ucinet软件使用简介
- 格式:ppt
- 大小:2.75 MB
- 文档页数:29

u c i n e t软件快速入门上手网络分析软件(总7页)-CAL-FENGHAI.-(YICAI)-Company One1-CAL-本页仅作为文档封面,使用请直接删除本指南提供了一种快速介绍UCINET的使用说明。
假定软件已经和数据安装在C:\Program Files\AnalyticTechnologies\Ucinet 6\DataFiles的文件夹中,被留作为默认目录。
这个子菜单按钮涉及到UCINET所有程序,它们被分为文件,数据、转换、工具、网络、视图、选择和帮助。
值得注意的是,这个按钮的下方,都是在子菜单中的这些调用程序的快捷键。
在底部出现的默认目录是用于UCINET收集任何数据和存储任何文件(除非另外说明),目录可以通过点击向右这个按钮被修改。
运行的一种程序为了运行UCINET程序,我们通常需要指定一个UCINET数据集,给出一些参数。
在可能的情况下,UCINET选用一些默认参数,用户可以修改 (如果需要)。
注意UCINET伴随着大量的标准数据集,而这些将会放置在默认值目录。
当一个程序被运行,有一些文本输出,它们会出现在屏幕上,而且通常UCINET的数据文件包含数据结果,这些结果又将会被储存在默认目录中。
我们将运行度的权重的程序来计算在一个称为TARO的标准UCINET数据集的全体参与者的权重。
首先我们强调网络>权重>度,再点击如果你点击了帮助按钮,,一个帮助界面就会在屏幕上打开,看起来像这样。
帮助文件给出了一个程序的详细介绍,会解释参数并描述在记录文件和屏幕上显示出来的输出信息。
关闭帮助文件,或者通过点击pickfile按钮或者输入名称选择TARO分析数据,如下。
现在点击OK运行程序验证。
这是一个文本文件给出的程序结果。
注意你可以向下滚动看到更多的文件。
这个文件可以保存或复制、粘贴到一个word处理包中。
当UCINET被关闭时,这个文件将会被删除。
关闭此文件。
注意,当这个程序运行时,我们也创建了一个名为FreemanDegree的新的UCINET 文档。

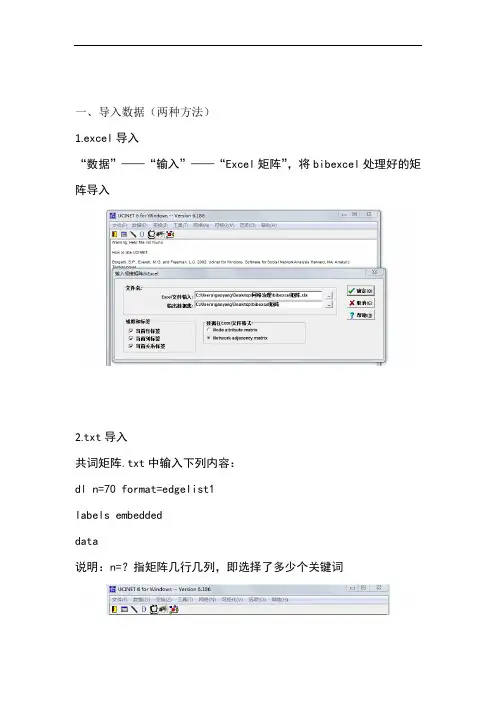
一、导入数据(两种方法)
1.excel导入
“数据”——“输入”——“Excel矩阵”,将bibexcel处理好的矩阵导入
2.txt导入
共词矩阵.txt中输入下列内容:
dl n=70 format=edgelist1
labels embedded
data
说明:n=?指矩阵几行几列,即选择了多少个关键词
“数据”——“输入”——“DL(D)”,选中共词矩阵.txt
点击“确定”,弹出下图所示的文本文档,并在输出路径所在地生成 .##h和 .##d文件。
二、可视化数据分析
点击可视化—netdraw,然后弹出netdraw界面
选择file—open—ucinet dataset—network,然后弹出如下界面
选择生成的 .##h文件,点击ok,然后出现如下界面:
然后进行中心度分析,选择analysis—centrality measures,然后在弹出界面的set node size by 下输入degree,点击 ok
然后就会出现依据中心度大小进行显示的节点情况
三、小团体分析
去箭头
点击可视化—netdraw,然后弹出netdraw界面
选择file—open—ucinet dataset—network,然后弹出如下界面
选择生成的 .##h文件,点击ok,然后出现如下界面:
点击右侧小箭头
调整一下每个节点的位置,让关键词都露出来,图要美观
————AnalysisSubgroupFactions
弹出小窗口
数字挨个试,出现转折时,选择转折前的那个数字
8时,Fitness=218;9时,Fitness=222,出现转折,选择数字“”8共有8个小团体。


A Brief Guide to Using NetDraw1NetDraw is a program for drawing social networks.Overview of FeaturesMultiple Relations. You can read in multiple relations on the same nodes, and switch between them (or combine them) easily.Valued Relations. If you read in valued data, you can sequentially “step” through different levels of dichotomization, effectively selecting only strong ties, only weak ties, etc. In addition, you have the option of letting the thickness of lines correspond to strength of ties.Node Attributes. The program makes it convenient to read in multiple node attributes for use in setting colors and sizes of nodes (as well as rims, labels, etc.). In addition, the program makes it easy to turn on and off groups of nodes defined by a variable, such as males or members of a given organization. If the attributes are read in using the VNA data format (see below), they can be textual in addition to numeric. This means that instead of coding location as numeric codes 1, 2, 3, etc, you can simply write Boston, New York, Tokyo …Analysis. A limited set of analytical procedures are included, such as the identification of isolates, components, k-cores, cut-points and bi-components (blocks).2-Mode Data. NetDraw can read 2-mode data, such as the Davis, Gardner and Gardner data and automatically create a bipartite representation of it.Data Formats. The program reads Ucinet datasets (the ##h and ##d files), Ucinet DL text files, Pajek files (net, clu and vec), and the program’s own VNA text file format, which allows the user to combine node attributes with tie information.Saving Data. Using the VNA file format, the program can save a network along with its spatial configuration, node colors, shapes, etc. so that the next time you open the file, the network looks exactly like it looked before. The program can also save data as Pajek net and clu files, and Ucinet datasets (both networks and attributes).Saving Pictures. Network diagrams can be saved as bitmaps (.bmp), jpegs (.jpg), windows metafiles (.wmf) and enhanced metafiles (.emf). In addition, the program exports to Pajek and Mage.1 Downloaded from: /downloadnd.htm, February 18, 2011.Printing. There is a Print button. This is very good for creating publication-quality diagrams because the results utilize the full resolution of the printer. (When you save an image like a bitmap to disk and insert into a document and then print that, the image resolution is no better than your screen’s.)Appearance Options. A full range of options is implemented, including the ability to change sizes and colors of nodes, node-rims, labels, lines and background. Different node shapes are not yet implemented. You can also rotate, flip, shift, resize and zoom configurations.Layout. Two basic kinds of layouts are implemented at present: a circle and an MDS/ spring embedding based on geodesic distance. The MDS includes options for exaggerating clustering, biasing toward equal-length edges, and turning on/off node-repulsion.Getting StartedSuppose you have a network currently stored as a Ucinet dataset. To draw it in network, just press the Open File button on the toolbar and select the file. The rest is automatic. Here is an example of drawing a file called campnet:Now suppose you have some information about each person that you would like to use to in the display. You might enter the information in a text file called CampAttribs.txt (e.g., enter it in Excel and Save As text file) in the following format:*node dataid gender role betweennessHOLLY female participant 78.33333588BRAZEY female participant 0CAROL female participant 1.333333373PAM female participant 32.5PAT female participant 39.5JENNIE female participant 6.333333492PAULINE female participant 12.5ANN female participant 0.5MICHAEL male participant 58.83333206BILL male participant 0LEE male participant 5DON male participant 16.33333397JOHN male participant 0HARRY male participant 2.333333254GERY male instructor 54.66666794STEVE male instructor 16.83333397BERT male instructor 13.66666698RUSS male instructor 47.33333206Note that the values do not need to be numeric. They should be separated from each other by a comma, space or tab (and values that contain spaces should be enclosed in quotes as in “Bill Smith”).To read this file, go to File|Open|VNA|Attributes and select the file. This will read the file and open the Node Selector window, which looks like this:Using this window you can select an attribute (ID is selected by default), and then use that click on and off nodes with specific properties, such as females or instructors.Now suppose you want to change the colors of nodes to reflect a node attribute, such as wanting to paint men blue and women red. Go to Properties|Nodes|Colors|By Attribute. A dialogue box will open which lets you choose the attribute (gender) and then choose the color of each gender. The dialogue box looks like this:You might also want to change the shape of the nodes to reflect the role that person plays in the group (as indicated by the Role variable). To do this, go toProperties|Nodes|Shape|by attribute, which opens a dialogue box very similar to the color box, except instead of colors, there are shapes. Something similar can be done with the size of nodes.After setting each gender to the desired color, each role to desired shape, and making theVNA Data FormatThe VNA data format allows the user to store not only network data but also attributes of the nodes, along with information about how to display them (color, size, etc.). A key feature of VNA attribute data is that textual data is permitted. In other words, instead of using numeric codes, the gender variable can have values like “male” and “female”.Here is a short example of a vna file:*node dataID name gender agej101 joe male 56w067 wendy female 23b303 bill male 48*tie datafrom to friends advicej101 w067 1 3w067 j101 0 1j101 b303 1 2w067 b303 0 6VNA files are ordinary text files. They consist of sections called “star sections”. Not every file has to have every possible star section, and sections can be in any order. At the moment, there are 3 possible star sections (soon to be 6). They are:*node data*node properties*tie dataA description of each follows. At the end of this document is a complete VNA file.Node Data SectionThe Node Data section contains variables that describe the actors in a network. Here is an example:*node dataid gender role betweennessHOLLY female participant 78.33333588BRAZEY female participant 0CAROL female participant 1.333333373PAM female participant 32.5PAT female participant 39.5JENNIE female participant 6.333333492PAULINE female participant 12.5ANN female participant 0.5MICHAEL male participant 58.83333206BILL male participant 0LEE male participant 5DON male participant 16.33333397JOHN male participant 0HARRY male participant 2.333333254GERY male instructor 54.66666794STEVE male instructor 16.83333397BERT male instructor 13.66666698RUSS male instructor 47.33333206The first line (“*node data”) identifies the section as containing node data.The line following “*node data” is a list of variable names. The first variable is assumed to be a unique identifier. It can be numeric or text, as long as each node has a distinct value. If any value (for any variable) contains spaces or other extraneous punctuation, it should be enclosed in full quotes, as in:“John Barrymore”Following the line of variable names is the actual data corresponding to those variables. All following lines are assumed to be node data until a new star command is read or the end of the file is reached.Node Properties SectionThe node properties section is very similar to the node data section, except that the variables all refer to display characteristics of the nodes, such as size, color, and shape. Here is an example:*Node propertiesID x y color shape size"HOLLY" 1094 415 255 1 10"BRAZEY" 84 742 255 1 10"CAROL" 1224 996 255 1 10"PAM" 1249 722 255 1 10"PAT" 1291 551 255 1 10"JENNIE" 1518 686 255 1 10"PAULINE" 1051 928 255 1 10"ANN" 1330 876 255 1 10"MICHAEL" 791 365 255 1 10"BILL" 785 52 255 1 10"LEE" 80 619 255 1 10"DON" 994 195 255 1 10"JOHN" 776 894 255 1 10"HARRY" 945 214 255 1 10"GERY" 600 578 255 1 10"STEVE" 338 636 255 1 10"BERT" 282 897 255 1 10"RUSS" 543 814 255 1 10As before, the first line (“*node properties”) identifies the section as containing node properties. The line following “*node properties” is a list of variable names. Aside from the first variable, which must be ID, all the other variables can be in any order, and none of them have to be there at all. But if they are present, they must be named exactly as shown in the example. Variable “X” is the horizontal coordinate of a node. Variable “Y” is the vertical coordinate (the 0,0 point is the top left corner of the drawing area). Variable “Color” is the color of the node (in hexadecimal). Variable “Shape” is the shape of the node (circle, square, up-triangle, etc.). Variable “Size” is the size of the nodes in points. Finally, (not shown in the example), the variable “Shortlabel” gives the label for each node (if not given, the program uses the ID code).Following the line of variable names is the actual data corresponding to those variables. Tie DataThe Tie Data section contains dyadic data – the presence/absence or strength of tie among pairs of nodes on one or more relations. Here is an example:*Tie datafrom to talk strengthHOLLY PAM 1 1HOLLY PAT 1 3HOLLY DON 1 2BRAZEY LEE 1 1BRAZEY STEVE 1 2BRAZEY BERT 1 3CAROL PAM 1 1CAROL PAT 1 2CAROL PAULINE 1 3PAM JENNIE 1 3PAM PAULINE 1 1…The second line contains the list of dyadic variables (relations), except that the first two variables are necessarily called “from” and “to” and identify the nodes that are tied. In this example, there are two relations (called “talk” and “strength”).Following the variable names are the actual ties. A data line such as “Holly Pam 1 1” indicates that Holly talks to Pam and their relationship has strength 1. Values of zero are assumed to indicate the absence of a tie on a given relation.Putting it all togetherNot all possible sections need to be in a given file – just one will do. Here is an example of a file with all sections:*Node dataID, gender, role, betweennessHOLLY female participant 78.33333588BRAZEY female participant 0CAROL female participant 1.333333373PAM female participant 32.5PAT female participant 39.5JENNIE female participant 6.333333492PAULINE female participant 12.5ANN female participant 0.5MICHAEL male participant 58.83333206BILL male participant 0LEE male participant 5DON male participant 16.33333397JOHN male participant 0HARRY male participant 2.333333254GERY male instructor 54.66666794STEVE male instructor 16.83333397BERT male instructor 13.66666698RUSS male instructor 47.33333206*Node propertiesID x y color shape size shortlabelHOLLY 1160 271 255 1 10 HOLLYBRAZEY 1214 577 255 1 10 BRAZEYCAROL 671 612 255 1 10 CAROLPAM 985 127 255 1 10 PAMPAT 802 402 255 1 10 PATJENNIE 729 187 255 1 10 JENNIEPAULINE 69 590 255 1 10 PAULINEANN 877 818 255 1 10 ANNMICHAEL 182 224 255 1 10 MICHAELBILL 380 137 255 1 10 BILLLEE 617 44 255 1 10 LEEDON 281 656 255 1 10 DONJOHN 617 839 255 1 10 JOHNHARRY 382 410 255 1 10 HARRYGERY 1051 706 255 1 10 GERYSTEVE 64 394 255 1 10 STEVEBERT 348 812 255 1 10 BERTRUSS 1176 426 255 1 10 RUSS*Tie datafrom to friends strengthHOLLY PAM 1 1PAT HOLLY 1 2PAULINE PAT 1 2JOHN RUSS 1 3HARRY HOLLY 1 2HARRY MICHAEL 1 1BERT RUSS 1 3RUSS GERY 1 1RUSS STEVE 1 3RUSS BERT 1 2HOLLY BRAZEY 0 7 HOLLY CAROL 0 17 BRAZEY PAULINE 0 7 BRAZEY ANN 0 6 BRAZEY MICHAEL 0 15 PAM MICHAEL 0 9 PAM BILL 0 16PAM LEE 0 13 JENNIE BRAZEY 0 8 PAULINE JENNIE 0 5 PAULINE ANN 0 4 ANN PAT 0 7ANN MICHAEL 0 9 BILL LEE 0 10DON ANN 0 12DL Data FormatThe DL protocol is a flexible language for describing data and itself encompasses a number of different formats. Three of these formats – nodelist, edgelist and fullmatrix – are described here.A sample nodelist file called borg4cent.txt is provided with the program.Nodelist FormatThis is usually the most efficient format. Just create a text file using any word processor (make sure to remember to save as text). Enter the data in the following format:dln = 50format = nodelistdata:1 7 8 23 19 21 49 62 6…The "DL" at the top is required and identifies the type of file. The "n=50" tells program to expect up to 50 distinct nodes. The "format = nodelist" tells the program to expect the node list format (as opposed to edge list and full matrix). The word "data:" (don't forget the colon) marks the end of information about the data and the beginning of the data itself.The first line of the data ("1 7 8 2") says that person 1 has ties to three people, who are 7, 8 and 2. The ordering of the people is arbitrary and makes no difference. The second line, "3 19 21 49 6" says that person 3 has ties to four people, who are 19, 21, 49 and 6.Important note: each value is separated by a space (or tab). Each value is a "sequential" ID number. By "sequential" I mean that the numbers run from 1 to n. You can't have arbitrary ID numbers like "1001" or non-numeric IDs like "BOS007" or "Steve" unless you add the words "Labels embedded" some time before the "data:" statement, as follows:dln = 50labels embeddedformat = nodelistdata:binlad geobus tonblai kenskibilste jeabar stebor judcla jandoekenski jandoe…These names or labels must be less than 20 characters long and should not contain spaces or punctuation (as in "osama bin laden") unless they are enclosed in full quotes.A sample data file called borg4cent.txt using nodelist format is provided with the program.Edgelist FormatThis format requires more typing but is convenient when entering data as one encounters it, such as when pulling links between people from newspaper articles. Again, create a text file using any word processor (make sure to remember to save as text). Enter the data in the following format: dln = 50format = edgelistdata:1 71 81 23 19…Note that "nodelist" has been replaced by "edgelist" in the format statement. Then, after "data:", the data are in pairs, separated by spaces or tabs. The first line ("1 7") says that persons 1 and 7 have a tie. The second line says that persons 1 and 8 have a tie. The ordering of nodes within in a pair, and of pairs within the file, is immaterial.As with the nodelist format, you can also use non-sequential, non-numeric IDs as long as you add the words "Labels embedded" some time before the "data:" statement, as follows:dln = 50labels embeddedformat = edgelistdata:binlad geobusbinlad tonblaibinlad kenskibilste jeabar…FullMatrix FormatThis format works well for small datasets that contain a lot of ties. Again, create a text file using any word processor or with Excel (making sure to remember to save as text). Enter the data in the following format:dln = 5format = fullmatrixdata:0 0 1 0 00 0 0 1 11 0 0 1 00 1 1 0 00 1 0 0 0Here, the format statement reads "format=fullmatrix". Then, after "data:", the data are in the form of a person-by-person table. Since n=5, there are 5 rows and 5 columns. The first row has values0, 0, 1, 0, 0, indicating that person one has ties only with the third person. In contrast, the second row of the table shows that person 2 has ties with person 4 and person 5.Note that this format does not have id codes at all: people are identified by their position in the table. The third row corresponds to the third person. The fourth column corresponds to the fourth person, and so on.However, non-numeric labels can be added with "labels embedded" statement as follows:dln = 5labels embeddedformat = fullmatrixdata:Bill Jan Jim Sue ZoeBill 0 0 1 0 0Jan 0 0 0 1 1Jim 1 0 0 1 0Sue 0 1 1 0 0Zoe 0 1 0 0 0Typing the data is the hardest part. Once you do that, the rest is easy.Technical SupportFeel free to contact me (steve@; +1 978 456 7372) for help or to report bugs or to make suggestions for improvements.。

ucinet点入度和点出度操作UCINet是一种用于社会网络分析的软件包,可以用于研究和分析复杂网络的结构和关系。
在UCINet中,点入度和点出度是两个重要的操作,用于描述节点在网络中的连接情况和影响力。
点入度(indegree)是指某个节点接收到的连接数,即其他节点向该节点发送的连接数量。
具体而言,对于一个节点来说,点入度越高,表示有更多的节点与其相连,意味着它在网络中具有更高的影响力和重要性。
通过点入度操作,我们可以计算并了解每个节点的接收连接数量,从而分析网络中节点的关系和相互作用。
点出度(outdegree)是指某个节点发出的连接数,即该节点向其他节点发送的连接数量。
与点入度类似,点出度也反映了节点在网络中的影响力和重要性。
一个节点的点出度越高,表示它与更多的节点相连,具有更强的信息传播和影响能力。
通过点出度操作,我们可以计算并了解每个节点发送连接的数量,从而分析网络中节点的传播能力和影响范围。
在UCINet中,进行点入度和点出度操作非常简单。
首先,我们需要加载网络数据,并确保数据中包含节点之间的连接信息。
然后,选择点入度或点出度操作,系统会自动计算每个节点的度量值,并将结果显示在界面上。
以点入度操作为例,我们可以通过以下步骤进行分析:1. 加载网络数据:在UCINet中,可以导入各种格式的网络数据,如Pajek、CSV等。
将数据导入软件后,系统会自动识别节点和边的信息。
2. 选择点入度操作:在菜单栏中选择“Analyze”->“Network”->“Centrality”->“Indegree”,即可进行点入度分析。
3. 查看结果:系统会计算每个节点的点入度,并将结果显示在结果窗口中。
我们可以根据节点的点入度值进行排序,了解网络中具有较高接收连接数量的节点。
通过点入度操作,我们可以发现网络中的重要节点和信息传播的路径。
具有较高点入度的节点通常是网络中的核心节点,它们在信息传播和影响力方面扮演着重要角色。


六个主要的社会网络分析软件的比较UCINET简介UCINET为菜单驱动的Windows程序,可能是最知名和最经常被使用的处理社会网络数据和其他相似性数据的综合性分析程序。
与UCINET捆绑在一起的还有Pajek、Mage和NetDraw 等三个软件。
UCINET能够处理的原始数据为矩阵格式,提供了大量数据管理和转化工具。
该程序本身不包含网络可视化的图形程序,但可将数据和处理结果输出至NetDraw、Pajek、Mage 和KrackPlot等软件作图。
UCINET包含大量包括探测凝聚子群(cliques, clans, plexes)和区域(components, cores)、中心性分析(centrality)、个人网络分析和结构洞分析在内的网络分析程序。
UCINET还包含为数众多的基于过程的分析程序,如聚类分析、多维标度、二模标度(奇异值分解、因子分析和对应分析)、角色和地位分析(结构、角色和正则对等性)和拟合中心-边缘模型。
此外,UCINET 提供了从简单统计到拟合p1模型在内的多种统计程序。
Pajek简介Pajek 是一个特别为处理大数据集而设计的网络分析和可视化程序。
Pajek可以同时处理多个网络,也可以处理二模网络和时间事件网络(时间事件网络包括了某一网络随时间的流逝而发生的网络的发展或进化)。
Pajek提供了纵向网络分析的工具。
数据文件中可以包含指示行动者在某一观察时刻的网络位置的时间标志,因而可以生成一系列交叉网络,可以对这些网络进行分析并考察网络的演化。
不过这些分析是非统计性的;如果要对网络演化进行统计分析,需要使用StOCNET 软件的SIENA模块。
Pajek可以分析多于一百万个节点的超大型网络。
Pajek提供了多种数据输入方式,例如,可以从网络文件(扩展名NET)中引入ASCII格式的网络数据。
网络文件中包含节点列表和弧/边(arcs/edges)列表,只需指定存在的联系即可,从而高效率地输入大型网络数据。


北京环中睿驰科技有限公司Ucinet软件操作指南安装、激活、使用方法QQ:971307775 Email: ss@欢迎交流联系沈帅5/2/2012主要介绍UCINET软件的安装方法、激活方法、用途特点介绍以及一个完整的建模实例。
1Ucinet软件操作指南1.1安装步骤1.1.1步骤一安装软件●Ucinet 6 Windows版本安装软件包名称为:UcinetSetup.exe,点击该软件安装包,然后弹出下边界面之后点击允许运行:图一●然后弹出如下界面,选择安装目录:图二●然后点击Next,选择安装文件夹名称:图三●点击Next,开始进行软件配置,完成安装。
图四点击next,完成Ucinet的安装,然后点击finish即可启动软件:图五1.1.2软件激活方法:●点击Install之后,在Help页面中选择Register注册按钮,然后输入购买时使用的UserID和RegistrationCode,具体如下:图六●激活成功之后,会提示激活成功。
1.2软件介绍1.2.1用途UCINET软件是由加州大学欧文(Irvine)分校的一群网络分析者编写的。
现在对该软件进行扩展的团队是由斯蒂芬·博加提(Stephen Borgatti)、马丁·埃弗里特(Martin·Everett)和林顿·弗里曼(Linton Freeman)组成的。
UCINET网络分析集成软件包括一维与二维数据分析的NetDraw,还有正在发展应用的三维展示分析软件Mage等,同时集成了Pajek用于大型网络分析的Free应用软件程序。
利用UCINET软件可以读取文本文件、KrackPlot、Pajek、Negopy、VNA等格式的文件。
它能处理32 767个网络节点。
当然, 从实际操作来看,当节点数在5000~10000之间时,一些程序的运行就会很慢。
社会网络分析法包括中心性分析、子群分析、角色分析和基于置换的统计分析等。
社会网络分析方法 ucinet 的应用简介社会网络分析(Social Network Analysis,简称SNA)是一种研究人与人之间关系的方法,它通过分析网络中的节点和连接来探索社会结构和信息传播。
UCINet是一种常用的社会网络分析工具,具有强大的功能和易用性,被广泛应用于社会科学、管理学、信息科学等领域。
本文将介绍UCINet的应用场景、主要功能和使用方法,帮助读者快速上手使用这一工具进行社会网络分析。
应用场景UCINet可以应用于多个领域的社会网络分析研究,例如:1.社交网络分析:研究人际关系网络、组织内部网络、虚拟社群网络等,分析社会网络结构、中心性指标、团队合作等。
2.信息传播研究:研究信息在网络中的传播路径、传播速度、影响力等,分析关键节点、群体影响力等。
3.知识管理研究:研究知识传播、知识产出与利用、知识创新等,分析知识传递路径、知识转化效率等。
4.组织管理研究:研究组织内部结构、组织变革、决策流程等,分析关键角色、信息流动等。
主要功能UCINet具有丰富的功能,可以帮助用户进行社会网络分析,主要功能包括:1.数据导入:UCINet支持导入多种数据格式,如Excel、CSV、Pajek格式等,使用户可以将已有的数据导入到工具中进行分析。
2.数据可视化:UCINet提供多种可视化方法,如节点图、连线图、矩阵图等,帮助用户直观地展示和理解网络结构和关系。
3.网络度量:UCINet提供多种网络度量方法,如中心性指标、群体聚类、连通性分析等,帮助用户分析网络中的节点和连接的特性。
4.社区检测:UCINet支持社区检测算法,帮助用户发现网络中的子群体和社区结构,进一步了解网络的组织和功能。
5.数据分析:UCINet提供统计分析、图论分析等功能,帮助用户对网络数据进行深入挖掘和分析。
使用方法以下是使用UCINet进行社会网络分析的基本步骤:1.准备数据:将需要分析的数据整理成UCINet支持的格式,如Excel表格或CSV文件。
ucinet使用方法UCINET是一款网络分析集成软件,可以用于一维与二维数据分析的NetDraw,以及三维展示分析软件Mage等。
使用UCINET可以读取多种格式的文件,如文本文件、KrackPlot、Pajek、Negopy、VNA等。
以下是UCINET的使用方法:1. 下载UCINET软件。
您可以从官网下载最新版本,或者从软件下载的网页上下载汉化版。
2. 导入Excel数据。
您需要将Excel数据转换为UCINET软件支持的格式,例如.txt或.csv文件。
3. 打开UCINET软件,选择导入的数据文件。
在UCINET软件中,您可以通过菜单栏选择“文件”>“打开”,然后选择要导入的数据文件。
4. 绘制网络图。
在UCINET软件中,您可以通过绘制节点和链接来创建网络图。
您可以使用菜单栏中的“网络”>“绘制网络图”来创建新的网络图。
5. 分析网络数据。
UCINET软件提供了多种网络分析工具,例如中心性分析、社群检测、模块度分析等。
您可以使用这些工具来分析网络数据,并获取有价值的见解。
6. 可视化网络数据。
UCINET软件支持多种可视化效果,例如节点大小、颜色、形状等。
您可以使用这些效果来更好地展示网络数据。
7. 导出网络数据。
您可以将UCINET软件中的网络数据导出为多种格式,例如.csv、.txt、.pdf等。
在菜单栏中选择“文件”>“导出”即可导出数据。
总之,UCINET软件是一个强大的网络分析工具,可以帮助您更好地理解和分析网络数据。
如果您对UCINET的使用有任何疑问,可以参考官方文档或寻求专业人士的帮助。
本指南提供了一种快速介绍UCINET得使用说明。
假定软件已经与数据安装在C:\Program Files\Analytic Technologies\Ucinet 6\DataFiles得文件夹中,被留作为默认目录。
这个子菜单按钮涉及到UCINET所有程序,它们被分为文件,数据、转换、工具、网络、视图、选择与帮助。
值得注意得就是,这个按钮得下方,都就是在子菜单中得这些调用程序得快捷键。
在底部出现得默认目录就是用于UCINET收集任何数据与存储任何文件(除非另外说明),目录可以通过点击向右这个按钮被修改。
运行得一种程序为了运行UCINET程序,我们通常需要指定一个UCINET数据集,给出一些参数。
在可能得情况下,UCINET选用一些默认参数,用户可以修改(如果需要)。
注意UCINET伴随着大量得标准数据集,而这些将会放置在默认值目录。
当一个程序被运行,有一些文本输出,它们会出现在屏幕上,而且通常UCINET得数据文件包含数据结果,这些结果又将会被储存在默认目录中。
我们将运行度得权重得程序来计算在一个称为TARO得标准UCINET数据集得全体参与者得权重。
首先我们强调网络>权重>度,再点击如果您点击了帮助按钮,,一个帮助界面就会在屏幕上打开,瞧起来像这样。
帮助文件给出了一个程序得详细介绍,会解释参数并描述在记录文件与屏幕上显示出来得输出信息。
关闭帮助文件,或者通过点击pickfile按钮或者输入名称选择TARO分析数据,如下。
现在点击OK运行程序验证。
这就是一个文本文件给出得程序结果。
注意您可以向下滚动瞧到更多得文件。
这个文件可以保存或复制、粘贴到一个word处理包中。
当UCINET被关闭时,这个文件将会被删除。
关闭此文件。
注意,当这个程序运行时,我们也创建了一个名为FreemanDegree得新得UCINET文档。
我们可以使用Display /dataset按钮查瞧新得UCINET文件。
一、导入数据(两种方法)
1.excel导入
“数据”——“输入”——“Excel矩阵”,将bibexcel处理好的矩阵导入
2.txt导入
共词矩阵.txt中输入下列内容:
dl n=70 format=edgelist1
labels embedded
data
说明:n=?指矩阵几行几列,即选择了多少个关键词
“数据”——“输入”——“DL(D)”,选中共词矩阵.txt
点击“确定”,弹出下图所示的文本文档,并在输出路径所在地生成 .##h和 .##d 文件。
二、可视化数据分析
点击可视化—netdraw,然后弹出netdraw界面
选择file—open—ucinet dataset—network,然后弹出如下界面
选择生成的 .##h文件,点击ok,然后出现如下界面:
然后进行中心度分析,选择analysis—centrality measures,然后在弹出界面的set node size by 下输入degree,点击 ok
然后就会出现依据中心度大小进行显示的节点情况
三、小团体分析
去箭头
点击可视化—netdraw,然后弹出netdraw界面
选择file—open—ucinet dataset—network,然后弹出如下界面选择生成的 .##h文件,点击ok,然后出现如下界面:
点击右侧小箭头
调整一下每个节点的位置,让关键词都露出来,图要美观Analysis——Subgroup——Factions
弹出小窗口
数字挨个试,出现转折时,选择转折前的那个数字
8时,Fitness=218;9时,Fitness=222,出现转折,选择数字“8”共有8个小团体。