(整理)实验六主成分分析.
- 格式:doc
- 大小:345.00 KB
- 文档页数:18

主成分分析地信0901班陈任翔010******* 【实验目的及要求】掌握主成分分析与因子分析的思想和具体步骤。
掌握SPSS实现主成分分析与因子分析的具体操作。
【实验原理】1.主成分分析的主要目的是希望用较少的变量去解释原来资料中的大部分变异,将我们手中许多相关性很高的变量转化成彼此相互独立或不相关的变量。
通常是选出比原始变量个数少,能解释大部分资料中的变异的几个新变量,即所谓主成分,并用以解释资料的综合性指标。
由此可见,主成分分析实际上是一种降维方法。
2.因子分析研究相关矩阵或协方差矩阵的内部依赖关系,它将多个变量综合为少数几个因子,以再现原始变量与因子之间的相关关系。
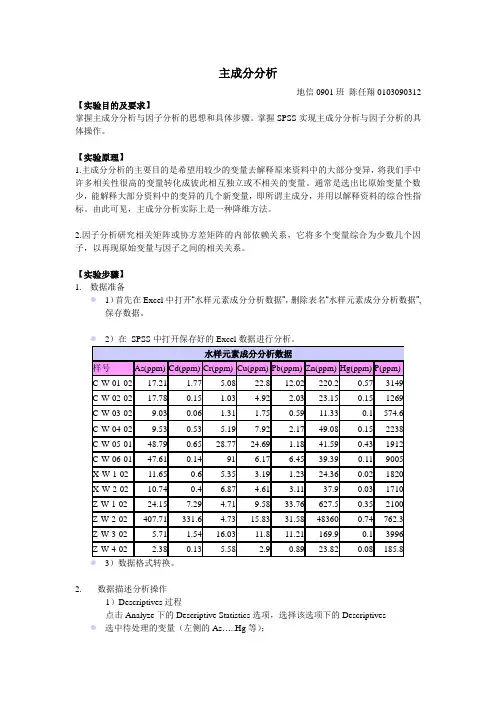
【实验步骤】1.数据准备●1)首先在Excel中打开“水样元素成分分析数据”,删除表名“水样元素成分分析数据”,保存数据。
●3)数据格式转换。
2.数据描述分析操作1)Descriptives过程点击Analyze下的Descriptive Statistics选项,选择该选项下的Descriptives●选中待处理的变量(左侧的As…..Hg等);●点击使变量As…..Hg 移至Variable(s)中;●选中Save standrdized values as variables;●点击Options2)数据标准化标准化处理后的结果2.主成分分析1)点击Analyze下的Data Reduction选项,选择该选项下的Factor过程。
选中待处理的变量,移至Variables2)点击Descriptives判断是否有进行因子分析的必要Coefficients(计算相关系数矩阵)Significance levels(显著水平)KMO and Bartlett’s test of sphericity (对相关系数矩阵进行统计学检验)Inverse(倒数模式):求出相关矩阵的反矩阵;Reproduced(重制的):显示重制相关矩阵,上三角形矩阵代表残差值,而主对角线及下三角形代表相关系数;Determinant(行列式):求出前述相关矩阵的行列式值;Anti-image(反映像):求出反映像的共同量及相关矩阵。
姓名课程多元统计分析实验内容主成份与因子分析指导老师实验目的本文旨在通过对通过对多个企业的效益指标的分析,对各企业进行主成份分析,并对各企业经营状况进行评分并排序。
同时,达到通过本实验达到熟练掌握主成份分析和因子分析操作的目的。
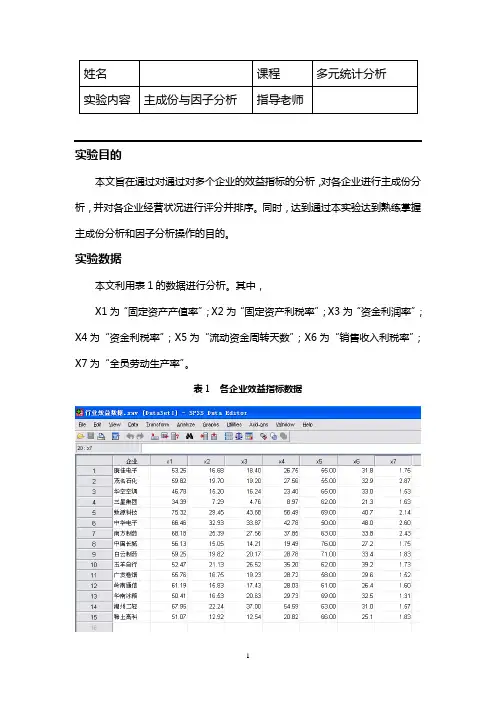
实验数据本文利用表1的数据进行分析。
其中,X1为“固定资产产值率”;X2为“固定资产利税率”;X3为“资金利润率”;X4为“资金利税率”;X5为“流动资金周转天数”;X6为“销售收入利税率”;X7为“全员劳动生产率”。
表1 各企业效益指标数据实验步骤选择【Analyze】-【Date Reduction】-【Factor】,如图2。
图2 主成份分析操作在主成份分析对话框中进行设置,将变量X1—X6选入Variables,如图3。
图3 主成份分析对话框选择【Descriptives】,弹出对话框如图4,保留默认设置。
图4 Descriptives对话框选择【Extraction】,弹出对话框如图5所示。
方法(method)默认为Principal components,即主成份分析,保留默认设置。
在提取Extract项下选Number of factors,填入6,即提取6个主成份。
图5 提取主成分设置选择【Rotation】,弹出对话框如图6所示,因子旋转采用Varimax方法,如图6所示。
图6 因子旋转对话框选择【Scores】,弹出对话框如图7所示。
选择将主成份保存成变量(Save as variables),方法(method)为回归(Regression)。
图7 主成份得分设置点击【OK】,即可得到主成份分析和因子分析结果。
实验结果表8为变量共同度,表中显示原始数据所有信息都被提取出来了。
表8 变量共同度CommunalitiesInitial Extraction固定资产产值率 1.000 1.000固定资产利税率 1.000 1.000资金利润率 1.000 1.000资金利税率 1.000 1.000流动资金周转天数 1.000 1.000销售收入利税率 1.000 1.000Extraction Method: Principal ComponentAnalysis.表9为各主成份特征根和累计贡献率。


一、实验目的本次实验旨在通过主成分分析(PCA)方法,对给定的数据集进行降维处理,从而简化数据结构,提高数据可解释性,并分析主成分对原始数据的代表性。
二、实验背景在许多实际问题中,数据集往往包含大量的变量,这些变量之间可能存在高度相关性,导致数据分析困难。
主成分分析(PCA)是一种常用的降维技术,通过提取原始数据中的主要特征,将数据投影到低维空间,从而简化数据结构。
三、实验数据本次实验采用的数据集为某电商平台用户购买行为的调查数据,包含用户年龄、性别、收入、职业、购买商品种类、购买次数等10个变量。
四、实验步骤1. 数据预处理首先,对数据进行标准化处理,消除不同变量之间的量纲影响。
然后,进行缺失值处理,删除含有缺失值的样本。
2. 计算协方差矩阵计算标准化后的数据集的协方差矩阵,以了解变量之间的相关性。
3. 计算特征值和特征向量求解协方差矩阵的特征值和特征向量,特征值表示对应特征向量的方差,特征向量表示数据在对应特征方向上的分布。
4. 选择主成分根据特征值的大小,选择前几个特征值对应特征向量作为主成分,通常选择特征值大于1的主成分。
5. 构建主成分空间将选定的主成分进行线性组合,构建主成分空间。
6. 降维与可视化将原始数据投影到主成分空间,得到降维后的数据,并进行可视化分析。
五、实验结果与分析1. 主成分分析结果根据特征值大小,选取前三个主成分,其累计贡献率达到85%,说明这三个主成分能够较好地反映原始数据的信息。
2. 主成分空间可视化将原始数据投影到主成分空间,绘制散点图,可以看出用户在主成分空间中的分布情况。
3. 主成分解释根据主成分的系数,可以解释主成分所代表的原始数据特征。
例如,第一个主成分可能主要反映了用户的购买次数和购买商品种类,第二个主成分可能反映了用户的年龄和性别,第三个主成分可能反映了用户的收入和职业。
六、实验结论通过本次实验,我们成功运用主成分分析(PCA)方法对数据进行了降维处理,提高了数据可解释性,并揭示了数据在主成分空间中的分布规律。

主成分分析、因子分析实验报告--SPSS主成分分析、因子分析实验报告SPSS一、实验目的主成分分析(Principal Component Analysis,PCA)和因子分析(Factor Analysis,FA)是多元统计分析中常用的两种方法,旨在简化数据结构、提取主要信息和解释变量之间的关系。
本次实验的目的是通过使用 SPSS 软件对给定的数据集进行主成分分析和因子分析,深入理解这两种方法的原理和应用,并比较它们的结果和差异。
二、实验原理(一)主成分分析主成分分析是一种通过线性变换将多个相关变量转换为一组较少的不相关综合变量(即主成分)的方法。
这些主成分是原始变量的线性组合,且按照方差递减的顺序排列。
主成分分析的主要目标是在保留尽可能多的数据信息的前提下,减少变量的数量,从而简化数据分析和解释。
(二)因子分析因子分析则是一种探索潜在结构的方法,它假设观测变量是由少数几个不可观测的公共因子和特殊因子线性组合而成。
公共因子解释了变量之间的相关性,而特殊因子则代表了每个变量特有的部分。
因子分析的目的是找出这些公共因子,并估计它们对观测变量的影响程度。
三、实验数据本次实验使用了一份包含多个变量的数据集,这些变量涵盖了不同的领域和特征。
数据集中的变量包括具体变量 1、具体变量 2、具体变量 3等,共X个观测样本。
四、实验步骤(一)主成分分析1、打开 SPSS 软件,导入数据集。
2、选择“分析”>“降维”>“主成分分析”。
3、将需要分析的变量选入“变量”框。
4、在“抽取”选项中,选择主成分的提取方法,如基于特征值大于1 或指定提取的主成分个数。
5、点击“确定”,运行主成分分析。
(二)因子分析1、同样在 SPSS 中,选择“分析”>“降维”>“因子分析”。
2、选入变量。
3、在“描述”选项中,选择相关统计量,如 KMO 检验和巴特利特球形检验。
4、在“抽取”选项中,选择因子提取方法,如主成分法或主轴因子法。

实验设计中的主成分分析方法实验设计是科学研究不可或缺的一部分,它可以帮助研究人员寻找变量之间的潜在关系并评估方案的效果。
主成分分析(PCA)是实验设计中常用的数据分析方法之一。
在本文中,我们将探讨主成分分析方法的定义、应用以及如何在实验设计中使用该方法。
什么是主成分分析?主成分分析是一种多元统计学方法,旨在将多个相关变量转换为一组无关变量,称为主成分。
主成分是根据方差的大小排序的,第一主成分包含最大方差,第二主成分次之,依此类推。
主成分的数量通常少于原始变量的数量。
主成分分析的应用主成分分析可用于不同领域的研究。
在医学领域,它可用于探索生理数据和诊断结果之间的潜在关系。
在社会科学领域,它可用于分析调查问卷数据。
在环境领域,它可用于分析水质监测数据。
主成分分析的步骤主成分分析的步骤可以归纳为以下几个步骤:1. 收集数据:将需要分析的原始数据收集起来。
2. 标准化数据:标准化数据可以确保不同变量处于相同的尺度,有利于后续的分析。
标准化可以使用z-score标准化或最大-最小标准化等方式实现。
3. 计算主成分:计算主成分可以使用传统的主成分分析方法或更高级的机器学习方法,例如k均值和深度学习。
4. 确定主成分数量:确定主成分数量的最常用方法是考虑前几个主成分的贡献率。
例如,如果前两个主成分的总贡献率超过70%,则可以将其视为显著的主成分。
5. 解释和解释主成分:通过分析每个主成分包含的变量,可以解释每个主成分的含义。
随着主成分数量的增加,解释和解释主成分会变得更为复杂。
主成分分析在实验设计中的应用主成分分析在实验设计中的应用可以分为以下几个方面:1. 降低变量数量:当实验涉及大量原始变量时,主成分分析可用于减少变量数量。
这有助于将注意力集中在更重要的变量上。
2. 探索变量之间的关系:主成分分析可用于探索变量之间的潜在关系。
如果两个变量高度相关,那么它们可能属于同一个主成分。
3. 预测:主成分分析可用于创建预测模型。

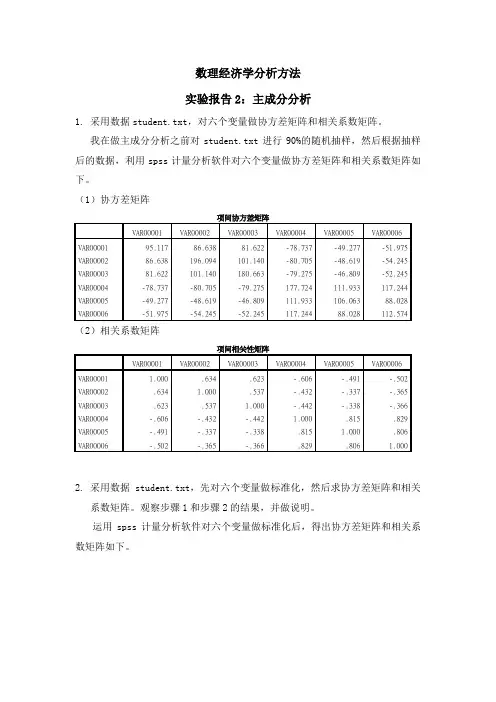
数理经济学分析方法实验报告2:主成分分析1.采用数据student.txt,对六个变量做协方差矩阵和相关系数矩阵。
我在做主成分分析之前对student.txt进行90%的随机抽样,然后根据抽样后的数据,利用spss计量分析软件对六个变量做协方差矩阵和相关系数矩阵如下。
(1)协方差矩阵(2)相关系数矩阵项间相关性矩阵VAR00001 VAR00002 VAR00003 VAR00004 VAR00005 VAR00006 VAR00001 1.000 .634 .623 -.606 -.491 -.502 VAR00002 .634 1.000 .537 -.432 -.337 -.365 VAR00003 .623 .537 1.000 -.442 -.338 -.366 VAR00004 -.606 -.432 -.442 1.000 .815 .829 VAR00005 -.491 -.337 -.338 .815 1.000 .806 VAR00006 -.502 -.365 -.366 .829 .806 1.0002.采用数据student.txt,先对六个变量做标准化,然后求协方差矩阵和相关系数矩阵。
观察步骤1和步骤2的结果,并做说明。
运用spss计量分析软件对六个变量做标准化后,得出协方差矩阵和相关系数矩阵如下。
(1)标准化后协方差矩阵(2)标准化后相关系数矩阵解释说明:步骤1是原始数据未经过标准化处理得到的协方差矩阵和相关系数矩阵,而步骤2是经过标准化处理后得到的协方差矩阵和相关系数矩阵。
从表格中,我们可以发现,标准化以后的协方差矩阵和相关系数矩阵对应相等,并且与未经标准化处理的相关系数矩阵对应相等,唯独与未经标准化处理的协方差矩阵对应不相等。
这表明在进行主成分分析时,一般采用相关系数矩阵进行分析,因为相关系数就是标准化以后的协方差,它可以消除量纲的影响,从而避免了由于量纲影响而导致的分析误差。
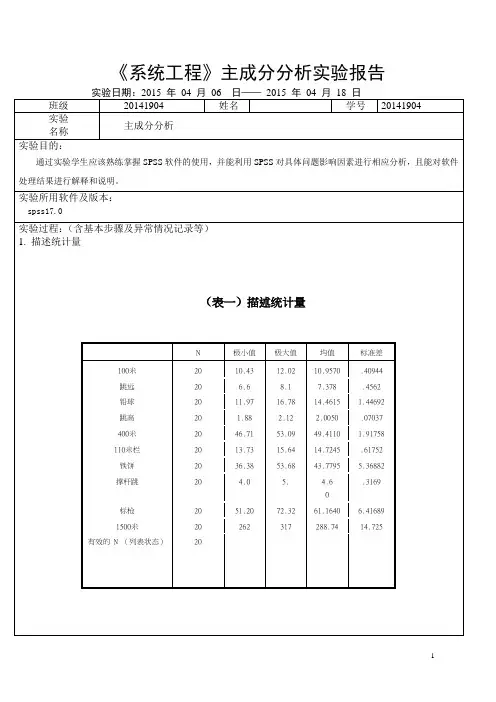
《系统工程》主成分分析实验报告
1500米.448 -.
81
-.274 -.788 .612 .577 -.267 -.404 -.124 1.000
a. 行列式 = 3.15E-005
KMO 和 Bartlett 的检验
取样足够度的 Kaiser-Meyer-Olkin 度量。
.780
Bartlett 的球形度检验近似卡方153.735
df 45
Sig. .000
由表可知:巴特利特球度检验统计量的观测值为153.735,相应的概率p值接近0,小于显著性水平(取0.05),所以应拒绝原假设,认为相关系数矩阵与单位矩阵有显著差异。
同时,KMO值为0.780,可知原有变量可以进行因子分析。
3.旋转前的因子矩阵
(表四)
表四成份矩阵也即是因子载荷矩阵,根据该表可以写出因子分析模型:
110米栏=-0.948f1+0.017f2+0.020f3 跳远=0.918f1-0.062f2+0.074f3
旋转后的成分矩阵
采用最大方差法对成份矩阵(因子载荷矩阵)实施正交旋转以使因子具有命名解释性,指定按第一因子载荷降序的顺序输出旋转后的因子载荷矩阵如表六所示
(表六)。

一、引言主成分分析(PCA)是一种常用的数据降维方法,通过对原始数据进行线性变换,将高维数据投影到低维空间,从而简化数据结构,提高计算效率。
本文通过对主成分分析实验的剖析,详细介绍了PCA的基本原理、实验步骤以及在实际应用中的注意事项。
二、实验背景随着数据量的不断增长,高维数据在各个领域变得越来越普遍。
高维数据不仅增加了计算难度,还可能导致信息过载,影响模型的性能。
因此,数据降维成为数据分析和机器学习中的关键步骤。
PCA作为一种有效的降维方法,在众多领域得到了广泛应用。
三、实验目的1. 理解主成分分析的基本原理;2. 掌握PCA的实验步骤;3. 分析PCA在实际应用中的优缺点;4. 提高数据降维的技能。
四、实验原理主成分分析的基本原理是将原始数据投影到新的坐标系中,该坐标系由主成分构成。
主成分是原始数据中方差最大的方向,可以看作是数据的主要特征。
通过选择合适的主成分,可以将高维数据降维到低维空间,同时保留大部分信息。
五、实验步骤1. 数据准备:选择一个高维数据集,例如鸢尾花数据集。
2. 数据标准化:将数据集中的每个特征缩放到均值为0、标准差为1的范围,以便消除不同特征之间的尺度差异。
3. 计算协方差矩阵:计算标准化数据集的协方差矩阵,以衡量不同特征之间的相关性。
4. 特征值分解:对协方差矩阵进行特征值分解,得到特征值和特征向量。
5. 选择主成分:根据特征值的大小选择前k个特征向量,这些向量对应的主成分代表数据的主要特征。
6. 数据投影:将原始数据投影到选择的主成分上,得到降维后的数据。
六、实验结果与分析1. 实验结果:通过实验,我们得到了降维后的数据集,并与原始数据集进行了比较。
结果表明,降维后的数据集保留了大部分原始数据的信息,同时降低了数据的维度。
2. 结果分析:实验结果表明,PCA在数据降维方面具有良好的效果。
然而,PCA也存在一些局限性,例如:(1)PCA假设数据服从正态分布,对于非正态分布的数据,PCA的效果可能不理想;(2)PCA降维后,部分信息可能丢失,尤其是在选择主成分时,需要权衡保留信息量和降低维度之间的关系;(3)PCA降维后的数据可能存在线性关系,导致模型难以捕捉数据中的非线性关系。
主成分分析的实验原理
主成分分析(Principal Component Analysis,PCA)是一种常
用的数据降维和特征提取方法,通过线性变换将原始数据转化为新的一组无关变量,称为主成分,以便于分析和解释数据的结构和关系。
PCA的实验原理基于以下假设和步骤:
1. 假设数据集包含d个变量和n个样本,构成一个d×n的数据矩阵X。
2. 对数据进行归一化处理,即对每个变量进行均值中心化处理,使得每个变量的平均值为0。
3. 计算数据矩阵X的协方差矩阵C,其中C的(i,j)元素表示第
i个变量和第j个变量之间的协方差。
4. 对协方差矩阵C进行特征值分解,得到特征值和特征向量。
特征值表示对应的特征向量所代表的方向上的方差,特征向量表示数据在该方向上的投影。
5. 选择特征值较大的前k个特征向量作为主成分,通常选择的依据是特征值的大小或者保留的方差占总方差的比例。
6. 将原始数据投影到选定的k个主成分上,得到降维后的数据矩阵Y,其中Y的维度为k×n。
7. 可选地,对降维后的数据进行可视化和进一步分析。
通过主成分分析,可以实现以下目标:
1. 提取数据中的主要特征,降低数据的维度,从而减少计算和存储的成本。
2. 去除数据中的噪声和冗余信息,提高数据的表达能力和泛化能力。
3. 揭示数据中的隐含结构和关系,帮助理解和解释数据。
4. 在数据可视化和聚类分析等任务中提供更好的表达和解释能力。
综上所述,主成分分析是一种基于线性变换和协方差分析的数据降维和特征提取方法,通过选择主要特征和投影数据到主成分上实现数据的简化和分析。
主成分分析实验报告主成分分析实验报告引言主成分分析(Principal Component Analysis, PCA)是一种常用的数据降维方法,可以将高维数据转化为低维数据,同时保留原始数据的主要信息。
本实验旨在通过主成分分析方法对一个实际数据集进行分析,探索数据的内在结构和特征。
实验设计我们选择了一个包含多个变量的数据集,该数据集包括了一些关于学生的信息,如年龄、身高、体重、成绩等。
我们的目标是通过主成分分析,找出这些变量之间的相关性,并将其转化为更少的几个主成分。
实验步骤1. 数据收集和预处理我们首先收集了一组学生的相关数据,并进行数据预处理。
对于缺失值,我们选择了删除或填补。
对于离群值,我们考虑了使用替代值或剔除的方法。
2. 数据标准化为了确保各个变量具有相同的尺度,我们对数据进行了标准化处理。
通过减去均值并除以标准差,我们使得每个变量的均值为0,标准差为1。
3. 计算协方差矩阵我们利用标准化后的数据计算协方差矩阵。
协方差矩阵反映了不同变量之间的线性关系。
4. 计算特征值和特征向量通过对协方差矩阵进行特征值分解,我们得到了一组特征值和对应的特征向量。
特征值表示了数据在对应特征向量方向上的方差。
5. 选择主成分我们按照特征值的大小,选择了最大的几个特征值对应的特征向量作为主成分。
这些主成分能够尽可能多地解释原始数据的方差。
6. 数据转化通过将原始数据与所选主成分进行线性组合,我们得到了转化后的数据。
这些转化后的数据具有更低的维度,但仍然保留了原始数据的主要信息。
实验结果通过主成分分析,我们得到了一组主成分,并计算了每个主成分对原始数据的解释方差比例。
我们发现,前几个主成分能够解释原始数据的大部分方差,而后面的主成分对方差的解释能力较弱。
讨论与结论主成分分析帮助我们发现了学生数据集中的一些内在结构和特征。
通过主成分分析,我们可以将原始数据转化为更少的几个主成分,从而降低了数据的维度,方便后续的数据分析和可视化。
实验课:主成分分析实验目的理解主成分(因子)分析的基本原理,熟悉并掌握SPSS中的主成分(因子)分析方法及其主要应用。
一、相关知识1 概念因子分析(Factor analysis):就是用少数几个因子来描述许多指标或因素之间的联系,以较少几个因子来反映原资料的大部分信息的统计学分析方法。
主成分分析(Principal component analysis):是因子分析的一个特例,是使用最多的因子提取方法。
它通过坐标变换手段,将原有的多个相关变量,做线性变化,转换为另外一组不相关的变量。
选取前面几个方差最大的主成分,这样达到了因子分析较少变量个数的目的,同时又能与较少的变量反映原有变量的绝大部分的信息。
从数学角度来看,主成分分析是一种化繁为简的降维处理技术。
两者关系:主成分分析(PCA)和因子分析(FA)是两种把变量维数降低以便于描述、理解和分析的方法,而实际上主成分分析可以说是因子分析的一个特例。
2 特点(1)因子变量的数量远少于原有的指标变量的数量,因而对因子变量的分析能够减少分析中的工作量。
(2)因子变量不是对原始变量的取舍,而是根据原始变量的信息进行重新组构,它能够反映原有变量大部分的信息。
(3)因子变量之间不存在显著的线性相关关系,对变量的分析比较方便,但原始部分变量之间多存在较显著的相关关系。
(4)因子变量具有命名解释性,即该变量是对某些原始变量信息的综合和反映。
在保证数据信息丢失最少的原则下,对高维变量空间进行降维处理(即通过因子分析或主成分分析)。
显然,在一个低维空间解释系统要比在高维系统容易的多。
3 类型根据研究对象的不同,把因子分析分为R型和Q型两种。
当研究对象是变量时,属于R型因子分析;当研究对象是样品时,属于Q型因子分析。
但有的因子分析方法兼有R型和Q型因子分析的一些特点,如因子分析中的对应分析方法,有的学者称之为双重型因子分析,以示与其他两类的区别。
4分析原理假定:有n 个地理样本,每个样本共有p 个变量,构成一个n ×p 阶的地理数据矩阵 :当p 较大时,在p 维空间中考察问题比较麻烦。
这就需要进行降维处理,即用较少几个综合指标代替原来指标,而且使这些综合指标既能尽量多地反映原来指标所反映的信息,同时它们之间又是彼此独立的。
线性组合:记x1,x2,…,xP 为原变量指标,z1,z2,…,zm (m ≤p )为新变量指标(主成分),则其线性组合为:Lij 是原变量在各主成分上的载荷无论是哪一种因子分析方法,其相应的因子解都不是唯一的,主因子解仅仅是无数因子解中之一。
Z 为因子变量或公共因子,可以理解为在高维空间中互相垂直的m 个坐标轴。
zi 与zj 相互无关;z1是x1,x2,…,xp 的一切线性组合中方差最大者,z2是与z1不相关的x1,x2,…的所有线性组合中方差最大者。
则,新变量指标z1,z2,…分别称为原变量指标的第一,第二,…主成分。
主成分分析实质就是确定原来变量xj (j=1,2 ,…,p )在各主成分zi (i=1,2,…,m )上的荷载 lij 。
从数学上容易知道,从数学上也可以证明,它们分别是相关矩阵的m 个较大的特征值所对应的特征向量。
5分析步骤5.1 确定待分析的原有若干变量是否适合进行因子分析(第一步)因子分析是从众多的原始变量中重构少数几个具有代表意义的因子变量的过程。
其潜在⎥⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎢⎣⎡=np n n p p x x x x x x x x x X 212222111211⎪⎪⎩⎪⎪⎨⎧+++=+++=+++=p mp m m m p p p p x l x l x l z x l x l x l z x l x l x l z 22112222121212121111⎪⎪⎩⎪⎪⎨⎧+++=+++=+++=p mp m m m p p p p x l x l x l z x l x l x l z x l x l x l z 22112222121212121111的要求:原有变量之间要具有比较强的相关性。
因此,因子分析需要先进行相关分析,计算原始变量之间的相关系数矩阵。
如果相关系数矩阵在进行统计检验时,大部分相关系数均小于0.3且未通过检验,则这些原始变量就不太适合进行因子分析。
进行原始变量的相关分析之前,需要对输入的原始数据进行标准化计算(一般采用标准差标准化方法,标准化后的数据均值为0,方差为1)。
SPSS 在因子分析中还提供了几种判定是否适合因子分析的检验方法。
主要有以下3种: 巴特利特球形检验(Bartlett Test of Sphericity )反映象相关矩阵检验(Anti-image correlation matrix ) KMO (Kaiser-Meyer-Olkin )检验 (1)巴特利特球形检验该检验以变量的相关系数矩阵作为出发点,它的零假设H0为相关系数矩阵是一个单位阵,即相关系数矩阵对角线上的所有元素都为1,而所有非对角线上的元素都为0,也即原始变量两两之间不相关。
巴特利特球形检验的统计量是根据相关系数矩阵的行列式得到。
如果该值较大,且其对应的相伴概率值小于用户指定的显著性水平,那么就应拒绝零假设H0,认为相关系数不可能是单位阵,也即原始变量间存在相关性。
(2)反映象相关矩阵检验该检验以变量的偏相关系数矩阵作为出发点,将偏相关系数矩阵的每个元素取反,得到反映象相关矩阵。
偏相关系数是在控制了其他变量影响的条件下计算出来的相关系数,如果变量之间存在较多的重叠影响,那么偏相关系数就会较小,这些变量越适合进行因子分析。
(3)KMO (Kaiser-Meyer-Olkin )检验该检验的统计量用于比较变量之间的简单相关和偏相关系数。
KMO 值介于0-1,越接近1,表明所有变量之间简单相关系数平方和远大于偏相关系数平方和,越适合因子分析。
其中,Kaiser 给出一个KMO 检验标准:KMO>0.9,非常适合;0.8<KMO<0.9,适合;0.7<KMO<0.8,一般;0.6<KMO<0.7,不太适合;KMO<0.5,不适合。
⎥⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎢⎣⎡=pp p p p p r r r r r r r r r R212222111211∑∑∑===----=nk nk jkj i ki nk j kj i kiij x xx xx x x xr 11221)()())((5.2 构造因子变量因子分析中有很多确定因子变量的方法,如基于主成分模型的主成分分析和基于因子分析模型的主轴因子法、极大似然法、最小二乘法等。
前者应用最为广泛。
主成分分析法(Principal component analysis ):该方法通过坐标变换,将原有变量作线性变化,转换为另外一组不相关的变量Zi (主成分)。
求相关系数矩阵的特征根λi (λ1,λ2,…,λp>0)和相应的标准正交的特征向量li ;根据相关系数矩阵的特征根,即公共因子Zj 的方差贡献(等于因子载荷矩阵L 中第j 列各元素的平方和),计算公共因子Zj 的方差贡献率与累积贡献率。
主成分分析是在一个多维坐标轴中,将原始变量组成的坐标系进行平移变换,使得新的坐标原点和数据群点的重心重合。
新坐标第一轴与数据变化最大方向对应。
通过计算特征根(方差贡献)和方差贡献率与累积方差贡献率等指标,来判断选取公共因子的数量和公共因子(主成分)所能代表的原始变量信息。
公共因子个数的确定准则:1)根据特征值的大小来确定,一般取大于1的特征值对应的几个公共因子/主成分。
2)根据因子的累积方差贡献率来确定,一般取累计贡献率达85-95%的特征值所对应的第一、第二、…、第m (m ≤p )个主成分。
也有学者认为累积方差贡献率应在80%以上。
5.3 因子变量的命名解释因子变量的命名解释是因子分析的另一个核心问题。
经过主成分分析得到的公共因子/主成分Z1,Z2,…,Zm 是对原有变量的综合。
原有变量是有物理含义的变量,对它们进行线性变换后,得到的新的综合变量的物理含义到底是什么?在实际的应用分析中,主要通过对载荷矩阵进行分析,得到因子变量和原有变量之间的关系,从而对新的因子变量进行命名。
利用因子旋转方法能使因子变量更具有可解释性。
计算主成分载荷,构建载荷矩阵A 。
),,2,1(1p i pk ki=∑=λλ),,2,1(11p i pk kik k=∑∑==λλ),,2,1,(p j i l a ij i ij ==λ⎥⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎢⎣⎡=⎥⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎢⎣⎡m pm p p m m m m pm p p m m l l l l l l l l l a a a a a a a a a A λλλλλλλλλ (211122)211211212111112212111211=⎪⎪⎧+++=+++=p p p p z a z a z a x z a z a z a x 2222121212121111⎪⎪⎧+++=+++=p p pp x l x l x l z x l x l x l z 2222121212121111计算主成分载荷,构建载荷矩阵A 。
载荷矩阵A 中某一行表示原有变量 Xi 与公共因子/因子变量的相关关系。
载荷矩阵A 中某一列表示某一个公共因子/因子变量能够解释的原有变量 Xi 的信息量。
有时因子载荷矩阵的解释性不太好,通常需要进行因子旋转,使原有因子变量更具有可解释性。
因子旋转的主要方法:正交旋转、斜交旋转。
正交旋转和斜交旋转是因子旋转的两类方法。
前者由于保持了坐标轴的正交性,因此使用最多。
正交旋转的方法很多,其中以方差最大化法最为常用。
方差最大正交旋转(varimax orthogonal rotation )——基本思想:使公共因子的相对负荷的方差之和最大,且保持原公共因子的正交性和公共方差总和不变。
可使每个因子上的具有最大载荷的变量数最小,因此可以简化对因子的解释。
斜交旋转(oblique rotation )——因子斜交旋转后,各因子负荷发生了变化,出现了两极分化。
各因子间不再相互独立,而是彼此相关。
各因子对各变量的贡献的总和也发生了改变。
斜交旋转因为因子间的相关性而不受欢迎。
但如果总体中各因子间存在明显的相关关系则应该考虑斜交旋转。
适用于大数据集的因子分析。
无论是正交旋转还是斜交旋转,因子旋转的目的:是使因子负荷两极分化,要么接近于0,要么接近于1。
从而使原有因子变量更具有可解释性。
5.4 计算因子变量得分因子变量确定以后,对于每一个样本数据,我们希望得到它们在不同因子上的具体数据值,即因子得分。
估计因子得分的方法主要有:回归法、Bartlette 法等。