服务。


服务器上架 (3)上电检查 (3)安装操作系统 (3)配置集群(MSCS) (3)1、单击开始—>程序—>管理工具—>群集管理器,打开群集管理器 (3)2、选择“建立一个新的群集” (4)3、输入群集中的集群名 (4)4、选择集群节点的计算机 (5)5、单击NEXT系统会自动开始配置集群 (5)6、输入集群的虚拟IP (6)7、输入已经设置好的cluster管理用户、密码以及域名 (6)8、验证集群配置 (7)9、配置集群资源 (7)10、第一个节点集群配置完成 (8)11、保持第一节点服务器处于开机状态,开启第二节点服务器 (8)12、输入在第一个节点创建的集群名 (9)13、选择第二个节点的计算机名,点击添加。
(9)14、点击下一步后系统自动分析当前系统配置 (9)15、输入登陆到域的密码 (10)16、验证集群配置 (10)17、验证完后系统自动配置集群服务 (11)18、第二个节点添加完成 (11)19、打开集群管理器后显示两个节点的信息 (12)Oracle8i安装 (13)1、双击安装文件 (13)2、单击下一步开始安装 (13)3、指定oracle8i程序安装名称和路径 (13)4、选安装oracle8i安装版本 (14)5、选择安装类型 (14)6、选择产品组件 (15)7、组件安装位置 (15)8、选择认证方法 (16)9、不创建数据库 (16)10、显示安装摘要 (17)11、开始拷贝安装文件 (17)12、配置Net8 configuration assistant (18)13、解除系统防火墙限制 (18)14、安装结束 (19)Oracle 8i 建库 (19)1、从开始菜单中启动建库程序 (19)2、点击下一步 (20)3、选择要创建数据库类型 (20)4、选择数据库中使用的应用程序类型 (21)5、输入用户并发连接数 (21)6、选择数据库缺省操作模式 (22)7、选择数据库中配置使用选项 (22)8、定义数据库实例名和初始化文件 (23)9、定义数据库控制文件 (23)10、定义数据库表的信息 (24)11、定义重做日志文件 (24)12、复查重做日志参数信息,启用归档日志 (25)13、定义SGA参数 (25)14、定义用户调试跟踪文件 (26)15、指定数据库字符集 (26)16、选现在创建或保存到批处理文件以后运行该批处理文件创建 (27)17、弹出提示宽 (27)18、进行创建数据库 (27)19、数据库创建完成,提示sys和system帐户信息 (28)数据库集群配置 (28)1、打开我的电脑系统属性,设置oracle8i实例环境参数 (28)2、在命令提示符下用oradim命令注册实例服务 (29)3、调整oracle的相关服务为手动 (29)4、开启集群管理器,在共享资源组上新建相应的资源 (30)5、建立oracle实例管理用虚拟IP (30)6、选择运行的节点 (31)7、设置依存关系 (31)8、设置tcp/ip地址参数 (32)9、点击完成,提示创建成功 (32)10创建OracleOraHome81Agent服务,在资源类型中选通用服务 (32)11、选择运行节点 (33)12、设置依存关系 (33)13、设置服务名 (34)14、提示注册表复制 (34)15、点击完成,弹出创建成功提示 (35)16、列出以上步骤创建的资源 (35)17、联机以上创建的资源 (36)18、在该节点中相应的服务自动启动,另外一节点仍是停止状态 (36)19、开启数据库控制台,手动添加虚拟IP实例数据库 (36)20、连接数据库输入相应的用户名和权限 (37)21、连接虚拟IP实例成功 (37)22、在群集管理器中手动移动资源组 (38)23、资源被切换到另外节点 (38)24、重新连接虚拟IP实例 (39)25、重新连接成功 (39)服务器上架利用机架安装套件将服务器及存储设备安装上机柜,并安装理线架,将服务器尾部线缆通过理线架接出。

Redhat6.1使用Luci搭建双机热备(虚拟机环境)一、环境准备T01 虚拟机准备2台Linux系统的虚拟机。
安装时要选自定义安装,最好安装桌面图形化支持的相关插件。
1台Openfile虚拟机,用来提供虚拟你双机热备的存储虚拟环境。
T02 主机端连接存储T02-0101 1.系统挂载tools(如果是VMware等虚拟化环境时,需要执行此步骤。
)mkdir /mnt 创建挂载点mount /dev/sr0 /mnt 拷贝文件到挂载点cd /mntlstar xvzf VM**.tar.gz 解压软件包lscd ./vmware-tools-dis**bls./vm**install.plT02-0102 (iscsi环境)建立连接确保主机与存储的网络已经连通。
(1) 运行命令rpm-qa|grep iscsi,检查Red Hat应用服务器是否已经安装了iSCSI启动器驱动程序。
如果应用服务器上已经安装iSCSI启动器驱动程序,则界面显示类似如下:iscsi-initiator-utils-6.2.0.868-0.7.el5如果没有安装iscsi启动器,则先安装。
根据具体操作系统版本选择相应的安装包。
例如:rpm -ivh iscsi-initiator-utils-6.2.0.742-0.5.el5.i386.rpm2. 配置目标器的IP地址。
[root@RHCS01 ~]# iscsiadm-m discovery-t st–p 10.20.30.63. 登录目标器。
[root@RHCS01 ~]# iscsiadm -m node -p 10.20.30.6 –l4. 设置目标器为自动启动模式。
设置目标器为自动启动模式后,每次应用服务器重新启动后会自动登录与其连接的目标器。
a.运行命令vi/etc/iscsi/iscsid.conf,打开“iscsid.conf”文件。
b.按“i”键,进入编辑模式,编辑“iscsid.conf”文件。

如何进行MySQL集群部署和管理1. 引言在现代的大数据时代,数据库的性能和可扩展性变得更加重要。
MySQL作为最常用的关系型数据库之一,也需要满足高可用和高性能的需求。
为了实现这些需求,MySQL集群部署和管理成为了不可忽视的技术。
2. 什么是MySQL集群MySQL集群是指在多个主机上同时运行MySQL,并通过某种方式进行数据同步和负载均衡的一种配置。
通过将数据库分布到多个节点上,可以提高系统的可用性和性能。
3. MySQL集群部署3.1 设计集群拓扑在部署MySQL集群之前,需要先设计集群的拓扑结构。
一般来说,集群拓扑可以分为主从复制和主从多个节点的方式。
选择哪种方式取决于数据的重要性和负载的情况。
3.2 安装MySQL软件部署MySQL集群的第一步是在每个节点上安装MySQL软件。
可以从官方网站下载MySQL二进制包,然后按照官方文档进行安装和配置。
3.3 配置集群节点配置集群节点包括设置各个节点的IP地址和端口号,并启动MySQL服务。
这些配置必须在集群的每个节点上进行,并确保各个节点之间的网络互通。
3.4 创建数据库用户在MySQL集群中,为了实现数据同步和负载均衡,需要创建专门的数据库用户,并赋予合适的权限。
这些用户将被用于集群中的数据同步和负载均衡的操作。
3.5 启动集群节点当所有节点都完成了配置和用户创建之后,可以启动集群节点。
可以通过启动MySQL服务来实现节点的启动,并通过查看日志文件来确认节点是否成功启动。
4. MySQL集群管理4.1 监控集群状态在正式投入使用之前,需要对MySQL集群进行监控,以确保集群的稳定性和性能。
可以使用MySQL自带的监控工具,如MySQL Enterprise Monitor或Percona Monitoring and Management进行集群状态的实时监测。
4.2 故障检测和恢复在MySQL集群环境中,故障是无法避免的。
当出现故障时,需要及时检测故障并采取相应的恢复措施。

MySQL集群部署与配置指南引言MySQL是一种开源的关系型数据库管理系统,被广泛应用于各种应用程序中。
在处理大规模数据和高并发访问时,单个MySQL服务器可能无法满足需求。
为了提高性能和可用性,使用MySQL集群来部署和配置数据库是一个不错的选择。
本文将详细介绍MySQL集群部署和配置的指南,帮助读者了解集群的概念,并提供一些实用的技巧。
1. 集群概述1.1 什么是MySQL集群MySQL集群是指由多个MySQL服务器组成的集合,通过共享数据和负载均衡来提供高性能和高可用性。
集群中的每个节点都存储相同的数据,并且可以处理来自客户端的查询请求。
如果其中一个节点发生故障,其他节点将继续提供服务,确保数据的有效性和可访问性。
1.2 集群的优势MySQL集群具有以下优势:- 高可用性:即使其中一个节点发生故障,其他节点也可以继续提供服务,避免了单点故障的风险。
- 负载均衡:通过将查询请求分发到不同的节点上,集群可以平衡负载,提高整个系统的性能。
- 扩展性:可以根据需求增加或减少集群节点,以应对不断增长的数据和用户访问量。
- 数据冗余:通过复制数据到多个节点,可以提供数据的冗余备份,避免数据丢失的风险。
2. 部署MySQL集群2.1 硬件要求部署MySQL集群需要考虑以下硬件要求:- 多台服务器:每个节点都需要一个独立的服务器来承载MySQL服务。
- 网络连接:节点之间需要可靠的网络连接,以便进行数据同步和通信。
2.2 软件要求部署MySQL集群还需要满足以下软件要求:- MySQL数据库:每个节点都需要安装并配置MySQL数据库。
- 集群管理软件:可以使用各种集群管理软件,如MySQL Cluster、Galera Cluster或Percona XtraDB Cluster等。
2.3 数据同步配置为了保持每个节点上的数据一致性,需要配置数据同步机制。
可以使用MySQL的复制功能来实现数据同步。
具体步骤如下:- 在一个节点上设置为主节点(master),并启用二进制日志功能。



集群部署方案引言随着互联网的快速发展,越来越多的企业或组织需要构建大规模的系统来应对高并发和大数据量的处理需求。
集群部署方案作为一种解决方案,可以有效地提高系统的可靠性、扩展性和性能。
本文将介绍什么是集群部署方案以及如何选择合适的集群部署方案进行应用。
什么是集群部署方案集群部署是一种将多个计算机组成一个逻辑上相互独立但可以互相通信和协作的集合体的方法。
集群部署可以提供高可用性、高性能和可扩展性,从而提高系统的稳定性和性能。
在集群部署方案中,通常会有一个主节点和多个工作节点。
主节点负责整个集群的管理和协调工作,而工作节点负责执行具体的任务。
通过将任务分散到多个工作节点上进行并行处理,可以提高系统的处理能力和响应速度。
选择集群部署方案的考虑因素在选择集群部署方案时,需要考虑以下几个因素:1. 可用性可用性是指系统在遇到故障或异常情况时能够继续提供服务的能力。
要保证集群的高可用性,需要选择具备故障转移、自动重启和负载均衡等功能的集群部署方案。
2. 性能性能是衡量系统处理能力的指标,对于需要处理大数据量或高并发请求的系统尤为重要。
选择高性能的集群部署方案可以提高系统的响应速度和吞吐量,提升用户体验。
3. 可扩展性可扩展性是指系统能够在需要增加处理能力时进行水平或垂直扩展的能力。
选择具备良好可扩展性的集群部署方案可以使系统更容易进行扩展和升级,以满足不断增长的需求。
4. 系统复杂性部署和管理一个集群系统可能会涉及到复杂的配置和操作,因此选择一个易于使用和管理的集群部署方案非常重要。
简化的部署流程和可视化的管理界面可以降低系统管理的复杂性。
常用的集群部署方案下面介绍几种常用的集群部署方案:1. KubernetesKubernetes是一个开源的容器编排工具,可以自动化地部署、扩展和管理容器化应用程序。
Kubernetes提供了高可用性、负载均衡和自动伸缩等功能,使得应用程序可以在集群环境中弹性地运行。
2. Apache MesosApache Mesos是一个分布式系统内核,可以提供跨集群资源管理和任务调度的功能。

手把手教你安装及配置服务器集群系统今天,我们方案大家谈的经销商为我们提供了安装及配置服务器集群系统的详细步骤。
下面,我们来手把手的教您配置服务器集群系统吧!1.集群服务器安装及配置:1.1 安装Windows Server 2003操作系统在服务器1和服务器2分别独立安装Windows Server 2003操作系统。
安装要开始安装过程,请直接从 Windows Server 2003 CD 启动。
您的 CD-ROM 必须支持可启动的 CD。
注意:在配置分区和格式化驱动器时,服务器硬盘驱动器上的数据均会被破坏。
1.1.1 开始安装安装程序在运行 Windows Server 2003 的计算机中创建磁盘分区,格式化驱动器,然后将安装文件从 CD 复制到服务器上。
注意:这些说明假定在尚未运行 Windows 的计算机上安装 Windows Server 2003。
如果从较早版本的Windows 进行升级,某些安装步骤可能会有所不同。
详细步骤如下:1.将“Windows Server 2003 CD”插入 CD-ROM 驱动器。
2.“重新启动”计算机。
在出现提示时,按任意键从 CD 启动。
此时将开始安装 Windows Server 2003。
3.在“欢迎使用安装程序”屏幕上,按“Enter”键。
4.阅读许可协议,如果接受的话,请按“F8”键。
注意:如果此服务器上已安装了较早版本的 Windows Server 2003,则可能会出现一条消息,询问您是否要修复驱动器。
按“Esc”键,继续进行安装而不修复驱动器。
5.按照说明进行操作,删除所有现有的磁盘分区。
具体步骤可能会因计算机上现有分区的数量和类型而异。
继续删除分区,直至所有磁盘空间均标记为“未划分的空间”为止。
6.在将所有磁盘空间均标记为“未划分的空间”后,按“C”键,在第一个磁盘驱动器的未划分空间中创建一个分区(如果适用)。
7.在出现“创建磁盘分区大小(单位 MB)”提示时,键入20480,然后按“Enter”键。
Hadoop集群配置(最全⾯总结)通常,集群⾥的⼀台机器被指定为 NameNode,另⼀台不同的机器被指定为JobTracker。
这些机器是masters。
余下的机器即作为DataNode也作为TaskTracker。
这些机器是slaves\1 先决条件1. 确保在你集群中的每个节点上都安装了所有软件:sun-JDK ,ssh,Hadoop2. Java TM1.5.x,必须安装,建议选择Sun公司发⾏的Java版本。
3. ssh 必须安装并且保证 sshd⼀直运⾏,以便⽤Hadoop 脚本管理远端Hadoop守护进程。
2 实验环境搭建2.1 准备⼯作操作系统:Ubuntu部署:Vmvare在vmvare安装好⼀台Ubuntu虚拟机后,可以导出或者克隆出另外两台虚拟机。
说明:保证虚拟机的ip和主机的ip在同⼀个ip段,这样⼏个虚拟机和主机之间可以相互通信。
为了保证虚拟机的ip和主机的ip在同⼀个ip段,虚拟机连接设置为桥连。
准备机器:⼀台master,若⼲台slave,配置每台机器的/etc/hosts保证各台机器之间通过机器名可以互访,例如:10.64.56.76 node1(master)10.64.56.77 node2 (slave1)10.64.56.78 node3 (slave2)主机信息:机器名 IP地址作⽤Node110.64.56.76NameNode、JobTrackerNode210.64.56.77DataNode、TaskTrackerNode310.64.56.78DataNode、TaskTracker为保证环境⼀致先安装好JDK和ssh:2.2 安装JDK#安装JDK$ sudo apt-get install sun-java6-jdk1.2.3这个安装,java执⾏⽂件⾃动添加到/usr/bin/⽬录。
验证 shell命令:java -version 看是否与你的版本号⼀致。
linux服务器集群的详细配置一、计算机集群简介计算机集群简称集群是一种计算机系统, 它通过一组松散集成的计算机软件和/或硬件连接起来高度紧密地协作完成计算工作;在某种意义上,他们可以被看作是一台计算机;集群系统中的单个计算机通常称为节点,通常通过局域网连接,但也有其它的可能连接方式;集群计算机通常用来改进单个计算机的计算速度和/或可靠性;一般情况下集群计算机比单个计算机,比如工作站或超级计算机性能价格比要高得多;二、集群的分类群分为同构与异构两种,它们的区别在于:组成集群系统的计算机之间的体系结构是否相同;集群计算机按功能和结构可以分成以下几类:高可用性集群 High-availability HA clusters负载均衡集群 Load balancing clusters高性能计算集群 High-performance HPC clusters网格计算 Grid computing高可用性集群一般是指当集群中有某个节点失效的情况下,其上的任务会自动转移到其他正常的节点上;还指可以将集群中的某节点进行离线维护再上线,该过程并不影响整个集群的运行;负载均衡集群负载均衡集群运行时一般通过一个或者多个前端负载均衡器将工作负载分发到后端的一组服务器上,从而达到整个系统的高性能和高可用性;这样的计算机集群有时也被称为服务器群Server Farm; 一般高可用性集群和负载均衡集群会使用类似的技术,或同时具有高可用性与负载均衡的特点;Linux虚拟服务器LVS项目在Linux操作系统上提供了最常用的负载均衡软件;高性能计算集群高性能计算集群采用将计算任务分配到集群的不同计算节点而提高计算能力,因而主要应用在科学计算领域;比较流行的HPC采用Linux操作系统和其它一些免费软件来完成并行运算;这一集群配置通常被称为Beowulf集群;这类集群通常运行特定的程序以发挥HPC cluster的并行能力;这类程序一般应用特定的运行库, 比如专为科学计算设计的MPI 库集群特别适合于在计算中各计算节点之间发生大量数据通讯的计算作业,比如一个节点的中间结果或影响到其它节点计算结果的情况;网格计算网格计算或网格集群是一种与集群计算非常相关的技术;网格与传统集群的主要差别是网格是连接一组相关并不信任的计算机,它的运作更像一个计算公共设施而不是一个独立的计算机;还有,网格通常比集群支持更多不同类型的计算机集合;网格计算是针对有许多独立作业的工作任务作优化,在计算过程中作业间无需共享数据;网格主要服务于管理在独立执行工作的计算机间的作业分配;资源如存储可以被所有结点共享,但作业的中间结果不会影响在其他网格结点上作业的进展;三、linux集群的详细配置下面就以WEB服务为例,采用高可用集群和负载均衡集群相结合;1、系统准备:准备四台安装Redhat Enterprise Linux 5的机器,其他node1和node2分别为两台WEB服务器,master作为集群分配服务器,slave作为master的备份服务器;所需软件包依赖包没有列出:2、IP地址以及主机名如下:3、编辑各自的hosts和network文件mastervim /etc/hosts 添加以下两行vim /etc/sysconfig/networkHOSTNAME= slavevim /etc/hosts 添加以下两行vim /etc/sysconfig/network HOSTNAME= node1vim /etc/hosts 添加以下两行vim /etc/sysconfig/network HOSTNAME= node2vim /etc/hosts 添加以下两行vim /etc/sysconfig/networkHOSTNAME= 注:为了实验过程的顺利,请务必确保network文件中的主机名和hostname命令显示的主机名保持一致,由于没有假设DNS服务器,故在hosts 文件中添加记录;4、架设WEB服务,并隐藏ARPnode1yum install httpdvim /var//html/添加如下信息:This is node1.service httpd startelinks 访问测试,正确显示&nbs隐藏ARP,配置如下echo 1 >> /proc/sys/net/ipv4/conf/lo/arp_ignoreecho 1 >> /proc/sys/net/ipv4/conf/all/arp_ignore echo 2 >> /proc/sys/net/ipv4/conf/lo/arp_announce echo 2 >> /proc/sys/net/ipv4/conf/all/arp_announce ifconfig lo:0 netmask broadcast uproute add -host dev lo:0node2yum install httpdvim /var//html/添加如下信息:This is node2.service httpd startelinks 访问测试,正确显示隐藏ARP,配置如下echo 1 >> /proc/sys/net/ipv4/conf/lo/arp_ignore echo 1 >> /proc/sys/net/ipv4/conf/all/arp_ignore echo 2 >> /proc/sys/net/ipv4/conf/lo/arp_announce echo 2 >> /proc/sys/net/ipv4/conf/all/arp_announceifconfig lo:0 netmask broadcast uproute add -host dev lo:0mastervim /var//html/添加如下内容:The service is bad.service httpd startslavevim /var//html/添加如下内容:The service is bad.service httpd start5、配置负载均衡集群以及高可用集群小提示:使用rpm命令安装需要解决依赖性这一烦人的问题,可把以上文件放在同一目录下,用下面这条命令安装以上所有rpm包:yum --nogpgcheck -y localinstall .rpmmastercd /usr/share/doc/ cp haresources authkeys /etc/cd /usr/share/doc/ cp /etccd /etcvim开启并修改以下选项:debugfile /var/log/ha-debuglogfile /var/log/ha-logkeepalive 2deadtime 30udpport 694bcast eth0增加以下两项:node node vim haresources增加以下选项:ldirectord::/etc/为/etc/authkeys文件添加内容echo -ne "auth 1\n1 sha1 "注意此处的空格 >> /etc/authkeysdd if=/dev/urandom bs=512 count=1 | openssl md5 >> /etc/authkeys &nbs更改key文件的权限chmod 600 /etc/authkeysvim /etc/修改如下图所示:slave 注:由于slave的配置跟master配置都是一样的可以用下面的命令直接复制过来,当然想要再练习的朋友可以自己手动再配置一边;scp root:/etc/{,haresources} /etc/输入的root密码scp root:/etc/ /etc输入的root密码6、启动heartbeat服务并测试master & slaveservice heartbeat start这里我就我的物理机作为客户端来访问WEB服务,打开IE浏览器这里使用IE浏览器测试,并不是本人喜欢IE,而是发现用google浏览器测试,得出的结果不一样,具体可能跟两者的内核架构有关,输入,按F5刷新,可以看到三次是2,一次是1,循环出现;7、停止主服务器,再测试其访问情况masterifdown eth0再次访问,可以看到,服务器依然能够访问;。
数据库集群的部署与管理步骤详解数据库集群是一种将多个独立的数据库服务器连接在一起的系统,通过共享数据和负载均衡来提高性能和可靠性。
在企业中,数据库集群的部署和管理非常重要,对于确保数据的安全性和可用性至关重要。
本文将详细介绍数据库集群的部署和管理步骤。
一. 部署数据库集群1. 需求分析与规划在部署数据库集群之前,需要进行需求分析与规划。
确定需要部署的数据库类型,数据量估计,可用性和容错性要求等。
同时,还需要考虑硬件资源和网络环境等因素。
2. 选取合适的数据库管理系统(DBMS)根据需求和规划,选择适合的数据库管理系统。
目前常用的数据库管理系统有MySQL、Oracle、SQL Server等。
选择合适的DBMS是确保数据库集群稳定运行的前提。
3. 配置硬件资源为数据库集群配置合适的硬件资源非常重要。
包括服务器类型、处理器、内存和存储设备等。
要确保硬件资源能够满足数据库集群所需的性能和容量要求。
4. 安装和配置数据库软件按照DBMS的安装指南,安装和配置数据库软件。
数据库软件安装完成后,需要根据需求进行相应的参数配置,如内存大小、连接数等。
5. 设计数据库架构根据需求和规划,设计数据库架构。
包括确定数据库的结构、表的关系和索引等。
设计好的数据库架构能够提高数据库的查询效率和数据存储的可靠性。
6. 数据库初始化和同步在数据库集群中的每个节点上执行数据库初始化操作。
通过主节点将数据同步到其他节点,确保数据的一致性。
7. 配置负载均衡配置负载均衡是实现数据库集群高可用性和性能增强的重要步骤。
常用的负载均衡策略有轮询、最小连接数和故障转移等。
8. 配置备份与恢复数据库集群的备份与恢复策略对于数据的安全性和可用性至关重要。
可以使用物理备份、逻辑备份或者增量备份来保护数据库的完整性和可靠性。
二. 管理数据库集群1. 监控集群状态建立合适的监控系统来实时监控数据库集群的状态。
包括服务可用性、性能指标和容量等。
及时发现潜在的问题和瓶颈,进行预警和调整。
Hadoop集群的搭建和配置Hadoop是一种分布式计算框架,它可以解决大数据处理和分析的问题。
Hadoop由Apache软件基金会开发和维护,它支持可扩展性、容错性、高可用性的分布式计算,并且可以运行在廉价的硬件设备上。
Hadoop集群的搭建和配置需要多个步骤,包括安装Java环境、安装Hadoop软件、配置Hadoop集群、启动Hadoop集群。
以下是这些步骤的详细说明。
第一步:安装Java环境Hadoop运行在Java虚拟机上,所以首先需要安装Java环境。
在Linux系统下,可以使用以下命令安装Java环境。
sudo apt-get install openjdk-8-jdk在其他操作系统下,安装Java环境的方式可能有所不同,请查阅相应的文档。
第二步:安装Hadoop软件Hadoop可以从Apache官方网站上下载最新版本的软件。
下载后,解压缩到指定的目录下即可。
解压缩后的目录结构如下:bin/:包含了Hadoop的可执行文件conf/:包含了Hadoop的配置文件lib/:包含了Hadoop的类库文件sbin/:包含了Hadoop的系统管理命令share/doc/:包含了Hadoop的文档第三步:配置Hadoop集群配置Hadoop集群需要编辑Hadoop的配置文件。
其中最重要的是hadoop-env.sh、core-site.xml、hdfs-site.xml和mapred-site.xml。
hadoop-env.sh:这个文件定义了Hadoop集群的环境变量。
用户需要设置JAVA_HOME、HADOOP_HOME等环境变量的值。
core-site.xml:这个文件定义了Hadoop文件系统的访问方式。
用户需要设置、hadoop.tmp.dir等参数的值。
hdfs-site.xml:这个文件定义了Hadoop分布式文件系统的配置信息。
用户需要设置.dir、dfs.data.dir等参数的值。
标准hadoop集群配置Hadoop是一个开源的分布式存储和计算框架,由Apache基金会开发。
它提供了一个可靠的、高性能的数据处理平台,可以在大规模的集群上进行数据存储和处理。
在实际应用中,搭建一个标准的Hadoop集群是非常重要的,本文将介绍如何进行标准的Hadoop集群配置。
1. 硬件要求。
在搭建Hadoop集群之前,首先需要考虑集群的硬件配置。
通常情况下,Hadoop集群包括主节点(NameNode、JobTracker)和从节点(DataNode、TaskTracker)。
对于主节点,建议配置至少16GB的内存和4核以上的CPU;对于从节点,建议配置至少8GB的内存和2核以上的CPU。
此外,建议使用至少3台服务器来搭建Hadoop集群,以确保高可用性和容错性。
2. 操作系统要求。
Hadoop可以在各种操作系统上运行,包括Linux、Windows和Mac OS。
然而,由于Hadoop是基于Java开发的,因此建议选择Linux作为Hadoop集群的操作系统。
在实际应用中,通常选择CentOS或者Ubuntu作为操作系统。
3. 网络配置。
在搭建Hadoop集群时,网络配置非常重要。
首先需要确保集群中的所有节点能够相互通信,建议使用静态IP地址来配置集群节点。
此外,还需要配置每台服务器的主机名和域名解析,以确保节点之间的通信畅通。
4. Hadoop安装和配置。
在硬件、操作系统和网络配置完成之后,接下来就是安装和配置Hadoop。
首先需要下载Hadoop的安装包,并解压到指定的目录。
然后,根据官方文档的指导,配置Hadoop的各项参数,包括HDFS、MapReduce、YARN等。
在配置完成后,需要对Hadoop集群进行测试,确保各项功能正常运行。
5. 高可用性和容错性配置。
为了确保Hadoop集群的高可用性和容错性,需要对Hadoop集群进行一些额外的配置。
例如,可以配置NameNode的热备份(Secondary NameNode)来确保NameNode的高可用性;可以配置JobTracker的热备份(JobTracker HA)来确保JobTracker的高可用性;可以配置DataNode和TaskTracker的故障转移(Failover)来确保从节点的容错性。
系统部署及集群配置
手册
版本:1.1
变更记录
1引言
1.1 编写目的
新HD是集群部署,所以在HD上线的时候我才有机会我目睹了部署的整个过程,所以编写一份集群部署的文档来和大家分享,也希望大家多提意见。
2安装系统、存储设置
2.1 服务器配置
现有设备HP服务器两台,首先是给服务器安装windows2008系统。
注意事项:HP服务器的特点是要先安装驱动,然后系统会提示插入系统盘,会自动将系统盘上的数据存入复制到服务器上的硬盘,然后再安装系统。
2.2 存储设置
2.2.1存储布线
电源线:将电源线插头插入到各电源装置中的插座中。
LAN连接线:以太网LAN电缆连接到控制器#0或控制器#1上的LAN管
理端口中另一端连接到管理控制台上的LAN端口。
*
10.0.0.16/10.0.0.17是无法改变的。
正常情况下请使用管理端口,连接时准备两条网线,将两个控制器同时联入内部局域网进行带外管理。
2.2.2存储设置
2.2.2.1安装管理软件
从随机光盘中找到对应版本的 Storage Navigator Modular2 安装程序,这里是“HSNM2-0600-W-GUI-P01.exe” ,双击该程序,安装默认安装即可。
2.2.2.2安装和配置JA V A
首先要删除管理PC上存留的所有java版本及所有的安装目录和文件,检查JAVA 目录下只有唯一的JAVA版本,并确保“添加/删除程序”中也只有唯一的JAVA 版本。
设置临时文件不要保留在计算机上。
将JAVA Runtime参数设置成:-Xmx192m
2.2.2.3登录管理软件
在管理PC上运行web浏览器,在地址栏输入:
http://<IP address>:23015/StorageNavigatorModular/
其中 <IP address> 是管理PC的 IPv4 地址。
http://127.0.0.1:23015/StorageNavigatorModular/Login
USER ID:system
Password: manager
2.2.2.4添加阵列
①点击“Add Array”出现添加阵列向导,点击“next”。
②输入阵列两个控制器默认的管理IP(192.168.0.16 / 192.168.0.17),点击“Finish”。
③阵列列表窗口中出现刚才添加的阵列。
2.2.2.5创建RAID组
①按次序选择“Groups”“RAID Groups”,点击右侧窗口下方的“Create RG”。
②根据实际情况作出合适的选择:RAID级别,如RAID5;
Parity Group,如8D+1P,表示由8块磁盘组成的RAID组,8块数据盘+1块校验盘;Drives,如自动还是手动。
选择自动,系统根据硬盘的ID由小到大自动选择合适数量的磁盘;
选择手动,挑选上(勾上)合适数量和类型的硬盘然后。
确认后,点击“OK”。
③右侧的RG菜单中会出现新添加的RAID Group。
2.2.2.6创建Logical Unit
①按次序选择“Groups”“RAID Groups”“Logic Units”,点击右侧窗口下方的“Create LU”。
②根据实际情况作出合适的选择:
Basic中Capacity,是选择LU的容量。
Advanced中Stripe Size默认是256KB,可以根据需要进行调整;默认情况下,Format是勾选的,创建完成之后会自行进行格式化;
2.2.2.7设置LU的映射打开“Mapping Mode”
①按次序选择“Settings”“Advanced Settings”,点击右侧窗口的“Open Advanced Setting”
②在出现的“Advanced Setting”里,按次序选择“Access Mode” “Mapping Mode”,点击窗口右下方的“Modify”,把映射模式更改为“Enable”
③激活各端口的“Host Group Security”
按次序选择“Groups”“Host Groups”“Host Group Security”,选中第一个Port,点击窗口右下方的“Change Host Group Security”,把该端口对应的“Host Group Security”更改为“Enable”。
同样的方法,依次把所有的端口对应的“Host Group Securit y”都更改为“Enable”。
2.2.2.8根据连结方式选择端口的参数
①按次序选择“Settings”“FC Settings”,可以看到当前系统所有端口的设置情况。
②如果需要更改端口的设置,点击上图窗口右侧的某个端口后,右上角会出现“Edit FC Port”按钮。
③点击“Edit FC Port”按钮,进入该端口的设置界面。
④Topology:主机和存储如果通过交换机连结,选择“P oint-to-Point”;如果直连,选择“Loop
2.2.2.9选择主机的操作系统类型和模式设置
2.2.2.10光纤端口设置
按次序选择“Settings”“FC Settings”,可以看到当前系统所有端口的设置情况
2.2.2.11Spare Drives设置热备磁盘
2.2.2.12在服务器上查看磁盘管理出现新的硬盘,进行分区格式化
3集群配置
3.1 配置windows2008故障集群
3.1.1准备工作
首先把服务器、存储放到有域环境的网络中,这里我们放到了机房。
布线:
电源线:将电源线插头插入到各电源装置中的插座中。
网线:每台服务器上有三个网线插口,网线分别连接服务器与交换机、服务器与服务器(心跳线ip:10.0.0.1)、服务器与存储(ISCSI)。
3.2服务器分别加入域管理
3.2.1服务器加入域管理
步骤:我的电脑—右键属性—计算机名—更改---隶属于域
3.3配置windows2008故障集群
3.3.1安装故障转移集管理器
①打开服务管理器:
②点击添加功能,点选故障转移集群,点击下一步
③在向导最后,点击安装。
3.3.2验证集群配置
在创建集群之前,运行验证集群配置,确认服务器、网络、存储是否符合要求。
①开始—管理工具—故障转移集群管理,打开故障转移集群管理单元
②在管理界面的中间位置,点击验证配置
③点击下一步,添加节点服务器
④检查完毕后,可以点击查看报告,也可以到C:\Windows\Cluster\Reports路径下去查看。
3.3.3建立集群
①开始——管理工具——故障转移集群管理,打开故障转移集群管理单元
②在中间位置点击创建一个集群
③点击下一步,添加集群内的节点服务器
填入集群名称和使用的虚拟IP地址,途中10段的ip地址用来连接iSCSI存储,可以将其去掉。
在生产环境的IP地址段,选择一个空闲IP当做集群的IP地址
确认之后,点击下一步继续,则开始创建集群
3.3.4添加存储:
3.3.5设置仲裁
步骤:打开故障转移集群管理器-选中集群节点—右键—更多操作—配置集群仲裁设置
3.3.6设置共享存储
打开故障转移集群--点击右侧“存储”项--选择右侧的“添加磁盘”功能
将节点中新添加的iSCSI存储添加到集群存储,并修改磁盘名称为SQL
3.3.7添加分布式事务处理集群化
①打开故障转移集群管理器,点击配置服务或应用程序
②选择添加“分布式事物协调器”进行添加
③下一步
3.4集成安装SQL server 2008
SQL Server集群要安装在共享磁盘上。
3.4.1安装sqlserver
①在弹出的安装界面中,选择新的SQL Server 故障转移集群
②通过安装检测
③点击安装,安装支持文件
④选择要安装SQL功能,选择全部数据库引擎服务
⑤创建实例名为SQL2008的数据库,并填写集SQL群网络名
⑥选择创建SQL Server资源组,名称为SQL Server(SQL2008)
⑦选择集群可用的SQL作为集群磁盘,此磁盘不用添加到集群共享卷中,作为网络磁
盘,只要添加到集群中,并在系统中可见即可。
正在被使用的磁盘不能选择
⑧指定集群的网络配置
⑨配置集群安全策略,本例为了方便都是用域管理组。
但是推荐在域内分别建立数据库引擎组、和SQL Server代理组。
例如在域内建立SQLadmin用户、SQLAgent组、SQLEngine
组,SQl隶属于这两个组,并且将sqladmin添加到个节点本地管理员组中
⑩指定SQL服务账户
11使用混合身份验证、配置数据库存储路径为之前添加的共享磁盘SQL“I:\SQLDarta
12检查通过,进行安装
13等待安装
打开故障转移集群管理器,我们可以看见SQL集群应用的一个节点已经存在了。