第4章 描述性统计
- 格式:ppt
- 大小:1.53 MB
- 文档页数:41


第四章数据的描述性分析1要求(1)计算零件的众数、中位数和均值;(2)说明该数列的分布特征。
2.某公司所属三个企业生产同种产品,2002年实际产量、计划完成3(2)由于质量变化而给该企业带来的收益(或损失)。
4试计算比较两个菜场价格的高低,并说明理由。
5.根据上述资料计算平均成绩、标准差及标准差系数。
6.根据下表资料,试用动差法计算偏度系数和峰度系数,并说明其偏斜7、计算5、13、17、29、80和150这一组数据的算术均值、调和均值和几何均值,并比较它们之间的大小。
8、根据2005年江苏省52个县市人均地区生产总值,进行如下计算:(1)计算江苏省52个县市的平均人均地区生产总值是多少元?1分A:20725 B:18674 C:15721 D:19711E:85124(2)计算江苏省52个县市人均地区生产总值的标准差是多少?1分A:36023 B:11969 C:9837 D:5632E:21773(3)江苏省52个县市人均地区生产总值的中位数是多少?1分A:6923 B:4292 C:13119 D:5798E:14992(4)江苏省52个县市人均地区生产总值的偏态系数是多少? 1分A:0.55 B:-1.23 C:2.56 D:2.48 E:-0.10(5)江苏省52个县市人均地区生产总值的峰度系数是多少? 1分A:8.92 B:-5.28 C:2.02 D:6.57 E:-0.54(6)计算江苏省52个县市人均地区生产总值的全距是多少?1分A:10964 B:108647 C:108586 D:32948E:25124(7)根据斯透奇斯规则对52个县市数据进行分组,组数是多少?1分A:9 B:5 C:7 D: 6E:8(8)若采用等距数列,根据组数和全距的关系,确定组距是多少?1分A:18500 B:16300 C:29400 D:17000 E:23200(9)人均地区生产总值在20600~36900元之间的县市个数是多少? 1分A:35 B:8 C:5 D: 6E:20(10)人均地区生产总值大于20600元的县市个数占全部县市比例是? 1分A:32.7% B:20.2% C:25.0% D:15.6% E: 28.8%第五章指数要求计算:(1)三种商品的个体价格指数(即价比);(2)拉氏、派氏价格指数(3)拉氏、派氏销售量指数(4)用马艾公式计算价格指数(5)用理想公式计算价格指数2.某商店三种商品的销售量与销售额资料如下:计算三种商品销售量总指数和由于销售量变动对销售额的影响额。




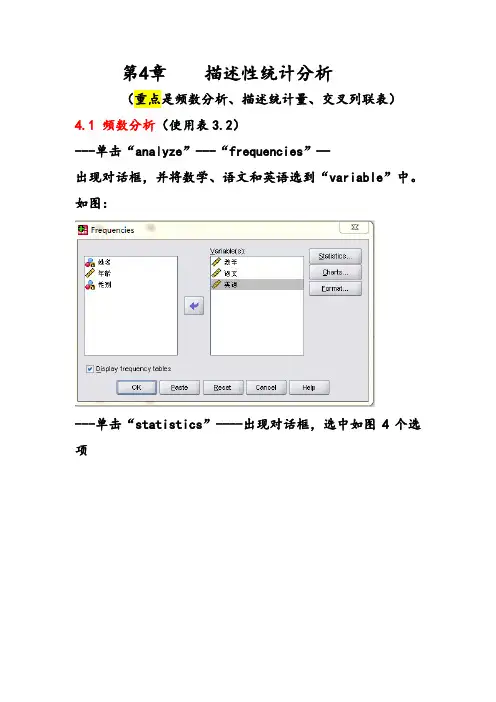
第4章描述性统计分析(重点是频数分析、描述统计量、交叉列联表)4.1 频数分析(使用表3.2)---单击“analyze”---“frequencies”—出现对话框,并将数学、语文和英语选到“variable”中。
如图:---单击“statistics”----出现对话框,选中如图4个选项-----单击“continue”回到前一对话框----单击“OK”结果如表4.1-----如图,重新选择语文---单击“charts”---得到一个对话框,如图选中2个选项----单击“continue”----回到前一对话框---单击“OK”。
结果如表4.24.2 基本描述统计量(使用表3.2)---单击“analyze”---“descriptive statistics”—“Descriptives”---得到对话框,并将数据进行如图选入:-----单击“options”—得到对话框,并选中如图6个选项:----单击“continue”----回到前一对话框---单击“OK”。
结果如表4.34.3 探索性分析(使用表3.2)---单击“analyze”---“descriptive statistics”—“Explore”---得到对话框,并将数据进行如图选入:----单击“Plots”—得到对话框,并选中如图4个选项:----单击“continue”----回到前一对话框---单击“OK”。
结果如表4.6(与书有不同)4.4交叉列联表分析(使用表化环0708)(1)T ransform(修改)----Recode into Different variable----选定身高------点击“向右箭头”------在“name”下写个名字:eg:T1-------change-------(此处T1和T2是已经做好的分组)点击-----old and new values对其分组---例:Range LOWEST through values :160 new values :1Rang :160 through :170 2Range HIGHEST through values :170 3 点击continue-----回到前一个对话框点击------OK同样的方法做好T2---------点击“analyze(分析)”-----“Descriptive Statistics(描述性统计)”------“Crosstabs(交叉列联表)”选中行列------点击“Exat….“则弹出“exct tests(精确检测)对话框”点“Statistics…”则弹出“Crosstabs:statistics(交叉表统计)对话框”-------点击“Chi—square(卡方检验)”----“continue”点“Cells…”则弹出“Crosstabs:Cells display(交叉表统计)对话框”-------选择“Counts”中的“Observed”和“Expected”为期望频数,-------选择“Percentages”中的“Row”“Column”“Total”选项,分别计算“频数”“列频数”“总频数”-------选择“Residuals”中的“Standardized”分别计算单元格的非标准化残差、标准化残差、调整后的残差----“continue”回到前一页点----“OK”4.5比率分析(课本71页)不需要掌握英语未写完作业:1-10,11-25,26-30。




如何使用Stata进行统计分析和数据管理第一章:Stata软件介绍Stata是一款功能强大的统计分析和数据管理软件,被广泛应用于学术研究、商业分析和政府决策等领域。
它提供了丰富的统计分析工具和数据操作功能,可以帮助用户进行各种数据处理、可视化和模型建立等工作。
第二章:数据导入和管理在使用Stata进行统计分析之前,首先需要将数据导入到软件中进行管理。
Stata支持多种数据格式的导入,比如Excel、CSV、SPSS等。
用户可以使用import命令将外部数据导入到Stata的数据集中,并可以使用rename、label等命令对数据集进行重命名和备注,提高数据管理的效率和准确性。
第三章:数据清洗和变量转换在进行统计分析之前,常常需要对原始数据进行清洗和变量转换。
Stata提供了丰富的数据清洗命令,如drop、replace、gen等,可以帮助用户处理缺失值、异常值和重复观测等问题。
同时,Stata还支持对变量进行变换,如计算新变量、重编码变量和生成虚拟变量等,以满足不同的分析需求。
第四章:描述性统计分析描述性统计是了解数据特征和总体情况的基本手段,Stata提供了多种描述性统计命令,如mean、median、sum、tab等。
这些命令可以计算数据的均值、中位数、总和、频数等统计量,并可以按照变量和组别进行分析,帮助用户发现数据的分布、集中趋势和离散程度等信息。
第五章:推断性统计分析推断性统计分析是基于样本数据对总体进行推断的方法,Stata 提供了丰富的推断性统计命令,如ttest、regress、anova等。
这些命令可以进行单样本和双样本假设检验、回归分析、方差分析等统计计算,从而帮助用户验证研究假设、探究变量之间的关系和差异。
第六章:多元统计分析多元统计分析是研究多个变量之间的关系和模式的方法,Stata 提供了多种多元统计分析命令,如因子分析、聚类分析和多元回归等。
用户可以使用这些命令对数据进行降维、分类、预测和解释,挖掘变量之间的潜在结构和相互作用关系,为研究提供更深入的认识和解释。
目录第四章统计描述 (2)4。
2 频数分析 (2)4.3描述性统计量 (2)4.4。
1(探索性数据分析)操作步骤 (4)第五章统计推断 (6)5.2单样本t检验 (6)5.3 两独立样本t检验 (7)5。
4 配对样本t检验 (8)第六章方差分析 (9)6.2.2 单因素单变量方差分析(One-way ANOVA)(操作步骤) (10)6。
3.3 多因素单变量方差分析操作步骤 (14)6.3。
5 不考虑交互效应的多因素方差分析 (17)6。
3。
6 引入协变量的多因素方差分析 (18)第八章相关分析 (19)8.2 连续变量相关分析实例 (20)8.3 离散变量相关分析的实例(列联表) (22)第九章回归分析 (24)9.1.3 线性回归(操作步骤) (26)1.多重共线性检验 (26)2。
使用变量筛选的方法克服多重共线性 (29)二、曲线估计(操作步骤) (32)9.2.5二项Logistic回归(操作步骤) (35)第十章聚类分析 (39)10。
3.1 K-均值操作步骤: (39)10。
4。
1 系统聚类法操作步骤 (43)第十一章判别分析 (47)11.3。
1 操作步骤 (48)第十二章因子分析 (53)12.2.2操作步骤 (56)第十三章主成分分析 (64)13。
2 操作步骤 (65)第十四章相应分析 (69)14。
2相应分析实例(操作步骤) (70)第十五章典型相关分析 (75)15。
2操作步骤: (75)第四章统计描述统计描述是指如何搜集、整理、分析、研究并提供统计资料的理论和方法,用于说明总体的情况和特征。
4.1 基本概念和原理4。
1.1 频数分布4。
1。
2 集中趋势指标算数平均值:适用于定比数据、定距数据中位数:适用于定比数据、定距数据和定序数据众数:适用于定比数据、定距数据、定序数据和定类数据4.1.3离散程度指标作用:(1)它可以表明现象的平衡程度和稳定程度;(2)离散性指标可以表明平均指标的代表性,数据离散程度越大,则该分布的平均指标的代表性就越小。