第9章统计实验统计实验(对应分析)
- 格式:doc
- 大小:514.50 KB
- 文档页数:6









篇一:统计学实验心得体会统计学实验心得体会为期半个学期的统计学实验就要结束了,这段以来我们主要通过excl软件对一些数据进行处理,比如抽样分析,方差分析等。
经过这段时间的学习我学到了很多,掌握了很多应用软件方面的知识,真正地学与实践相结合,加深知识掌握的同时也锻炼了操作能力,回顾整个学习过程我也有很多体会。
统计学是比较难的一个学科,作为工商专业的一名学生,统计学对于我们又是相当的重要。
因此,每次实验课我都坚持按时到实验室,试验期间认真听老师讲解,看老师操作,然后自己独立操作数遍,不懂的问题会请教老师和同学,有时也跟同学商量找到更好的解决方法。
几次实验课下来,我感觉我的能力确实提高了不少。
统计学是应用数学的一个分支,主要通过利用概率论建立数学模型,收集所观察系统的数据,进行量化的分析、总结,并进而进行推断和预测,为相关决策提供依据和参考。
它被广泛的应用在各门学科之上,从物理和社会科学到人文科学,甚至被用来工商业及政府的情报决策之上。
可见统计学的重要性,认真学习显得相当必要,为以后进入社会有更好的竞争力,也为多掌握一门学科,对自己对社会都有好处。
几次的实验课,我每次都有不一样的体会。
个人是理科出来的,对这种数理类的课程本来就很感兴趣,经过书本知识的学习和实验的实践操作更加加深了我的兴趣。
每次做实验后回来,我还会不定时再独立操作几次为了不忘记操作方法,这样做可以加深我的记忆。
根据记忆曲线的理论,学而时习之才能保证对知识和技能的真正以及掌握更久的掌握。
就拿最近一次实验来说吧,我们做的是“平均发展速度”的问题,这是个比较容易的问题,但是放到软件上进行操作就会变得麻烦,书本上只是直接给我们列出了公式,但是对于其中的原理和意义我了解的还不够多,在做实验的时候难免会有很多问题。
不奇怪的是这次试验好多人也都是不明白,操作不好,不像以前几次试验老师讲完我们就差不多掌握了,但是这次似乎遇到了大麻烦,因为内容比较多又是一些没接触过的东西。

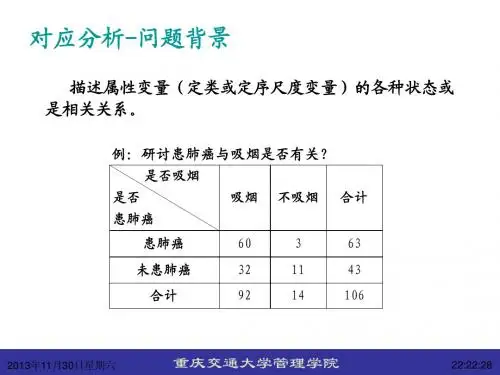
应用多元统计分析第九章对应分析对应分析又称相应分析,于1970年由法国统计学家J.P.Beozecri提出的.它是在R型和Q型因子分析基础上发展起来的多元统计分析方法,故也称为R-Q型因子分析.因子分析方法是用少数几个公共因子去提取研究对象的绝大部分信息,既减少了因子的数目,又把握住了研究对象的相互关系.在因子分析中根据研究对象的不同,分为R型和Q型,如果研究变量间的相互关系时采用R型因子分析;如果研究样品间相互关系时采用Q型因子分析.无论是R型或Q型都未能很好地揭示变量和样品间的双重关系.另方面在处理实际问题中,样本的大小经常是比变量个数多得多.当样品个数n很大(如n>100),进行Q型因子分析时,计算n阶方阵的特征值和特征向量对于微型计算机的容量和速度都是难以胜任的.还有进行数据处理时,为了将数量级相差很大的变量进行比较,常常先对变量作标准化处理,然而这种标准化处理对于变量和样品是非对等的,这给寻找R型和Q型之间的联系带来一定的困难.第九章什么是对应分析对应分析方法是在因子分析的基础上发展起来的,它对原始数据采用适当的标度方法.把R型和Q型分析结合起来,同时得到两方面的结果---在同一因子平面上对变量和样品一块进行分类,从而揭示所研究的样品和变量间的内在联系.对应分析由R 型因子分析的结果,可以很容易地得到Q 型因子分析的结果,这不仅克服样品量大时作Q 型因子分析所带来计算上的困难,且把R 型和Q 型因子分析统一起来,把样品点和变量点同时反映到相同的因子轴上,这就便于我们对研究的对象进行解释和推断. 第九章 对应分析的基本思想由于R 型因子分析和Q 型分析都是反映一个整体的不同侧面,因而它们之间一定存在内在的联系. 对应分析就是通过一个变换后的过渡矩阵Z 将二者有机地结合起来.具体地说,首先给出变量间的协差阵R S =Z'Z 和样品间的协差阵Q S =ZZ' ,由于Z'Z 和ZZ'有相同的非零特征根,记为12...m λλλ≥≥≥,如果R S 的特征根i λ对应的特征向量为i v ,则Q S 的特征根i λ对应的特征向量i u Zv =由此可以很方便地由R 型因子分析而得到Q 型因子分析的结果.对应分析的基本思想由A 的特征根和特征向量即可写出R 型因子分析的因子载荷阵(记为R A )和Q 型因子分析的因子载荷阵(记为Q A ).§9.1 什么是对应分析基本思想由于A和B具有相同的非零特征根,而这些特征根又正是各个公共因子的方差,因此可以用相同的因子轴同时表示变量点和样品点,即把变量点和样品点同时反映在具有相同坐标轴的因子平面上,以便对变量点和样品点一起考虑进行分类.第十章典型相关分析相关分析是研究多个变量与多个变量之间的相关关系.如研究两个随机变量之间的相关关系可用简单相关系数表示;研究一个随机变量与多个随机变量之间的相关关系可用全相关系数表示.1936年Hotelling首先将相关分析推广到研究多个随机变量与多个随机变量之间的相关关系,故而产生了典型相关分析,广义相关系数等一些有用的方法.第十章什么是典型相关分析在实际问题中,经常遇到要研究一部分变量和另一部分变量之间的相关关系,例如:在工业中,考察原料的主要质量指标(1,.....,p X X ) 与产品的主要质量指标(1,.....,p Y Y )间的相关性;在经济学中,研究主要肉类的价格与销售量之间的相关性; 在地质学中,为研究岩石形成的成因关系,考察岩石的化学成份与其周围围岩化学成份的相关性;在气象学中为分析预报24小时后天气的可靠程度,研究当天和前一天气象因子间的相关关系;第十章 什么是典型相关分析在教育学中,研究学生在高考的各科成绩与高二年级各主科成绩间的相关关系;在婚姻的研究中,考察小伙子对追求姑娘的主要指标与姑娘想往的小伙子的主要尺度之间的相关关系;在医学中,研究患某种疾病病人的各种症状程度与用科学方法检查的一些结果之间的相关关系;在体育学中,研究运动员的体力测试指标与运动能力指标之间的相关关系等.第十章 什么是典型相关分析一般地,假设有一组变量1,.....,p X X 与另一组变量1,.....,p Y Y (也可以记为1,....,p p q X X ++),我们要研究这两组变量的相关关系,如何给两组变量之间的相关性以数量的描述,这就是本章研究的典型相关分析.当p=q=1时,就是研究两个变量X 与Y 之间的相关关系.简单相关系数是最常见的度量.其定义为第十章 什么是典型相关分析当p ≥ 1 ,q=1时(或 q ≥ 1 , p =1) 设 则称为Y 与(X1,…,Xp) 的全相关系数.其实Y 对X 的回归为1(|)()()Y YX XX X E Y X x def x μμϕ-=+∑∑-且 并称R 为全相关系数 .第十章 什么是典型相关分析当p,q>1时,利用主成分分析的思想,可以把多个变量与多个变量之间的相关化为两个新变量之间的相关.也就是求α=(α1,…, αp ) '和β =(β1,…, βq ) ' , 使得新变量:V = α1X 1+…+αp X p = α 'X1~(,),0XX XY p YX YY X N Y μσ+∑∑⎛⎫⎛⎫∑∑=> ⎪ ⎪∑⎝⎭⎝⎭1/21YX XX XY YY R σ-⎛⎫∑∑∑= ⎪⎝⎭(,())Y x Rρϕ=W = β1Y 1+…+ βq Y q = β 'Y 之间有最大可能的相关,基于这个思想就产生了典型相关分析(Canonical correlatinal analysis).第十章 总体典型相关设X=(X1,...,Xp )及Y=(Y1,...,Yq)为随机向量(不妨设p ≤q),记随机向量Z 的协差阵为 其中Σ11是X 的协差阵,Σ22是Y 的协差阵,Σ12=Σ’21是X,Y 的协差阵. 第十章 总体典型相关我们用X 和Y 的线性组合V=a X 和W=b Y 之间的相关来研究X 和Y 之间的相关.我们希望找到a 和b,使ρ(V,W) 最大.由相关系数的定义:又已知⎪⎭⎫ ⎝⎛∑∑∑∑=∑22211211第十章总体典型相关故有对任给常数c1,c2,d1,d2,显然有ρ(c1V+d1, c2W+d2)=ρ(V,W)即使得相关系数最大的V=a'X和W=b'X并不唯一.故加附加约束条件 Var(V)=a'Σ11a=1,Var(W)=b'Σ22b=1.问题化为在约束条件Var(V)= 1,Var(W)=1下,求a和b,使得ρ(V,W)= a'Σ12b达最大 .第十章样本典型相关设总体Z=(X1,...,X p,Y1,…,Y q )’.在实际问题中,总体的均值E(Z)= 和协差阵D(Z)= 通常是未知的,因而无法求得总体的典型相关变量和典型相关系数.首先需要根据观测到的样本资料阵对其进行估计.已知总体Z的n个样品:第十章 样本典型相关样本资料阵为若假定Z ~N(μ,∑),则协差阵 的最大似然估 计为第十章 样本典型相关我们从协差阵 的最大似然估计S*(或样本协差阵S)出发,按上节的方法可以导出样本典型相关变量和样本典型相关系数.还可以证明样本典型相关变量和样本典型相关系数是总体典型相关变量和样本典型相关系数的极大似然估计.也可以从样本相关阵R 出发来导出样本典型相关变量和样本典型相关系数.第十章 样本典型相关典型相关系数的显著性检验:总体Z 的两组变量X=(X 1,...,X p )’和Y =(Y 1, …,Y q )’如果不相()()()()1(1,2,...,)t t t p q X Z t n Y +⨯⎛⎫== ⎪⎝⎭'()()11()()nt t t Z Z Z Z def Sn ∧=∑=--∑关,即COV(X,Y )=∑12=0,以上有关两组变量典型相关的讨论就毫无意义.故在讨论两组变量间相关关系之前,应首先对以下假设H 0作统计检验.(1) 检验H 0 : ∑12=0 (即λ1=0)设总体Z ~N p+q (μ,∑).用似然比方法可导出检验H 0的似然比统计量为(A ,A 11,A 22为离差阵)第十章 样本典型相关典型相关系数的显著性检验 (2)检验H 0(i): λi =0 (i =2,...,p )当否定H 0时,表明X,Y 相关,进而可得出至少第一个典型相关系数λ1≠ 0.相应的第一对典型相关变量V 1,W 1可能已经提取了两组变量相关关系的绝大部分信息.在实际问题中,经常迂到需要研究两组多重相关变量间的相互依赖关系,并研究用一组变量(常称为自变量或预测变量)去预测另一组变量(常称为因变量或响应变量),除了最小二乘准则下的经典多元线性回归分析(MLR),提取自变量组主成分的主成分回归分析(PCR)等方11221122||||||A S A A S S Λ==⨯⨯法外,还有近年发展起来的偏最小二乘(PLS)回归方法.第十一章什么是偏最小二乘回归偏最小二乘回归提供一种多对多线性回归建模的方法,特别当两组变量的个数很多,且都存在多重相关性,而观测数据的数量(样本量)又较少时,用偏最小二乘回归建立的模型具有传统的经典回归分析等方法所没有的优点。
统计学实验报告范文标题:统计学实验报告,探究随机抽样的效果与样本容量的关系一、引言统计学是一门利用数理统计的理论与方法研究统计现象规律的学科,通过研究分布规律、抽样等统计问题,可以对大量数据进行分析与预测。
而在实际应用中,为了节约成本与时间,常常选取一部分代表性的样本进行研究,而非对整个总体进行调查。
而这种随机抽样的效果与样本容量之间的关系便是本实验的研究对象。
二、实验目的本实验的目的是通过对不同样本容量下的抽样实验,研究随机抽样对总体性质的估计的准确性与可靠性的影响,并探究样本容量对于抽样结果的影响,为合理布局样本容量提供依据。
三、实验设计与方法1.实验设计:本实验选择超市60日内销售额的总体进行研究,将使用不同大小的样本容量进行随机抽样,并对所得样本进行分析与推断,比较不同样本容量下抽样估计的准确性与可靠性。
2.实验方法:(1)首先,我们根据超市销售额的总体数据,构建总体模型。
(2)拟定不同大小(10、30、50、100)的样本容量,随机抽取多组样本。
(3)对每组样本进行描述性统计,并计算样本的平均值、标准差等指标。
(4)计算每组样本的区间估计,并与总体参数进行比较。
(5)比较不同样本容量下的估计结果,分析样本容量对于抽样估计的影响。
四、实验结果与分析通过对不同样本容量下的抽样实验,我们得到了以下结果:1.样本容量的增加能够提高抽样估计的准确性与可靠性。
将样本容量从10增加到30,样本均值的标准差显著减小,说明样本均值的估计结果更加准确。
当样本容量增加到50时,样本均值的估计方差更进一步减小,相较于30的样本,误差减小幅度明显。
当样本容量增加到100时,样本均值的估计方差相对稳定,进一步减小的幅度有限。
2.随着样本容量的增加,样本均值的区间估计结果更加接近总体参数真值。
在样本容量为10的情况下,样本均值的95%置信区间的宽度较大,与总体均值相差较远;样本容量增加到30时,置信区间变窄,与总体均值更加接近;随着样本容量的增加,置信区间的宽度进一步减小,样本均值与总体均值的接近程度也进一步提高。
第三节成对数据的统计分析一、教材概念·结论·性质重视1.相关关系两个变量有关系,但又没有确切到可由其中的一个去精确地决定另一个的程度,这种关系称为相关关系.2.散点图将各数据在平面直角坐标系中的对应点画出来,得到表示两个变量的一组数据的图形,这样的图形叫做散点图.利用散点图,可以判断两个变量是否相关,相关时是正相关还是负相关.3.正相关和负相关(1)当一个变量的值增加时,另一个变量的相应值也呈现增加的趋势,我们就称这两个变量正相关.(2)负相关:当一个变量的值增加时,另一个变量的相应值呈现减少的趋势,则称这两个变量负相关.相关关系与函数关系的区别与联系(1)相同点:两者均是指两个变量的关系.(2)不同点:①函数关系是一种确定的关系,相关关系是一种非确定的关系;②函数关系是一种因果关系,而相关关系不一定是因果关系,也可能是伴随关系.(1)一般地,如果两个变量的取值呈现正相关或负相关,而且散点落在一条直线附近,我们就称这两个变量线性相关.(2)一般地,如果两个变量具有相关性,但不是线性相关,那么我们就称这两个变量非线性相关或曲线相关.5.样本相关系数(1)r=Σni=1(x i-x)(y i-y)Σni=1(x i-x)2Σni=1(y i-y)2=Σni=1x i y i-n x yΣni=1x2i-n x2Σni=1y2i-n y2,称r为变量x和变量y的样本相关系数.(2)样本相关系数r是一个描述成对样本数据的数字特征,它的正负性和绝对值的大小可以反映成对样本数据的变化特征:①当r>0时,称成对样本数据正相关;②当r<0时,称成对样本数据负相关.(3)样本相关系数r的取值范围为[-1,1],样本相关系数r的绝对值大小可以反映成对数据之间线性相关的程度:①当|r|越接近1时,成对数据的线性相关程度越强;②当|r|越接近0时,成对数据的线性相关程度越弱.6.经验回归方程我们将y^=b^x+a^称为Y关于x的经验回归方程,也称经验回归函数或经验回归公式,其图形称为经验回归直线,其中(1)经验回归方程不一定都有实际意义.回归分析是对具有相关关系的两个变量进行统计分析的方法,只有在散点图大致呈线性时,求出的经验回归方程才有实际意义.(2)根据经验回归方程进行预报,得到的仅是一个估计值,而不一定是真实发生的值.(3)经验回归直线一定过样本点的中心.7.利用R2刻画回归效果R2的计算公式为R2=1-∑i=1n(y i-y^i)2∑i=1n(y i-y)2,其意义是R2越大,残差平方和∑i=1n(y i -y^i)2越小,即模型的拟合效果越好;R2越小,残差平方和越大,即模型的拟合效果越差.8.独立性检验(1)χ2的计算公式:记n=a+b+c+d,则χ2=n(ad-bc)2(a+b)(c+d)(a+c)(b+d).(2)利用χ2的取值推断分类变量X和Y是否独立的方法称为χ2独立性检验,读作“卡方独立性检验”,简称独立性检验.(3)应用独立性检验解决实际问题包括以下几个环节:①提出零假设H0:X和Y相互独立,并给出在问题中的解释;②根据抽样数据整理出2×2列联表,计算χ2的值,并与临界xα值比较;③根据检验规则得出推断结论;④在X和Y不独立的情况下,根据需要,通过比较相应的频率,分析X和Y 间的影响规律.根据χ2的值可以判断两个分类变量有关的可信程度.若χ2的值越大,则两个分类变量有关系的把握越大.1.判断下列说法的正误,对的打“√”,错的打“×”.(1)“名师出高徒”可以解释为教师的教学水平与学生的水平成正相关关系.(√)(2)通过经验回归方程y^=b^x+a^可以估计预报变量的取值和变化趋势.(√)(3)经验回归方程y^=b^x+a^中,若a^<0,则变量x和y负相关.(×)(4)因为由任何一组观测值都可以求得一个经验回归方程,所以没有必要进行相关性检验.(×)2.(多选题)关于回归分析,下列说法正确的是( )A .在回归分析中,变量间的关系若是非确定性关系,那么因变量不能由自变量唯一确定B .线性相关系数可以是正的也可以是负的C .在回归分析中,如果r 2=1或r =±1,说明x 与y 之间完全线性相关D .样本相关系数r ∈(-1,1)ABC 解析:选项D 中,样本的相关系数应满足-1≤r ≤1,故D 错误,ABC 都正确.3.甲、乙、丙、丁四位同学在建立变量x ,y 的回归模型时,分别选择了4种不同模型,计算可得它们的R 2分别如下表:A .甲B .乙C .丙D .丁A 解析: R 2越大,表示回归模型的拟合效果越好.4.高二第二学期期中考试,按照甲、乙两个班学生的数学成绩优秀和及格统计人数后,得到如下列联表:A .0.600B .0.828C .2.712D .6.004A 解析:根据列联表中的数据,可得χ2=90×(11×37-34×8)245×45×19×71≈0.600.故选A .5.若变量y 与x 的非线性回归方程是y ^=2x -1,则当y ^的值为2时,x 的估计值为________.94解析:由2x-1=2,得x=94,即x的估计值为94.考点1相关关系的判断——基础性1. (多选题)下列变量之间的关系是相关关系的是()A.二次函数y=ax2+bx+c中,a,c是已知常数,取b为自变量,因变量是判别式Δ=b2-4acB.光照时间和果树亩产量C.降雪量和交通事故发生率D.每亩田施肥量和粮食亩产量BCD解析:在A中,若b确定,则a,b,c都是常数,Δ=b2-4ac也就唯一确定了,因此,这两者之间是确定性的函数关系.一般来说,光照时间越长,果树亩产量越高;降雪量越大,交通事故发生率越高;施肥量越多,粮食亩产量越高,所以B,C,D是相关关系.2.以下是在某地搜集到的不同楼盘房屋的销售价格y(单位:万元)和房屋面积x(单位:m2)的数据:房屋面积x/m211511080135105销售价格y/万元49.643.238.858.444(2)判断房屋的销售价格和房屋面积之间是否具有相关关系.如果有相关关系,是正相关还是负相关?解:(1)数据对应的散点图如图所示.(2)通过以上数据对应的散点图可以判断,房屋的销售价格和房屋面积之间具有相关关系,并且是正相关.两个变量是否相关的两种判断方法(1)根据实际经验,借助积累的经验进行分析判断.(2)通过散点图,观察它们的分布是否存在一定的规律,直观地进行判断.考点2一元线性回归模型及其应用——应用性考向1线性回归分析维尼纶纤维的耐热水性能的好坏可以用指标“缩醛化度”y来衡量,这个指标越高,耐热水性能也越好.而甲醛浓度是影响缩醛化度的重要因素,在生产中常用甲醛浓度x(g/L)去控制这一指标,为此必须找出它们之间的关系.现安排一批实验,获得如下数据:甲醛浓度(g/L)18202224262830缩醛化度(克分26.8628.3528.7528.8729.7530.0030.36子%)(2)求相关系数r(精确到0.01),并通过样本相关系数判断甲醛浓度与缩醛化度的相关程度和变化趋势的异同.解:(1)画出散点图如图所示.由散点图可以看出,成对数据呈现出相关关系.(2)x=1687=24,y=202.947,Σ7i=1x i y i=4 900.16,Σ7i=1x2i=4 144,Σ7i=1y2i≈5 892,所以r=Σ7i=1x i y i-7x y⎝⎛⎭⎪⎫Σ7i=1x2i-7x2⎝⎛⎭⎪⎫Σ7i=1y2i-7y2≈4 900.16-7×24×202.947(4 144-7×242)×⎣⎢⎡⎦⎥⎤5 892-7×⎝⎛⎭⎪⎫202.9472≈0.96.由此推断,甲醛浓度与缩醛化度正线性相关,即甲醛浓度与缩醛化度有相同的变化趋势,且相关程度很强.考向2非线性回归分析(2020·南平质检)千百年来,人们一直在通过不同的方式传递信息.在古代,烽火狼烟、飞鸽传书、快马驿站等通信方式被人们广泛传知;第二次工业革命后,科技的进步带动了电讯事业的发展,电报、电话的发明让通信领域发生了翻天覆地的变化;之后,计算机和互联网的出现则使得“千里眼”“顺风耳”变为现实……此时此刻,5G的到来即将给人们的生活带来颠覆性的变革.“5G 领先”一方面是源于我国顶层设计的宏观布局,另一方面则来自政府高度重视、企业积极抢滩、企业层面的科技创新能力和先发优势.某科技创新公司基于领先技术的支持,丰富的移动互联网应用等明显优势,随着技术的不断完善,该公司的5G经济收入在短期内逐月攀升.业内预测,该创新公司在第1个月至第7个月的5G经济收入y(单位:百万元)关于月份x的数据如下表:时间(月份)1234567收入(百万元)611213466101196(1)为了更充分运用大数据、人工智能、5G 等技术,公司需要派出员工实地检测产品性能和使用状况.公司领导要从报名的五名科技人员A ,B ,C ,D ,E 中随机抽取3个人前往,则A ,B 同时被抽到的概率为多少?(2)根据散点图判断,y =ax +b 与y =c ·d x (a ,b ,c ,d 均为大于零的常数)哪一个适宜作为5G 经济收入y 关于月份x 的经验回归方程类型?(给出判断即可,不必说明理由)并根据你判断结果及表中的数据,求出y 关于x 的回归方程.(3)请你预测该公司8月份的5G 经济收入. 参考数据:Σ7i =1y i Σ7i =1lg y i Σ7i =1x i y i Σ7i =1x i v i100.45 100.54 43.5 10.782535 50.122.823.47i i 参考公式:对于一组具有线性相关关系的数据(x i ,v i )(i =1,2,3,…,n ),其经验回归直线v^=β^x +α^的斜率和截距的最小二乘估计公式分别为β^=Σn i =1x i v i -n x vΣni =1x 2i -n x2,α^=v -β^x . 解:(1)从报名的科技人员A ,B ,C ,D ,E 中随机抽取3个人,则所有的情况为{A ,B ,C },{A ,B ,D },{A ,B ,E },{A ,C ,D },{A ,C ,E },{A ,D ,E },{B ,C ,D },{B ,C ,E },{B ,D ,E },{C ,D ,E },共10种.记“A ,B 同时被抽到”为事件Q ,则事件Q 包含的样本点为{A ,B ,C },{A ,B ,D },{A ,B ,E },共3个,故P (Q )=310.(2)根据散点图判断,y =c ·d x 适宜作为5G 经济收入y 关于月份x 的回归方程类型.由y =c ·d x ,两边同时取常用对数得lg y =lg(c ·d x )=lg c +x lg d .设lg y =v ,所以v =lg c +x lg d .因为x =17×(1+2+3+4+5+6+7)=4,所以v =17Σ7i =1v i =17Σ7i =1lg y i =17×10.78=1.54,Σ7i =1x 2i =12+22+32+42+52+62+72=140,所以lg d ^=Σ7i =1x i v i -7x y Σ7i =1x 2i -7x2=50.12-7×4×1.54140-7×42=728=0.25. 把样本中心(4,1.54)的坐标代入v =lg c ^+lg d ^·x ,得1.54=lg c ^+0.25×4, 所以lg c ^=0.54,所以v ^=0.54+0.25x , 所以lg y ^=0.54+0.25x ,所以y 关于x 的回归方程为y ^=100.54+0.25x =3.47×100.25x . (3)当x =8时,y ^=100.54+0.25x =3.47×100.25×8=347, 所以预测8月份的5G 经济收入为347百万元.非线性回归分析的步骤非线性回归问题有时并不给出经验公式.这时我们可以画出已知数据的散点图,把它与学过的各种函数(幂函数、指数函数、对数函数等)图象作比较,挑选一种跟这些散点拟合得最好的函数,然后采用适当的变量变换,把问题化为线性回归分析问题,使之得到解决.其一般步骤如下:(2020·广州一模)某种昆虫的日产卵数和时间变化有关,现收集了该昆虫第1天到第5天的日产卵数据:第x 天 1 2 3 4 5 日产卵数y (个)612254995Σ5i =1x i Σ5i =1x 2iΣ5i =1(ln y i ) Σ5i =1(x i ·ln y i ) 155515.9454.75程为y =e a +bx (其中e 为自然对数的底数),求实数a ,b 的值(精确到0.1).(2)根据某项指标测定,若日产卵数在区间(e 6,e 8)上的时段为优质产卵期.利用(1)的结论,估计在第6天到第10天中任取2天,其中恰有1天为优质产卵期的概率.附:对于一组数据(v 1,μ1),(v 2,μ2),…,(v n ,μn ),其经验回归直线的斜率和截距的最小二乘估计公式分别为β^=Σni =1v i u i -n v uΣni =1v 2i -n v2,α^=u -β^·v .解:(1)因为y=e a+bx,两边取自然对数,得ln y=a+bx. 令m=x,n=ln y,得n=a+bm.因为b^=54.75-5×155×15.94555-5×32=6.9310=0.693,所以b≈0.7.因为a^=n-b^m=15.945-0.7×3=1.088,所以a≈1.1,即a≈1.1,b≈0.7.(2)根据(1)得y=e1.1+0.7x.由e6<e1.1+0.7x<e8,得7<x<697.所以在第6天到第10天中,第8,9天为优质产卵期.从未来第6天到第10天中任取2天的所有可能事件有(6,7),(6,8),(6,9),(6,10),(7,8),(7,9),(7,10),(8,9),(8,10),(9,10),共10种.其中恰有1天为优质产卵期的有(6,8),(6,9),(7,8),(7,9),(8,10),(9,10),共6种.设从未来第6天到第10天中任取2天,其中恰有1天为优质产卵期的事件为A,则P(A)=610=3 5.所以从未来第6天到第10天中任取2天,其中恰有1天为优质产卵期的概率为35.考点3残差分析——基础性(2020·聊城6月高三模拟)2019年上半年我国多个省市暴发了“非洲猪瘟”疫情,生猪大量病死,存栏量急剧下降,一时间猪肉价格暴涨,其他肉类价格也跟着大幅上扬,严重影响了居民的生活.为了解决这个问题,我国政府一方面鼓励有条件的企业和散户防控疫情,扩大生产;另一方面积极向多个国家开放猪肉进口,扩大肉源,确保市场供给稳定.某大型生猪生产企业分析当前市场形势,决定响应政府号召,扩大生产决策层调阅了该企业过去生产相关数据,就“一天中一头猪的平均成本与生猪存栏数量之间的关系”进行研究.现相关数据统计如下表:生猪存栏数量x (千头) 2 3 4 5 8 头猪每天平均成本y (元)3.22.421.91.5x 的线性回归方程y ^(1)=b^x +a ^(计算结果精确到0.01).(2)研究员乙根据以上数据得出y 与x 的回归模型:y ^(2)=4.8x +0.8.为了评价两种模型的拟合效果,请完成以下任务:①完成下表(计算结果精确到0.01)(备注:e ^i 称为对于点(x i ,y i )的残差); 生猪存栏数量x (千头) 2 3 4 5 8 头猪每天平均成本y (元) 3.2 2.4 2 1.9 1.5 模型甲估计值y ^(1)i 残差e ^(1)i 模型乙估计值y ^(2)i 3.2 2.4 2 1.76 1.4 残差e ^(2)i0.140.11212大小,判断哪个模型拟合效果更好.(3)根据市场调查,生猪存栏数量达到1万头时,饲养一头猪每一天的平均收入为7.5元;生猪存栏数量达到1.2万头时,饲养一头猪每一天的平均收入为7.2元.若按(2)中拟合效果较好的模型计算一天中一头猪的平均成本,问:该生猪存栏数量选择1万头还是1.2万头能获得更多利润?请说明理由.(利润=收入-成本)参考数据:Σ5i =1(x i -x )(y 1-y)=-5.3,Σ5i =1(x i -x )2=21.2. 解:(1)由题知:x -=4.4,y -=2.2, b ^=Σni =1(x i -x -)(y i -y -) Σni =1(x i -x -)2=-5.321.2=-0.25, a ^=y --b ^x =2.2+0.25×4.4=3.30, 故y ^(1)=-0.25x +3.30. (2)①经计算,可得下表: 生猪存栏数量x (千头) 2 3 4 5 8 头猪每天平均成本y (元) 3.2 2.4 2 1.9 1.5 模型甲 估计值y ^(1)i 2.80 2.552.302.051.30 残差e ^(1)i 0.40 -0.15 -0.30 -0.15 0.20 模型乙估计值y ^(2)i 3.2 2.4 2 1.76 1.4 残差e ^(2)i0.140.112+(0.1)2=0.029 6.因为Q 1>Q 2,故模型y ^(2)=4.8x+0.8的拟合效果更好.(3)若生猪存栏数量达到1万头,由(2)中模型乙可知,每头猪的成本为4.810+0.8=1.28(元),这样一天获得的总利润为 (7.5-1.28)×10 000=62 200(元);若生猪存栏数量达到1.2万头,由(2)中模型乙可知,每头猪的成本为4.812+0.8=1.2(元),这样一天获得的总利润为(7.2-1.2)×12 000=72 000(元).因为72 000>62 200,所以选择生猪存栏数量1.2万头能获得更多利润.在进行线性回归分析时,要按线性回归分析步骤进行.在求R 2时,通常采用分步计算的方法,R 2越大,模型的拟合效果越好.关于x 与y 有如下数据:x 24568y 30 40 60 50 70(1)y ^=6.5x +17.5;(2)y ^=7x +17.试比较哪一个拟合效果更好. 解:由(1)可得y i -y ^i 与y i -y 的关系如下表:y i -y ^i -0.5 -3.5 10 -6.5 0.5 y i -y-20-101020所以Σ5i =1(y i -y ^i )2=(-0.5)2+(-3.5)2+102+(-6.5)2+0.52=155,Σ5i =1(y i -y )2=(-20)2+(-10)2+102+02+202=1 000.所以R 21=1-Σ5i =1 (y i -y ^i )2Σ5i =1(y i -y )2=1-1551 000=0.845. 由(2)可得y i -y ^i 与y i -y 的关系如下表:y i -y ^i -1 -5 8 -9 -3 y i -y-20 -10 1020所以Σ5i =1(y i -y ^i )2=(-1)2+(-5)2+82+(-9)2+(-3)2=180,所以R 22=1-Σ5i =1(y i -y ^i )2Σ5i =1(y i -y )2=1-1801 000=0.82.所以R 21>R 22.所以(1)的拟合效果更好.考点4列联表与独立性检验——综合性某省进行高中新课程改革已经四年了,为了了解教师对新课程教学模式的使用情况,某一教育机构对某学校的教师关于新课程教学模式的使用情况进行了问卷调查.共调查了50人,其中有老教师20人,青年教师30人.老教师对新课程教学模式赞同的有10人,不赞同的有10人;青年教师对新课程教学模式赞同的有24人,不赞同的有6人.(1)根据以上数据建立一个2×2列联表;(2)依据小概率α=0.001值,能否推断青年教师和老教师在新课程教学模式的使用上有差异?解:(1)2×2列联表如下所示.赞同不赞同总计老教师101020青年教师24630总计341650由公式得χ2=50×(10×6-24×10)234×16×20×30≈4.963<10.828=x0.001,我们推断H0不成立,即认为青年教师和老教师在新课程教学模式的使用上有差异,此推断犯错误的概率不大于0.001.(1)利用χ2=n(ad-bc)2(a+b)(c+d)(a+c)(b+d)求出χ2的值.再利用小概率α的值以及对应的临界值来判断有多大的把握判断两个事件有关.(2)解题时应注意准确计算,不可错用公式,准确进行比较与判断.(2020·新高考全国卷Ⅰ)为加强环境保护,治理空气污染,环境监测部门对某市空气质量进行调研,随机抽查了100天空气中的PM2.5和SO 2浓度(单位:μg/m 3),得下表SO 2PM2.5[0,50] (50,150] (150,475][0,35] 32 18 4 (35,75] 6 8 12 (75,115]37102150”的概率;(2)根据所给数据,完成下面的2×2列联表:SO 2PM2.5[0,150](150,475][0,75] (75,115]浓度与SO 2浓度有关?解:(1)根据抽查数据,该市100天的空气中PM2.5浓度不超过75,且SO 2浓度不超过150的天数为32+18+6+8=64,因此,该市一天空气中PM2.5浓度不超过75,且SO 2浓度不超过150的概率p =64100=0.64.(2)根据抽查数据,可得2×2列联表如下:SO 2PM2.5[0,150] (150,475] [0,75] 64 16 (75,115]1010χ2=100×(64×10-16×10)274×26×20×80≈7.484.因为7.484>6.635,故有99%的把握认为该市一天空气中PM2.5浓度与SO2浓度有关.。
(名师选题)2023年人教版高中数学第九章统计知识总结例题单选题1、某单位有男职工56人,女职工42人,按性别分层,用分层随机抽样的方法从全体职工中抽出一个样本,如果样本按比例分配,男职工抽取的人数为16人,则女职工抽取的人数为()A.12B.20C.24D.28答案:A分析:根据题意,结合分层抽样的计算方法,即可求解.根据题意,设抽取的样本人数为n,=16,所以n=28,因此女职工抽取的人数为28−16=12(人).因男职工抽取的人数为56n56+42故选:A.2、下列调查适合作抽样调查的是().A.学校调查本届学生某学科水平考的校合格率B.小区居委了解小区内70岁以上老人的生活状况C.环保部门调查5月份黄河某段水域的水质量情况D.班主任了解全班同学本周末参加社区活动的时间答案:C分析:由抽样调查的概念判断由题意,A,B,D适合全面调查,C适合抽样调查,故选:C3、新莽铜嘉量是由王莽国师刘歆等人设计制造的标准量器,它包括了龠(yuè)、合、升、斗、斛这五个容量单位.每一个量又有详细的分铭,记录了各器的径、深、底面积和容积.现根据铭文计算,当时制造容器时所用的圆周率分别为3.1547,3.1992,3.1498,3.2031,比《周髀算经》的“径一而周三”前进了一大步,则上面4个数据与祖冲之给出的约率(227≈3.1429)、密率(355113≈3.1416)这6个数据的中位数与极差分别为()A.3.1429,0.0615B.3.1523,0.0615C.3.1498,0.0484D.3.1547,0.0484答案:B分析:先对这6个数由小到大(或由大到小)排列,然后利用中位数和极差的定义求解即可所给6个数据由小到大排列依次为3.1416,3.1429,3.1498,3.1547,3.1992,3.2031,所以这6个数据的中位数为(3.1498+3.1547)÷2≈3.1523,极差为3.2031−3.1416=0.0615,故选:B.4、“中国天眼”为500米口径球面射电望远镜,是具有我国自主知识产权、世界最大单口径、最灵敏的射电望远镜.建造“中国天眼”的目的是()A.通过调查获取数据B.通过试验获取数据C.通过观察获取数据D.通过查询获得数据答案:C分析:直接由获取数据的途径求解即可.“中国天眼”主要是通过观察获取数据.故选:C.5、某购物广场开展的“买三免一”促销活动异常火爆,对其中一日8时至22时的销售额进行统计,组距为2小时的频率分布直方图如图所示.已知12时至l6时的销售额为90万元,则10时至12时的销售额为().A.60万元B.80万元C.100万元D.120万元答案:A分析:依据频率分布直方图的性质即可求得10时至12时的销售额.12时至l6时的频率为0.100×2+0.125×2=0.45,10时至12时的频率为0.150×2=0.30×90=60(万元)10时至12时的销售额0.300.45则故选:A6、甲、乙两名射击运动爱好者在相同条件下各射击10次,中靶环数情况如图所示.则甲、乙两人中靶环数的方差分别为()A.7,7B.7,1.2C.1.1,2.3D.1.2,5.4答案:D分析:求出平均数,利用方差公式即可求解.实线的数字为:2,4,6,8,7,7,8,9,9,10,虚线的数字为:9,5,7,8,7,6,8,6,7,7,所以x乙=110(2+4+6+8+7+7+8+9+9+10)=7,x 甲=110(9+5+7+8+7+6+8+6+7+7)=7,S甲2=110[(9-7)2+(5-7)2+(7−7)2+(8−7)2+⋯+(7−7)2]=1.2S 乙2=110[(2-7)2+(4-7)2+(6−7)2+(8−7)2+⋯+(10−7)2]=5.4.故选:D7、已知某7个数的平均数为4,方差为2,现加入一个新数据4,此时这8个数的平均数为x,方差为s2,则()A.x=4,s2<2B.x=4,s2=2C.x>4,s2<2D.x>4,s2>2答案:A分析:由题设条件,利用平均数和方差的计算公式计算即可求解.设7个数为x1,x2,x3,x4,x5,x6,x7,则x1+x2+x3+x4+x5+x6+x77=4,(x1−4)2+(x2−4)2+(x3−4)2+(x4−4)2+(x5−4)2+(x6−4)2+(x7−4)27=2,所以x1+x2+x3+x4+x5+x6+x7=28,所以(x1−4)2+(x2−4)2+(x3−4)2+(x4−4)2+(x5−4)2+(x6−4)2+(x7−4)2=14,则这8个数的平均数为x=18(x1+x2+x3+x4+x5+x6+x7+4)=18×(28+4)=4,方差为s2=18×[(x1−4)2+(x2−4)2+(x3−4)2+(x4−4)2+(x5−4)2+(x6−4)2+(x7−4)2+(4−4)2]=18×(14+0)=74<2.故选:A.8、甲、乙两组数据的频率分布直方图如图所示,两组数据采用相同的分组方法,用x̅1和x̅2分别表示甲、乙的平均数,s12,s22分别表示甲、乙的方差,则()A.x̅1=x̅2,s12<s22B.x̅1=x̅2,s12>s22C.x̅1<x̅2,s12=s22D.x̅1>x̅2,s12=s22答案:B分析:由平均数和方差的定义和性质判断即可得出结果.平均数是每个矩形的底边中点的横坐标乘以本组频率(对应矩形面积)再相加,因为两组数据采取相同分组且面积相同,故x̅1=x̅2,由图观察可知,甲的数据更分散,所以甲方差大,即s12>s22,故选:B.9、关于圆周率π,数学发展史上出现过许多很有创意的求法,如著名的浦丰实验和查理斯实验.受其启发,我们也可以通过设计下面的实验来估计π的值:先请全校m名同学每人随机写下一个都小于1的正实数对(x,y);再统计两数能与1构成钝角三角形三边的数对(x,y)的个数a;最后再根据统计数a估计π的值,那么可以估计π的值约为()A.4am B.a+2mC.a+2mmD.4a+2mm答案:D解析:由试验结果知m对0~1之间的均匀随机数x,y,满足{0<x<10<y<1,面积为1,再计算构成钝角三角形三边的数对(x,y),满足条件的面积,由几何概型概率计算公式,得出所取的点在圆内的概率是圆的面积比正方形的面积,即可估计π的值.解:根据题意知,m 名同学取m 对都小于1的正实数对(x,y ),即{0<x <10<y <1, 对应区域为边长为1的正方形,其面积为1,若两个正实数x,y 能与1构成钝角三角形三边,则有{x 2+y 2<1x +y >10<x <10<y <1, 其面积S =π4−12;则有a m =π4−12,解得π=4a+2m m故选:D .小提示:本题考查线性规划可行域问题及随机模拟法求圆周率的几何概型应用问题. 线性规划可行域是一个封闭的图形,可以直接解出可行域的面积;求解与面积有关的几何概型时,关键是弄清某事件对应的面积,必要时可根据题意构造两个变量,把变量看成点的坐标,找到试验全部结果构成的平面图形,以便求解.10、某校高一共有10个班,编号为01,02,…,10,现用抽签法从中抽取3个班进行调查,设高一(5)班被抽到的可能性为a ,高一(6)班被抽到的可能性为b ,则( )A .a =310,b =29B .a =110,b =19 C .a =310,b =310D .a =110,b =110答案:C分析:根据简单随机抽样的定义,分析即可得答案.由简单随机抽样的定义,知每个个体被抽到的可能性相等,故高一(5)班和高一(6)班被抽到的可能性均为310.故选:C11、从某班50名学生中抽取6名学生进行视力状况的统计分析,下列说法正确的是( )A .50名学生是总体B .每个被调查的学生是个体C .抽取的6名学生的视力是一个样本D .抽取的6名学生的视力是样本容量答案:C分析:根据总体、样本、个体、样本容量的概念判断.从某班50名学生中抽取6名学生进行视力状况的统计分析,则50个学生的视力状况是总体,抽取的6名学生的视力是一个样本,每个被调查的学生的视力状况是个体,样本容量是6,结合所给的选项,只有C 正确.故选:C .12、某工厂利用随机数表对生产的700个零件进行抽样测试,先将700个零件进行编号,001,002,……,699,700,从中抽取70个样本,下图提供随机数表的第4行到第6行,若从表中第5行第6列开始向右读取数据,则得到的第8个样本编号是( )322118342978645407325242064438122343567735789056428442125331345786073625300732862345788907236896080432567808436789535577348994837522535578324577892345A .623B .368C .253D .072答案:B解析:从表中第5行第6列开始向右读取数据,每3个数为一个编号,不在编号范围内或重复的排除掉,第8个数据即为答案.从表中第5行第6列开始向右读取数据,依次得到253,313,457,860(舍),736(舍),253(舍),007,328,623, 457(舍),889(舍),072,368由此可得出第8个样本编号是368故选:B双空题13、某校高一共有10个班,编号分别为01,02,…,10,现用抽签法从中抽取3个班进行调查,设高一(5)班被抽到的可能性为a ,高一(6)班被抽到的可能性为b ,则a =___________;b =___________.答案: 310##0.3 310##0.3分析:利用简单随机抽样的等可能性,即得解由简单随机抽样的定义,知每个个体被抽到的可能性相等,故高一(5)班和高一(6)班被抽到的可能性均为310.故a=310,b=310所以答案是:310,3 1014、如图是一组样本数据的频率分布直方图,则依据图形中的数据,可以估计总体的平均数与中位数分别是______,______.答案: 13 13分析:先根据频率分布直方图计算出每组的频率,再用每组数据的中点代表整组即可计算出平均数;由中位数两侧面积相等列出方程即可得解.第1组的频率为0.04×5=0.2,第2组的频率为0.1×5=0.5,则第3组的频率为1−0.2−0.5=0.3,估计总体平均数为7.5×0.2+12.5×0.5+17.5×0.3=13.由题意知,中位数在第2组内,设为10+x,则有0.1x+0.2= 0.5,解得x=3,从而中位数是13.所以答案是:13,13.小提示:本题考查了根据频率分布直方图计算数据的平均数和中位数,属于基础题.15、某集团为了解员工的通勤时间长度,通过简单随机抽样获取了157名员工上下班的通勤时长,在该问题中,样本量为______;样本为_______________.答案: 157 被抽取的157名员工上下班的通勤时长分析:由题意材料,可直接写出样本量以及样本.由题意材料可知,为了解员工的通勤时间长度,抽取了157名员工上下班的通勤时长,所以样本量为157;样本为被抽取的157名员工上下班的通勤时长.所以答案是:157;被抽取的157名员工上下班的通勤时长.16、①数据20,14,26,18,28,30,24,26,33,12,35,22的70%分位数为_______;②数据1,5,9,12,13,19,21,23,28,36的第50百分位数是_______.答案:2816分析:将数据从小到大排列,利用百分位数的计算方法求解.把①的所有数据按从小到大的顺序排列可得:12,14,18,20,22,24,26,26,28,30,33,35,共有12个数据,所以12×70%=8.4,不是整数,所以数据的70%分位数为第9个数28;把②的所有数据按从小到大的顺序排列可得:1,5,9,12,13,19,21,23,28,36,共10个数据,所以10×50%=5,所以数据的第=16.50百分位数是第5和第6个数的平均值为13+192所以答案是:28;1617、已知甲、乙两组数据已整理成如图所示的茎叶图,则甲组数据的中位数是___________,乙组数据的25%分位数是___________.答案: 45 35分析:利用中位数的概念及百分位数的概念即得.由题可知甲组数据共9个数,所以甲组数据的中位数是45,由茎叶图可知乙组数据共9个数,又9×25%=2.25,所以乙组数据的25%分位数是35.所以答案是:45;35.解答题18、某市为了了解人们对“中国梦”的伟大构想的认知程度,针对本市不同年龄和不同职业的人举办了一次“一带一路”知识竞赛,满分100分(95分及以上为认知程度高),结果认知程度高的有m(m>20)人,按年龄分成5组,其中第一组:[20,25),第二组:[25,30),第三组:[30,35),第四组:[35,40),第五组:[40,45],得到如图所示的频率分布直方图.(1)根据频率分布直方图,估计这m人的平均年龄和第80百分位数;(2)现从以上各组中采用分层随机抽样的方法抽取20人,担任本市的宣传使者.若第四组宣传使者的年龄的平,第五组宣传使者的年龄的平均数与方差分别为43和1,求这m人中35~45岁所有人均数与方差分别为37和52的年龄的方差.答案:(1)平均年龄32.25岁,第80百分位数为37.5;(2)10.分析:(1)直接根据频率分布直方图计算平均数和百分位数;(2)由分层抽样得第四组和第五组分别抽取4人和2人,进而设第四组、第五组的宣传使者的年龄的平均数分别为x4,x5,方差分别为s42,s52,第四组和第五组所有宣传使者的年龄平均数为z,方差为s2,进而根据方差{4×[s42+(x4−z)2]+2×[s52+(x5−z)2]},代入计算即可得答案.公式有s2=16解:(1)设这m人的平均年龄为x,则x=22.5×0.05+27.5×0.35+32.5×0.3+37.5×0.2+42.5×0.1=32.25.设第80百分位数为a,由5×0.02+(40−a)×0.04=0.2,解得a=37.5.(2)由频率分布直方图得各组人数之比为1:7:6:4:2,故各组中采用分层随机抽样的方法抽取20人,第四组和第五组分别抽取4人和2人,设第四组、第五组的宣传使者的年龄的平均数分别为x4,x5,方差分别为s42,s52,,s52=1,则x4=37,x5=43,s42=52设第四组和第五组所有宣传使者的年龄平均数为z,方差为s2.=39,则z=4x4+2x56{4×[s42+(x4−z)2]+2×[s52+(x5−z)2]}=10,s2=16因此,第四组和第五组所有宣传使者的年龄方差为10,据此,可估计这m人中年龄在35~45岁的所有人的年龄方差约为10.19、文明城市是反映城市整体文明水平的综合性荣誉称号,作为普通市民,既是文明城市的最大受益者,更是文明城市的主要创造者某市为提高市民对文明城市创建的认识,举办了“创建文明城市”知识竞赛,从所有答卷中随机抽取100份作为样本,将样本的成绩(满分100分,成绩均为不低于40分的整数)分成六段:[40,50)[50,60),…,[90,100],得到如图所示的频率分布直方图.(1)求频率分布直方图中a的值;(2)求样本成绩的第75百分位数;(3)已知落在[50,60)的平均成绩是54,方差是7,落在[60,70)的平均成绩为66,方差是4,求两组成绩的总平均数z和总方差s2.答案:(1)a=0.030(2)84(3)z =62,s 2=37分析:(1)根据每组小矩形的面积之和为1即可求解;(2)由频率分布直方图求第百分位数的计算公式即可求解;(3)根据平均数和方差的计算公式即可求解.(1)解:∵每组小矩形的面积之和为1,∴(0.005+0.010+0.020+a +0.025+0.010)×10=1,∴a =0.030.(2)解:成绩落在[40,80)内的频率为(0.005+0.010+0.020+0.030)×10=0.65,落在[40,90)内的频率为(0.005+0.010+0.020+0.030+0.025)×10=0.9,设第75百分位数为m ,由0.65+(m −80)×0.025=0.75,得m =84,故第75百分位数为84;(3)解:由图可知,成绩在[50,60)的市民人数为100×0.1=10,成绩在[60,70)的市民人数为100×0.2=20,故z =10×54+66×2010+20=62.设成绩在[50,60)中10人的分数分别为x 1,x 2,x 3,…,x 10;成绩在[60,70)中20人的分数分别为y 1,y 2,y 3,…,y 20,则由题意可得x 12+x 22+⋅⋅⋅+x 10210−542=7,y 12+y 22+⋅⋅⋅+y 20220−662=4,所以x 12+x 22+⋅⋅⋅+x 102=29230,y 12+y 22+⋅⋅⋅+y 202=87200,所以s 2=110+20(x 12+x 22+⋅⋅⋅+x 102+y 12+y 22+⋅⋅⋅+y 202)−z 2=130(29230+87200)−622=37,所以两组市民成绩的总平均数是62,总方差是37.20、为了调查某厂工人生产某种产品的能力,随机抽查了20名工人某天生产该产品的数量,得到频率分布直方图如图所示.(1)求这20名工人中一天生产该产品的数量在[55,75)内的人数;(2)求这20名工人一天生产该产品的数量的中位数;(3)求这20名工人一天生产该产品的数量的平均数.答案:(1)13(2)62.5(3)64分析:(1)20名工人中一天生产该产品的数量在[55,75)内的人数用频率乘以20即可算出.(2)先假设,然后利用条件列出方程解出.(3)平均数为每一组中点数乘以每组频率全部加起来即可.(1)这20名工人中一天生产该产品的数量在[55,75)内的人数为(0.04×10+0.025×10)×20=13.所以答案是:13.(2)设中位数为x,则0.2+(x-55)×0.04=0.5,解得x=62.5.故中位数为:62.5.(3)这20名工人一天生产该产品的数量的平均数为0 .2×50+0.4×60+0.25×70+0.1×80+0.05×90=64.故平均数为:64.。
学生实验报告学院:统计学院课程名称:多元统计分析专业班级:统计123班姓名:叶常青学号:0124253学生实验报告一、实验目的及要求:目的熟悉和掌握对应分析的原理和上机操作方法容及要求本次操作就父母与孩子的受教育程度的关系进行对应分析,分别对父亲与孩子和母亲与孩子的受教育程度做对应分析,最后再对输出结果进行详细的分析。
二、仪器用具:三、实验方法与步骤:打开GSS93 subset .sav数据,对变量Degree与变量padeg和madeg进行对应分析,依次选择分析→降维…进入对应分析对话框,进行进行如下设置,便可输出想要的数据的:四、实验结果与数据处理:按照上述方法和步骤得出以下输出结果.对父亲受教育程度与孩子受教育程度的关系进行分析如下:表1表21 .400 .160 .846 .846 .025 .2562 .164 .027 .142 .988 .0263.047 .002 .012 1.004.006 .000 .000 1.00总计. 228.193.000a 1.001.00a. 16 自由度,表3第二部分摘要给出了惯量,卡方值以及每一维度所解释的总惯量的百分比信息。
总惯量为0.,卡方值为228.193 ,有关系式228.193=0.*1205,由此可以清楚的看到总惯量和卡方的关系。
Sig.是假设卡方值为0成立的概率,它的值几乎为0说明列联表之间有较强的相关性。
表注表明的自由度为(5-1)*(5-1)=16。
惯量部分是四个公共因子分别解释总惯量的百分比。
表4表5LT High School .808 .487 .387 .218 .253 .467 High School .140 .392 .453 .383 .374 .353 Junior College .005 .017 .027 .039 .030 .Bachelor . .068 . .228 .182 .100 Graduate .016 . .040 .131 .162 .有效边际 1.000 1.000 1.000 1.000 1.000第三部分的结果是在对应分析中点击Statistics按钮,进入Statistics对话框,选中Row profiles和Column profiles 交友程序运行所得到的。
实验五对应分析1.实验目的:本实验讨论利用对应分析从众多变量和样品信息中找出变量间、样品间、变量与样品间的本质联系。
通过该实验,能够起到如下的效果:(1) 理解对应分析的作用、思想、数学基础、方法和步骤;(2) 熟悉如何利用对应分析,提出问题、分析问题、解决问题、得出结论;(3)会调用SAS软件实现对应分析的各个步骤,根据计算的结果进行分析,得出正确的结论,解决实际的问题。
2.知识准备:对应分析是从众多变量和样品信息中找出变量间、样品间、变量与样品间的本质联系。
其思想是:对于某份数据(n份样品、p维数据),其变量点(n维空间的点,坐标为该变量在各个样品处的值)的协差阵和样品点(p维空间的点,坐标为该样品在各个变量处的值)的协差阵有本质的联系,而且有相同的特征值,特征向量也具有某种联系。
利用该联系进行适当的、尽量保留较多信息的降维,就会既反映变量间、样品间的本质联系,又反映变量与样品间的本质联系。
对应分析的步骤大体分为:首先把指标进行正向化;然后计算过渡矩阵,消除原始数据量纲的影响,使样品和变量具有某种意义下的对等性,以便可以在同一坐标轴中进行描述;然后对数据进行R型因子分析,根据过渡矩阵的相关阵的特征根和累计贡献率选取适当的公因子,计算出R型(变量点对应的)因子载荷和Q型(样品点对应的)因子载荷;然后把样品点和变量点根据它们变换后的坐标(R型因子得分或Q型因子的得分),描述到同一坐标轴中;最后根据样品点和变量点间的距离进行分析,得出结论。
3.实验内容:下面表1的数据是2009年广东省城镇居民家庭平均每人全年消费性支出构成的基本数据,其中的单位是百分比,数据来源于《广东省2009统计年鉴》:表1 广东省城镇居民家庭平均每人全年消费性支出构成的基本数据居民经济成份食品衣着居住家庭设备用品医疗保健交通和通讯教育文化娱乐服务其他消费最低收入户52.84 3.64 14.97 4.15 5.53 10.36 6.24 2.27 困难户54.52 3.43 15.24 4.65 5.55 8.63 5.70 2.28 低收入户52.77 4.78 13.03 4.56 4.67 10.29 7.57 2.33 中等偏下户46.92 5.46 11.20 5.69 4.91 13.49 9.68 2.65 中等收入户39.23 6.37 10.26 5.83 5.97 16.72 11.92 3.70 中等偏上户35.55 6.59 9.65 6.36 5.56 18.77 13.46 4.06 高收入户29.56 6.58 12.08 7.04 5.08 20.35 15.39 3.92 最高收入户28.70 7.17 9.86 7.05 5.91 21.10 15.71 4.50 利用对应分析对该数据进行处理,给出R型、Q型因子载荷,并结合该数据,给出适当的结论。
4.实验步骤:SAS程序:1.读入数据:Data consumption;input type X1-X8;cards;1 52.84 3.64 14.97 4.15 5.53 10.36 6.24 2.272 54.52 3.43 15.24 4.65 5.55 8.63 5.70 2.283 52.77 4.78 13.03 4.56 4.67 10.29 7.57 2.334 46.92 5.46 11.20 5.69 4.91 13.49 9.68 2.655 39.23 6.37 10.26 5.83 5.97 16.72 11.92 3.706 35.55 6.59 9.65 6.36 5.56 18.77 13.46 4.067 29.56 6.58 12.08 7.04 5.08 20.35 15.39 3.928 28.70 7.17 9.86 7.05 5.91 21.10 15.71 4.50;run;2.进行对应分析,并画出散点图:Proc corresp data=consumption out=result;var X1-X8;id type;Proc plot data=result;plot dim1*dim2="*"$type/ haxis=-0.06 to 0.1 by 0.02vaxis=-0.35 to 0.35 by 0.1vspace=3hspace=10HREF=0VREF=0;run;语句解释:“Proc corresp”指调用对应分析程序;“var X1-X8;”指变量是“X1-X8”;“id type;”指样品名是变量“type”;“Proc plot”指调用作图程序;“plot dim1*dim2="*"$type”指作以“dim1”为纵坐标、以“dim2”为横坐标的平面坐标图,坐标点用“*”和样品名“type”标出,其中符号“$”指后面变量“type”是字符型;“/ haxis=-0.06 to 0.1 by 0.02 vaxis=-0.35 to 0.35 by 0.1”中“/”指后面的语句是对坐标轴进行补充说明,“haxis=-0.06 to 0.1 by 0.02”指横轴上的刻度是从“-0.06”到“0.1”,每格代表“0.02”,“vaxis=-0.35 to 0.35 by 0.1”指横轴上的刻度是从“-0.35”到“0.35”,每格代表“0.1”;“vspace=3 hspace=10”指定图中纵坐标、横坐标单位格在图中的实际长度;“HREF=0 VREF=0”在横坐标等于“0”、纵坐标等于“0”的地方分别划一条平行与纵轴、横轴的参考线,其它更多的语句参见书【2】。
运行结果及解释:图1中数据“Singular Value”是过渡矩阵的奇异值,“Principal Inertia”是过渡矩阵的奇异值的特征值,“Chi-Square”是卡方检验值,“Percent”是特征值的贡献率,“Cumulative Percent”是特征值的累计贡献率;图1中重点的信息在于“特征值”及其“贡献率”,根据图1的数据知道:第一特征值的贡献率为96.47%,基本上反映了所有的信息,前两个特征值的累计贡献率为98.92%,因此选用前两个公因子就基本上反映了所有的信息;图2是样品点在两个公因子下的载荷,即R型因子载荷,也可以认为是样品点在新坐标系(以Dim1、Dim2为坐标轴)中的坐标;图1惯量和卡方分解图图2样品点的新坐标图3样品点的统计量图4 样品点对公因子贡献图3中数据“Quality”是前两个公因子对样品的共同度(如果保留所有的8个公因子,则共同度应该等于1),“Mass”是原始数据中各行数据之和占总数据之和的比,“Inertia”指各样品对总特征值的贡献率;图3中重点信息在于“Quality”的值。
由图3中数据知道:前两个公因子对每个样品的共同度都达到了0.89以上,基本上反映了每个样品的信息;图4是每个样品对公因子的贡献率,各列之和应该等于1。
由据图4中数据知道:样品1、2、3、7、8(最低收入户、困难户、低收入户、高收入户、最高收入户)对第一个公因子贡献比较大,样品1、2、4、5、7(最低收入户、困难户、中等偏下户、中等收入户、高收入户、最高收入户)对第二个公因子贡献比较大;图5对样品点贡献最大的公因子图5是各样品点的坐标对特征值贡献多少的说明,其中0、1、2分别代表贡献少、中、多;图6样品点余弦平方值图6是前两个公因子各自对样品的贡献率,各行的数值和应该等于图3中“Quality”的数值;根据图6的数据知道:第一个公因子对除4(中等偏下户)外的其他样品的贡献率都达到了0.81以上,基本上反映了除4外的其他样品的信息;图7 变量点的新坐标图8 变量点的统计量图9 变量点对公因子贡献图10 对变量点贡献最大的公因子图11 变量点余弦平方值图7-图11的数据是对变量点情况的说明,类似与图2-图6;根据图11的数据知道:第一个公因子对除X3(居住消费)、X5(医疗保健消费)外的其他变量的贡献率都达到了0.92以上,基本上反映了除X3、X5外的其他变量的信息;又根据图8中“Quality”的数据知道:前两个公因子对X3的共同度达到了0.99以上,基本上反映了X3的信息;图12 散点图实验结论:从图1的数据知道:第一公因子反映了绝大部分信息,前两个公因子基本上反映了所有的信息;而且从图6和图11的数据知道:第一个公因子(Dim1)基本上反映了除4(中等偏下户)、X3(居住消费)、X5(医疗保健消费)外的其他样品及变量的信息;前两个公因子基本上反映了除X5(居住消费)外的其他样品及变量的信息;因此以Dim1为纵轴、以Dim2为横轴的坐标轴基本上能反映样品和变量的信息,特别是纵轴的信息更为重要;从散点图上分析:(1)X1(食品)、X3(居住)纵轴坐标为负,而且X3与1(最低收入户)和2(困难户)距离最近,X1与3(低收入户)和4(中等偏下户)距离最近。
这说明X1和X3是最低端的生活必须品,经济条件差的居民与该消费关系最为密切,政府应该关心低收入人群的食品和居住费用,控制食品的价格,提供价格便宜的廉租房。
(2)X2(衣着)、X4-X8(家庭设备用品、医疗保健、交通和通讯、教育文化娱乐服务、其他消费)纵轴坐标为正,而且X2与5(中等收入户)和6(中等偏上户)距离最近,X4-X8与7(高收入户)和8(最高收入户)距离最近。
这说明衣着消费与中等收入的居民关系密切,中等收入的居民有了一定的生活保证,开始通过购买服装来追求时尚、体现个性。
家庭设备用品、医疗保健、交通和通讯、教育文化娱乐服务、其他消费是属于相对高端的消费,只有高收入的人群才有较大的消费比重。
(3)从上面的分析可以看到,目前收入中等偏上的居民主要的消费还只是与衣着消费密切,交通和通讯、教育文化娱乐服务等还属于高收入人群的消费。
这说明虽然广东省的人民生活水平步入了小康阶段,但与发达国家相比还是有不少的差距,有待提高。
5. 思考与练习:⑴运用对应分析研究我国近些年的社会消费品零售额的构成。
⑵运用对应分析尝试研究我国各省市国民生产总值的收入和支出的情况,并进行适当的分析。
⑶运用对应分析尝试研究我国各省市住房有关指标的情况,并进行适当的分析。
参考文献【1】于秀林、任雪松(1999):《多元统计分析》,中国统计出版社。
【2】汪远征、徐雅静(2007):《SAS软件与统计应用教程》,机械工业出版社。
【3】林海明:《因子分析模型的改进和应用》,数理统计与管理,28,2009,998-1012。
【4】林海明:《对主成分分析法运用中十个问题的解析》,统计与决策,16,2007,16-18。