SUN-SVM-在线更换硬盘-RAID1
- 格式:docx
- 大小:103.78 KB
- 文档页数:7

在线更换硬盘说明:现有一台Sun T5220的主机系统的一个分区镜像损坏,分区处于维护模式,系统有如下报错:一.基本检测:1.尝试同步分区2.查看传输状态结果:同步时,磁盘状态显示传输错误一直增加,分区镜像无法同步,需要在线更换损坏磁盘。
二.在线更换:1.查询分区镜像信息bash-3.2# metastat d6d6: 镜像次镜像0: d16状态:确定次镜像1: d26状态:需要维护传送:1读入选项:roundrobin (缺省)写入选项:parallel (缺省)大小:74549376 块(35 GB)d16: d6 的次镜像状态: 确定大小:74549376 块(35 GB)条0:设备引导块Dbase 状态Reloc 热备援c1t0d0s6 0 否确定是d26: d6 的次镜像状态: 需要维护调用:metareplace d6 c1t1d0s6 <新设备>大小:74549376 块(35 GB)条0:设备引导块Dbase 状态Reloc 热备援c1t1d0s6 0 否维护是bash-3.2# metadbflags first blk block counta m p luo 16 8192 /dev/dsk/c1t0d0s4a p luo 8208 8192 /dev/dsk/c1t0d0s4a p luo 16 8192 /dev/dsk/c1t1d0s4a p luo 8208 8192 /dev/dsk/c1t1d0s4a p luo 16400 8192 /dev/dsk/c1t1d0s4bash-3.2# metastat -pd7 -m d17 d27 1d17 1 1 c1t0d0s7d27 1 1 c1t1d0s7d5 -m d15 d25 1d15 1 1 c1t0d0s5d25 1 1 c1t1d0s5d3 -m d13 d23 1d13 1 1 c1t0d0s3d23 1 1 c1t1d0s3d1 -m d11 d21 1d11 1 1 c1t0d0s1d21 1 1 c1t1d0s1d0 -m d10 d20 1d10 1 1 c1t0d0s0d20 1 1 c1t1d0s0d6 -m d16 d26 1d16 1 1 c1t0d0s6d26 1 1 c1t1d0s62.删除损坏磁盘的分区镜像bash-3.2# metadetach d6 d26metadetach: LSOMCR01: d6: 尝试在具有错误组件的次镜像上操作bash-3.2# metadetach -f d6 d26d6: 次镜像d26 已拆除bash-3.2# metadetach d0 d20d0: 次镜像d20 已拆除bash-3.2# metadetach d1 d21d1: 次镜像d21 已拆除bash-3.2# metadetach d3 d23d3: 次镜像d23 已拆除bash-3.2# metadetach d5 d25d5: 次镜像d25 已拆除bash-3.2# metadetach d7 d27d7: 次镜像d27 已拆除bash-3.2# metaclear d26d26: Concat/Stripe 已清除bash-3.2# metaclear d20d20: Concat/Stripe 已清除bash-3.2# metaclear d21d21: Concat/Stripe 已清除bash-3.2# metaclear d23d23: Concat/Stripe 已清除bash-3.2# metaclear d25d25: Concat/Stripe 已清除bash-3.2# metaclear d27d27: Concat/Stripe 已清除3.删除损坏磁盘状态数据库bash-3.2# metadbflags first blk block counta m p luo 16 8192 /dev/dsk/c1t0d0s4a p luo 8208 8192 /dev/dsk/c1t0d0s4a p luo 16 8192 /dev/dsk/c1t1d0s4a p luo 8208 8192 /dev/dsk/c1t1d0s4a p luo 16400 8192 /dev/dsk/c1t1d0s4bash-3.2# metadb -d c1t1d0s4bash-3.2# metadbflags first blk block counta m p luo 16 8192 /dev/dsk/c1t0d0s4a p luo 8208 8192 /dev/dsk/c1t0d0s44.更换损坏的磁盘在确保镜像信息已清理的状态下,拔出损坏磁盘,更换新的磁盘。

- 一块硬盘安装系统,不破坏数据和系统的情况下迁移为 RAID1.txt今天心情不好。
我只有四句话想说。
包括这句和前面的两句。
我的话说完了对付凶恶的人,就要比他更凶恶;对付卑鄙的人,就要比他更卑鄙没有情人味,哪来人情味拿什么整死你,我的爱人。
收银员说:没零钱了,找你两个塑料袋吧! HP ProLiant DL160 G5 服务器系列(热插拔机型)一块硬盘安装系统,不破坏数据和系统的情况下迁移为 RAID1。
开机按 F10,首先进入 BIOS 中,将硬盘的模式设置为 compatible,这样安装 windows 2003 sp1 系统时就不会提示需要软驱来加载驱动了。
一块硬盘安装操作系统安装完成后,需要在系统下打 Embedded RAID 的驱动,否则如果直接更改阵列级别,则在更改 raid 之后再启动系统,会造成系统蓝屏,而无法进入系统。
从惠普网站上,选择 HP ProLiant DL120 G5 Server 的驱动下载中,下载 HP Embedded G5 SATA RAID Controller Driver,将其解压缩到某个目录。
下注 :这个文件在系统下是无法直接运行的,会提示软件无需安装。
打开控制面板中添加新硬件 /选择硬件已连接好 /选择添加新硬件 /手动选择 /从磁盘安装/选择之前解压缩好的文件中,其中有一个 aarahci.inf 的文件 /列表里会有 2 个设备,这2 个设备都要安装上,当然,一次只能安装一个,另外一个重复上面的过程,重新再添加一次。
/添加完成添加完成后,重新启动一次服务器,然后再进入到 BIOS 中将 Compatible 模式改为Enhanced -> RAID重启 server,按 F8 进入阵列配置模式选择 Configure Drives >按 Insert 键,将 2 块硬盘添加去 >然后在主菜单中,选择 Create Array,按 Insert 键添加 2 块硬盘,回车。

以SUN Fire V880 Server(6*73GB Dsik)为例讲解在Solarsi8下使用命令行的方式安装及维护RAID1和RAID5。
本文档内容都经本人实践验证过,但对于不同机型仅供参考。
Disk分布情况:注:0,1做镜像;2,3,4,5做RAID5系统盘(c1t0d0)分区及镜像盘(c1t1d0)情况:系统安装完成后,使用Solarsi8 software 2 of 2安装DiskSuite_4.2.1软件,安装路径:/cdrom/cdrom0/Solaris_8/EA/installer & 选择默认安装就可以。
用root用户登陆,运行以下命令:上面命令将第二块硬盘(c1t1d0)的文件分区表调整为和引导盘一致。
将下面这行注释掉或删除,如下:一、RAID1对各个分区逐一作镜像:①先生成replicas,这是DiskSuite内部用的。
②Creating a mirr or from swap③Creating a mirror from /usr④Creating a mirro r from /opt⑤Creating a mirror from /var⑥Creating a mirror from /home⑦Creating a mirror from /#metastat (检查镜像进度)镜像完成后,还需作如下操作:修改EEPROMok devalias(察看启动设备)ok nvalias rootdisk /pci@8,600000/SUNW,qlc@4/fp@0,0/disk@0,0ok nvalias mirrdisk /pci@8,600000/SUNW,qlc@4/fp@0,0/disk@1,0ok setenv boot-device rootdisk mirrdiskeeprom命令:boot-device=rootdisk mirrdiskboot-device=rootdisk mirrdiskuse-nvramrc?=truenvramrc=devalias mirrdisk /pci@8,600000/SUNW,qlc@4/fp@0,0/disk@1,0 devalias rootdisk /pci@8,600000/SUNW,qlc@4/fp@0,0/disk@0,0#ls -l c1t0d0s0lrwxrwxrwx 1 root root 70 1月 2 10:45 c1t0d0s0-> ../../devices/pci@8,600000/SUNW,qlc@4/fp@0,0/ssd@w21000000870e80e7,0:a 对应:/pci@8,600000/SUNW,qlc@4/fp@0,0/disk@0,0root@voiplnjvr4 # ls -l c1t1d0s0lrwxrwxrwx 1 root root 70 1月 2 10:45 c1t1d0s0-> ../../devices/pci@8,600000/SUNW,qlc@4/fp@0,0/ssd@w21000000870fb287,0:a 对应:/pci@8,600000/SUNW,qlc@4/fp@0,0/disk@1,0测试:ok boot rootdisk 系统启动正常。

在Sun Fire V440 服务器上,可以使用板载Ultra-4 SCSI 控制器来配置硬件磁盘镜像。
它的性能比使用卷管理软件的常规软件镜像的性能更高。
RAID 1 提供了最高级别的数据保护,但是,由于所有的数据都要存储两遍,因此增加了存储成本,而且,它与RAID 0 或RAID 5 相比,写操作性能有所降低。
在Sun Fire V440 服务器上,Ultra-4 SCSI 控制器支持使用Solaris 操作环境raidctl实用程序来进行内部硬件磁盘镜像。
使用raidctl 实用程序创建的硬件磁盘镜像,与使用卷管理软件创建的硬件磁盘镜像稍有不同。
使用软件的镜像中,每个驱动器在虚拟设备树中都有其自己的条目,并且对两个虚拟设备都可以执行读/ 写操作。
在硬件磁盘镜像中,设备树中只出现一个设备(主设备)。
镜像的设备(从设备)对操作系统是不可见的,只能通过Ultra-4 SCSI 控制器进行访问。
一.如何创建硬件磁盘镜像执行此过程可以在系统上创建内部硬件磁盘镜像配置。
1.开始之前,验证磁盘驱动器与逻辑设备名称及物理设备名称之间的对应关系。
[Copy to clipboard][ - ] CODE:磁盘插槽号逻辑设备名称* 物理设备名称0号插槽 c1t0d0 /devices/pci@1f,700000/scsi@2/sd@0,03号插槽 c1t1d0 /devices/pci@1f,700000/scsi@2/sd@1,02号插槽 c1t2d0 /devices/pci@1f,700000/scsi@2/sd@2,03号插槽 c1t3d0 /devices/pci@1f,700000/scsi@2/sd@3,0注:逻辑设备名称在您的系统上的显示方式可能有所不同,这取决于所安装的附加磁盘控制器的数量和类型。
2.要验证硬件磁盘镜像尚未存在,请键入:[Copy to clipboard][ - ] CODE:# raidctlNo RAID volumes found.3.创建内部硬件磁盘镜像:[Copy to clipboard][ - ] CODE:# raidctl -c c1t0d0 c1t1d0创建RAID 镜像之后,从属驱动器(在本例中为c1t1d0)将从Solaris 设备树中消失。

一次SUNv440更换硬盘过程solaris9+vxvm 一台sun v440 机器出现了硬件错误.本地硬盘有4块, 显示如下槽位磁盘状态---- ------ ---------0 c1t0d0 硬件错误1 c1t1d0 正常2 c1t2d0 正常3 c1t3d0 正常原先是c1t0d0和c1t1d0做了硬raid 1.查询raidctl状态发现为degraded.使用format命令检查c1t0d0出现大量无法修复的IO错误,无法软修复. 以下处理过程主要实现把0槽位硬盘拿掉, 3槽位硬盘挪到0槽位上, 暂时顶替0槽位工作.1和2槽位硬盘做硬raid.最后处理的结果是0-2槽位都有硬盘,3槽位空出,待sun服务工程师来更换硬盘.槽位磁盘状态---- ------ ---------0 c1t0d0 正常1 c1t1d0 正常2 c1t2d0 正常3 c1t3d0 空置操作过程如下1. 需要修改/etc/vfstab,把所有的c1t0d0替换成c1t1d0 (防止重启之后找不到引导盘).2. 修改dump device 为c1t1d0dumpadm -d /dev/dsk/c1t1d03. 从vxvm删除硬盘c1t0d0本地硬盘并让vxvm完全控制(本地没有vxvm volume,所有卷都在磁阵上), 只是在vxdisk命令能看到所有的磁盘信息.vxdisk rm c1t0d0由于dmp控制,需要从vxvm强制拆除对硬盘的控制root@mmsc1 # vxdmpadm getsubpaths ctlr=c1NAME STATE[A] PATH-TYPE[M] DMPNODENAME ENCLR-TYPE ENCLR-NAME ATTRS====================================== ========================================= =c1t0d0s2 ENABLED(A) - c1t0d0s2 OTHER_DISKS OTHER_DISKS -c1t1d0s2 ENABLED(A) - c1t1d0s2 OTHER_DISKS OTHER_DISKS -c1t2d0s2 ENABLED(A) - c1t2d0s2 OTHER_DISKS OTHER_DISKS -c1t3d0s2 ENABLED(A) - c1t3d0s2 OTHER_DISKS OTHER_DISKS -要拆除的是第一块硬盘c1t0d0s2.root@mmsc1 # vxdmpadm -f disable path=c1t0d0s2 ctlr=c1 再次查询发现state状态更改为disabled了.root@mmsc1 # vxdmpadm getsubpaths ctlr=c1NAME STATE[A] PATH-TYPE[M] DMPNODENAME ENCLR-TYPE ENCLR-NAME ATTRS====================================== ========================================= =c1t0d0s2 DISABLED - c1t0d0s2 OTHER_DISKS OTHER_DISKS -c1t1d0s2 ENABLED(A) - c1t1d0s2 OTHER_DISKS OTHER_DISKS -c1t2d0s2 ENABLED(A) - c1t2d0s2 OTHER_DISKS OTHER_DISKS -c1t3d0s2 ENABLED(A) - c1t3d0s2 OTHER_DISKS OTHER_DISKS -4. 准备拆除0槽位硬盘cfgadm -c unconfigure c1::dsk/c1t0d0这时候硬盘边上亮起了蓝灯,表示可以拔出硬盘.5. 对c1t3d0同样的操作vxdmpadm -f disable path=c1t3d0s2 ctlr=c1cfgadm -c unconfigure c1::dsk/c1t3d0同样,等蓝灯亮起拔出该盘,插入到0槽位.6. 恢复系统对0槽位的控制cfgadm -c configure c1::dsk/c1t0d0root@mmsc1 # vxdisk listDEVICE TYPE DISK GROUP STATUSc1t0d0s2 auto:sliced - -onlinec1t1d0s2 auto:none - - online invalidc1t2d0s2 auto:none - - online invalidc1t3d0s2 auto - - errorc3t8d0s2 auto:sliced - - onlinec3t9d0s2 auto:sliced - - onlinec3t10d0s2 auto:sliced - - onlinec3t11d0s2 auto:sliced - - onlinec3t12d0s2 auto:none - - online invalidc5t8d0s2 auto:sliced - - onlinec5t9d0s2 auto:sliced - - onlinec5t10d0s2 auto:sliced - - onlinec5t11d0s2 auto:sliced - - onlinec5t12d0s2 auto:sliced - - online7. 不要让vxvm管理该硬盘root@mmsc1 # vxdisk destroy c1t0d08. 修改openboot信息,把c1t1d0,c1t2d0 配置起来.eeprom "nvramrc=devalias rootdisk /pci@1f,700000/scsi@2/disk@1,0:adevalias rootmirr /pci@1f,700000/scsi@2/disk@2,0:a"eeprom "use-nvramrc?=true"eeprom boot-device="rootdisk rootmirr net"9. 创建硬raidraidctl -c c1t1d0 c1t2d010. 等同步完成后重启系统,验证结果。

XX城D1000硬盘更换步骤方案作者Utstarcom参与人gechengping审核人签发人签发日期全球服务事业部(2006年XX月XX日)文档修订记录本文的相关约定本文内容涉及到许多操作命令,为了便于读者阅读,我们对本文进行了如下约定:•输入图标表示以下的内容为输入命令,输入命令使用宋体黑斜体9号字符,并缩进两个字符。
•输出图标表示以下的内容为输出显示,输出显示使用宋体黑斜体9号字符,并缩进两个字符。
•以分析图标的文字内容是对上面输出显示的解释,在分析的文字内容中如要引用输出显示的内容,则使用双引号。
•当一行代码太长以至于超过本文的一行时,它在一个合适的地方断开并在下一行继续,续行符“\”出现在上一行的行尾。
(在输入含有这个续行符的一行时,应该把它作为没有断开的一个长行)。
•本文所有检查命令除特殊申明,都是在主数据库服务器ipasdb执行的。
若命令以”#”开头表示以root用户来执行,若命令以”$”开头表示以Oracle用户来执行。
•……注意部分的的内容,以注意图标开始,具体内容加黑框表示。
注意给出了重要的信息,以帮助读者理解。
•……警告部分的的内容,以警告图标开始,具体内容加黑框表示。
警告提供了有关有害操作或危险错误的信息。
对警告信息要特别注意。
XXX系统实施方案目录1问题描述 (1)2故障分析 (1)3实施时间点 (3)4故障实施步骤 (3)4.1更换D1000硬盘 (3)4.2停止DB2服务器,更换磁带机。
............................ 错误!未定义书签。
5恢复业务 ......................................... 错误!未定义书签。
6测试业务 (5)1 问题描述巡检中发现一台D1000磁盘阵列故障。
并且已经被卷管理软件剔除。
需要及时更换。
2 故障分析XX城市DB服务器,硬件环境是两台sun netra 20 和两台d1000阵列,软件环境为sun cluster3.0与vxvm 3.2. 其中一台d1000上面出现一块硬盘故障,需要更换,下面截取了部分系统的信息.#vxprint –thDisk group: ipasdgDG NAME NCONFIG NLOG MINORS GROUP-IDDM NAME DEVICE TYPE PRIVLEN PUBLEN STATERV NAME RLINK_CNT KSTATE STATE PRIMARY DATAVOLS SRLRL NAME RVG KSTATE STATE REM_HOST REM_DG REM_RLNKV NAME RVG KSTATE STATE LENGTH READPOL PREFPLEX UTYPEPL NAME VOLUME KSTATE STATE LENGTH LAYOUT NCOL/WID MODESD NAME PLEX DISK DISKOFFS LENGTH [COL/]OFF DEVICE MODESV NAME PLEX VOLNAME NVOLLAYR LENGTH [COL/]OFF AM/NM MODEDC NAME PARENTVOL LOGVOLSP NAME SNAPVOL DCOdg ipasdg default default 101000 1069948421.1079.sxjc_db2dm ipasdg01 c3t0d0s2 sliced 2888 71121402 -dm ipasdg02 c3t1d0s2 sliced 2888 71121402 -dm ipasdg03 c3t8d0s2 sliced 2888 71121402 -dm ipasdg04 c3t9d0s2 sliced 2888 71121402 -dm ipasdg05 c5t0d0s2 sliced 2888 71121402 -dm ipasdg06 - - - - NODEVICEdm ipasdg07 c5t8d0s2 sliced 2888 71121402 -dm ipasdg08 c5t9d0s2 sliced 2888 71121402 -#vxdisk listDEVICE TYPE DISK GROUP STATUSc1t0d0s2 sliced - - errorc1t0d0s7 simple c1t0d0s7 rootdg onlinec1t1d0s2 sliced - - errorc1t1d0s7 simple c1t1d0s7 rootdg onlinec3t0d0s2 sliced ipasdg01 ipasdg onlinec3t1d0s2 sliced ipasdg02 ipasdg onlinec3t8d0s2 sliced ipasdg03 ipasdg onlinec3t9d0s2 sliced ipasdg04 ipasdg onlinec5t0d0s2 sliced ipasdg05 ipasdg onlinec5t1d0s2 sliced - (ipasdg) onlinec5t8d0s2 sliced ipasdg07 ipasdg onlinec5t9d0s2 sliced ipasdg08 ipasdg online- - ipasdg06 ipasdg failed was:c5t1d0s2从系统的信息中发现,故障的硬盘为c5t1d0s2并且该硬盘不是系统的Quorum devices.#scdidadm –L1 sxjc_db1:/dev/rdsk/c0t6d0 /dev/did/rdsk/d12 sxjc_db1:/dev/rdsk/c1t0d0 /dev/did/rdsk/d23 sxjc_db1:/dev/rdsk/c1t1d0 /dev/did/rdsk/d34 sxjc_db1:/dev/rdsk/c3t0d0 /dev/did/rdsk/d44 sxjc_db2:/dev/rdsk/c3t0d0 /dev/did/rdsk/d46 sxjc_db1:/dev/rdsk/c3t8d0 /dev/did/rdsk/d66 sxjc_db2:/dev/rdsk/c3t8d0 /dev/did/rdsk/d67 sxjc_db1:/dev/rdsk/c3t9d0 /dev/did/rdsk/d77 sxjc_db2:/dev/rdsk/c3t9d0 /dev/did/rdsk/d78 sxjc_db1:/dev/rdsk/c5t0d0 /dev/did/rdsk/d88 sxjc_db2:/dev/rdsk/c5t0d0 /dev/did/rdsk/d89 sxjc_db1:/dev/rdsk/c5t1d0 /dev/did/rdsk/d99 sxjc_db2:/dev/rdsk/c5t1d0 /dev/did/rdsk/d910 sxjc_db1:/dev/rdsk/c5t8d0 /dev/did/rdsk/d1010 sxjc_db2:/dev/rdsk/c5t8d0 /dev/did/rdsk/d1011 sxjc_db1:/dev/rdsk/c5t9d0 /dev/did/rdsk/d1111 sxjc_db2:/dev/rdsk/c5t9d0 /dev/did/rdsk/d1112 sxjc_db2:/dev/rdsk/c0t6d0 /dev/did/rdsk/d1213 sxjc_db2:/dev/rdsk/c1t1d0 /dev/did/rdsk/d1314 sxjc_db2:/dev/rdsk/c1t0d0 /dev/did/rdsk/d1416 sxjc_db1:/dev/rdsk/c3t1d0 /dev/did/rdsk/d1616 sxjc_db2:/dev/rdsk/c3t1d0 /dev/did/rdsk/d168185 sxjc_db2:/dev/rmt/5 /dev/did/rmt/78186 sxjc_db2:/dev/rmt/4 /dev/did/rmt/68187 sxjc_db2:/dev/rmt/3 /dev/did/rmt/58188 sxjc_db2:/dev/rmt/2 /dev/did/rmt/48189 sxjc_db2:/dev/rmt/1 /dev/did/rmt/38190 sxjc_db2:/dev/rmt/0 /dev/did/rmt/28191 sxjc_db1:/dev/rmt/0 /dev/did/rmt/1此外DB2系统Netra 20服务器的磁带机无法识别,环路报错,需要更换磁带机。


SDS RAID1更换硬盘操作一、查看客户SUN E3500设备SDS配置情况。
1、查看SDS运行状态,确定故障硬盘。
# metastat2、查看md.tab 文件。
# cd /etc/lvm/# more md.tab& # metainit –a& # metastat –p > filename3、查看vfstab 文件。
# more /etc/vfstab4、查看硬盘分区情况,确定metadb挂接分区。
# format5、查看metadb状态# metadb –i6、查看bootdisk mirrdisk 配置情况# eeprom | boot-device& OK printenv& OK devalias二、用户配置环境查看结束,并做相关纪录后开始更换硬盘。
假如c1t0d0主盘坏掉,metadb挂接在c1t0d0s7,停机更换硬盘后需要如下的操作:1、ok boot mirrdisk –s2、#metadb -d c1t0d0s7#prtvtoc /dev/rdsk/c1t1d0s2 |fmthard - s -/dev/rdsk/c1t0d0s23、#metadb -a -f -c 3 c1t0d0s74、#halt5、ok boot mirrdisk#metareplace -e d0 c1t0d0s0d0:device c1t0d0s0 is enabled#metareplace -e d1 c1t0d0s1#metareplace -e d3 c1t0d0s3#metareplace -e d4 c1t0d0s4#metareplace -e d5 c1t0d0s5#metareplace -e d6 c1t0d0s66、#installboot /usr/platform/`uname-i`/lib/fs/ufs/bootblk /dev/rdsk/c1t0d0s07、检查/etc/vfstab文件,以bootdisk重启系统。

Solaris中创建RAID1镜像RAID1也叫做镜像,需要至少两块硬盘,提供数据冗余。
Solaris 8是用SUN Solstice DiskSuite来做RAID1,在Solaris 9等后续版本中更新为Solaris V olume Manager,功能一样,使用的命令也类似。
一、准备工作1.在安装系统时,对硬盘分区需注意,一般我们把c0t0d0s7划分为一个10MB到100MB的分区留着用来存放Metadb数据,Metadb是DiskSuite存储硬盘配置信息的文件,机器每次启动时DiskSuite都从Metadb文件中读取这些信息。
一旦Metadb被破坏,机器将不能正常启动,所以一般我们都将Metadb做多个备份,这个分区的大小取决于你Metadb备份的多少。
2.如果是Solaris 9,在安装系统时包含了Solaris V olume Manager,可以直接使用。
如果是Solaris 8,就稍微麻烦一点了,需要手动从Solaris 8 Software 2 of 2光盘中安装DiskSuite,安装方法如下:1)将Solaris 8 Software 2 of 2光盘插入光驱,cd到/cdrom目录下并ls查看是否已自动挂载了光驱,如果没有,手动挂载光驱:# mount -F hsfs -o ro /dev/dsk/c0t1d0s0 /cdrom如果不知道光驱的位置,可以# iostat -En查看。
2)进入DiskSuite安装包所在目录:# cd /cdrom/cdrom0/Solaris_8/EA/products/DiskSuite_4.2.1/sparc/Packages查看安装包# ls,4.2.1版本中有10个包,分别为SUNWlvma、SUNWlvmg、SUNWlvmr、SUNWmdg、SUNWmdja、SUNWmdnr、SUNWmdnu、SUNWmdr、SUNWmdu、SUNWmdx。
精品文档
更换硬盘步骤
步骤一打开 toolkit工具,选择存储-> 部件更换 ->FRU 更换
步骤二添加设备,按提示输入存储登录信息。
步骤三选择添加的存储设备。
并确认。
步骤四选择硬盘
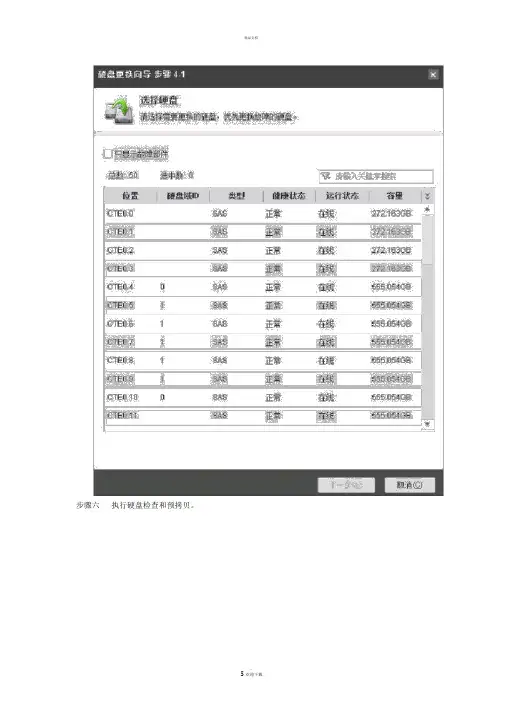
步骤五选择需要更换的硬盘。
步骤六执行硬盘检查和预拷贝。
步骤七完成预拷贝后,请拔出旧硬盘,更换新硬盘,请注意硬盘槽位。
更换完成后点击“确认已更换。
”
步骤八通过更换后健康状态检查。
完成更换硬盘操作。
欢迎您的下载,
资料仅供参考!
致力为企业和个人提供合同协议,策划案计划书,学习资料等
等
打造全网一站式需求。

VxVM在线数据迁移和卷空间扩容(raid0串联-条带)1.概述在使用VxVM管理的卷,由于使用串联方式存储数据,IO越来越不能满足当前需求,存储设备也要更换为更高端的设备;所以需要数据进行在线迁移,在新存储上使用条带化的raid0存储数据,并对目录空间也进行相应的扩容。
操作环境如下:2.操作准备1、从新存储映射3块8G的磁盘给服务器;2、在服务器上识别到3块新磁盘,并进行初始化;3.操作步骤3.1.查看VxVM信息查看当前VxVM 磁盘、卷和分区状态信息bash-3.2# vxdisk listDEVICE TYPE DISK GROUP STATUSdisk_0 auto:SVM - - SVMdisk_1 auto:SVM - - SVMds3400-0_0 auto:none - - online invalidds3400-0_1 auto:none - - online invalidds3400-0_2 auto:none - - online invalid//新映射的三块磁盘ds3400-0_3 auto:none - - online invalidds3400-0_4 auto:none - - online invalidds3400-0_5 auto:cdsdisk quan-dg01 quan-dg online//当前VxVM只使用了一块磁盘bash-3.2# vxprint –ht //查看当前VxVM卷的状态Disk group: quan-dgTY NAME ASSOC KSTATE LENGTH PLOFFS STATE TUTIL0 PUTIL0 dg quan-dg quan-dg - - - - - -v vol-10g - ENABLED ACTIVE 20971520 SELECT - fsgen pl vol-10g-01 vol-10g ENABLED ACTIVE 20971520 CONCAT - RWsd quan-dg01-01 vol-10g-01 quan-dg01 0 20971520 0 ds3400-0_5 ENAbash-3.2# df –h 查看当前系统分区状态Filesystem size used avail capacity Mounted on/dev/md/dsk/d100 34G 7.6G 26G 23% //devices 0K 0K 0K 0% /devicesctfs 0K 0K 0K 0% /system/contractproc 0K 0K 0K 0% /procmnttab 0K 0K 0K 0% /etc/mnttabswap 13G 1.8M 13G 1% /etc/svc/volatileswap 13G 128K 13G 1% /tmpswap 13G 48K 13G 1% /var/runswap 13G 0K 13G 0% /dev/vx/dmpswap 13G 0K 13G 0% /dev/vx/rdmp/dev/md/dsk/d130 14G 260M 14G 2% /export/home/dev/vx/dsk/quan-dg/vol-10g9.8G 4.3G 5.5G 45% /quan-databash-3.2#3.2.初始化新磁盘并加入quan-dg把新存储映射的三块磁盘初始化并加入quan-dg的磁盘组bash-3.2# vxdiskadd ds3400-0_0 ds3400-0_1 ds3400-0_2Add or initialize disksMenu: VolumeManager/Disk/AddDisksHere are the disks selected. Output format: [Device_Name]ds3400-0_0 ds3400-0_1 ds3400-0_2Continue operation? [y,n,q,?] (default: y)You can choose to add these disks to an existing disk group, anew disk group, or you can leave these disks available for useby future add or replacement operations. To create a new diskgroup, select a disk group name that does not yet exist. Toleave the disks available for future use, specify a disk groupname of "none".Which disk group [<group>,none,list,q,?] (default: none) quan-dg //输入要加入的dg名Use default disk names for these disks? [y,n,q,?] (default: y)Add disks as spare disks for quan-dg? [y,n,q,?] (default: n)Exclude disks from hot-relocation use? [y,n,q,?] (default: n)Add site tag to disks? [y,n,q,?] (default: n)The selected disks will be added to the disk group quan-dg withdefault disk names.ds3400-0_0 ds3400-0_1 ds3400-0_2Continue with operation? [y,n,q,?] (default: y)Do you want to use the default layout for all disks being initialized?[y,n,q,?] (default: y)Initializing device ds3400-0_0.Initializing device ds3400-0_1.Initializing device ds3400-0_2.VxVM NOTICE V-5-2-88Adding disk device ds3400-0_0 to disk group quan-dg with diskname quan-dg02.VxVM NOTICE V-5-2-88Adding disk device ds3400-0_1 to disk group quan-dg with diskname quan-dg03.VxVM NOTICE V-5-2-88Adding disk device ds3400-0_2 to disk group quan-dg with diskname quan-dg04.Goodbye.bash-3.2#3.3.手动创建三个子磁盘在刚才初始化的三个磁盘上各创建一个4G空间的子磁盘,bash-3.2# vxmake -g quan-dg sd quan-dg02-02 quan-dg02,0g,4gbash-3.2# vxmake -g quan-dg sd quan-dg03-02 quan-dg03,0g,4gbash-3.2# vxmake -g quan-dg sd quan-dg04-02 quan-dg04,0g,4gbash-3.2# vxprint –ht //查看子磁盘信息Disk group: quan-dgdg quan-dg default default 15000 1417245255.44.test-02dm quan-dg01 ds3400-0_5 auto 65536 52354816 -dm quan-dg02 ds3400-0_0 auto 65536 41869056 -dm quan-dg03 ds3400-0_1 auto 65536 41869056 -dm quan-dg04 ds3400-0_2 auto 65536 41869056 -sd quan-dg02-02 vol-raid0-st quan-dg02 25165824 8388608 0/0 ds3400-0_0 ENA sd quan-dg03-02 vol-raid0-st quan-dg03 25165824 8388608 1/0 ds3400-0_1 ENA sd quan-dg04-02 vol-raid0-st quan-dg04 25165824 8388608 2/0 ds3400-0_2 ENAv vol-10g - ENABLED ACTIVE 20971520 SELECT - fsgen pl vol-10g-01 vol-10g ENABLED ACTIVE 20971520 CONCAT - RW sd quan-dg01-01 vol-10g-01 quan-dg01 0 20971520 0 ds3400-0_5 ENA3.4.手动创建条带的plex手动创建条带化的plex(vol-raid0-st),并加入三块子磁盘bash-3.2# vxmake -g quan-dg plex vol-raid0-st layout=stripe stwidth=32 ncolumn=3sd=quan-dg02-02,quan-dg03-02,quan-dg04-02 bash-3.2#bash-3.2# vxprint –ht //查看plex状态Disk group: quan-dgdg quan-dg default default 15000 1417245255.44.test-02dm quan-dg01 ds3400-0_5 auto 65536 52354816 -dm quan-dg02 ds3400-0_0 auto 65536 41869056 -dm quan-dg03 ds3400-0_1 auto 65536 41869056 -dm quan-dg04 ds3400-0_2 auto 65536 41869056 -pl vol-raid0-st - DISABLED - 25165824 STRIPE 3/32 RWsd quan-dg02-02 vol-raid0-st quan-dg02 0 8388608 0/0 ds3400-0_0 ENAsd quan-dg03-02 vol-raid0-st quan-dg03 0 8388608 1/0 ds3400-0_1 ENAsd quan-dg04-02 vol-raid0-st quan-dg04 0 8388608 2/0 ds3400-0_2 ENAv vol-10g - ENABLED ACTIVE 20971520 SELECT - fsgen pl vol-10g-01 vol-10g ENABLED ACTIVE 20971520 CONCAT - RW sd quan-dg01-01 vol-10g-01 quan-dg01 0 20971520 0 ds3400-0_5 ENA bash-3.2#3.5.手动把plex关联给卷vol-10g把上一步简的条带化得plex(vol-raid0-st)关联给系统正在使用的卷vol-10g;bash-3.2# vxplex -g quan-dg att vol-10g vol-raid0-st &//加上&让其后台执行,便于在同步过程中查看同步进度和系统状态bash-3.2#3.6.查看同步进度和卷的状态用vxtask list可以查看数据同步进度bash-3.2# vxtask list //查看数据同步进度TASKID PTID TYPE/STATE PCT PROGRESS163 ATCOPY/R 56.11%0/20971520/11767808 PLXATT vol-10g vol-raid0-st quan-dg bash-3.2#bash-3.2# vxprint -htDisk group: quan-dgdg quan-dg default default 15000 1417245255.44.test-02dm quan-dg01 ds3400-0_5 auto 65536 52354816 -dm quan-dg02 ds3400-0_0 auto 65536 41869056 -dm quan-dg03 ds3400-0_1 auto 65536 41869056 -dm quan-dg04 ds3400-0_2 auto 65536 41869056 -v vol-10g - ENABLED ACTIVE 20971520 SELECT vol-raid0-st fsgen pl vol-10g-01 vol-10g ENABLED ACTIVE 31457280 CONCAT - WOsd quan-dg01-01 vol-10g-01 quan-dg01 0 31457280 0 ds3400-0_5 ENApl vol-raid0-st vol-10g ENABLED TEMP 25165824 STRIPE 3/32 RW//在数据同步过程中plex状态为TEMP,同步完成后会变为ACTIVE sd quan-dg02-02 vol-raid0-st quan-dg02 25165824 8388608 0/0 ds3400-0_0 ENAsd quan-dg03-02 vol-raid0-st quan-dg03 25165824 8388608 1/0 ds3400-0_1 ENAsd quan-dg04-02 vol-raid0-st quan-dg04 25165824 8388608 2/0 ds3400-0_2 ENA 3.7.分离旧的plex并查检目录状态在新的plex数据同步完成后,可以把旧的plex(vol-10g-01)从卷中分离出来,然后查看挂在目录/quan-data的数据是否正常;bash-3.2# vxplex -g quan-dg det vol-10g-01 //分离plexbash-3.2#bash-3.2# df –h //查看当前系统分区状态Filesystem size used avail capacity Mounted on/dev/md/dsk/d100 34G 7.6G 26G 23% //devices 0K 0K 0K 0% /devicesctfs 0K 0K 0K 0% /system/contractproc 0K 0K 0K 0% /procmnttab 0K 0K 0K 0% /etc/mnttabswap 13G 1.8M 13G 1% /etc/svc/volatileswap 13G 128K 13G 1% /tmpswap 13G 48K 13G 1% /var/runswap 13G 0K 13G 0% /dev/vx/dmpswap 13G 0K 13G 0% /dev/vx/rdmp/dev/md/dsk/d130 14G 260M 14G 2% /export/home/dev/vx/dsk/quan-dg/vol-10g9.8G 4.3G 5.5G 45% /quan-databash-3.2#3.8.删除旧的plex和旧存储磁盘在新的plex数据同步完成后,可以把旧的plex(vol-10g-01)删除bash-3.2# vxedit -g quan-dg -r rm vol-10g-013.9.目录空间扩容查看卷(vol-10g)可扩容的最大空间为24 G,之前在创建子磁盘时三块子磁盘一共使用了12G的空间,还可以扩容11G多的空间。
案例设备:SUNT4-1备注:T3,T4系列是一样的案例目标:按照用户需求,4块300GB硬盘做2个RAID1案例解决步骤:一、在OBP下创建卷1.在创建之前要设置auto-boot?为falseok setenvauto-boot? falseauto-boot?= falseok reset-all2、进入到disk目录ok show-disks........ok probe-scsi-all/pci@400/pci@2/pci@0/pci@f/pci@0/usb@0,2/hub@2/hub@3/storage@2Unit 0 Removable Read Only device AMI Virtual CDROM 1.00/pci@400/pci@2/pci@0/pci@4/scsi@0ok select /pci@400/pci@2/pci@0/pci@4/scsi@03、查看是否创建了卷ok show-volumesNo volumes to show4、使用create命令创建卷show-children Lists all connected physical drives and logical volumes.show-volumes Lists all connected logical volumes in detail.create-raid0-volume Creates a RAID 0 volume (minimum two targets).create-raid1-volume Creates a RAID 1 volume (exactly two targets).create-raid1e-volume Creates a RAID 1e volume (minimum three targets).delete-volume Deletes a RAID volume.activate-volume Re-activate a RAID volume after the motherboard has beenreplaced. ok a 9 create-raid1-volume (使用a 9两块硬盘做raid1)Volumehas been createdok c b create-raid1-volume(使用c b两块硬盘做raid1)Volumehas been created两个卷已经建好5、查看建立的卷Volume 0 Target 380 Type RAID1 (Mirroring)Name voldisk2 WWID 0c4550c2e3a2bd1cOptimal Enabled Volume Not Consistent Operations Pending2 Members 583983104 Blocks, 298 GBDisk 1Primary OptimalTarget c HITACHI H106030SDSUN300G A2B0 PhyNum 1Disk 0Secondary OptimalTarget b HITACHI H106030SDSUN300G A2B0 PhyNum 3Volume 1 Target 381 Type RAID1 (Mirroring)Name voldisk1 WWID 0686b54dd6602dc1Optimal Enabled Volume Not Consistent Background Init In Progress 2 Members 583983104 Blocks, 298 GBDisk 3Primary OptimalTarget a HITACHI H106030SDSUN300G A2B0 PhyNum 2Disk 2Secondary OptimalTarget 9 HITACHI H106030SDSUN300G A2B0 PhyNum 06、退出设备目录ok unselect-dev7、把我们第一步的参数改回来auto-boot?为true,reset系统案例延伸二、在OBP下删除卷1、在创建之前要设置auto-boot?为false fcode-debug? 为trueok setenv auto-boot? falseauto-boot?= falseok reset-all2、进入到disk目录ok show-disks。
raid1更换故障硬盘处理过程:1.服务器两个硬盘/dev/sda和/dev/sdb组成raid1,结构如下/dev/sda1 + /dev/sdb1 = /dev/md0/dev/sda2 + /dev/sdb2 = /dev/md1现在通过cat /proc/mdstat发现/dev/sdb不正常,需要更换2.先在系统移除/dev/sdb,操作时需要先移除/dev/sdb的每一个分区a.移除/dev/sdb1先标记/dev/sdb1为fail[root@servera~]# mdadm --manage /dev/md0 --fail /dev/sdb1 这时输入cat /proc/mdstat应该可以看到以下信息Personalities : [linear] [multipath] [raid0] [raid1] [raid5] [raid4] [raid6] [raid10]md0 : active raid1 sda1[0] sdb1[2](F)24418688 blocks [2/1] [U_]md1 : active raid1 sda2[0] sdb2[1]24418688 blocks [2/2] [UU]unused devices: <none>移除/dev/sdb1[root@servera~]# mdadm --manage /dev/md0 --remove /dev/sdb1 这时系统返回的结果应该是mdadm: hot removed /dev/sdb1这时输入cat /proc/mdstat应该可以看到以下信息Personalities : [linear] [multipath] [raid0] [raid1] [raid5] [raid4] [raid6] [raid10]md0 : active raid1 sda1[0]24418688?blocks [2/1] [U_]md1 : active raid1 sda2[0] sdb2[1]24418688?blocks [2/2] [UU]unused devices: <none>b.用相同方法移除/dev/sdb2[root@servera~]# mdadm --manage /dev/md1 --fail /dev/sdb2[root@servera~]# cat /proc/mdstatPersonalities : [linear] [multipath] [raid0] [raid1] [raid5] [raid4] [raid6] [raid10]md0 : active raid1 sda1[0]24418688 blocks [2/1] [U_]md1 : active raid1 sda2[0] sdb2[2](F)24418688 blocks [2/1] [U_]unused devices: <none>[root@servera~]# mdadm --manage /dev/md1 --remove /dev/sdb2mdadm: hot removed /dev/sdb2[root@servera~]# cat /proc/mdstatPersonalities : [linear] [multipath] [raid0] [raid1] [raid5] [raid4] [raid6] [raid10]md0 : active raid1 sda1[0]24418688 blocks [2/1] [U_]md1 : active raid1 sda2[0]24418688 blocks [2/1] [U_]unused devices: <none>这时可以看到只有/dev/sda在工作.3.关机[root@servera~]# shutdown -h now4.将硬盘/dev/sdb更换为新的硬盘,开机5.系统启动完成以后,给新硬盘/dev/sdb做与/dev/sda相同的分区,可以用下面的命令完成[root@servera~]# sfdisk -d /dev/sda | sfdisk /dev/sdb上面的命令表示从/dev/sda复制分区表至/dev/sdb。
SUN svm系统盘故障更换方案神州数码系统集成服务有限公司2015-06-09一、实施原因:在系统中输入format查看系统中的硬盘在系统中输入metastat查看故障硬盘的所有子镜像状态是否有maintenance 在系统中输入iostat -En查看硬盘是否有报错。
二、实施目的:更换故障硬盘,避免系统宕机风险三、实施人员:神州数码工程师四、实施前期准备:(一)客户方需要做好如下的准备:1)做好相关应用数据备份2)做好操作系统备份3)协调好非业务繁忙时间段(二)神州数码方需要做好如下的准备:1)确认备件到场;2)准备好现场使用相关工具3) 更换操作前,先登检查机器状态,搜集相关信息,做好设备检查工作4)确认故障硬盘位置五、实施步骤:方案一:直接踢盘使用metareplace同步1.删除有故障的meta数据库,metadb –d c1t0d0s7,使用metadb –i验证2.将硬盘踢出,luxadm remove_device /dev/rdsk/c1t0d0s2,踢不出的情况,使用luxadm remove_device –F /dev/rdsk/c1t0d0s2还无法踢出那么先将该盘offline,使用luxadm –e offine /dev/rdsk/c1t0d0s2,然后再执行踢盘操作3.将盘踢出后物理更换硬盘,然后使用devfsadm –C扫描新硬盘4.将新添加的硬盘接入系统,使用luxadm insert_device /dev/rdsk/c1t0d0s25.复制分区表,使用prtvtoc /dev/rdsk/ c1t4d0s2|fmthard -s - /dev/rdsk/c1t0d0s26.进行故障修复同步,分别对故障分片同步,同步完成一个再同步下一个metareplace –e d0 c1t0d0s0metareplace –e d1 c1t0d0s1metareplace –e d3 c1t0d0s3metareplace –e d4 c1t0d0s4metareplace –e d5 c1t0d0s5metareplace –e d6 c1t0d0s67.重建meta数据库,metadb –a –c 3 c1t0d0s78.全部做好之后使用metastat验证镜像和软分区的状态方案二:拆镜像更换硬盘1.删除有故障的meta数据库,metadb –d c1t0d0s7,使用metadb –i验证2.分别拆除故障子镜像metadetach –f d0 d20metadetach –f d1 d21metadetach –f d3 d23metadetach –f d4 d24metadetach –f d5 d25metadetach –f d6 d263.删除故障子镜像metaclear d20metaclear d21metaclear d23metaclear d24metaclear d25metaclear d264.将硬盘踢出,luxadm remove_device /dev/rdsk/c1t0d0s2,踢不出的情况,使用luxadm remove_device –F /dev/rdsk/c1t0d0s2还无法踢出那么先将该盘offline,使用luxadm –e offine /dev/rdsk/c1t0d0s2,然后再执行踢盘操作5.将盘踢出后物理更换硬盘,然后使用devfsadm –C扫描新硬盘6.复制分区表,使用prtvtoc /dev/rdsk/c1t4d0s2|fmthard –s - /dev/rdsk/c1t0d0s27.刷新设备ID ,metadevadm –u c1t0d08.重建meta数据库metadb –a –c 3 c1t0d0s79.重新创建子镜像metainit d20 1 1 c1t0d0s0metainit d21 1 1 c1t0d0s1metainit d23 1 1 c1t0d0s3metainit d24 1 1 c1t0d0s4metainit d25 1 1 c1t0d0s5metainit d26 1 1 c1t0d0s610.依附子镜像,依附之后开始同步metattach d0 d20metattach d1 d21metattach d3 d23metattach d4 d24metattach d5 d25metattach d6 d2611.使用metastat查看同步状态进行硬盘更换操作需会影响到该机器上的应用业务读写速度,更换时间大致如下,更换前做机器检查 30分钟更换控制器硬盘过程 1小时更换后检查 30分钟# fsck -F ufs /dev/md/rdsk/d10vi /etc/vfstab /dev/dsk/c0t0d0s0 /dev/rdsk/c0t0d0s0 / ufs 1 novi /etc/system #rootdev:/pseudo/md@0:0,1,blk修改mddb.cf文件 # vi /a/etc/lvm/mddb.cf#sd 7 16 id0 -449#sd 7 8208 id0 -8641六、存在风险点:更换硬盘过程中不排除主机其它部件同时也出问题,有可能导致数据丢失,客户一定要做好应用和操作系统的备份。
现场查看硬盘灯状态,灯已不亮1.查看当前镜像状态root@byshwlerp # metastatd66: MirrorSubmirror 0: d76State: OkaySubmirror 1: d86State: Needs maintenancePass: 1Read option: roundrobin (default)Write option: parallel (default)Size: 286556160 blocks (136 GB)d76: Submirror of d66State: OkaySize: 286556160 blocks (136 GB)Stripe 0:Device Start Block Dbase State Reloc Hot Sparec1t4d0s6 0 No Okay Yesd86: Submirror of d66State: Needs maintenanceInvoke: metareplace d66 c1t5d0s6 <new device>Size: 286556160 blocks (136 GB)Stripe 0:Device Start Block Dbase State Reloc Hot Sparec1t5d0s6 0 No Maintenance Yes2.将子镜像d86从主镜像d66剔除root@byshwlerp # metadetach -f d66 d86d66: submirror d86 is detached3.清除子镜像d86root@byshwlerp # metaclear d86d86: Concat/Stripe is cleared4.查看当前镜像状态数据库root@byshwlerp # metadbflags first blk block counta m p luo 16 8192 /dev/dsk/c1t0d0s7a p luo 8208 8192 /dev/dsk/c1t0d0s7a p luo 16400 8192 /dev/dsk/c1t0d0s7a p luo 16 8192 /dev/dsk/c1t1d0s7a p luo 8208 8192 /dev/dsk/c1t1d0s7a p luo 16400 8192 /dev/dsk/c1t1d0s7a p luo 16 8192 /dev/dsk/c1t2d0s7a p luo 8208 8192 /dev/dsk/c1t2d0s7a p luo 16400 8192 /dev/dsk/c1t2d0s7a p luo 16 8192 /dev/dsk/c1t8d0s7a p luo 8208 8192 /dev/dsk/c1t8d0s7a p luo 16400 8192 /dev/dsk/c1t8d0s7a p luo 16 8192 /dev/dsk/c1t4d0s7a p luo 8208 8192 /dev/dsk/c1t4d0s7a p luo 16400 8192 /dev/dsk/c1t4d0s7M p 16 unknown /dev/dsk/c1t5d0s7M p 8208 unknown /dev/dsk/c1t5d0s7M p 16400 unknown /dev/dsk/c1t5d0s7#c1t5d0s7的数据库已受损 a p luo 16 8192 /dev/dsk/c1t11d0s7a p luo 8208 8192 /dev/dsk/c1t11d0s7a p luo 16400 8192 /dev/dsk/c1t11d0s75.删除坏盘的状态数据库root@byshwlerp # metadb -d c1t5d0s76.将坏盘从系统中踢除root@byshwlerp # luxadm remove_device /dev/dsk/c1t5d0s2WARNING!!! Please ensure that no filesystems are mounted on these device(s).All data on these devices should have been backed up.Inquiry failed for /devices/pci@8,600000/SUNW,qlc@2/fp@0,0/ssd@w500000e010aefa11,0:cError opening the path. - /dev/dsk/c1t5d0s2.由于该盘已经在系统中无法识别,所以可以直接拔出,如是在系统尚可识别情况下,根据提示拔出硬盘再按enter键7.拔出硬盘后,执行如下指令root@byshwlerp # luxadm insert_devicePlease hit <RETURN> when you have finished adding Fibre Channel Enclosure(s)/Device(s):出现以上这个提示就可以插入硬盘,插入之后再按enter挂载硬盘!!!!Waiting for Loop Initialization to complete...New Logical Nodes under /dev/dsk and /dev/rdsk :c1t5d0s0c1t5d0s1c1t5d0s2c1t5d0s3c1t5d0s4c1t5d0s5c1t5d0s6c1t5d0s7#系统已经识别到该硬盘No new enclosure(s) were added!!8.查看系统识别硬盘情况root@byshwlerp # formatSearching for disks...donec1t5d0: configured with capacity of 136.71GBAVAILABLE DISK SELECTIONS:0. c1t0d0 <SUN146G cyl 14087 alt 2 hd 24 sec 848>/pci@8,600000/SUNW,qlc@2/fp@0,0/ssd@w500000e011e658b1,01. c1t1d0 <SUN146G cyl 14087 alt 2 hd 24 sec 848>/pci@8,600000/SUNW,qlc@2/fp@0,0/ssd@w500000e011e6b771,02. c1t2d0 <SUN146G cyl 14087 alt 2 hd 24 sec 848>/pci@8,600000/SUNW,qlc@2/fp@0,0/ssd@w2100001862204428,03. c1t3d0 <SUN146G cyl 14087 alt 2 hd 24 sec 848>/pci@8,600000/SUNW,qlc@2/fp@0,0/ssd@w500000e01a5e4c81,04. c1t4d0 <SUN146G cyl 14087 alt 2 hd 24 sec 848>/pci@8,600000/SUNW,qlc@2/fp@0,0/ssd@w500000e010ad2c01,05. c1t5d0 <SUN146G cyl 14087 alt 2 hd 24 sec 848>/pci@8,600000/SUNW,qlc@2/fp@0,0/ssd@w500000e014ab26e1,0#该盘已挂载6. c1t8d0 <SUN146G cyl 14087 alt 2 hd 24 sec 848>/pci@8,600000/SUNW,qlc@2/fp@0,0/ssd@w2100001862d3bdc4,07. c1t11d0 <SUN146G cyl 14087 alt 2 hd 24 sec 848>/pci@8,600000/SUNW,qlc@2/fp@0,0/ssd@w210000186274ce40,0Specify disk (enter its number): ^Z[1]+ Stopped formatroot@byshwlerp # prtvtoc /dev/rdsk/c1t4d0s2 |fmthard -s - /dev/rdsk/c1t5d0s2 执行指令失效/dev/rdsk/c1t5d0s2: Cannot read VTOCroot@byshwlerp # formatSearching for disks...donec1t5d0: configured with capacity of 136.71GBAVAILABLE DISK SELECTIONS:0. c1t0d0 <SUN146G cyl 14087 alt 2 hd 24 sec 848>/pci@8,600000/SUNW,qlc@2/fp@0,0/ssd@w500000e011e658b1,01. c1t1d0 <SUN146G cyl 14087 alt 2 hd 24 sec 848>/pci@8,600000/SUNW,qlc@2/fp@0,0/ssd@w500000e011e6b771,02. c1t2d0 <SUN146G cyl 14087 alt 2 hd 24 sec 848>/pci@8,600000/SUNW,qlc@2/fp@0,0/ssd@w2100001862204428,03. c1t3d0 <SUN146G cyl 14087 alt 2 hd 24 sec 848>/pci@8,600000/SUNW,qlc@2/fp@0,0/ssd@w500000e01a5e4c81,04. c1t4d0 <SUN146G cyl 14087 alt 2 hd 24 sec 848>/pci@8,600000/SUNW,qlc@2/fp@0,0/ssd@w500000e010ad2c01,05. c1t5d0 <SUN146G cyl 14087 alt 2 hd 24 sec 848>/pci@8,600000/SUNW,qlc@2/fp@0,0/ssd@w500000e014ab26e1,06. c1t8d0 <SUN146G cyl 14087 alt 2 hd 24 sec 848>/pci@8,600000/SUNW,qlc@2/fp@0,0/ssd@w2100001862d3bdc4,07. c1t11d0 <SUN146G cyl 14087 alt 2 hd 24 sec 848>/pci@8,600000/SUNW,qlc@2/fp@0,0/ssd@w210000186274ce40,0Specify disk (enter its number): 5#进入该新换硬盘selecting c1t5d0[disk formatted]Disk not labeled. Label it now? y#需要label标记下,新盘需要label!!!!!!FORMAT MENU:disk - select a disktype - select (define) a disk typepartition - select (define) a partition tablecurrent - describe the current diskformat - format and analyze the diskrepair - repair a defective sectorlabel - write label to the diskanalyze - surface analysisdefect - defect list managementbackup - search for backup labelsverify - read and display labelssave - save new disk/partition definitionsinquiry - show vendor, product and revisionvolname - set 8-character volume name!<cmd> - execute <cmd>, then returnquitformat> quit9.复制分区root@byshwlerp # prtvtoc /dev/rdsk/c1t4d0s2 | fmthard -s - /dev/rdsk/c1t5d0s2#c1t4d0s2是为另一子镜像,2号分区为硬盘总分区,复制这个就行了fmthard: New volume table of contents now in place.指令运行正常了10.重建该盘状态数据库root@byshwlerp # metadb -a -c 3 c1t5d0s7root@byshwlerp # metadbflags first blk block counta m p luo 16 8192 /dev/dsk/c1t0d0s7 a p luo 8208 8192 /dev/dsk/c1t0d0s7 a p luo 16400 8192 /dev/dsk/c1t0d0s7 a p luo 16 8192 /dev/dsk/c1t1d0s7 a p luo 8208 8192 /dev/dsk/c1t1d0s7 a p luo 16400 8192 /dev/dsk/c1t1d0s7 a p luo 16 8192 /dev/dsk/c1t2d0s7 a p luo 8208 8192 /dev/dsk/c1t2d0s7 a p luo 16400 8192 /dev/dsk/c1t2d0s7 a p luo 16 8192 /dev/dsk/c1t8d0s7 a p luo 8208 8192 /dev/dsk/c1t8d0s7 a p luo 16400 8192 /dev/dsk/c1t8d0s7 a p luo 16 8192 /dev/dsk/c1t4d0s7 a p luo 8208 8192 /dev/dsk/c1t4d0s7 a p luo 16400 8192 /dev/dsk/c1t4d0s7 a u 16 8192 /dev/dsk/c1t5d0s7 a u 8208 8192 /dev/dsk/c1t5d0s7 a u 16400 8192 /dev/dsk/c1t5d0s7 a p luo 16 8192 /dev/dsk/c1t11d0s7 a p luo 8208 8192 /dev/dsk/c1t11d0s7a p luo 16400 8192 /dev/dsk/c1t11d0s711.重建子镜像root@byshwlerp # metainit d86 1 1 c1t5d0s6d86: Concat/Stripe is setup12.将子镜像d86加入主镜像d66root@byshwlerp # metattach d66 d86d66: submirror d86 is attached13.再次查看状态数据库root@byshwlerp # metastatd66: MirrorSubmirror 0: d76State: OkaySubmirror 1: d86State: ResyncingResync in progress: 0 % donePass: 1Read option: roundrobin (default)Write option: parallel (default)Size: 286556160 blocks (136 GB)d76: Submirror of d66State: OkaySize: 286556160 blocks (136 GB)Stripe 0:Device Start Block Dbase State Reloc Hot Sparec1t4d0s6 0 No Okay Yesd86: Submirror of d66State: ResyncingSize: 286556160 blocks (136 GB)Stripe 0:Device Start Block Dbase State Reloc Hot Sparec1t5d0s6 0 No Okay Yes14.查看镜像同步百分比,当无输出时,同步完成,可再运行metastat查看镜像状态root@byshwlerp # metastat | grep %Resync in progress: 0 % done。
在线更换硬盘说明:现有一台Sun T5220的主机系统的一个分区镜像损坏,分区处于维护模式,系统有如下报错:一.基本检测:1. 尝试同步分区2.查看传输状态结果:同步时,磁盘状态显示传输错误一直增加,分区镜像无法同步,需要在线更换损坏磁盘。
二.在线更换:1.查询分区镜像信息bash-3.2# metastat d6d6: 镜像次镜像0: d16状态:确定次镜像1: d26状态:需要维护传送:1读入选项:roundrobin (缺省)写入选项:parallel (缺省)大小:74549376 块(35 GB)d16: d6 的次镜像状态: 确定大小:74549376 块(35 GB)条0:设备引导块Dbase 状态Reloc 热备援c1t0d0s6 0 否确定是d26: d6 的次镜像状态: 需要维护调用:metareplace d6 c1t1d0s6 <新设备>大小:74549376 块(35 GB)条0:设备引导块Dbase 状态Reloc 热备援c1t1d0s6 0 否维护是bash-3.2# metadbflags first blk block counta m p luo 16 8192 /dev/dsk/c1t0d0s4a p luo 8208 8192 /dev/dsk/c1t0d0s4a p luo 16 8192 /dev/dsk/c1t1d0s4a p luo 8208 8192 /dev/dsk/c1t1d0s4a p luo 16400 8192 /dev/dsk/c1t1d0s4bash-3.2# metastat -pd7 -m d17 d27 1d17 1 1 c1t0d0s7d27 1 1 c1t1d0s7d5 -m d15 d25 1d15 1 1 c1t0d0s5d25 1 1 c1t1d0s5d3 -m d13 d23 1d13 1 1 c1t0d0s3d23 1 1 c1t1d0s3d1 -m d11 d21 1d11 1 1 c1t0d0s1d21 1 1 c1t1d0s1d0 -m d10 d20 1d10 1 1 c1t0d0s0d20 1 1 c1t1d0s0d6 -m d16 d26 1d16 1 1 c1t0d0s6d26 1 1 c1t1d0s62.删除损坏磁盘的分区镜像bash-3.2# metadetach d6 d26metadetach: LSOMCR01: d6: 尝试在具有错误组件的次镜像上操作bash-3.2# metadetach -f d6 d26d6: 次镜像d26 已拆除bash-3.2# metadetach d0 d20d0: 次镜像d20 已拆除bash-3.2# metadetach d1 d21d1: 次镜像d21 已拆除bash-3.2# metadetach d3 d23d3: 次镜像d23 已拆除bash-3.2# metadetach d5 d25d5: 次镜像d25 已拆除bash-3.2# metadetach d7 d27d7: 次镜像d27 已拆除bash-3.2# metaclear d26d26: Concat/Stripe 已清除bash-3.2# metaclear d20d20: Concat/Stripe 已清除bash-3.2# metaclear d21d21: Concat/Stripe 已清除bash-3.2# metaclear d23d23: Concat/Stripe 已清除bash-3.2# metaclear d25d25: Concat/Stripe 已清除bash-3.2# metaclear d27d27: Concat/Stripe 已清除3.删除损坏磁盘状态数据库bash-3.2# metadbflags first blk block counta m p luo 16 8192 /dev/dsk/c1t0d0s4a p luo 8208 8192 /dev/dsk/c1t0d0s4a p luo 16 8192 /dev/dsk/c1t1d0s4a p luo 8208 8192 /dev/dsk/c1t1d0s4a p luo 16400 8192 /dev/dsk/c1t1d0s4bash-3.2# metadb -d c1t1d0s4bash-3.2# metadbflags first blk block counta m p luo 16 8192 /dev/dsk/c1t0d0s4a p luo 8208 8192 /dev/dsk/c1t0d0s44.更换损坏的磁盘在确保镜像信息已清理的状态下,拔出损坏磁盘,更换新的磁盘。
注意:在拔出磁盘是要仔细看清设备上磁盘的标示,确定那块才是损坏的磁盘,仔细检查更换磁盘的PN号,看是否一至。
A.更换以后查看磁盘是否是否识别bash-3.2# devfsadmbash-3.2# cfgadm –alAp_Id Type Receptacle Occupant Conditionc1 scsi-bus connected configured unknownc1::dsk/c1t0d0 disk connected configured unknownc2 fc-private connected configured unknownc2::201600a0b848fa22 disk connected configured unknownc4 fc-private connected configured unknownc4::201700a0b848fa22 disk connected configured unknownusb0/1 unknown empty unconfigured okusb0/2 unknown empty unconfigured okusb0/3 unknown empty unconfigured okusb1/1 unknown empty unconfigured okusb1/2 unknown empty unconfigured okusb2/1 unknown empty unconfigured okusb2/2 usb-storage connected configured okusb2/3 unknown empty unconfigured okusb2/4 unknown empty unconfigured okusb2/5 unknown empty unconfigured okbash-3.2# formatSearching for disks...doneAVAILABLE DISK SELECTIONS:0. c1t0d0 <SUN146G cyl 14087 alt 2 hd 24 sec 848>/pci@0/pci@0/pci@2/scsi@0/sd@0,01. c1t1d0 <SUN146G cyl 14087 alt 2 hd 24 sec 848>/pci@0/pci@0/pci@2/scsi@0/sd@1,02. c3t600A0B800048F6860000078B52C5461Fd0 <SUN-CSM200_R-0710 cyl 60158 alt 2 hd 256sec 64>/scsi_vhci/ssd@g600a0b800048f6860000078b52c5461f3. c3t600A0B800048F6860000078252C545C5d0 <SUN-CSM200_R-0710 cyl 51198 alt 2 hd 256sec 64>/scsi_vhci/ssd@g600a0b800048f6860000078252c545c54. c3t600A0B800048F6860000078F52C54636d0 <SUN-CSM200_R-0710 cyl 33278 alt 2 hd 512sec 64>/scsi_vhci/ssd@g600a0b800048f6860000078f52c546365. c3t600A0B800048FA220000092D4E6EE1CEd0 <SUN-CSM200_R-0710 cyl 51198 alt 2 hd 64sec 64>/scsi_vhci/ssd@g600a0b800048fa220000092d4e6ee1ce6. c3t600A0B800048FA22000009344E6EE23Ad0 <SUN-CSM200_R-0710 cyl 46718 alt 2 hd 256sec 64>/scsi_vhci/ssd@g600a0b800048fa22000009344e6ee23a7. c3t600A0B800048FA22000009384E6EE265d0 <SUN-CSM200_R-0710 cyl 46718 alt 2 hd 256sec 64>/scsi_vhci/ssd@g600a0b800048fa22000009384e6ee265Specify disk (enter its number): ^Dbash-3.2#4.重新制作镜像A.复制分区表到新硬盘:bash-3.2# prtvtoc /dev/rdsk/c1t0d0s2 | fmthard -s - /dev/rdsk/c1t1d0s2fmthard: New volume table of contents now in place.B.创建状态数据库bash-3.2# metadb -a -f -c 3 c1t1d0s4bash-3.2# metadbflags first blk block counta m p luo 16 8192 /dev/dsk/c1t0d0s4a p luo 8208 8192 /dev/dsk/c1t0d0s4a u 16 8192 /dev/dsk/c1t1d0s4a u 8208 8192 /dev/dsk/c1t1d0s4a u 16400 8192 /dev/dsk/c1t1d0s4B.开始创建镜像:在创建镜像是因保持和以前的镜像的命名一直,否则要修改配置文件/etc/vfstab中的配置。
bash-3.2# metainit d20 1 1 c1t1d0s0d20: Concat/Stripe 已设置bash-3.2# metainit d21 1 1 c1t1d0s1d21: Concat/Stripe 已设置bash-3.2# metainit d23 1 1 c1t1d0s3d23: Concat/Stripe 已设置bash-3.2# metainit d25 1 1 c1t1d0s5d25: Concat/Stripe 已设置bash-3.2# metainit d26 1 1 c1t1d0s6d26: Concat/Stripe 已设置bash-3.2# metainit d27 1 1 c1t1d0s7d27: Concat/Stripe 已设置bash-3.2# metattach d7 d27d7:子镜像d27 is attachedbash-3.2# metattach d5 d25d5:子镜像d25 is attachedbash-3.2# metattach d3 d23d3:子镜像d23 is attachedbash-3.2# metattach d1 d21d1:子镜像d21 is attachedbash-3.2# metattach d0 d20d0:子镜像d20 is attachedbash-3.2# metattach d6 d26d6:子镜像d26 is attached5.查看镜像同步状态bash-3.2# metastat |grep %重新同步在进行中: 0 % 完成重新同步在进行中: 0 % 完成重新同步在进行中: 0 % 完成重新同步在进行中: 0 % 完成重新同步在进行中: 0 % 完成重新同步在进行中: 0 % 完成。