视觉SLAM十四讲 第七讲 视觉里程计(1)
- 格式:pptx
- 大小:1.82 MB
- 文档页数:27

视觉SLAM十四讲引言视觉SLAM(Simultaneous Localization and Mapping)是一种通过摄像头获取图像数据,并在其中实时地定位和构建地图的技术。
它在无人驾驶、增强现实、机器人导航等领域有着广泛的应用。
《视觉SLAM十四讲》是一本经典的教材,本文将对该教材进行探讨和总结。
什么是视觉SLAM视觉SLAM是一种通过计算机视觉技术来实现实时定位和地图构建的技术。
通过摄像头获取图像,利用SLAM算法来实时地对机器人的位置和运动进行估计,并同时构建地图。
与传统的SLAM技术相比,视觉SLAM能够减少对其他传感器的依赖,提高系统的自主性和灵活性。
视觉SLAM的基本流程视觉SLAM的基本流程包括图像预处理、特征提取与匹配、运动估计、地图更新等步骤。
具体步骤如下:1.图像预处理–图像去畸变:对图像进行去除镜头畸变的处理,提高后续特征提取和匹配的效果。
–图像降噪:通过滤波等方法降低图像中的噪声,提高图像质量。
2.特征提取与匹配–特征提取:通过提取图像中的角点、边缘等特征点,用于后续的特征匹配和运动估计。
–特征匹配:通过比较两幅图像中的特征点,找到它们之间的对应关系,用于后续的运动估计和地图更新。
3.运动估计–单目SLAM:通过分析图像序列中的特征点的运动,估计机器人的运动轨迹。
–双目SLAM:利用双目摄像头获取的图像,通过立体视觉的方法来估计机器人的运动轨迹。
–深度估计SLAM:通过利用深度传感器获取的深度信息,估计机器人的运动轨迹。
4.地图更新–同步优化:通过对图像序列中的特征点和机器人的位姿进行联合优化,得到更精确的运动轨迹和地图。
–闭环检测:通过对图像序列中的特征点和地图进行匹配,检测是否存在闭环,进而修正运动估计和地图。
视觉SLAM算法简介视觉SLAM算法有很多种,常用的包括特征点法、直接法、半直接法等。
•特征点法:通过提取图像中的特征点,利用这些特征点之间的关系来进行定位和地图构建。


SLAM14讲第七章特征点法视觉前端和优化后端视觉⾥程计VO-根据相邻图像的信息估计处粗略的相机运动,给后端较好的估计值【⼀】特征提取与匹配:特征点法——运⾏稳定,对光照、动态物体不敏感主要问题:根据图像来估计相机运动特征点-路标-有代表性的点-图像信息的⼀种表达形式-在相机运动之后保持稳定-⾓点|边缘|区块仅灰度值:受光照、形变、物体材质的影响严重【×】SIFT\SURF\ORB——可重复性、可区别性、⾼效、局部特征点=关键点(图像中的位置、朝向、⼤⼩)+描述⼦(向量,周围像素)依据【外观相似的特征有相似的描述⼦原则】SIFT尺度不变特征变换 5228.7msFAST关键点——计算速度很快,没有描述⼦,不具有⽅向性ORB(旋转、尺度不变性)——速度极快的⼆进制描述⼦BRIEF 1000点/15.3msSURF 217.3ms7.1 ORB特征Oriented FAST关键点(FAST+特征点主⽅向)+BRIEF特征⼦1 FAST关键点FAST⾓点:检测局部像素像素灰度变化明显的地⽅(只⽐较像素亮度⼤⼩)FAST-9/11/12(半径为3的圆上16个像素点中有N个⼤于或⼩于中⼼点的阈值120%/80%)FAST-12预测试:第1/5/9/13个点的情况#⾮极⼤值抑制:⼀定区域内仅保留响应极⼤值的⾓点,避免集中【缺点1】FAST特征点量⼤且不确定,往往希望对图像提取固定数量的特征【改进】固定数量N,原始FAST⾓点计算Harries响应值【缺点2】FAST不具有⽅向信息【改进】由构建图像⾦字塔并在每⼀层检测⾓点实现尺度不变性,灰度质⼼(以图像块灰度值作为权重的中⼼)法实现特征旋转2 BRIEF描述⼦关键点附近两个像素p和q的⼤⼩关系,1/0,128维,随机选取旋转后的Steer BRIEF特征7.2 特征匹配(数据关联)#场景⼤量重复纹理导致的误匹配问题计算特征点之间的描述⼦距离,通常汉明距离,⼆进制不同位数的个数特征点多时,⽤快速近似最近邻FLANN算法#include <iostream>#include <opencv2/core/core.hpp>#include <opencv2/features2d/features2d.hpp>#include <opencv2/highgui/highgui.hpp>using namespace std;using namespace cv;int main ( int argc, char** argv ){if ( argc != 3 ) //确认输⼊为两张图⽚{cout<<"usage: feature_extraction img1 img2"<<endl;return1;}//-- 读取图像// imread C++ 模型// include <opencv2/imgcodecs.hpp>// Mat cv::imread( const String & filename, int flags = IMREAD_COLOR)// 返回MAT类型,读取失败时返回空矩阵 Mat::data = NULL// 参数1:filename 读取的图⽚⽂件名绝对/相对路径要加后缀// 参数2:flags 读取标记,读取图⽚的⽅式,默认为IMREAD_COLOR(好像没影响)Mat img_1 = imread ( argv[1], IMREAD_COLOR );Mat img_2 = imread ( argv[2], CV_LOAD_IMAGE_COLOR );//-- 初始化std::vector<KeyPoint> keypoints_1, keypoints_2;//关键点-放置keypoint对象的⼀个vectorMat descriptors_1, descriptors_2;//描述⼦,cv::Mat类型//OpenCV提供FeatureDetector实现特征检测及匹配;//FeatureDetetor是虚类,通过定义FeatureDetector的对象可以使⽤多种特征检测⽅法。

视觉SLAM⼗四讲学习笔记1——ch1预备知识ch2初始SLAM第⼀章SLAM(Simultaneous Localization and Mapping(同时定位与地图构建)):搭载特定传感器的主体,在没有环境先验信息的情况下,于运动过程中建⽴环境的模型,同时估计⾃⼰的运动。
第⼆章考虑携带于机器⼈本体上的传感器——IMU、激光、相机。
SLAM⼀般分为激光SLAM和视觉SLAM(相机),⽬前激光SLAM技术⽐较成熟,相机SLAM仍在发展过程中。
视觉SLAM⼀般分为3种:单⽬相机(Monocular)、双⽬相机(Stereo)、深度相机(Stereo)单⽬相机:没有深度,必须通过移动相机产⽣深度。
双⽬相机:通过视差计算深度。
深度相机:通过物理⽅法测量深度。
(量程较⼩、易受⼲扰、功耗较⼤)视觉SLAM整体流程图: 视觉⾥程计(Visual Odometry,VO):视觉⾥程计的任务是估算相邻图像间相机的运动,以及局部地图的样⼦(VO ⼜称为前端) 后端优化(Optimization):后端接受不同时刻视觉⾥程计测量的相机位姿,以及回环检测的信息,对它们进⾏优化,得到全局⼀致的轨迹和地图(由于接在 VO 之后,⼜称为后端) 回环检测(Loop Closing):回环检测判断机器⼈是否到达过先前的位置。
如果检测到回环,它会把信息提供给后端进⾏处理。
建图(Mapping):它根据估计的轨迹,建⽴与任务要求对应的地图。
视觉⾥程计:根据相邻的图像估计相机的运动,不可避免地存在漂移。
⽬前基本存在两种主要⽅法:特征点法(第七讲)、直接法(第⼋讲)后端优化:从带有噪声的数据中优化轨迹和地图,解决状态估计的问题。
后端优化要考虑状态估计的不确定性有多⼤——即最⼤后验概率估计(MAP)。
后端优化的⽅法前期以EKF为代表,现在以图优化为代表。
(第⼗讲、第⼗⼀讲)回环检测:词袋模型(第⼗⼆讲)建图:(第⼗三讲)SLAM问题的数学描述: 前⼀个⽅程为运动⽅程,描述了从k-1时刻到k时刻,机器⼈的位置是如何变化的。

《视觉SLAM⼗四讲》笔记(ch7)ch7 视觉⾥程计1本章⽬标:1.理解图像特征点的意义,并掌握在单副图像中提取出特征点及多副图像中匹配特征点的⽅法2.理解对极⼏何的原理,利⽤对极⼏何的约束,恢复出图像之间的摄像机的三维运动3.理解PNP问题,以及利⽤已知三维结构与图像的对应关系求解摄像机的三维运动4.理解ICP问题,以及利⽤点云的匹配关系求解摄像机的三维运动5.理解如何通过三⾓化获得⼆维图像上对应点的三维结构本章⽬的:基于特征点法的vo,将介绍什么是特征点,如何提取和匹配特征点,以及如何根据配对的特征点估计相机运动和场景结构,从⽽实现⼀个基本的两帧间视觉⾥程计。
特征点:⾓点、SIFT(尺度不变特征变换,Scale-Invariant Feature Transform)、SURF、、ORB(后三个是⼈⼯设计的特征点,具有更多的优点)特征点的组成:1.关键点:指特征点在图像⾥的位置2.描述⼦:通常是⼀个向量,按照某种⼈为设计的⽅式,描述了该关键点周围像素的信息。
相似的特征应该有相似的描述⼦(即当两个特征点的描述⼦在向量空间上的距离相近,认为这两个特征点是⼀样的)以ORB特征为代表介绍提取特征的整个过程:ORB特征:OrientedFAST关键点+BRIEF关键⼦提取ORB特征的步骤:1.提取FAST⾓点:找出图像中的“⾓点”,计算特征点的主⽅向,为后续BRIEF描述⼦增加了旋转不变特性FAST⾓点:主要检测局部像素灰度变化明显的地⽅特点:速度快缺点:1).FAST特征点数量很⼤且不确定,但是我们希望对图像提取固定数量的特征2).FAST⾓点不具有⽅向信息,并且存在尺度问题解决⽅式:1).指定要提取的⾓点数量N,对原始FAST⾓点分别计算Harris响应值,然后选取前N个具有最⼤响应值的⾓点作为最终的⾓点集合2).添加尺度和旋转的描述 尺度不变性的实现:构建图像⾦字塔,并在⾦字塔的每⼀层上检测⾓点(⾦字塔:指对图像进⾏不同层次的降采样,以获得不同分辨率的图像)特征旋转的实现:灰度质⼼法(质⼼:指以图像块灰度值作为权重的中⼼)2.计算BRIEF描述⼦:对前⼀步提取出的特征点周围图像区域进⾏扫描特点:使⽤随机选点的⽐较,速度⾮常快,由于使⽤了⼆进制表达,存储起来也⼗分⽅便,适⽤于实时的图像匹配在不同图像之间进⾏特征匹配的⽅法:1.暴⼒匹配:浮点类型的描述⼦,使⽤欧式距离度量⼆进制类型的描述⼦(⽐如本例中的BRIEF描述⼦),使⽤汉明距离度量缺点:当特征点数量很⼤时,暴⼒匹配法的运算量会变得很⼤2.快速近似最近邻(FLANN):适合匹配特征点数量极多的情况实践部分:1.OpenCV的图像特征提取、计算和匹配的过程:演⽰如何提取ORB特征并进⾏匹配代码: 1 #include <iostream>2 #include <opencv2/core/core.hpp>3 #include <opencv2/features2d/features2d.hpp>4 #include <opencv2/highgui/highgui.hpp>56using namespace std;7using namespace cv;89int main(int argc,char** argv)10 {11if(argc!=3)12 {13 cout<<"usage:feature_extraction img1 img2"<<endl;14return1;15 }1617//读取图像18 Mat img_1=imread(argv[1],CV_LOAD_IMAGE_COLOR);19 Mat img_2=imread(argv[2],CV_LOAD_IMAGE_COLOR);2021//初始化22 vector<KeyPoint> keypoints_1,keypoints_2;//关键点,指特征点在图像⾥的位置23 Mat descriptors_1,descriptors_2;//描述⼦,通常是向量24 Ptr<ORB> orb=ORB::create(500,1.2f,8,31,0,2,ORB::HARRIS_SCORE,31,20);2526//第⼀步:检测OrientFAST⾓点位置27 orb->detect(img_1,keypoints_1);28 orb->detect(img_2,keypoints_2);2930//第2步:根据⾓点位置计算BRIEF描述⼦31 orb->compute(img_1,keypoints_1,descriptors_1);32 orb->compute(img_2,keypoints_2,descriptors_2);3334 Mat outimg1;35 drawKeypoints(img_1,keypoints_1,outimg1,Scalar::all(-1),DrawMatchesFlags::DEFAULT);36 imshow("1.png的ORB特征点",outimg1);37 Mat outimg2;38 drawKeypoints(img_2,keypoints_2,outimg2,Scalar::all(-1),DrawMatchesFlags::DEFAULT);39 imshow("2.png的ORB特征点",outimg2);4041//第3步:对两幅图像中的BRIEF描述⼦进⾏匹配,使⽤Hamming距离42 vector<DMatch> matches;43//特征匹配的⽅法:暴⼒匹配44 BFMatcher matcher(NORM_HAMMING);45 matcher.match(descriptors_1,descriptors_2,matches);46// for(auto it=matches.begin();it!=matches.end();++it)47// {48// cout<<*it<<" ";49// }50// cout<<endl;5152//第4步:匹配点对筛选53 distance是min_dist5455double min_dist=10000,max_dist=0;5657//找出所有匹配之间的最⼩距离和最⼤距离,即最相似的和最不相似的和最不相似的两组点之间的距离58for(int i=0;i<descriptors_1.rows;++i)59 {60double dist=matches[i].distance;61// cout<<dist<<endl;62if(dist<min_dist) min_dist=dist;63if(dist>max_dist) max_dist=dist;64 }6566 printf("--Max dist:%f\n",max_dist);67 printf("--Min dist:%f\n",min_dist);6869//当描述⼦之间的距离⼤于两倍的最⼩距离时,即认为匹配有误70//但有时候最⼩距离会⾮常⼩,设置⼀个经验值作为下限71 vector<DMatch> good_matches;72for(int i=0;i<descriptors_1.rows;++i)73 {74if(matches[i].distance<=max(2*min_dist,30.0))75 {76 good_matches.push_back(matches[i]);77 }78 }7980//第5步:绘制匹配结果81 Mat img_match;82 Mat img_goodmatch;83 drawMatches(img_1,keypoints_1,img_2,keypoints_2,matches,img_match);84 drawMatches(img_1,keypoints_1,img_2,keypoints_2,good_matches,img_goodmatch);85 imshow("所有匹配点对",img_match);86 imshow("优化后匹配点对",img_goodmatch);87 waitKey(0);8889return0;90 }实验结果:1.png中提取到的特征点2.png中提取到的特征点匹配结果: 所有点对匹配结果 优化后的匹配点对结果(筛选依据是Hamming距离⼩于最⼩距离的两倍)结果分析:尽管在这个例⼦中利⽤⼯程经验优化筛选出正确的匹配,但并不能保证在所有其他图像中得到的匹配都是正确的,所以,在后⾯的运动估计中,还要使⽤去除误匹配的算法。

MPIG Seminar0045Feature Extraction陈伟杰Machine Perception and Interaction Group (MPIG)cwj@Feature ExtractionRefined based on the book:Mastering OpenCV with Practical Computer VisionProjects_full.pdfandBay H, Tuytelaars T, Van Gool L. Surf: Speeded up robust features [M]. Computer vision–ECCV 2006. Springer. 2006: 404-417.or F for [R|t]Drawing pathThe main steps of Visual Odometryimages parametersFeature ExtractionFeaturematchingCompute EFirstFeature Extraction What feature is?Characteristics can be easily identified in imagesEdges Corners Blobslines pointsHarris SIFT SURF Commonly used algorithm:•Corner extractor•Fast operation •Poor resolution •Not applicable when scalechanges •Blobs extractor•Slow operation•Good resolution•Scale invariance•Upgrade fromSIFT•Speed up•More robustSURF(Speed Up Robust Feature) opencv2/nonfree/features2d.hppSurfFeatureDetectordetector()SurfDescriptorExtractorSURF(Speed Up Robust Feature)Integral imageii x,y = i=0i≤x j=0j≤yI(i,j)(x,y)ACB D1234ii 1= A ii 2= A + BD =ii 1+ii 4−ii 2−ii 3SURF(Speed Up Robust Feature)Hessian matrixH x,σ=L xx(x,σ)L xy(x,σ) L xy(x,σ)L yy(x,σ)L x,σ=Gσ∗I(x,y)Gσ=ð2g(σ)ðx2g(σ) is Gaussian function andσis varianceIt’s the image conversion like frequency domain transformApproximation of Hessian matrixDetHapprox=D xx D yy−0.9D xy2L yy L xyD yy DxyWe can use integral image to compute easily nowH x,σ=L xx(x,σ)L xy(x,σ)L xy(x,σ)L yy(x,σ) Filter templateSURF(Speed Up Robust Feature)scale space (image pyramid)SIFT SURF Change size of filter only Easier and fasterPositioning feature points3×3 window“x”is extreme point when it’s themax or the min of 26 points aroundSetting a threshold value tif x>t, x is feature pointThe larger t is, the less points will beSURF feature descriptorMain directionStatistics harr wavelet feature around the feature point with the range of 60°in a circle of radius6s(s is the scale of the feature point)The max value is main directionSURF feature descriptormain directionfeature point 20s Every descriptor has4*4*4=64 dimensional vectorMat img1 = imread( "chapel00.png");Mat img2 = imread("chapel01.png");int minHessian = 400;SurfFeatureDetector detector( minHessian );std::vector<KeyPoint> keypoints1, keypoints2;detector.detect(img1, keypoints1);detector.detect(img2, keypoints2);// computing descriptorsSurfDescriptorExtractor extractor;Mat descriptors1, descriptors2;pute(img1, keypoints1, descriptors1);pute(img2, keypoints2, descriptors2);CODE//--Draw keypoints Mat img_keypoints_1; Mat img_keypoints_2;drawKeypoints( img1, keypoints1, img_keypoints_1, Scalar::all(-1), DrawMatchesFlags::DEFAULT );drawKeypoints( img2, keypoints2, img_keypoints_2, Scalar::all(-1), DrawMatchesFlags::DEFAULT );//--Show detected (drawn) keypoints imshow("Keypoints 1", img_keypoints_1 );imshow("Keypoints 2", img_keypoints_2 );waitKey(0);return 0;800 400200 minHessian。

12_视觉⾥程计1_ICP算法前⾔ICP的英⽂全称为Iterative Closest Point,即为迭代最近点。
它在激光雷达应⽤频率很⾼,主要是在点云配准领域。
ICP算法在是是视觉SLAM中应⽤也⾮常多,这个算法还是很重要。
我们下⾯的讨论还是基于视觉SLAM,好了我们开始吧!ICP算法流程ICP算法顾名思义,就是找最近点。
算法流程如下:step1:预处理点云step2:寻找对应点(最近点)step3:根据对应点,计算R和tstep4:对点云进⾏转换,计算误差step5:不断迭代,直⾄误差⼩于某⼀个值3D-3D: ICP假设我们有⼀组配对好的3D点如下:\boldsymbol{P}=\left\{\boldsymbol{p}_{1}, \cdots, \boldsymbol{p}_{n}\right\}, \quad \boldsymbol{P}^{\prime}=\left\{\boldsymbol{p}_{1}^{\prime}, \cdots, \boldsymbol{p}_{n}^{\prime}\right\}现在我们想要找到⼀个欧式变换,使得\forall i, \boldsymbol{p}_{i}=\boldsymbol{R} \boldsymbol{p}_{i}^{\prime}+\boldsymbol{t}.上述的这个问题就可以使⽤ICP算法求解。
这⾥主要需要注意下,如果仅考虑3D点之间的变换,此时和相机并没有关系。
在RGB-D SLAM中⽤ICP问题指代匹配好的两组点间的运动估计问题(跟激光SLAM有区别,激光SLAM通常是未知的情况)。
ICP求解主要是两种⽅式,⼀种是SVD,另⼀种是⾮线性优化⽅式求解。
SVD⽅法根据前⾯描述的ICP问题,令第i对点的误差为:\boldsymbol{e}_{i}=\boldsymbol{p}_{i}-\left(\boldsymbol{R} \boldsymbol{p}_{i}^{\prime}+\boldsymbol{t}\right).这⾥解释⼀下,我们⽤⼀个点\boldsymbol{p}_{i}^{\prime}(第⼆幅图中数据)来估算另⼀个点\boldsymbol{p}_{i}时(在第⼀幅中数据,即为观测坐标),必然会产⽣误差。
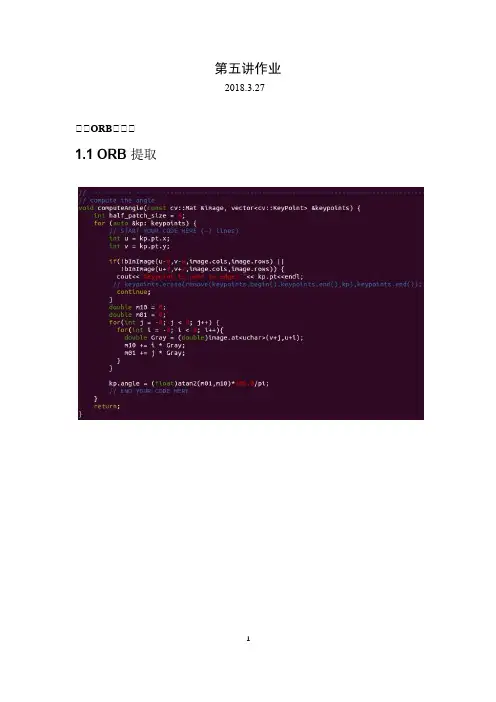
第五讲作业2018.3.27一一ORB一一一1.1 ORB 提取1.2 ORB 描述1.3 暴力匹配问题回答如下:1.ORB 的描述子是用许多对像素点坐标(此处坐标需要经过旋转校正)所在位置的灰度值的大小对比来组成,对比结果为0 和1,假设有256 对像素点,那么ORB 的特征点描述子便有256 个0 或1 组成,因此称ORB 是一种二进制特征;2.ORB 匹配时是计算两个描述子之前的汉明距离,即计算两个二进制值在每一位上不相等的个数,当然我们希望这个不相等的个数越少越好,当个数为0,则说明两个描述子的特征完全一致,随着个数越多,说明两个特征不一致的程度也就越高,因此若将阈值取小,则匹配点对的数量越少,但是误匹配几率越小,反之,若将阈值调高,则匹配出的点对数量增加,但误匹配几率也增加。
3.匹配出107 组点,耗时为3329.67ms 。
若在CMakeLists 中增加-O2 编译优化,则耗时可减小至160.675ms,若改为-O3 编译优化,耗时可继续减小至154.373ms。
一一一E一一R,t三一一G-N 一一Bundle Adjustment问题回答如下:1.重投影误差:(ξ) = P uv − 1 Kexp(ξ∧)P wz c2.雅可比矩阵为:f xJ(ξ)=−zc0 [0z c −−f x zx2c2−−ff xy zx cc−2y c z c f2x2+ff yx zzxx c c c2c2y2c−f y zfx c x z c y c ] z cf y f y y c f y y cc3.更新之前估计:T k+1 exp T k四一一ICP一一一一一一11。

2 LK 光流(5分,约3小时)2.1光流文献综述(1分)我们课上演示了Lucas-Kanade 稀疏光流,用OpenCV 函数实现了光流法追踪特征点。
实际上,光流法有很长时间的研究历史,直到现在人们还在尝试用Deeplearning 等方法对光流进行改进[1,2]。
本题将指导你完成基于Gauss-Newton 的金字塔光流法。
首先,请阅读文献[3](paper 目录下提供了pdf ),回答下列问题。
问题:1. 按此文的分类,光流法可分为哪几类?答:作者在文中对光流法按照两种不同的方法进行分类。
➢ 按照估计的是参数的叠加增量还是增量Warp 将光流法分为叠加(additional)和组合(compositional)算法➢ 按照Warp 更新规则可以将光流法分为前向(forward )和逆向/反向(inverse)两种算法综上:可以分4类,分别是 FA(Forward Additional), FC(Forward Composition), (Inverse Additional) 和 IC(Inverse Compositional)。
2. 在compositional 中,为什么有时候需要做原始图像的wrap ?该wrap 有何物理意义?答: 与Lucas-Kanade 算法中那样简单地将迭代的更新 p ∆添加到当前估计的参数p 不同,组合(compositional )算法中,对扭曲();W x p ∆的增量更新必须由Warp 的当前估计组成() ;Wx p 。
这两个 warp 的组合可能更复杂。
因此,我们对 warp 集合有两个要求: 1)warp 集合必须包含 identity warp 。
2)warp 集合必须在组合运算中闭合。
需要在当前位姿估计之前引入增量式 warp (incremental warp )以建立半群约束要求(the semi-group requirement )。

基于SLAM的视觉里程计特征匹配方法研究基于SLAM的视觉里程计特征匹配方法研究摘要:视觉里程计(Visual Odometry, VO)是一种基于单目相机或多目相机的建模方法,通过分析连续图像间的特征点匹配来实现对相机运动的估计。
本文主要针对基于SLAM (Simultaneous Localization and Mapping)的视觉里程计特征匹配方法进行研究,对几种常用的特征提取和匹配算法进行分析,并提出一种改进的特征匹配算法,在多种场景下进行实验验证。
1. 引言视觉里程计是自主移动机器人和增强现实等领域中的重要研究内容,它通过分析图像序列来估计相机的运动,为机器人的导航和定位提供实时信息。
传统的特征匹配方法主要基于SIFT (Scale-Invariant Feature Transform)算法,但由于其计算量较大、实时性较差,近年来逐渐被ORB(Oriented FAST and Rotated BRIEF)算法所取代。
然而,在复杂环境或光照变化较大的情况下,ORB算法也存在较大的局限性。
因此,改进特征匹配算法成为了当前研究的重点。
2. 特征提取与描述特征提取是视觉里程计中的关键步骤之一。
本文采用ORB算法进行特征点提取,该方法结合了FAST角点检测器和BRIEF描述子,在保持较好计算效率的同时,依然保持了一定的特征点质量。
为了进一步改进ORB算法,本文使用了自适应密集采样的方法,通过提高特征点的密度来增强对复杂场景的适应性。
3. 特征匹配方法特征匹配是视觉里程计中的核心环节。
为了提高匹配的准确性和鲁棒性,本文提出了一种改进的基于SLAM的特征匹配方法。
首先,在特征提取的基础上,利用EPnP算法对场景中的特征点进行三维重建,以获得更多的几何信息。
然后,采用改进的基于BOW(Bag of Words)的特征描述方法,将特征点进行编码,形成特征词袋。
最后,在图像间建立基于词袋间的相似度度量,通过最小化误差函数进行特征点匹配。

视觉SLAM中的视觉里程计算法研究随着现代科技的不断发展,人们对机器视觉的研究也日益深入。
其中,视觉SLAM技术就是机器视觉领域中的一项重要研究内容。
在视觉SLAM系统中,视觉里程计算法是实现实时位姿估计的核心部件,其基本功能是通过分析传感器所采集的图像序列,计算出相机的运动轨迹和位姿信息。
本文将从视觉里程计算法的原理、发展历程以及研究现状三个方面对该技术进行介绍和探讨。
一、原理视觉里程计是一种利用相邻图像之间的像素运动来估计相机位姿和运动的技术。
它通常基于对图像两两之间的相似性进行分析,从而确定相邻图像之间运动的向量,并进一步累积运动向量以计算相机的运动。
其核心思想是通过优化所构建的矩阵,最小化估计值与观测值之间的误差差距,从而得到最优的位姿和轨迹。
二、发展历程1. 基于特征点的方法最早的视觉里程计方法是基于特征点的匹配。
该算法利用特征点在图像上的唯一性和高可重复性,通过图像特征的匹配推导出相机位姿。
该算法最早应用于微软Kinect深度相机和Leap Motion手势控制器等设备中。
2. 基于直接法的方法直接法是近年来兴起的一种视觉里程计算法。
该方法利用像素强度值之间的变化关系来计算相邻图像之间的运动。
与基于特征点的方法不同,直接法不需要进行前期特征提取,从而可以克服特征提取的不稳定性和局限性。
该方法在2014年首次被应用于自主驾驶汽车,大大提高了车辆的行驶安全性和精度。
3. 基于深度学习的方法深度学习的发展为视觉里程计的研究提供了新的思路和方法。
基于深度学习的方法通过构建深度神经网络模型,利用深度感知技术提取图像的深度信息,在视觉里程计的计算中发挥重要作用。
该方法在场景重建、运动估计和位姿估计等方面都取得了不俗的成果,是未来研究的重点方向之一。
三、研究现状视觉里程计是视觉SLAM系统中的一个关键技术,也是目前研究的热点领域之一。
国内外学者在该领域开展了大量的深入研究,并取得了一系列重要的进展。
视觉里程计原理视觉里程计是一种基于机器视觉的定位技术,它利用摄像头来捕捉场景图像,并通过视觉模式识别、图像匹配和定位算法来定位于空间中的物体和环境,从而获取运动的轨迹等一系列受控数据。
由于其具有低成本、易操作等优点,视觉里程计技术广泛应用于机器人定位导航、工业自动化、空中和地面测绘等领域。
一般情况下,视觉里程计系统是由两个主要构成部件组成的:摄像头和定位系统。
摄像头用于捕捉场景图像,而定位系统则用来根据捕获的图像信息进行定位。
对于精度要求较高的应用场景,摄像头可以搭配电子游标等配件使用,以提高场景图像的清晰度;而定位系统则包括硬件设备和软件系统两部分,硬件设备由电脑、运动控制硬件、摄像头等组成,软件系统则负责开发、实现和管理视觉里程计系统的各项功能。
视觉里程计系统的核心技术主要有视觉模式识别技术、图像匹配技术和定位算法技术。
视觉模式识别技术提供了定位系统的基础技术支持,能够根据图像的结构特征划分或识别出不同的场景,以实现空间识别;图像匹配技术则主要用于识别捕捉图像中特定物体,从而提取其特征信息;定位算法技术则在视觉模式识别和图像匹配的基础上,采用多种不同的定位算法(例如最小二乘法、基于距离的定位算法等),根据物体和环境的特征信息,对定位性能进行更进一步的改善和优化。
视觉里程计技术被广泛应用于机器人定位导航、空中和地面测绘,工业自动化以及无人机等多个领域,它结合了摄像头和定位系统,具有低成本、易操作、可移植性等特点;此外,它还可以根据特定场景的要求进行实时优化和调整,以期获得更好的定位性能。
与GPS和红外技术相比,视觉里程计技术的优势在于它可以在有阴影、遮挡或改变地形的情况下实现定位,以及不受白天黑夜的影响,从而更好地满足室内定位和室外定位的需求。
总之,视觉里程计技术是一种由摄像头、定位系统和定位算法技术构成的综合机器视觉位置定位技术,它具有低成本、易操作和可移植性优势,同时可以根据场景要求进行实时优化和调整,更好地满足各种室内和室外定位需求。
CV⾥程计、推算定位与视觉⾥程计简介转⾃:以下内容翻译⾃wiki百科。
⾥程计(Odometry):原⽂链接在此:⾥程计是⼀种利⽤从移动传感器获得的数据来估计物体位置随时间的变化⽽改变的⽅法。
该⽅法被⽤在许多种机器⼈系统(轮式或者腿式)上⾯,来估计,⽽不是确定这些机器⼈相对于初始位置移动的距离。
这种⽅法对由速度对时间积分来求得位置的估计时所产⽣的误差⼗分敏感。
快速、精确的数据采集,设备标定以及处理过程对于⾼效的使⽤该⽅法是⼗分必要的。
假设⼀个机器⼈在其轮⼦或腿关节处配备有旋转编码器等设备,当它向前移动⼀段时间后,想要知道⼤致的移动距离,借助旋转编码器,可以测量出轮⼦旋转的圈数,如果知道了轮⼦的周长,便可以计算出机器⼈移动的距离。
假设有⼀个简单的机器⼈,配备有两个能够前后移动的轮⼦,这两个轮⼦是平⾏安装的,并且相距机器⼈的中⼼的距离是相等的。
假如每个电机都配备有⼀个旋转编码器,我们便可以计算出任意⼀个轮⼦向前或向后移动⼀个单位时,机器⼈中⼼实际移动的距离。
该单位长度为轮⼦周长的某⼀⽐例值,该⽐例依赖于编码器的精度。
假设左边的轮⼦向前移动了⼀个单位,⽽右边的轮⼦保持静⽌,则右边的轮⼦可以被看做是旋转轴,⽽左边的轮⼦沿顺时针⽅向移动了⼀⼩段圆弧。
因为我们定义的单位移动距离的值通常都很⼩,我们可以粗略的将该段圆弧看做是⼀条线段。
因此,左轮的初始与最终位置点,右轮的位置点就构成⼀个三⾓形A。
同时,机器⼈中⼼的初始与最终位置点,以及右轮的位置点,也构成了⼀个三⾓形B。
由于机器⼈中⼼到两轮⼦的距离相等,同时,两三⾓形共⽤以右轮位置为顶点的⾓,故三⾓形A,B相似。
在这种情况下,机器⼈中⼼位置的改变量为半个单位长度。
机器⼈转过的⾓度可以⽤正弦定理求出。
推算定位(dead reckoning):原⽂链接在此:在导航系统中,推算定位(DR)是⼀个借助于先前已知位置,以及估计出的速度随时间的变化量来推导出当前位置的过程。
基于卷积神经网络的视觉里程计经典的视觉里程计系统提取稀疏或密集的特征并匹配以执行帧到帧的运动估计,但是都需要针对它们所处的特定环境进行仔细的参数调整。
受深度网络的最新进展和以前关于应用于VO 的学习方法的启发,探索了使用卷积神经网络来学习视觉位姿估计任务。
通过对公开数据集进行实验,验证方法性能。
最后,对算法进行总结分析并对展望其发展趋势。
标签:视觉里程计;位姿估计;深度学习; 卷积神经网络0 引言视觉里程计[1],也称为帧间估计,是视觉SLAM[2](simultaneous localization and mapping)中的核心内容。
经典的基于几何的视觉里程计方法分为特征点法与直接法。
但是其依据于大量的计算,并且估计结果对相机参数极为敏感。
近年来,人工智能、深度学习再次掀起了热潮,基于深度学习的视觉任务丰富多样,在分类、跟踪等问题上都取得了很好的效果。
但是多学习外观特征,而视觉里程计需要学习图片的几何特征。
本文提出了一种基于卷积神经网络的视觉里程计方法,将数据集进行预处理,将图片序列中相邻的两张RGB图片进行串联,每张图片的通道数为3,得到一个通道数为6的张量,输入到神经网络中。
参考Vgg网络结构进行特征提取工作。
将提取的特征输入到全链接层将张量压缩为位姿特征向量。
通过KITTI 数据集进行实验,输出图片之间的相对位姿,并转化为绝对位姿和地面真实轨迹进行对比。
1 相关内容1.1 经典的几何方法经典的几何帧间估计方法有着悠久的解决方案设计的历史。
最开始是基于稀疏的特征跟踪,研究者们设计了很多具有鲁棒性的角点、边缘点、区块等比较有代表性的点的特征提取与匹配的算法,在这些特征的基础上估计相机的运动,如SIFT,SURF,ORB等。
Eigel[3]等人开发了最经典的直接方法之一LSD-SLAM。
直接方法在过去几年中得到了最多的关注,Mur-Artal等人的ORB-SLAM[4]算法进行稀疏特征的跟踪也达到了令人印象深刻的鲁棒性和准确性。