灰色系统理论及其应用讲义
- 格式:doc
- 大小:805.00 KB
- 文档页数:21


数学建模讲稿-------灰色系统分析五步建模思想研究一个系统,一般应首先建立系统的数学模型,进而对系统的整体功能、协调功能以及系统各因素之间的关联关系、因果关系、动态关系进行具体的量化研究。
这种研究必须以定性分析为先导,定量与定性紧密结合。
系统模型的建立,一般要经历思想开发、因素分析、量化、动态化、优化五个步骤,故称为五步建模。
第一步:开发思想,形成概念,通过定性分析、研究,明确研究的方向、目标、途径、措施,并将结果用准确简练的语言加以表达,这便是语言模型。
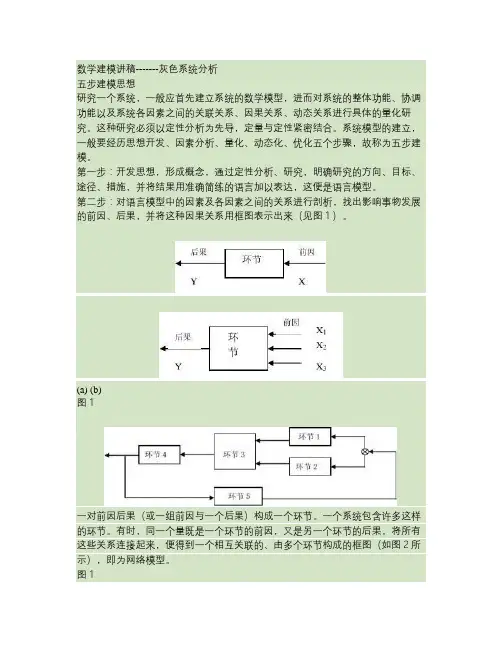
第二步:对语言模型中的因素及各因素之间的关系进行剖析,找出影响事物发展的前因、后果,并将这种因果关系用框图表示出来(见图1)。
(a) (b)图1一对前因后果(或一组前因与一个后果)构成一个环节。
一个系统包含许多这样的环节。
有时,同一个量既是一个环节的前因,又是另一个环节的后果,将所有这些关系连接起来,便得到一个相互关联的、由多个环节构成的框图(如图2所示),即为网络模型。
图1第三步:对各环节的因果关系进行量化研究,初步得出低层次的概略量化关系,即为量化模型。
第四步:进一步收集各环节输入数据和输出数据,利用所得数据序列,建立动态GM模型,即动态模型。
动态模型是高层次的量化模型,它更为深刻地揭示出输入与输出之间的数量关系或转换规律,是系统分析、优化的基础。
第五步:对动态模型进行系统研究和分析,通过结构、机理、参数的调整,进行系统重组,达到优化配置、改善系统动态品质的目的。
这样得到的模型,称之为优化模型。
五步建模的全过程,是在五个不同阶段建立五种模型的过程:网络模型优化模型在建模过程中,要不断地将下一阶段中所得的结果回馈,经过多次循环往复,使整个模型逐步趋于完善。
数学建模讲稿-------灰色系统分析灰色系统建模的基本思路可以概括为以下几点:1科学实验数据;○2经验数据;○3生产数据;○4决策数据。
(1)建立模型常用的数据有以下几种:○(2)序列生成数据是建立灰色模型的基础数据。

第六章灰色系统理论客观世界的很多实际问题,其内部的结构、参数以及特征并未全部被人们了解,人们不可能象研究白箱问题那样将其内部机理研究清楚,只能依据某种思维逻辑与推断来构造模型。
对这类部分信息已知而部分信息未知的系统,我们称之为灰色系统。
本章介绍的方法是从灰色系统的本征灰色出发,研究在信息大量缺乏或紊乱的情况下,如何对实际问题进行分析和解决。
§1 灰色系统概论客观世界在不断发展变化的同时,往往通过事物之间及因素之间相互制约、相互联系而构成一个整体,我们称之为系统。
按事物内涵的不同,人们已建立了工程技术、社会系统、经济系统等。
人们试图对各种系统所外露出的一些特征进行分析,从而弄清楚系统内部的运行机理。
从信息的完备性与模型的构建上看,工程技术等系统具有较充足的信息量,其发展变化规律明显、定量描述较方便、结构与参数较具体、人们称之为白色系统;对另一类系统诸如社会系统、农业系统、生态系统等,人们无法建立客观的物理原型,其作用原理亦不明确,内部因素难以辨识或之间关系隐蔽,人们很难准确了解这类系统的行为特征,因此对其定量描述难度较大,带来建立模型的困难。
这类系统内部特性部分已知的系统称之为灰色系统。
一个系统的内部特性全部未知,则称之为黑色系统。
区别白色系统与灰色系统的重要标志是系统内各因素之间是否具有确定的关系。
运动学中物体运动的速度、加速度与其所受到的外力有关,其关系可用牛顿定律以明确的定量来阐明,因此,物体的运动便是一个白色系统。
作为实际问题,灰色系统在大千世界中是大量存在的,绝对的白色或黑色系统是很少的社会、经济、农业以及生态系统一般都会有不可忽略的“噪声”(即随机干扰)。
现有的研究经常被“噪声”污染。
受随机干扰侵蚀的系统理论主要立足于概率统计。
通过统计规律、概率分布对事物的发展进行预测,对事物的处置进行决策。
现有的系统分析的量化方法,大都是数理统计法如回归分析、方差分析、主成分分析等,回归分析是应用最广泛的一种办法。





灰色系统理论及其应用第一章灰色系统的概念与基本原理1.1灰色系统理论的产生和发展动态1982年,北荷兰出版公司出版的《系统与控制通讯》杂志刊载了我国学者邓聚龙教授的第一篇灰色系统理论论文”灰色系统的控制问题”,同年,《华中工学院学报》发表邓聚龙教授的第一篇中文论文《灰色控制系统》,这两篇论文的发表标志着灰色系统这一学科诞生。
1985灰色系统研究会成立,灰色系统相关研究发展迅速。
1989海洋出版社出版英文版《灰色系统论文集》,同年,英文版国际刊物《灰色系统》杂志正式创刊。
目前,国际、国内300多种期刊发表灰色系统论文,许多国际会议把灰色系统列为讨论专题。
国际著名检索已检索我国学者的灰色系统论著3000多次。
灰色系统理论已应用范围已拓展到工业、农业、社会、经济、能源、地质、石油等众多科学领域,成功地解决了生产、生活和科学研究中的大量实际问题,取得了显著成果。
1.2几种不确定方法的比较(系统科学---系统理论)概率统计,模糊数学和灰色系统理论是三种最常用的不确定系统研究方法。
其研究对象都具有某种不确定性,是它们共同的特点。
也正是研究对象在不确定性上的区别,才派生了这三种各具特色的不确定学科。
模糊数学着重研究“认识不确定”问题,其研究对象具有“内涵明确,外延不明确”的特点。
比如“年轻人”内涵明确,但要你划定一个确定的范围,在这个范围内是年轻人,范围外不是年轻人,则很难办到了。
概率统计研究的是“随机不确定”现象,考察具有多种可能发生的结果之“随机不确定”现象中每一种结果发生的可能性大小。
要求大样本,并服从某种典型分布。
灰色系统理论着重研究概率统计,模糊数学难以解决的“小样本,贫信息”不确定性问题,着重研究“外延明确,内涵不明确”的对象。
如到2050年,中国要将总人口控制在15亿到16亿之间,这“15亿到16亿之间“是一个灰概念,其外延很清楚,但要知道具体数值,则不清楚。
三种不确定性系统研究方法的比较分析1.3灰色系统理论的基本概念定义1.3.1信息完全明确的系统称为白色系统。
灰色系统理论及其应用第一章灰色系统的概念与基本原理1.1灰色系统理论的产生和发展动态1982年,北荷兰出版公司出版的《系统与控制通讯》杂志刊载了我国学者邓聚龙教授的第一篇灰色系统理论论文”灰色系统的控制问题”,同年,《华中工学院学报》发表邓聚龙教授的第一篇中文论文《灰色控制系统》,这两篇论文的发表标志着灰色系统这一学科诞生。
1985灰色系统研究会成立,灰色系统相关研究发展迅速。
1989海洋出版社出版英文版《灰色系统论文集》,同年,英文版国际刊物《灰色系统》杂志正式创刊。
目前,国际、国内300多种期刊发表灰色系统论文,许多国际会议把灰色系统列为讨论专题。
国际著名检索已检索我国学者的灰色系统论著3000多次。
灰色系统理论已应用范围已拓展到工业、农业、社会、经济、能源、地质、石油等众多科学领域,成功地解决了生产、生活和科学研究中的大量实际问题,取得了显著成果。
1.2几种不确定方法的比较(系统科学---系统理论)概率统计,模糊数学和灰色系统理论是三种最常用的不确定系统研究方法。
其研究对象都具有某种不确定性,是它们共同的特点。
也正是研究对象在不确定性上的区别,才派生了这三种各具特色的不确定学科。
模糊数学着重研究“认识不确定”问题,其研究对象具有“内涵明确,外延不明确”的特点。
比如“年轻人”内涵明确,但要你划定一个确定的范围,在这个范围内是年轻人,范围外不是年轻人,则很难办到了。
概率统计研究的是“随机不确定”现象,考察具有多种可能发生的结果之“随机不确定”现象中每一种结果发生的可能性大小。
要求大样本,并服从某种典型分布。
灰色系统理论着重研究概率统计,模糊数学难以解决的“小样本,贫信息”不确定性问题,着重研究“外延明确,内涵不明确”的对象。
如到2050年,中国要将总人口控制在15亿到16亿之间,这“15亿到16亿之间“是一个灰概念,其外延很清楚,但要知道具体数值,则不清楚。
三种不确定性系统研究方法的比较分析1.3灰色系统理论的基本概念定义1.3.1信息完全明确的系统称为白色系统。

灰色系统理论及其应用一、灰色系统理论概述灰色系统理论,是一种研究不确定性问题的方法。
它起源于20世纪80年代,由中国学者邓聚龙教授提出。
灰色系统理论认为,现实世界中的许多问题并非非黑即白,而是介于黑白之间的灰色地带。
这种理论为我们处理复杂、模糊、不确定性问题提供了一种新的视角。
灰色系统理论的核心思想是通过对部分已知信息的挖掘和加工,实现对整个系统行为的合理预测和控制。
它将系统分为白色系统、黑色系统和灰色系统。
白色系统是指信息完全已知的系统,黑色系统是指信息完全未知的系统,而灰色系统则是介于两者之间的系统,部分信息已知,部分信息未知。
二、灰色系统理论的基本原理1. 灰灰是灰色系统理论的基础,它通过对原始数据进行处理,具有规律性的序列。
常见的灰方法有累加(AGO)、累减(IGO)和均值等。
2. 灰关联分析灰关联分析是灰色系统理论的重要方法,用于分析系统中各因素之间的关联程度。
通过对系统各因素发展变化的相似度进行比较,揭示系统内部因素之间的联系。
3. 灰预测灰预测是灰色系统理论在实际应用中的重要手段,它通过对部分已知信息的挖掘,建立灰色模型,对系统未来发展趋势进行预测。
三、灰色系统理论的应用领域1. 经济管理灰色系统理论在经济学和管理学领域具有广泛的应用,如企业竞争力分析、市场预测、投资决策等。
通过灰关联分析,可以找出影响企业发展的关键因素,为企业制定发展战略提供依据。
2. 工程技术在工程技术领域,灰色系统理论可用于设备故障预测、质量控制、能源消耗分析等。
例如,通过对设备运行数据的分析,建立灰色预测模型,提前发现潜在故障,确保设备安全运行。
3. 社会科学4. 生态环境在生态环境领域,灰色系统理论可以用于水资源评价、环境污染预测、生态平衡分析等。
通过对生态环境数据的挖掘,有助于我们更好地了解和把握生态环境的发展态势。
四、灰色系统理论的优势与局限性优势:1. 对小样本数据的适用性:灰色系统理论不需要大量数据即可进行建模和分析,这对于样本量有限的情况尤其有价值。
第六章灰色系统理论客观世界的很多实际问题,其内部的结构、参数以及特征并未全部被人们了解,人们不可能象研究白箱问题那样将其内部机理研究清楚,只能依据某种思维逻辑与推断来构造模型。
对这类部分信息已知而部分信息未知的系统,我们称之为灰色系统。
本章介绍的方法是从灰色系统的本征灰色出发,研究在信息大量缺乏或紊乱的情况下,如何对实际问题进行分析和解决。
§1 灰色系统概论客观世界在不断发展变化的同时,往往通过事物之间及因素之间相互制约、相互联系而构成一个整体,我们称之为系统。
按事物内涵的不同,人们已建立了工程技术、社会系统、经济系统等。
人们试图对各种系统所外露出的一些特征进行分析,从而弄清楚系统内部的运行机理。
从信息的完备性与模型的构建上看,工程技术等系统具有较充足的信息量,其发展变化规律明显、定量描述较方便、结构与参数较具体、人们称之为白色系统;对另一类系统诸如社会系统、农业系统、生态系统等,人们无法建立客观的物理原型,其作用原理亦不明确,内部因素难以辨识或之间关系隐蔽,人们很难准确了解这类系统的行为特征,因此对其定量描述难度较大,带来建立模型的困难。
这类系统内部特性部分已知的系统称之为灰色系统。
一个系统的内部特性全部未知,则称之为黑色系统。
区别白色系统与灰色系统的重要标志是系统内各因素之间是否具有确定的关系。
运动学中物体运动的速度、加速度与其所受到的外力有关,其关系可用牛顿定律以明确的定量来阐明,因此,物体的运动便是一个白色系统。
作为实际问题,灰色系统在大千世界中是大量存在的,绝对的白色或黑色系统是很少的社会、经济、农业以及生态系统一般都会有不可忽略的“噪声”(即随机干扰)。
现有的研究经常被“噪声”污染。
受随机干扰侵蚀的系统理论主要立足于概率统计。
通过统计规律、概率分布对事物的发展进行预测,对事物的处置进行决策。
现有的系统分析的量化方法,大都是数理统计法如回归分析、方差分析、主成分分析等,回归分析是应用最广泛的一种办法。
但回归分析要求大样本,只有通过大量的数据才能得到量化的规律,这对很多无法得到或一时缺乏数据的实际问题的解决带来困难。
回归分析还要求样本有较好的分布规律,而很多实际情形并非如此。
例如,我国建国以来经济方面有几次大起大落,难以满足样本有较规律的分布要求。
因此,有了大量的数据也不一定能得到统计规律,甚至即使得到了统计规律,也并非任何情况都可以分析。
另外,回归分析不能分析因素间动态的关联程度,即使是静态,其精度也不高,且常常出现反常现象。
灰色系统理论提出了一种新的分析方法—关联度分析方法,即根据因素之间发展态势的相似或相异程度来衡量因素间关联的程度,它揭示了事物动态关联的特征与程度。
由于以发展态势为立足点,因此对样本量的多少没有过分的要求,也不需要典型的分布规律,计算量少到甚至可用手算,且不致出现关联度的量化结果与定性分析不一致的情况。
这种方法已应用到农业经济、水利、宏观经济等各方面,都取得了较好的效果。
灰色系统理论建模的主要任务是根据具体灰色系统的行为特征数据,充分开发并利用不多的数据中的显信息和隐信息,寻找因素间或因素本身的数学关系。
通常的办法是采用离散模型,建立一个按时间作逐段分析的模型。
但是,离散模型只能对客观系统的发展做短期分析,适应不了从现在起做较长远的分析、规划、决策的要求。
尽管连续系统的离散近似模型对许多工程应用来讲是有用的,但在某些研究领域中,人们却常常希望使用微分方程模型。
事实上,微分方程的系统描述了我们所希望辨识的系统内部的物理或化学过程的本质。
灰色系统理论首先基于对客观系统的新的认识。
尽管某些系统的信息不够充分,但作为系统必然是有特定功能和有序的,只是其内在规律并未充分外露。
有些随机量、无规则的干扰成分以及杂乱无章的数据列,从灰色系统的观点看,并不认为是不可捉摸的。
相反地,灰色系统理论将随机量看作是在一定范围内变化的灰色量,按适当的办法将原始数据进行处理,将灰色数变换为生成数,从生成数进而得到规律性较强的生成函数。
§2 关联分析大千世界里的客观事物往往现象复杂,因素繁多。
我们往往需要对系统进行因素分析,这些因素中哪些对系统来讲是主要的,哪些是次要的,哪些需要发展,哪些需要抑制,哪些是潜在的,哪些是明显的。
一般来讲,这些都是我们极为关心的问题。
事实上,因素间关联性如何、关联程度如何量化等问题是系统分析的关键和起点。
因素分析的基本方法过去主要采取回归分析等办法。
正如前一节指出的,回归分析的办法有很多欠缺,如要求大量数据、计算量大及可能出现反常情况等。
为克服以上弊病,本节采用关联度分析的办法来做系统分析。
作为一个发展变化的系统,关联分析实际上是动态过程发展态势的量化比较分析。
所谓发展态势比较,也就是系统各时期有关统计数据的几何关系的比较。
例1 某地区1977~1983 年总收入与养猪、养兔收入资料见表1。
表 1 例1的数据1977 1978 1979 1980 1981 1982 1983 养猪 10 15 16 24 38 40 50 养兔 3 2 12 10 22 18 20 总收入18202240444860根据表 1我们可以得到更为形象的图,如图 1所示。
图 1 例1变化趋势由上图易看出,养猪曲线与总收入曲线发展趋势比较接近,而与养兔曲线 相差较大,因此可以判断,该地区对总收入影响较直接的是养猪业,而不是养兔业。
很显然,几何形状越接近,关联程度也就越大。
当然,直观分析对于稍微复杂些的问题则显得难于进行。
因此,需要给出一种计算方法来衡量因素间关联程度的大小。
2.1 数据变换技术为保证建模的质量与系统分析的正确结果,对收集来的原始数据必须进行数据变换和处理,使其消除量纲和具有可比性。
定义1 设有序列 则称映射(函数)为序列x 到序列y 的数据变换。
常见的数据变换有如下几种。
1) 初值化变换,映射f 为()(())(),(1)0(1)x k f x k y k x x ==≠ (1)2) 均值化变换,映射f 为1()1(())(),()nk x k f x k y k x x k x n ====∑(2)3) 百分比变换,映射f 为()(())()max ()kx k f x k y k x k ==(3)4) 倍数变换,映射f 为()(())()min ()0min ()k kx k f x k y k x k x k ==≠,(4)5) 归一化变换,映射f 为00()(())(),0x k f x k y k x x ==> (5)6) 极差最大值化变换,映射f 为()min ()(())()max ()kkx k x k f x k y k x k -== (6)7) 区间值化变换,映射f 为()min ()(())()max ()min ()kkkx k x k f x k y k x k x k -==- (7)2.2 关联分析 定义2 选取参考数列00000{()|1,2,}{(1),(2),,()}x x k k n x x x n ===(8)其中k 表示时刻。
假设有m 个比较数列{()|1,2,}((1),(2),,()),1,2,,i i i i x x k k n x x x n i m i ====(9)则称()0000min min ()()max max ()()()()()max max ()()s s i ststi s stx t x t x t x t k x k x k x t x t ρξρ-+-=-+- (10)为比较数列x i 对参考数列0x 在k 时刻的关联系数,其中[]0,1ρ∈为分辨系数。
在式(10)中,称0min min ()()s stx t x t -(11)为两极最小差,称0max max ()()s stx t x t -(12)为两极最大差。
一般来讲,分辨系数ρ越大,分辨率越大;ρ越小,分辨率越小。
(10)式定义的关联系数是描述比较数列与参考数列在某时刻关联程度的一种指标,由于各个时刻都有一个关联数,因此信息显得过于分散,不便于比较,为此我们给出关联度。
定义3 称11()ni i k r k n ξ==∑(13)为数列x i 对参考数列0x 的关联度。
由(6)易看出,关联度是把各个时刻的关联系数集中为一个平均值,亦即把过于分散的信息集中处理。
下面我们来仔细研究一下关联度这个概念,并看一下它的应用。
例2 给出下述数列 0(20,22,40)x =,1(30,35,55)x =,2(40,45,43)x =,试求两极最小差与两级最大差。
解:先求两极最小差。
对于1=i , 所以 10)15,13,10(min =k对于2=i ,所以 3)3,23,20(min =k由于10)()(min 10=-k x k x k,3)()(min 20=-k x k x k,所以,0min(min ()())min(10,3)3i ikx k x k -==。
再求两极最大差: 所以23)23,15m ax ())()((m ax m ax 0==-k x k x i ki。
例2 求关联系数和关联度 求关联系数的步骤。
Step1. 先将数列作初值化处理。
即用每一个数列的第一个数)1(i x 除本身及其他数)(k x i ,这样即可使数列无量纲。
设已经给出已初值化的序列,如表 2所示。
Step 2.求差序列。
各时刻)(k x i 与)(0k x 的绝对差,如表3所示。
表. 2 数列作初值化处理表. 3 差序列Step 3.求两极最小差与最大差。
求两极最小差0|)()(|min 10=-k x k x k,0|)()(|min 20=-k x k x k,0|)()(|min 30=-k x k x k所以再求两极最大差1|)()(|max 10=-k x k x k,25.2|)()(|max 20=-k x k x k,8.2|)()(|max 30=-k x k x k所以Step 4.计算关联系数。
根据已求出的0))()(min (min 0=-k x k x i ki, 8.2))()(max (max 0=-k x k x i ki代入关联系数计算公式(10): 将表3的数据依次代入上式得:14.104.1)1(1=+=ε,955.04.1066.04.1)2(1=+=ε,894.04.1166.04.1)3(1=+=ε, 848.04.125.04.1)4(1=+=ε,6796.04.166.04.1)5(1=+=ε,1 1.4(6)0.5831 1.4ε==+所以同理,可求出)(2k ε与)(3k ε分别为通过上述计算,我们得到的是一个关联系数矩阵E ,)(ik E ε=的信息过于分散,不便于比较,为此有必要将各时刻关联系数集中为一个值,求平均值。