多元统计分析--判别分析SPSS实验报告
- 格式:doc
- 大小:292.50 KB
- 文档页数:8

《应用多元统计分析》第四章判别分析实验报告第四章判别分析实验报告实验环境Windows xp、Windows vista、Windows 7等,软件SPSS 11.0版本及以上。
实验结果与分析本题中记变量值CF_TD, NI_TA, CA_CL, CA_NS分别为X1,X2,X3,X4 (1)Fisher判别函数特征值EigenvaluesFunction Eigenvalue% of Variance Cumulative %CanonicalCorrelation1.940a100.0100.0.696a. First 1 canonical discriminant functions were used in the analysis.(2)Fisher判别函数有效性检验Wilks' LambdaTest ofFunction(s)Wilks' Lambda Chi-square df Sig.1.51527.8394.000(3)标准化的Fisher判别函数系数Standardized Canonical Discriminant FunctionCoefficientsFunction1CF_TD.134NI_TA.463CA_CL.715CA_NS-.220所以标准化的判别函数为:Y=0.134X1+0.463X2+0.715X3-0.220X4得出Y=0.9012(4)未标准化的Fisher判别函数系数Canonical Discriminant Function CoefficientsFunction1CF_TD.629NI_TA 4.446CA_CL.889CA_NS-1.184 (Constant)-1.327 Unstandardized coefficients所以为标准化的费希尔判别函数为:Y=-1.327+0.629X1+4.446X2+0.889X3-1.184X4得出Y=-0.1703(5)组重心处的费希尔判别函数值Functions at Group CentroidsG Function11.8692-1.035 Unstandardized canonical discriminant functions evaluated at group means各类重心在空间中的坐标位置。

【精品】多元统计分析--判别分析SPSS实验报告一、实验目的1.掌握判别分析的基本原理和应用方法;2.掌握SPSS软件进行判别分析的具体操作;3.通过一个实例,学习如何运用判别分析对指标进行判别。
二、实验内容三、实验原理1.判别分析基本原理:判别分析(Discriminant Analysis),是一种统计学中的分类技术,它是对变量进行归类的技术。
判别分析是用来确定一个对象或自变量集合属于哪一个预设类型或者组别的过程。
判别分析能够生成一个函数,将数据点映射到特定的类型上。
判别分析的应用领域非常广泛,主要应用于以下领域:(1)股票市场(预测股价的涨跌与时间、公司发展情况等因素的关系);(2)医学(区分疾病、患者状态等);(3)市场调查(确定客户类型、产品或服务喜好);(4)产业分析(区分有助于产品销售的市场决策因素);(5)经济学(预测月度或季度的经济指标)。
3.判别分析的主要应用步骤:(1)建立模型:首先选择和收集数据,将收集的数据分为训练集和测试集;(2)训练模型:使用训练数据建立模型;(3)评估模型:通过模型诊断来评估建立的模型的好坏;(4)应用模型:对新的数据建立模型并进行预测。
四、实验过程1. 上机操作:1)打开SPSS软件,加载数据文件;2)选择分类变量和连续变量;3)选择训练数据集;4)建立模型;5)预测实验数据集。
2. 操作步骤:SPSS分析的步骤如下:1)将数据输入SPSS软件,确保数据格式正确;2)选择Analyse- Classify- Discriminant;3)有两种不同的分类变量,单分类或多分类,如果你要解释一个特定的分类变量,选择单分类。
如果你不确定哪个分类变量最适合,请尝试不同的选项;4)选择两个或更个你认为与指定分类变量相关的连续变量;5)选择要用于判别分析的数据集;6)确定分类变量分类比率。
这可以在设置选项中完成;7)点击OK,开始进行分析;8)评估结果,包括汇总、判别函数、方差-方差贡献、判别矩阵;五、实验结果选取鸢尾花数据,经过训练,得到如下表所示的结果。



华东理工大学2013—2014 学年第二学期《多元统计分析与SPSS应用》实验报告6班级学号姓名开课学院商学院任课教师任飞成绩实验报告:1、使用默认值进行判别分析打开“data14-04.sav”文件,依次选择Analyze→Classify →Discriminant,将变量“slen,swid,plen,pwid”移入Independents框,将变量“spno”移入Grouping V ariables框,单击Grouping Variables框,再在Define Range弹出框中,Minimum输入1,Maximum输入2,如图1.1所示,单击OK输入结果如图1.2、图1.3、图1.4、图1.5所示图1.1图1.2Analysis Case P rocessing Su mmary150100.00.00.00.00.0150100.0Unweighted Cases Valid Missing orout-of-range group codesAt least one missing discriminating variable Both missing or out-of-range group codes and at least one missing discriminating variable TotalExcluded TotalN Percent分析:总体样本为150个,有效样本数为150个,占总数的100%,无效或者未分组的样本数为0个。
图1.3分析:图1.4为分组统计量列表分析:图1.4为Fisher 判别法的两个Fisher 判别函数特征值。
Function1的特征值为30.419,解释了99%的变异.典型相关系数为0.984。
Function2的判别函数的特征值为0.293,解释了1%的变异.典型相关系数为0.476。
其特征值是组间平方和与组内平方和之比。

判别分析实验报告SPSS实验目的:判别分析(Discriminant Analysis)是一种经典的多元统计分析方法,用于解释和预测分类变量。
该实验旨在使用SPSS软件进行判别分析,探索一组变量对分类结果的贡献和预测能力。
实验步骤:1.数据收集:从一些公司的人力资源数据库中随机选择了200个员工作为样本,收集了以下变量:性别(男、女)、教育程度(本科、研究生、博士)、工龄(年)、绩效评分(0-5)、离职与否(是、否)。
2.数据清洗:检查数据中是否存在缺失值,并对缺失值进行处理。
删除离职与否变量中缺失值。
3.数据探索:使用SPSS进行描述性统计分析,了解样本的基本情况。
分别计算男女性别比例和各教育程度及离职状态的分布情况。
4. 变量选择:使用SPSS进行判别分析,将离职与否作为分类变量,性别、教育程度、工龄和绩效评分作为预测变量。
使用Wilks' Lambda检验选择预测变量,确定对分类结果的贡献。
5.判别函数计算:根据选择的预测变量,计算判别函数。
使用判别函数对样本进行分类,并计算分类结果的准确率。
实验结果:1.数据探索结果显示,样本中男女性别比例约为1:1,教育程度主要集中在本科和研究生,离职比例为14%。
2. 判别分析结果显示,Wilks' Lambda检验结果为0.632,p值小于0.05,说明选取的预测变量对分类结果有统计上显著的贡献。
3.计算得到的判别函数为D=-0.311(性别)+0.236(教育程度)+0.011(工龄)+0.585(绩效评分)。
4.使用判别函数对样本进行分类,分类准确率为81.5%。
其中,离职样本的分类准确率为75%,非离职样本的分类准确率为82%。
实验结论:通过判别分析实验,我们得出以下结论:1.性别、教育程度、工龄和绩效评分这四个变量对员工的离职与否有显著的预测能力。
2.预测变量中绩效评分对离职结果的贡献最大,说明绩效评分较低的员工更容易离职。

《多元统计分析》实验报告实验名称: 判别分析及正态检验专业:统计学班级:120802姓名:指导教师:2014 年6 月26 日给出血友病基因携带者数据1,共分2组,第一组为非携带者(1π),第二组为必然携带者(2π),分组变量为g ,变量x1表示()10log AHF 活性,变量x2表示()10log AHF 抗原,利用上述数据: (1)对两个组检查二元正态性假定;一通过菜单系统实现 二运行结果第一组的正态性检验一运行程序proc princomp data=sasuser.zu1 out=prin prefix=z standard;var x1 x2;run;proc univariate data=work.prin normal plot;var z1 z2;run;二运行结果三结论分析第二组的正态性检验一运行程序proc princomp data=sasuser.zu2 out=prin1 prefix=z standard; var x1 x2;run;proc univariate data=work.prin1 normal plot;var z1 z2;run;二运行结果三结论分析(2)假定两组先验概率相等,求样本线性判别函数,并估计误判概率;一运行程序proc discrim data=sasuser.liangzu listerr crosslisterr;class g;var x1-x2;run;二运行结果三结论分析(3)将血友病基因携带者数据2中的10个新事例用(2)得到的判别函数进行分类;一运行程序proc discrim data=sasuser.liangzu testdata=sasuser.daipan listerr crosslisterr testlist;class g;var x1-x2;run;二运行结果三结论分析(3)假定必然携带者(组2)的先验概率为0.25。

多元统计分析实验报告(精选多篇)第一篇:多元统计分析实验报告多元统计分析得实验报告院系:数学系班级:13级 B 班姓名:陈翔学号:20131611233 实验目得:比较三大行业得优劣性实验过程有如下得内容:(1)正态性检验;(2)主体间因子,多变量检验a;(3)主体间效应得检验;(4)对比结果(K 矩阵);(5)多变量检验结果;(6)单变量检验结果;(7)协方差矩阵等同性得Box 检验a,误差方差等同性得Levene 检验 a;(8)估计;(9)成对比较,多变量检验;(10)单变量检验。
实验结果:综上所述,我们对三个行业得运营能力进行了具体得比较分析,所得数据表明,从总体来瞧,信息技术业要稍好于电力、煤气及水得生产与供应业以及房地产业。
1。
正态性检验Kolmogorov-SmirnovaShapir o—Wilk 统计量 df Sig.统计量df Sig、净资产收益率。
113 35、200*。
978 35。
677 总资产报酬率。
121 35、200*。
964 35、298 资产负债率。
086 35。
200*.962 35、265 总资产周转率.180 35、006。
864 35。
000流动资产周转率、164 35、018.88535、002 已获利息倍数、28135.000。
55135、000 销售增长率.103 35、200*。
949 35、104 资本积累率。
251 35。
000、655 35。
000 *。
这就是真实显著水平得下限。
a。
Lilliefors显著水平修正此表给出了对每一个变量进行正态性检验得结果,因为该例中样本中n=35<2000,所以此处选用 Shapiro—W ilk 统计量。
由 Sig。
值可以瞧到,总资产周转率、流动资产周转率、已获利息倍数及资本积累率均明显不遵从正态分布,因此,在下面得分析中,我们只对净资产收益率、总资产报酬率、资产负债率及销售增长率这四个指标进行比较,并认为这四个变量组成得向量遵从正态分布(尽管事实上并非如此)。

华东理工大学《多元统计分析与SPSS应用实验》实验报告2 班级学号姓名开课学院商学院任课教师任飞成绩实验报告:实验2.1 熟悉One---Sample T Test 功能(1)选用Employee data.sav 文件中的变量,Analyze→Compare Means→One---Sample T Test,将salary作为Test因变量,test值分别取34000、35000、34419、24000,作均值检验。
如图实验结果:1.Test Value=34000:双尾概率P=0.593>α=0.05,故接受原假设,说明样本salary均值与假设值34000无显著性差异;2.Test Value=35000:双尾概率P=0.460>α=0.05,故接受原假设,说明样本salary均值与假设值35000无显著性差异;3.Test Value=34419:双尾概率P=0.999>>α=0.05,故接受原假设,说明样本salary均值与假设值35000不仅无显著性差异,而且接近样本均值。
4.Test Value=24000:双尾概率P=0.00<<α=0.05,故接受原假设,说明样本salary均值与假设值24000显著性差异。
(2). 仍选用Employee data.sav 文件中的变量,先作10%的随机抽样,然后将salary作为Test因变量,test 值取34419,作均值检验。
随机抽样:data→select cases→random sample of cases→sample→approximately 10%→Continue→OK实验结果(部分原始数据序号被划掉):再均值检验过程:Analyze →Compare Means →One---Sample T Test,将salary作为Test因变量,test 值取34419,所得实验数据结果如下图所示:双尾概率P=0.284>α=0.05,故接受原假设,说明随机抽样样本的salary均值与假设值34419无显著性差异。
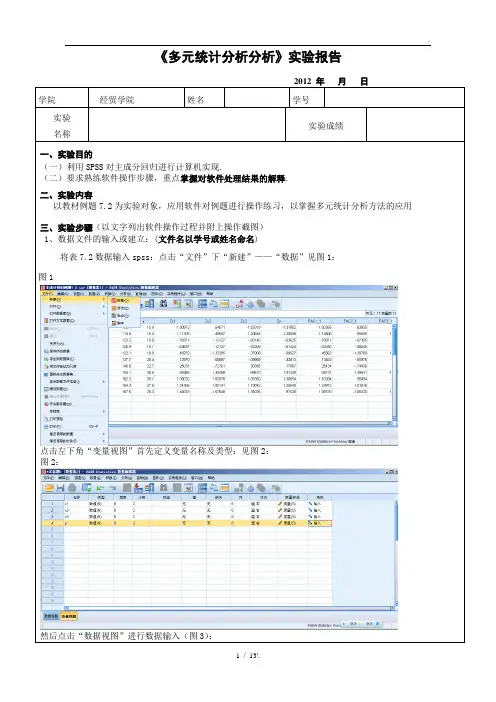
《多元统计分析分析》实验报告2012 年月日学院经贸学院姓名学号实验实验成绩名称一、实验目的(一)利用SPSS对主成分回归进行计算机实现.(二)要求熟练软件操作步骤,重点掌握对软件处理结果的解释.二、实验内容以教材例题7.2为实验对象,应用软件对例题进行操作练习,以掌握多元统计分析方法的应用三、实验步骤(以文字列出软件操作过程并附上操作截图)1、数据文件的输入或建立:(文件名以学号或姓名命名)将表7.2数据输入spss:点击“文件”下“新建”——“数据”见图1:图1点击左下角“变量视图”首先定义变量名称及类型:见图2:图2:然后点击“数据视图”进行数据输入(图3):图3完成数据输入2、具体操作分析过程:(1)首先做因变量Y与自变量X1-X3的普通线性回归:在变量视图下点击“分析”菜单,选择“回归”-“线性”(图4):图4将因变量Y调入“因变量”栏,将x1-x3调入“自变量”栏(图5):然后选择相关要输出的结果:①点击右上角“统计量(s)”:“回归系数”下选择“估计”;“残差”下选择“D.W”;在右上角选择输出“模型拟合度”、“部分相关和偏相关”“共线性诊断”(后两项是做多重共线性检验)。
选完后点击“继续”(见图6)②如果需要对因变量与残差进行图形分析则需要在“绘制”下选择相关项目(图7),一般不需要则继续③如果需要将相关结果如因变量预测值、残差等保存则点击“保存”(图8),选择要保存的项目④如果是逐步回归法或者设置不带常数项的回归模型则点击“选项”(图9)其他选项按软件默认。
最后点击“确定”,运行线性回归,输出相关结果(见表1-3)图5 图6图7图8图9回归分析输出结果:的协差阵也就是相关阵进行分解做因子分析或主成分分析),如果不需要对变量做标准化处理就选“协方差矩阵”;“输出”中的两项都选,要求输出没有旋转的因子解(主成分分析必选项)和碎石图(用图形决定提取的主成分或因子的个数);“抽取“下,默认的是基于特征值(大于1表示提取的因子或主成分至少代表1个单位标准差的变量信息,因为标准化后的变量方差为1,因子或者主成分作为提取的综合变量应该至少代表1个变量的信息),也可以自选提取的因子个数(即第二项),本例中做主成分回归,选择提取全部可能的3个主成分,所以自选个数填3。

判别分析:实验步骤:1. 在SPSS窗口中选择:分析-分类-判别,将变量导入自变量框中,group 导入分组变量中,选择定义范围,最小为1最大为3,并选择一起输入自变量,点击继续2. 点击统计量,描述性中选择“均值”,“单变量”和”Box”,选择函数系数中的“Fisher”“未标准化”,矩阵中选择“组内相关”,点击继续3. 点击分类点击继续4. 点击“保存”,三个框均选中,点击继续5. 点击确定实验结果分析:1. 表1 组统计量看各个总体在均值等指标上的值是否接近,若接近说明各类之间在该指标差异不大表2组均值的均等性的检验Wilks 的 Lambda F df1 df2 Sig. 0岁组死亡概率.997 .019 2 12 .981 1岁组死亡概率.990 .063 2 12 .939 10岁组死亡概率.645 3.301 2 12 .072 55岁组死亡概率.438 7.690 2 12 .007 80岁组死亡概率.174 28.557 2 12 .000由表中看到第一二六个指标的sig值很大,说明拒绝原假设,在总体间差异不大表3 汇聚的组内矩阵若自变量之间存在高度相关,则判别分析价值不大,但并不严格,允许出现一定的相关表4 协方差矩阵的均等性的箱式检验检验结果 p值>0.05时,说明协方差矩阵相等,可以进行bayes检验表5由表5看出,函数1的特征值很大,对判别的贡献大表6表7给出非标准化的典型判别函数系数典型判别式函数系数函数1 20岁组死亡概率-1.861 -.8671岁组死亡概率 1.656 1.155 10岁组死亡概率-.877 -.356 55岁组死亡概率.798 -.089 80岁组死亡概率.098 .054平均预期寿命 1.579 .690 (常量) -74.990 -29.482由表7可知,两个Fisher判别函数分别为表8 结构矩阵结构矩阵函数1 20岁组死亡概率.008* -.001 80岁组死亡概率.288 -.388* 55岁组死亡概率.149 -.199* 10岁组死亡概率.098 .106* 1岁组死亡概率.007 .104* 平均预期寿命-.036 .091*该表是原始变量与典型变量(标准化的典型判别函数)的相关系数,相关系数的绝对值越大,说明原始变量与这个判别函数的相关性越强表9 组重心处的函数由表9可知各类别重心的位置,通过计算观测值与各重心的距离,距离最小的即为该观测值的分类。
. . .数学与计算科学学院实验报告实验项目名称相应与典型相关分析所属课程名称多元统计分析实验实验类型验证型实验日期2016年6月13日星期一班级学号姓名成绩因素B 具有对等性。
通过变换。
得c '=ΣZ Z ,r '=ΣZZ 。
(3)对因素B 进行因子分析。
计算出c '=ΣZ Z 的特征向量 及其相应的特征向量计算出因素B 的因子)(4)对因素A 进行因子分析。
计算出r '=ΣZZ 的特征向量 及其相应的特征向量计算出因素A 的因子(5)选取因素B 的第一、第二公因子 选取因素A 的第一、第二公因子将B 因素的c 个水平,,A 因素的r 个水平同时反应到相同坐标轴的因子平面上上(6)根据因素A 和因素B 各个水平在平面图上的分布,描述两因素及各个水平之间的相关关系。
1.3 在进行相应分析时,应注意的问题要注意通过独立性检验判定是否有必要进行相应分析。
因此在进行相应分析前应做独立性检验。
独立性检验中,0H :因素A 和因素B 是独立的;1H :因素A 和因素B 不独立 由上面的假设所构造的统计量为2211ˆ[()]ˆ()rcij ij i j ijk E k E k χ==-=∑∑211()r c ij i j k z ===∑∑ 其中....(/)/ij ij i j i j z k k k k k k =-,拒绝区域为221[(1)(1)]r c αχχ->--()(1)()(1)i i P Pa X '++a X ()(2)()(2)i i q qb X '++b X(2))1=X 的条件下,使得()(2)()(2)i i q qb X '+b X(2))1=X 的条件下,使得(1)、(2)X 的第一对典型相关变量。
1,2,,)r()p⎦()p ⎥⎦pU⎥⎥⎦p V⎥⎥⎦*(1)*== A X V Bˆˆr() ++b bz【实验过程】(实验步骤、记录、数据、分析)一.问题1的求解步骤:1. 将数据输入在SPSS后,在窗口中选择数据→加权个案,调出加权个案主界面,并将变量人数移入加权个案中的频率变量框中。
判别分析实验报告 SPSS一、实验目的判别分析是一种用于分类和预测的统计方法。
本次实验旨在通过使用 SPSS 软件,掌握判别分析的基本原理和操作流程,能够运用判别分析方法对实际数据进行分类,并对分类结果进行评估和解释。
二、实验数据本次实验使用的数据集包含了两个类别(类别 A 和类别 B)的样本,每个样本具有若干个特征变量,如年龄、收入、教育程度等。
数据集共有 200 个样本,其中类别 A 有 100 个样本,类别 B 有 100 个样本。
三、实验步骤1、数据导入首先,打开 SPSS 软件,选择“文件”菜单中的“打开”选项,将实验数据文件导入到 SPSS 中。
2、变量定义在 SPSS 数据视图中,对各个变量进行定义,包括变量名称、变量类型、变量标签等。
3、判别分析操作选择“分析”菜单中的“分类”子菜单,然后点击“判别分析”选项。
在弹出的判别分析对话框中,将类别变量选入“分组变量”框中,将其他特征变量选入“自变量”框中。
4、选择判别方法SPSS 提供了多种判别方法,如费希尔判别法、贝叶斯判别法等。
本次实验选择费希尔判别法。
5、模型评估在判别分析结果中,查看判别函数的系数、判别函数的显著性检验、分类结果的准确性等指标,以评估模型的性能。
四、实验结果与分析1、判别函数系数判别函数的系数反映了各个自变量对判别函数的贡献程度。
通过查看系数的大小和符号,可以了解各个变量在区分不同类别中的重要性。
例如,年龄变量的系数为正,说明年龄越大,越有可能属于某个类别;而收入变量的系数为负,说明收入越低,越有可能属于另一个类别。
2、判别函数的显著性检验通过对判别函数的显著性检验,可以判断判别函数是否能够有效地区分不同的类别。
如果检验结果显著,说明判别函数具有统计学意义,可以用于分类。
3、分类结果SPSS 会给出每个样本的分类结果,以及分类的准确性。
通过比较实际类别和预测类别,可以评估模型的分类效果。
如果分类准确性较高,说明模型能够较好地对样本进行分类;如果分类准确性较低,则需要进一步分析原因,可能是数据质量问题、变量选择不当或者判别方法不合适等。
实验课程名称: __多元统计分析--判别分析___准则判别归类,则可写成:⎪⎩⎪⎨⎧=>∈<∈),(),( ,),(),(,),(),(,21212211G X D G X D G X D G X D G X G X D G X D G X 当待判当当题目:表11.5的数据包含三种鸢尾的X2=萼片宽度与X4=花瓣的宽度的观测值。
对每种鸢尾有n1=n2=n3=50个观测值。
部分数据:第二部分:实验过程记录(可加页)(包括实验原始数据记录,实验现象记录,实验过程发现的问题等)散点图:图形→旧对话框→散点图,打开简单散点图子对话框;将想X2选入X轴变量,X4选入Y轴变量,将总体选入设置标记框中,点击确定。
判别分析:步骤:1、选择分析→分类→判别,打开判别分析子对话框。
2、选择变量“总体”,单击→,将其加入到分组变量栏中。
3、打开定义范围子对话框,最小值输入1,最大值输入3。
4、将变量“X2萼片宽度”、“X4花瓣的宽度”选入自变量栏中。
选择“一起输入自变量”的方法。
5、打开统计变量子对话框,选择均值、单变量ANOVA、Box’M、未标准化、组内协方差、分组协方差及总体协方差,单击继续。
6、打开分类子对话框,选择不考虑该个案时的分类,其余为默认值。
7、打开保存,选择所有的变量。
相关系数矩阵a总体萼片宽度X2 花瓣宽度X4合计萼片宽度X2 .190 -.122花瓣宽度X4 -.122 .581对数行列式总体秩对数行列式1 2 -6.4962 2 -6.1413 2 -5.189汇聚的组内 2 -5.583检验结果箱的M 52.832F 近似。
8.632df1 6df2 538562.769Sig. .000Wilks 的Lambda函数检验Wilks 的Lambda 卡方df Sig.1 到2 .038 477.868 4 .0002 .809 31.075 1 .000典型判别式函数系数函数1 2萼片宽度X2 -1.987 2.680花瓣宽度X4 5.477 .817(常量) -.494 -9.174非标准化系数组质心处的函数总体函数1 21 -5.958 .2152 1.265 -.6673 4.693 .452分类结果b,c总体预测组成员1 2 3 合计初始计数 1 50 0 0 502 0 49 1 503 04 46 50% 1 100.0 .0 .0 100.02 .0 98.0 2.0 100.03 .0 8.0 92.0 100.0 交叉验证a计数 1 50 0 0 502 0 48 2 503 04 46 50% 1 100.0 .0 .0 100.02 .0 96.0 4.0 100.03 .0 8.0 92.0 100.0。
数学实验报告判别分析一、实验目的要求熟练掌握运用SPSS软件实现判别分析。
二、实验内容已知某研究对象分为3类,每个样品考察4项指标,各类观测的样品数分别为7,4,6;另外还有2个待判样品分别为第一个样品:=-=-==x x x x18,214,316,456第二个样品:==-==x x x x192,217,318,4 3.0运用SPSS软件对实验数据进行分析并判断两个样品的分组。
三、实验步骤及结论1.SPSS数据分析软件中打开实验数据,并将两个待检验样本键入,作为样本18和样本19。
2.实验分析步骤为:分析→分类→判别分析3.得到实验结果如下:(1)由表1,对相等总体协方差矩阵的零假设进行检验,Sig值为0.022<0.05,则拒绝原假设,则各分类间协方差矩阵相等。
表1 协方差阵的均等性函数检验结果表检验结果a箱的 M 35.960 F 近似。
2.108df1 10df2 537.746Sig. .022由表2可得,函数1所对应的特征值贡献率已达到99.6%,说明样本数据均向此方向投影就可得到效果很高的分类,故只取函数1作为投影函数,舍去函数2不做分析。
表3为典型判别式函数的Wilks的Lambda检验,此检验中函数1的Wilks Lambda检验sig值为0.022<0.05,则拒绝原假设,说明函数1判别显著。
表4为求得的各典型函数判别式函数系数,由此表可以求得具体函数,得y=9.240+0.010x1+0.543x2+0.047x3-0.068x4。
表5 组质心处函数值表组质心处的函数类别号函数1 21.00 -1.846 -.0322.00 .616 .1783.00 1.744 -.081 在组均值处评估的非标准化典型判别式函数由表5给出的组质心处的函数值,可以得到函数1的置信坐标为(-1.846,0.616,1.744)。
(2)关于两个待判样本的分组方法:将样本1的因变量数据代入方程y=9.240+0.010x1+0.543x2+0.047x3-0.068x4求得y1=-1.498,分别减去上表中-1.846,0.616,1.744,取绝对值得0.348,0.882,0.246,则样本1为第1组;同理可得,y2=1.571,分别减去上表中-1.846,0.616,1.744,取绝对值得3.417,0.955,0.173,则样本2为第3组。
可编辑修改精选全文完整版实验报告5判别分析(设计性实验)(Discriminant analysis)实验原理:判别分析是判别样品所属类型的一种统计方法。
判别分析是在已知研究对象分成若干类型(或组别)并已取得各种类型的一批已知样品的观测数目,在此基础上根据某些准则建立判别式,然后对未知类型的样品进行判别分类。
本实验要求学生应用距离判别准则(即,对任给的一次观测,若它与第i类的重心距离最近,就认为它来自第i类),对两总体和多总体情形下分别进行判别分析。
实验中需注意协方差矩阵相等时,选取线性判别函数;协方差矩阵不相等时,应选取二次判别函数。
实验题目一:为了检测潜在的血友病A携带者,下表中给出了两组数据:(t11a8)其中x1=log10(AHF activity),x2=log10(AHF antigen)。
下表给出了五个新的观测,试对这些观测判别归类;(t11b8)实验要求:(1)分别检验两组数据是否大致满足二元正态性;(2)分别计算两组数据的协方差矩阵,是否可以认为两者近似相等?(3)对训练样本和新观测合并作散点图,不同的类用不同颜色标识;(4)用lda函数做判别分析,即在协方差矩阵相等的情形下作判别分析;(5)用qda函数做判别分析,即在协方差矩阵不相等的情形下作判别分析;(6)比较方法(4)和方法(5)的误判率。
实验题目二:某商学研究生院的招生官员利用指标――大学期间平均成绩GPA和研究生管理能力考试GMAT的成绩,将申请者分为三类:接受,不接受,待定。
下表中给出了三类申请者的GPA与GMAT成绩:(t11a6)GPA (x1)GMAT(x2)接受GPA(x1)GMAT(x2)不接受GPA(x1)GMAT(x2)待定2.96 596 1 2.54 446 2 2.86 494 33.14 473 1 2.43 425 2 2.85 496 3 3.22 482 1 2.2 474 2 3.14 419 3 3.29 527 1 2.36 531 2 3.28 371 3 3.69 505 1 2.57 542 2 2.89 447 3 3.46 693 1 2.35 406 2 3.15 313 3 3.03 626 1 2.51 412 2 3.5 402 3 3.19 663 1 2.51 458 2 2.89 485 3 3.63 447 1 2.36 399 2 2.8 444 33.59 588 1 2.36 482 2 3.13 416 33.3 563 1 2.66 420 2 3.01 471 33.4 553 1 2.68 414 2 2.79 490 33.5 572 1 2.48 533 2 2.89 431 33.78 591 1 2.46 509 2 2.91 446 33.44 692 1 2.63 504 2 2.75 546 33.48 528 1 2.44 336 2 2.73 467 33.47 552 1 2.13 408 2 3.12 463 33.35 520 1 2.41 469 2 3.08 440 33.39 543 1 2.55 538 2 3.03 419 33.28 523 1 2.31 505 2 3 509 33.21 530 1 2.41 489 2 3.03 438 33.58 564 1 2.19 411 2 3.05 399 33.33 565 1 2.35 321 2 2.85 483 33.4 431 1 2.6 394 2 3.01 453 33.38 605 1 2.55 528 2 3.03 414 33.26 664 1 2.72 399 2 3.04 446 33.6 609 1 2.85 381 23.37 559 1 2.9 384 23.8 521 13.76 646 13.24 467 1实验要求:(1)对上表中的数据作散点图,不同的类用不同的颜色标识;(2)用lda函数做判别分析,即在协方差矩阵相等的情形下作判别分析;(3)用qda函数做判别分析,即在协方差矩阵不相等的情形下作判别分析;(4)比较方法(2)和方法(3)的误判率;(5)现有一新申请者的GPA为3.21,GMAT成绩为497。
实验课程名称: __多元统计分析--判别分析___
准则判别归类,则可写成:
⎪⎩
⎪
⎨⎧=>∈<∈)
,(),( ,),(),(,),(),(,21212211G X D G X D G X D G X D G X G X D G X D G X 当待判当当
题目:表11.5的数据包含三种鸢尾的X2=萼片宽度与X4=花瓣的宽度的观测值。
对每种鸢尾有n1=n2=n3=50个观测值。
部分数据:
第二部分:实验过程记录(可加页)(包括实验原始数据记录,实验现象记录,实验过程发现的问题等)
散点图:图形→旧对话框→散点图,打开简单散点图子对话框;将想X2选入X轴变量,X4选入Y轴变量,将总体选入设置标记框中,点击确定。
判别分析:
步骤:
1、选择分析→分类→判别,打开判别分析子对话框。
2、选择变量“总体”,单击→,将其加入到分组变量栏中。
3、打开定义范围子对话框,最小值输入1,最大值输入3。
4、将变量“X2萼片宽度”、“X4花瓣的宽度”选入自变量栏中。
选择“一起输入自
变量”的方法。
5、打开统计变量子对话框,选择均值、单变量ANOVA、Box’M、未标准化、组内协
方差、分组协方差及总体协方差,单击继续。
6、打开分类子对话框,选择不考虑该个案时的分类,其余为默认值。
7、打开保存,选择所有的变量。
相关系数矩阵a
总体萼片宽度X2 花瓣宽度X4
合计萼片宽度X2 .190 -.122
花瓣宽度X4 -.122 .581
对数行列式
总体秩对数行列式
1 2 -6.496
2 2 -6.141
3 2 -5.189
汇聚的组内 2 -5.583
检验结果
箱的M 52.832
F 近似。
8.632
df1 6
df2 538562.769
Sig. .000
Wilks 的Lambda
函数检
验Wilks 的Lambda 卡方df Sig.
1 到
2 .038 477.868 4 .000
2 .809 31.075 1 .000
典型判别式函数系数
函数
1 2
萼片宽度X2 -1.987 2.680
花瓣宽度X4 5.477 .817
(常量) -.494 -9.174
非标准化系数
组质心处的函数
总体
函数
1 2
1 -5.958 .215
2 1.265 -.667
3 4.693 .452
分类结果b,c
总体
预测组成员
1 2 3 合计
初始计数 1 50 0 0 50
2 0 49 1 50
3 0
4 46 50
% 1 100.0 .0 .0 100.0
2 .0 98.0 2.0 100.0
3 .0 8.0 92.0 100.0 交叉验证a计数 1 50 0 0 50
2 0 48 2 50
3 0
4 46 50
% 1 100.0 .0 .0 100.0
2 .0 96.0 4.0 100.0
3 .0 8.0 92.0 100.0。