Python爬虫情况总结
- 格式:doc
- 大小:1.27 MB
- 文档页数:23

爬虫项目总结(一)爬虫项目总结文稿前言爬虫项目是一项有着广泛应用的技术,它可以帮助我们从互联网上获取所需的数据,并进行进一步的分析和处理。
作为一名资深的创作者,我已经参与了许多爬虫项目,积累了丰富的经验和技巧。
在本文中,我将总结一些关键点,分享给大家。
正文在进行爬虫项目时,以下几点十分重要:1. 确定需求在开始爬虫项目之前,明确目标和需求是至关重要的。
我们需要考虑要抓取的网站、需要获取的数据类型以及数据的使用方式。
只有明确需求,才能制定出有效的爬虫策略。
2. 选择合适的爬虫框架选择合适的爬虫框架对于项目的成功至关重要。
有许多常见的爬虫框架可供选择,例如Scrapy、BeautifulSoup等。
在选择框架时,要考虑到项目的复杂性、抓取速度、对网站的兼容性等因素。
3. 编写高效的爬虫代码编写高效的爬虫代码能够提高抓取效率和稳定性。
遵循良好的代码规范和设计原则,使用合适的数据结构和算法,优化网络请求和数据处理流程等都是值得注意的点。
4. 处理反爬虫机制在抓取网页的过程中,我们经常会遇到各种反爬虫机制,如验证码、IP封禁等。
为了规避这些机制,我们需要使用一些技巧,例如使用代理IP、设置合理的请求频率、处理验证码等。
5. 数据存储与处理获取到的数据需要进行适当的存储和处理,以便后续的分析和使用。
可以选择将数据存储到数据库中,或生成CSV、JSON等格式的文件。
同时,还要注意数据的清洗和去重,确保数据的质量。
6. 定期维护和更新爬虫项目需要长期维护和更新,因为网站的结构和数据可能会发生变化。
我们需要建立良好的监控机制,及时发现问题并进行修复。
另外,也要关注网站的法律法规和反爬虫政策,确保项目的合法性和可持续性。
结尾总结而言,爬虫项目是一项充满挑战和机遇的技术。
只有根据需求选择合适的框架、编写高效的代码、处理反爬虫机制以及妥善存储和处理数据,我们才能顺利完成爬虫项目并取得良好的结果。
希望本文能对大家在进行爬虫项目时提供帮助。

python爬虫的实验报告一、实验目的随着互联网的迅速发展,大量有价值的数据散落在各个网站中。
Python 爬虫作为一种获取网络数据的有效手段,具有广泛的应用前景。
本次实验的目的是通过使用 Python 编写爬虫程序,深入理解网络爬虫的工作原理,掌握基本的爬虫技术,并能够成功获取指定网站的数据。
二、实验环境1、操作系统:Windows 102、开发工具:PyCharm3、编程语言:Python 3x三、实验原理网络爬虫的基本原理是模拟浏览器向服务器发送请求,获取服务器返回的 HTML 页面,然后通过解析 HTML 页面提取所需的数据。
在Python 中,可以使用`requests`库发送请求,使用`BeautifulSoup`或`lxml`库解析 HTML 页面。
四、实验步骤(一)安装所需库首先,需要安装`requests`、`BeautifulSoup4`和`lxml`库。
可以通过以下命令使用`pip`安装:```pip install requestspip install beautifulsoup4pip install lxml```(二)分析目标网站选择一个要爬取的目标网站,例如具体网站地址。
对该网站的页面结构进行分析,确定要获取的数据所在的位置以及页面的链接规律。
(三)发送请求获取页面使用`requests`库发送 HTTP 请求获取目标页面的 HTML 内容。
以下是一个简单的示例代码:```pythonimport requestsdef get_html(url):response = requestsget(url)if responsestatus_code == 200:return responsetextelse:print("请求失败,状态码:", responsestatus_code)return Noneurl =""html = get_html(url)```(四)解析页面提取数据使用`BeautifulSoup`或`lxml`库对获取到的 HTML 内容进行解析,提取所需的数据。

爬虫实验总结心得一、引言在本次实验中,我们学习了爬虫的基本原理和常用工具,通过实际操作,深入理解了网络爬虫的使用方法和注意事项。
本文将对本次实验的内容进行总结和心得分享。
二、爬虫的基本原理2.1 网络爬虫简介网络爬虫是一种自动获取网络信息的程序,通过模拟浏览器的行为访问网站,并提取和存储感兴趣的数据。
爬虫主要分为两个步骤:访问页面和解析页面。
在访问页面时,我们可以使用Python的requests库发送HTTP请求获取HTML源代码。
解析页面时,常用的库有BeautifulSoup、正则表达式等。
2.2 Robots.txt协议Robots.txt协议用于指示网络爬虫访问网站的权限和限制。
在编写爬虫时,我们需要尊重Robots.txt协议,遵守网站的访问规则,以免对目标网站造成过大的负担或违反法律法规。
2.3 反爬机制和应对方法为了防止恶意爬虫对网站的影响,许多网站采取了反爬机制。
常见的反爬机制包括验证码、IP封禁、User-Agent检测等。
针对这些反爬机制,我们可以采取一些应对方法,如使用代理IP、设置延时访问、修改User-Agent等。
三、常用的爬虫工具3.1 requests库requests库是Python中用于发送HTTP请求的常用库,它简单易用,功能强大。
我们可以使用requests库发送GET请求、POST请求,设置请求头,处理Cookie 等。
3.2 BeautifulSoup库BeautifulSoup库是Python中用于解析HTML和XML的库,它能够自动将HTML文档转换为Python的数据结构,方便我们提取所需的数据。
通过使用BeautifulSoup,我们可以通过标签名、类名、CSS选择器等方式来定位和解析页面中的元素。
3.3 Scrapy框架Scrapy是一个功能强大的Python爬虫框架,它提供了一套完整的爬虫流程,包括请求管理、URL调度、页面解析等。
使用Scrapy可以更加高效地开发和管理爬虫项目。

爬虫实验总结心得在进行爬虫实验的过程中,我深刻体会到了爬虫技术的重要性和应用价值。
通过对网页的分析和数据的提取,可以获取大量有用的信息,为后续的数据分析和业务决策提供支持。
一、实验目的本次实验主要是为了学习爬虫技术,并掌握基本的爬虫工具和方法。
具体目标包括:1. 熟悉Python编程语言,并掌握基本语法和常用库函数。
2. 掌握网页结构分析方法,并能够使用XPath或正则表达式提取所需信息。
3. 掌握常见的爬虫工具,如BeautifulSoup、Scrapy等,并能够灵活运用。
二、实验过程1. 爬取静态网页首先,我们需要确定需要爬取的网站和目标页面。
然后,通过浏览器开发者工具查看页面源代码,分析页面结构并确定所需信息在页面中的位置。
最后,使用Python编写程序,在页面中定位所需信息并进行抓取。
2. 爬取动态网页对于动态网页,我们需要使用Selenium等工具模拟浏览器行为,在获取完整页面内容后再进行解析和数据提取。
此外,在使用Selenium 时需要注意设置浏览器窗口大小和等待时间,以保证程序能够正常运行。
3. 使用Scrapy框架进行爬虫Scrapy是一个强大的Python爬虫框架,可以大大简化爬虫的编写和管理。
在使用Scrapy时,我们需要定义好爬取规则和数据处理流程,并编写相应的Spider、Item和Pipeline等组件。
此外,Scrapy还提供了丰富的中间件和扩展功能,可以实现更多高级功能。
三、实验心得在进行本次实验过程中,我深刻体会到了爬虫技术的重要性和应用价值。
通过对网页的分析和数据的提取,可以获取大量有用的信息,为后续的数据分析和业务决策提供支持。
同时,在实验中我也遇到了一些问题和挑战。
例如,在爬取动态网页时需要模拟浏览器行为并等待页面加载完成,否则可能会出现数据不完整或无法访问页面等问题。
此外,在使用Scrapy框架时也需要注意组件之间的协作和数据流转。
总之,本次实验让我更深入地了解了爬虫技术,并掌握了基本的编程方法和工具。

第1篇随着互联网的飞速发展,信息已经成为现代社会不可或缺的一部分。
而在这浩瀚的信息海洋中,如何高效地获取和利用数据成为了许多领域的研究热点。
作为计算机科学中的一员,我有幸参与了一次爬虫作业,通过实践体验到了爬虫技术的魅力和挑战。
以下是我对这次爬虫作业的感悟和心得体会。
一、认识爬虫技术在开始爬虫作业之前,我对爬虫技术只有一知半解。
通过这次作业,我对爬虫有了更深入的认识。
爬虫,即网络爬虫,是一种自动抓取互联网信息的程序。
它模拟人类的网络行为,按照一定的规则遍历网页,从中提取所需数据。
爬虫技术广泛应用于搜索引擎、数据挖掘、舆情分析等领域。
二、作业过程1. 确定目标网站在开始爬虫作业之前,我们需要确定目标网站。
这次作业的目标网站是一个知名的新闻网站,旨在获取其最新新闻数据。
2. 分析网站结构为了更好地抓取数据,我们需要分析目标网站的结构。
通过观察网页源代码和浏览器开发者工具,我们了解了网站的URL规则、页面布局和数据存储方式。
3. 编写爬虫程序根据网站结构,我们选择了Python语言编写爬虫程序。
程序主要包括以下几个部分:(1)URL管理器:负责生成待爬取的URL列表,并按顺序分配给爬取器。
(2)爬取器:负责从目标网站获取网页内容,并提取所需数据。
(3)数据存储:将提取的数据存储到数据库或文件中。
4. 避免反爬虫策略在实际爬取过程中,我们发现目标网站采取了一些反爬虫策略,如IP封禁、验证码等。
为了顺利抓取数据,我们采取了以下措施:(1)使用代理IP:通过更换IP地址,降低被封禁的风险。
(2)设置合理的请求频率:避免短时间内大量请求导致IP被封禁。
(3)模拟浏览器行为:使用requests库模拟浏览器头部信息,提高爬取成功率。
三、感悟与心得1. 技术提升通过这次爬虫作业,我熟练掌握了Python语言和爬虫技术。
在编写程序过程中,我学会了如何分析网站结构、提取数据、存储数据等。
此外,我还学会了使用代理IP、设置请求频率等技巧,提高了爬取成功率。

python期末爬虫个人总结一、背景介绍:最近,我参加了一门关于Python爬虫的课程,并在期末考试中进行了综合实践。
在这门课程中,我学习了爬虫的基本原理、常用的爬虫库和实际应用。
通过实践,我对Python 爬虫有了更深刻的理解,并取得了一些成果。
二、学习目标:在这门课程中,我有以下几个学习目标:1. 学习掌握Python爬虫的原理和常用库的使用;2. 能够使用Python编写简单的爬虫程序;3. 能够分析网页结构,提取所需信息;4. 能够处理爬取的数据,进行存储和分析。
三、学习过程:1. 原理学习:在学习爬虫之前,我首先了解了爬虫的基本原理。
爬虫是模拟浏览器在互联网中浏览网页的行为,通过发送HTTP请求获取网页内容,并解析网页结构,提取所需信息。
在这个过程中,我们可以使用Python编写爬虫程序,通过常用的爬虫库如Requests、BeautifulSoup和Scrapy来方便我们进行爬取。
2. 常用库的使用:学习了爬虫的基本原理后,我开始掌握了一些常用的爬虫库的使用。
首先,我学习了使用Requests库发送HTTP请求,从而获取网页的内容。
然后,我学习了BeautifulSoup库的使用,用于解析网页结构,提取所需的信息。
最后,我学习了Scrapy框架的使用,它是一个功能强大的爬虫框架,可以帮助我们更高效地开发爬虫程序。
3. 实践项目:在课程的最后阶段,我们进行了一个实践项目。
我选择了一个特定的网站,编写了一个爬虫程序,爬取了该网站上的商品信息。
在实践中,我首先使用Requests库发送HTTP请求获取网页内容,并使用BeautifulSoup解析网页结构,提取所需的信息。
然后,我将爬取到的数据进行存储和分析,以便后续的应用。
四、取得成果:通过这门课程的学习和实践,我取得了一些成果:1. 掌握了Python爬虫的基本原理和常用库的使用;2. 能够使用Python编写简单的爬虫程序,获取网页内容并解析网页结构;3. 能够分析网页结构、提取所需信息,并进行数据的存储和分析;4. 完成了一个实践项目,爬取了特定网站的商品信息。

爬虫实验报告总结在本次爬虫实验中,我主要使用Python的第三方库Scrapy来进行网页数据的爬取和处理。
通过这次实验,我对爬虫的原理和应用有了更深刻的理解,并且学会了如何使用Scrapy来构建一个简单的爬虫程序。
首先,我学习了爬虫的基本原理。
爬虫是一种自动化程序,能够模拟浏览器行为,访问网页并提取所需的数据。
它通过发送HTTP请求获取网页的HTML源代码,然后使用正则表达式或解析库来提取出需要的数据。
爬虫可以帮助我们高效地从互联网上获取大量的数据,并进行进一步的分析和应用。
接着,我深入学习了Scrapy框架的使用。
Scrapy是一个功能强大的Python爬虫框架,它提供了一套完整的爬取流程和多个扩展接口,方便我们开发和管理爬虫程序。
我通过安装Scrapy库,创建和配置了一个新的Scrapy项目,并定义了爬取规则和数据处理方法。
通过编写Spider类和Item类,我能够指定要爬取的网页链接和需要提取的数据字段,并使用Scrapy提供的Selector类来进行数据的抓取和解析。
在实验过程中,我遇到了一些问题和挑战。
例如,有些网页采取了反爬虫措施,如验证码、IP封禁等。
为了解决这些问题,我学习了一些常用的反爬虫手段,如使用代理IP、设置请求头等。
此外,我还学习了如何处理异步加载的数据,使用Scrapy的中间件来模拟Ajax 请求,以及如何设置爬取速度和并发数,以避免对目标网站造成过大的负担。
通过这次实验,我不仅学会了如何使用Scrapy框架进行网页数据的爬取和处理,还加深了对爬虫技术的理解。
爬虫作为一种强大的数据采集工具,在各行业都有广泛的应用,能够帮助我们获取和分析大量的网络数据,从而为决策和应用提供有力支持。
我相信在今后的学习和工作中,爬虫技术将会发挥越来越重要的作用。
Python爬⾍学习总结-爬取某素材⽹图⽚ Python爬⾍学习总结-爬取某素材⽹图⽚最近在学习python爬⾍,完成了⼀个简单的爬取某素材⽹站的功能,记录操作实现的过程,增加对爬⾍的使⽤和了解。
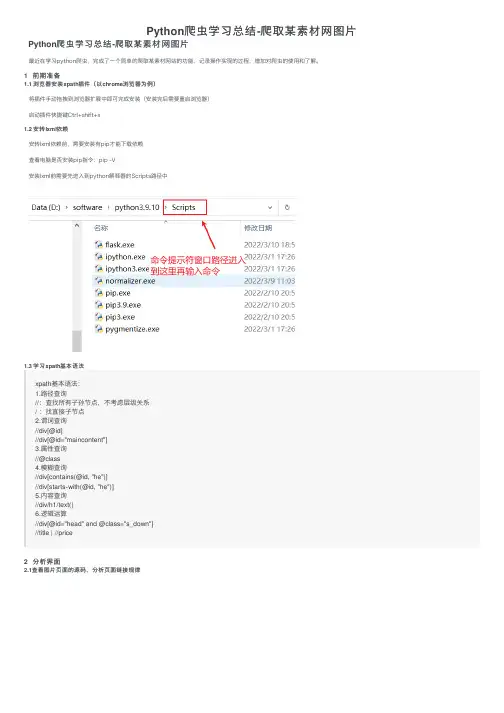
1 前期准备1.1 浏览器安装xpath插件(以chrome浏览器为例)将插件⼿动拖拽到浏览器扩展中即可完成安装(安装完后需要重启浏览器)启动插件快捷键Ctrl+shift+x1.2 安转lxml依赖安转lxml依赖前,需要安装有pip才能下载依赖查看电脑是否安装pip指令:pip -V安装lxml前需要先进⼊到python解释器的Scripts路径中1.3 学习xpath基本语法xpath基本语法:1.路径查询//:查找所有⼦孙节点,不考虑层级关系/ :找直接⼦节点2.谓词查询//div[@id]//div[@id="maincontent"]3.属性查询//@class4.模糊查询//div[contains(@id, "he")]//div[starts‐with(@id, "he")]5.内容查询//div/h1/text()6.逻辑运算//div[@id="head" and @class="s_down"]//title | //price2 分析界⾯2.1查看图⽚页⾯的源码,分析页⾯链接规律打开有侧边栏的风景图⽚(以风景图⽚为例,分析⽹页源码)通过分析⽹址可以得到每页⽹址的规律,接下来分析图⽚地址如何获取到2.2 分析如何获取图⽚下载地址⾸先在第⼀页通过F12打开开发者⼯具,找到图⽚在源代码中位置: 通过分析源码可以看到图⽚的下载地址和图⽚的名字,接下来通过xpath解析,获取到图⽚名字和图⽚地址2.3 xpath解析获取图⽚地址和名字调⽤xpath插件得到图⽚名字://div[@id="container"]//img/@alt图⽚下载地址://div[@id="container"]//img/@src2注意:由于该界⾯图⽚的加载⽅式是懒加载,⼀开始获取到的图⽚下载地址才是真正的下载地址也就是src2标签前⾯的⼯作准备好了,接下来就是书写代码3 代码实现3.1 导⼊对应库import urllib.requestfrom lxml import etree3.2 函数书写请求对象的定制def create_request(page,url):# 对不同页⾯采⽤不同策略if (page==1):url_end = urlelse:#切割字符串url_temp = url[:-5]url_end = url_temp+'_'+str(page)+'.html'# 如果没有输⼊url就使⽤默认的urlif(url==''):url_end = 'https:///tupian/fengjingtupian.html'# 请求伪装headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36 Edg/99.0.1150.39' }# 请求对象的定制request = urllib.request.Request(url = url_end,headers=headers)# 返回伪装后的请求头return request获取⽹页源码def get_content(request):# 发送请求获取响应数据response = urllib.request.urlopen(request)# 将响应数据保存到contentcontent = response.read().decode('utf8')# 返回响应数据return content下载图⽚到本地def down_load(content):# 下载图⽚#urllib.request.urlretrieve('图⽚名称','⽂件名字')# 解析⽹页tree = etree.HTML(content)# 获取图⽚姓名返回的是列表img_name = tree.xpath('//div[@id="container"]//a/img/@alt')img_add = tree.xpath('//div[@id="container"]//a/img/@src2')# 循环下载图⽚for i in range(len(img_name)):# 挨个获取下载的图⽚名字和地址name = img_name[i]add = img_add[i]# 对图⽚下载地址进⾏定制url = 'https:'+add# 下载到本地下载图⽚到当前代码同⼀⽂件夹的imgs⽂件夹中需要先在该代码⽂件夹下创建imgs⽂件夹urllib.request.urlretrieve(url=url,filename='./imgs/'+name+'.jpg')主函数if __name__ == '__main__':print('该程序为采集站长素材图⽚')url = input("请输⼊站长素材图⽚第⼀页的地址(内置默认为风景图⽚)")start_page = int(input('请输⼊起始页码'))end_page = int(input('请输⼊结束页码'))for page in range(start_page,end_page+1):#请求对象的定制request = create_request(page,url)# 获取⽹页的源码content = get_content(request)# 下载down_load(content)完整代码# 1.请求对象的定制# 2.获取⽹页源码# 3.下载# 需求:下载前⼗页的图⽚# 第⼀页:https:///tupian/touxiangtupian.html# 第⼆页:https:///tupian/touxiangtupian_2.html# 第三页:https:///tupian/touxiangtupian_3.html# 第n页:https:///tupian/touxiangtupian_page.htmlimport urllib.requestfrom lxml import etree# 站长素材图⽚爬取下载器def create_request(page,url):# 对不同页⾯采⽤不同策略if (page==1):url_end = urlelse:#切割字符串url_temp = url[:-5]url_end = url_temp+'_'+str(page)+'.html'# 如果没有输⼊url就使⽤默认的urlif(url==''):url_end = 'https:///tupian/fengjingtupian.html'headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36 Edg/99.0.1150.39' }request = urllib.request.Request(url = url_end,headers=headers)return requestdef get_content(request):response = urllib.request.urlopen(request)content = response.read().decode('utf8')return contentdef down_load(content):# 下载图⽚#urllib.request.urlretrieve('图⽚名称','⽂件名字')tree = etree.HTML(content)# 获取图⽚姓名返回的是列表img_name = tree.xpath('//div[@id="container"]//a/img/@alt')img_add = tree.xpath('//div[@id="container"]//a/img/@src2')for i in range(len(img_name)):name = img_name[i]add = img_add[i]# 对图⽚下载地址进⾏定制url = 'https:'+add# 下载到本地urllib.request.urlretrieve(url=url,filename='./imgs/'+name+'.jpg')if __name__ == '__main__':print('该程序为采集站长素材图⽚')url = input("请输⼊站长素材图⽚第⼀页的地址(内置默认为风景图⽚)")start_page = int(input('请输⼊起始页码'))end_page = int(input('请输⼊结束页码'))for page in range(start_page,end_page+1):#请求对象的定制request = create_request(page,url)# 获取⽹页的源码content = get_content(request)# 下载down_load(content)4 运⾏结果总结此次案例是基于尚硅⾕的python视频学习后的总结,感兴趣的可以去看全套视频,⼈们总说兴趣是最好的⽼师,⾃从接触爬⾍后我觉得python⼗分有趣,这也是我学习的动⼒,通过对⼀次案例的简单总结,回顾已经学习的知识,并不断学习新知识,是记录也是分享。

一、实训背景随着互联网的飞速发展,信息资源日益丰富,如何高效地从海量信息中获取所需数据成为了一个亟待解决的问题。
网络爬虫技术作为一种自动获取网络信息的工具,在数据挖掘、信息检索、搜索引擎等领域有着广泛的应用。
为了提高自己的实际操作能力,我参加了本次爬虫实训,通过实践学习,掌握了网络爬虫的基本原理和操作方法。
二、实训目标1. 掌握网络爬虫的基本原理和操作方法;2. 学会使用Python编写爬虫程序;3. 熟悉常用的爬虫框架和库;4. 能够根据实际需求设计并实现网络爬虫。
三、实训内容1. 网络爬虫基本原理网络爬虫是按照一定的规则自动从互联网上抓取信息的程序。
它主要包括三个部分:爬虫、数据存储、数据解析。
本次实训主要学习了爬虫的工作原理、数据抓取流程、数据存储方式等。
2. Python爬虫编写实训过程中,我学习了Python语言的基础语法,掌握了常用的数据结构、控制流等编程技巧。
在此基础上,我尝试使用Python编写爬虫程序,实现了对指定网站的爬取。
3. 常用爬虫框架和库实训中,我了解了Scrapy、BeautifulSoup、Requests等常用的爬虫框架和库。
这些框架和库可以帮助我们快速搭建爬虫项目,提高爬虫效率。
4. 爬虫设计实现根据实际需求,我设计并实现了一个简单的爬虫项目。
该项目实现了对指定网站文章内容的抓取,并将抓取到的数据存储到数据库中。
四、实训成果1. 掌握了网络爬虫的基本原理和操作方法;2. 能够使用Python编写简单的爬虫程序;3. 熟悉了常用的爬虫框架和库;4. 设计并实现了一个简单的爬虫项目。
五、实训心得1. 理论与实践相结合。
本次实训让我深刻体会到,只有将理论知识与实践相结合,才能更好地掌握网络爬虫技术。
2. 不断学习新技术。
随着互联网的快速发展,网络爬虫技术也在不断更新。
作为一名爬虫开发者,我们需要不断学习新技术,提高自己的技术水平。
3. 注重代码规范。
在编写爬虫程序时,要注重代码规范,提高代码可读性和可维护性。

爬虫实验报告心得简短前言在进行本次爬虫实验之前,我对爬虫技术有一定的了解,但对具体实现和应用还存在一些困惑。
通过本次实验,我对爬虫技术有了更深入的理解,并学习到了一些实用的技巧和注意事项。
实验过程实验准备在实验开始前,我首先对需要爬取的网站进行了分析。
我观察了目标网站的网页结构和URL规律,并思考了如何设计程序来提取所需数据。
我还研究了一些相关的库和工具,如Python的Requests库和Beautiful Soup库。
实验步骤1. 构建HTTP请求:在这一步中,我使用Requests库发送GET请求,获取目标网页的HTML源代码。
2. 解析HTML数据:利用Beautiful Soup库,我解析了HTML源代码,提取了目标数据。
3. 数据存储:我选择将爬取到的数据存储到CSV文件中,方便日后分析使用。
实验结果在进行实验过程中,我遇到了一些挑战和问题。
其中包括:1. 网络流量和速度限制:为了防止对目标网站造成负担,我限制了每次请求的间隔时间,并在程序中处理了可能出现的错误和异常。
2. 频繁更改网站结构:有些网站会不断更改其网页结构,这会导致之前编写的爬虫程序无法正常运行。
所以,我需要时常观察目标网站的变化,并及时调整爬虫程序。
经过不断的尝试和调试,我成功地完成了爬虫任务,并获得了所需的数据。
我将数据保存为CSV文件,便于后续的数据分析和处理。
心得体会通过本次实验,我对爬虫技术有了更深入的了解,并学到了许多有用的技巧和方法。
以下是我在实验过程中的一些心得体会:1. 网页分析和数据提取是爬虫的关键步骤。
在进行爬取之前,需要仔细观察目标网页的结构、URL规律和数据存储方式,以便编写相应的爬虫程序。
2. 理解HTML和CSS基础知识对于解析网页非常重要。
了解标签、类名、属性等的含义,可以帮助我们更快地定位和提取目标数据。
3. 爬虫程序的可靠性和稳定性是关键。
在编写程序时,要考虑到各种异常情况和错误处理,并进行相应的监控和调试。

Python网络爬虫实习报告目录一、选题背景二、爬虫原理三、爬虫历史和分类四、常用爬虫框架比较Scrapy框架:Scrapy框架是一套比较成熟的Python爬虫框架,是使用Python开发的快速、高层次的信息爬取框架,可以高效的爬取web页面并提取出结构化数据。
Scrapy应用范围很广,爬虫开发、数据挖掘、数据监测、自动化测试等。
Crawley框架:Crawley也是Python开发出的爬虫框架,该框架致力于改变人们从互联网中提取数据的方式。
Portia框架:Portia框架是一款允许没有任何编程基础的用户可视化地爬取网页的爬虫框架。
newspaper框架:newspaper框架是一个用来提取新闻、文章以及内容分析的Python爬虫框架。
Python-goose框架:Python-goose框架可提取的信息包括:<1>文章主体内容;<2>文章主要图片;<3>文章中嵌入的任heYoutube/Vimeo视频;<4>元描述;<5>元标签五、数据爬取实战(豆瓣网爬取电影数据)1分析网页# 获取html源代码def __getHtml():data = []pageNum = 1pageSize = 0try:while (pageSize <= 125):# 'Referer':None #注意如果依然不能抓取的话,这里可以设置抓取网站的host# }# opener.addheaders = [headers]pageNum)pageSize += 25pageNum += 1print(pageSize, pageNum)except Exception as e:raise ereturn data2爬取数据def __getData(html):title = [] # 电影标题#rating_num = [] # 评分range_num = [] # 排名#rating_people_num = [] # 评价人数movie_author = [] # 导演data = {}# bs4解析htmlsoup = BeautifulSoup(html, "html.parser")for li in soup.find("ol", attrs={'class':'grid_view'}).find_all("li"):title.append(li.find("span", class_="title").text) #rating_num.append(li.find("div",class_='star').find("span", class_='rating_num').text) range_num.append(li.find("div",class_='pic').find("em").text)#spans = li.find("div",class_='star').find_all("span")#for x in range(len(spans)):# if x <= 2:# pass# else:#rating_people_num.append(spans[x].string[-len(spans[x].stri ng):-3])str = li.find("div", class_='bd').find("p",class_='').text.lstrip()index = str.find("主")if (index == -1):index = str.find("...")print(li.find("div",class_='pic').find("em").text)if (li.find("div", class_='pic').find("em").text == 210):index = 60# print("aaa")# print(str[4:index])movie_author.append(str[4:index])data['title'] = title#data['rating_num'] = rating_numdata['range_num'] = range_num#data['rating_people_num'] = rating_people_numdata['movie_author'] = movie_authorreturn data3数据整理、转换def __getMovies(data):f.write("<html>")f.write("<head><meta charset='UTF-8'><title>Insert title here</title></head>")f.write("<body>")f.write("<h1>爬取豆瓣电影</h1>")f.write("<h4> 作者:刘文斌</h4>")f.write("<h4> 时间:" + nowtime + "</h4>")f.write("<hr>")f.write("<table width='800px' border='1' align=center>")f.write("<thead>")f.write("<tr>")f.write("<th><font size='5' color=green>电影</font></th>")#f.write("<th width='50px'><font size='5' color=green>评分</font></th>")f.write("<th width='50px'><font size='5' color=green>排名</font></th>")#f.write("<th width='100px'><font size='5' color=green>评价人数</font></th>")f.write("<th><font size='5' color=green>导演</font></th>")f.write("</tr>")f.write("</thead>")f.write("<tbody>")for data in datas:for i in range(0, 25):f.write("<tr>")f.write("<tdstyle='color:orange;text-align:center'>%s</td>" %data['title'][i])# f.write("<tdstyle='color:blue;text-align:center'>%s</td>" %data['rating_num'][i])f.write("<tdstyle='color:red;text-align:center'>%s</td>" % data['range_num'][i])# f.write("<tdstyle='color:blue;text-align:center'>%s</td>" % data['rating_people_num'][i])f.write("<tdstyle='color:black;text-align:center'>%s</td>" % data['movie_author'][i])f.write("</tr>")f.write("</tbody>")f.write("</thead>")f.write("</table>")f.write("</body>")f.write("</html>")f.close()if __name__ == '__main__':datas = []htmls = __getHtml()for i in range(len(htmls)):data = __getData(htmls[i])datas.append(data)__getMovies(datas)4数据保存、展示结果如后图所示:5技术难点关键点数据爬取实战(搜房网爬取房屋数据)from bs4 import BeautifulSoupimport requestsrep = requests.get()rep.encoding = "gb2312" # 设置编码方式html = rep.textsoup = BeautifulSoup(html, 'html.parser')f = open(, 'w',encoding='utf-8')f.write("<html>")f.write("<head><meta charset='UTF-8'><title>Insert title here</title></head>")f.write("<body>")f.write("<center><h1>新房成交TOP3</h1></center>")f.write("<table border='1px' width='1000px' height='800px' align=center><tr>")f.write("<th><h2>房址</h2></th>")f.write("<th><h2>成交量</h2></th>")f.write("<th><h2>均价</h2></th></tr>")for li in soup.find("ul",class_="ul02").find_all("li"):name=li.find("div",class_="pbtext").find("p").textchengjiaoliang=li.find("span",class_="red-f3").text try:junjia=li.find("div",class_="ohter").find("p",class_="gray-9 ")#.text.replace('?O', '平方米')except Exception as e:junjia=li.find("div",class_="gray-9")#.text.replace('?O', '平方米')f.write("<tr><td align=center><font size='5px'color=red>%s</font></td>" % name)f.write("<td align=center><font size='5px'color=blue>%s</font></td>" % chengjiaoliang)f.write("<td align=center><font size='5px'color=green>%s</font></td></tr>" % junjia)print(name)f.write("</table>")f.write("</body>")六、总结教师评语:成绩:指导教师:。
大学爬虫实训总结报告
通过这次Python实训,我收获了很多,一方面学习到了许多以前没学过的专业知识与知识的应用,另一方面还提高了自我动手做项目的潜力。
本次实训是对我潜力的进一步锻炼,也是一种考验。
从中获得的诸多收获,也是很可贵的,是十分有好处的。
在实训中我学到了许多新的知识,是一个让我把书本上的理论知识运用于实践中的好机会,原先,学的时候感叹学的资料太难懂,此刻想来,有些其实并不难,关键在于理解。
在这次实训中还锻炼了我其他方面的潜力,提高了我的综合素质。
首先,它锻炼了我做项目的潜力,提高了独立思考问题、自我动手操作的潜力,在工作的过程中,复习了以前学习过的知识,并掌握了一些应用知识的技巧等。
其次,实训中的项目作业也使我更加有团队精神。
Python是一种开源语言,Python是一个高层次的结合了解释性、编译性、互动性和面向对象的脚本语言。
Python的设计具有很强的可读性,相比其他语言经常使用英文关键字,其他语言的一些标点符号,它具有比其他语言更有特色语法结构。
搭建Python环境我们只需要一个解析器和一个编译器,解析器我们可以选择从Python官方网站上下载,也可以直接去安装Anaconda(这个东西不但有完整的Python解析器,而且自带很多Python常用库,甚至还有可以运行代码的IDE)。
随后我们找到了PyCharm-Professional这样一个专业IDE以求更好地编写代码。
关于PyCharm这个东西的激活问题,你可以去网上搜索各种破解方法
或者加入一个教学团队获得永久激活权限。
第1篇一、前言随着互联网的快速发展,网络数据量呈爆炸式增长,为了更好地利用这些数据,网络爬虫技术应运而生。
作为一名网络爬虫工程师,我在过去的工作中积累了一定的经验,现将工作总结如下。
一、工作背景网络爬虫是一种自动抓取互联网信息的程序或脚本,通过模拟浏览器行为,从网页中提取所需数据。
随着大数据时代的到来,网络爬虫技术在各个领域得到了广泛应用,如搜索引擎、数据分析、舆情监控等。
二、工作内容1. 技术选型在开展网络爬虫项目时,我首先进行技术选型。
根据项目需求,选择合适的爬虫框架和工具。
常用的爬虫框架有Scrapy、BeautifulSoup、Requests等。
在实际工作中,我主要使用Scrapy框架,因为它具有高效、易用、可扩展等特点。
2. 爬虫设计爬虫设计是网络爬虫工作的核心环节。
我根据目标网站的特点,设计合适的爬虫策略。
主要包括以下几个方面:(1)目标网站分析:了解目标网站的架构、数据分布、更新频率等,为爬虫设计提供依据。
(2)URL管理:根据目标网站结构,设计URL管理策略,确保爬取路径的合理性和完整性。
(3)数据提取:针对目标网站页面结构,编写解析代码,提取所需数据。
(4)数据存储:选择合适的数据存储方式,如数据库、文件等,实现数据的持久化。
3. 爬虫实现根据设计好的爬虫策略,编写爬虫代码。
主要包括以下步骤:(1)创建Scrapy项目:使用Scrapy命令行工具创建新项目,配置项目信息。
(2)编写爬虫文件:在Scrapy项目中,编写爬虫文件,实现爬虫逻辑。
(3)配置爬虫参数:设置爬虫参数,如下载延迟、并发数、用户代理等。
(4)测试爬虫:在本地或远程服务器上运行爬虫,测试爬虫效果。
4. 异常处理在实际爬取过程中,可能会遇到各种异常情况,如网络异常、解析错误、数据存储问题等。
我针对这些异常情况,编写了相应的处理代码,确保爬虫的稳定运行。
5. 数据清洗与处理爬取到的数据可能存在重复、缺失、格式不统一等问题。
第1篇一、实训背景与目的随着互联网技术的飞速发展,数据已成为现代社会的重要资源。
爬虫技术作为数据采集的重要手段,在信息检索、市场分析、舆情监测等领域发挥着越来越重要的作用。
为了提高学生对爬虫技术的掌握程度,培养实际操作能力,我们开展了爬虫游戏实训课程。
本次实训旨在使学生了解爬虫技术的基本原理,掌握常用的爬虫工具,并能运用爬虫技术解决实际问题。
二、实训内容与过程本次实训共分为三个阶段:理论学习、实践操作和总结报告。
1. 理论学习阶段(1)爬虫技术概述:介绍了爬虫技术的发展历程、应用场景以及常见的爬虫类型。
(2)爬虫原理:讲解了爬虫的工作原理,包括网络请求、HTML解析、数据提取等环节。
(3)Python爬虫开发:介绍了Python编程语言在爬虫开发中的应用,包括常用的库和模块。
(4)常见爬虫工具:介绍了常用的爬虫工具,如BeautifulSoup、Scrapy等。
2. 实践操作阶段(1)模拟爬虫:通过模拟爬取网页数据,让学生熟悉爬虫的基本流程。
(2)实战演练:选取实际网站进行爬虫操作,包括数据采集、存储、处理等环节。
(3)异常处理:讲解爬虫过程中可能遇到的异常情况及解决方法。
3. 总结报告阶段(1)总结实训过程中的收获与不足。
(2)分析爬虫技术的应用前景及发展趋势。
(3)提出改进建议,为今后的学习和实践提供参考。
三、实训成果与收获通过本次实训,学生们取得了以下成果和收获:1. 理论知识掌握:学生对爬虫技术的基本原理、开发流程以及常用工具有了全面了解。
2. 实践操作能力:学生能够运用Python编程语言和爬虫工具完成实际数据的采集和处理。
3. 问题解决能力:在实训过程中,学生遇到了各种问题,通过查阅资料、请教老师和同学,逐步掌握了解决问题的方法。
4. 团队协作能力:在实训项目中,学生需要分工合作,共同完成项目任务,提高了团队协作能力。
四、实训总结与反思1. 实训内容设置合理:本次实训内容涵盖了爬虫技术的各个方面,理论与实践相结合,使学生能够全面掌握爬虫技术。
python爬虫实验报告Python 爬虫实验报告引言:随着互联网的飞速发展,网络数据的获取和处理越来越重要。
爬虫作为一种自动化网络数据采集工具,在各个领域发挥着重要的作用。
本文将介绍我在实验中使用 Python 编写的爬虫程序,并详细分析其实现方法及结果。
一、实验目的本次实验的目的是使用 Python 编写一个简单的爬虫程序,实现对指定网站的信息抓取。
通过这个实验,我将学习到如何使用Python 的相关库,如 requests、BeautifulSoup 等,来实现简单的网络数据采集。
二、实验过程1. 确定目标网站首先,我选择了一个免费的电影资源网站作为本次实验的目标网站。
这个网站上有大量电影资源的信息,我们可以从中获取电影的名称、评分、导演等相关信息。
2. 发送 HTTP 请求使用 Python 的 requests 库,我们可以轻松地发送 HTTP 请求来获取网页的内容。
在这一步中,我使用 get 方法发送了一个请求,并获取了目标网站的 HTML 内容。
3. 解析 HTML 内容获取到 HTML 内容后,我们需要使用 BeautifulSoup 库将其进行解析,提取出我们所需要的信息。
通过分析网页的结构,我找到了对应电影信息的元素和特征,然后利用 Beautiful Soup 提供的方法,将这些信息从 HTML 中提取出来。
4. 保存数据提取到电影信息后,我使用 Python 的文件操作相关函数,将这些信息保存到一个文本文件里。
这样我们就可以在之后的操作中使用这些数据了。
三、实验结果经过实验,我成功地编写了一个简单的爬虫程序,并成功抓取了目标网站中的电影信息。
在浏览保存的数据时,我发现程序能够准确地提取出电影的名称、评分和导演等信息。
这意味着我成功地提取到了目标网站的内容,并将其保存到了本地文件。
这样,我就能够进一步对这些数据进行分析和处理。
四、实验总结通过这次实验,我对 Python 爬虫的实现有了更深入的了解。
python爬虫项目完结体会
在完成一个Python爬虫项目后,体会到了以下几点。
1.技能提升:通过实践,我掌握了Python爬虫的基本原理和技巧,例如使用requests库进行网络请求,使用Be autifulSoup库解析HTML页面,以及使用正则表达式处理文本数据等。
同时,我还学会了如何使用Scrapy等框架进行分布式爬虫,提高了自己的编程能力。
2.问题解决:在项目实施过程中,我遇到了许多问题,如反爬策略、网络请求异常、数据解析错误等。
通过查找资料、请教他人和尝试多种解决方案,我逐渐克服了这些困难,这让我更加熟练地掌握了问题解决的方法。
3.团队协作:在完成项目的过程中,我与团队成员保持密切沟通,共同解决问题,分工合作。
这让我体会到了团队协作的重要性,学会了如何与他人高效地配合,共同实现项目目标。
4.项目管理:在项目实施过程中,我学会了如何进行时间管理、任务分配和进度跟踪,以确保项目按计划完成。
此外,我还掌握了如何根据实际需求调整项目计划,以应对突发情况。
5.成果展示:在项目完成后,我们向客户展示了我们的成果,包括获取的数据、分析报告和可视化结果。
这让我明
白了成果展示的重要性,学会了如何向他人清晰地展示自己的工作成果。
6.反思与总结:在项目结束后,我对自己在项目中的表现进行了反思和总结,发现了自己的不足之处,并制定了改进计划。
这让我更加明确了自己的发展方向,为今后的学习和成长奠定了基础。
总之,在完成Python爬虫项目的过程中,我不仅提升了自己的技能,学会了问题解决和团队协作,还掌握了项目管理和成果展示的方法。
这段经历让我受益匪浅,为今后的职业发展奠定了基础。
爬虫作业总结一、爬虫作业是啥呢?爬虫作业啊,就像是在互联网这个超级大森林里探险的小机器人干的活儿。
我刚开始接触的时候,那真是一头雾水,感觉就像是在迷宫里乱转的小迷糊。
我在的这个小团队,大家都是刚接触爬虫不久,我们就像一群摸索着前进的小探险家。
我们用的工具可不少呢,Python就是我们的得力助手。
Python 里那些个库,像BeautifulSoup,就像是专门为我们在网页这片“大森林”里采集果实(数据)准备的小篮子。
还有Scrapy框架,这个可牛了,就像是给我们的小机器人配上了超级装备,让它跑得更快,采集得更有效率。
我们的工作内容那叫一个丰富。
有时候是去采集新闻网站上的新闻标题和链接,这就像是在新闻的海洋里捞鱼,我们得小心地把那些“鱼”(数据)一条一条准确地捞起来。
还有时候是去电商网站采集商品信息,这可就复杂多了,要避开一些反爬虫机制,就像在一个到处是陷阱的宝藏洞里找宝贝。
二、遇到的那些事儿在这个过程中,那可真是状况百出。
比如说,有些网站的反爬虫机制特别严格,就像一个有着重重防护的城堡,我们的小机器人刚一靠近就被拦住了。
这时候我们就得想办法,像调整请求头啊,设置延迟啊,就像给我们的小机器人穿上伪装服,让它能悄悄溜进去。
还有数据清洗的时候,那数据就像一堆乱麻,有些格式不对,有些有重复的。
我们就得像耐心的小裁缝一样,把这些乱麻一点点理顺,把多余的线头(重复数据)剪掉,把衣服(数据)缝得整整齐齐。
三、我的收获通过这个爬虫作业,我感觉自己就像升级了一样。
以前看到那些网页,只觉得是一些花花绿绿的东西,现在看到的都是数据的宝库。
我的编程能力也提升了不少,以前写代码总是磕磕绊绊的,现在就顺畅多了。
而且我还学会了怎么去分析问题,遇到那些反爬虫机制或者数据混乱的问题,不再是干瞪眼,而是能想出一些办法来解决。
我还知道了团队合作的重要性。
在团队里,大家互相交流经验,有人遇到问题,其他人就会来帮忙出主意。
就像一群小蚂蚁,虽然每只蚂蚁的力量有限,但是大家团结起来就能搬动比自己大很多倍的食物(完成复杂的任务)。
Python总结目录Python总结 (1)前言 (2)(一)如何学习Python (2)(二)一些Python免费课程推荐 (3)(三)Python爬虫需要哪些知识? (4)(四)Python爬虫进阶 (6)(五)Python爬虫面试指南 (7)(六)推荐一些不错的Python博客 (8)(七)Python如何进阶 (9)(八)Python爬虫入门 (10)(九)Python开发微信公众号 (12)(十)Python面试概念和代码 (15)(十一)Python书籍 (23)前言知乎:路人甲微博:玩数据的路人甲微信公众号:一个程序员的日常在知乎分享已经有一年多了,之前一直有朋友说我的回答能整理成书籍了,一直偷懒没做,最近有空仔细整理了知乎上的回答和文章另外也添加了一些新的内容,完成了几本小小的电子书,这一本是有关于Python方面的。
还有另外几本包括我的一些数据分析方面的读书笔记、增长黑客的读书笔记、机器学习十大算法等等内容。
将会在我的微信公众号:一个程序员的日常进行更新,同时也可以关注我的知乎账号:路人甲及时关注我的最新分享用数据讲故事。
(一)如何学习Python学习Python大致可以分为以下几个阶段:1.刚上手的时候肯定是先过一遍Python最基本的知识,比如说:变量、数据结构、语法等,基础过的很快,基本上1~2周时间就能过完了,我当时是在这儿看的基础:Python 简介 | 菜鸟教程2.看完基础后,就是做一些小项目巩固基础,比方说:做一个终端计算器,如果实在找不到什么练手项目,可以在Codecademy - learn to code, interactively, for free上面进行练习。
3. 如果时间充裕的话可以买一本讲Python基础的书籍比如《Python编程》,阅读这些书籍,在巩固一遍基础的同时你会发现自己诸多没有学习到的边边角角,这一步是对自己基础知识的补充。
4.Python库是Python的精华所在,可以说Python库组成并且造就了Python,Python 库是Python开发者的利器,所以学习Python库就显得尤为重要:The Python Standard Library,Python库很多,如果你没有时间全部看完,不妨学习一遍常用的Python库:Python常用库整理 - 知乎专栏5.Python库是开发者利器,用这些库你可以做很多很多东西,最常见的网络爬虫、自然语言处理、图像识别等等,这些领域都有很强大的Python库做支持,所以当你学了Python库之后,一定要第一时间进行练习。
如何寻找自己需要的Python库呢?推荐我之前的一个回答:如何找到适合需求的 Python 库?6.学习使用了这些Python库,此时的你应该是对Python十分满意,也十分激动能遇到这样的语言,就是这个时候不妨开始学习Python数据结构与算法,Python设计模式,这是你进一步学习的一个重要步骤:faif/python-patterns7.当度过艰难的第六步,此时选择你要研究的方向,如果你想做后端开发,不妨研究研究Django,再往后,就是你自己自由发挥了。
(二)一些Python免费课程推荐以下课程都为免费课程1.python零基础相关适用人群:Python零基础的初学者、Web开发程序员、运维人员、有志于从事互联网行业以及各领域应用Python的人群➢疯狂的Python:快速入门精讲➢零基础入门学习Python➢玩转Python语言➢Python语言程序设计➢程序设计入门➢可汗学院公开课:计算机科学➢python 入门到精通➢Python交互式编程入门的课程主页➢Python交互编程入门(第2部分)的课程主页2.python web方向Python Django 快速Web应用开发入门3.python爬虫Python实战:一周学会爬取网页4.python数据分析方向数据分析实战基础课程(三)Python爬虫需要哪些知识?要学会使用Python爬取网页信息无外乎以下几点内容:1、要会Python2、知道网页信息如何呈现3、了解网页信息如何产生4、学会如何提取网页信息第一步Python是工具,所以你必须熟练掌握它,要掌握到什么程度呢?如果你只想写一写简单的爬虫,不要炫技不考虑爬虫效率,你只需要掌握:➢数据类型和变量➢字符串和编码➢使用list和tuple➢条件判断、循环➢使用dict和set你甚至不需要掌握函数、异步、多线程、多进程,当然如果想要提高自己小爬虫的爬虫效率,提高数据的精确性,那么记住最好的方式是去系统的学习一遍Python,去哪儿学习?Python教程假设已经熟悉了最基础的Python知识,那么进入第二步:知道网页信息如何呈现?你首先要知道所需要抓取的数据是怎样的呈现的,就像是你要学做一幅画,在开始之前你要知道这幅画是用什么画出来的,铅笔还是水彩笔...可能种类是多样的,但是放到网页信息来说这儿只有两种呈现方式:1、HTML (HTML 简介)2、JSON (JSON 简介)HTML是用来描述网页的一种语言JSON是一种轻量级的数据交换格式假设你现在知道了数据是由HTML和JSON呈现出来的,那么我们紧接着第三步:数据怎么来?数据当然是从服务器反馈给你的,为什么要反馈给你?因为你发出了请求。
“Hi~ ,服务器我要这个资源”“正在传输中...”“已经收到HTML或者JSON格式的数据”这个请求是什么请求?要搞清楚这一点你需要了解一下http的基础知识,更加精确来说你需要去了解GET和POST是什么,区别是什么。
也许你可以看看这个:浅谈HTTP中Get与Post的区别 - hyddd - 博客园很高兴你使用的是Python,那么你只需要去掌握好快速上手 - Requests 2.10.0 文档,requests可以帮你模拟发出GET和POST请求,这真是太棒了。
饭菜已经备好,两菜一汤美味佳肴,下面就是好好享受了。
现在我们已经拿到了数据,我们需要在这些错乱的数据中提取我们需要的数据,这时候我们有两个选择。
第一招:万能钥匙Python正则表达式指南,再大再乱的内容,哪怕是大海捞针,只要告诉我这个针的样子我都能从茫茫大海中捞出来,强大的正则表达式是你提取数据的不二之选。
第二招:笑里藏刀Beautiful Soup 4.2.0 文档,或许我们有更好的选择,我们把原始数据和我们想要的数据的样子扔个这个Beautifulsoup,然后让它帮我们去寻找,这也是一个不错的方案,但是论灵活性,第二招还是略逊于第一招。
第三招:双剑合璧最厉害的招式莫过于结合第一招和第二招了,打破天下无敌手。
基础知识我都会,可是我还是写不了一个爬虫啊!客观别急,这还没完。
以下这些项目,你拿来学习学习练练手。
一些教学项目你值得拥有:➢03. 豆瓣电影TOP250➢04. 另一种抓取方式还不够?这儿有很多:➢知乎--你需要这些:Python3.x爬虫学习资料整理➢如何学习Python爬虫[入门篇]? - 知乎专栏➢知乎--Python学习路径及练手项目合集(四)Python爬虫进阶爬虫无非分为这几块:分析目标、下载页面、解析页面、存储内容,其中下载页面不提。
1. 分析目标所谓分析就是首先你要知道你需要抓取的数据来自哪里?怎么来?普通的网站一个简单的POST或者GET请求,不加密不反爬,几行代码就能模拟出来,这是最基本的,进阶就是学会分析一些复杂的目标,比如说:淘宝、新浪微博登陆以及网易云的评论信息等等。
2. 解析页面解析页面主要是选择什么库或者那些库结合能使解析速度更快,可能你一开始你通过种种地方了解到了bs库,于是你对这个库很痴迷,以后只要写爬虫,总是先写上:import requestsfrom bs4import BeautifulSoup当然bs已经很优秀了,但是并不代表可以用正则表达式解析的页面还需要使用bs,也不代表使用lxml能解决的还要动用bs,所以这些解析库的速度是你在进阶时要考虑的问题。
3. 存储内容刚开始学爬虫,一般爬取的结果只是打印出来,最后把在终端输出的结果复制粘贴保存就好了;后来发现麻烦会用上xlwt/openpyxl/csv的把存储内容写入表格,再后来使用数据库sqlite/mysql/neo4j只要调用了库都很简单,当然这是入门。
进阶要开始学习如何选择合适的数据库,或者存储方式。
当爬取的内容过千万的时候,如何设计使存储速度更快,比如说当既有人物关系又有人物关系的时候,一定会用neo4j来存储关系,myslq用来存储用户信息,这样分开是因为如果信息全部存入neo4j,后期的存储速度经十分的慢。
当你每个步骤都能做到很优秀的时候,你应该考虑如何组合这四个步骤,使你的爬虫达到效率最高,也就是所谓的爬虫策略问题,爬虫策略学习不是一朝一夕的事情,建议多看看一些比较优秀的爬虫的设计方案,比如说Scrapy。
除了爬取策略以外,还有几点也是必备的:1. 代理策略以及多用户策略代理是爬虫进阶阶段必备的技能,与入门阶段直接套用代理不同,在进阶阶段你需要考虑如何设计使用代理策略,什么时候换代理,代理的作用范围等等,多用户的抓取策略考虑的问题基本上与代理策略相同。
2. 增量式抓取以及数据刷新比如说你抓取的是一个酒店网站关于酒店价格数据信息的,那么会有这些问题:酒店的房型的价格是每天变动的,酒店网站每天会新增一批酒店,那么如何进行存储、如何进行数据刷新都是应该考虑的问题。
3.验证码相关的一些问题有很多人提到验证码,我个人认为验证码不是爬虫主要去解决的问题,验证码不多的情况考虑下载到本地自己输入验证码,在多的情况下考虑接入打码平台。
(五)Python爬虫面试指南前段时间快要毕业,而我又不想找自己的老本行Java开发了,所以面了很多Python 爬虫岗位。
因为我在南京上学,所以我一开始只是在南京投了简历,我一共面试了十几家企业,其中只有一家没有给我发offer,其他企业都愿意给到10K的薪资,不要拿南京的薪资水平和北上深的薪资水平比较,结合面试常问的问题类型说一说我的心得体会。
第一点:Python因为面试的是Python爬虫岗位,面试官大多数会考察面试者的基础的Python知识,包括但不限于:➢Python2.x与Python3.x的区别➢Python的装饰器➢Python的异步➢Python的一些常用内置库,比如多线程之类的第二点:数据结构与算法数据结构与算法是对面试者尤其是校招生面试的一个很重要的点,当然小公司不会太在意这些,从目前的招聘情况来看对面试者的数据结构与算法的重视程度与企业的好坏成正比,那些从不问你数据结构的你就要当心他们是否把你当码农用的,当然以上情况不绝对,最终解释权归面试官所有。