复制已有表结构及数据
- 格式:docx
- 大小:12.99 KB
- 文档页数:1

会计信息系统复习资料一、判断题1.ERP的核心管理思想就是实现对对整个供应链的有效管理。
√2.MRPII的销售管理子系统中不包含客户关系管理。
×3.UFO报表中,报表数据处理不一定在“数据”状态下进行。
×4.UFO报表中,单元公式中涉及到的符号均为英文全角字符。
×5.UFO报表中,格式状态下输入内容的单元均默认为表样单元,未输入数据的单元均默认为数值单元,在数据状态下可输入数值。
√6.UFO报表中,关键字的位置可以用偏移量来表示,负数值表示向左移,正数值表示向右移。
√7.UFO报表中,关键字偏移量单位为毫米。
×8.UFO报表中,日期关键字可以确认报表数据取数的时间范围,即确定数据生成的具体日期。
√9.UFO报表中,舍位平衡公式中可以使用如“+”“/”“*”等任何运算符号。
×10.UFO报表中,一张报表最多只能管理99999张表页。
√11.UFO报表中进行公式设置时,单击“fx”按钮,或双击某公式单元,或按“=”键,都可打开“定义公式”对话框。
√12.UFO报表中形成的报表文件名后缀为.REP 。
√13.按照不同的分类方式,会计软件分为不同的类型。
按提供信息的层次划分可分为通用会计软件和定点开发会计软件;按适用范围划分可分为核算型会计软件和管理型会计软件。
×14.报表按结构的复杂性分为简单表和复合表两类。
√15.报表处理软件只能编制会计报表。
×16.报表处理系统一般是一个三维立体报表处理系统,要确定一个数据的所有要素为:表名、列、行和表页。
√17.报表的编制是由计算机在人的控制下自动完成的。
√18.报表的单元是指行和列确定的方格。
√19.报表的区域是由一组单元组成。
×20.报表格式的设置方式可以划分为非直观和直观两种。
√21.报表格式设置实质上是设置一模版,使用这个模版可以无限复制相同格式的表格供用户使用。
√22.报表格式设置是实现计算机自动处理报表数据的关键步骤。

达梦迁移表结构全文共四篇示例,供读者参考第一篇示例:达梦数据库是一种流行的数据库管理系统,广泛应用于各个行业和领域。
在实际开发中,可能会遇到需要将达梦数据库中的表结构迁移到其他数据库的情况,这就需要进行达梦迁移表结构的操作。
达梦迁移表结构是指将达梦数据库中的表结构转移到其他数据库系统中,例如MySQL、Oracle等。
在进行这一操作时,需要考虑到表结构的各个方面,包括表的字段、索引、约束等。
因为不同的数据库系统对表结构的定义和支持有所差异,所以在进行达梦迁移表结构时需要注意一些细节,以确保数据的完整性和准确性。
在进行表结构迁移时,需要特别注意以下几个方面:1. 表的字段定义:不同的数据库系统对字段的类型和长度的支持可能有所差异,所以在进行迁移时需要确保表的字段定义符合目标数据库系统的要求。
在将达梦数据库中的VARCHAR类型字段迁移至MySQL时,可能需要将长度定义调整为符合MySQL的规茄。
2. 索引的定义:索引是数据库系统中提高查询效率的重要手段,不同的数据库系统对索引的定义和支持也有所不同。
在进行表结构迁移时,需要注意索引的定义是否符合目标数据库系统的规范,以确保索引能够正常使用。
4. 数据类型的转换:在进行表结构迁移时,可能会遇到数据类型的转换问题。
将达梦数据库中的日期类型字段迁移至Oracle时,可能需要对日期格式进行调整,以确保数据能够被正确存储和查询。
达梦迁移表结构是一项比较复杂的操作,需要对表结构的各个方面进行仔细的处理和调整。
在进行迁移操作时,建议先进行充分的规划和准备工作,对目标数据库系统的表结构定义进行了解,确保迁移操作的顺利进行。
通过正确合理地迁移表结构,可以确保数据的完整性和准确性,提高数据库系统的使用效率和性能。
第二篇示例:达梦数据库是一款功能强大的关系型数据库管理系统,广泛应用于各种行业的信息化建设中。
在实际应用过程中,由于业务需求的变化或系统升级等原因,我们通常需要对数据库进行迁移。

一.单项选择题(50题)1.在数据管理中,同一数据重复存储的现象,称为( B)A.不一致B.数据冗余C.规范化D.异常2.依据数据库逻辑模型完成数据库内部模型设计的阶段是CA。
概念设计B。
逻辑设计C.物理设计D。
外部设计3.下列选项中,不.属于关系模型3个重要组成部分的是CA.数据结构B.数据操纵C.数据控制D。
数据完整性规则4.将关系模式S(学号,姓名,班级,班主任,课程编号,课程名称,学时,成绩)规范化到3NF,能得到的关系数目是DA.1 B。
2C。
3 D。
45.在Access中,不.能用来编辑表中数据的数据库对象是AA.报表B。
窗体C.数据访问页D。
查询6.在Access中,下列有关压缩数据库的说法中错误..的是BA.压缩数据库是重新组织该文件在磁盘上的存储方式B.不能压缩当前数据库C.可以压缩未打开的数据库D。
通过设置可实现关闭数据库时自动压缩7.在Access中,下列关于创建表的方法中,错误..的是 DA。
通过输入数据创建表 B.通过导入Excel电子表格创建表C.执行CREATE TABLE命令创建表D.执行ALTER TABLE命令创建表8.为防止输入重复数据,可在表的字段上DA。
设置有效性规则 B.设置掩码C。
设置格式 D.设置无重复索引9。
基于职工信息表创建一个查询,搜索当天过生日的职工,该查询有“姓名”、“出生月:Month ([出生日期])”、“出生日:Day([出生日期])”3个字段,显示职工的姓名、出生月和出生日,则在“出生月”和“出生日"2个字段的准则(条件)中依次输入 AA.Month(Now()),Day(Now())B。
Month([出生日期]),Day([出生日期])C。
Month([Date()]),Day([Date()])D。
Like Month([Now()]),Like Day([Now()])10.下列关于子窗体的说法中,错误..的是 BA.包含在另一个窗体中的窗体称为子窗体B.利用“自动创建窗体”方法可以创建含有子窗体的窗体C。


复制表结构和数据SQL语句1.复制表结构及数据到新表CREATE TABLE新表SELECT * FROM旧表2.只复制表结构到新表CREATE TABLE新表SELECT * FROM旧表WHERE1=2即:让WHERE条件不成⽴.⽅法⼆:(由tianshibao提供)CREATE TABLE新表 LIKE 旧表3.复制旧表的数据到新表(假设两个表结构⼀样)INSERT INTO新表SELECT * FROM旧表4.复制旧表的数据到新表(假设两个表结构不⼀样)INSERT INTO新表(字段1,字段2,.......)SELECT字段1,字段2,...... FROM旧表如果是 SQL SERVER 2008 复制表结构,使⽤如下⽅法:在表上⾯右击——编写表脚本为:——Create到——新查询编辑器窗⼝,你也可以保存为sql⽂件,新查询编辑器窗⼝的话在最上⾯⼀条把use databasename改成你要复制过去的数据库名称如果遇到:IDENTITY_INSERT 设置为 OFF 时,不能向表 'id' 中的标识列插⼊显式值。
插⼊数据的时候不要为id列指定值,也就是insert into table ( ...)语句中,括号中的字段中不要包含id列。
SQL SERVER 2008insert into b(a, b, c) select d,e,f from b;说明:复制表(只复制结构,源表名:a 新表名:b)SQL: select * into b from a where 1<>1说明:拷贝表(拷贝数据,源表名:a ⽬标表名:b)SQL: insert into b(a, b, c) select d,e,f from b;说明:显⽰⽂章、提交⼈和最后回复时间SQL: select a.title,ername,b.adddate from table a,(select max(adddate) adddate from table where table.title=a.title) b说明:外连接查询(表名1:a 表名2:b)SQL: select a.a, a.b, a.c, b.c, b.d, b.f from a LEFT OUT JOIN b ON a.a = b.c说明:⽇程安排提前五分钟提醒SQL: select * from ⽇程安排 where datediff('minute',f开始时间,getdate())>5说明:两张关联表,删除主表中已经在副表中没有的信息SQL:delete from info where not exists ( select * from infobz where info.infid=infobz.infid )说明:--SQL:SELECT A.NUM, , B.UPD_DATE, B.PREV_UPD_DATEFROM TABLE1,(SELECT X.NUM, X.UPD_DATE, Y.UPD_DATE PREV_UPD_DATEFROM (SELECT NUM, UPD_DATE, INBOUND_QTY, STOCK_ONHANDFROM TABLE2WHERE TO_CHAR(UPD_DATE,'YYYY/MM') = TO_CHAR(SYSDATE, 'YYYY/MM')) X,(SELECT NUM, UPD_DATE, STOCK_ONHANDFROM TABLE2WHERE TO_CHAR(UPD_DATE,'YYYY/MM') =TO_CHAR(TO_DATE(TO_CHAR(SYSDATE, 'YYYY/MM') || '/01','YYYY/MM/DD') - 1, 'YYYY/MM') ) Y,WHERE X.NUM = Y.NUM (+)AND X.INBOUND_QTY + NVL(Y.STOCK_ONHAND,0) <> X.STOCK_ONHAND ) BWHERE A.NUM = B.NUM说明:--SQL:select * from studentinfo where not exists(select * from student where studentinfo.id=student.id) and 系名称='"&strdepartmentname&"' and 专业名称='"&strprofessionname&"' order by 性别,⽣源地,⾼考总成绩说明:从数据库中去⼀年的各单位电话费统计(电话费定额贺电化肥清单两个表来源)SQL:SELECT erper, a.tel, a.standfee, TO_CHAR(a.telfeedate, 'yyyy') AS telyear,SUM(decode(TO_CHAR(a.telfeedate, 'mm'), '01', a.factration)) AS JAN,SUM(decode(TO_CHAR(a.telfeedate, 'mm'), '02', a.factration)) AS FRI,SUM(decode(TO_CHAR(a.telfeedate, 'mm'), '03', a.factration)) AS MAR,SUM(decode(TO_CHAR(a.telfeedate, 'mm'), '04', a.factration)) AS APR,SUM(decode(TO_CHAR(a.telfeedate, 'mm'), '05', a.factration)) AS MAY,SUM(decode(TO_CHAR(a.telfeedate, 'mm'), '06', a.factration)) AS JUE,SUM(decode(TO_CHAR(a.telfeedate, 'mm'), '07', a.factration)) AS JUL,SUM(decode(TO_CHAR(a.telfeedate, 'mm'), '08', a.factration)) AS AGU,SUM(decode(TO_CHAR(a.telfeedate, 'mm'), '09', a.factration)) AS SEP,SUM(decode(TO_CHAR(a.telfeedate, 'mm'), '10', a.factration)) AS OCT,SUM(decode(TO_CHAR(a.telfeedate, 'mm'), '11', a.factration)) AS NOV,SUM(decode(TO_CHAR(a.telfeedate, 'mm'), '12', a.factration)) AS DECFROM (SELECT erper, a.tel, a.standfee, b.telfeedate, b.factrationFROM TELFEESTAND a, TELFEE bWHERE a.tel = b.telfax) aGROUP BY erper, a.tel, a.standfee, TO_CHAR(a.telfeedate, 'yyyy')说明:四表联查问题:SQL: select * from a left inner join b on a.a=b.b right inner join c on a.a=c.c inner join d on a.a=d.d where .....说明:得到表中最⼩的未使⽤的ID号SQL:SELECT (CASE WHEN EXISTS(SELECT * FROM Handle b WHERE b.HandleID = 1) THEN MIN(HandleID) + 1 ELSE 1 END) as HandleID FROM HandleWHERE NOT HandleID IN (SELECT a.HandleID - 1 FROM Handle。

oracle 命令复制表结构及数据主键索引注释In Oracle, there are several ways to copy a table's structure, data, primary keys, indexes, and comments. Here are the methods you can use:1. Using CREATE TABLE AS SELECT statement:You can use the CREATE TABLE AS SELECT statement to create a new table with the same structure and data as an existing table.Example:CREATE TABLE new_table AS SELECT * FROM existing_table;This command will create a new table called "new_table" with the same structure and data as "existing_table".使用CREATE TABLE AS SELECT语句:您可以使用CREATE TABLE AS SELECT语句来创建一个具有与现有表相同的结构和数据的新表。
示例:CREATE TABLE new_table AS SELECT * FROM existing_table;这个命令将创建一个名为“new_table”的新表,该表的结构和数据与“existing_table”相同。
2. Using the EXPDP/IMPDP utility:You can use the Oracle Data Pump utility (EXPDP/IMPDP) to export and import tables with their structures, data, primary keys, indexes, and comments.Example:To export the table:expdp system/password@database_name tables=table_name directory=directory_name dumpfile=dumpfile_name.dmplogfile=log_file.logTo import the table:impdp system/password@database_name tables=table_name directory=directory_name dumpfile=dumpfile_name.dmplogfile=log_file.log使用EXPDP/ IMPDP实用程序:您可以使用Oracle Data Pump实用程序(EXPDP/ IMPDP)导出和导入带有其结构、数据、主键、索引和注释的表。

文章标题:深度探讨人大金仓数据库复制表结构和数据的方法及应用在数据库管理中,复制表结构和数据是一项非常重要的操作。
它可以帮助我们快速、高效地将一个数据库中的表结构和数据复制到另一个数据库中。
人大金仓数据库作为一种主流的数据库管理系统,在实际应用中也经常需要进行表结构和数据的复制操作。
本文将深入探讨人大金仓数据库复制表结构和数据的方法及其应用,以帮助读者更全面、深刻地理解这一重要的数据库管理技术。
一、人大金仓数据库复制表结构和数据的基本概念在开始深入探讨人大金仓数据库复制表结构和数据的方法之前,我们先来了解一下复制表结构和数据的基本概念。
复制表结构和数据,顾名思义,即是将一个数据库中的表结构和数据复制到另一个数据库中的操作。
这样做的好处是可以避免重复创建表结构和手工插入数据的繁琐工作,从而提高工作效率和数据一致性。
二、基于人大金仓数据库的表结构复制方法在人大金仓数据库中,复制表结构可以通过一些简单的SQL语句来实现。
我们可以使用SHOW CREATE TABLE语句来生成指定表的创建语句,然后将这些语句在目标数据库中执行,即可实现表结构的复制。
另外,人大金仓数据库还提供了一些更高级的工具和命令来帮助我们更方便地进行表结构的复制操作,比如使用mysqldump命令导出表结构,并使用mysql命令导入到目标数据库中。
这些方法在实际应用中都非常实用,可以根据具体情况选择合适的方式来复制表结构。
三、基于人大金仓数据库的数据复制方法除了复制表结构,复制数据同样是非常重要的。
在人大金仓数据库中,我们可以使用INSERT INTO ... SELECT ...语句来实现数据的复制。
这条语句可以将源表中的数据复制到目标表中,非常方便实用。
人大金仓数据库还提供了一些数据复制的工具和函数,比如使用mysqldump导出数据,并使用mysql导入到目标数据库中。
这些方法都非常适用于数据复制的场景,可以帮助我们快速、高效地进行数据迁移和复制操作。

电子文档信息管理系统解决方案山东东昀电子科技有限公司目录1. 系统功能模块的划分和各模块的设计 (1)1.1总体功能设计 (1)1.2信息管理 (4)1.2.1 数据录入 (5)1.2.2 文件上传、下载 (6)1.3日常管理 (7)1.3.1 检索查询 (7)1.3.3 统计报表 (8)1.4视频资料管理 (10)1.4.3 媒体文件资料管理 (10)1.5系统设置 (11)1.5.1 建立符合用户要求的文档管理结构 (11)1.5.2 对现有文档管理系统的其他设置 (13)1.6系统安全 (13)1.6.1 用户管理 (14)1.6.2 角色管理 (14)1.6.3 权限管理 (15)1.7日志管理 (17)1.8数据存储和备份 (18)1.8.1 数据存储 (18)1.8.2 数据备份 (20)1. 系统功能模块的划分和各模块的设计1.1总体功能设计如图所示:电子文档信息自动化管理系统总体设计如上面的系统逻辑架构,根据文档管理工作的分工不同分为:信息采集、日常管理、信息服务、系统安全、系统设置、软件接口六个部分。
其中信息采集、日常管理和信息服务三部分包括了用户文档信息管理的主要业务内容,实现了文档信息的收集整理、日常管理和利用服务的网络化和电子化。
信息采集主要负责文档信息的整理、编目与电子文件的自动挂接,完成文档信息的收集、录入和数字化工作。
日常管理部分主要完成电子文档的鉴定、销毁、移交、编研、征集等工作,同时可以辅助实体管理、形成文档的目录、进行借阅、利用、统计等管理工作。
信息服务主要通过简单方便的方式,为用户提供快捷的文档信息服务。
系统安全则充分保证了文档系统和数据的安全性,使对电子文档信息的安全管理能够控制到每一具体功能操作和每一具体文件。
系统设置部分为用户搭建符合自身文档信息管理需要的文档管理结构提供了定制工具,可以让用户自己量身定制本单位的文档管理结构,无论是从眼前,还是从长远考虑,都将比其他任何系统更加能够适应用户自身不断变化和不断增长的功能需求。
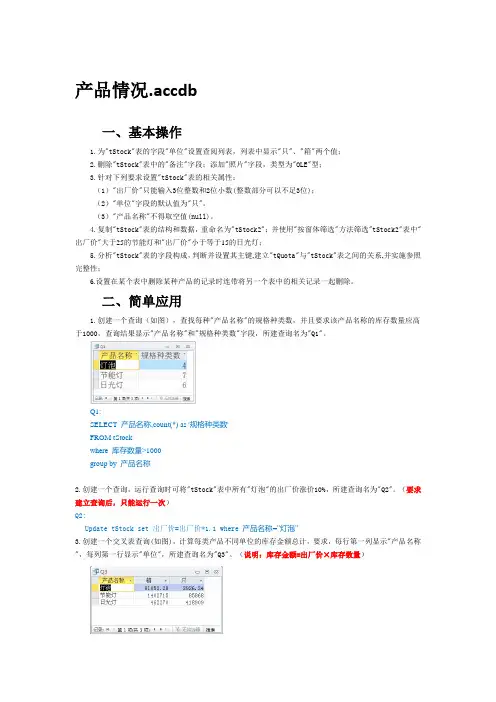
产品情况.accdb一、基本操作1.为"tStock"表的字段"单位"设置查阅列表,列表中显示"只"、"箱"两个值;2.删除"tStock"表中的"备注"字段;添加"照片"字段,类型为"OLE"型;3.针对下列要求设置"tStock"表的相关属性:(1)"出厂价"只能输入3位整数和2位小数(整数部分可以不足3位);(2)"单位"字段的默认值为"只"。
(3)"产品名称"不得取空值(null)。
4.复制"tStock"表的结构和数据,重命名为"tStock2";并使用"按窗体筛选"方法筛选"tStock2"表中"出厂价"大于25的节能灯和"出厂价"小于等于15的日光灯;5.分析"tStock"表的字段构成,判断并设置其主键,建立"tQuota"与"tStock"表之间的关系,并实施参照完整性;6.设置在某个表中删除某种产品的记录时连带将另一个表中的相关记录一起删除。
二、简单应用1.创建一个查询(如图),查找每种"产品名称"的规格种类数,并且要求该产品名称的库存数量应高于1000,查询结果显示"产品名称"和"规格种类数"字段,所建查询名为"Q1"。
Q1:SELECT 产品名称,count(*) as '规格种类数'FROM tStockwhere 库存数量>1000group by 产品名称2.创建一个查询,运行查询时可将"tStock"表中所有"灯泡"的出厂价涨价10%,所建查询名为"Q2"。

doris复制大表原理-概述说明以及解释1.引言1.1 概述在数据处理领域,复制大表是一项常见的操作,它通常涉及从一个数据源复制大量数据到目标表中。
Doris作为一种开源的分布式数据仓库,具有强大的数据存储和查询能力,因此也支持对大表的复制操作。
本文主要介绍了Doris复制大表的原理及其实现方式。
通过深入探讨Doris在数据复制过程中所采用的技术手段和策略,读者将了解到在大规模数据迁移和同步方面的实际应用。
在接下来的章节中,我们将详细讨论Doris复制大表的原理、实现方式以及在不同应用场景下的应用案例,希望读者可以通过本文对数据复制技术有更深入的了解和应用。
文章结构部分是关于整篇文章的组织和内容安排的描述。
在这篇关于Doris复制大表原理的长文中,文章结构可以按照以下方式展开:文章结构:1. 引言- 简述Doris复制大表原理的重要性和背景意义。
1.2 文章结构- 对整篇长文的组织和内容安排进行介绍,包括各个部分的主要内容。
1.3 目的- 阐明本文撰写的主旨和目的,为读者提供清晰的阅读导向。
2. 正文2.1 Doris复制大表原理- 详细介绍Doris复制大表原理,包括其定义、特点和优势。
2.2 实现原理- 探讨Doris复制大表原理的具体实现方法和技术细节。
2.3 应用场景- 分析Doris复制大表原理在实际应用中的场景和效果,为读者提供参考。
3. 结论- 总结本文所讨论的Doris复制大表原理的重要性和影响。
3.2 展望- 展望未来Doris复制大表原理的发展趋势和潜在价值。
3.3 结语- 对全文进行总结和致谢,为读者留下深刻印象。
通过以上结构的展开,读者可以清晰地了解到全文的内容安排和逻辑结构,有助于他们更好地理解和吸收文章内容。
1.3 目的本文的目的是介绍Doris复制大表原理,探讨其实现原理以及适用的应用场景。
通过深入了解Doris复制大表的机制,可以帮助读者更好地理解数据复制和同步的过程,并为其在实际应用中进行优化和调整提供指导。

JDBC复制表结构概述JDBC(Java Database Connectivity)是Java编程语言中用于执行SQL语句与数据库进行交互的API。
复制表结构是指在关系型数据库中创建一个与已有表结构完全相同的新表。
在实际应用中,我们经常会遇到需要复制表结构的情况,例如需要在同一数据库中创建具有相同结构但不同数据的表,或者需要将表结构从一个数据库迁移到另一个数据库。
本文将介绍如何使用JDBC实现复制表结构的功能。
环境准备在开始之前,确保你已经做好了以下准备: 1. 安装了Java开发环境(JDK) 2. 了解基本的Java编程知识 3. 熟悉关系型数据库以及SQL语言步骤1. 导入JDBC驱动考虑到不同数据库对JDBC实现的差异,我们需要根据所使用的数据库导入相应的JDBC驱动。
一般情况下,JDBC驱动位于数据库提供商的官方网站上可以下载。
以MySQL为例,你可以在MySQL官方网站上找到相应的JDBC驱动下载地址。
将下载的JDBC驱动的jar文件添加到你的Java项目的classpath中。
可以使用IDE(如Eclipse、IntelliJ IDEA等)的项目配置功能,或直接将jar文件复制到项目的lib目录中。
2. 建立数据库连接在使用JDBC进行数据库操作之前,我们需要建立与数据库的连接。
JDBC提供了一组接口和类,用于创建数据库连接。
以下是一个建立与MySQL数据库连接的示例代码:import java.sql.Connection;import java.sql.DriverManager;import java.sql.SQLException;public class JdbcDemo {public static void main(String[] args) {String url = "jdbc:mysql://localhost:3306/test";String user = "root";String password = "123456";try {// 加载JDBC驱动Class.forName("com.mysql.jdbc.Driver");// 建立数据库连接Connection conn = DriverManager.getConnection(url, user, password);// 执行操作...// 关闭连接conn.close();} catch (ClassNotFoundException e) {e.printStackTrace();} catch (SQLException e) {e.printStackTrace();}}}其中,url是数据库连接的URL,user和password分别是连接数据库使用的用户名和密码。
电子文档信息管理系统解决方案山东东昀电子科技有限公司目录1. 系统功能模块的划分和各模块的设计 (1)1.1总体功能设计 (1)1.2信息管理 (5)1.2。
1 数据录入 (5)1.2.2 文件上传、下载 (6)1。
3日常管理 (7)1.3.1 检索查询 (7)1。
3。
3 统计报表 (9)1。
4视频资料管理 (11)1。
4.3 媒体文件资料管理 (11)1.5系统设置 (11)1。
5.1 建立符合用户要求的文档管理结构 (12)1.5。
2 对现有文档管理系统的其他设置 (14)1。
6系统安全 (14)1。
6。
1 用户管理 (15)1.6.2 角色管理 (15)1.6。
3 权限管理 (16)1。
7日志管理 (18)1。
8数据存储和备份 (19)1。
8.1 数据存储 (19)1。
8.2 数据备份 (21)1。
系统功能模块的划分和各模块的设计1。
1总体功能设计如图所示:电子文档信息自动化管理系统总体设计如上面的系统逻辑架构,根据文档管理工作的分工不同分为:信息采集、日常管理、信息服务、系统安全、系统设置、软件接口六个部分。
其中信息采集、日常管理和信息服务三部分包括了用户文档信息管理的主要业务内容,实现了文档信息的收集整理、日常管理和利用服务的网络化和电子化。
信息采集主要负责文档信息的整理、编目与电子文件的自动挂接,完成文档信息的收集、录入和数字化工作。
日常管理部分主要完成电子文档的鉴定、销毁、移交、编研、征集等工作,同时可以辅助实体管理、形成文档的目录、进行借阅、利用、统计等管理工作。
信息服务主要通过简单方便的方式,为用户提供快捷的文档信息服务。
系统安全则充分保证了文档系统和数据的安全性,使对电子文档信息的安全管理能够控制到每一具体功能操作和每一具体文件。
系统设置部分为用户搭建符合自身文档信息管理需要的文档管理结构提供了定制工具,可以让用户自己量身定制本单位的文档管理结构,无论是从眼前,还是从长远考虑,都将比其他任何系统更加能够适应用户自身不断变化和不断增长的功能需求。
371).?5+4*2**6的结果为21。
(×)372).{^99/02/10}和ctod("99/02/11")都是Visual FoxPro数据库的日期型数据。
(√)373).Visual FoxPro表达式CTOD("99/10/20")+10,结果为﹛99/10/30﹜。
(√)374).Visual FoxPro的浮点型字段比数值字段的计算精度高。
(√)375).Visual FoxPro的浮点型字段的计算精度比数值型字段高,最长为15位。
(×)376).Visual FoxPro的浮点型字段的计算精度比数值型字段高,最长为20位。
(√)377).Visual FoxPro的浮点字段与数值字段相类似,只有数字,小数点及整数,而不带正、负号。
(×)378).Visual FoxPro的关系运算符包括<、>、=、<>共四种。
(×)379).Visual FoxPro的关系运算符包括<、>、=、==、<>(#或!=)、<=和>=共七种。
(√)380).Visual FoxPro的日期型字段的长度为6位。
(×)381).Visual FoxPro的日期型字段的长度为8位。
(√)382).Visual FoxPro的字符串运算符有+、-、$和%。
(×)383).Visual FoxPro的字符型字段最长为254个汉字。
(×)384).Visual FoxPro的字符型字段最长为254个字符。
(√)385).Visual FoxPro的字符型字段最长为256个字符。
(×)386).Visual FoxPro数据类型仅包括数值型、字符型、逻辑型、日期型和备注型。
(×)387).Visual FoxPro下对数据库操作只能在命令窗口键入命令才可以操作。
MySQL数据库原理设计与应用考试题一、单选题(共30题,每题1分,共30分)1、使用mysqldump命令时,()选项表示导出xml格式的数据。
A、#REF!B、#REF!C、#REF!D、#REF!正确答案:D2、下面关于“CREATE VIEW v_goods AS SELECT id, name FROM goods”描述错误的是()。
A、创建v_goods的用户默认为当前用户B、视图算法由MySQL自动选择C、视图的安全控制默认为DEFINERD、以上说法都不正确正确答案:D3、InnoDB表的自动增长字段值为1和2,那么删除2后,重启服务器,再次插入记录,自动增长字段的值为()。
A、1B、2C、3D、4正确答案:B4、以下不属于MySQL安装时自动创建的数据库是()。
A、mysqlB、information_schemaC、sysD、mydb正确答案:D5、下面对“ORDER BY pno,level”描述正确的是()。
A、先按level全部升序后,再按pno升序B、先按level升序后,相同的level再按pno升序C、先按pno全部升序后,再按level升序D、先按pno升序后,相同的pno再按level升序正确答案:D6、以下选项中,运算优先级别最低的是()。
A、位运算符B、算术运算符C、赋值运算符D、逻辑运算符正确答案:C7、命令行客户端工具的选项中,()用于指定连接的端口号。
A、-pB、-uC、-PD、-h正确答案:C8、下列mysql数据库中用于保存用户名和密码的表是()。
A、dbB、columns_privC、tables_privD、user正确答案:D9、以下可以创建外键约束的表是()。
A、MyISAM表B、InnoDB表C、MEMORY表D、以上答案全部正确正确答案:B10、下面关于MySQL安装目录描述错误的是()。
A、lib目录用于存储一系列的库文件B、include目录用于存放一些头文件C、bin目录用于存放一些课执行文件D、以上答案都不正确正确答案:D11、以下选项中,不属于MySQL特点的是()。
1、ACCESS是中小(ACCESS最大为2G)型的关系数据库管理系统2、ACCESS数据库对象包含6个对象:表、查询、窗体、报表、宏、模块。
其中表是核心。
3、ACCESS数据库的结构层次是:数据库→数据表→记录→字段4、ACCESS2010用户界面三大构成:功能区、导航窗格、Backstage视图;功能区包括五个命令选项卡:文件、开始、创建、外部数据、数据库工具。
5、ACCESS2010数据库文件扩展名:*.accdb6、ACCESS2010数据库类型:桌面数据库、WEB数据库7、外部数据导入到ACCESS2010的形式:创建新表、添加到现有表、链接表8、字段名:字段名不能超过64个字符,不能包含的字符:句点.惊叹号!方括号[]左单引号’。
9、ACCESS2010字段数据类型:文本、备注、数字、货币、时间/日期、是否、自动编号、OLE对象、超级链接、查阅向导、附件、计算字段10、数据类型大小:文本最大255字符、备注最大65536个字符。
11、不能进行排序、分组、索引的字段:备注、超链接、OLE对象类型、附件12、动编号:一个表只能设置一个自动编号类型字段,与记录是永久绑定的。
13、OLE字段:链接(仅存储数据的路径)、嵌入(直接把数据放入到表中)14、三类型主键:自动编号主键、单字段主键、多字段主键15、ACCESS2010的数据表视图,即可以创建表、修改表的结构。
16、表的关系类型:一对一联系(1:1)、一对多联系(1:n)、多对多联系(m:n)17、表的三类完整性:实体完整性、用户定义完整性、参照完整性(级联更新、级联删除)18、更改主键时,主键上建立了关系,则先要删除其关系,再进行更改。
19、主键、外键属性名称可以不一样,只要意义相同即可。
20、复制表选项的含义:仅结构、结构和数据、添加到现有表中21、通配符的含义:*、?、[]、!、-、#22、调整表的外观:改变字段次序,设定列宽、行高,隐藏和显示列,冻结列,改变字体显示,设置数据表格式23、列宽设置为“0”,该列被隐藏。
第一章测试1.数据库DB、数据库系统DBS及数据库管理系统DBMS三者之间的关系是()。
A:DBMS包含DB和DBSB:DBS 就是DB,也就是DBMSC:DBS包含DB和DBMSD:DB包含DBS和DBMS答案:C2.下列实体的联系中,属于多对多联系的是()。
A:住院的病人与病床B:工人与工资C:学校与校长D:学生与教师答案:D3.下列所述不属于数据库基本特点的是()。
A:数据的完整性B:数据的共享性C:数据的独立性D:数据量特别大答案:D4.在关系数据模型中,域是指()。
A:属性B:属性的取值范围C:记录D:字段答案:B5.下列叙述中,正确的是()。
A:实体完整性要求关系的主键整体可以有重复值B:主键不能是组合的C:在关系数据库中,不同的属性必须来自不同的域D:在关系数据库中,外键不是本关系的主键答案:D6.在E-R图中,用来表示实体的图形是()。
A:椭圆形B:菱形C:矩形D:三角形答案:C7.关系运算的分量和结果都是()。
A:模型B:实数C:字符串D:关系答案:D8.将E-R图中的实体和联系转换为关系模型中的关系,这是数据库设计过程中()阶段的任务。
A:概念设计B:物理设计C:需求分析D:逻辑设计答案:D9.对于数据库系统,负责定义数据库内容、决定存储结构和存取策略、具体进行安全授权等维护、管理和控制数据库系统工作的人员是()。
A:应用程序员B:用户C:数据库管理系统的软件设计员D:数据库管理员答案:D10.数据库概念设计的E-R方法中,所用的图形包括()。
A:三角形B:矩形C:菱形D:椭圆形答案:BCD第二章测试1.Access 2010数据库类型是()。
A:层次数据库B:圆状数据库C:关系数据库D:网状数据库答案:C2.Access 2010是一个()系统。
A:数据库管理B:财务管理C:人事管理D:数据库答案:A3.Access2010界面中,()位于功能区的下边左侧,它可以帮助组织归类数据库对象,并且是打开或更改数据库对象设计的主要方式。
Hive复制分区表和数据 1. ⾮分区表: 复制表结构: create table new_table as select * from exists_table where 1=0; 复制表结构和数据: create table new_table as select * from exists_table; 2. 分区表:-- 创建⼀个分区表drop table if exists kimbo_test;create table kimbo_test(order_id int,system_flag string)PARTITIONED BY(dt string )ROW FORMAT DELIMITED FIELDS TERMINATED BY'\001' LINES TERMINATED BY'\n'STORED AS TEXTFILE;-- 插⼊数据insert overwrite table kimbo_test partition(dt='20170601')values (186000983,'A'),(286000983,'B') ;insert overwrite table kimbo_test partition(dt='20170602')values (386000983,'F'),(486000983,'W') ;create table test_par like kimbo_test;-- ⽤ as select 复制⼀个新表create table test_par2 as select*from kimbo_test where dt='20170601' limit 0;-- ⽤ like 复制⼀个新表create table test_par3 like kimbo_test;-- 注意差异: as select 复制的是⼀个⾮分区表, like 复制的是⼀个分区表。
一、同时复制表结构及数据
在数据库的实际应用中,有时会存在单个表数据备份的情况,或创建一个与已有表结构相同的表,在sqlserver和oracle中,这种情况可以用一个语句即可完成。
1、sqlserver中,用select * into table1 from table2 where 条件
1)select * into table1 from table2,创建与table2相同结构的table1,并向table1导入table2的所有数据
2)select * into table1 from table2 where 1=2,创建与table2相同结构的table1,表数据为空3)select * into table1 from table2 where ....,创建与table2相同结构的table1,插入符合条件的表数据
2、oracle 中用create table1 as (select * from table2 where ......)
1)create table1 as (select * from table2),创建与table2相同结构的table1,并向table1导入table2的所有数据
2)create table1 as (select * from table2 where 1=2),创建与table2相同结构的table1,表数据为空
3)create table1 as (select * from table2 where ....),创建与table2相同结构的table1,插入符合条件的表数据
二、只复制数据
在表已经存在,只需要把表2的数据导入到表1中时,可以用以下方式(oracle和sqlserver 相同):
1、表结构完全相同时用insert into table1 (select * from table2 where ......)
2、表结构不同时用指定字段方式insert into table1(field11,field12,......) (select field21,field22,... from table2 where ......),此时会table2的查询结果按字段顺序插入到table1中,所以要求table1和table2的指定字段要一一对应。
复制数据时要注意,因为table1已经存在,在向table1中插入中数据时,由于主键和自动编号等字段不可重复的特点,要考虑插入的数据是否合法,否则不能成功。
如在sqlserver 中,如存在自动编号的字段,如果此字段插入的数据已经存在,则不能再次插入。