rfc4978.The IMAP COMPRESS Extension
- 格式:pdf
- 大小:13.67 KB
- 文档页数:9

imaplib解析authentication-results -回复IMAPlib解析authenticationresultsIMAPlib是Python标准库中提供的一个模块,用于实现基于IMAP (Internet Mail Access Protocol)协议的邮件访问功能。
IMAP协议允许用户通过远程服务器来访问和管理邮件,而不需要将邮件下载到本地。
在使用IMAPlib进行邮件访问时,常常需要进行身份验证(authentication),以确保只有授权用户能够访问邮件。
本文将深入探讨IMAPlib解析authenticationresults的过程。
首先,我们需要了解什么是authenticationresults。
在IMAP协议中,当客户端向服务器发送身份验证请求时,服务器将返回一个authenticationresults的响应。
这个响应包含了关于身份验证结果的信息,以指示该请求是否成功以及授权用户的权限。
通过解析这个authenticationresults,我们可以判断身份验证是否成功,以及进一步处理邮件的访问。
在使用IMAPlib进行身份验证时,我们需要首先建立与IMAP服务器的连接。
可以使用IMAPlib的IMAP4或IMAP4_SSL类来实现连接。
其中,IMAP4_SSL类使用了加密连接,提高了安全性。
连接建立后,我们需要通过login()方法来进行身份验证。
login()方法需要传入邮箱账号和密码作为参数,以便验证用户身份。
一旦身份验证请求被发送,服务器将返回一个authenticationresults响应。
我们可以使用IMAPlib的response()方法来获取这个响应。
response()方法返回的是服务器对最近一条指令的响应,以一个(响应代码,响应数据)的元组形式返回。
在获取authenticationresults响应后,我们需要解析这个响应以获得更具体的信息。

Could Not Find Acceptable RepresentationIntroductionThe phrase “could not find acceptable representation” often refers to a situation where a client or user agent encounters an error whiletrying to access or retrieve a resource from a server. This error typically occurs when the server is unable to provide a suitable representation of the requested resource in a format that the client can understand or accept. In this article, we will explore the reasons behind this error and discuss possible solutions to resolve it.Understanding the ErrorWhen a client sends a request to a server, it includes information about the desired representation of the resource. This can be in the form of a content type, language preference, or any other specific requirements. The server then processes this information and attempts to find an acceptable representation that matches the client’s criteria.However, there are several scenarios where the server may fail to find an acceptable representation:1.Unsupported Content Type: If the client requests a specificcontent type that the server does not support or cannot generate, the server will be unable to provide an acceptable representation.nguage Mismatch: If the client specifies a preferred languagefor the response, but the server does not have a representationavailable in that language, the error may occur.3.Encoding Issues: If the server cannot encode the requestedresource in a format that the client can understand or accept, the error may be encountered.4.Negotiation Failure: Content negotiation is the process ofselecting the best representation of a resource based on theclien t’s preferences and the server’s capabilities. Ifnegotiation fails, the server may not be able to find anacceptable representation.To resolve the “could not find acceptable representation” error, both the client and server can take certain steps:Client-side Solutions1.Check Request Headers: The client should ensure that the requestheaders accurately specify the desired representation, contenttype, and language preferences. Reviewing and correcting anyerrors in the request headers can help the server find anacceptable representation.2.Broaden Acceptable Formats: If the client specifies a veryspecific content type, consider broadening the acceptable formats to increase the chances of finding an acceptable representation.For example, instead of requesting a specific image format, allow for multiple image formats.nguage Flexibility: If language preferences are causing theerror, the client can consider being more flexible with therequested language. Alternatively, the client can request a listof available languages from the server and select an acceptableone.Server-side Solutions1.Content Type Support: If the server does not support the requestedcontent type, it can be updated to include the necessary libraries or configurations to generate the desired representation.nguage Support: If the server does not have a representationavailable in the requested language, it can be updated to include translations or localization for the desired languages.3.Encoding Compatibility: The server should ensure that it canencode the requested resource in a format that the client canaccept. This may involve updating the server’s encodingcapabilities or providing alternate encodings for the resource.4.Negotiation Mechanisms: The server can implement robust contentnegotiation mechanisms to improve the chances of finding anacceptable representation. This may involve considering multiplefactors such as content type, language, and encoding preferences.The “could not find acceptable representation” error occurs when a server is unable to provide a suitable representation of a requested resource. This can happen due to unsupported content types, language mismatches, encoding issues, or negotiation failures. By following the suggested solutions, both clients and servers can work together to overcome this error and ensure successful resource retrieval. It is essential for developers and system administrators to understand the causes and solutions to this error to provide a better user experience and improve the interoperability of web applications.。

foxmail常见故障及排除1、Foxmail发送邮件时提示错误535:分析:一般是身份验证失败,确认你的邮件服务器发送邮件是需要身份验证的,你可以尝试检查一下你的权限设置,看看你的属性中的“SMTP服务器需要身份验证”复选框是否已经选中。
如用户选中该复选框仍提示该错误,请检查用户账号和密码是否和OA相一致。
2、Foxmail发送邮件时提示错误552:分析:foxmail提示552时一般为原因为:发送的信件大小超过了邮件系统允许接收的最大限制。
●发送的信件大小超过了用户允许接收的最大限制。
●收件人邮箱已满,您可以发送小于1KB的信件提醒收件人。
●发送的信件大小小于系统允许接收的最小限制。
(公司未启用)3、服务器超容造成收发不了:一般提示:unable to write to database because database would exceed its disk quota。
故障原因:无法写入数据库,因为数据库将超过其磁盘配额解决方法:进入OA中的电子邮件,将OA中的电子邮件清理并压缩到限额以下4、服务器返回“550: Invalid User”、“550:local user only”或者“551 delivery not allowed to non-local recipient”。
1)、如果出现在您使用普通方式发送邮件时,这是由于服务器对发件人地址进行检查,对于发件人地址不是由本服务器提供的邮件,不予已发送。
解决的办法是:打开Foxmail“帐户属性”中对话框,在“个人信息”的“电子邮件地址”中填写SMTP服务器正确的邮件地址。
如果该提示出现在您使用特快专递发送邮件时,则表明对方的邮件服务器不接收这种特快专递的投递方式,请针对这次发送改用普通的方式。
2)、如果收信人为中国大陆以外时,出现这种错误,可能为邮件的数据传输过程中邮件内容受“国家公共网络监控系统(GFW,The Great Fire Wall of China)”的过滤所导致的错误.,由于我们无法与GFW联系去告诉他们GFW发生了错误,所以我们能做的就只有等待GFW自己发现并解决我们的问题。

Network Working Group R. Housley Request for Comments: 5652 Vigil Security Obsoletes: 3852 September 2009 Category: Standards TrackCryptographic Message Syntax (CMS)AbstractThis document describes the Cryptographic Message Syntax (CMS). This syntax is used to digitally sign, digest, authenticate, or encryptarbitrary message content.Status of This MemoThis document specifies an Internet standards track protocol for the Internet community, and requests discussion and suggestions forimprovements. Please refer to the current edition of the "InternetOfficial Protocol Standards" (STD 1) for the standardization stateand status of this protocol. Distribution of this memo is unlimited. Copyright and License NoticeCopyright (c) 2009 IETF Trust and the persons identified as thedocument authors. All rights reserved.This document is subject to BCP 78 and the IETF Trust’s LegalProvisions Relating to IETF Documents(/license-info) in effect on the date ofpublication of this document. Please review these documentscarefully, as they describe your rights and restrictions with respect to this document. Code Components extracted from this document must include Simplified BSD License text as described in Section 4.e ofthe Trust Legal Provisions and are provided without warranty asdescribed in the BSD License.This document may contain material from IETF Documents or IETFContributions published or made publicly available before November10, 2008. The person(s) controlling the copyright in some of thismaterial may not have granted the IETF Trust the right to allowmodifications of such material outside the IETF Standards Process.Without obtaining an adequate license from the person(s) controlling the copyright in such materials, this document may not be modifiedoutside the IETF Standards Process, and derivative works of it maynot be created outside the IETF Standards Process, except to formatit for publication as an RFC or to translate it into languages other than English.Housley Standards Track [Page 1]Table of Contents1. Introduction (3)1.1. Evolution of the CMS (4)1.1.1. Changes Since PKCS #7 Version 1.5 (4)1.1.2. Changes Since RFC 2630 (4)1.1.3. Changes Since RFC 3369 (5)1.1.4. Changes Since RFC 3852 (5)1.2. Terminology (5)1.3. Version Numbers (6)2. General Overview (6)3. General Syntax (7)4. Data Content Type (7)5. Signed-data Content Type (8)5.1. SignedData Type (9)5.2. EncapsulatedContentInfo Type (11)5.2.1. Compatibility with PKCS #7 (12)5.3. SignerInfo Type (13)5.4. Message Digest Calculation Process (16)5.5. Signature Generation Process (16)5.6. Signature Verification Process (17)6. Enveloped-Data Content Type (17)6.1. EnvelopedData Type (18)6.2. RecipientInfo Type (21)6.2.1. KeyTransRecipientInfo Type (22)6.2.2. KeyAgreeRecipientInfo Type (23)6.2.3. KEKRecipientInfo Type (25)6.2.4. PasswordRecipientInfo Type (26)6.2.5. OtherRecipientInfo Type (27)6.3. Content-encryption Process (27)6.4. Key-Encryption Process (28)7. Digested-Data Content Type (28)8. Encrypted-Data Content Type (29)9. Authenticated-Data Content Type (30)9.1. AuthenticatedData Type (31)9.2. MAC Generation (33)9.3. MAC Verification (34)10. Useful Types (34)10.1. Algorithm Identifier Types (35)10.1.1. DigestAlgorithmIdentifier (35)10.1.2. SignatureAlgorithmIdentifier (35)10.1.3. KeyEncryptionAlgorithmIdentifier (35)10.1.4. ContentEncryptionAlgorithmIdentifier (36)10.1.5. MessageAuthenticationCodeAlgorithm (36)10.1.6. KeyDerivationAlgorithmIdentifier (36)10.2. Other Useful Types (36)10.2.1. RevocationInfoChoices (36)10.2.2. CertificateChoices (37)Housley Standards Track [Page 2]10.2.3. CertificateSet (38)10.2.4. IssuerAndSerialNumber (38)10.2.5. CMSVersion (39)10.2.6. UserKeyingMaterial (39)10.2.7. OtherKeyAttribute (39)11. Useful Attributes (39)11.1. Content Type (40)11.2. Message Digest (40)11.3. Signing Time (41)11.4. Countersignature (42)12. ASN.1 Modules (43)12.1. CMS ASN.1 Module (44)12.2. Version 1 Attribute Certificate ASN.1 Module (51)13. References (52)13.1. Normative References (52)13.2. Informative References (53)14. Security Considerations (54)15. Acknowledgments (56)1. IntroductionThis document describes the Cryptographic Message Syntax (CMS). This syntax is used to digitally sign, digest, authenticate, or encryptarbitrary message content.The CMS describes an encapsulation syntax for data protection. Itsupports digital signatures and encryption. The syntax allowsmultiple encapsulations; one encapsulation envelope can be nestedinside another. Likewise, one party can digitally sign somepreviously encapsulated data. It also allows arbitrary attributes,such as signing time, to be signed along with the message content,and it provides for other attributes such as countersignatures to be associated with a signature.The CMS can support a variety of architectures for certificate-based key management, such as the one defined by the PKIX (Public KeyInfrastructure using X.509) working group [PROFILE].The CMS values are generated using ASN.1 [X.208-88], using BER-encoding (Basic Encoding Rules) [X.209-88]. Values are typicallyrepresented as octet strings. While many systems are capable oftransmitting arbitrary octet strings reliably, it is well known that many electronic mail systems are not. This document does not address mechanisms for encoding octet strings for reliable transmission insuch environments.Housley Standards Track [Page 3]1.1. Evolution of the CMSThe CMS is derived from PKCS #7 version 1.5, which is documented inRFC 2315 [PKCS#7]. PKCS #7 version 1.5 was developed outside of the IETF; it was originally published as an RSA Laboratories TechnicalNote in November 1993. Since that time, the IETF has takenresponsibility for the development and maintenance of the CMS.Today, several important IETF Standards-Track protocols make use ofthe CMS.This section describes that changes that the IETF has made to the CMS in each of the published versions.1.1.1. Changes Since PKCS #7 Version 1.5RFC 2630 [CMS1] was the first version of the CMS on the IETFStandards Track. Wherever possible, backward compatibility with PKCS #7 version 1.5 is preserved; however, changes were made toaccommodate version 1 attribute certificate transfer and to supportalgorithm-independent key management. PKCS #7 version 1.5 includedsupport only for key transport. RFC 2630 adds support for keyagreement and previously distributed symmetric key-encryption keytechniques.1.1.2. Changes Since RFC 2630RFC 3369 [CMS2] obsoletes RFC 2630 [CMS1] and RFC 3211 [PWRI].Password-based key management is included in the CMS specification,and an extension mechanism to support new key management schemeswithout further changes to the CMS is specified. Backwardcompatibility with RFC 2630 and RFC 3211 is preserved; however,version 2 attribute certificate transfer is added, and the use ofversion 1 attribute certificates is deprecated.Secure/Multipurpose Internet Mail Extensions (S/MIME) v2 signatures[MSG2], which are based on PKCS #7 version 1.5, are compatible withS/MIME v3 signatures [MSG3]and S/MIME v3.1 signatures [MSG3.1].However, there are some subtle compatibility issues with signaturesbased on PKCS #7 version 1.5. These issues are discussed in Section 5.2.1. These issues remain with the current version of the CMS.Specific cryptographic algorithms are not discussed in this document, but they were discussed in RFC 2630. The discussion of specificcryptographic algorithms has been moved to a separate document[CMSALG]. Separation of the protocol and algorithm specificationsallows the IETF to update each document independently. Thisspecification does not require the implementation of any particular Housley Standards Track [Page 4]algorithms. Rather, protocols that rely on the CMS are expected tochoose appropriate algorithms for their environment. The algorithms may be selected from [CMSALG] or elsewhere.1.1.3. Changes Since RFC 3369RFC 3852 [CMS3] obsoletes RFC 3369 [CMS2]. As discussed in theprevious section, RFC 3369 introduced an extension mechanism tosupport new key management schemes without further changes to theCMS. RFC 3852 introduces a similar extension mechanism to supportadditional certificate formats and revocation status informationformats without further changes to the CMS. These extensions areprimarily documented in Sections 10.2.1 and 10.2.2. Backwardcompatibility with earlier versions of the CMS is preserved.The use of version numbers is described in Section 1.3.Since the publication of RFC 3369, a few errata have been noted.These errata are posted on the RFC Editor web site. These errorshave been corrected in this document.The text in Section 11.4 that describes the counter signatureunsigned attribute is clarified. Hopefully, the revised text isclearer about the portion of the SignerInfo signature that is covered by a countersignature.1.1.4. Changes Since RFC 3852This document obsoletes RFC 3852 [CMS3]. The primary reason for the publication of this document is to advance the CMS along thestandards maturity ladder.This document includes the clarifications that were originallypublished in RFC 4853 [CMSMSIG] regarding the proper handling of the SignedData protected content type when more than one digitalsignature is present.Since the publication of RFC 3852, a few errata have been noted.These errata are posted on the RFC Editor web site. These errorshave been corrected in this document.1.2. TerminologyIn this document, the key words MUST, MUST NOT, REQUIRED, SHOULD,SHOULD NOT, RECOMMENDED, MAY, and OPTIONAL are to be interpreted asdescribed in [STDWORDS].Housley Standards Track [Page 5]1.3. Version NumbersEach of the major data structures includes a version number as thefirst item in the data structure. The version numbers are intendedto avoid ASN.1 decode errors. Some implementations do not check the version number prior to attempting a decode, and if a decode erroroccurs, then the version number is checked as part of the errorhandling routine. This is a reasonable approach; it places errorprocessing outside of the fast path. This approach is also forgiving when an incorrect version number is used by the sender.Most of the initial version numbers were assigned in PKCS #7 version 1.5. Others were assigned when the structure was initially created. Whenever a structure is updated, a higher version number is assigned. However, to ensure maximum interoperability, the higher versionnumber is only used when the new syntax feature is employed. Thatis, the lowest version number that supports the generated syntax isused.2. General OverviewThe CMS is general enough to support many different content types.This document defines one protection content, ContentInfo.ContentInfo encapsulates a single identified content type, and theidentified type may provide further encapsulation. This documentdefines six content types: data, signed-data, enveloped-data,digested-data, encrypted-data, and authenticated-data. Additionalcontent types can be defined outside this document.An implementation that conforms to this specification MUST implement the protection content, ContentInfo, and MUST implement the data,signed-data, and enveloped-data content types. The other contenttypes MAY be implemented.As a general design philosophy, each content type permits single pass processing using indefinite-length Basic Encoding Rules (BER)encoding. Single-pass operation is especially helpful if content is large, stored on tapes, or is "piped" from another process. Single- pass operation has one significant drawback: it is difficult toperform encode operations using the Distinguished Encoding Rules(DER) [X.509-88] encoding in a single pass since the lengths of thevarious components may not be known in advance. However, signedattributes within the signed-data content type and authenticatedattributes within the authenticated-data content type need to betransmitted in DER form to ensure that recipients can verify acontent that contains one or more unrecognized attributes. Signedattributes and authenticated attributes are the only data types used in the CMS that require DER encoding.Housley Standards Track [Page 6]3. General SyntaxThe following object identifier identifies the content informationtype:id-ct-contentInfo OBJECT IDENTIFIER ::= { iso(1) member-body(2)us(840) rsadsi(113549) pkcs(1) pkcs9(9) smime(16) ct(1) 6 }The CMS associates a content type identifier with a content. Thesyntax MUST have ASN.1 type ContentInfo:ContentInfo ::= SEQUENCE {contentType ContentType,content [0] EXPLICIT ANY DEFINED BY contentType }ContentType ::= OBJECT IDENTIFIERThe fields of ContentInfo have the following meanings:contentType indicates the type of the associated content. It isan object identifier; it is a unique string of integers assignedby an authority that defines the content type.content is the associated content. The type of content can bedetermined uniquely by contentType. Content types for data,signed-data, enveloped-data, digested-data, encrypted-data, andauthenticated-data are defined in this document. If additionalcontent types are defined in other documents, the ASN.1 typedefined SHOULD NOT be a CHOICE type.4. Data Content TypeThe following object identifier identifies the data content type:id-data OBJECT IDENTIFIER ::= { iso(1) member-body(2)us(840) rsadsi(113549) pkcs(1) pkcs7(7) 1 }The data content type is intended to refer to arbitrary octetstrings, such as ASCII text files; the interpretation is left to the application. Such strings need not have any internal structure(although they could have their own ASN.1 definition or otherstructure).S/MIME uses id-data to identify MIME-encoded content. The use ofthis content identifier is specified in RFC 2311 for S/MIME v2[MSG2], RFC 2633 for S/MIME v3 [MSG3], and RFC 3851 for S/MIME v3.1[MSG3.1].Housley Standards Track [Page 7]The data content type is generally encapsulated in the signed-data,enveloped-data, digested-data, encrypted-data, or authenticated-data content type.5. Signed-data Content TypeThe signed-data content type consists of a content of any type andzero or more signature values. Any number of signers in parallel can sign any type of content.The typical application of the signed-data content type representsone signer’s digital signature on content of the data content type.Another typical application disseminates certificates and certificate revocation lists (CRLs).The process by which signed-data is constructed involves thefollowing steps:1. For each signer, a message digest, or hash value, is computed on the content with a signer-specific message-digest algorithm. If the signer is signing any information other than the content, the message digest of the content and the other information aredigested with the signer’s message digest algorithm (see Section 5.4), and the result becomes the "message digest."2. For each signer, the message digest is digitally signed using the signer’s private key.3. For each signer, the signature value and other signer-specificinformation are collected into a SignerInfo value, as defined in Section 5.3. Certificates and CRLs for each signer, and thosenot corresponding to any signer, are collected in this step.4. The message digest algorithms for all the signers and theSignerInfo values for all the signers are collected together with the content into a SignedData value, as defined in Section 5.1.A recipient independently computes the message digest. This message digest and the signer’s public key are used to verify the signaturevalue. The signer’s public key is referenced in one of two ways. It can be referenced by an issuer distinguished name along with anissuer-specific serial number to uniquely identify the certificatethat contains the public key. Alternatively, it can be referenced by a subject key identifier, which accommodates both certified anduncertified public keys. While not required, the signer’scertificate can be included in the SignedData certificates field. Housley Standards Track [Page 8]When more than one signature is present, the successful validation of one signature associated with a given signer is usually treated as a successful signature by that signer. However, there are someapplication environments where other rules are needed. Anapplication that employs a rule other than one valid signature foreach signer must specify those rules. Also, where simple matching of the signer identifier is not sufficient to determine whether thesignatures were generated by the same signer, the applicationspecification must describe how to determine which signatures weregenerated by the same signer. Support of different communities ofrecipients is the primary reason that signers choose to include more than one signature. For example, the signed-data content type might include signatures generated with the RSA signature algorithm andwith the Elliptic Curve Digital Signature Algorithm (ECDSA) signature algorithm. This allows recipients to verify the signature associated with one algorithm or the other.This section is divided into six parts. The first part describes the top-level type SignedData, the second part describesEncapsulatedContentInfo, the third part describes the per-signerinformation type SignerInfo, and the fourth, fifth, and sixth partsdescribe the message digest calculation, signature generation, andsignature verification processes, respectively.5.1. SignedData TypeThe following object identifier identifies the signed-data contenttype:id-signedData OBJECT IDENTIFIER ::= { iso(1) member-body(2)us(840) rsadsi(113549) pkcs(1) pkcs7(7) 2 }The signed-data content type shall have ASN.1 type SignedData:SignedData ::= SEQUENCE {version CMSVersion,digestAlgorithms DigestAlgorithmIdentifiers,encapContentInfo EncapsulatedContentInfo,certificates [0] IMPLICIT CertificateSet OPTIONAL,crls [1] IMPLICIT RevocationInfoChoices OPTIONAL,signerInfos SignerInfos }DigestAlgorithmIdentifiers ::= SET OF DigestAlgorithmIdentifierSignerInfos ::= SET OF SignerInfoHousley Standards Track [Page 9]The fields of type SignedData have the following meanings:version is the syntax version number. The appropriate valuedepends on certificates, eContentType, and SignerInfo. Theversion MUST be assigned as follows:IF ((certificates is present) AND(any certificates with a type of other are present)) OR((crls is present) AND(any crls with a type of other are present))THEN version MUST be 5ELSEIF (certificates is present) AND(any version 2 attribute certificates are present)THEN version MUST be 4ELSEIF ((certificates is present) AND(any version 1 attribute certificates are present)) OR (any SignerInfo structures are version 3) OR(encapContentInfo eContentType is other than id-data) THEN version MUST be 3ELSE version MUST be 1digestAlgorithms is a collection of message digest algorithmidentifiers. There MAY be any number of elements in thecollection, including zero. Each element identifies the messagedigest algorithm, along with any associated parameters, used byone or more signer. The collection is intended to list themessage digest algorithms employed by all of the signers, in anyorder, to facilitate one-pass signature verification.Implementations MAY fail to validate signatures that use a digest algorithm that is not included in this set. The message digesting process is described in Section 5.4.encapContentInfo is the signed content, consisting of a contenttype identifier and the content itself. Details of theEncapsulatedContentInfo type are discussed in Section 5.2.certificates is a collection of certificates. It is intended that the set of certificates be sufficient to contain certificationpaths from a recognized "root" or "top-level certificationauthority" to all of the signers in the signerInfos field. There may be more certificates than necessary, and there may becertificates sufficient to contain certification paths from two or more independent top-level certification authorities. There mayalso be fewer certificates than necessary, if it is expected that recipients have an alternate means of obtaining necessaryHousley Standards Track [Page 10]certificates (e.g., from a previous set of certificates). Thesigner’s certificate MAY be included. The use of version 1attribute certificates is strongly discouraged.crls is a collection of revocation status information. It isintended that the collection contain information sufficient todetermine whether the certificates in the certificates field arevalid, but such correspondence is not necessary. Certificaterevocation lists (CRLs) are the primary source of revocationstatus information. There MAY be more CRLs than necessary, andthere MAY also be fewer CRLs than necessary.signerInfos is a collection of per-signer information. There MAY be any number of elements in the collection, including zero. When the collection represents more than one signature, the successful validation of one of signature from a given signer ought to betreated as a successful signature by that signer. However, there are some application environments where other rules are needed.The details of the SignerInfo type are discussed in Section 5.3.Since each signer can employ a different digital signaturetechnique, and future specifications could update the syntax, all implementations MUST gracefully handle unimplemented versions ofSignerInfo. Further, since all implementations will not supportevery possible signature algorithm, all implementations MUSTgracefully handle unimplemented signature algorithms when they are encountered.5.2. EncapsulatedContentInfo TypeThe content is represented in the type EncapsulatedContentInfo:EncapsulatedContentInfo ::= SEQUENCE {eContentType ContentType,eContent [0] EXPLICIT OCTET STRING OPTIONAL }ContentType ::= OBJECT IDENTIFIERThe fields of type EncapsulatedContentInfo have the followingmeanings:eContentType is an object identifier. The object identifieruniquely specifies the content type.eContent is the content itself, carried as an octet string. TheeContent need not be DER encoded.Housley Standards Track [Page 11]The optional omission of the eContent within theEncapsulatedContentInfo field makes it possible to construct"external signatures". In the case of external signatures, thecontent being signed is absent from the EncapsulatedContentInfo value included in the signed-data content type. If the eContent valuewithin EncapsulatedContentInfo is absent, then the signatureValue is calculated and the eContentType is assigned as though the eContentvalue was present.In the degenerate case where there are no signers, theEncapsulatedContentInfo value being "signed" is irrelevant. In this case, the content type within the EncapsulatedContentInfo value being "signed" MUST be id-data (as defined in Section 4), and the contentfield of the EncapsulatedContentInfo value MUST be omitted.5.2.1. Compatibility with PKCS #7This section contains a word of warning to implementers that wish to support both the CMS and PKCS #7 [PKCS#7] SignedData content types.Both the CMS and PKCS #7 identify the type of the encapsulatedcontent with an object identifier, but the ASN.1 type of the content itself is variable in PKCS #7 SignedData content type.PKCS #7 defines content as:content [0] EXPLICIT ANY DEFINED BY contentType OPTIONALThe CMS defines eContent as:eContent [0] EXPLICIT OCTET STRING OPTIONALThe CMS definition is much easier to use in most applications, and it is compatible with both S/MIME v2 and S/MIME v3. S/MIME signedmessages using the CMS and PKCS #7 are compatible because identicalsigned message formats are specified in RFC 2311 for S/MIME v2[MSG2], RFC 2633 for S/MIME v3 [MSG3], and RFC 3851 for S/MIME v3.1[MSG3.1]. S/MIME v2 encapsulates the MIME content in a Data type(that is, an OCTET STRING) carried in the SignedData contentInfocontent ANY field, and S/MIME v3 carries the MIME content in theSignedData encapContentInfo eContent OCTET STRING. Therefore, inS/MIME v2, S/MIME v3, and S/MIME v3.1, the MIME content is placed in an OCTET STRING and the message digest is computed over the identical portions of the content. That is, the message digest is computedover the octets comprising the value of the OCTET STRING, neither the tag nor length octets are included.Housley Standards Track [Page 12]There are incompatibilities between the CMS and PKCS #7 SignedDatatypes when the encapsulated content is not formatted using the Datatype. For example, when an RFC 2634 signed receipt [ESS] isencapsulated in the CMS SignedData type, then the Receipt SEQUENCE is encoded in the SignedData encapContentInfo eContent OCTET STRING and the message digest is computed using the entire Receipt SEQUENCEencoding (including tag, length and value octets). However, if anRFC 2634 signed receipt is encapsulated in the PKCS #7 SignedDatatype, then the Receipt SEQUENCE is DER encoded [X.509-88] in theSignedData contentInfo content ANY field (a SEQUENCE, not an OCTETSTRING). Therefore, the message digest is computed using only thevalue octets of the Receipt SEQUENCE encoding.The following strategy can be used to achieve backward compatibility with PKCS #7 when processing SignedData content types. If theimplementation is unable to ASN.1 decode the SignedData type usingthe CMS SignedData encapContentInfo eContent OCTET STRING syntax,then the implementation MAY attempt to decode the SignedData typeusing the PKCS #7 SignedData contentInfo content ANY syntax andcompute the message digest accordingly.The following strategy can be used to achieve backward compatibility with PKCS #7 when creating a SignedData content type in which theencapsulated content is not formatted using the Data type.Implementations MAY examine the value of the eContentType, and thenadjust the expected DER encoding of eContent based on the objectidentifier value. For example, to support Microsoft Authenticode[MSAC], the following information MAY be included:eContentType Object Identifier is set to { 1 3 6 1 4 1 311 2 1 4 } eContent contains DER-encoded Authenticode signing information5.3. SignerInfo TypePer-signer information is represented in the type SignerInfo:SignerInfo ::= SEQUENCE {version CMSVersion,sid SignerIdentifier,digestAlgorithm DigestAlgorithmIdentifier,signedAttrs [0] IMPLICIT SignedAttributes OPTIONAL,signatureAlgorithm SignatureAlgorithmIdentifier,signature SignatureValue,unsignedAttrs [1] IMPLICIT UnsignedAttributes OPTIONAL }Housley Standards Track [Page 13]。

Internet Message Access Protocol (IMAP) is an email retrieval protocol. It stores email messages on a mail server and enables the recipient to view and manipulate them as though they were stored locally on their device. IMAP was developed in the late 1980s and has since become one of the most widely used email retrieval protocols.The IMAP standard is defined in RFC 3501, which was published in 2003. This document provides a detailed description of the protocol's functionality, including its data formats, commands, and responses. The standard specifies how IMAP clients and servers should communicate with each other to enable the retrieval and manipulation of email messages.One of the key features of IMAP is its support for multiple clients accessing the same mailbox simultaneously. This is achieved through the use of a "shared" storage model, where all clients see the same set of messages and folders stored on the server. This allows users to access their email from different devices without having to worry about synchronizing their messages manually.Another important aspect of IMAP is its support for message organization and management. Clients can create, delete, and rename folders, as well as move messages between folders. They can also search for specific messages based on various criteria, such as sender, subject, or date.IMAP also provides a range of features for managing individual messages. Clients can mark messages as read or unread, flag them for follow-up, and even move them to a specific folder. They can also reply to messages, forward them to others, and generate replies or forwards with attachments.Overall, the IMAP standard provides a powerful and flexible framework for managing email messages. Its support for shared storage, message organization, and advanced message management features make it a popular choice for both personal and business email users.。
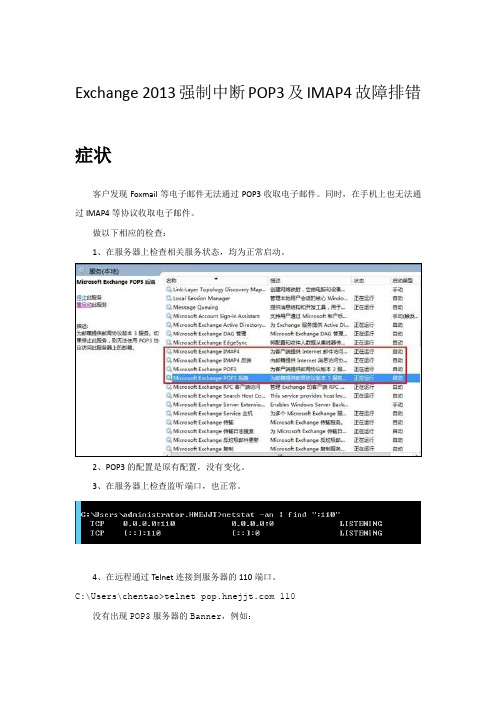
Exchange 2013强制中断POP3及IMAP4故障排错症状客户发现Foxmail等电子邮件无法通过POP3收取电子邮件。
同时,在手机上也无法通过IMAP4等协议收取电子邮件。
做以下相应的检查:1、在服务器上检查相关服务状态,均为正常启动。
2、POP3的配置是原有配置,没有变化。
3、在服务器上检查监听端口,也正常。
4、在远程通过Telnet连接到服务器的110端口。
C:\Users\chentao>telnet 110没有出现POP3服务器的Banner,例如:而是直接退出。
5、在远程通过Nmap扫描服务器端口,端口也处于打开状态6、检查服务器防火墙,也是正常。
7、使用WireShark,分析邮件客户端与服务器110之间的连接,发现在TCP 3次握手,连接直接断开。
8、在服务器上安装Foxmail电子邮件客户端,将POP3服务器地址设置为127.0.0.1,接收正常!设置为FQDN或内网域名,就失败。
9、检查Exchange服务器组件[PS] C:\Windows\system32>Get-ServerComponentState -Identity xxmail1发现有两个组件处于非活动状态。
排错执行以下两个命令,将此组件激活Set-ServerComponentState -Identity xxmail1 -Component PopProxy-Requester HealthAPI -State ActiveSet-ServerComponentState -Identity xxmail1 -Component ImapProxy -Requester HealthAPI -State Active然后通过Get-ServerComponentState -Identity xxmail1检查组件状态。
原因由于无法确定出现故障的准确时间,在此时间进行过系统的变更也无法确定。
imap 协议 java代码为你提供一个用 Java 编写的简单的 IMAP 客户端示例,用于连接并读取 Gmail 邮箱中的邮件:```javaimport java.io.UnsupportedEncodingException;import java.util.Date;import java.util.Properties;import javax.mail.Authenticator;import javax.mail.FetchProfile;import javax.mail.Folder;import javax.mail.Message;import javax.mail.Message.RecipientType;import javax.mail.PasswordAuthentication;import javax.mail.Session;import javax.mail.Store;import javax.mail.Transport;import javax.mail.internet.InternetAddress;import javax.mail.internet.MimeMessage;import javax.mail.internet.MimeUtility;public class EmailUtil {private String username = null;private String password = null;// 传入自己的邮箱用户名和密码public EmailUtil(String username, String password) {ername = username;this.password = password;}// 创建连接会话public Session createSession(Properties props) {Session session = Session.getInstance(props, new Authenticator() { // 返回用户名密码认证@Overridepublic PasswordAuthentication getPasswordAuthentication() {PasswordAuthentication pa = new PasswordAuthentication(username, password);return pa;}});return session;}// 发送邮件(需设置 SMTP)public void sendMail(Properties props, SendEmailMessage sem) throws Exception {Session session = createSession(props);// 消息Message msg = new MimeMessage(session);msg.setFrom(InternetAddress.parse(MimeUtility.decodeText(sem.getFrom())));msg.setRecipients(RecipientType.TO,InternetAddress.parse(sem.getRecipient()));msg.setSubject(sem.getSubject());msg.setText(sem.getText());msg.setSentDate(new Date());// 发送消息Transport.send(msg);}// 接收邮件(需设置 POP3 或 SAMP)public void receiveMail(Properties props, String protocol) throwsException {Session session = createSession(props);Store store = session.getStore(protocol);store.connect();// 连接Folder inbox = store.getFolder("INBOX");// 进入根目录inbox.open(Folder.READ_WRITE);// 只读方式FetchProfile profile = new FetchProfile();profile.add(FetchProfile.Item.ENVELOPE);// 获取信封Message[] msgs = inbox.getMessages();// 得到所有邮件inbox.fetch(msgs, profile);// 预获取信息// 打印for (int i = 0; i < msgs.length; i++) {System.out.println("发送时间:" + msgs[i].getSentDate());System.out.println("发送人:" + decodeText(msgs[i].getFrom()(0).toString()));System.out.println("大小:" + msgs[i].getSize());System.out.println("标题:" + msgs[i].getSubject());}}private String decodeText(String text) {try {return MimeUtility.decodeText(text);} catch (UnsupportedEncodingException e) {e.printStackTrace();return null;}}}```在上述代码中,首先定义了一个`EmailUtil`类,在类中创建`createSession`方法,用于创建邮件会话。
IMAP协议解析邮件服务器与客户端的高级通信协议详解IMAP(Internet Mail Access Protocol)是一种邮件服务器与客户端之间进行通信的高级协议。
它的主要功能是允许邮件客户端在服务器上直接管理和操作邮件,而无需将所有邮件下载到本地设备。
本文将详细解析IMAP协议的工作原理和功能。
一、IMAP协议的基本原理IMAP协议采用客户端-服务器的通信模型。
客户端连接到邮件服务器,通过IMAP协议与服务器进行通信和交互,完成对邮件的管理和操作。
客户端首先与邮件服务器建立连接,并进行身份验证。
验证通过后,客户端可以查看邮件服务器上的邮件列表,选择性地将邮件下载到本地设备,或者直接在服务器上进行邮件操作,如删除、移动、标记等。
客户端可以通过IMAP协议将邮件保留在服务器上,从而实现在不同设备上同步邮件的功能。
二、IMAP协议的功能1. 邮件的查看和搜索:通过IMAP协议,客户端可以获取邮件服务器上的邮件列表,并根据条件进行邮件的搜索。
客户端可以按发件人、主题、日期等条件对邮件进行过滤和查找,提高邮件检索的效率。
2. 邮件的管理和操作:IMAP协议允许客户端在邮件服务器上对邮件进行管理和操作。
客户端可以标记邮件为已读或未读状态,将邮件移到指定文件夹,删除不需要的邮件等。
这些操作都会反映在服务器上,保证邮件在不同设备上的一致性。
3. 文件夹的管理:IMAP协议支持客户端对邮件服务器上的文件夹进行管理。
客户端可以创建、重命名、删除文件夹,从而更好地组织和管理邮件。
4. 邮件状态的同步:IMAP协议可以保持客户端与服务器上邮件状态的同步。
当在一个设备上读取或删除邮件时,其他设备上的客户端也会同步更新邮件的状态,确保用户在不同设备上的邮件体验一致。
5. 多设备的消息同步:IMAP协议支持多设备之间的消息同步。
当用户在一个设备上发送邮件或进行其他操作时,其他设备上的客户端也会同步更新,确保用户在不同设备上的邮件操作保持一致。
建议:1. 使用收发邮件检测工具自动定位问题。
2. 排查计算机网络环境、代理设置、杀毒软件设置等原因。
3. 进入设置- 帐号–高级,检查服务器、端口和SSL 安全连接是否正确设置。
...这种错误出现在你的邮箱帐号在指定时间内连接服务器过于频繁。
在较短时间内进行了较频繁的个人收发操作可能会导致这个错误;此外,也有可能是所在的公网IP 段有较多人......建议:1. 使用收发邮件检测工具自动定位问题。
2. 排查计算机网络环境、代理设置、杀毒软件设置等原因。
3. 进入设置- 帐号–高级,检查服务器、端口和SSL 安全连接是否正确设置。
...建议:1. 使用收发邮件检测工具自动定位问题。
2. 排查计算机网络环境、代理设置、杀毒软件设置等原因。
3. 进入设置- 帐号–高级,检查服务器、端口和SSL 安全连接是否正确设置。
...建议:1. 使用收发邮件检测工具自动定位问题。
2. 排查计算机网络环境、代理设置、杀毒软件设置等原因。
3. 进入设置- 帐号–高级,检查服务器、端口和SSL 安全连令...令...建议:1. 使用收发邮件检测工具自动定位问题。
2. 排查计算机网络环境、代理设置、杀毒软件设置等原因。
3. 进入设置- 帐号–高级,检查服务器、端口和SSL 安全连接是否正确设置。
...这种错误出现在你的邮箱使用情况超出了对方服务器的流量、收发频率、收发量的限制,被暂时限制使用。
一般情况下,过一段时间会自动恢复,具体需联系对方邮箱提供商。
...建议:1. 使用收发邮件检测工具自动定位问题。
2. 排查计算机网络环境、代理设置、杀毒软件设置等原因。
3. 进入设置- 帐号–高级,检查服务器、端口和SSL 安全连接是否正确设置。
...建议:1. 使用收发邮件检测工具自动定位问题。
2. 排查计算机网络环境、代理设置、杀毒软件设置等原因。
3. 进入设置- 帐号–高级,检查服务器、端口和SSL 安全连接是否正确设置。
RFC821 简单邮件传输协议(SMTP)(RFC821 SIMPLE MAIL TRANSFER PROTOCOL)目录1. 介绍 22. SMTP模型 33. SMTP过程 43.1. MAIL 43.2. 转发 53.3. 确认和扩展 63.4. 发送信件(mailing)和获得信件(sending) 7 3.5. 打开和关闭73.6. 转发 83.7. 域93.8. 改变角色94. SMTP说明94.1. SMTP命令94.1.1. 命令语法94.1.2. COMMAND语法格式134.2. SMTP响应154.3. 命令和应答序列164.4. 状态图174.5. 详细内容184.5.1. 最小实现184.5.2. 透明性194.5.3. 大小19附录 A TCP传输服务19附录 B NCP传输服务20附录 C NITS 20附录 D X.25传输服务 20附录 E 应答码构成方法20附录 F 一些例子22参考资料361. 介绍简单邮件传输协议(SMTP)的目标是可靠高效地传送邮件,它独立于传送子系统而且仅要求一条可以保证传送数据单元顺序的通道。
附录A,B,C和D描述了不同传送服务下SMTP的使用。
在名词表中还定义了本文档中使用的术语。
SMTP的一个重要特点是它能够在传送中接力传送邮件,传送服务提供了进程间通信环境(IPCE),此环境可以包括一个网络,几个网络或一个网络的子网。
理解到传送系统(或IPCE)不是一对一的是很重要的。
进程可能直接和其它进程通过已知的IPCE通信。
邮件是一个应用程序或进程间通信。
邮件可以通过连接在不同IPCE上的进程跨网络进行邮件传送。
更特别的是,邮件可以通过不同网络上的主机接力式传送。
2. SMTP模型SMTP设计基于以下通信模型:针对用户的邮件请求,发送SMTP建立与接收SMTP之间建立一个双向传送通道。
接收SMTP可以是最终接收者也可以是中间传送者。
SMTP命令由发送SMTP发出,由接收SMTP接收,而应答则反方面传送。
Network Working Group A. Gulbrandsen Request for Comments: 4978 Oryx Mail Systems GmbH Category: Standards Track August 2007 The IMAP COMPRESS ExtensionStatus of this MemoThis document specifies an Internet standards track protocol for the Internet community, and requests discussion and suggestions forimprovements. Please refer to the current edition of the "InternetOfficial Protocol Standards" (STD 1) for the standardization stateand status of this protocol. Distribution of this memo is unlimited. AbstractThe COMPRESS extension allows an IMAP connection to be effectivelyand efficiently compressed.Table of Contents1. Introduction and Overview (2)2. Conventions Used in This Document (2)3. The COMPRESS Command (3)4. Compression Efficiency (4)5. Formal Syntax (6)6. Security Considerations (6)7. IANA Considerations (6)8. Acknowledgements (7)9. References (7)9.1. Normative References (7)9.2. Informative References (7)Gulbrandsen Standards Track [Page 1]1. Introduction and OverviewA server which supports the COMPRESS extension indicates this withone or more capability names consisting of "COMPRESS=" followed by a supported compression algorithm name as described in this document.The goal of COMPRESS is to reduce the bandwidth usage of IMAP.Compared to PPP compression (see [RFC1962]) and modem-basedcompression (see [MNP] and [V42BIS]), COMPRESS offers much bettercompression efficiency. COMPRESS can be used together with Transport Security Layer (TLS) [RFC4346], Simple Authentication and Securitylayer (SASL) encryption, Virtual Private Networks (VPNs), etc.Compared to TLS compression [RFC3749], COMPRESS has the following(dis)advantages:- COMPRESS can be implemented easily both by IMAP servers andclients.- IMAP COMPRESS benefits from an intimate knowledge of the IMAPprotocol’s state machine, allowing for dynamic and aggressiveoptimization of the underlying compression algorithm’s parameters. - When the TLS layer implements compression, any protocol using that layer can transparently benefit from that compression (e.g., SMTPand IMAP). COMPRESS is specific to IMAP.In order to increase interoperation, it is desirable to have as fewdifferent compression algorithms as possible, so this documentspecifies only one. The DEFLATE algorithm (defined in [RFC1951]) is standard, widely available and fairly efficient, so it is the onlyalgorithm defined by this document.In order to increase interoperation, IMAP servers that advertise this extension SHOULD also advertise the TLS DEFLATE compression mechanism as defined in [RFC3749]. IMAP clients MAY use either COMPRESS or TLS compression, however, if the client and server support both, it isRECOMMENDED that the client choose TLS compression.The extension adds one new command (COMPRESS) and no new responses. 2. Conventions Used in This DocumentThe key words "MUST", "MUST NOT", "REQUIRED", "SHALL", "SHALL NOT","SHOULD", "SHOULD NOT", "RECOMMENDED", "MAY", and "OPTIONAL" in this document are to be interpreted as described in [RFC2119].Formal syntax is defined by [RFC4234] as modified by [RFC3501]. Gulbrandsen Standards Track [Page 2]In the examples, "C:" and "S:" indicate lines sent by the client and server respectively. "[...]" denotes elision.3. The COMPRESS CommandArguments: Name of compression mechanism: "DEFLATE".Responses: NoneResult: OK The server will compress its responses and expects theclient to compress its commands.NO Compression is already active via another layer.BAD Command unknown, invalid or unknown argument, or COMPRESS already active.The COMPRESS command instructs the server to use the namedcompression mechanism ("DEFLATE" is the only one defined) for allcommands and/or responses after COMPRESS.The client MUST NOT send any further commands until it has seen theresult of COMPRESS. If the response was OK, the client MUST compress starting with the first command after COMPRESS. If the serverresponse was BAD or NO, the client MUST NOT turn on compression.If the server responds NO because it knows that the same mechanism is active already (e.g., because TLS has negotiated the same mechanism), it MUST send COMPRESSIONACTIVE as resp-text-code (see [RFC3501],Section 7.1), and the resp-text SHOULD say which layer compresses.If the server issues an OK response, the server MUST compressstarting immediately after the CRLF which ends the tagged OKresponse. (Responses issued by the server before the OK responsewill, of course, still be uncompressed.) If the server issues a BAD or NO response, the server MUST NOT turn on compression.For DEFLATE (as for many other compression mechanisms), thecompressor can trade speed against quality. When decompressing there isn’t much of a tradeoff. Consequently, the client and server areboth free to pick the best reasonable rate of compression for thedata they send.When COMPRESS is combined with TLS (see [RFC4346]) or SASL (see[RFC4422]) security layers, the sending order of the three extensions MUST be first COMPRESS, then SASL, and finally TLS. That is, before data is transmitted it is first compressed. Second, if a SASLsecurity layer has been negotiated, the compressed data is thensigned and/or encrypted accordingly. Third, if a TLS security layer has been negotiated, the data from the previous step is signed and/or Gulbrandsen Standards Track [Page 3]encrypted accordingly. When receiving data, the processing orderMUST be reversed. This ensures that before sending, data iscompressed before it is encrypted, independent of the order in which the client issues COMPRESS, AUTHENTICATE, and STARTTLS.The following example illustrates how commands and responses arecompressed during a simple login sequence:S: * OK [CAPABILITY IMAP4REV1 STARTTLS COMPRESS=DEFLATE]C: a starttlsS: a OK TLS activeFrom this point on, everything is encrypted.C: b login arnt tnraS: b OK Logged in as arntC: c compress deflateS: d OK DEFLATE activeFrom this point on, everything is compressed before beingencrypted.The following example demonstrates how a server may refuse tocompress twice:S: * OK [CAPABILITY IMAP4REV1 STARTTLS COMPRESS=DEFLATE][...]C: c compress deflateS: c NO [COMPRESSIONACTIVE] DEFLATE active via TLS4. Compression EfficiencyThis section is informative, not normative.IMAP poses some unusual problems for a compression layer.Upstream is fairly simple. Most IMAP clients send the same fewcommands again and again, so any compression algorithm that canexploit repetition works efficiently. The APPEND command is anexception; clients that send many APPEND commands may want tosurround large literals with flushes in the same way as isrecommended for servers later in this section.Downstream has the unusual property that several kinds of data aresent, confusing all dictionary-based compression algorithms. Gulbrandsen Standards Track [Page 4]One type is IMAP responses. These are highly compressible; zlibusing its least CPU-intensive setting compresses typical responses to 25-40% of their original size.Another type is email headers. These are equally compressible, andbenefit from using the same dictionary as the IMAP responses.A third type is email body text. Text is usually fairly short andincludes much ASCII, so the same compression dictionary will do agood job here, too. When multiple messages in the same thread areread at the same time, quoted lines etc. can often be compressedalmost to zero.Finally, attachments (non-text email bodies) are transmitted, either in binary form or encoded with base-64.When attachments are retrieved in binary form, DEFLATE may be able to compress them, but the format of the attachment is usually not IMAP- like, so the dictionary built while compressing IMAP does not help.The compressor has to adapt its dictionary from IMAP to theattachment’s format, and then back. A few file formats aren’tcompressible at all using deflate, e.g., .gz, .zip, and .jpg files.When attachments are retrieved in base-64 form, the same problemsapply, but the base-64 encoding adds another problem. 8-bitcompression algorithms such as deflate work well on 8-bit fileformats, however base-64 turns a file into something resembling 6-bit bytes, hiding most of the 8-bit file format from the compressor.When using the zlib library (see [RFC1951]), the functionsdeflateInit2(), deflate(), inflateInit2(), and inflate() suffice toimplement this extension. The windowBits value must be in the range -8 to -15, or else deflateInit2() uses the wrong format.deflateParams() can be used to improve compression rate and resource use. The Z_FULL_FLUSH argument to deflate() can be used to clear the dictionary (the receiving peer does not need to do anything).A client can improve downstream compression by implementing BINARY(defined in [RFC3516]) and using FETCH BINARY instead of FETCH BODY. In the author’s experience, the improvement ranges from 5% to 40%depending on the attachment being downloaded.A server can improve downstream compression if it hints to thecompressor that the data type is about to change strongly, e.g., bysending a Z_FULL_FLUSH at the start and end of large non-textliterals (before and after ’*CHAR8’ in the definition of literal inRFC 3501, page 86). Small literals are best left alone. A possible boundary is 5k.Gulbrandsen Standards Track [Page 5]A server can improve the CPU efficiency both of the server and theclient if it adjusts the compression level (e.g., using thedeflateParams() function in zlib) at these points, to avoid trying to compress incompressible attachments. A very simple strategy is tochange the level to 0 at the start of a literal provided the firsttwo bytes are either 0x1F 0x8B (as in deflate-compressed files) or0xFF 0xD8 (JPEG), and to keep it at 1-5 the rest of the time. Morecomplex strategies are possible.5. Formal SyntaxThe following syntax specification uses the Augmented Backus-NaurForm (ABNF) notation as specified in [RFC4234]. This syntax augments the grammar specified in [RFC3501]. [RFC4234] defines SP and[RFC3501] defines command-auth, capability, and resp-text-code.Except as noted otherwise, all alphabetic characters are case-insensitive. The use of upper or lower case characters to definetoken strings is for editorial clarity only. Implementations MUSTaccept these strings in a case-insensitive fashion.command-auth =/ compresscompress = "COMPRESS" SP algorithmcapability =/ "COMPRESS=" algorithm;; multiple COMPRESS capabilities allowedalgorithm = "DEFLATE"resp-text-code =/ "COMPRESSIONACTIVE"Note that due the syntax of capability names, future algorithm names must be atoms.6. Security ConsiderationsAs for TLS compression [RFC3749].7. IANA ConsiderationsThe IANA has added COMPRESS=DEFLATE to the list of IMAP capabilities. Gulbrandsen Standards Track [Page 6]8. AcknowledgementsEric Burger, Dave Cridland, Tony Finch, Ned Freed, Philip Guenther,Randall Gellens, Tony Hansen, Cullen Jennings, Stephane Maes, Alexey Melnikov, Lyndon Nerenberg, and Zoltan Ordogh have all helped withthis document.The author would also like to thank various people in the rooms atmeetings, whose help is real, but not reflected in the author’smailbox.9. References9.1. Normative References[RFC1951] Deutsch, P., "DEFLATE Compressed Data Format Specification version 1.3", RFC 1951, May 1996.[RFC2119] Bradner, S., "Key words for use in RFCs to IndicateRequirement Levels", BCP 14, RFC 2119, March 1997.[RFC3501] Crispin, M., "INTERNET MESSAGE ACCESS PROTOCOL - VERSION4rev1", RFC 3501, March 2003.[RFC4234] Crocker, D. and P. Overell, "Augmented BNF for SyntaxSpecifications: ABNF", RFC 4234, October 2005.9.2. Informative References[RFC1962] Rand, D., "The PPP Compression Control Protocol (CCP)",RFC 1962, June 1996.[RFC3516] Nerenberg, L., "IMAP4 Binary Content Extension", RFC 3516, April 2003.[RFC3749] Hollenbeck, S., "Transport Layer Security ProtocolCompression Methods", RFC 3749, May 2004.[RFC4346] Dierks, T. and E. Rescorla, "The Transport Layer Security (TLS) Protocol Version 1.1", RFC 4346, April 2006.[RFC4422] Melnikov, A. and K. Zeilenga, "Simple Authentication and Security Layer (SASL)", RFC 4422, June 2006.[V42BIS] ITU, "V.42bis: Data compression procedures for datacircuit-terminating equipment (DCE) using error correction procedures", http://www.itu.int/rec/T-REC-V.42bis, January 1990.Gulbrandsen Standards Track [Page 7][MNP] Gilbert Held, "The Complete Modem Reference", SecondEdition, Wiley Professional Computing, ISBN 0-471-00852-4, May 1994.Author’s AddressArnt GulbrandsenOryx Mail Systems GmbHSchweppermannstr. 8D-81671 MuenchenGermanyFax: +49 89 4502 9758EMail: arnt@Gulbrandsen Standards Track [Page 8]Full Copyright StatementCopyright (C) The IETF Trust (2007).This document is subject to the rights, licenses and restrictionscontained in BCP 78, and except as set forth therein, the authorsretain all their rights.This document and the information contained herein are provided on an "AS IS" basis and THE CONTRIBUTOR, THE ORGANIZATION HE/SHE REPRESENTS OR IS SPONSORED BY (IF ANY), THE INTERNET SOCIETY, THE IETF TRUST AND THE INTERNET ENGINEERING TASK FORCE DISCLAIM ALL WARRANTIES, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO ANY WARRANTY THAT THE USE OF THE INFORMATION HEREIN WILL NOT INFRINGE ANY RIGHTS OR ANY IMPLIEDWARRANTIES OF MERCHANTABILITY OR FITNESS FOR A PARTICULAR PURPOSE. Intellectual PropertyThe IETF takes no position regarding the validity or scope of anyIntellectual Property Rights or other rights that might be claimed to pertain to the implementation or use of the technology described inthis document or the extent to which any license under such rightsmight or might not be available; nor does it represent that it hasmade any independent effort to identify any such rights. Information on the procedures with respect to rights in RFC documents can befound in BCP 78 and BCP 79.Copies of IPR disclosures made to the IETF Secretariat and anyassurances of licenses to be made available, or the result of anattempt made to obtain a general license or permission for the use of such proprietary rights by implementers or users of thisspecification can be obtained from the IETF on-line IPR repository at /ipr.The IETF invites any interested party to bring to its attention anycopyrights, patents or patent applications, or other proprietaryrights that may cover technology that may be required to implementthis standard. Please address the information to the IETF atietf-ipr@.Gulbrandsen Standards Track [Page 9]。