数据库和表
- 格式:pptx
- 大小:164.75 KB
- 文档页数:82

数据库及表的创建心得一、引言数据库是存储、检索和管理数据的重要工具,而表是数据库中组织和存储数据的基本单元。
在实际的数据库设计与开发工作中,创建数据库及表是首要任务之一。
在这个过程中,我经过实践和总结,积累了一些创建数据库及表的经验和心得。
本文将就此进行详细探讨。
二、创建数据库2.1 数据库的选择在创建数据库之前,首先要确定使用什么数据库管理系统。
市面上有很多种不同的数据库系统,如MySQL、Oracle、SQL Server等。
选取适合自身需求的数据库系统非常重要。
不同的数据库系统各自有其特点和优势,比如MySQL适用于大部分中小型项目,Oracle适用于大型企业级项目。
根据实际需求和项目的规模,选择合适的数据库系统是关键。
2.2 数据库命名规范数据库的命名规范直接关系到后续的维护和管理。
通常,数据库的命名应该能够清晰地表达其所包含的内容。
命名应具备可读性和可维护性,避免使用过于简单和含糊的名字。
同时,数据库的命名应该符合一定的命名规范,比如使用全小写字母、下划线连接不同的单词等。
2.3 数据库字符集和校对规则在创建数据库时,字符集和校对规则的设置是非常重要的。
字符集决定了数据库中可以使用的字符种类,包括各种语言和特殊字符。
而校对规则决定了对这些字符进行排序和比较的规则。
一般来说,选择常用的字符集和校对规则即可满足大部分需求,但对于特殊需求,可以根据实际情况进行定制。
三、创建表3.1 表的设计原则在创建表之前,需要进行详细的表设计。
表的设计原则是关系数据库设计的基石,良好的表设计能够提高数据库的性能和扩展性。
在进行表设计时,应该遵循以下原则: 1. 实体和属性之间的一致性:一个表应该只包含一个实体,表中的每个列都应该定义一个属性。
2. 消除冗余数据:避免在多个表中存储相同的数据,而是通过关联等方式进行引用。
3. 数据类型选择合理:对每个列选择合适的数据类型,既能满足存储需求,又能节省存储空间。



数据库之表与表之间建关系⼀、⼀对多关系定义⼀张部门员⼯表我们就会发现把所有数据存放于⼀张表的弊端:1.组织结构不清晰2.浪费硬盘空间3.扩展性极差这样的弊端是不是看着很眼熟,没错!这就类似于我们代码全部写在⼀个py⽂件中,那么当我们发现⼀个py⽂件中的代码冗余度很⾼会怎么做呢?当然就是要进⾏解耦合!那么我再来分析这张表数据之间的关系:多个⽤户对应⼀个部门,⼀个部门就对应了多个⽤户,那么他们之间的关系就应该是⼀对多的关系,我们可以将上⾯的表拆开成两张表,⼀张是记录⽤户信息,另⼀张记录部门信息,再⽤某种⽅法使者两张表关联起来,这个⽅法就是:使⽤Foreign Key确⽴表与表之间的关系⼀定要换位思考(必须两⽅⾯都考虑周全之后才能得出结论)Foreign Key:外键约束1.在创建表的时候,必须先创建被关联表2.插⼊数据的时候,也必须先插⼊被关联表的数据创建表:1#在创建表的时候,⼀定要先建被关联的表,才能创建关联表2create table dep(3id int primary key auto_increment,4 dep_name varchar(64),5 dep_desc varchar(64)6);78create table emp(9id int primary key auto_increment,10 name varchar(16),11 gender enum('male','female','others')not null default 'male',12age int,13emp_id int,14foreign key(emp_id) references dep(id)15 );插⼊记录:1#插⼊记录时,必须先插被关联的表dep,才能插关联表emp2insert into dep(dep_name,dep_desc) values3 ('⽂娱部','⽂艺熏陶'),4 ('体育部','强⾝健体'),5 ('⼩卖部','好吃好喝');67insert into emp(name,gender,age,emp_id) values8 ('jason','female',18,1),9 ('egon','male',90,2),10 ('tank','male',38,2),11 ('kevien','female',20,3),12 ('jerry','male',40,3);这样我们就把表都创建好了,并且表与表之间也建⽴了联系,但是问题也接踵⽽来,当我想修改emp⾥的dep_id或dep⾥⾯的id(修改成两张表都没有id)或者删除dep表⾥的记录时都会报错,如下图:解决⽅式有两种:⽅式1:先删除部门对应的所有的员⼯,在删除这个部门★⽅式2:先把之前创的表删除,先删除员⼯表,再删除部门表,最后按照下⾯的⽅式重新创建表关系更新与删除都需要考虑到关系与被关联的关系,也就是做到同步更新,同步删除1create table dep(2 id int primary key auto_increment,3 dep_name varchar(64),4 dep_desc varchar(64)5 );6 create table emp(7 id int primary key auto_increment,8 name varchar(16),9 gender enum('male','female','others')not null default 'male',10 age int,11 emp_id int,12 foreign key(emp_id) references dep(id)13 on update cascade14 on delete cascade15 );插⼊记录:1insert into dep(dep_name,dep_desc) values2 ('⽂娱部','⽂艺熏陶'),3 ('体育部','强⾝健体'),4 ('⼩卖部','好吃好喝');56insert into emp(name,gender,age,emp_id) values7 ('jason','female',18,1),8 ('egon','male',90,2),9 ('tank','male',38,2),10 ('kevien','female',20,3),11 ('jerry','male',40,3);删除部门后,对应的部门⾥⾯的员⼯表数据同步对应删除更新部门后,对应员⼯表中的标识部门的字段同步更新⼆、多对多例:图书表与作者表之间的关系我们仍然站在两张表的⾓度来分析:1.站在图书表:⼀本书可不可以有多个作者,可以的!那么就是书籍多对⼀了作者2.站在作者表:⼀个作者可不可以写多本书,也可以!那么就是作者多对⼀了书籍双⽅都能⼀条数据对应对⽅多条记录,这种关系就是多对多!那么我们应该如何创建表呢?图书表需要有⼀个外键关联作者,作者也需要有⼀个外键来关联书籍,然后问题来了,那我到底先创建谁呢?怎么解决这个问题呢?解决⽅案:创建第三张表,该表中应该有⼀个foreign key字段关联图书表中的id,还应该有⼀个foreign key字段来关联作者表中的id,这样这两张表就通过⼀个中间者,建⽴起了联系。

数据库之表与表之间的关系表1 foreign key 表2则表1的多条记录对应表2的⼀条记录,即多对⼀利⽤foreign key的原理我们可以制作两张表的多对多,⼀对⼀关系多对多:表1的多条记录可以对应表2的⼀条记录表2的多条记录也可以对应表1的⼀条记录⼀对⼀:表1的⼀条记录唯⼀对应表2的⼀条记录,反之亦然分析时,我们先从按照上⾯的基本原理去套,然后再翻译成真实的意义,就很好理解了1、先确⽴关系2、找到多的⼀⽅,吧关联字段写在多的⼀⽅⼀、多对⼀或者⼀对多(左边表的多条记录对应右边表的唯⼀⼀条记录)需要注意的:1.先建被关联的表,保证被关联表的字段必须唯⼀。
2.在创建关联表,关联字段⼀定保证是要有重复的。
其实上⼀篇博客已经举了⼀个多对⼀关系的⼩例⼦了,那我们在⽤另⼀个⼩例⼦来回顾⼀下。
这是⼀个书和出版社的⼀个例⼦,书要关联出版社(多个书可以是⼀个出版社,⼀个出版社也可以有好多书)。
谁关联谁就是谁要按照谁的标准。
书要关联出版社被关联的表create table press(id int primary key auto_increment,name char(20));关联的表create table book(book_id int primary key auto_increment,book_name varchar(20),book_price int,press_id int,constraint Fk_pressid_id foreign key(press_id) references press(id)on delete cascadeon update cascade);插记录insert into press(name) values('新华出版社'),('海燕出版社'),('摆渡出版社'),('⼤众出版社');insert into book(book_name,book_price,press_id) values('Python爬⾍',100,1),('Linux',80,1),('操作系统',70,2),('数学',50,2),('英语',103,3),('⽹页设计',22,3);运⾏结果截图:⼆、⼀对⼀例⼦⼀:⽤户和管理员(只有管理员才可以登录,⼀个管理员对应⼀个⽤户)管理员关联⽤户===========例⼦⼀:⽤户表和管理员表=========先建被关联的表create table user(id int primary key auto_increment, #主键⾃增name char(10));在建关联表create table admin(id int primary key auto_increment,user_id int unique,password varchar(16),foreign key(user_id) references user(id)on delete cascadeon update cascade);insert into user(name) values('susan1'),('susan2'),('susan3'),('susan4'),('susan5'),('susan6');insert into admin(user_id,password) values(4,'sds156'),(2,'531561'),(6,'f3swe');运⾏结果截图:例⼦⼆:学⽣表和客户表========例⼦⼆:学⽣表和客户表=========create table customer(id int primary key auto_increment,name varchar(10),qq int unique,phone int unique);create table student1(sid int primary key auto_increment,course char(20),class_time time,cid int unique,foreign key(cid) references customer(id)on delete cascadeon update cascade);insert into customer(name,qq,phone) values('⼩⼩',13564521,11111111),('嘻哈',14758254,22222222),('王维',44545522,33333333),('胡军',545875212,4444444),('李希',145578543,5555555),('李迪',754254653,8888888),('艾哈',74545145,8712547),('啧啧',11147752,7777777);insert into student1(course,class_time,cid) values('python','08:30:00',3),('python','08:30:00',4),('linux','08:30:00',1),('linux','08:30:00',7);运⾏结果截图:三、多对多(多条记录对应多条记录)书和作者(我们可以再创建⼀张表,⽤来存book和author两张表的关系)要把book_id和author_id设置成联合唯⼀联合唯⼀:unique(book_id,author_id)联合主键:alter table t1 add primary key(id,avg)多对多:⼀个作者可以写多本书,⼀本书也可以有多个作者,双向的⼀对多,即多对多 关联⽅式:foreign key+⼀张新的表========书和作者,另外在建⼀张表来存书和作者的关系#被关联的create table book1(id int primary key auto_increment,name varchar(10),price float(3,2));#========被关联的create table author(id int primary key auto_increment,name char(5));#========关联的create table author2book(id int primary key auto_increment,book_id int not null,author_id int not null,unique(book_id,author_id),foreign key(book_id) references book1(id)on delete cascadeon update cascade,foreign key(author_id) references author(id)on delete cascadeon update cascade);#========插⼊记录insert into book1(name,price) values('九阳神功',9.9),('葵花宝典',9.5),('辟邪剑谱',5),insert into author(name) values('egon'),('e1'),('e2'),('e3'),('e4'); insert into author2book(book_id,author_id) values(1,1),(1,4),(2,1),(2,5),(3,2),(3,3),(3,4),(4,5);多对多关系举例⽤户表,⽤户组,主机表-- ⽤户组create table user (id int primary key auto_increment,username varchar(20) not null,password varchar(50) not null);insert into user(username,password) values('egon','123'),('root',147),('alex',123),('haiyan',123),('yan',123);-- ⽤户组表create table usergroup(id int primary key auto_increment,groupname varchar(20) not null unique);insert into usergroup(groupname) values('IT'),('Sale'),('Finance'),('boss');-- 建⽴user和usergroup的关系表create table user2usergroup(id int not NULL UNIQUE au to_increment,user_id int not null,group_id int not NULL,PRIMARY KEY(user_id,group_id),foreign key(user_id) references user(id)ON DELETE CASCADEon UPDATE CASCADE ,foreign key(group_id) references usergroup(id)ON DELETE CASCADEon UPDATE CASCADE);insert into user2usergroup(user_id,group_id) values(1,1), (1,2),(1,3),(1,4),(2,4),(3,4);-- 主机表CREATE TABLE host(id int primary key auto_increment,ip CHAR(15) not NULL UNIQUE DEFAULT '127.0.0.1' );insert into host(ip) values('172.16.45.2'),('172.16.31.10'),('172.16.45.3'),('172.16.31.11'),('172.10.45.3'),('172.10.45.4'),('172.10.45.5'),('192.168.1.20'),('192.168.1.21'),('192.168.1.22'),('192.168.2.23'),('192.168.2.223'),('192.168.2.24'),('192.168.3.22'),('192.168.3.23'),('192.168.3.24');-- 业务线表create table business(id int primary key auto_increment,business varchar(20) not null unique);insert into business(business) values('轻松贷'),('随便花'),('⼤富翁'),('穷⼀⽣');-- 建⽴host和business关系表CREATE TABLE host2business(id int not null unique auto_increment,host_id int not null ,business_id int not NULL ,PRIMARY KEY(host_id,business_id),foreign key(host_id) references host(id),FOREIGN KEY(business_id) REFERENCES business(id));insert into host2business(host_id,business_id) values (1,1),(1,2),(1,3),(2,2),(2,3),(3,4);-- 建⽴user和host的关系create table user2host(id int not null unique auto_increment,user_id int not null,host_id int not null,primary key(user_id,host_id),foreign key(user_id) references user(id),foreign key(host_id) references host(id));insert into user2host(user_id,host_id) values(1,1), (1,2),(1,3),(1,4),(1,5),(1,6),(1,7),(1,8),(1,9),(1,10),(1,11),(1,12),(1,13),(1,14),(1,15),(1,16),(2,2),(2,3), (2,4), (2,5), (3,10), (3,11), (3,12);练习。

创建数据库和数据表实验总结创建数据库和数据表是数据库管理的基础工作之一,也是数据库设计的第一步。
通过创建数据库和数据表,可以存储和管理各种数据,为数据的操作提供基础支持。
本文将从创建数据库和数据表的目的、创建步骤、常见问题及解决方法等方面进行总结。
一、创建数据库的目的创建数据库是为了存储和管理数据,提供数据的持久化存储和高效访问。
数据库可以用于存储各种类型的数据,如文本、数字、图片、音频等,满足不同应用场景的数据存储需求。
通过创建数据库,可以实现数据的结构化存储、数据的一致性和完整性约束、数据的高效检索和查询等功能。
二、创建数据库的步骤1. 确定数据库管理系统(DBMS):根据实际需求选择合适的数据库管理系统,如MySQL、Oracle、SQL Server等。
不同的数据库管理系统有不同的特点和功能,需要根据具体需求选择合适的系统。
2. 安装数据库管理系统:根据选择的数据库管理系统,进行相应的安装和配置工作。
安装过程中需要填写一些基本信息,如数据库的名称、端口号、用户名和密码等。
安装完成后,就可以启动数据库服务。
3. 创建数据库:使用数据库管理系统提供的命令或可视化工具,创建数据库。
在创建数据库时,需要指定数据库的名称、字符集、校对规则等参数。
创建完成后,就可以在数据库管理系统中看到新创建的数据库。
4. 创建数据表:在创建数据库后,需要创建数据表来存储具体的数据。
数据表是数据库的基本组成单位,用于存储具有相同结构和属性的数据记录。
创建数据表时,需要指定表名、字段名、字段类型、约束条件等信息。
通过创建不同的数据表,可以满足不同的数据存储需求。
5. 设计数据表结构:在创建数据表时,需要设计表的结构,即确定表中的字段和字段的属性。
字段包括字段名、字段类型、字段长度、是否允许为空、默认值等属性。
通过合理的字段设计,可以满足数据的存储和查询需求。
6. 添加数据表约束:在创建数据表时,可以添加一些约束条件,来保证数据的完整性和一致性。
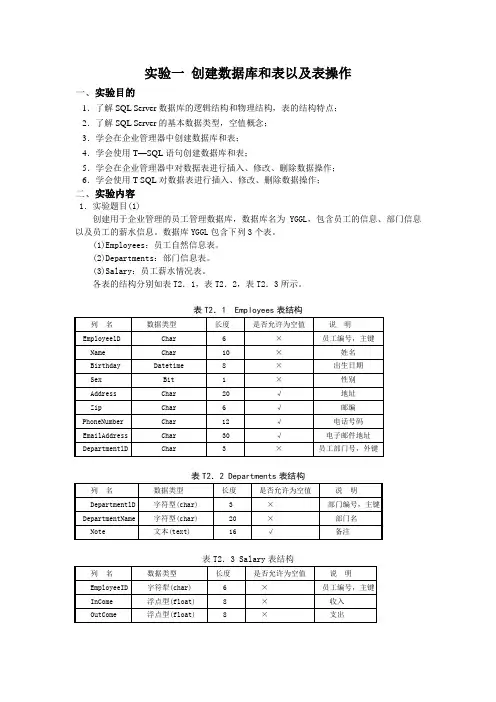
实验一创建数据库和表以及表操作一、实验目的1.了解SQL Server数据库的逻辑结构和物理结构,表的结构特点;2.了解SQL Server的基本数据类型,空值概念;3.学会在企业管理器中创建数据库和表;4.学会使用T—SQL语句创建数据库和表;5.学会在企业管理器中对数据表进行插入、修改、删除数据操作;6.学会使用T-SQL对数据表进行插入、修改、删除数据操作;二、实验内容1.实验题目(1)创建用于企业管理的员工管理数据库,数据库名为YGGL,包含员工的信息、部门信息以及员工的薪水信息。
数据库YGGL包含下列3个表。
(1)Employees:员工自然信息表。
(2)Departments:部门信息表。
(3)Salary:员工薪水情况表。
各表的结构分别如表T2.1,表T2.2,表T2.3所示。
表T2.1 Employees表结构表T2.2 Departments表结构实验步骤1.在企业管理器中创建数据库YGGL要求:数据库YGGL初始大小为10MB,最大大小为50MB,数据库自动增长,增长方式是按5%比例增长;日志文件初始为2MB,最大可增长到5MB(默认为不限制),按1MB增长(默认是按5%比例增长)。
数据库的逻辑文件名和物理文件名均采用默认值,分别为 YGGL_data 和e:\sql\data\MSSQL\Data\YGGL.mdf,其中e:\sql\data\MSSQL为SQL Server 的系统安装目录;事务日志的逻辑文件名和物理文件名也均采用默认值分别为YGGL—LOG 和 e:\sql\data\MSSQL\Data\YGGL_Log.1df。
以系统管理员Administrator是被授权使用CREATE DATABASE语句的用户登录SQL Server服务器,启动企业管理器一>在服务器上单击鼠标右键一>新建数据库一>输入数据库名“YGGL”一>选择“数据文件”选项卡一>设置增长方式和增长比例一>选择“事务口志”选项卡一设置增长方式和增长比例。

数据库和表的创建实验报告数据库和表的创建实验报告引言:数据库是现代信息系统中的重要组成部分,它可以存储、管理和检索大量的数据。
在数据库中,表是数据的基本单位,它由列和行组成,用于存储具有相同结构的数据。
本实验旨在通过使用SQL语言创建数据库和表,掌握数据库的基本操作。
实验步骤:1. 创建数据库:首先,我们需要使用SQL语句创建一个新的数据库。
在MySQL中,可以使用以下语句创建一个名为"mydb"的数据库:```sqlCREATE DATABASE mydb;```创建数据库后,可以使用以下语句选择要使用的数据库:```sqlUSE mydb;```2. 创建表:接下来,我们需要使用SQL语句创建一个新的表。
表的创建需要指定表的名称和各列的名称、数据类型和约束条件。
以下是一个示例创建名为"students"的表的语句:CREATE TABLE students (id INT PRIMARY KEY,name VARCHAR(50),age INT,gender VARCHAR(10));```上述语句创建了一个包含id、name、age和gender列的表。
其中,id列被定义为主键,保证了每个记录的唯一性。
name列和gender列被定义为VARCHAR类型,可以存储最大长度为50和10的字符串。
age列被定义为INT 类型,用于存储整数值。
3. 插入数据:创建表后,我们可以使用INSERT语句向表中插入数据。
以下是一个示例插入数据的语句:```sqlINSERT INTO students (id, name, age, gender)VALUES (1, 'Alice', 20, 'Female'),(2, 'Bob', 21, 'Male'),(3, 'Charlie', 19, 'Male');```上述语句将三条记录插入到students表中。

数据库字符集编码和表字符集编码数据库字符集编码和表字符集编码是数据库中非常重要的概念,它们决定了数据库中存储的数据的字符编码方式。
正确设置字符集编码可以确保数据的正确存储和显示,避免出现乱码等问题。
数据库字符集编码是指数据库服务器使用的字符编码方式,它决定了数据库中所有表的默认字符集编码。
常见的数据库字符集编码有UTF-8、GBK、GB2312等。
UTF-8是一种通用的字符编码方式,支持全球范围内的字符,是目前最常用的字符集编码方式。
GBK和GB2312是中文字符集编码方式,适用于中文环境。
表字符集编码是指每个表在数据库中的字符编码方式,它可以与数据库字符集编码不同。
在创建表时,可以指定表的字符集编码,也可以使用数据库的默认字符集编码。
如果表的字符集编码与数据库的字符集编码不一致,那么在存储和显示数据时就需要进行字符集转换,这可能会导致性能下降和数据损坏。
正确设置数据库字符集编码和表字符集编码非常重要。
首先,它可以确保数据的正确存储和显示。
如果数据库字符集编码和表字符集编码不一致,那么在存储和显示数据时就可能出现乱码等问题,影响用户体验。
其次,它可以提高数据库的性能。
如果数据库字符集编码和表字符集编码一致,那么在存储和显示数据时就不需要进行字符集转换,可以提高数据库的性能。
在设置数据库字符集编码和表字符集编码时,需要考虑以下几个因素。
首先,需要考虑数据库的使用环境。
如果数据库主要用于存储中文数据,那么可以选择中文字符集编码,如GBK或GB2312。
如果数据库需要支持全球范围内的字符,那么可以选择UTF-8字符集编码。
其次,需要考虑数据库的性能和存储空间。
不同的字符集编码对存储空间的占用和性能有不同的影响。
一般来说,UTF-8字符集编码占用的存储空间较大,但支持更多的字符,而GBK和GB2312字符集编码占用的存储空间较小,但只支持中文字符。
最后,需要考虑与其他系统的兼容性。
如果数据库需要与其他系统进行数据交换,那么需要确保数据库字符集编码和表字符集编码与其他系统兼容。

数据库与表实验报告数据库与表实验报告一、引言数据库是现代信息系统中的重要组成部分,它承载着大量的数据,并提供了高效的数据管理和查询功能。
而表作为数据库中的一种数据结构,用于存储和组织数据。
本实验旨在通过实际操作,探索数据库和表的基本概念、功能和使用方法。
二、实验目的1. 理解数据库的概念和作用;2. 掌握数据库的基本操作方法;3. 熟悉表的创建、插入、查询和删除等操作;4. 实践数据库和表的应用场景。
三、实验过程1. 数据库的创建和连接在实验环境中,我们首先创建了一个名为"mydatabase"的数据库,并成功连接到该数据库。
通过数据库连接,我们可以进行后续的操作。
2. 表的创建接下来,我们创建了一个名为"students"的表,用于存储学生的信息。
表中包含了学生的学号、姓名、性别和年龄等字段。
通过定义表的字段和数据类型,我们可以规定表中数据的结构。
3. 数据的插入为了模拟真实场景,我们手动插入了几条学生信息的数据记录。
通过插入数据,我们可以将具体的信息存储到表中,以便后续的查询和分析。
4. 数据的查询为了验证数据的插入是否成功,我们进行了一些简单的查询操作。
通过使用SQL语句,我们可以从表中检索出满足条件的数据记录。
例如,我们可以查询出所有性别为女性的学生,或者按照年龄进行升序排序。
5. 数据的删除在实验的最后,我们删除了一个学生的信息记录。
通过删除数据,我们可以对表中的数据进行动态管理,以确保数据的准确性和完整性。
四、实验结果通过本次实验,我们成功创建了数据库和表,并进行了数据的插入、查询和删除操作。
在查询中,我们得到了符合条件的数据记录,并进行了排序和筛选。
在删除中,我们成功删除了指定的数据记录。
这些操作都展示了数据库和表的基本功能和灵活性。
五、实验总结本次实验使我们更加深入地理解了数据库和表的概念、功能和使用方法。
通过实际操作,我们掌握了数据库的创建和连接,以及表的创建、插入、查询和删除等操作。
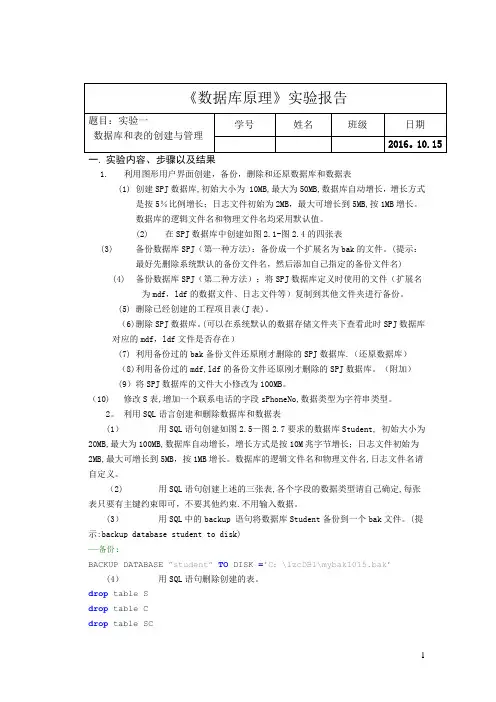
一.实验内容、步骤以及结果1.利用图形用户界面创建,备份,删除和还原数据库和数据表(1)创建SPJ数据库,初始大小为 10MB,最大为50MB,数据库自动增长,增长方式是按5%比例增长;日志文件初始为2MB,最大可增长到5MB,按1MB增长。
数据库的逻辑文件名和物理文件名均采用默认值。
(2)在SPJ数据库中创建如图2.1-图2.4的四张表(3)备份数据库SPJ(第一种方法):备份成一个扩展名为bak的文件。
(提示:最好先删除系统默认的备份文件名,然后添加自己指定的备份文件名)(4)备份数据库SPJ(第二种方法):将SPJ数据库定义时使用的文件(扩展名为mdf,ldf的数据文件、日志文件等)复制到其他文件夹进行备份。
(5) 删除已经创建的工程项目表(J表)。
(6) 删除SPJ数据库。
(可以在系统默认的数据存储文件夹下查看此时SPJ数据库对应的mdf,ldf文件是否存在)(7) 利用备份过的bak备份文件还原刚才删除的SPJ数据库.(还原数据库)(8) 利用备份过的mdf,ldf的备份文件还原刚才删除的SPJ数据库。
(附加)(9)将SPJ数据库的文件大小修改为100MB。
(10) 修改S表,增加一个联系电话的字段sPhoneNo,数据类型为字符串类型。
2。
利用SQL语言创建和删除数据库和数据表(1)用SQL语句创建如图2.5—图2.7要求的数据库Student, 初始大小为20MB,最大为100MB,数据库自动增长,增长方式是按10M兆字节增长;日志文件初始为2MB,最大可增长到5MB,按1MB增长。
数据库的逻辑文件名和物理文件名,日志文件名请自定义。
(2) 用SQL语句创建上述的三张表,各个字段的数据类型请自己确定,每张表只要有主键约束即可,不要其他约束.不用输入数据。
(3)用SQL中的backup 语句将数据库Student备份到一个bak文件。
(提示:backup database student to disk)——备份:BACKUP DATABASE ”student”TO DISK ='C:\lzcDB1\mybak1015.bak’(4)用SQL语句删除创建的表。
数据库和表之间的关系数据库:数据库即数据的仓库。
在数据库中提供了专门的管理系统。
对数据库中的数据进⾏集中的控制和管理。
能⾼效的对数据库进⾏存储、检索。
关系型数据库:关系模型把世界看作是由实体(Entity)和联系(Relationship)组成的。
关系模型数据库是⼀种以表做为实体,以主键和外键关系作为联系的⼀种数据库结构。
在关系数据库中,相类似的实体被存⼊表中。
表(table)是关系型数据库的核⼼单元,它是数据存储的地⽅。
关系数据库管理系统:关系型数据库只是⼀个保存数据的容器,⼤多数数据库依靠⼀个称为数据库管理系统(DatabaseManagement System,简称DBMS)的软件来管理数据库中数据。
数据库管理系统的分类:本地数据库管理系统数据库服务器管理系统。
⼀对⼀关系:关系模型:⼀条主表记录对应⼀条从表记录。
同时⼀条从表记录对应⼀条主表记录对象模型:⼀个类包含另⼀个类的对象,⽽另⼀个类包含该类的对象Class Man private Code code class Code provate private Man man公民表公民编号姓名⽣⽇1Xx Xxxx-xx-xx⾝份表公民编号⾝份证号1Xxxxxxx⼀对⼀关系是⽐较少见的关系类型。
很多数据库也很少包含⼀对⼀关系主键:这就是主键:主键是唯⼀标识⼀条记录,不能有重复的,不允许为空。
特点:主键的两个特点不可以重复、不能为空。
外键:在关系型数据库中,外建(ForergnKey)是⽤来表达表和表之间关联关系的列。
这就是外键:表的外键是另⼀表的主键,外键可以有重复的,可以是空值⼀对多关系:关系模型:⼀条主表记录对应多条从表记录。
同时⼀条从表记录对应⼀条主表记录对象模型:⼀个类包含另⼀个类的集合,⽽另⼀个类包含该类的对象Class Man{ private List<Room> roomlist; class Room{ private Man man,公民表公民编号姓名⽣⽇1房间表房间编号房间地址公民编号11我们通常把⼀对多关系中,” 多边”的表称为从表,把”⼀边”的表称为主表。
实验内容一
实验序号:一实验项目名称:数据库表和表间关系的建立
2、数据库中建立6个表后,指定其主外键关系如下图所示:
①课程信息表_学生选课表关系
②使用SQL脚本建立教学任务表1
④使用SQL脚本建立学生选课表1
⑥使用SQL脚本建立学生档案表1
五、分析与讨论
通过本次实验,初步掌握了数据库的建立,在数据库中建立基本表以及建立基本表间的关系,不过,在建立基本表间的关系是,要特别注意哪个表为主键表,哪个为外键表,同时还要注意,两个表间的联系字段的数据类型一定要相同,并且字段大小也要一样,弄清楚这些关系后,就可以很容易建立表间关系。
数据库(数据库、表及表数据、SQL语句)数据库MYSQL今⽇内容介绍u MySQL数据库u SQL语句第1章数据库1.1 数据库概述l 什么是数据库数据库就是存储数据的仓库,其本质是⼀个⽂件系统,数据按照特定的格式将数据存储起来,⽤户可以对数据库中的数据进⾏增加,修改,删除及查询操作。
l 什么是数据库管理系统数据库管理系统(DataBase Management System,DBMS):指⼀种操作和管理数据库的⼤型软件,⽤于建⽴、使⽤和维护数据库,对数据库进⾏统⼀管理和控制,以保证数据库的安全性和完整性。
⽤户通过数据库管理系统访问数据库中表内的数据。
l 常见的数据库管理系统MYSQL :开源免费的数据库,⼩型的数据库.已经被Oracle收购了.MySQL6.x版本也开始收费。
Oracle :收费的⼤型数据库,Oracle公司的产品。
Oracle收购SUN公司,收购MYSQL。
DB2 :IBM公司的数据库产品,收费的。
常应⽤在银⾏系统中.SQLServer:MicroSoft 公司收费的中型的数据库。
C#、.net等语⾔常使⽤。
SyBase :已经淡出历史舞台。
提供了⼀个⾮常专业数据建模的⼯具PowerDesigner。
SQLite : 嵌⼊式的⼩型数据库,应⽤在⼿机端。
Java相关的数据库:MYSQL,Oracle.这⾥使⽤MySQL数据库。
MySQL中可以有多个数据库,数据库是真正存储数据的地⽅。
l 数据库与数据库管理系统的关系1.2 数据库表数据库中以表为组织单位存储数据。
表类似我们的Java类,每个字段都有对应的数据类型。
那么⽤我们熟悉的java程序来与关系型数据对⽐,就会发现以下对应关系。
类----------表类中属性----------表中字段对象----------记录1.3 表数据根据表字段所规定的数据类型,我们可以向其中填⼊⼀条条的数据,⽽表中的每条数据类似类的实例对象。
表中的⼀⾏⼀⾏的信息我们称之为记录。
数据库表与表之间的关系
表与表之间的关系有三种:⼀对⼀、⼀对多、多对多
1. ⼀对⼀
⼀张表的⼀条记录⼀定只能与另外⼀张表的⼀条记录进⾏对应;反之亦然。
⼀个常⽤表中的⼀条记录,永远只能在⼀张不常⽤表中匹配⼀条记录;反过来,⼀个不常⽤表中的⼀条记录在常⽤表中也只能匹配⼀条记录:⼀对⼀关系。
在实际的开发中应⽤不多,因为⼀对⼀可以创建成⼀张表。
建表原则:
外键唯⼀:主表的主键和从表的外键(唯⼀),形成主外键关系,外键唯⼀。
外键是主键:主表的主键和从表的外键,形成主外键关系。
2. ⼀对多
⼀张表中有⼀条记录可以对应另外⼀张表中的多条记录;但是反过来,另外⼀张表的⼀条记录只能对应第⼀张表的⼀条记录。
建表原则:
在“多”的⼀⽅创建⼀个字段,字段作为外键指向“⼀”的⼀⽅的主键。
3. 多对多
第⼀张表中的⼀条记录能够对应第⼆张表中的多条记录;同时第⼆张表中的⼀条记录也能对应第⼀张表中的多条记录。
中间表与⽼师表形成⼀对多的关系,⽽且中间表是“多”的⼀⽅,维护了能够唯⼀找到“⼀”表的关系;同样的,学⽣表与中间表也形成了⼀对多的关系。
⽼师找学⽣:⽼师表-中间表-学⽣表
学⽣赵⽼师:学⽣表-中间表-⽼师表
建表原则:
创建第三张表,中间表⾄少两个字段,分别作为外键指向各⾃⼀⽅的主键。
实训一数据库和表的创建实训目的(1) 掌握数据库和表的基础知识。
(2) 掌握使用企业管理器和Transact-SQL语句创建数据库和表的方法。
(3) 掌握数据库和表的修改、查看、删除等基本操作方法。
实训内容和要求1 •数据库的创建、查看、修改和删除(1) 使用企业管理器创建数据库创建成绩管理数据库Grademanager,要求见表10-1。
(2)①在企业管理器中查看创建后的gradema nager数据库,查看gradema nager_data.md仁grademanager_log」df两个数据库文件所处的文件夹。
②使用企业管理器更改数据库。
更改的参数见表10-2。
(3)(4) 使用Transact-SQL命令创建上述要求的数据库(5) 使用Transact-SQL命令查看和修改上述要求的数据库⑹使用Transact-SQL命令删除该数据库2.表的创建、查看、修改和删除(1) 在Grademanager数据库中创建如表10-3、表10-4和表10- 5所示结构的表。
文档来源为:从网络收集整理.word版本可编辑•欢迎下载支持表10-3 Student表的表结构⑵向表10-3、表10-4和表10-5输入数据记录,见表10-6、表10-7和表10-8。
表10-6 学生关系表Student①向student表中增加“入学时间”列,其数据类型为日期时间型。
②将student表中的sdept字段长度改为20。
③将student表中的Speciality字段删除。
(4) 删除student 表。
思考题(1) SQL Server的数据库文件有几种?扩展名分别是什么?(2) SQL Server 2000中有哪几种整型数据类型?它们占用的存储空间分别是多少?取值范围分别是什么?(3) 在定义基本表语句时,NOT NULL参数的作用是什么?⑷主码可以建立在“值可以为NULL ”的列上吗?实训二单表查询实训目的(1) 掌握SELECT语句的基本用法。