SPSS Modeler数据挖掘操作之分类回归树的基本应用示例
- 格式:pptx
- 大小:1.10 MB
- 文档页数:12
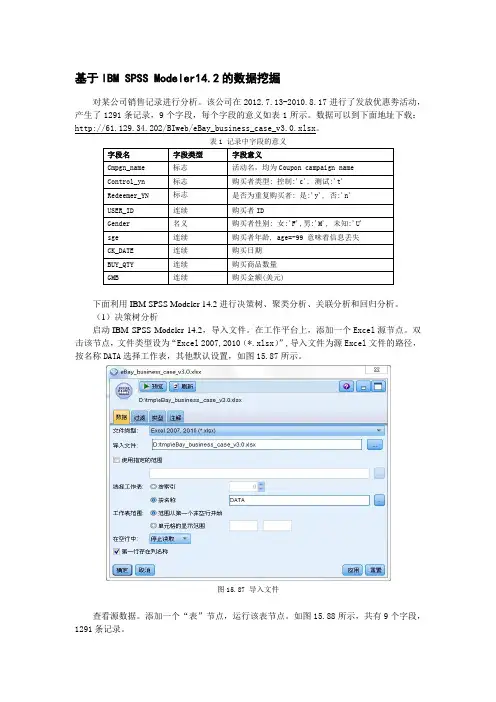
基于IBM SPSS Modeler14.2的数据挖掘对某公司销售记录进行分析。
该公司在2012.7.13-2010.8.17进行了发放优惠劵活动,产生了1291条记录,9个字段,每个字段的意义如表1所示。
数据可以到下面地址下载:http://61.129.34.202/BIweb/eBay_business_case_v3.0.xlsx。
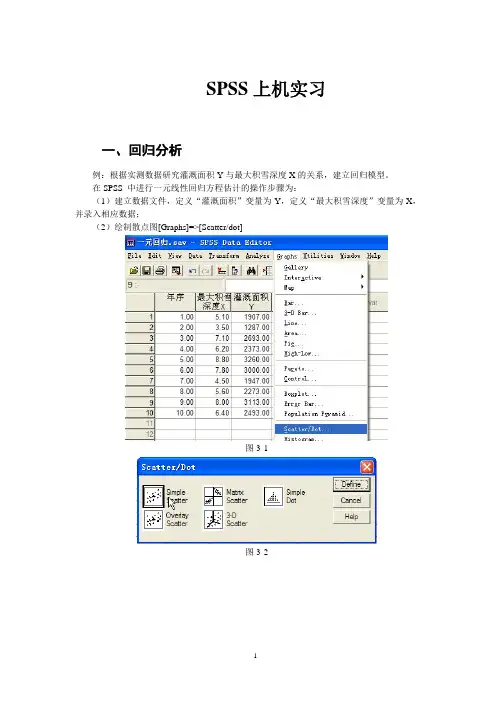
表1 记录中字段的意义字段名字段类型字段意义Cmpgn_name 标志活动名,均为Coupon campaign nameControl_yn 标志购买者类型: 控制:'c', 测试:'t'Redeemer_YN 标志是否为重复购买者: 是:'y', 否:'n'USER_ID 连续购买者IDGender 名义购买者性别: 女:'F',男:'M', 未知:'U'sge 连续购买者年龄, age=-99 意味着信息丢失CK_DATE 连续购买日期BUY_QTY 连续购买商品数量GMB 连续购买金额(美元)下面利用IBM SPSS Modeler 14.2进行决策树、聚类分析、关联分析和回归分析。
(1)决策树分析启动IBM SPSS Modeler 14.2,导入文件。
在工作平台上,添加一个Excel源节点。
双击该节点,文件类型设为“Excel 2007,2010(*.xlsx)”,导入文件为源Excel文件的路径,按名称DATA选择工作表,其他默认设置,如图15.87所示。
图15.87 导入文件查看源数据。
添加一个“表”节点,运行该表节点。
如图15.88所示,共有9个字段,1291条记录。
图15.88源数据下面首先利用C5.0算法进行决策树分析,探讨客户的年龄、性别、单次购买量、单次购买金额与购买者是否重复购物的关系。
添加“类型”节点。
在数据源节点后添加一个类型节点,把gender、age、BUY_QTY和GMB的角色设为数据流的输入,redeemer_yn的角色设为目标,其他的角色设为无,如图15.89所示。

基于IBM SPSS Modeler 14.2的客户数据挖掘IBM SPSS Modeler 14.2是一个从大量数据中挖掘有用模式的企业级数据分析平台,遵循跨行业数据挖掘流程标准(CRISP-DM)。
从数据源到数据建模,IBM SPSS Modeler 14.2提供了丰富的数据挖掘流程各个阶段需要的组件。
IBM SPSS Modeler 14.2包含数据获取、数据预处理、数据建模、评估和部署等一系列步骤,分析人员可通过拖放方式组合节点完成数据挖掘流程(以下简称数据流)。
IBM SPSS Modeler 14.2主界面如图 1 所示,包括流工作区、节点选项卡、管理器和IBM SPSS Modeler工程。
其中流工作区主要是用于创建数据流,用户可以把节点选项卡下的组件直接拖放到流工作区。
节点选项卡有多种节点:数据源、记录选项、字段选项、图形、建模、输出和导出等。
管理器主要用于管理输出和模型,用户可以对这些输出和模型进行打开、重命名、保存和删除等操作。
IBM SPSS Modeler工程允许用户以CRISP-DM模式管理数据流。
图1 IBM SPSS Modeler主界面IBM SPSS Modeler 14.2允许用户直接手动输入数据和把可变文件、Statistics文件、SAS文件、Excel和XML等多种数据导入,以供数据分析。
在导入数据后,需要对数据进行预处理。
IBM SPSS Modeler 14.2提供丰富的数据预处理组件,主要包括记录预处理和字段预处理。
其中在记录预处理中,提供了选择、抽样、汇总、排序、合并和追加等组件。
字段预处理包括类型、过滤、导出、分箱、字段重排、自动数据准备和分区等组件。
IBM SPSS Modeler 14.2提供了各种来自机器学习和统计学的建模方法,如分类、关联、聚类、序列和回归等模型。
本章应用IBM SPSS Modeler 14.2平台的几种常用数据挖掘算法,对客户交易的数据进行分析,获取客户管理有用的知识。



Modeler 建立线性回归模型示例线性回归模型是一种常用的统计学模型。
IBM SPSS Modeler 是一个强大的数据挖掘分析工具,本文将介绍如何用它进行线性回归预测模型的建立和使用。
在本文中,将通过建立一个理赔欺诈检测模型的实例来展示如何利用IBM SPSS Modeler 建立线性回归预测模型以及如何解释及应用该模型。
回归分析(Regression Analysis)是一种统计学上对数据进行分析的方法,主要是希望探讨数据之间是否有一种特定关系。
线性回归分析是最常见的一种回归分析,它用线性函数来对因变量及自变量进行建模(自变量和因变量都必须是连续型变量),这种方式产生的模型称为线性模型。
线性回归模型由于其运算速度快、直观性强以及参数易于确定等特点,在实践中应用最为广泛,也是建立预测模型的重要手段之一。
IBM SPSS Modeler 是一组数据挖掘工具,通过这些工具可以采用商业技术快速建立预测性模型,并将其应用于商业活动,从而改进决策过程。
在后面的文章中,将通过一个理赔欺诈检测的实际商业应用来介绍如何用IBM SPSS Modeler 建立、分析及应用线性回归分析模型。
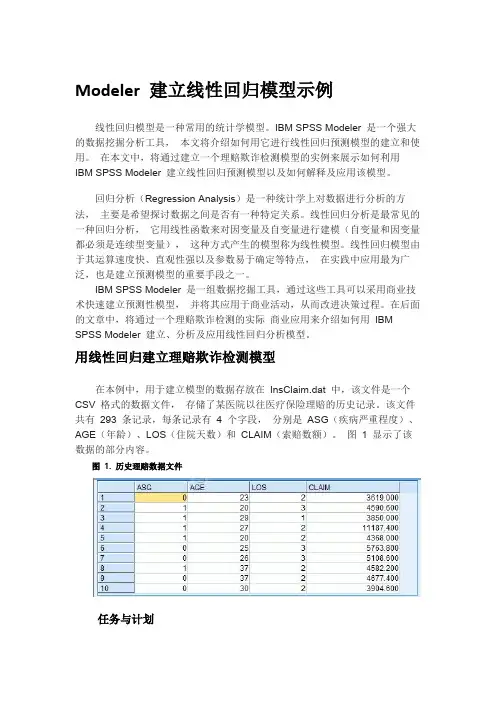
用线性回归建立理赔欺诈检测模型在本例中,用于建立模型的数据存放在InsClaim.dat 中,该文件是一个CSV 格式的数据文件,存储了某医院以往医疗保险理赔的历史记录。
该文件共有293 条记录,每条记录有 4 个字段,分别是ASG(疾病严重程度)、AGE(年龄)、LOS(住院天数)和CLAIM(索赔数额)。
图1 显示了该数据的部分内容。
图 1. 历史理赔数据文件任务与计划基于已有的数据,我们的任务主要有如下内容:∙建立理赔金额预测模型,该模型将基于病人的疾病严重程度、住院天数及年龄预测其索赔金额。
∙假设模型匹配良好,分析那些与预测误差较大的病人资料。
∙通过模型来进行索赔欺诈预测。
根据经验及对数据进行的初步分析(这个数据初步分析可以通过IBM SPSS Modeler 的功能实现,此处不是重点,故不做深入介绍),可以猜测理赔金额与疾病严重程度、住院天数以及年龄存在线性相关关系,因此我们将首先选用线性回归模型进行建模,因此可以得到下面这样一个初步计划:∙应用线性回归分析来建立模型。

回归树和分类树例子
回归树和分类树是两种不同类型的决策树,它们在数据挖掘中有着广泛的应用。
回归树主要用于预测连续的目标变量,例如预测房价、股票价格等。
以预测房价为例,我们可以使用回归树来建立一个模型,通过输入房屋的各个特征(如面积、卧室数量、所在区域等),模型可以预测出房屋的售价。
在回归树中,每个叶节点表示一个连续的目标变量的值,而非叶节点表示一个特征和该特征的阈值,用于将数据集分成更小的子集。
分类树主要用于预测离散的目标变量,例如预测疾病类型、用户分类等。
以预测用户是否会购买某产品为例,我们可以使用分类树来建立一个模型,通过输入用户的各个特征(如年龄、性别、收入等),模型可以预测出用户是否会购买该产品。
在分类树中,每个叶节点表示一个离散的目标变量的类别,而非叶节点表示一个特征和该特征的阈值,用于将数据集分成更小的子集。
总之,回归树和分类树都是通过建立决策树来对数据进行分类或回归预测,但它们所处理的目标变量类型不同。