分别以邻接矩阵和邻接表作为图的存储结构
- 格式:doc
- 大小:25.00 KB
- 文档页数:2

2018年上半年数据库系统工程师真题+答案解析上午选择1、计算机运行过程中,遇到突发事件,要求CPU暂时停止正在运行的程序,转去为突发事件服务,服务完毕,再自动返回原程序继续执行,这个过程称为(1),其处理过程中保存现场的目的是(2)。
A. 阻塞B. 中断C. 动态绑定D. 静态绑定答案:B2、计算机运行过程中,遇到突发事件,要求CPU暂时停止正在运行的程序,转去为突发事件服务,服务完毕,再自动返回原程序继续执行,这个过程称为(1),其处理过程中保存现场的目的是(2)。
A. 防止丢失数据B. 防止对其他部件造成影响C. 返回去继续执行原程序D. 为中断处理程序提供数据答案:C3、流水线的吞吐率是指单位时间流水线处理的任务数,如果各段流水的操作时间不同,则流水线的吞吐率是()的倒数。
A. 最短流水段操作时间B. 各段流水的操作时间总和C. 最长流水段操作时间D. 流水段数乘以最长流水段操作时间答案:C流水线吞吐率为流水线周期的倒数,而流水线周期为最长流水段操作时间。
4、计算机中机械硬盘的性能指标不包括()。
A. 磁盘转速及容量B. 盘片数及磁道数C. 容量及平均寻道时间D. 磁盘转速及平均寻道时间答案:B硬盘的性能指标,包括硬盘容量、硬盘速度、硬盘转速、接口、缓存、硬盘单碟容量等5、算术表达式采用后缀式表示时不需要使用括号,使用(5)就可以方便地进行求值。
a-b(c+d)(其中,-、+、*表示二元算术运算减、加、乘)的后缀式为(6),与该表达式等价的语法树为(7)。
A. 队列B. 数组C. 栈D. 广义表答案:C6、算术表达式采用后缀式表示时不需要使用括号,使用(5)就可以方便地进行求值。
a-b(c+d)(其中,-、+、*表示二元算术运算减、加、乘)的后缀式为(6),与该表达式等价的语法树为(7)。
A. a b c d -*+B. a b c d*+ -C. ab-c*d+D. a b c d+*-答案:D7、算术表达式采用后缀式表示时不需要使用括号,使用(5)就可以方便地进行求值。

图的存储结构:
邻接矩阵:存储方式用两个数组来表示图,一个一维数组存储图中的顶点信息,一个二维数组存储图中的边或者弧的信息
邻接矩阵存储结构:
邻接点的指针。
图中每个顶点vi的所有邻接点构成一个线性表,由于个数不定,用单链表存储,无向图称为顶点vi的边表,有向图称为顶点vi作为弧尾的出边表。
对于带权的网图,可以在边表结点定义中增加一个weight的数据域,存储权值信息即可。
1
2
十字链表:
firstin是入边表头指针,指向该顶点的入边表中第一个结点firstout表示出边表头指针,指向该顶点的出边表中的第一个顶点
headvex:指弧终点在顶点表中的下标
headlink:指入边表指针域,指向终点相同的下一条边
taillink:指边表指针域,指向起点相同的下一条边。
边,jlink指向依附顶点jvex的下一条边
3。

图的常⽤存储结构⼀、邻接矩阵 邻接矩阵是简单的也是⽐较常⽤的⼀种表⽰图的数据结构,对于⼀个有N个点的图,需要⼀个N*N的矩阵,这个矩阵的i⾏第j列的数值表⽰点vi到点vj的距离。
邻接矩阵需要初始化,map[i][i] = 0;map[i][j] = INF(i != j),对于每组读⼊的数据vi,vj,w(vi为边的起点,vj为边的终点,w为边的权值),赋值map[vi][vj] = w,另外邻接矩阵的值和边的输⼊顺序⽆关。
对于邻接矩阵来说,初始化需要O(n^2)的时间,建图需要O(m),所以总时间复杂度是O(n^2),空间上,邻接矩阵的开销也是O(n^2),和点的个数有关。
⼆、前向星 前向星是⼀种通过存储边的⽅式来存储图的数据结构。
构造的时候,只需要读⼊每条边的信息,将边存放在数组中,把数组中的边按照起点顺序排序,前向星就构造完毕,为了查询⽅便,经常会有⼀个数组存储起点为vi的第⼀条边的位置. 由于涉及排序,前向星的构造时间复杂度与排序算法有关,⼀般情况下时间复杂度为O(mlogN),空间上需要两个数组,所以空间复杂度为O(m + n),有点在于可以应对点⾮常多的情况,可以存储重边,但是不能直接判断任意两个顶点之间是否有边.1 #include <iostream>2 #include <cmath>3 #include <cstdio>4 #include <cstring>5 #include <cstdlib>6 #include <algorithm>7using namespace std;8 typedef long long LL;910const int MAXN = 1000 + 3;11int head[MAXN]; //存储起点为Vi的边第⼀次出现的位置1213struct NODE14 {15int from;16int to;17int w;18 };19 NODE edge[MAXN];2021bool cmp(NODE a, NODE b)22 {23if(a.from == b.from && a.to == b.to) return a.w < b.w;24if(a.from == b.from) return a.to < b.to;25return a.from < b.from;26 }2728int main()29 {30 freopen("input.txt", "r", stdin);31int n,m;32 cin >> n >> m;33for(int i = 0; i < m; i++)34 {35 cin >> edge[i].from >> edge[i].to >> edge[i].w;36 }37 sort(edge, edge + m, cmp);38 memset(head, -1, sizeof(head));39 head[edge[0].from] = 0;40for(int i = 1; i < m; i++)41 {42if(edge[i].from != edge[i - 1].from)43 {44 head[edge[i].from] = i;45 }46 }47for(int i = 1; i <= n; i++)48 {49for(int k = head[i]; edge[k].from == i && k < m; k++)50 {51 cout << edge[k].from << '' << edge[k].to << '' << edge[k].w <<endl;52 }53 }54for(int i = 0; i <= n; i++)55 {56 cout << head[i] << "";57 }58 cout << endl;59return0;60 }三、链式前向星 链式前向星采⽤数组模拟链表的⽅式实现邻接表的功能,并且使⽤很少的额外空间,是当前建图和遍历效率最⾼的存储⽅式.数组模拟链表的主要⽅式是记录下⼀个节点的数组的在哪⼀个位置。

二、填空题1. 线性表是一种典型的___线性______结构。
2. 在一个长度为n的顺序表的第i个元素之前插入一个元素,需要后移__n-i+1__个元素。
3. 顺序表中逻辑上相邻的元素的物理位置__相邻______。
4. 要从一个顺序表删除一个元素时,被删除元素之后的所有元素均需向__前___移一个位置,移动过程是从_前____向_后____依次移动每一个元素。
5. 在线性表的顺序存储中,元素之间的逻辑关系是通过__物理存储位置_____决定的;在线性表的链接存储中,元素之间的逻辑关系是通过__链域的指针值_____决定的。
6. 在双向链表中,每个结点含有两个指针域,一个指向___前趋____结点,另一个指向____后继___结点。
7. 当对一个线性表经常进行存取操作,而很少进行插入和删除操作时,则采用___顺序__存储结构为宜。
相反,当经常进行的是插入和删除操作时,则采用__链接___存储结构为宜。
8. 顺序表中逻辑上相邻的元素,物理位置__一定_____相邻,单链表中逻辑上相邻的元素,物理位置___不一定____相邻。
9. 线性表、栈和队列都是__线性_____结构,可以在线性表的___任何___位置插入和删除元素;对于栈只能在___栈顶____位置插入和删除元素;对于队列只能在___队尾____位置插入元素和在___队头____位置删除元素。
10. 根据线性表的链式存储结构中每个结点所含指针的个数,链表可分为__单链表_______和__双链表_____;而根据指针的联接方式,链表又可分为__循环链表______和__非循环链表______。
11. 在单链表中设置头结点的作用是__使空表和非空表统一______。
12. 对于一个具有n个结点的单链表,在已知的结点p后插入一个新结点的时间复杂度为_o(1)_____,在给定值为x的结点后插入一个新结点的时间复杂度为__o(n)_____。
13. 对于一个栈作进栈运算时,应先判别栈是否为__栈满_____,作退栈运算时,应先判别栈是否为_栈空______,当栈中元素为m时,作进栈运算时发生上溢,则说明栈的可用最大容量为___m____。

一、单选题C01、在一个图中,所有顶点的度数之和等于图的边数的倍。
A)1/2 B)1 C)2 D)4B02、在一个有向图中,所有顶点的入度之和等于所有顶点的出度之和的倍。
A)1/2 B)1 C)2 D)4B03、有8个结点的无向图最多有条边。
A)14 B)28 C)56 D)112C04、有8个结点的无向连通图最少有条边。
A)5 B)6 C)7 D)8C05、有8个结点的有向完全图有条边。
A)14 B)28 C)56 D)112B06、用邻接表表示图进行广度优先遍历时,通常是采用来实现算法的。
A)栈 B)队列 C)树 D)图A07、用邻接表表示图进行深度优先遍历时,通常是采用来实现算法的。
A)栈 B)队列 C)树 D)图A08、一个含n个顶点和e条弧的有向图以邻接矩阵表示法为存储结构,则计算该有向图中某个顶点出度的时间复杂度为。
A)O(n) B)O(e) C)O(n+e) D)O(n2)C09、已知图的邻接矩阵,根据算法思想,则从顶点0出发按深度优先遍历的结点序列是。
A)0 2 4 3 1 5 6 B)0 1 3 6 5 4 2 C)0 1 3 4 2 5 6 D)0 3 6 1 5 4 2B10、已知图的邻接矩阵同上题,根据算法,则从顶点0出发,按广度优先遍历的结点序列是。
A)0 2 4 3 6 5 1 B)0 1 2 3 4 6 5 C)0 4 2 3 1 5 6 D)0 1 3 4 2 5 6D11、已知图的邻接表如下所示,根据算法,则从顶点0出发按深度优先遍历的结点序列是。
A)0 1 3 2 B)0 2 3 1 C)0 3 2 1 D)0 1 2 3A12、已知图的邻接表如下所示,根据算法,则从顶点0出发按广度优先遍历的结点序列是。
A)0 3 2 1 B)0 1 2 3 C)0 1 3 2 D)0 3 1 2A13、图的深度优先遍历类似于二叉树的。
A)先序遍历 B)中序遍历 C)后序遍历 D)层次遍历D14、图的广度优先遍历类似于二叉树的。

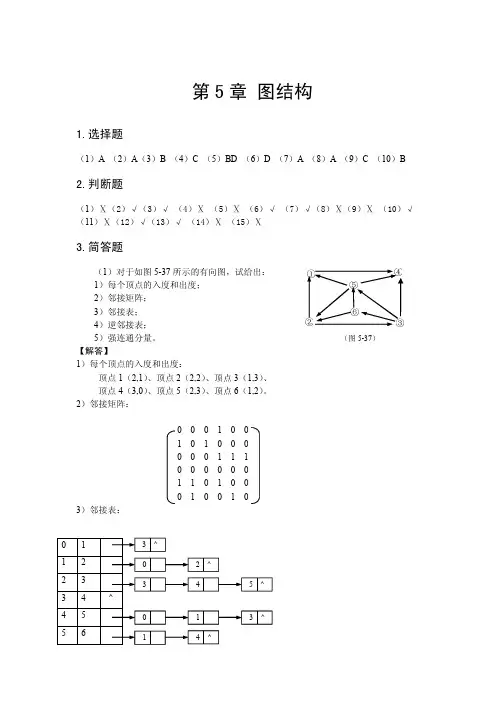
7_1对于图题7.1(P235)的无向图,给出:(1)表示该图的邻接矩阵。
(2)表示该图的邻接表。
(3)图中每个顶点的度。
解:(1)邻接矩阵:0111000100110010010101110111010100100110010001110(2)邻接表:1:2----3----4----NULL;2: 1----4----5----NULL;3: 1----4----6----NULL;4: 1----2----3----5----6----7----NULL;5: 2----4----7----NULL;6: 3----4----7----NULL;7: 4----5----6----NULL;(3)图中每个顶点的度分别为:3,3,3,6,3,3,3。
7_2对于图题7.1的无向图,给出:(1)从顶点1出发,按深度优先搜索法遍历图时所得到的顶点序(2)从顶点1出发,按广度优先法搜索法遍历图时所得到的顶点序列。
(1)DFS法:存储结构:本题采用邻接表作为图的存储结构,邻接表中的各个链表的结点形式由类型L_NODE规定,而各个链表的头指针存放在数组head中。
数组e中的元素e[0],e[1],…..,e[m-1]给出图中的m条边,e中结点形式由类型E_NODE规定。
visit[i]数组用来表示顶点i是否被访问过。
遍历前置visit各元素为0,若顶点i被访问过,则置visit[i]为1.算法分析:首先访问出发顶点v.接着,选择一个与v相邻接且未被访问过的的顶点w访问之,再从w 开始进行深度优先搜索。
每当到达一个其所有相邻接的顶点都被访问过的顶点,就从最后访问的顶点开始,依次退回到尚有邻接顶点未曾访问过的顶点u,并从u开始进行深度优先搜索。
这个过程进行到所有顶点都被访问过,或从任何一个已访问过的顶点出发,再也无法到达未曾访问过的顶点,则搜索过程就结束。
另一方面,先建立一个相应的具有n个顶点,m条边的无向图的邻接表。

数据结构图的存储结构及基本操作数据结构图的存储结构及基本操作1·引言数据结构图是一种用来描述数据元素之间关系的图形结构,它可以表示实体之间的联系和依赖关系。
本文将介绍数据结构图的存储结构及基本操作。
2·存储结构2·1 邻接矩阵邻接矩阵是使用二维数组来表示数据结构图中各个节点之间的关系。
矩阵的行和列代表节点,如果两个节点之间存在边,则矩阵相应位置的值为1,否则为0。
2·2 邻接表邻接表是使用链表来表示数据结构图中各个节点之间的关系。
每个节点都有一个链表,链表中的每个元素表示与该节点相邻的节点。
2·3 十字链表十字链表是使用链表来表示数据结构图中各个节点之间的关系。
每个节点都有两个链表,一个表示该节点指向的节点,另一个表示指向该节点的节点。
2·4 邻接多重表邻接多重表是使用链表来表示数据结构图中各个节点之间的关系。
每个节点都有一个链表,链表中的每个元素表示与该节点相邻的边。
3·基本操作3·1 创建图创建一个空的数据结构图,根据需要选择适当的存储结构。
3·2 插入节点在数据结构图中插入一个节点,并建立与其他节点的关系。
3·3 删除节点从数据结构图中删除一个节点,并删除与其他节点的关系。
3·4 插入边在数据结构图中插入一条边,连接两个节点。
3·5 删除边从数据结构图中删除一条边,断开两个节点的连接。
3·6 遍历图按照某种规则遍历整个数据结构图,访问每个节点。
本文档涉及附件:无本文所涉及的法律名词及注释:1·邻接矩阵:用于表示图的存储结构,矩阵的行和列代表图的节点,矩阵的值表示节点之间的连接关系。
2·邻接表:用于表示图的存储结构,每个节点都有一个链表,链表中的每个元素表示与该节点相邻的节点。
3·十字链表:用于表示图的存储结构,每个节点都有两个链表,一个表示该节点指向的节点,另一个表示指向该节点的节点。

数据结构-1(总分100,考试时间90分钟)一、单项选择题在每小题列出的四个选项中只有一个选项是符合题目要求的1. 设数组data[0..m]作为循环队列SQ的存储空间,front为队头指针,rear为队尾指针,则执行出队操作的语句为( )A. front:=front+1B. front:=(front+1)mod mC. rear:=(rear+1)mod mD. front:=(front+1)mod(m+1)2. 在Hash函数H(k)=k MOD m中,一般来讲,m应取( )A. 奇数B. 偶数C. 素数D. 充分大的数3. 实现任意二叉树的后序遍历的非递归算法而不使用栈结构,最佳方案是二叉树采用( )存储结构。
A. 二叉链表B. 广义表C. 三叉链表D. 顺序4. 向一个栈顶指针为Top的链栈中插入一个s所指结点时,其操作步骤为( )A. Top—>next=s;B. s—>next=Top—>next;Top—>next=s;C. s—>next=Top;top=s;D. s—>next=Top; Top=Top—>next;5. 快速排序在最坏情况下的时间复杂度是( )A. O(nlogB. O(n2)C. O(n3)D. 都不对6. 内部排序的方法有许多种,( )方法是从未排序序列中依次取出元素,与已排序序列中的元素作比较,将其放入已排序序列的正确位置上。
A. 归并排序B. 插入排序C. 快速排序D. 选择排序7. 对于一个具有N个顶点的图,如果我们采用邻接矩阵法表示,则此矩阵的维数应该是( )A. (N-1)×(N-1)B. N×NC. (N+1)×(N+1)D. 不确定8. 在一个长度为n的顺序表(顺序存储的线性表)中,向第i个元素(1≤i≤n+1)之前插入一个新元素时,需向后移动( )个元素。
A. n-iB. n-i+1C. n-i-1D. i9. 下面四种排序方法中,平均查找长度最小的是( )A. 插入排序B. 选择排序C. 快速排序D. 归并排序10. 如果我们采用二分查找法查找一个长度为n的有序表,则查找每个元素的平均比较次数( )对应的判定树的高度(假设树高h≥2)。

邻接矩阵和邻接表邻接矩阵与邻接表都是建立在图结构中的逻辑关系,用于存储图中相邻节点之间的连接关系,是用来表示网络的重要的数据结构,大量应用于无权图或带权图的表示、存储和操作。
一、邻接矩阵1.概念:邻接矩阵(Adjacency Matrix)是一种用来存储图G中顶点之间的关系的结构,它是由一个二维数组来表示的,数组中的每一行和每一列都代表一个顶点,而数组元素之间的值有一定含义,这些值代表了两个顶点之间是否存在连接,也就是说,只有存在边才能够表示值,否则以无穷大表示。
2.特点:(1)存储空间大:邻接矩阵是一个矩形数组,其中的每一行和每一列都代表一个顶点,那么它所占用的空间一定是与节点的度数有关的,因此在稀疏图结构中使用邻接矩阵对空间也会非常消耗;(2)查找方便:邻接矩阵存储的是节点两两之间的连接关系,只要矩阵中相应位置上的值不为无穷大,就能判断这两个节点之间是否存在连接,因此在查找图中某两节点之间连接关系的时候,邻接矩阵的效率会比较高。
二、邻接表1.概念:邻接表也是一种非常常用的表示图的数据结构,它采用的是链表的形式来存储顶点的相邻的结点的关系,也就是说,每个顶点都会有一个链表来存储它周围的结点。
它能够比较好的展示出图中各个顶点之间的关系,以及图中结点的孤立情况。
2.特点:(1)存储空间小:由于邻接表使用链表的方式存储节点,它可以精确的表示两个节点的距离,而非像邻接矩阵一样,数组中的每一行和每一列都代表一个节点,因此,它所占用的空间会比邻接矩阵小些,在内存空间中有比较大的空间优势;(2)查找速度略低:虽然邻接表能精确的表示两个节点之间的距离,而且只需要占用少量内存,但是查找两点之间连接关系所花费的时间会略大于邻接矩阵。

邻接矩阵和邻接表是图论中用于表示图结构的两种常见方式,而深度遍历和广度遍历则是图论中常用的两种图遍历算法。
本文将从简介、原理和应用三个方面探讨这四个主题。
一、邻接矩阵和邻接表1.邻接矩阵邻接矩阵是一种使用二维数组来表示图中顶点之间关系的方法。
如果图中有n个顶点,那么对应的邻接矩阵就是一个n*n的矩阵,其中元素a[i][j]表示顶点i和顶点j之间是否有边,通常用0和1表示。
邻接矩阵适用于稠密图,其存储结构简单,可以直观地展示图的结构,但对于稀疏图来说可能会造成存储空间的浪费。
2.邻接表邻接表是一种使用链表来表示图中顶点之间关系的方法。
对于图中的每一个顶点,都维护一个相邻顶点的列表,图中所有顶点的列表再组合成一个链表,用于表示整个图的结构。
邻接表适用于稀疏图,其存储结构灵活,可以有效地节省存储空间,但查找任意两个顶点之间的关系可能会比较耗时。
二、深度遍历和广度遍历原理1.深度遍历深度遍历是一种用于遍历或搜索图中节点的算法,其原理是从图的某一顶点出发,沿着一条路径不断向下遍历直到末端,然后回溯到上一个节点继续遍历。
深度遍历使用栈来实现,可以通过递归或迭代来进行。
2.广度遍历广度遍历是一种用于遍历或搜索图中节点的算法,其原理是从图的某一顶点出发,依次访问其所有相邻节点,然后再依次访问这些相邻节点的相邻节点,以此类推。
广度遍历使用队列来实现。
三、深度遍历和广度遍历的应用1.深度遍历的应用深度遍历常用于求解图的连通分量、拓扑排序、解决迷宫问题等。
在连通分量中,深度遍历可以帮助我们找到图中的所有连通分量,并对其进行标记,用于进一步的算法运算。
在拓扑排序中,深度遍历可以帮助我们找到一个合理的顺序,用以处理依赖关系问题。
在解决迷宫问题时,深度遍历可以帮助我们找到一条从起点到终点的路径。
2.广度遍历的应用广度遍历常用于求解最短路径、解决迷宫问题等。
在求解最短路径中,广度遍历可以帮助我们找到起点到终点的最短路径,从而解决了许多实际问题。
图的两种存储⽅式---邻接矩阵和邻接表图:图是⼀种数据结构,由顶点的有穷⾮空集合和顶点之间边的集合组成,表⽰为G(V,E),V表⽰为顶点的集合,E表⽰为边的集合。
⾸先肯定是要对图进⾏存储,然后进⾏⼀系列的操作,下⾯对图的两种存储⽅式邻接矩阵和邻接表尽⾏介绍。
(⼀)、邻接矩阵存储:⽤两个数组分别进⾏存储数据元素(顶点)的信息和数据元素之间的关系(边或弧)的信息。
存储顶点:⽤⼀个连续的空间存储n个顶点。
存储顶点之间的边:将由n个顶点组成的边⽤⼀个n*n的矩阵来存储,如果两个顶点之间有边,则表⽰为1,否则表⽰为0。
下⾯⽤代码来实现邻接矩阵的存储:#define SIZE 10class Graph{public:Graph(){MaxVertices = SIZE;NumVertices = NumEdges = 0;VerticesList = new char[sizeof(char)*MaxVertices];Edge = new int*[sizeof(int*)*MaxVertices];int i,j;for(i = 0;i<MaxVertices;i++)Edge[i] = new int[sizeof(int)*MaxVertices];for(i = 0;i<MaxVertices;i++){for(j = 0;j<MaxVertices;++j)Edge[i][j] = 0;}}void ShowGraph(){int i,j;cout<<"";for(i = 0;i<NumVertices;i++)cout<<VerticesList[i]<<"";cout<<endl;for(i = 0;i<NumVertices;i++){cout<<VerticesList[i]<<"";for(j = 0;j<NumVertices;j++)cout<<Edge[i][j] <<"";cout<<endl;}cout<<endl;}int GetVertexPos(char v){int i;for(i = 0;i<NumVertices;i++){if(VerticesList[i] == v)return i;}return -1;}~Graph(){Destroy();}void Insert(char v){if(NumVertices < MaxVertices){VerticesList[NumVertices] = v;NumVertices++;}}void InsertEdge(char v1,char v2){int i,j;int p1 = GetVertexPos(v1);int p2 = GetVertexPos(v2);if(p1 == -1 || p2 == -1)return ;Edge[p1][p2] = Edge[p2][p1] = 1;NumEdges++;}void RemoveEdge(char v1,char v2){int p1 = GetVertexPos(v1);int p2 = GetVertexPos(v2);if(p1 == -1 || p2== -1)return;if(Edge[p1][p2] == 0)return;Edge[p1][p2] = Edge[p2][p1] = 0;NumEdges--;}void Destroy(){delete[] VerticesList;VerticesList = NULL;for(int i = 0;i<NumVertices;i++){delete Edge[i];Edge[i] = NULL;}delete[] Edge;Edge = NULL;MaxVertices = NumVertices = 0;}void RemoveVertex(char v){int i,j;int p = GetVertexPos(v);int reNum = 0;if(p == -1)return;for(i = p;i<NumVertices-1;i++){VerticesList[i] = VerticesList[i+1];}for(i = 0;i<NumVertices;i++){if(Edge[p][i] != 0)reNum++;}for(i = p;i<NumVertices-1;i++){for(j = 0;j<NumVertices;j++){Edge[i][j] = Edge[i+1][j];}}for(i = p;i<NumVertices;i++){for(j = 0;j<NumVertices;j++)Edge[j][i] = Edge[j][i+1];}NumVertices--;NumEdges = NumEdges - reNum;}private:int MaxVertices;int NumVertices;int NumEdges;char *VerticesList;int **Edge;};上⾯的类中的数据有定义最⼤的顶点的个数(MaxVertices),当前顶点的个数(NumVertices),当前边的个数(NumEdges),保存顶点的数组,保存边的数组。
2022年南京林业大学计算机科学与技术专业《数据结构与算法》科目期末试卷A(有答案)一、选择题1、用数组r存储静态链表,结点的next域指向后继,工作指针j指向链中结点,使j沿链移动的操作为()。
A.j=r[j].nextB.j=j+lC.j=j->nextD.j=r[j]->next2、下列说法不正确的是()。
A.图的遍历是从给定的源点出发每个顶点仅被访问一次B.遍历的基本方法有两种:深度遍历和广度遍历C.图的深度遍历不适用于有向图D.图的深度遍历是一个递归过程3、某线性表中最常用的操作是在最后一个元素之后插入一个元素和删除第一个元素,则采用()存储方式最节省运算时间。
A.单链表B.仅有头指针的单循环链表C.双链表D.仅有尾指针的单循环链表4、最大容量为n的循环队列,队尾指针是rear,队头:front,则队空的条件是()。
A.(rear+1)MOD n=frontB.rear=frontC.rear+1=frontD.(rear-1)MOD n=front5、在用邻接表表示图时,拓扑排序算法时间复杂度为()。
A.O(n)B.O(n+e)C.O(n*n)D.O(n*n*n)6、已知字符串S为“abaabaabacacaabaabcc”,模式串t为“abaabc”,采用KMP算法进行匹配,第一次出现“失配”(s!=t)时,i=j=5,则下次开始匹配时,i和j的值分别()。
A.i=1,j=0 B.i=5,j=0 C.i=5,j=2 D.i=6,j=27、下列选项中,不能构成折半查找中关键字比较序列的是()。
A.500,200,450,180 B.500,450,200,180C.180,500,200,450 D.180,200,500,4508、有关二叉树下列说法正确的是()。
A.二叉树的度为2B.一棵二叉树的度可以小于2C.二叉树中至少有一个结点的度为2D.二叉树中任何一个结点的度都为29、下述二叉树中,哪一种满足性质:从任一结点出发到根的路径上所经过的结点序列按其关键字有序()。
分别以邻接矩阵和邻接表作为图的存储结构,给出连通图的深度优先
遍历的递归算法
算法思想:
(1)访问出发点vi,并将其标记为已访问过。
(2)遍历vi的的每一个邻接点vj,若vi未曾访问过,则以vi为新的出发点继续进行深度优先遍历。
算法实现:
Boolean visited[max]; // 访问标志数
void DFS(Graph G, int v)
{ // 算法7.5从第v个顶点出发递归地深度优先遍历图G
int w;
visited[v] = TRUE; printf("%d ",v); // 访问第v个顶点for (w=FirstAdjVex(G, v); w>=0; w=NextAdjVex(G, v, w)) if (!visited[w]) // 对v的尚未访问的邻接顶点w递归调用DFS DFS(G, w);
}
/*****************************************************/ /*以邻接矩阵作为存储结构*/
DFS1(MGraph G,int i)
{int j;
visited[i]=1;
printf("%c",G.vexs[i]);
for(j=1;j<=G.vexnum;j++)
if(!visited[j]&&G.arcs[i][j]==1) DFS1(G,j);
}
/*以邻接表作为存储结构*/
DFS2(ALGraph G,int i)
{int j;
ArcPtr p;
visited[i]=1;
printf("%c",G.vertices[i].data);
for(p=G.vertices[i].firstarc;p!=NULL;p=p->nextarc)
{j=p->adjvex;
if(!visited[j]) DFS2(j);
}
}。