Hadoop大数据平台部署与应用
- 格式:pptx
- 大小:1.17 MB
- 文档页数:61

基于Hadoop的大数据技术研究与应用一、概述随着互联网的迅速发展和普及,大数据已经成为互联网行业中一个不可忽视的重要领域。
如何高效地对大数据进行收集、存储、分析和应用,是当前互联网行业中急需解决的问题。
基于Hadoop的大数据技术在这方面发挥了非常重要的作用,本文将从Hadoop的基本架构、数据存储、数据处理、数据安全等方面对基于Hadoop的大数据技术进行深入研究,并对其应用进行分析。
二、Hadoop基本架构Hadoop的基本架构主要由两个部分组成:HDFS和MapReduce。
其中,HDFS是Hadoop分布式文件系统,用于存储大量数据,具有高可靠性、高扩展性和高容错性等特点。
MapReduce是Hadoop的并行处理框架,用于将大量数据分解为多个小块,并将这些小块分配给不同的计算节点进行处理,最终将处理结果收集起来。
Hadoop中还有一个重要的组件是YARN,即“Yet Another Resource Negotiator”,它用于管理Hadoop的计算资源,包括CPU、内存等。
通过YARN,Hadoop可以更加灵活地利用计算资源,提高计算效率和数据处理速度。
三、数据存储在Hadoop中,数据存储和计算是分开的,数据存储在HDFS 中,而计算则由MapReduce执行。
由于HDFS是一个分布式文件系统,数据可以被分散存储在多个计算节点上,这样可以大大提高数据的可靠性和容错性。
Hadoop中的数据一般都是以键值对(key-value)形式进行存储,这种方式可以更方便地进行数据的查询和处理。
同时,Hadoop还支持多种数据存储格式,如文本、序列化、二进制、JSON、CSV 等,可以根据实际需求选择适合的存储格式。
四、数据处理Hadoop最重要的功能就是数据处理,它通过MapReduce框架实现对大规模数据的分布式处理。
其中,Map阶段主要用于对数据进行拆分和处理,Reduce阶段则用于将各个Map节点处理的结果进行汇总。


基于Hadoop的大数据处理平台搭建与部署一、引言随着互联网和信息技术的快速发展,大数据已经成为当今社会中不可或缺的重要资源。
大数据处理平台的搭建与部署对于企业和组织来说至关重要,而Hadoop作为目前最流行的大数据处理框架之一,其搭建与部署显得尤为重要。
本文将介绍基于Hadoop的大数据处理平台搭建与部署的相关内容。
二、Hadoop简介Hadoop是一个开源的分布式存储和计算框架,能够高效地处理大规模数据。
它由Apache基金会开发,提供了一个可靠、可扩展的分布式系统基础架构,使用户能够在集群中使用简单的编程模型进行计算。
三、大数据处理平台搭建准备工作在搭建基于Hadoop的大数据处理平台之前,需要进行一些准备工作: 1. 硬件准备:选择合适的服务器硬件,包括计算节点、存储节点等。
2. 操作系统选择:通常选择Linux系统作为Hadoop集群的操作系统。
3. Java环境配置:Hadoop是基于Java开发的,需要安装和配置Java环境。
4. 网络配置:确保集群内各节点之间可以相互通信。
四、Hadoop集群搭建步骤1. 下载Hadoop从Apache官网下载最新版本的Hadoop压缩包,并解压到指定目录。
2. 配置Hadoop环境变量设置Hadoop的环境变量,包括JAVA_HOME、HADOOP_HOME等。
3. 配置Hadoop集群编辑Hadoop配置文件,包括core-site.xml、hdfs-site.xml、mapred-site.xml等,配置各个节点的角色和参数。
4. 启动Hadoop集群通过启动脚本启动Hadoop集群,可以使用start-all.sh脚本启动所有节点。
五、大数据处理平台部署1. 数据采集与清洗在搭建好Hadoop集群后,首先需要进行数据采集与清洗工作。
通过Flume等工具实现数据从不同来源的采集,并进行清洗和预处理。
2. 数据存储与管理Hadoop提供了分布式文件系统HDFS用于存储海量数据,同时可以使用HBase等数据库管理工具对数据进行管理。

Hadoop在大数据处理中的应用第一章概述Hadoop是一种跨平台、开源的分布式计算框架,由Apache开发和维护。
它能够处理海量数据,帮助我们进行数据存储、管理和处理,并可以应用于数据挖掘、机器学习、网络搜索、自然语言处理等多个领域。
在大数据处理中,Hadoop起到了至关重要的作用。
第二章 Hadoop架构Hadoop的核心组件包括Hadoop Distributed File System(HDFS)和MapReduce计算模型。
HDFS是一种分布式文件系统,它能够存储海量数据,并能够在不同的计算节点上访问这些数据。
MapReduce计算模型是用于分布式处理数据的一种编程模型。
它能够将任务分解为多个子任务,并将它们分发到不同的计算节点进行计算,最后将结果汇总。
除了核心组件之外,Hadoop还包括许多其他组件,例如YARN资源管理器,它管理计算集群的资源分配。
此外,Hadoop还支持许多数据处理工具,例如Hive,用于SQL查询,Pig,用于数据处理和清洗,以及Spark,用于迭代式计算和数据分析。
第三章 Hadoop的优势Hadoop在大数据处理中的优势主要体现在以下几个方面:1.可扩展性:Hadoop可以通过添加更多的计算节点来扩展性能,因此可以处理多达数百TB的数据。
2.价格效益:开源和“共享”模式使得Hadoop成本低廉,同时也让更多的开发人员可以了解和使用这种技术。
3.可靠性:Hadoop在其HDFS上使用数据备份技术,从而提高了数据的可靠性和可恢复性。
4.灵活性:Hadoop可以与多种数据处理工具和技术集成,使其具有更广泛的适用性。
第四章 Hadoop的应用Hadoop已在许多领域得到广泛应用,包括以下几个方面:1.数据挖掘和分析:Hadoop可以帮助在海量数据中找到有价值的信息。
许多公司使用Hadoop进行大规模数据挖掘和分析,以生成报告和动态信息图表。
2.机器学习:Hadoop可以在分析海量数据的基础上学习新的数据模式,从而提高预测准确性,这在电子商务和金融领域非常有用。

hadoop大数据原理与应用Hadoop大数据原理与应用随着信息技术的飞速发展,大数据成为当今社会的热门话题之一。
而Hadoop作为大数据处理的重要工具,因其可靠性和高效性而备受关注。
本文将介绍Hadoop大数据的原理和应用。
一、Hadoop的原理Hadoop是一个开源的分布式计算框架,可以处理大规模数据集。
其核心组件包括Hadoop分布式文件系统(HDFS)和Hadoop分布式计算框架(MapReduce)。
HDFS是一个可靠的分布式文件系统,能够将大文件分成多个块并存储在不同的计算机节点上,以实现高容错性和高可用性。
而MapReduce是一种编程模型,将大规模数据集分成多个小的子集,然后在分布式计算集群上进行并行处理。
Hadoop的工作流程如下:首先,将大文件切分成多个块,并将这些块存储在不同的计算机节点上。
然后,在计算机节点上进行并行计算,每个节点都可以处理自己所存储的数据块。
最后,将每个节点的计算结果进行整合,得到最终的结果。
Hadoop的优势在于其可扩展性和容错性。
由于其分布式计算的特性,Hadoop可以轻松地处理大规模数据集。
同时,Hadoop还具有高容错性,即使某个计算机节点发生故障,整个计算任务也不会中断,系统会自动将任务分配给其他可用节点。
二、Hadoop的应用Hadoop广泛应用于大数据分析和处理领域。
以下是几个典型的应用场景:1.数据仓库:Hadoop可以存储和处理海量的结构化和非结构化数据,为企业提供全面的数据仓库解决方案。
通过使用Hadoop,企业可以轻松地将各种类型的数据整合到一个统一的平台上,从而更好地进行数据分析和挖掘。
2.日志分析:随着互联网的普及,各种网站和应用产生的日志数据越来越庞大。
Hadoop可以帮助企业对这些日志数据进行实时分析和处理,从而发现潜在的问题和机会。
3.推荐系统:在电子商务和社交媒体领域,推荐系统起着重要的作用。
Hadoop可以帮助企业分析用户的行为和偏好,从而提供个性化的推荐服务。

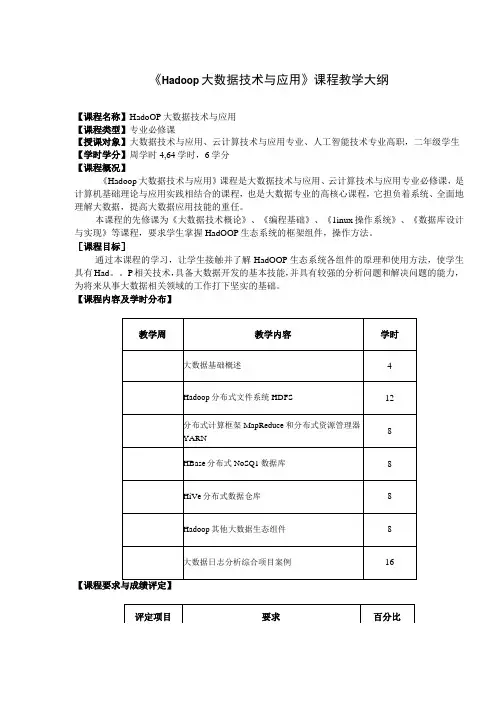
《Hadoop大数据技术与应用》课程教学大纲
【课程名称】HadoOP大数据技术与应用
【课程类型】专业必修课
【授课对象】大数据技术与应用、云计算技术与应用专业、人工智能技术专业高职,二年级学生【学时学分】周学时4,64学时,6学分
【课程概况】
《Hadoop大数据技术与应用》课程是大数据技术与应用、云计算技术与应用专业必修课,是计算机基础理论与应用实践相结合的课程,也是大数据专业的高核心课程,它担负着系统、全面地理解大数据,提高大数据应用技能的重任。
本课程的先修课为《大数据技术概论》、《编程基础》、《1inux操作系统》、《数据库设计与实现》等课程,要求学生掌握HadOOP生态系统的框架组件,操作方法。
[课程目标]
通过本课程的学习,让学生接触并了解HadOOP生态系统各组件的原理和使用方法,使学生具有Had。
P相关技术,具备大数据开发的基本技能,并具有较强的分析问题和解决问题的能力,为将来从事大数据相关领域的工作打下坚实的基础。
【课程内容及学时分布】
【使用教材及教学参考书】
使用教材:《Hadoop生态系统及开发》,邓永生、刘铭皓等主编,西安电子
科技大学出版社,2023年
大纲执笔人:
大纲审定人:
年月日。

基于Hadoop的大数据处理平台设计与实现一、引言随着互联网的快速发展和智能设备的普及,大数据已经成为当今社会中不可忽视的重要资源。
大数据处理平台作为支撑大数据应用的基础设施,扮演着至关重要的角色。
本文将围绕基于Hadoop的大数据处理平台的设计与实现展开讨论,探讨其架构、关键技术和实际应用。
二、Hadoop简介Hadoop是一个开源的分布式计算平台,由Apache基金会开发和维护。
它主要包括Hadoop Distributed File System(HDFS)和MapReduce两个核心模块。
HDFS用于存储大规模数据集,而MapReduce 则用于并行处理这些数据。
Hadoop具有高可靠性、高扩展性和高效率等特点,被广泛应用于大数据领域。
三、大数据处理平台架构设计1. 架构概述基于Hadoop的大数据处理平台通常采用分布式架构,包括数据采集、数据存储、数据处理和数据展示等模块。
其中,数据采集模块负责从各种数据源中收集数据,数据存储模块负责将数据存储到分布式文件系统中,数据处理模块负责对数据进行分析和计算,数据展示模块则负责将处理结果可视化展示给用户。
2. 架构组件数据采集组件:包括日志收集器、消息队列等工具,用于实时或批量地采集各类数据。
数据存储组件:主要使用HDFS作为底层存储,保证数据的可靠性和高可用性。
数据处理组件:使用MapReduce、Spark等计算框架进行数据处理和分析。
数据展示组件:通过BI工具或Web界面展示处理结果,帮助用户理解和分析数据。
四、关键技术探讨1. 数据存储技术在基于Hadoop的大数据处理平台中,HDFS是最常用的分布式文件系统之一。
它通过将大文件切分成多个块,并在集群中多个节点上进行存储,实现了高容错性和高可靠性。
2. 数据处理技术MapReduce是Hadoop中最经典的并行计算框架之一,通过将任务分解成Map和Reduce两个阶段,并在多个节点上并行执行,实现了高效的大规模数据处理能力。

Hadoop大数据分析原理与应用随着互联网的不断发展,数据量越来越大,因此如何高效地处理这些数据成为了互联网公司不可或缺的一环。
而Hadoop作为分布式计算平台,被越来越多的公司所采用。
本文将从Hadoop的原理、应用以及优缺点三个方面进行探讨。
一、Hadoop的原理Hadoop作为一个分布式计算平台,主要运用了HDFS分布式文件系统和MapReduce计算模型。
其中HDFS将大文件分割成小块,分别保存在多个磁盘上,并且自动备份以实现容错。
而MapReduce计算模型则是将大数据分割成小数据块,分发给多个节点完成并行处理,最终将结果合并输出。
因此,Hadoop的核心思想在于将一个任务分解成多个小任务,再将这些小任务分配给多个计算节点进行并行计算。
二、Hadoop的应用1、网站日志分析一些大型的网站需要统计用户行为及网站流量数据,这就需要用到Hadoop进行大数据处理。
Hadoop可以通过分析网站流量数据,帮助网站拓展营销渠道,优化营销策略,提高网站的用户体验度和粘性,进而提高网站收益。
2、金融数据分析目前,许多公司更倾向于使用Hadoop分析金融数据。
Hadoop可以高效地处理非常庞大的金融数据,不仅能加快分析业务过程,同时还能降低操作成本。
此外,Hadoop也可以对贷款审批、投资决策等方面提供支持。
3、社交媒体分析在社交媒体环境下,海量的社交媒体数据需要进行处理。
而使用Hadoop可以进行快速的社交媒体分析,以得出针对特定人群的市场趋势、方法和意见等。
此外,利用Hadoop的技术,还可以对社交媒体数据生成精细化报告,以用于组织创造、推广营销、客户关系管理等方面的决策。
三、Hadoop的优缺点优点:1、分布式计算能力。
2、横向扩展能力。
3、容错能力强。
4、可以处理极大数据。
缺点:1、要求专业技能。
2、运行平台不太稳定。
3、运行效率不高,容易造成数据流不畅。
四、结语随着企业对效率和数据制造便利性不断的要求提高,Hadoop成为了企业处理大数据的绝佳选择。
Hadoop平台搭建与应用教案靠、高性能、分布式和面向列的动态模式数据库。
⑤ ZooKeeper(分布式协作服务):其用于解决分布式环境下的数据管理问题,主要是统一命名、同步状态、管理集群、同步配置等。
⑥ Sqoop(数据同步工具):Sqoop是SQL-to-Hadoop的缩写,主要用于在传统数据库和Hadoop之间传输数据。
⑦ Pig(基于Hadoop的数据流系统):Pig的设计动机是提供一种基于MapReduce 的Ad-Hoc(计算在query时发生)数据分析工具。
⑧ Flume(日志收集工具):Flume是Cloudera开源的日志收集系统,具有分布式、高可靠、高容错、易于定制和扩展的特点。
⑨ Oozie(作业流调度系统):Oozie是一个基于工作流引擎的服务器,可以运行Hadoop的MapReduce和Pig任务。
⑩ Spark(大数据处理通用引擎):Spark提供了分布式的内存抽象,其最大的特点就是快,是Hadoop MapReduce处理速度的100倍。
YARN(另一种资源协调者):YARN是一种新的Hadoop资源管理器,它是一个通用资源管理系统,可为上层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处。
Kafka(高吞吐量的分布式发布订阅消息系统):Kafka可以处理消费者规模的网站中的所有动作流数据。
任务1.1 认知大数据,完成系统环境搭建(1)安装CentOS系统(确保CentOS系统版本在7及以上,以便配合后续Docker 安装)。
①在VMware中设置CentOS 7镜像,进入后选择第一项安装CentOS 7,如图1-8所示。
②在新打开页面中设置时间(DATE&TIME),分配磁盘(INSTALLATION DESTINATION)和网络设置(NETWORK&HOST NAME)等,如图1-9所示。
③单击“INSTALLATION DESTINATION”链接,在打开的界面中选择“I will configure partitioning”选项,然后单击“Done”按钮,跳转到分配磁盘页面即可进行磁盘分配,如图1-10所示。

基于Hadoop的大数据处理与分析平台搭建与优化一、引言随着互联网和物联网技术的快速发展,大数据已经成为当今社会中不可或缺的一部分。
大数据处理与分析平台的搭建与优化对于企业来说至关重要。
Hadoop作为目前最流行的大数据处理框架之一,其在大数据领域有着广泛的应用。
本文将重点介绍基于Hadoop的大数据处理与分析平台的搭建与优化。
二、Hadoop简介Hadoop是一个开源的分布式计算平台,可以对大规模数据进行存储和处理。
它包括Hadoop Distributed File System(HDFS)和MapReduce两个核心组件。
HDFS用于存储数据,而MapReduce用于处理数据。
除此之外,Hadoop生态系统还包括Hive、Pig、HBase、Spark等工具和框架,为用户提供了丰富的功能和工具。
三、大数据处理与分析平台搭建1. 硬件环境准备在搭建大数据处理与分析平台之前,首先需要准备适当的硬件环境。
通常情况下,需要考虑服务器数量、内存大小、存储容量等因素。
同时,为了保证系统的稳定性和性能,建议采用高可靠性的硬件设备。
2. 软件环境准备在硬件环境准备完成后,接下来需要安装和配置Hadoop及其相关组件。
可以选择使用Apache Hadoop或者Cloudera、Hortonworks等发行版。
在安装过程中,需要注意版本兼容性以及各组件之间的依赖关系。
3. 配置Hadoop集群配置Hadoop集群是搭建大数据处理与分析平台的关键步骤之一。
需要配置主节点(NameNode、ResourceManager)和从节点(DataNode、NodeManager),并确保集群中各节点之间可以正常通信。
4. 数据导入与处理在搭建好Hadoop集群后,可以开始导入数据并进行处理。
可以通过Sqoop将关系型数据库中的数据导入到HDFS中,也可以通过Flume实时收集日志数据。
同时,可以编写MapReduce程序或使用Spark进行数据处理和分析。
基于Hadoop的大数据分析与处理应用研究一、引言随着互联网的快速发展和智能设备的普及,海量数据的产生和积累已经成为一种常态。
如何高效地处理和分析这些海量数据,挖掘出其中蕴藏的有价值信息,成为了各行各业面临的重要挑战。
在这样的背景下,大数据技术应运而生,而Hadoop作为大数据处理的重要工具之一,发挥着至关重要的作用。
二、Hadoop简介Hadoop是一个开源的分布式计算平台,可以对大规模数据进行存储和处理。
它由Apache基金会开发,采用Java编程语言编写。
Hadoop的核心包括Hadoop Distributed File System(HDFS)和MapReduce。
HDFS是一种高度容错性的文件系统,适合存储大规模数据;MapReduce是一种编程模型,用于将任务分解成小块并在集群中并行执行。
三、大数据分析与处理应用1. 数据采集在大数据分析与处理应用中,首先需要进行数据采集。
数据可以来自各种来源,如传感器、日志文件、社交媒体等。
通过Hadoop可以实现对这些数据的实时或批量采集,并将其存储在HDFS中。
2. 数据清洗与预处理采集到的原始数据往往存在噪声和不完整性,需要进行清洗和预处理。
Hadoop提供了丰富的工具和库,如Apache Hive、Apache Pig 等,可以帮助用户对数据进行清洗、转换和筛选,以便后续分析使用。
3. 数据存储与管理Hadoop的HDFS具有高可靠性和可扩展性,适合存储大规模数据。
此外,Hadoop还支持多种存储格式,如SequenceFile、Avro等,用户可以根据需求选择合适的存储格式。
4. 数据分析与挖掘通过MapReduce等计算框架,用户可以对存储在HDFS中的数据进行复杂的计算和分析。
例如,可以实现词频统计、图像处理、机器学习等应用。
同时,Hadoop还支持SQL查询,用户可以通过类似于SQL的语法对数据进行查询和分析。
5. 可视化与展示大数据分析结果往往需要以直观的方式展示给用户。
hadoop大数据技术原理与应用
Hadoop是由Apache基金会在2006年提出的分布式处理系统。
它由一系列技术和系统所组成,包括Hadoop集群、Hadoop Distributed File System (HDFS)、MapReduce任务和JobTracker以及基于Apache HBase的非关系型数据库技术。
Hadoop集群是一群Hadoop包所组成的虚拟机,每个机器都具有它所需要和管理Hadoop系统所需要的功能。
HDFS是Hadoop的核心,它可以将数据存储在集群中的不同服务器上。
MapReduce是一种编程模型,可以用来在分布式集群上大规模的运行任务,开发和优化并行应用的表示方法。
JobTracker是Hadoop集群的集群管理器,负责管理任务。
HBase是基于Apache的非关系型数据库技术,可以支持大量的结构化数据以及查询和操纵它们。
Hadoop技术可以将海量数据存储在分布式系统中,然后再快速有效地处理这些数据。
它可以执行更复杂的计算,不受台式机和服务器硬件限制,同时可靠。
它也可以节省机器资源和购置费用,因为可以用更少的服务器来支撑更多的工作负载。
由于Hadoop的易用性,它被许多行业所采用,用来处理和分析数据,也可以
用来进行大规模的科学和工程类的计算。
它也可以在搜索引擎以及商业数据挖掘方面得到应用。
⼤数据Hadoop学习之搭建Hadoop平台(2.1) 关于⼤数据,⼀看就懂,⼀懂就懵。
⼀、简介 Hadoop的平台搭建,设置为三种搭建⽅式,第⼀种是“单节点安装”,这种安装⽅式最为简单,但是并没有展⽰出Hadoop的技术优势,适合初学者快速搭建;第⼆种是“伪分布式安装”,这种安装⽅式安装了Hadoop的核⼼组件,但是并没有真正展⽰出Hadoop的技术优势,不适⽤于开发,适合学习;第三种是“全分布式安装”,也叫做“分布式安装”,这种安装⽅式安装了Hadoop的所有功能,适⽤于开发,提供了Hadoop的所有功能。
⼆、介绍Apache Hadoop 2.7.3 该系列⽂章使⽤Hadoop 2.7.3搭建的⼤数据平台,所以先简单介绍⼀下Hadoop 2.7.3。
既然是2.7.3版本,那就代表该版本是⼀个2.x.y发⾏版本中的⼀个次要版本,是基于2.7.2稳定版的⼀个维护版本,开发中不建议使⽤该版本,可以使⽤稳定版2.7.2或者稳定版2.7.4版本。
相较于以前的版本,2.7.3主要功能和改进如下: 1、common: ①、使⽤HTTP代理服务器时的⾝份验证改进。
当使⽤代理服务器访问WebHDFS时,能发挥很好的作⽤。
②、⼀个新的Hadoop指标接收器,允许直接写⼊Graphite。
③、与Hadoop兼容⽂件系统(HCFS)相关的规范⼯作。
2、HDFS: ①、⽀持POSIX风格的⽂件系统扩展属性。
②、使⽤OfflineImageViewer,客户端现在可以通过WebHDFS API浏览fsimage。
③、NFS⽹关接收到⼀些可⽀持性改进和错误修复。
Hadoop端⼝映射程序不再需要运⾏⽹关,⽹关现在可以拒绝来⾃⾮特权端⼝的连接。
④、SecondaryNameNode,JournalNode和DataNode Web UI已经通过HTML5和Javascript进⾏了现代化改造。
3、yarn: ①、YARN的REST API现在⽀持写/修改操作。
Hadoop大数据开发基础教案-Hadoop集群的搭建及配置教案教案章节一:Hadoop简介1.1 课程目标:了解Hadoop的发展历程及其在大数据领域的应用理解Hadoop的核心组件及其工作原理1.2 教学内容:Hadoop的发展历程Hadoop的核心组件(HDFS、MapReduce、YARN)Hadoop的应用场景1.3 教学方法:讲解与案例分析相结合互动提问,巩固知识点教案章节二:Hadoop环境搭建2.1 课程目标:学会使用VMware搭建Hadoop虚拟集群掌握Hadoop各节点的配置方法2.2 教学内容:VMware的安装与使用Hadoop节点的规划与创建Hadoop配置文件(hdfs-site.xml、core-site.xml、yarn-site.xml)的编写与配置2.3 教学方法:演示与实践相结合手把手教学,确保学生掌握每个步骤教案章节三:HDFS文件系统3.1 课程目标:理解HDFS的设计理念及其优势掌握HDFS的搭建与配置方法3.2 教学内容:HDFS的设计理念及其优势HDFS的架构与工作原理HDFS的搭建与配置方法3.3 教学方法:讲解与案例分析相结合互动提问,巩固知识点教案章节四:MapReduce编程模型4.1 课程目标:理解MapReduce的设计理念及其优势学会使用MapReduce解决大数据问题4.2 教学内容:MapReduce的设计理念及其优势MapReduce的编程模型(Map、Shuffle、Reduce)MapReduce的实例分析4.3 教学方法:互动提问,巩固知识点教案章节五:YARN资源管理器5.1 课程目标:理解YARN的设计理念及其优势掌握YARN的搭建与配置方法5.2 教学内容:YARN的设计理念及其优势YARN的架构与工作原理YARN的搭建与配置方法5.3 教学方法:讲解与案例分析相结合互动提问,巩固知识点教案章节六:Hadoop生态系统组件6.1 课程目标:理解Hadoop生态系统的概念及其重要性熟悉Hadoop生态系统中的常用组件6.2 教学内容:Hadoop生态系统的概念及其重要性Hadoop生态系统中的常用组件(如Hive, HBase, ZooKeeper等)各组件的作用及相互之间的关系6.3 教学方法:互动提问,巩固知识点教案章节七:Hadoop集群的调优与优化7.1 课程目标:学会对Hadoop集群进行调优与优化掌握Hadoop集群性能监控的方法7.2 教学内容:Hadoop集群调优与优化原则参数调整与优化方法(如内存、CPU、磁盘I/O等)Hadoop集群性能监控工具(如JMX、Nagios等)7.3 教学方法:讲解与案例分析相结合互动提问,巩固知识点教案章节八:Hadoop安全与权限管理8.1 课程目标:理解Hadoop安全的重要性学会对Hadoop集群进行安全配置与权限管理8.2 教学内容:Hadoop安全概述Hadoop的认证与授权机制Hadoop安全配置与权限管理方法8.3 教学方法:互动提问,巩固知识点教案章节九:Hadoop实战项目案例分析9.1 课程目标:学会运用Hadoop解决实际问题掌握Hadoop项目开发流程与技巧9.2 教学内容:真实Hadoop项目案例介绍与分析Hadoop项目开发流程(需求分析、设计、开发、测试、部署等)Hadoop项目开发技巧与最佳实践9.3 教学方法:案例分析与讨论团队协作,完成项目任务教案章节十:Hadoop的未来与发展趋势10.1 课程目标:了解Hadoop的发展现状及其在行业中的应用掌握Hadoop的未来发展趋势10.2 教学内容:Hadoop的发展现状及其在行业中的应用Hadoop的未来发展趋势(如Big Data生态系统的演进、与大数据的结合等)10.3 教学方法:讲解与案例分析相结合互动提问,巩固知识点重点和难点解析:一、Hadoop生态系统的概念及其重要性重点:理解Hadoop生态系统的概念,掌握生态系统的组成及相互之间的关系。
基于Hadoop的大数据处理与分析平台设计与实现一、引言随着互联网的快速发展和智能化技术的不断进步,大数据已经成为当今社会中不可或缺的重要资源。
大数据的处理和分析对于企业决策、市场营销、风险控制等方面起着至关重要的作用。
在这样的背景下,基于Hadoop的大数据处理与分析平台设计与实现显得尤为重要。
二、Hadoop简介Hadoop是一个开源的分布式计算平台,可以对大规模数据进行存储和处理。
它由Apache基金会开发,采用Java编程语言。
Hadoop主要包括Hadoop Common、Hadoop Distributed File System(HDFS)、Hadoop YARN和Hadoop MapReduce等模块。
三、大数据处理与分析平台设计1. 架构设计在设计基于Hadoop的大数据处理与分析平台时,首先需要考虑整体架构。
典型的架构包括数据采集层、数据存储层、数据处理层和数据展示层。
其中,数据采集层负责从各个数据源收集数据,数据存储层用于存储原始和处理后的数据,数据处理层包括数据清洗、转换和计算等功能,数据展示层则提供可视化的报表和图表展示。
2. 数据采集与存储在大数据处理平台中,数据采集是至关重要的一环。
可以通过Flume、Kafka等工具实现对各类数据源的实时采集。
而数据存储方面,HDFS是Hadoop中用于存储海量数据的分布式文件系统,具有高可靠性和高扩展性。
3. 数据处理与计算Hadoop MapReduce是Hadoop中用于并行计算的编程模型,通过Map和Reduce两个阶段实现对大规模数据的处理和计算。
同时,Hadoop YARN作为资源管理器,可以有效管理集群中的资源,并提供任务调度功能。
4. 数据展示与应用为了更好地展示和利用处理后的数据,可以使用Apache Hive、Apache Pig等工具进行SQL查询和复杂分析操作。
此外,通过搭建BI系统或者开发自定义应用程序,可以实现对数据进行更深入的挖掘和应用。