从CAJ等文件中提取全文本的方法
- 格式:docx
- 大小:14.56 KB
- 文档页数:5

这2个⽅法能将CAJ免费完整转换成WordCAJ是中国学术期刊全⽂数据库⽂件的⼀种格式,⽽这种CAJ格式只有使⽤中国知⽹提供的CAJ阅读器(CAJViewer)才能阅读,并且打开⽂档后也⽆法像Word格式⼀样随意复制粘贴。
那么如何才能将caj转换成word呢?有没有免费就能直接将整篇CAJ都成功转换的⽅法或者⼯具呢?第⼀种是利⽤CAJViewer阅读器本⾝的功能转换,可能很多⼈会说CAJViewer的⽂字识别成Word功能只能框选部分区域,最多也只能单次识别⼀页内容,整篇转换太难了。
这⾥我们需要⽤到的是另⼀个功能,打开⽂件后点击软件左上⾓“⽂件”中的“另存为”;然后在弹出的保存窗⼝将格式选择*txt保存为TXT⽂本⽂档,⽽记事本与Word是通⽤的,我们只需要⽤Word软件打开这个TXT⽂本并重新保存⼀下就可以了。
不过以上⽅式有时也可能导致会出现乱码的情况,我们也可以借助⼀些转换⼯具来实现,转换效果也更好。
Speedpdf在线转换⽀持20多种⽂档转换格式,每种⽂档转换格式每天都有免费试⽤次数,⽽且⼿机和电脑可以分别试⽤不累计次数,基本满⾜每天的转换需求,操作过程也很简单。
打开speedpdf⼯具⾸页(直接百度搜索即可)后,选择caj转Word进⼊下⼀步转换。
同时也⽀持CAJ转PDF的转换。
添加需要转换的CAJ⽂件后,点击每个⽂件进度条后⾯对应的转换就可以开始转换了,等待转换完成后点击下载就可以了。
注意:由于我们免费试⽤,转换前没有登录账户,所以转换期间切勿关闭或刷新⽹页,以免导致⽆法下载成功的⽂档或转换失败;如已登录可忽略,任何时候直接在转换记录中查看并下载均可。
在我们⽇常⽣活或办公经常都会⽤到各种⽂档之间互转,在线转换是最便捷的⽅法,建议收藏使⽤哦。
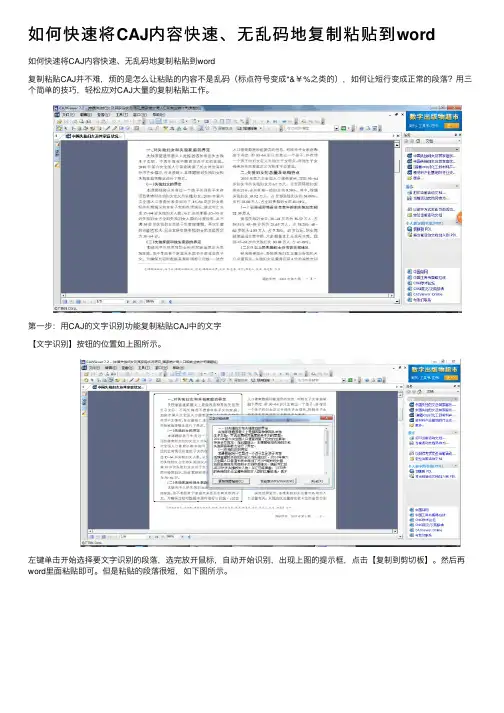
如何快速将CAJ内容快速、⽆乱码地复制粘贴到word如何快速将CAJ内容快速、⽆乱码地复制粘贴到word复制粘贴CAJ并不难,烦的是怎么让粘贴的内容不是乱码(标点符号变成*&¥%之类的),如何让短⾏变成正常的段落?⽤三个简单的技巧,轻松应对CAJ⼤量的复制粘贴⼯作。
第⼀步:⽤CAJ的⽂字识别功能复制粘贴CAJ中的⽂字【⽂字识别】按钮的位置如上图所⽰。
左键单击开始选择要⽂字识别的段落,选完放开⿏标,⾃动开始识别,出现上图的提⽰框,点击【复制到剪切板】。
然后再word⾥⾯粘贴即可。
但是粘贴的段落很短,如下图所⽰。
第⼆步:⽤word的替换功能将短⾏变为长⾏。
出现这种的原因在于CAJ段落复制过来后有很多⾃带的段落标记。
将段落标记替换为空即可去掉它们,让短⾏变成长⾏。
选中有问题的短⾏-点击【开始】-【替换】。
查找内容⾥⾯填写的内容为^p,这个符号可以直接选择,在替换界⾯点击【特殊格式】-【段落标记】即可⾃动输⼊这个符号。
替换⼀栏不输⼊任何字符。
点击全部替换即可(注意不要把替换正常的⾏,出现提⽰【是否搜索⽂档的其余部分】时,选择【否】)。
第三步:再次⽤word的替换功能将没有分段的长⾏变成正常现在的问题是,所有⾏变成⼀⼤坨,没有分段。
但是事实上每段前⾯都有空格符存在,要显⽰空格符需要点击word的显⽰/隐藏编辑标记键(在【开始】-段落版块的右上⾓),效果如下图。
那些点就是空格,⼏个点就是⼏个空格。
现在把这些空格替换为段落标记,替换的具体操作为:【查找内容】⾥⾯填四个空格(视实际情况⽽定,有⼏个点就按⼏下空格键),【替换】⾥⾯填段落标记,即^p。
如下图所⽰。
点击【全部替换】-【否】。
最终的处理结果为下图所⽰:第四步:检查有⽆识别错误。
⽂字识别难免出错,格式整理好后⼀定要检查,⽐如是不是特殊符号没有识别出来之类的。
格式直接⽤格式刷就可以和正常⽂档⼀样了。
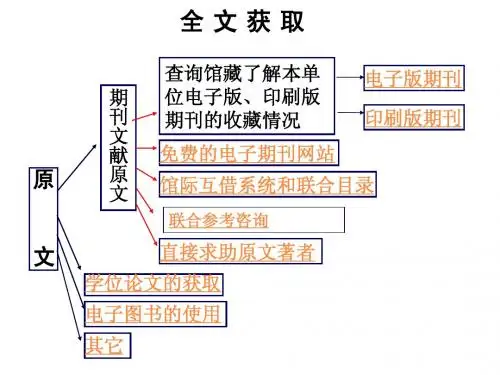


如何通过网络获取医学文献的全文?查询文献遇到的最大问题是如何取得文章的全文?通过PUBMED等途径好不容易筛选出需要的文章,却因图书馆开放时间与工作时间冲突、馆藏有限、现刊滞后等原因无法获取印刷版的文章全文。
但随着互联网技术的高度发展,网络为医生获取全文提供了新的途径,在此介绍几种通过网络获取电子版全文的常见方法:一、向作者索取全文:通常从文献检索结果中可得到文章作者的E-Mail地址或个人网页,可以通过电子邮件向作者本人索取原文。
二、浏览文章所属期刊的网站:通常期刊网站会免费提供部分文献全文,有些网站提供过刊(6-12月以前的文章)的全文,有些网站提供每期中部分文章的全文,而有些网站则免费提供全部文献的全文,所以浏览所需文章所属期刊的网站,可能会找到所需的文章全文。
"期刊热推"栏目罗列了常见呼吸疾病有关期刊的网站,对该期刊提供全文服务的方式进行了介绍。
通过这个途径可以轻松浏览相关期刊,无需记忆每一种期刊冗长的网站地址。
三、检索全文数据库:一些大型的电子出版商如Elsevier等除了开展互联网业务外,还定期提供全文数据库光盘供检索。
所以,如果您所在的图书馆有这类全文数据库,或已取得互联网访问授权,您可作为图书馆的用户,对这类光盘进行检索。
四、访问在线电子出版商的网站:这类网站目前较多,但通常是收费的。
以下列举部分国内和国外的网站仅供参考:1、/ OVID技术公司网目前提供90多种有关人文、社科、科技的数据库,其中一半为生物医学数据库,且数据库中部分目录有全文链接。
如Journals@Ovid全文期刊库共收录了60个出版商提供的392种科技期刊,最早可回溯至1993年。
2、/ ScienceDirect Onsite(SDOS)系统由荷兰著名的Elsevier Science公司开发,提供用户在本地访问基于Web的全文电子期刊。
自1998年以来该公司共出版了1200多种全文电子期刊,其中医学类有:Clinical Medicine 271种,Life Science 437种。

如何将整篇caj转Word-迅捷OCR文字识别软件
如何将整篇caj转Word呢?caj文件因为不可以直接打开阅读的属性,所以时常需要将caj文件转换成可以编辑的Word文本的形式。
那么今天小编就通过使用迅捷OCR文字识别软件,来告诉大家如何将整篇的caj转Word吧。
使用工具:迅捷OCR文字识别软件
软件介绍:该软件是一款智能化的OCR图片文字识别软件。
支持PDF 识别、扫描件识别、图片文字识别、caj文件识别等功能,所以在办公中遇到上面所说到的问题迅捷OCR文字识别软件https:///ocr是不错的选择。
操作步骤:
步骤一:在电脑上准备好一款OCR文字识别软件,可以电脑百度搜索迅捷办公进入其官网将迅捷OCR文字识别软件下载到电脑上。
步骤二:准备好一份caj文件,然后打开OCR软件,这时会弹出一
个添加文件的选项,然后通过这个选项将准备好的caj文件添加进来。
步骤三:文件添加进来以后,可以在软件的左下角将识别后的文件的输出目录进行修改。
步骤四:输出目录修改好后,还需要在等待识别的文件上方,将文件的识别格式修改为doc或docx的格式,识别效果可根据需要进行改动。
步骤五:这时我们就可以点击开始识别按钮,对caj文件进行识别转换了,识别转换的时间会因为文件的大小,和网络速度的快慢有所差异。
步骤六:耐心等待文件识别结束后,就可以点击查看文件的选项,对识别转换后的Word文档进行查看了。
整篇caj转换成Word的问题在借助迅捷OCR文字识别软件的前提下就显得异常的简单了,大家在工作中有需要的话,不妨试试看。

中国知网CNKI系列全文数据库使用说明(一)访问方式:江海职业技术学院对中国知网主站的访问时包库访问,校园网用户可以直接免费访问。
(二)注意事项:一、我院购买的是该数据库的包库使用权,并发用户数的限制为20。
如果用户数满将无法进行检索,请稍后再试。
建议使用者避开使用高峰期(下午和晚上),查询完毕,请点击“退出”按钮退出系统,以方便其他用户使用。
二、全文采用CAJ格式和PDF格式阅读,CAJ格式必须用CAJ Viewer阅读,而PDF 格式可以用Acrobat Reader和CAJ Viewer阅读。
所以推荐读者使用CAJ Viewer。
请在中国知网(/)主页点击“常用软件下载”下载并安装阅读器。
“CAJ全文浏览器”已更新多版本,如果版本太旧,打开全文时可能会出现乱码等现象,请关注并下载安装最新版“CAJ全文浏览器”软件。
三、数据库使用年限为2010年整年,数据库用户名/密码为sy jhzy/syjhzy。
并发用户数:20(注意:在线用户数超过20时,就只能检索而无法下载全文;当在线用户数在20的基础上超过一定的数目时,数据库就无法登录,并提示“对不起,最大登陆数已满,请稍后再试”。
)(三)数据库简介:《中国学术期刊网络出版总库》简称CAJD(China Academic Journal Network Publishing Database),是中国知识基础设施简称 CNKI 工程的重要组成部分,是目前世界上最大的连续动态跟新的中国学术期刊全文数据库,收录了国内7000多种学术期刊,内容覆盖自然科学、工程技术、农业、哲学、医学、人文社会科学等各个领域,全文文献总量2200多万篇。
总库共分为8个专业文献总库(基础科学、工程科技Ⅰ、工程科技Ⅱ、哲学与人文科学、社会科学Ⅰ、社会科学Ⅱ、信息科技和经济与管理科学),168个专题数据库。
收录年限从1915年至今。
CNKI中心网站及数据库交换服务中心每日更新,各镜像站点通过互联网或者卫星传送数据可实现每日更新,专辑光盘每月更新。


CAJViewer软件进⾏pdf⽂字识别以及公式截取的使⽤说明
CAJViewer软件进⾏pdf⽂字识别以及公式截取的使⽤说明
1、准备⼯作
⾸先下载CAJViewer这个软件(压缩包⾥有)并解压
运⾏这个⽂件打开软件
2、打开⾃⼰要翻译的pdf⽂件
左上⾓—⽂件---打开(和word操作类似,不赘述),打开⾃⼰要翻译的pdf⽂件。
例如我的⽂件是
3、运⾏选择图像⼯具
左上⾓有如图的⼯具栏,运⾏第⼆个图中的⼩⼯具(选择图像⼯具)
4、⽤选择图像⼯具选中需要进⾏⽂字识别的句⼦
左键点击想要识别的⽂字左上⾓,拉出框框选中这个句⼦,松开⿏标左键。
完成的效果如图
5、进⾏⽂字识别
在框框⾥右键选中⽂字识别,就会出现下图的结果(马上就要完成了,是不是很鸡动)
6、截出公式
⽤选择图⽚⼯具选中公式,框框⾥右键点击发送图像⾄Word
7、点击发送⾄word即可创建word⽂档(后⾯的⼯作就不难了,你懂的)。

caj导出中文参考文献的方法
要在CAJ(中国学术期刊网络出版总库)中导出中文参考文献,你可以按照以下步骤操作:
1. 首先,在CAJ数据库中找到你需要的文献,并打开该文献的
详细页面。
2. 在文献的详细页面中,通常会有一个“导出”或者“引用”
按钮,点击这个按钮。
3. 在弹出的导出或引用选项中,选择“中文参考文献”或者
“中文格式”作为导出的格式。
4. 确认选择后,CAJ系统会生成一个包含中文参考文献的引用
文本,你可以将其复制粘贴到你的文档或参考文献管理软件中。
另外,有些文献在CAJ中可能提供了多种格式的导出选项,你
可以根据自己的需要选择合适的格式进行导出。
总的来说,导出中文参考文献的方法主要是在文献详细页面中
找到导出选项,并选择中文格式进行导出。
希望这些信息能够对你有所帮助。
如果还有其他问题,欢迎继续询问。
如何快速将C A J内容快速、无乱码地复制粘贴到wo rd复制粘贴CAJ并不难,烦的是怎么让粘贴的内容不是乱码(标点符号变成*&¥%之类的),如何让短行变成正常的段落?用三个简单的技巧,轻松应对CA J大量的复制粘贴工作。
第一步:用CAJ的文字识别功能复制粘贴C AJ中的文字【文字识别】按钮的位置如上图所示。
左键单击开始选择要文字识别的段落,选完放开鼠标,自动开始识别,出现上图的提示框,点击【复制到剪切板】。
然后再wor d里面粘贴即可。
但是粘贴的段落很短,如下图所示。
第二步:用word的替换功能将短行变为长行。
出现这种的原因在于CA J段落复制过来后有很多自带的段落标记。
将段落标记替换为空即可去掉它们,让短行变成长行。
选中有问题的短行-点击【开始】-【替换】。
查找内容里面填写的内容为^p,这个符号可以直接选择,在替换界面点击【特殊格式】-【段落标记】即可自动输入这个符号。
替换一栏不输入任何字符。
点击全部替换即可(注意不要把替换正常的行,出现提示【是否搜索文档的其余部分】时,选择【否】)。
第三步:再次用wor d的替换功能将没有分段的长行变成正常现在的问题是,所有行变成一大坨,没有分段。
但是事实上每段前面都有空格符存在,要显示空格符需要点击w ord的显示/隐藏编辑标记键(在【开始】-段落版块的右上角),效果如下图。
那些点就是空格,几个点就是几个空格。
现在把这些空格替换为段落标记,替换的具【查找内容】里面填四个空格(视实际情况而定,有几个点就按几下空格键),【替体操作为:换】里面填段落标记,即^p。
如下图所示。
点击【全部替换】-【否】。
最终的处理结果为下图所示:第四步:检查有无识别错误。
文字识别难免出错,格式整理好后一定要检查,比如是不是特殊符号没有识别出来之类的。
Caj文件中复制文字的教程
caj文件中的文字是不可以直接进行复制的,所以,我们要想对里面的文字进行复制,就要先将其转换为可以进行编辑的文档形式,然后再进行复制,这样就会简单很多,那么下面我们就一起来看一下caj文件中复制文字的具体教程吧。
需要用到的工具:捷速OCR文字识别软件
软件介绍:该软件具备改进图片处理算法功能:软件进一步改进图像处理算法,提高扫描文档显示质量,更好地识别拍摄文本。
所以想要实现图片转换为其它格式,或者是票证识别,捷速OCR文字识别/都是不错的选择。
方法讲解:
步骤一:首先我们要先把需要用到的工具下载下来,打开电脑浏览器,搜索并下载,捷速OCR文字识别软件。
步骤二:软件安装好后,打开该软件,选择软件正中央“添加”文件的
选项,将需要转换的caj文件添加进来。
步骤三:caj文件添加进来后,先不要急着进行转换,在软件的正上方先将文件的识别格式更改为docx或doc格式,docx和doc格式识别后都为Word的形式,大家可根据自己的需要进行修改。
步骤四:识别格式修改成功后,在软件的左下角,可根据自己的需要将识别后的输出目录修改一下。
步骤五:输出目录修改好后,我们就可以点击“开始识别”按钮进行caj 文件识别了,识别时间的长短,可能会因为文件的大小的不一,有所不同。
我们只需耐心等待一会即可。
步骤六:等待caj文件识别结束后,点击“打开文件”按钮即可查看文件识别后的效果。
Caj文件中复制文字的教程,已经为大家分享完了,学会了这个教程,工作中就再也不用怕遇到caj文件文字复制的问题了。
免费期刊全文的获取
一、获取的途径
(1)PubMed
free-fulltext
PMC
(2) HighWire Press /
/
三种免费方式
Free Back Issues表示在某个时间之前的所有文献全文均为免费的;
Free Site则是可以完全免费获取全文的站点;
Free Trial表示在限定的时间内,所有文献可免费使用。
收录期刊可以按照主题或字母顺序进行浏览
(1)
完全免费限时免费完全免费
限时免费
限时免费
(2)WHOLIS
http://unicorn.who.ch/uhtbin/webcat
免费检索获取全文
(3)BIOVISA
其中有180多种免费期刊。
(4)BioMed Central(BMC)
(5)DOAJ
DOAJ Directory of Open Access Journals Open Access Journals由一些基金资助,对个人读者以及研究机构提供免费检索全文的科学和学术期刊
843
5.生物医学期刊网站
/collections
现在国内许多著名的高校,都购买全文电子期刊,只能在本校内免费浏览或友好校间共用,故可直接去这些高校的图书馆的电子阅览室检索。
◆◆◆◆。
从CAJ等文件中提取全文本的方法从CAJ等文件中提取全文本的方法现在网上的许多资料都是以CAJ、PDF等文件格式提供的,其中的文本不能被直接编辑。
网上提供了许多处理这种情况的软件,但是它们不是效率低,就是只能提取其中部分文本。
本文所述利用微软提供的OCR识别技术从CAJ、PDF等文件中提取全部文本的方法,简便快捷,效率很高。
从不同格式的文件中提取文本前需要做好以下准备工作,安装CAJViewer5.5浏览器软件和acrobat 5 专业版浏览器软件安装Office2003,并完全安装Of?鄄fice工具Microsoft Office Document Imaging,然后在打印机里面会增加Microsoft Office Document Image Writer打印机。
Microsoft Office Document Image可以非常准确的全文件识别转化中文、英文、表格。
一、CAJ文件的识别(一)首先,从网上下载CAJ格式的资料文件保存到本地硬盘上。
(二)然后,启动CAJViewer浏览器程序,并在该程序中打开刚才保存的CAJ格式的文件。
浏览文件到最后一页后,不要关闭CAJ浏览器程序。
(三)在CAJ浏览器程序窗口中,选择“文件”→“打印”,并选择打印机为Microsoft Office Document Image Writer打印机,勾选打印到文件选项和确定打印页数。
(四)保存打印文件(*.prn)到适当位置。
等待打印完成后,Microsoft Office Document Image 自动打开刚才保存的打印文件。
d+E(五)在Microsoft Office Document Image窗口中,选择“页面”菜单中的“选择所有页面”菜单项,然后选择“工具”菜单中的“使用OCR识别文本”提取文本。
(六)选择“工具”下的“将文本发送到word”,最后将把整个CAJ文件识别输出到word文件中。
获取原文的方法有:①选择全文数据库进行查询②含有全文的电子期刊网③图书馆互借、复印④学位论文档案馆⑤电子邮件向作者或索引编制单位⑥各种课程或研讨会的资源网页⑦付费的文献数据库般来讲,知道一篇文章的题目想查全文链接,很好办,只要Google学术里一搜,使用intitle:"文章题目"命令,定位会很精确。
但我们经常会去查文献引用的reference,由于格式的原因,往往只有作者、期刊、卷数、期、页码等信息,这时journalseek就变得非常有用了,输入期刊的缩写或者全称很快就能得到期刊所在的数据库,然后再根据卷、期、页等即可精确定位一篇文章,接下来要做的工作只是login相应的数据库了,如果Journalseek搞不定,就交给PubMed来弄。
我一般只用PubMed把缩写转化为全称,然后再到资源丰富的名校E-Journal Search里去查找,常用Columbia、Yale、MIT来查好了,前言就这么多了,赶紧进入获取文献原文的7种途径。
1、UserName+Password当你用journalseek找到文章所在的数据库之后,就可以用该数据库的MM Login进行查询,获取UserName+Password的方法很多、教程也很多,高手们都喜欢用google去搞定它,一般的公式是UserName+Password+具体数据库,但我一般更喜欢用UID来搜索,大家可以试试,不过这样搜到的MM可用的不多也很容易失效,多看看相关的教程,精炼你的检索过程,就能有更多的收获哦。
2、使用文献代理代理的知识我就不罗嗦了吧,每个数据库有每个数据库独特的特征验证码,只要验证码准确剩下的事就是吸附足够的代理进行验证了。
(耗时耗Money哦)其实建议只搜搜SD的代理就好,因为多为高校的代理,SD只是其中一个数据库,你根据IP找到IP所属高校就可以使用基本上所有的数据库了,绝不仅仅是SD哦。
好,无论你的代理是搜得还是买的,是普通代理还是密代,只要权限够,挂上代理,右键另存为,你所下载的内容就会由.html变为.pdf。
从CAJ等文件中提取全文本的方法从CAJ等文件中提取全文本的方法现在网上的许多资料都是以CAJ、PDF等文件格式提供的,其中的文本不能被直接编辑。
网上提供了许多处理这种情况的软件,但是它们不是效率低,就是只能提取其中部分文本。
本文所述利用微软提供的OCR识别技术从CAJ、PDF等文件中提取全部文本的方法,简便快捷,效率很高。
从不同格式的文件中提取文本前需要做好以下准备工作,安装CAJViewer5.5浏览器软件和acrobat 5 专业版浏览器软件安装Office2003,并完全安装Of?鄄fice工具Microsoft Office Document Imaging,然后在打印机里面会增加Microsoft Office Document Image Writer打印机。
Microsoft Office Document Image可以非常准确的全文件识别转化中文、英文、表格。
一、CAJ文件的识别(一)首先,从网上下载CAJ格式的资料文件保存到本地硬盘上。
(二)然后,启动CAJViewer浏览器程序,并在该程序中打开刚才保存的CAJ格式的文件。
浏览文件到最后一页后,不要关闭CAJ浏览器程序。
(三)在CAJ浏览器程序窗口中,选择“文件”→“打印”,并选择打印机为Microsoft Office Document Image Writer打印机,勾选打印到文件选项和确定打印页数。
(四)保存打印文件(*.prn)到适当位置。
等待打印完成后,Microsoft Office Document Image 自动打开刚才保存的打印文件。
d+E(五)在Microsoft Office Document Image窗口中,选择“页面”菜单中的“选择所有页面”菜单项,然后选择“工具”菜单中的“使用OCR识别文本”提取文本。
(六)选择“工具”下的“将文本发送到word”,最后将把整个CAJ文件识别输出到word文件中。
二、PDF文件的识别)(一)以文本形式保存的PDF文件,用acrobat 5 专业版,识别整个文件。
直接打开从网上下载的PDF格式文件另存为RTF文件,或者选择工具栏上的文字选择按钮,然后选择文字区域,然后复制到Word中即可。
(二)以图片形式保存的PDF文件,将PDF文件打印到Microsoft Office DocumentImage Writer打印机,选择打印形成的文件的保存位置,然后会自动形成一个MDI文件,并且自动用Microsoft Office Document Image打开此文件,然后在Microsoft Office Document Im?鄄age中选择“工具”菜单中的“使用OCR识别文本”,识别完成后,在选择“工具”下的,“将文本发送到word”,最后将把整个PDF文件识别输出到word文件中。
(三)加密的PDF文件先下载解密软件,解密后在参照上述步骤1),2) 进行。
(四)繁体PDF文件用上述步骤2)的方法识别到word后,用word中的“工具”→“语言”→“中文繁简转换”三、超星文件的识别(一)全文件识别打印到Microsoft Office Document Image Writer打印机,然后按上述PDF文件的识别步骤中第二点操作,要注意的是,超星打印功能有点区别,因为超星是目录和全文分开的,所以打印时,需要分别把目录和正文识别到Word中,再合并到一起。
打印时要填入打印页码从1到最后一页,不要选择打印全部。
在打印选项中,要将页面比例设成真实大小,而不是整宽。
注意识别速度比其他格式要慢很多,请保持耐心。
一般一本200多页的书,识别需要几分钟的时间。
(二)超星文件识别相对比较麻烦一些,如果还有问题,可以先把超星打印成完整的PDF文件,然后再用上述识别PDF文件的方法转成Word。
四、后记经过试验,发现Microsoft Office Document Image 存在一些不稳定的问题,如在用CAJ打印到Microsoft Office Document Image Writer时,发现用CAJ5.5版本比较快,而CAJ5.0有时出现假死机。
页面显示大时,转化的识别率较高。
如果页数多的文件,包括超星,可以分多次转化。
由于虚拟打印到Microsoft Office Document Image Writer 比较慢,并且形成的虚拟文件很大,1本200多页的书大约是60M,因此会严重影响机器的运行速度、C盘和内存空间。
建议配置好的机器一次转化不要超过200页,配置差的不要超过100页,同时打印时在任务栏中会出现打印机图标,可以双击,看到打印任务的进度,避免误以为死机。
转化完成后请删除c:\windows\temp目录下的虚拟打印文件,否则C盘很快会被用光。
caj从5.5版本可以进行文字识别功能,我们的pdf文件用CAJ打开,然后用里面的文字识别功能即可得到我们需要的文字了,特别有优势的一个地方在于:即便是图片格式的PDF文件也能识别;另外一个功能就是:有时候pdf 设置了密码保护,不允许打印,我们可以用CAJ打开然后再打印,大家不妨试试,这也是CAJ文档的两个用途吧。
(caj,PDF,超星,维普............)中文字提取,如大家常用的caj,超星,维普............只需要两个软件VIRTUAL PRINTER;尚书六号,先装一个VIRTUAL PRINTER(虚拟打印机)打成OCR软件(我用的是尚书六号)可识别的图像格式(如jpg)之后,就可以提取其中的文字了。
这个方法尤其对于有些caj(转成PDF什么也看不清楚的caj)特别有效。
我为人人,人人为我。
鼓励别人,就是鼓励自己!:P:P:P:P:P:P:P:P:P:P:P:P:P:P:P作者:小虫007我靠,这么好的东东没人顶!我自己顶先!!!作者:小虫007不好意思,刚才没有排版好。
从不同格式的文件中提取文本前需要做好以下准备工作,安装CAJViewer5.5浏览器软件和acrobat 5专业版浏览器软件安装Office2003,并完全安装Of?鄄fice工具Microsoft Office Document Imaging,然后在打印机里面会增加Microsoft Office Document Image Writer打印机。
Microsoft Office Document Image可以非常准确的全文件识别转化中文、英文、表格。
一、CAJ文件的识别(一)首先,从网上下载CAJ格式的资料文件保存到本地硬盘上。
(二)然后,启动CAJViewer浏览器程序,并在该程序中打开刚才保存的CAJ格式的文件。
浏览文件到最后一页后,不要关闭CAJ浏览器程序。
(三)在CAJ浏览器程序窗口中,选择“文件”→“打印”,并选择打印机为Microsoft Office Document Image Writer打印机,勾选打印到文件选项和确定打印页数。
(四)保存打印文件(*.prn)到适当位置。
等待打印完成后,Microsoft Office Document Image 自动打开刚才保存的打印文件。
(五)在Microsoft Office Document Image窗口中,选择“页面”菜单中的“选择所有页面”菜单项,然后选择“工具”菜单中的“使用OCR识别文本”提取文本。
(六)选择“工具”下的“将文本发送到word”,最后将把整个CAJ文件识别输出到word文件中。
二、PDF文件的识别(一)以文本形式保存的PDF文件,用acrobat 5 专业版,识别整个文件。
直接打开从网上下载的PDF格式文件另存为RTF文件,或者选择工具栏上的文字选择按钮,然后选择文字区域,然后复制到Word中即可。
(二)以图片形式保存的PDF文件,将PDF文件打印到Microsoft Office Document Image Writer打印机,选择打印形成的文件的保存位置,然后会自动形成一个MDI文件,并且自动用Microsoft Office Document Image打开此文件,然后在Microsoft Office Document Im?鄄age中选择“工具”菜单中的“使用OCR识别文本”,识别完成后,在选择“工具”下的,“将文本发送到word”,最后将把整个PDF文件识别输出到word文件中。
(三)加密的PDF文件先下载解密软件,解密后在参照上述步骤1),2) 进行。
(四)繁体PDF文件用上述步骤2)的方法识别到word后,用word中的“工具”→“语言”→“中文繁简转换”三、超星文件的识别(一)全文件识别打印到Microsoft Office Document Image Writer打印机,然后按上述PDF文件的识别步骤中第二点操作,要注意的是,超星打印功能有点区别,因为超星是目录和全文分开的,所以打印时,需要分别把目录和正文识别到Word中,再合并到一起。
打印时要填入打印页码从1到最后一页,不要选择打印全部。
在打印选项中,要将页面比例设成真实大小,而不是整宽。
注意识别速度比其他格式要慢很多,请保持耐心。
一般一本200多页的书,识别需要几分钟的时间。
(二)超星文件识别相对比较麻烦一些,如果还有问题,可以先把超星打印成完整的PDF文件,然后再用上述识别PDF文件的方法转成Word。
四、后记经过试验,发现Microsoft Office Document Image 存在一些不稳定的问题,如在用CAJ打印到Microsoft Office Document Image Writer时,发现用CAJ5.5版本比较快,而CAJ5.0有时出现假死机。
页面显示大时,转化的识别率较高。
如果页数多的文件,包括超星,可以分多次转化。
由于虚拟打印到Microsoft Office Document Image Writer 比较慢,并且形成的虚拟文件很大,1本200多页的书大约是60M,因此会严重影响机器的运行速度、C盘和内存空间。
建议配置好的机器一次转化不要超过200页,配置差的不要超过100页,同时打印时在任务栏中会出现打印机图标,可以双击,看到打印任务的进度,避免误以为死机。
转化完成后请删除c:\windows\temp目录下的虚拟打印文件,否则C盘很快会被用光。