聚类分析和MATLAB实现完整版.ppt
- 格式:ppt
- 大小:1.34 MB
- 文档页数:66





用matlab做聚类分析MATLAB提供了两种方法进行聚类分析:一、利用clusterdata 函数对数据样本进行一次聚类,这个方法简洁方便,其特点是使用范围较窄,不能由用户根据自身需要来设定参数,更改距离计算方法;二、步聚类:(1)用pdist函数计算变量之间的距离,找到数据集合中两辆变量之间的相似性和非相似性;(2)用linkage函数定义变量之间的连接;(3)用cophenet函数评价聚类信息;(4)用cluster函数进行聚类。
下边详细介绍两种方法:1、一次聚类Clusterdata函数可以视为pdist、linkage与cluster的综合,即Clusterdata函数调用了pdist、linkage和cluster,用来由原始样本数据矩阵X创建系统聚类,一般比较简单。
clusterdata函数的调用格式:T=clusterdata(X,cutoff)输出参数T是一个包含n个元素的列向量,其元素为相应观测所属类的类序号。
输入 的矩阵,矩阵的每一行对应一个观测(样品),每一列对应一个变量。
Cutoff 参数X是n p为阈值。
(1)当0<cutoff<2时,T=clusterdata(X,cutoff) 等价于Y=pdist(X,’euclid’); Z=linkage(Y,’single’); T=cluster(Z,’cutoff’,cutoff) ;(‘cutoff’指定不一致系数或距离的阈值,参数值为正实数)(2)Cutoff>>2时,T=clusterdata(X,cutoff) 等价于Y=pdist(X,’euclid’); Z=linkage(Y,’single’); T=cluster(Z, ‘maxclust’,cutoff) ;(‘maxclust’指定最大类数,参数值为正整数)2、分步聚类(1)求出变量之间的相似性用pdist函数计算出相似矩阵,有多种方法可以求距离,若此前数据还未无量纲化,则可用zscore函数对其标准化【pdist函数:调用格式:Y=pdist(X,’metric’)说明:X是M*N矩阵,为由M个样本组成,每个样本有N个字段的数据集‘seuclidean’:metirc取值为:’euclidean’:欧氏距离(默认)标准化欧氏距离;‘mahalanobis’:马氏距离;闵科夫斯基距离:‘ minkowski’;绝对值距离:‘ cityblock’…】pdist生成一个M*(M-1)/2个元素的行向量,分别表示M个样本两两间的距离。

§8.利用Matlab和SPSS软件实现聚类分析1. 用Matlab编程实现运用Matlab中的一些基本矩阵计算方法,通过自己编程实现聚类算法,在此只讨论根据最短距离规则聚类的方法。
调用函数:min1.m——求矩阵最小值,返回最小值所在行和列以及值的大小min2.m——比较两数大小,返回较小值std1.m——用极差标准化法标准化矩阵ds1.m——用绝对值距离法求距离矩阵cluster.m——应用最短距离聚类法进行聚类分析print1.m——调用各子函数,显示聚类结果聚类分析算法假设距离矩阵为vector,a阶,矩阵中最大值为max,令矩阵上三角元素等于max聚类次数=a-1,以下步骤作a-1次循环:求改变后矩阵的阶数,计作c求矩阵最小值,返回最小值所在行e和列f以及值的大小gfor l=1:c,为vector(c+1,l)赋值,产生新类令第c+1列元素,第e行和第f行所有元素为,第e列和第f列所有元素为max源程序如下:%std1.m,用极差标准化法标准化矩阵function std=std1(vector)max=max(vector); %对列求最大值min=min(vector);[a,b]=size(vector); %矩阵大小,a为行数,b为列数for i=1:afor j=1:bstd(i,j)= (vector(i,j)-min(j))/(max(j)-min(j));endend%ds1.m,用绝对值法求距离function d=ds1(vector);[a,b]=size(vector);d=zeros(a);for i=1:afor j=1:afor k=1:bd(i,j)=d(i,j)+abs(vector(i,k)-vector(j,k));endendendfprintf('绝对值距离矩阵如下:\n');disp(d)%min1.m,求矩阵中最小值,并返回行列数及其值function [v1,v2,v3]=min1(vector);%v1为行数,v2为列数,v3为其值[v,v2]=min(min(vector'));[v,v1]=min(min(vector));v3=min(min(vector));%min2.m,比较两数大小,返回较小的值function v1=min(v2,v3);if v2>v3v1=v3;elsev1=v2;end%cluster.m,最短距离聚类法function result=cluster(vector);[a,b]=size(vector);max=max(max(vector));for i=1:afor j=i:bvector(i,j)=max;endend;for k=1:(b-1)[c,d]=size(vector);fprintf('第%g次聚类:\n',k);[e,f,g]=min1(vector);fprintf('最小值=%g,将第%g区和第%g区并为一类,记作G%g\n\n',g,e,f,c+1);for l=1:cif l<=min2(e,f)vector(c+1,l)=min2(vector(e,l),vector(f,l));elsevector(c+1,l)=min2(vector(l,e),vector(l,f));endend;vector(1:c+1,c+1)=max;vector(1:c+1,e)=max;vector(1:c+1,f)=max;vector(e,1:c+1)=max;vector(f,1:c+1)=max;end%print1,调用各子函数function print=print1(filename,a,b); %a为地区个数,b为指标数fid=fopen(filename,'r')vector=fscanf(fid,'%g',[a b]);fprintf('标准化结果如下:\n')v1=std1(vector)v2=ds1(v1);cluster(v2);%输出结果print1('fname',9,7)2.直接调用Matlab函数实现2.1调用函数层次聚类法(Hierarchical Clustering)的计算步骤:①计算n个样本两两间的距离{d ij},记D②构造n个类,每个类只包含一个样本;③合并距离最近的两类为一新类;④计算新类与当前各类的距离;若类的个数等于1,转到5);否则回3);⑤画聚类图;⑥决定类的个数和类;Matlab软件对系统聚类法的实现(调用函数说明):cluster 从连接输出(linkage)中创建聚类clusterdata 从数据集合(x)中创建聚类dendrogram 画系统树状图linkage 连接数据集中的目标为二元群的层次树pdist计算数据集合中两两元素间的距离(向量) squareform 将距离的输出向量形式定格为矩阵形式zscore 对数据矩阵X 进行标准化处理各种命令解释⑴T = clusterdata(X, cutoff)其中X为数据矩阵,cutoff是创建聚类的临界值。

(完整版)matlab实现Kmeans聚类算法题目:matlab实现Kmeans聚类算法姓名学号背景知识1.简介:Kmeans算法是一种经典的聚类算法,在模式识别中得到了广泛的应用,基于Kmeans的变种算法也有很多,模糊Kmeans、分层Kmeans 等。
Kmeans和应用于混合高斯模型的受限EM算法是一致的。
高斯混合模型广泛用于数据挖掘、模式识别、机器学习、统计分析。
Kmeans 的迭代步骤可以看成E步和M步,E:固定参数类别中心向量重新标记样本,M:固定标记样本调整类别中心向量。
K均值只考虑(估计)了均值,而没有估计类别的方差,所以聚类的结构比较适合于特征协方差相等的类别。
Kmeans在某种程度也可以看成Meanshitf的特殊版本,Meanshift 是一种概率密度梯度估计方法(优点:无需求解出具体的概率密度,直接求解概率密度梯度。
),所以Meanshift可以用于寻找数据的多个模态(类别),利用的是梯度上升法。
在06年的一篇CVPR文章上,证明了Meanshift方法是牛顿拉夫逊算法的变种。
Kmeans 和EM算法相似是指混合密度的形式已知(参数形式已知)情况下,利用迭代方法,在参数空间中搜索解。
而Kmeans和Meanshift相似是指都是一种概率密度梯度估计的方法,不过是Kmean选用的是特殊的核函数(uniform kernel),而与混合概率密度形式是否已知无关,是一种梯度求解方式。
k-means是一种聚类算法,这种算法是依赖于点的邻域来决定哪些点应该分在一个组中。
当一堆点都靠的比较近,那这堆点应该是分到同一组。
使用k-means,可以找到每一组的中心点。
当然,聚类算法并不局限于2维的点,也可以对高维的空间(3维,4维,等等)的点进行聚类,任意高维的空间都可以。
上图中的彩色部分是一些二维空间点。
上图中已经把这些点分组了,并使用了不同的颜色对各组进行了标记。
这就是聚类算法要做的事情。

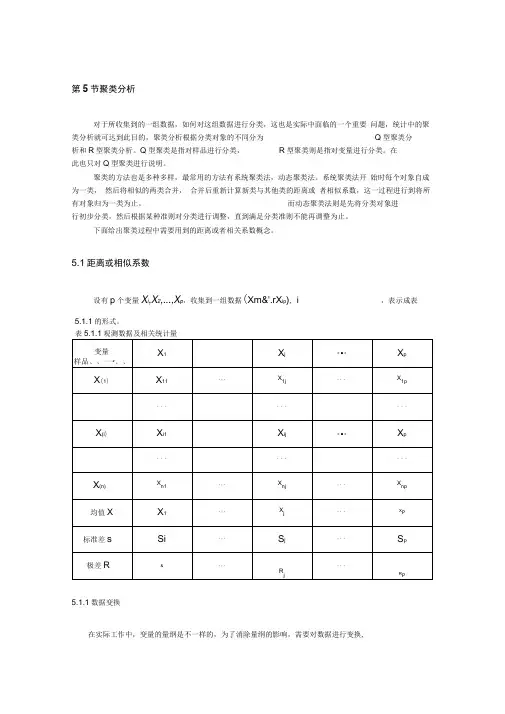
第5节聚类分析对于所收集到的一组数据,如何对这组数据进行分类,这也是实际中面临的一个重要问题,统计中的聚类分析就可达到此目的,聚类分析根据分类对象的不同分为Q型聚类分析和R型聚类分析。
Q型聚类是指对样品进行分类,R型聚类则是指对变量进行分类。
在此也只对Q型聚类进行说明。
聚类的方法也是多种多样,最常用的方法有系统聚类法,动态聚类法。
系统聚类法开始时每个对象自成为一类,然后将相似的两类合并,合并后重新计算新类与其他类的距离或者相似系数,这一过程进行到将所有对象归为一类为止。
而动态聚类法则是先将分类对象进行初步分类,然后根据某种准则对分类进行调整,直到满足分类准则不能再调整为止。
下面给出聚类过程中需要用到的距离或者相关系数概念。
5.1距离或相似系数设有p个变量X i,X2,...,X p,收集到一组数据(Xm&'.rX ip), i ,表示成表5.1.1的形式。
5.1.1数据变换在实际工作中,变量的量纲是不一样的,为了消除量纲的影响,需要对数据进行变换,常用的变换有如下几种。
(1)中心化变换: X jj 二X jj -召,i =1,..., n, j =1,...,p ,此变换后的数据的均值为0,协方差矩阵不变。
(2) 标准化变换:x j =区「X j )/S j ,i =1,..., n, j =1,..., p ,经此变换后的数据均值为 0, 标准差为1,且变换后的数据没有量纲。
(3) 极差正规化变换:X jj =区一段£ X ) / R j ,i =1,..., n,j =1,..., p 。
变换后的数据值在[0,1]区间内,极差为1,没有量纲。
此外还有其他变换,这里不详述。
5.1.2样品间的距离为了刻画这n 个样品间的关系的亲密程度,可用距离来度量。
对于区间型和比率型数据,距离常用的有如下几个:1明考夫斯基(Minkowski )距离:第i 个样品x :=(为1,心,...,心)与第j 个样品X 】=(冷,X j2,...,X jp )的明考夫斯基距离定义为:pr =1时,d ij (1)=送为-X j|,称为绝对值距离im < pd j (2) = Z |XI2r =°°时,d j (乂)=辆習X i —Xji ,称为切比雪夫距离2 马氏(Mahalanobis )距离第i 个样品x 】=(X^1,X i2,..., X^p )与第j 个样品x 【=(x j1,x j 2,...,X jp )的马氏距离定义 为:1 n _ _d ij (M ) = (x i -x j )T S 4(x i -旳),其中 S' (x i -X )(x i -X )T ,为样本的协方差矩 n —1 i 壬_ 1 n x x i 为样本的平均值。