matlab多元非线性回归教程
- 格式:doc
- 大小:235.50 KB
- 文档页数:22

基于MAT LAB 的多元非线性回归模型3董大校(临沧师范高等专科学校,云南临沧6770000)摘 要: MAT LAB 是源于矩阵运算的一种高度集成的计算机语言。
它提供了强大的科学运算、灵活的程序设计流程、高质量的图形可视化与界面设计、便捷的与其他程序和语言接口的功能。
文章充分利用MAT LAB 统计工具箱的优势,通过程序的实现,对多元非线性回归模型的未知参数的估计方法以及对估计后的模型预报做出研究,并以实例验证了该方法的有效性。
关键词: MAT LAB;多元非线性回归;最小二乘法;统计工具箱中图分类号:TP301 文献标识码: A 文章编号: 1007-9793(2009)02-0045-041 预备知识非线性回归最小二乘法拟合的基本原理[1]。
对给定数据(x i ,y i )(i =0,1,…,m ),在取定的函数类Φ中,求p (x )∈Φ,使误差r i =p (x )-y i (i=0,1,…,m )的平方和最小,即∑m i =1r2i =∑m i =0[p (x i )-y i ]2最小,从几何意义上讲,就是寻求与给定点(x i ,y i )(i =0,1,…,m )的距离平方和为最小的曲线y =p (x )(图1)。
函数p (x )称为拟合函数或最小二乘解,求拟合函数p (x )的方法称为曲线拟合的最小二乘法。
2 MAT LAB 非线性曲线拟合命令介绍211nlinfit 函数[2]用nlinfit 函数进行非线性最小二乘数据拟合。
该函数使用高斯—牛顿算法,调用格式如下:●beta =nlinfit (X,y,fun,beta0) 用最小二乘法估计非线性函数系数。
y 为响应值(因变量)矢量。
一般地,为自变量值组成的设计矩阵,每一行对应与y 中的一发个值。
但是,X 可以是fun 参数能接受的任何数组。
fun 参数为一函数,该函数具有下面的形式yhat =myfun (beta,X )其中beta 为系数矢量,X 为设计矩阵。
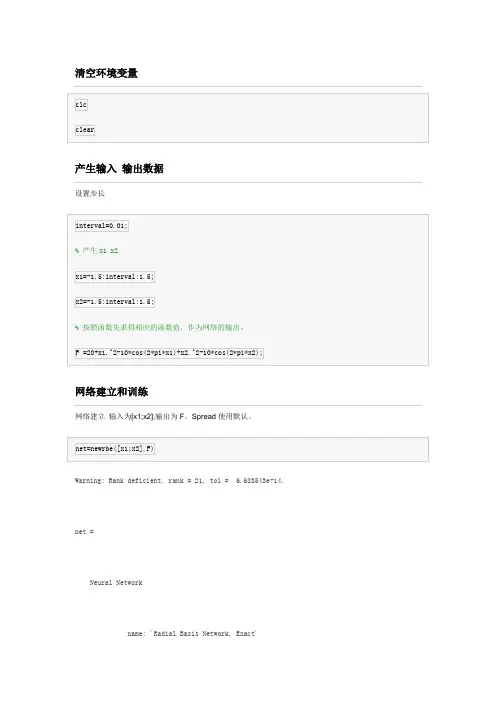
清空环境变量产生输入输出数据设置步长网络建立和训练网络建立输入为[x1;x2],输出为F。
Spread使用默认。
Warning: Rank deficient, rank = 21, tol = 6.683543e-14. net =Neural Networkname: 'Radial Basis Network, Exact'efficiency: .cacheDelayedInputs, .flattenTime, .memoryReductionuserdata: (your custom info)dimensions:numInputs: 1numLayers: 2numOutputs: 1numInputDelays: 0numLayerDelays: 0numFeedbackDelays: 0numWeightElements: 1205sampleTime: 1connections:biasConnect: [1; 1]inputConnect: [1; 0]layerConnect: [0 0; 1 0]outputConnect: [0 1]subobjects:inputs: {1x1 cell array of 1 input}layers: {2x1 cell array of 2 layers}outputs: {1x2 cell array of 1 output}biases: {2x1 cell array of 2 biases}inputWeights: {2x1 cell array of 1 weight}layerWeights: {2x2 cell array of 1 weight}functions:adaptFcn: (none)adaptParam: (none)derivFcn: 'defaultderiv'divideFcn: (none)divideParam: (none)divideMode: 'sample'initFcn: 'initlay'performFcn: 'mse'performParam: .regularization, .normalization plotFcns: {}plotParams: {1x0 cell array of 0 params}trainFcn: (none)trainParam: (none)weight and bias values:IW: {2x1 cell} containing 1 input weight matrix LW: {2x2 cell} containing 1 layer weight matrix b: {2x1 cell} containing 2 bias vectorsmethods:adapt: Learn while in continuous useconfigure: Configure inputs & outputsgensim: Generate Simulink modelinit: Initialize weights & biasesperform: Calculate performancesim: Evaluate network outputs given inputstrain: Train network with examplesview: View diagramunconfigure: Unconfigure inputs & outputs网络的效果验证。
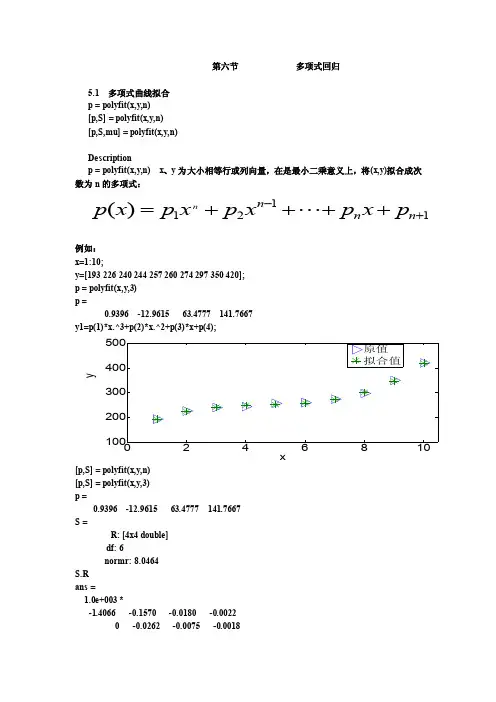
第六节 多项式回归5.1 多项式曲线拟合 p = polyfit(x,y,n) [p,S] = polyfit(x,y,n) [p,S,mu] = polyfit(x,y,n)Descriptionp = polyfit(x,y,n) x 、y 为大小相等行或列向量,在是最小二乘意义上,将(x,y)拟合成次数为n 的多项式:1121)(+-++++=n n n p x p x p x p x p n例如: x=1:10;y=[193 226 240 244 257 260 274 297 350 420]; p = polyfit(x,y,3) p =0.9396 -12.9615 63.4777 141.7667y1=p(1)*x.^3+p(2)*x.^2+p(3)*x+p(4);xy[p,S] = polyfit(x,y,n) [p,S] = polyfit(x,y,3) p =0.9396 -12.9615 63.4777 141.7667 S =R: [4x4 double] df: 6normr: 8.0464 S.R ans =1.0e+003 *-1.4066 -0.1570 -0.0180 -0.0022 0 -0.0262 -0.0075 -0.00180 0 -0.0019 -0.00140 0 0 0.0005normr是残差的模,即:norm(y-y1)ans =8.0464[p,S,MU] = polyfit(x,y,n)[p,S,MU] = polyfit(x,y,3)p =26.0768 23.2986 18.6757 255.1312S =R: [4x4 double]df: 6normr: 8.0464MU =5.50003.0277MU是x均值和x的标准差即std(x)S.Rans =5.1959 0.0000 2.7682 0.00000 -3.7926 -0.0000 -2.37310 0 1.1562 0.00000 0 0 -2.0901P它等于:[p,S] = polyfit((x-mean(x))./std(x),y,3)p =26.0768 23.2986 18.6757 255.1312S =R: [4x4 double]df: 6normr: 8.0464>> S.Rans =5.1959 0.0000 2.7682 0.00000 -3.7926 -0.0000 -2.37310 0 1.1562 0.00000 0 0 -2.09015.2 多项式估计y= polyval(p,x)[y,DELT A] = polyval(p,x,S)y= polyval(p,x) 返回给定系数p和变量x值的多项式的预测y = P(1)*x^N + P(2)*x^(N-1) + ... + P(N)*x + P(N+1)x=1:10;y= polyval([3 2],x)y =5 8 11 14 17 20 23 26 29 32[3 2]有两个数,因此为一次多项式,即y=3x+2如:x=1:10;y=[193 226 240 244 257 260 274 297 350 420];p=polyfit(x,3)y1= polyval(p,x)norm(y-y1)ans =8.0464如果是矩阵,则polyval(p,x)为对应x的每一个预测值。

matlab多元非线性回归及显著性分析给各位高手:小弟有一些数据需要回归分析(非线性)及显著性检验(回归模型,次要项,误差及失拟项纯误差,F值和P值),求大侠帮助,给出程序,不胜感激。
模型:DA TA=... %DA TA前三列是影响因子,第四列为响应值[2 130 75 48.61;2 110 75 56.43;2 130 45 61.32;2 110 45 65.28;1 110 45 55.80;1 130 75 45.65;1 110 75 50.91;1 130 45 67.94;1.5 120 60 74.15;1.5 120 60 71.28;1.5 120 60 77.95;1.5 120 60 74.16;1.5 120 60 75.20;1.5 120 85 35.65;1.5 140 60 48.66;1.5 120 30 74.10;1.5 100 60 62.30;0.5 120 60 66.00;2.5 120 60 75.10];回归分析过程:(1)MA TLAB编程步骤1:首先为非线性回归函数编程,程序存盘为user_function.m function y=user_function(beta,x)b0 = beta(1);b1 = beta(2);b2 = beta(3);b3 = beta(4);x0 = x(:,1);x1 = x(:,2);x2 = x(:,3);x3 = x(:,4);y=b0*x0+b1*x1.^2+b2*x2.^2+b3*x3.^2;(2)MA TLAB编程步骤2:编写非线性回归主程序,程序运行时调用函数user_functionx=[1 2 130 75 48.61;1 2 110 75 56.43;1 2 130 45 61.32;1 2 110 45 65.28;1 1 110 45 55.80;1 1 130 75 45.65;1 1 110 75 50.91;1 1 130 45 67.94;1 1.5 120 60 74.15;1 1.5 120 60 71.28;1 1.5 120 60 77.95;1 1.5 120 60 74.16;1 1.5 120 60 75.20;1 1.5 120 85 35.65;1 1.5 140 60 48.66;1 1.5 120 30 74.10;1 1.5 100 60 62.30;1 0.5 120 60 66.00;1 2.5 120 60 75.10]; %%第1列全是1,第6列是指标变量,其余列是自变量xx=x(:,1:5);yy=x(:,5); %%指定响应变量yy和自变量xxbeta0=[0.5 0.4 0.7 0.5]; %%设置初始回归系数(如何确定初值?)[beta_fit,residual] = nlinfit(xx,yy,@user_function,beta0) %%非线性回归结果beta_fit =91.37571.2712-0.0009-0.0049residual =-4.2935-1.0248-9.2044-9.7957-15.4620-3.4398-2.73111.229311.18898.318914.988911.198912.2389-9.5678-9.3704-2.0767-4.83315.58147.0540即y=.3757+1.2712*x1.^2-0.0009*x2.^2-0.0049*x3.^2;。

应用MATLAB进行非线性回归分析非线性回归分析是一种用于建立非线性函数与自变量之间的关系的统计方法。
与线性回归不同,非线性回归假设因变量与自变量之间的关系是一个非线性函数,通常是指数型、对数型、幂函数等。
MATLAB是一种强大的科学计算软件,提供了丰富的函数和工具箱,可以用于进行非线性回归分析。
下面将介绍如何在MATLAB中进行非线性回归分析的步骤。
1.数据准备首先,需要准备用于非线性回归分析的数据。
数据应包括自变量和因变量的观测值。
可以将数据保存在一个MATLAB数据文件中,或使用MATLAB中的数组或矩阵来表示。
2.建立模型根据实际情况,选择适当的非线性函数模型来描述自变量和因变量之间的关系。
例如,可以使用指数函数模型y = a * exp(b * x)、对数函数模型y = a * log(b * x)、幂函数模型y = a * x^b等。
3.拟合模型并求解参数使用MATLAB中的非线性最小二乘法函数(如lsqcurvefit)拟合模型,并求解模型中的参数。
这些函数需要提供待拟合的非线性模型、观测数据和初始参数值。
例如,可以使用以下代码进行非线性最小二乘拟合:```MATLABx=[1,2,3,4,5];%自变量观测值y=[2,3,5,7,9];%因变量观测值p0=[1,1];%初始参数值p = lsqcurvefit(model, p0, x, y); % 拟合模型和求解参数```4.分析结果通过拟合模型得到的参数,可以分析和解释自变量和因变量之间的关系。
可以通过计算拟合优度等指标评价模型的拟合效果。
5.可视化结果使用MATLAB的绘图函数,将观测数据和拟合函数的曲线绘制在同一张图上,以直观地展示非线性回归分析的结果。
例如,可以使用以下代码绘制拟合曲线:```MATLABxx = linspace(min(x), max(x), 100); % 生成等间距的自变量yy = model(p, xx); % 计算拟合函数的因变量plot(x, y, 'o', xx, yy); % 绘制观测数据和拟合曲线```通过以上步骤,就能够应用MATLAB进行非线性回归分析。



Matlab关于非线性回归的应用一、Matlab非线性拟合工具箱——————单一变量的曲线逼近Matlab有一个功能强大的曲线拟合工具箱 cftool ,使用方便,能实现多种类型的线性、非线性曲线拟合。
下面结合我使用的 Matlab R2007b 来简单介绍如何使用这个工具箱。
假设我们要拟合的函数形式是 y=A*x*x + B*x, 且A>0,B>0 。
1、在命令行输入数据:》x=[110.3323 148.7328 178.064 202.8258033 224.7105 244.5711 262.908 280.0447 296.204 311.5475];》y=[5 10 15 20 25 30 35 40 45 50];2、启动曲线拟合工具箱》cftool3、进入曲线拟合工具箱界面“Curve Fitting tool”(1)点击“Data”按钮,弹出“Data”窗口;(2)利用X data和Y data的下拉菜单读入数据x,y,可修改数据集名“Data set name”,然后点击“Create data set”按钮,退出“Data”窗口,返回工具箱界面,这时会自动画出数据集的曲线图;(3)点击“Fitting”按钮,弹出“Fitting”窗口;(4)点击“New fit”按钮,可修改拟合项目名称“Fit name”,通过“Data set”下拉菜单选择数据集,然后通过下拉菜单“Type of fit”选择拟合曲线的类型,工具箱提供的拟合类型有:Custom Equations:用户自定义的函数类型Exponential:指数逼近,有2种类型, a*exp(b*x) 、 a*exp(b*x) + c*exp(d*x) Fourier:傅立叶逼近,有7种类型,基础型是 a0 + a1*cos(x*w) + b1*sin(x*w) Gaussian:高斯逼近,有8种类型,基础型是 a1*exp(-((x-b1)/c1)^2) Interpolant:插值逼近,有4种类型,linear、nearest neighbor、cubic spline、shape-preservingPolynomial:多形式逼近,有9种类型,linear ~、quadratic ~、cubic ~、4-9th degree ~Power:幂逼近,有2种类型,a*x^b 、a*x^b + cRational:有理数逼近,分子、分母共有的类型是linear ~、quadratic ~、cubic ~、4-5th degree ~;此外,分子还包括constant型Smoothing Spline:平滑逼近(翻译的不大恰当,不好意思)Sum of Sin Functions:正弦曲线逼近,有8种类型,基础型是 a1*sin(b1*x + c1)Weibull:只有一种,a*b*x^(b-1)*exp(-a*x^b)选择好所需的拟合曲线类型及其子类型,并进行相关设置:——如果是非自定义的类型,根据实际需要点击“Fit options”按钮,设置拟合算法、修改待估计参数的上下限等参数;——如果选Custom Equations,点击“New”按钮,弹出自定义函数等式窗口,有“Linear Equations线性等式”和“General Equations构造等式”两种标签。

MATLAB实例:多元函数拟合(线性与⾮线性)MATLAB实例:多元函数拟合(线性与⾮线性)作者:凯鲁嘎吉 - 博客园更多请看:之前写过⼀篇博⽂,是。
现在⽤拟合多元函数,实现线性拟合与⾮线性拟合,其中⾮线性拟合要求⾃定义拟合函数。
下⾯给出三种拟合⽅式,第⼀种是多元线性拟合(回归),第⼆三种是多元⾮线性拟合,实际中第⼆三种⽅法是⼀个意思,任选⼀种即可,推荐第⼆种拟合⽅法。
1. MATLAB程序fit_nonlinear_data.mfunction [beta, r]=fit_nonlinear_data(X, Y, choose)% Input: X ⾃变量数据(N, D), Y 因变量(N, 1),choose 1-regress, 2-nlinfit 3-lsqcurvefitif choose==1X1=[ones(length(X(:, 1)), 1), X];[beta, bint, r, rint, states]=regress(Y, X1)% 多元线性回归% y=beta(1)+beta(2)*x1+beta(3)*x2+beta(4)*x3+...% beta—系数估计% bint—系数估计的上下置信界% r—残差% rint—诊断异常值的区间% states—模型统计信息rcoplot(r, rint)saveas(gcf,sprintf('线性曲线拟合_残差图.jpg'),'bmp');elseif choose==2beta0=ones(7, 1);% 初始值的选取可能会导致结果具有较⼤的误差。
[beta, r, J]=nlinfit(X, Y, @myfun, beta0)% ⾮线性回归% beta—系数估计% r—残差% J—雅可⽐矩阵[Ypred,delta]=nlpredci(@myfun, X, beta, r, 'Jacobian', J)% ⾮线性回归预测置信区间% Ypred—预测响应% delta—置信区间半⾓plot(X(:, 1), Y, 'k.', X(:, 1), Ypred, 'r');saveas(gcf,sprintf('⾮线性曲线拟合_1.jpg'),'bmp');elseif choose==3beta0=ones(7, 1);% 初始值的选取可能会导致结果具有较⼤的误差。

应用MATLAB进行非线性回归分析摘要早在十九世纪,英国生物学家兼统计学家高尔顿在研究父与子身高的遗传问题时,发现子代的平均高度又向中心回归大的意思,使得一段时间内人的身高相对稳定。
之后回归分析的思想渗透到了数理统计的其他分支中。
随着计算机的发展,各种统计软件包的出现,回归分析的应用就越来越广泛。
回归分析处理的是变量与变量间的关系。
有时,回归函数不是自变量的线性函数,但通过变换可以将之化为线性函数,从而利用一元线性回归对其进行分析,这样的问题是非线性回归问题。
下面的第一题:炼钢厂出钢水时用的钢包,在使用过程中由于钢水及炉渣对耐火材料的侵蚀,使其容积不断增大。
要找出钢包的容积用盛满钢水时的质量与相应的实验次数的定量关系表达式,就要用到一元非线性回归分析方法。
首先我们要对数据进行分析,描出数据的散点图,判断两个变量之间可能的函数关系,对题中的非线性函数,参数估计是最常用的“线性化方法”,即通过某种变换,将方程化为一元线性方程的形式,接着我们就要对得到的一些曲线回归方程进行选择,找出到底哪一个才是更好一点的。
此时我们通常可采用两个指标进行选择,第一个是决定系数,第二个是剩余标准差。
进而就得到了我们想要的定量关系表达式。
第二题:给出了某地区1971—2000年的人口数据,对该地区的人口变化进行曲线拟合。
也用到了一元非线性回归的方法。
首先我们也要对数据进行分析,描出数据的散点图,然后用MATLAB编程进行回归分析拟合计算输出利用Logistic模型拟合曲线。
关键词:参数估计,Logistic模型,MATLAB正文一、一元非线性回归分析的求解思路:•求解函数类型并检验。
•求解未知参数。
可化曲线回归为直线回归,用最小二乘法求解;可化曲线回归为多项式回归。
二、回归曲线函数类型的选取和检验1、直接判断法2、作图观察法,与典型曲线比较,确定其属于何种类型,然后检验。
3、直接检验法(适应于待求参数不多的情况)4、表差法(适应于多想式回归,含有常数项多于两个的情况)三、化曲线回归为直线回归问题用直线检验法或表差法检验的曲线回归方程都可以通过变量代换转化为直线回归方程,利用线性回归分析方法可求得相应的参数估计值。

本次(běn cì)教程的主要内容包含:一、多元(duō yuán)线性回归 2#多元(duō yuán)线性回归:regress二、多项式回归(huíguī) 3#一元(yī yuán)多项式:polyfit或者polytool 多元二项式:rstool或者rsmdemo三、非线性回归 4#非线性回归:nlinfit四、逐步回归 5#逐步回归:stepwise一、多元线性回归多元线性回归:1、b=regress(Y, X ) 确定回归系数的点估计值2、[b, bint,r,rint,stats]=regress(Y,X,alpha)求回归系数的点估计和区间估计、并检验回归模型①bint表示回归系数的区间估计.②r表示残差③rint表示置信区间④stats表示用于检验回归模型的统计量,有三个数值:相关系数r2、F值、与F对应的概率p说明:相关系数r2越接近1,说明回归方程越显著;时拒绝H0,F越大,说明回归方程越显著;与F对应的概率p<α时拒绝H0⑤alpha表示显著性水平(缺省时为0.05)3、rcoplot(r,rint)画出残差及其置信区间具体参见下面的实例演示4、实例演示,函数使用说明(1)输入数据1.>>x=[143 145 146 147 149 150 153 154 155 156 157 158 159 160 162 164]';2.>>X=[ones(16,1) x];3.>>Y=[88 85 88 91 92 93 93 95 96 98 97 96 98 99 100 102]';复制代码(2)回归分析及检验1. >> [b,bint,r,rint,stats]=regress(Y,X)2.3. b =4.5. -16.07306. 0.71947.8.9.bint =10.11. -33.7071 1.561212. 0.6047 0.834013.14.15.r =16.17. 1.205618. -3.233119. -0.952420. 1.328221. 0.889522. 1.170223. -0.987924. 0.292725. 0.573426. 1.854027. 0.134728. -1.584729. -0.304030. -0.023431. -0.462132. 0.099233.34.35.rint =36.37. -1.2407 3.652038. -5.0622 -1.404039. -3.5894 1.684540. -1.2895 3.945941. -1.8519 3.630942. -1.5552 3.895543. -3.7713 1.795544. -2.5473 3.132845. -2.2471 3.393946. -0.7540 4.462147. -2.6814 2.950848. -4.2188 1.049449. -3.0710 2.463050. -2.7661 2.719351. -3.1133 2.189252. -2.4640 2.662453.54.55.stats =56.57. 0.9282 180.9531 0.0000 1.7437复制代码运行结果解读如下参数回归结果为,对应的置信区间分别为[-33.7017,1.5612]和[0.6047,0.8r2=0.9282(越接近于1,回归效果越显著),F=180.9531, p=0.0000,由p<0.05, 可知回归模型y=-16.073+0.7194x成立(3)残差分析作残差图1.rcoplot(r,rint)复制代码从残差图可以看出,除第二个数据外,其余数据的残差离零点均较近,且残差的置信区间均包含零这说明回归模型 y=-16.073+0.7194x能较好的符合原始数据,而第二个数据可视为异常点。
§5. 利用Matlab编程计算非线性回归模型——以Logistic曲线为例1.原始数据下表给出了某地区1971—2000年的人口数据(表1)。
试分别用Matlab和SPSS软件,对该地区的人口变化进行曲线拟合。
表1 某地区人口变化数据年份时间变量t=年份-1970人口y/人1971133 8151972233 9811973334 0041974434 1651975534 2121976634 3271977734 3441978834 4581979934 49819801034 47619811134 48319821234 48819831334 51319841434 49719851534 51119861634 52019871734 50719881834 50919891934 52119902034 51319912134 51519922234 51719932334 51919942434 51919952534 52119962634 5211997 27 34 523 1998 28 34 525 1999 29 34 525 20003034 527根据上表中的数据,做出散点图,见图1。
337003380033900340003410034200343003440034500346001970197219741976197819801982198419861988199019921994199619982000年份人口图1 某地区人口随时间变化的散点图从图1可以看出,人口随时间的变化呈非线性过程,而且存在一个与横坐标轴平行的渐近线,故可以用Logistic 曲线模型进行拟合。
因为Logistic 曲线模型的基本形式为:tbe a y -+=1所以,只要令:t e x yy -='=',1,就可以将其转化为直线模型: x b a y '+='下面,我们分别用Matlab 和SPSS 软件进行回归分析拟合计算。
matlab 逻辑回归多元Matlab逻辑回归多元逻辑回归是一种常用的分类算法,在许多实际应用中得到广泛应用。
而多元逻辑回归则是逻辑回归的一种扩展,用于处理多个自变量的分类问题。
本文将以Matlab为工具,详细介绍多元逻辑回归的原理和实现步骤。
一、多元逻辑回归原理多元逻辑回归是逻辑回归的扩展,适用于有多个自变量的分类问题。
逻辑回归通过对输入特征的线性组合,然后经过一个非线性的sigmoid函数,将输出值转化为概率,进而进行分类。
多元逻辑回归的目标是找到最优的参数权重,使得分类结果最准确。
在多元逻辑回归中,我们需要先定义一个假设函数h(x),它将特征向量x 映射到预测的概率值。
假设函数的形式为:h_θ(x) = g(θ^Tx)其中,g(z)表示sigmoid函数,其形式为:g(z) = \frac{1}{1+e^{-z}}通过这个假设函数,我们可以得到样本x属于正例(1)的概率和负例(0)的概率分别为:P(y=1 x,θ) = h_θ(x)P(y=0 x,θ) = 1 - h_θ(x)多元逻辑回归的目标是最大化对数似然函数,即最大化所有样本的预测概率(或最小化其负对数)。
我们可以通过梯度下降或其他优化算法来求解最优的参数权重θ。
二、使用Matlab实现多元逻辑回归在Matlab中,可以使用统计和机器学习工具箱提供的函数来实现多元逻辑回归。
下面将一步一步介绍如何在Matlab中使用多元逻辑回归算法来解决分类问题。
# 1.数据准备首先,我们需要准备用于训练和测试的数据。
假设我们有一个包含多个特征的数据集,其中每个样本都有相应的标签(正例或负例)。
我们可以选择将数据拆分为训练集和测试集,通常采用70的数据用于训练,30的数据用于测试。
# 2.参数初始化接下来,我们需要初始化参数权重θ。
在多元逻辑回归中,θ是一个向量,长度为特征数量加1。
我们可以将所有θ初始化为0,或者随机初始化。
# 3.梯度下降求解在多元逻辑回归中,可以使用梯度下降算法来最小化损失函数。
回归(拟合)自己的总结(20100728)1:学三条命令:polyfit(x,y,n)---拟合成一元幂函数(一元多次) regress(y,x)----可以多元,nlinfit(x,y,’fun ’,beta0) (可用于任何类型的函数,任意多元函数,应用范围最主,最万能的)2:同一个问题,可能这三条命令都可以使用,但结果肯定是不同的,因为拟合的近似结果,没有唯一的标准的答案。
相当于咨询多个专家。
3:回归的操作步骤:(1) 根据图形(实际点),选配一条恰当的函数形式(类型)---需要数学理论与基础和经验。
(并写出该函数表达式的一般形式,含待定系数)(2) 选用某条回归命令求出所有的待定系数所以可以说,回归就是求待定系数的过程(需确定函数的形式)配曲线的一般方法是: (一)先对两个变量x 和y 作n 次试验观察得n i y x ii,...,2,1),,( 画出散点图,散点图(二)根据散点图确定须配曲线的类型. 通常选择的六类曲线如下:(1)双曲线xb a y +=1 (2)幂函数曲线y=a bx , 其中x>0,a>0(3)指数曲线y=a bx e 其中参数a>0.(4)倒指数曲线y=a xb e/其中a>0,(5)对数曲线y=a+blogx,x>0(6)S 型曲线x be a y -+=1(三)然后由n 对试验数据确定每一类曲线的未知参数a 和b.一、一元多次拟合polyfit(x,y,n)一元回归polyfit多元回归regress---nlinfit(非线性)二、多元回归分析(其实可以是非线性,它通用性极高)对于多元线性回归模型:e x x y p p ++++=βββ 110设变量12,,,p x x x y的n 组观测值为12(,,,)1,2,,i i ip i x x x y i n=.记 ⎪⎪⎪⎪⎪⎭⎫⎝⎛=np n n p p x x x x x x x x x x 212222111211111,⎪⎪⎪⎪⎪⎭⎫⎝⎛=n y y y y 21,则⎪⎪⎪⎪⎪⎭⎫ ⎝⎛=p ββββ 10 的估计值为排列方式与线性代数中的线性方程组相同()拟合成多元函数---regress 使用格式:左边用b=或[b, bint, r, rint, stats]= 右边用regress(y, x) 或regress(y, x, alpha)---命令中是先y 后x,---须构造好矩阵x(x 中的每列与目标函数的一项对应) ---并且x 要在最前面额外添加全1列/对应于常数项 ---y 必须是列向量---结果是从常数项开始---与polyfit 的不同。
MATLAB 回归分析regress,nlinfit,stepwise函数matlab回归分析regress,nlinfit,stepwise函数回归分析1.多元线性重回在matlab统计工具箱中使用命令regress()实现多元线性回归,调用格式为b=regress(y,x)或[b,bint,r,rint,statsl=regess(y,x,alpha)其中因变量数据向量y和自变量数据矩阵x按以下排列方式输入对一元线性重回,挑k=1即可。
alpha为显著性水平(缺省时预设为0.05),输入向量b,bint为回归系数估计值和它们的置信区间,r,rint为残差及其置信区间,stats就是用作检验重回模型的统计数据量,存有三个数值,第一个就是r2,其中r就是相关系数,第二个就是f统计数据量值,第三个就是与统计数据量f对应的概率p,当p拒绝h0,回归模型成立。
图画出来残差及其置信区间,用命令rcoplot(r,rint)实例1:已知某湖八年来湖水中cod浓度实测值(y)与影响因素湖区工业产值(x1)、总人口数(x2)、捕鱼量(x3)、降水量(x4)资料,建立污染物y的水质分析模型。
(1)输出数据x1=[1.376,1.375,1.387,1.401,1.412,1.428,1.445,1.477]x2=[0.450,0.475,0.485,0.50 0,0.535,0.545,0.550,0.575]x3=[2.170,2.554,2.676,2.713,2.823,3.088,3.122,3.262]x4=[0.8922,1.1610,0.5346,0.9589,1.0239,1.0499,1.1065,1.1387]y=[5.19,5.30,5.60,5.82,6.00,6.06,6.45,6.95](2)留存数据(以数据文件.mat形式留存,易于以后调用)savedatax1x2x3x4yloaddata(抽出数据)(3)继续执行重回命令x=[ones(8,1),];[b,bint,r,rint,stats]=regress得结果:b=(-16.5283,15.7206,2.0327,-0.2106,-0.1991)’stats=(0.9908,80.9530,0.0022)即为=-16.5283+15.7206xl+2.0327x2-0.2106x3+0.1991x4r2=0.9908,f=80.9530,p=0.00222.非线性重回非线性回归可由命令nlinfit来实现,调用格式为[beta,r,j]=nlinfit(x,y,'model’,beta0)其中,输人数据x,y分别为n×m矩阵和n维列向量,对一元非线性回归,x为n维列向量model是事先用m-文件定义的非线性函数,beta0是回归系数的初值,beta是估计出的回归系数,r是残差,j是jacobian矩阵,它们是估计预测误差需要的数据。
回归分析1.多元线性回归在Matlab统计工具箱中使用命令regress()实现多元线性回归,调用格式为b=regress(y,x)或[b,bint,r,rint,statsl = regess(y,x,alpha)其中因变量数据向量y和自变量数据矩阵x按以下排列方式输入对一元线性回归,取k=1即可。
alpha为显著性水平(缺省时设定为0.05),输出向量b,bint为回归系数估计值和它们的置信区间,r,rint为残差及其置信区间,stats是用于检验回归模型的统计量,有三个数值,第一个是R2,其中R是相关系数,第二个是F统计量值,第三个是与统计量F对应的概率P,当P<α时拒绝H0,回归模型成立。
画出残差及其置信区间,用命令rcoplot(r,rint)实例1:已知某湖八年来湖水中COD浓度实测值(y)与影响因素湖区工业产值(x1)、总人口数(x2)、捕鱼量(x3)、降水量(x4)资料,建立污染物y的水质分析模型。
(1)输入数据x1=[1.376, 1.375, 1.387, 1.401, 1.412, 1.428, 1.445, 1.477]x2=[0.450, 0.475, 0.485, 0.500, 0.535, 0.545, 0.550, 0.575]x3=[2.170 ,2.554, 2.676, 2.713, 2.823, 3.088, 3.122, 3.262]x4=[0.8922, 1.1610 ,0.5346, 0.9589, 1.0239, 1.0499, 1.1065, 1.1387]y=[5.19, 5.30, 5.60,5.82,6.00, 6.06,6.45,6.95](2)保存数据(以数据文件.mat形式保存,便于以后调用)save data x1 x2 x3 x4 yload data (取出数据)(3)执行回归命令x =[ones(8,1),];[b,bint,r,rint,stats] = regress得结果:b = (-16.5283,15.7206,2.0327,-0.2106,-0.1991)’stats = (0.9908,80.9530,0.0022)即= -16.5283 + 15.7206xl + 2.0327x2 - 0.2106x3 + 0.1991x4R2 = 0.9908,F = 80.9530,P = 0.00222.非线性回归非线性回归可由命令nlinfit来实现,调用格式为[beta,r,j] = nlinfit(x,y,'model’,beta0)其中,输人数据x,y分别为n×m矩阵和n维列向量,对一元非线性回归,x 为n维列向量model是事先用m-文件定义的非线性函数,beta0是回归系数的初值,beta是估计出的回归系数,r是残差,j是Jacobian矩阵,它们是估计预测误差需要的数据。
matlab 回归(多元拟合)教程前言1、学三条命令polyfit(x,y,n)---拟合成一元幂函数(一元多次) regress(y,x)----可以多元,nlinfit(x,y,’fun ’,beta0) (可用于任何类型的函数,任意多元函数,应用范围最主,最万能的)2、同一个问题,这三条命令都可以使用,但结果肯定是不同的,因为拟合的近似结果,没有唯一的标准的答案。
相当于咨询多个专家。
3、回归的操作步骤:根据图形(实际点),选配一条恰当的函数形式(类型)---需要数学理论与基础和经验。
(并写出该函数表达式的一般形式,含待定系数)------选用某条回归命令求出所有的待定系数。
所以可以说,回归就是求待定系数的过程(需确定函数的形式)一、回归命令一元多次拟合polyfit(x,y,n);一元回归polyfit;多元回归regress---nlinfit(非线性)二、多元回归分析对于多元线性回归模型(其实可以是非线性,它通用性极高):e x x y p p++++=βββ 110设变量12,,,p x x x y 的n 组观测值为12(,,,)1,2,,i i ip i x x x y i n =记 ⎪⎪⎪⎪⎪⎭⎫⎝⎛=np n n p p x x x x x x x x x x 212222111211111,⎪⎪⎪⎪⎪⎭⎫⎝⎛=n y y y y 21,则⎪⎪⎪⎪⎪⎭⎫ ⎝⎛=p ββββ 10 的估计值为排列方式与线性代数中的线性方程组相同(),拟合成多元函数---regress使用格式:左边用b=[b, bint, r, rint, stats]右边用=regress(y, x)或regress(y, x, alpha) ---命令中是先y 后x,---须构造好矩阵x(x 中的每列与目标函数的一项对应) ---并且x 要在最前面额外添加全1列/对应于常数项---y 必须是列向量---结果是从常数项开始---与polyfit 的不同。
)其中: b 为回归系数,β的估计值(第一个为常数项),bint 为回归系数的区间估计,r: 残差 ,rint: 残差的置信区间,stats: 用于检验回归模型的统计量,有四个数值:相关系数r2、F 值、与F 对应的概率p 和残差的方差(前两个越大越好,后两个越小越好),alpha: 显著性水平(缺省时为0.05,即置信水平为95%),(alpha 不影响b,只影响bint(区间估计)。
它越小,即置信度越高,则bint 范围越大。
显著水平越高,则区间就越小)(返回五个结果)---如有n 个自变量-有误(n 个待定系数),则b 中就有n+1个系数(含常数项,---第一项为常数项)(b---b 的范围/置信区间---残差r---r 的置信区间rint-----点估计----区间估计此段上课时不要:---- 如果i β的置信区间(bint 的第1i +行)不包含0,则在显著水平为α时拒绝0i β=的假设,认为变量i x 是显著的.*******(而rint 残差的区间应包含0则更好)。
b,y 等均为列向量,x 为矩阵(表示了一组实际的数据)必须在x 第一列添加一个全1列。
----对应于常数项-------而nlinfit 不能额外添加全1列。
结果的系数就是与此矩阵相对应的(常数项,x1,x2,……xn )。
(结果与参数个数:1/5=2/3-----y,x 顺序---x 要额外添加全1列)而nlinfit:1/3=4------x,y 顺序---x 不能额外添加全1列,---需编程序,用于模仿需拟合的函数的任意形式,一定两个参数,一为系数数组,二为自变量矩阵(每列为一个自变量)有n 个变量---不准确,x 中就有n 列,再添加一个全1列(相当于常数项),就变为n+1列,则结果中就有n+1个系数。
x 需要经过加工,如添加全1列,可能还要添加其他需要的变换数据。
相关系数r2越接近1,说明回归方程越显著;(r2越大越接近1越好)F 越大,说明回归方程越显著;(F 越大越好)与F 对应的概率p 越小越好,一定要P<a 时拒绝H0而接受H1,即回归模型成立。
乘余(残差)标准差(RMSE )越小越好(此处是残差的方差,还没有开方)(前两个越大越好,后两个越小越好)regress 多元(可通过变形而适用于任意函数),15/23顺序(y,x---结果是先常数项,与polyfit 相反)y 为列向量;x 为矩阵,第一列为全1列(即对应于常数项),其余每一列对应于一个变量(或一个含变量的项),即x 要配成目标函数的形式(常数项在最前)x 中有多少列则结果的函数中就有多少项首先要确定要拟合的函数形式,然后确定待定的系,从常数项开始排列,须构造x(每列对应于函数中的一项,剔除待定系数),拟合就是确定待定系数的过程(当然需先确定函数的型式)重点:regress(y,x) 重点与难点是如何加工处理矩阵x。
y是函数值,一定是只有一列。
也即目标函数的形式是由矩阵X来确定如s=a+b*x1+c*x2+d*x3+e*x1^2+f*x2*x3+g*x1^2,一定有一个常数项,且必须放在最前面(即x的第一列为全1列)X中的每一列对应于目标函数中的一项(目标函数有多少项则x中就有多少列)X=[ones, x1, x2, x3, x1.^2, x2.*x3,x1.ˆ2] (剔除待定系数的形式)regress: y/x顺序,矩阵X需要加工处理nlinfit: x/y顺序,X/Y就是原始的数据,不要做任何的加工。
(即regress靠矩阵X来确定目标函数的类型形式(所以X很复杂,要作很多处理)而nlinfit是靠程序来确定目标函数的类型形式(所以X就是原始数据,不要做任何处理)例1测16名成年女子的身高与腿长所得数据如下:配成y=a+b*x形式>> x=[143 145 146 147 149 150 153 154 155 156 157 158 159 160 162 164]';>> y=[88 85 88 91 92 93 93 95 96 98 97 96 98 99 100 102]';>> plot(x,y,'r+') >> z=x;>> x=[ones(16,1),x];----常数项>> [b,bint,r,rint,stats]=regress(y,x);---处结果与polyfit(x,y,1)相同 >>b,bint,stats得结果:b = bint =-16.0730 -33.7071 1.5612------每一行为一个区间 0.7194 0.6047 0.8340 stats = 0.9282 180.9531 0.0000即7194.0ˆ,073.16ˆ10=-=ββ;0ˆβ的置信区间为[-33.7017,1.5612], 1ˆβ的置信区间为[0.6047,0.834]; r 2=0.9282, F=180.9531, p=0.0。
p<0.05, 可知回归模型 y=-16.073+0.7194x 成立.>> [b,bint,r,rint,stats]=regress(Y ,X,0.05);-----结果相同 >> [b,bint,r,rint,stats]=regress(Y ,X,0.03);>> polyfit(x,y,1)-----当为一元时(也只有一组数),则结果与regress 是相同的,只是 命令中x,y 要交换顺序,结果的系数排列顺序完全相反,x 中不需要全1列。
ans =0.7194 -16.0730--此题也可用polyfit 求解,杀鸡用牛刀,脖子被切断。
3、残差分析,作残差图:>>rcoplot(r,rint)Residual Case Order PlotR e s i d u a l sCase Number从残差图可以看出,除第二个数据外,其余数据的残差离零点均较近,且残差的置信区间均包含零点,这说明回归模型 y=-16.073+0.7194x 能较好的符合原始数据,而第二个数据可视为异常点(而剔除)4、预测及作图:>> plot(x,y,'r+') >> hold on >> a=140:165; >> b=b(1)+b(2)*a; >> plot(a,b,'g')例2观测物体降落的距离s 与时间t 的关系,得到数据如下表,求s 关于t 的回归方程2ˆct bt a s++=法一:直接作二次多项式回归 t=1/30:1/30:14/30;>> [p,S]=polyfit(t,s,2)p =489.2946 65.8896 9.1329 得回归模型为 :1329.98896.652946.489ˆ2++=t t s方法二----化为多元线性回归:2ˆct bt a s++=t=1/30:1/30:14/30;s=[11.86 15.67 20.60 26.69 33.71 41.93 51.13 61.49 72.90 85.44 99.08 113.77 129.54 146.48];>> T=[ones(14,1), t', (t.^2)'] %是否可行等验证...----因为有三个待定系数,所以有三列,始于常数项 >> [b,bint,r,rint,stats]=regress(s',T); >> b,stats b = 9.1329 65.8896 489.2946 stats =1.0e+007 *0.0000 1.0378 0 0.0000 得回归模型为 :22946.4898896.651329.9ˆt t s++=>> T=[ones(14,1),t, (t.^2)'] %是否可行等验证... polyfit------一元多次regress----多元一次---其实通过技巧也可以多元多次regress 最通用的,万能的,表面上是多元一次,其实可以变为多元多次且任意函数,如x 有n 列(不含全1列),则表达式中就有n+1列(第一个为常数项,其他每项与x 的列序相对应)此处的说法需进一步验证证……………………………例3设某商品的需求量与消费者的平均收入、商品价格的统计数据如下,建立回归模型,预测平均收入为1000、价格为6时的商品需求量. 需求量 100 75 80 70 50 65 90 100 110 60 收入10006001200500300400130011001300300价格5 76 6 87 5 4 3 9选择纯二次模型,即2222211122110x x x x y βββββ++++=----用户可以任意设计函数>> x1=[1000 600 1200 500 300 400 1300 1100 1300 300]; >> x2=[5 7 6 6 8 7 5 4 3 9];>> y=[100 75 80 70 50 65 90 100 110 60]';X=[ones(10,1) x1' x2' (x1.^2)' (x2.^2)']; %注意技巧性 [b,bint,r,rint,stats]=regress(y,X); %这是万能方法需进一步验证 >> b,stats b = 110.5313 0.1464 -26.5709 -0.0001 1.8475stats = 0.9702 40.6656 0.0005 20.5771故回归模型为:2221218475.10001.05709.261464.05313.110x x x x y +--+=剩余标准差为4.5362, 说明此回归模型的显著性较好.--------(此题还可以用 rstool(X,Y)命令求解,详见回归问题详解)>> X=[ones(10,1) x1' x2' (x1.^2)' (x2.^2)',sin(x1.*x2)',(x1.*exp(x2))']; >> [b,bint,r,rint,stats]=regress(y,X); >> b,stats(个人2011年认为,regress 只能用于函数中的每一项只能有一个待定系数的情况,不能用于aebx等的情况)regress(y,x)----re是y/x逆置的---y是列向量---须确定目标函数的形式---x须构造(通过构造来反映目标函数)---x中的每一列与目标函数的一项对应(剔除待定系数)----首项为常数项(x的第一列为全1)----有函数有n 项(待定系数),则x就有n列----regress只能解决每项只有一个待定系数的情况且必须有常数项的情况(且每项只有一个待定系数,即项数与待定系数数目相同)***其重(难、关键)点:列向量、构造矩阵(X):目标函数中的每项与X中的一列对应。