SPSS17神经网络学习pdf
- 格式:pdf
- 大小:569.84 KB
- 文档页数:4

第九章对数线性模型第一节 General过程9.1.1 主要功能9.1.2 实例操作第二节 Hierarchical过程9.2.1 主要功能9.2.2 实例操作第三节 Logit过程9.3.1 主要功能9.3.2 实例操作对数线性模型是用于离散型数据或整理成列联表格式的计数资料的统计分析工具。
在对数线性模型中,所有用作的分类的因素均为独立变量,列联表各单元中的例数为应变量。
对于列联表资料,通常作χ 2 检验,但χ 2 检验无法系统地评价变量间的联系,也无法估计变量间相互作用的大小,而对数线性模型是处理这些问题的最佳方法。
第一节 General过程9.1.1 主要功能调用该过程可对一个或多个二维列联表资料进行非层次对数线性分析。
它只能拟合全饱和模型,即分类变量各自效应及其相互间效应均包含在对数线性模型中。
返回目录返回全书目录9.1.2 实例操作[例9-1]在住院病人中,研究其受教育程度与对保健服务满意程度的关系,资料整理成列联表后如下所示。
按一般情形作χ2检验,结果显示不同受教育程度的住院病人其对保健服务满意程度无差别。
但从百分比分析中可见,随受教育程度的提高,满意程度有下降的趋势;且我们还想了解受教育程度与满意程度有无交互作用和交互作用的大小。
对此,必须采用对数线性模型加以分析。
9.1.2.1 数据准备激活数据管理窗口,定义变量名:实际观察频数的变量名为freq,受教育程度和满意程度作为行、列分类变量(即独立变量),变量名分别为educ、care。
输入原始数据,结果如图9.1所示。
如同第四章Crosstab过程中所述,为使列联表的频数有效,应选Data菜单的Weight Cases...项,弹出Weight Cases对话框(图9.2),激活Weight cases by项,从变量列表中选freq点击 钮使之进入Frequency Variable框,点击OK钮即可。
图9.1 原始数据的输入图9.2 频数的加权定义9.1.2.2 统计分析激活Statistics菜单选Loglinear中的General...项,弹出General Loglinear Analysis对话框(图9.3)。

SPSS神经⽹络模型实验⽬的 学会使⽤SPSS的简单操作,掌握神经⽹络模型。
实验要求 使⽤SPSS。
实验内容 (1)创建多层感知器⽹络,使⽤多层感知器评估信⽤风险,银⾏信贷员需要能够找到预⽰有可能拖⽋贷款的⼈的特征来识别信⽤风险的⾼低。
(2)实现神经⽹络预测模型,使⽤径向基函数分类电信客户。
实验步骤 (1)创建多层感知器⽹络,分析⽰例——使⽤多层感知器评估信⽤风险,银⾏信贷员需要能够找到预⽰有可能拖⽋贷款的⼈的特征来识别信⽤风险的⾼低。
详细见bankloan.sav⽂件。
SPSS操作,点击【转换】→【随机数⽣成器】,在打开的对话框中,勾选【设置起点】,点击【估计值】,值设为“9191972”,单击【确定】。
【转换】→【计算变量】,在打开的对话框中,把“partion”输⼊【⽬标变量】。
在【数字表达式】中输⼊表达式(2*RV.BERNOULLI(0.7)-1),单击【确定】。
点击【分析】→【神经⽹络】→【多层感知器】,在打开的对话框中,把如图⽰的变量选⼊相应的地⽅。
【分区】,点击【使⽤分区变量来分配个案】,并把“partion”选⼊【分区变量】中。
点击【输出】,勾选想要输出的图表,点击【保存】,单击【确定】。
运⾏结果,个案处理摘要个案数百分⽐样本训练49971.3%坚持20128.7%有效700100.0%排除150总计850⽹络信息输⼊层因⼦1Level ofeducation协变量1Age in years2Years withcurrent employer3Years at currentaddress4Householdincome inthousands5Debt to income5Debt to incomeratio (x100)6Credit card debtin thousands7Other debt inthousands单元数a12协变量的重新标度⽅法隐藏层隐藏层数1隐藏层 1 中的单元数a4激活函数输出层因变量1单元数2激活函数误差函数a. 排除偏差单元模型摘要训练交叉熵误差156.605不正确预测百分⽐15.6%使⽤的中⽌规则超出最⼤时程数(100)训练时间0:00:00.25坚持不正确预测百分⽐25.4%因变量:Previously defaulted分类样本实测预测No Yes正确百分⽐训练No3472892.5% Yes507459.7%Yes507459.7%总体百分⽐79.6%20.4%84.4%坚持No1231986.6% Yes322745.8%总体百分⽐77.1%22.9%74.6%因变量:Previously defaulted曲线下⽅的区域区域Previously defaulted No.907Yes.907代码:1 COMPUTE partion=2*RV.BERNOULLI(0.7)-1.2 EXECUTE.3 *Multilayer Perceptron Network.4 MLP default (MLEVEL=N) BY ed WITH age employ address income debtinc creddebt othdebt5 /RESCALE COVARIATE=STANDARDIZED6 /PARTITION VARIABLE=partion7 /ARCHITECTURE AUTOMATIC=YES (MINUNITS=1 MAXUNITS=50)8 /CRITERIA TRAINING=BATCH OPTIMIZATION=SCALEDCONJUGATE LAMBDAINITIAL=0.00000059 SIGMAINITIAL=0.00005 INTERVALCENTER=0 INTERVALOFFSET=0.5 MEMSIZE=100010 /PRINT CPS NETWORKINFO SUMMARY CLASSIFICATION11 /PLOT NETWORK ROC GAIN LIFT PREDICTED12 /SAVE PREDVAL PSEUDOPROB13 /STOPPINGRULES ERRORSTEPS= 1 (DATA=AUTO) TRAININGTIMER=ON (MAXTIME=15) MAXEPOCHS=AUTO14 ERRORCHANGE=1.0E-4 ERRORRATIO=0.00115 /MISSING USERMISSING=EXCLUDE .多层神经⽹络 (1)实现神经⽹络预测模型,分析⽰例——使⽤径向基函数分类电信客户,具体见telco.sav。



SPSS17.0的基本操作入门操作数据的输入建立字段——输入数字——保存(分别在data view和variabe view下处理)数据的简单描述(n,最大值,最小值,平均值,方差)Descriptive Statistics→Descriptives→选择变量→ok(分组描述方法:Data→Split File→选择分组指标→ok→再进行上面分析)绘制直方图Graphs→Histogram→选择变量→ok统计分析(两个样本的均值比较-t检验)Analyze→Compare Mean→Independent-Samples T test→选择变量和分组变量→设置分组变量值→ok(结果如下)Independent Samples TestLevene's Test for Equality of Variances t-test for Equality of MeansF Sig. t df Sig. (2-tailed) Mean Difference Std. Error Difference 95% Confidence Interval of the DifferenceLower Upperx Equal variances assumed .032 .860 2.524 22 .019 .43629 .17288 .07777 .79482Equal variances not assumed 2.524 21.353 .020 .43629 .17286 .07716 .79542(1)方差齐性检验时F越小(p越大),就证明没有差异,就说明齐,这与方差分析均数时F越大约好相反。
F=MS组间/MS误差=(处理因素的影响+个体差异带来的误差)/个体差异带来的误差(2)统计显著性(sig)就是出现目前样本这结果的机率,即P=sig=0.860,sig越接近1越齐(3)df为自由度df=n-2=24-2=22(4) ∂=0.05数据编辑窗口的用法variable view下的设置,主要是name,lable,measure栏value是可以改关联数字代表的意义,可以定义三组类型,显示可以view /value lables Measure可以选三种类型:scale 标度测量Ordinal 有序测量,有序分类,有高低之分Nominal 名义测量,没有高低之分;例如:血型数据编辑操作的技巧(1)快速查找异常值极端值排序,右键排序(2)冻结数据表右键,pin selected coolumns(只能从左端开始冻结)(3)快速改变列位托(4)利用变量标签数据文件的处理data和transform菜单的应用Transforms(1)compute过程(赋值,条件赋值)新建自变量→transforms/compute→赋值一个→再制造条件if(2)count过程(定义缺失值,变量范围)Transforms/count→define values→定义缺失值,range变量范围(3)recode过程(根据原条件得到新的变量)Transforms/recode→different variable→填写新变量名→选择自变量→change→old and new values→定义条件和new values(4)rank cases过程(分组排序)Transforms/rank cases→选择自变量和分组变量DATA(1)sort case过程(排序)Data/sort case→选择变量→选择升序和降序(2)transpose(变量和记录的置换,即变量变成记录,记录变成变量)(3)restructure过程(重复测量模型中应用)Data/restructure→选择变换模型→选择ID变量(区分个体的变量)和index变量(区分次数变量)→ok(4)merge files过程(批量加载数据)纵向合并:添加新的自变量data→merge files→add cases (*表示当前数据集变量,+表示需加的数据集变量)横向合并:添加变量行data→merge files→add variables(5)aggregate过程(数据分类汇总)(6)split file(分组处理)技术技巧(1)二项分布累计概率Data/transform/compute→填入新变量名→functions中选择cdf.binom(q,n,p)(p是实际发生数,n总样本数,p总体发生数)SPSS结果窗口用法详解§4.1结果窗口元素介绍SPSS实际上提供了两个结果窗口--结果浏览窗口和结果草稿浏览窗口。

SPSS 17中文版统计分析典型实例精粹目录第一篇 SPSS 17基础知识第1章 SPSS 17入门 (3)1.1 SPSS 软件的特点 (3)1.2 SPSS的组成与安装 (4)1.2.1 SPSS for Windows 17.0的模块介绍 (4)1.2.2 SPSS for Windows 17.0的安装步骤 (5)1.3 SPSS的运行方式 (10)1.4 SPSS的主要界面 (10)1.4.1 SPSS的启动 (10)1.4.2 SPSS的数据编辑窗口. 111.4.3 SPSS的结果输出窗口 151.5 本章小结 (18)第2章数据的基本操作 (19)2.1 建立数据文件 (19)2.1.1 输入数据建立数据文件 (19)2.1.2 直接打开其他格式的数据文件 (20)2.1.3 使用数据库查询建立数据文件 (21)2.1.4 导入文本文件建立数据文件 (22)2.2 编辑数据文件 (23)2.2.1 输入数据 (23)2.2.2 定义数据的属性 (24)2.2.3 插入或删除数据 (33)2.2.4 数据的排序 (34)2.2.5 选择个案 (35)2.2.6 转置数据 (38)2.2.7 合并数据文件 (38)2.2.8 数据的分类汇总 (44)2.2.9 数据菜单的其他功能.. 462.3 数据加工 (47)2.3.1 数据转换 (47)2.3.2 数据的手动分组(编码) (50)2.3.3 数据的自动分组(编码) (54)2.3.4 产生计数变量 (55)2.3.5 数据秩(序)的确定.. 572.3.6 替换缺失值 (59)2.4 数据文件的保存或导出 (61)2.4.1 保存数据文件 (61)2.4.2 导出数据文件 (62)2.5 本章小结 (62)第3章 SPSS基础统计描述 (63)3.1 数理统计量概述 (63)3.1.1 均值(Mean)和均值标准误差(S.E. Mea n) (63)3.1.2 中位数(Median) (64)3.1.3 众数(Mode) (64)3.1.4 全距(Range) (65)3.1.5 方差(Variance)和标准差(Standard Deviatio n) (65)3.1.6 峰度(Kurtosis)和偏度(Skewness).. 663.1.7 四分位数(Quartiles)、十分位数(Deciles)和百分位数(Percentiles) (66)3.2 数据描述 (67)3.3 频数分析 (69)3.4 探索分析 (73)3.5 交叉列联表分析 (78)3.6 比率分析 (84)3.7 P-P图和Q-Q图 (86)3.8 图表绘制 (89)3.8.1 条形图 (89)3.8.2 线图 (94)3.8.3 面积图 (96)3.8.4 饼形图 (98)3.8.5 高低图 (99)3.8.6 箱图 (101)3.8.7 直方图 (103)3.9 本章小结 (104)第4章 SPSS基础模块分析 (105)4.1 均值分析 (105)4.1.1 均值的计算公式 (105)4.1.2 均值分析菜单 (106)4.2 方差分析 (108)4.2.1 单因素方差分析 (109)4.2.2 其他方差分析 (113)4.3 参数检验 (116)4.3.1 单样本T检验 (117)4.3.2 其他参数检验 (119)4.4 非参数检验 (120)4.4.1 卡方检验 (121)4.4.2 其他非参数检验 (124)4.5 回归分析 (131)4.5.1 线性回归 (131)4.5.2 其他回归分析 (138)4.6 聚类分析 (146)4.6.1 两步聚类分析 (146)4.6.2 其他聚类分析 (152)4.7 判别分析 (154)4.7.1 判别的函数公式 (155)4.7.2 判别分析的菜单 (155)4.8 因子分析与主成分分析 (161)4.8.1 因子分析 (161)4.8.2 主成分分析 (166)4.9 时间序列分析 (167)4.9.1 定义日期变量 (168)4.9.2 创建时间序列 (169)4.9.3 填补缺失数据 (171)4.9.4 时间序列分析 (171)4.10 生存分析 (172)4.10.1 寿命表分析 (173)4.10.2 其他生存分析 (174)4.11 相关分析 (176)4.11.1 简单相关分析 (176)4.11.2 散点图 (181)4.11.3 偏相关分析 (184)4.12 信度分析 (186)4.12.1 信度分析概述 (187)4.12.2 SPSS信度分析 (189)4.12.3 信度分析的其他问题 (192)4.13 本章小结 (197)第二篇 SPSS 17统计分析应用实例第一部分调查统计5.1 硬币均匀性判断 (203)5.1.1 实例内容说明 (203)5.1.2 实现方法分析 (204)5.1.3 具体操作步骤 (204)5.2 使用回归分析判断住房与收入的关系 (207)5.2.1 实例内容说明 (207)5.2.2 实现方法分析 (208)5.2.3 具体操作步骤 (208)5.3 不同性别同学成绩的均值和方差分析 (216)5.3.1 实例内容说明 (216)5.3.2 实现方法分析 (216)5.3.3 具体操作步骤 (216)5.4 本章小结 (220)第6章调查统计提高实例 (221)6.1 学生身高的探索性分析 (221)6.1.1 实例内容说明 (221)6.1.2 实现方法分析 (222)6.1.3 具体操作步骤 (222)6.2 使用对数线性模型分析骨折资料 (229)6.2.1 实例内容说明 (229)6.2.2 实现方法分析 (229)6.2.3 具体操作步骤 (230)6.3 培训班学习成绩的显著性分析 (237)6.3.1 实例内容说明 (237)6.3.2 实现方法分析 (238)6.3.3 具体操作步骤 (238)6.4 本章小结 (241)7.1 学习成绩的聚类分析 (243)7.1.1 实例内容说明 (243)7.1.2 实现方法分析 (243)7.1.3 具体操作步骤 (244)7.2 身体生长发育指标的地区显著性差异判断 (251)7.2.1 实例内容说明 (251)7.2.2 实现方法分析 (252)7.2.3 具体操作步骤 (252)7.3 复习时间和考试成绩的关系判断 (262)7.3.1 实例内容说明 (262)7.3.2 实现方法分析 (263)7.3.3 具体操作步骤 (263)7.4 本章小结 (266)第二部分市场研究第8章市场研究入门实例 (269)8.1 机电产品销售额的影响因素分析 (269)8.1.1 实例内容说明 (269)8.1.2 实现方法分析 (270)8.1.3 具体操作步骤 (270)8.2 消费支出与可支配收入的线性回归分析 (276)8.2.1 实例内容说明 (276)8.2.2 实现方法分析 (277)8.2.3 具体操作步骤 (277)8.3 商品的季节性分析 (289)8.3.1 实例内容说明 (289)8.3.2 实现方法分析 (290)8.3.3 具体操作步骤 (290)8.4 本章小结 (300)第9章市场研究提高实例 (301)9.1 保险公司革新速度与规模及其类型间的关系分析 (301)9.1.1 实例内容说明 (301)9.1.2 实现方法分析 (302)9.1.3 具体操作步骤 (302)9.2 不同厂家同种产品的质量分析 (313)9.2.1 实例内容说明 (313)9.2.2 实现方法分析 (314)9.2.3 具体操作步骤 (314)9.3 合成纤维的强度与拉伸倍数的关系分析 (318)9.3.1 实例内容说明 (318)9.3.2 实现方法分析 (319)9.3.3 具体操作步骤 (319)9.4 本章小结 (325)第10章市场研究经典实例 (327)10.1 灯丝不同的灯泡的使用寿命分析 (327)10.1.1 实例内容说明 (327)10.1.2 实现方法分析 (327)10.1.3 具体操作步骤 (328)10.2 不同商品的消费者满意度分析 (336)10.2.1 实例内容说明 (336)10.2.2 实现方法分析 (337)10.2.3 具体操作步骤 (337)10.3 顾客对不同款式衬衣喜爱程度的分析 (344)10.3.1 实例内容说明 (344)10.3.2 实现方法分析 (344)10.3.3 具体操作步骤 (344)10.4 本章小结 (348)第三部分企业/政府数据分析第11章企业/政府数据分析入门实例 (351)11.1 儿童身高数据频数分析 (351)11.1.1 实例内容说明 (351)11.1.2 实现方法分析 (352)11.1.3 具体操作步骤 (352)11.2 百姓对奥运会评价的方差分析 (360)11.2.1 实例内容说明 (360)11.2.2 实现方法分析 (361)11.2.3 具体操作步骤 (361)11.3 居民交通工具使用情况的回归分析 (369)11.3.1 实例内容说明 (369)11.3.2 实现方法分析 (370)11.3.3 具体操作步骤 (370)11.4 本章小结 (377)第12章企业/政府数据分析提高实例 (379)12.1 卫生部门对居民寿命情况的分析 (379)12.1.1 实例内容说明 (379)12.1.2 实现方法分析 (379)12.1.3 具体操作步骤 (380)12.2 农作物产量与降水量和平均温度的相关性分析 (386)12.2.1 实例内容说明 (386)12.2.2 实现方法分析 (386)12.2.3 具体操作步骤 (387)12.3 加强体育锻炼与增强身体素质的关系分析.. 39012.3.1 实例内容说明 (390)12.3.2 实现方法分析 (390)12.3.3 具体操作步骤 (391)12.4 本章小结 (394)第13章企业/政府数据分析经典实例 (395)13.1 当代大学生价值观的因子分析 (395)13.1.1 实例内容说明 (395)13.1.2 实现方法分析 (396)13.1.3 具体操作步骤 (397)13.2 职业女性家庭特征资料的信度评价 (404)13.2.1 实例内容说明 (404)13.2.2 实现方法分析 (405)13.2.3 具体操作步骤 (405)13.3 对国内生产总值和零售总额之间的关系分析 (412)13.3.1 实例内容说明 (412)13.3.2 实现方法分析 (413)13.3.3 具体操作步骤 (414)13.4 本章小结 (420)第四部分医学统计分析第14章医学统计分析入门实例 (423)14.1 血红蛋白值描述性统计分析 (423)14.1.1 实例内容说明 (423)14.1.2 实现方法分析 (424)14.1.3 具体操作步骤 (424)14.2 环氯胍的半数致死剂量计算 (428)14.2.1 实例内容说明 (428)14.2.2 实现方法分析 (429)14.2.3 具体操作步骤 (429)14.3 发硒与血硒的相关分析 (435)14.3.1 实例内容说明 (435)14.3.2 实现方法分析 (436)14.3.3 具体操作步骤 (436)14.4 本章小结 (439)第15章医学统计分析提高实例 (441)15.1 用统计图描述血压状态与冠心病的关系 (441)15.1.1 实例内容说明 (441)15.1.2 实现方法分析 (441)15.1.3 具体操作步骤 (442)15.2 判断红细胞计数的频数是否呈正态分布 (448)15.2.1 实例内容说明 (448)15.2.2 实现方法分析 (448)15.2.3 具体操作步骤 (449)15.3 胃癌患者发生术后院内感染的影响因素分析 (452)15.3.1 实例内容说明 (452)15.3.2 实现方法分析 (453)15.3.3 具体操作步骤 (453)15.4 本章小结 (462)第16章医学统计分析经典实例 (463)16.1 不同治疗方案的生存率分析 (463)16.1.1 实例内容说明 (463)16.1.2 实现方法分析 (464)16.1.3 具体操作步骤 (465)16.2 不同制剂的药效分析 (473)16.2.1 实例内容说明 (473)16.2.2 实现方法分析 (473)16.2.3 具体操作步骤 (474)16.3 同种药物在不同治疗阶段的药效分析 (481)16.3.1 实例内容说明 (481)16.3.2 实现方法分析 (481)16.3.3 具体操作步骤 (483)16.4 本章小结 (487)《SPSS 17中文版统计分析典型实例精粹》:以经典统计学软件SPSS 17中文版为写作平台,提供软件命令的中英对照基础篇学习软件基本操作和统计描述知识,实例篇详解案例应用原理、流程和操作技巧36个实例典型、丰富,涉及调查统计、市场研究、企业/政府数据分析和医学统计领域循序渐进、由浅入深,围绕SPSS应用的原理、流程和操作技巧娓娓阐述插图:1.3 SPSS的运行方式SPSS提供了三种基本的运行方式:完全窗口菜单运行方式、程序运行方式和批处理方式。
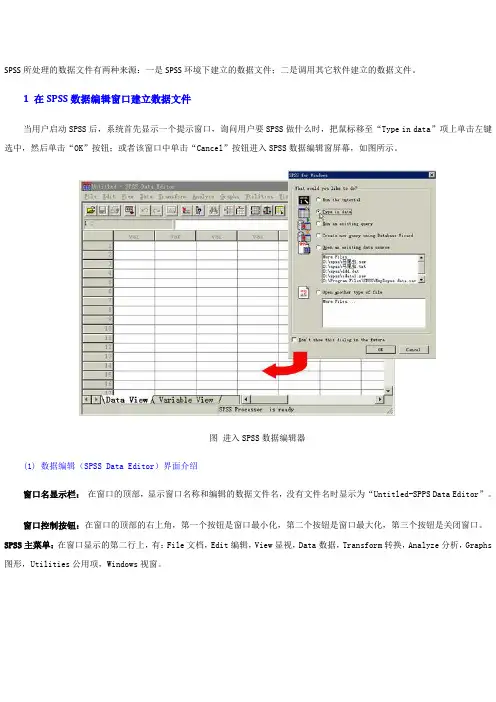
SPSS所处理的数据文件有两种来源:一是SPSS环境下建立的数据文件;二是调用其它软件建立的数据文件。
1 在SPSS数据编辑窗口建立数据文件当用户启动SPSS后,系统首先显示一个提示窗口,询问用户要SPSS做什么时,把鼠标移至“Type in data”项上单击左键选中,然后单击“OK”按钮;或者该窗口中单击“Cancel”按钮进入SPSS数据编辑窗屏幕,如图所示。
图进入SPSS数据编辑器(1) 数据编辑(SPSS Data Editor)界面介绍窗口名显示栏:在窗口的顶部,显示窗口名称和编辑的数据文件名,没有文件名时显示为“Untitled-SPPS Data Editor”。
窗口控制按钮:在窗口的顶部的右上角,第一个按钮是窗口最小化,第二个按钮是窗口最大化,第三个按钮是关闭窗口。
SPSS主菜单:在窗口显示的第二行上,有:File文档,Edit编辑,View显视,Data数据,Transform转换,Analyze分析,Graphs 图形,Utilities公用项,Windows视窗。
图 SPSS窗口界面常用工具按钮:在窗口显示的第三行上,有:打开文档,保存文档,打印,对话检索,取消当前操作,重做操作,转到图形窗口,指向记录,指定变量操作,查找,在当前记录的上方插入新的空白记录,在当前变量的左边插入新的空白变量,切分文件,设置权重单元,标记单元,显示价值标签。
数据单元格信息显示栏:在编辑显示区的上方,左边显示单元格和变量名(单元格:变量名),右边显示单元里的内容。
编辑显示区:在窗口的中部,最左边列显示单元序列号,最上边一行显示变量名称,缺省为“Var”。
编辑区选择栏:在编辑显示区下方,Data View 在编辑显示区中显示编辑数据,Variable View在编辑显示区中显示编辑数据变量信息。
状态显示栏:在窗口的底部,左边显示执行的系统命令,右边显示窗口状态。
(2) 数据文件格式数据文件格式以每一行为一个记录,或称观察单位(Cases),每一列为一个变量(Variable)。


一、感知器的学习结构感知器的学习是神经网络最典型的学习。
目前,在控制上应用的是多层前馈网络,这是一种感知器模型,学习算法是BP法,故是有教师学习算法。
一个有教师的学习系统可以用图1—7表示。
这种学习系统分成三个部分:输入部,训练部和输出部。
神经网络学习系统框图1-7 图神经网络的学习一般需要多次重复训练,使误差值逐渐向零趋近,最后到达零。
则这时才会使输出与期望一致。
故而神经网络的学习是消耗一定时期的,有的学习过程要重复很多次,甚至达万次级。
原因在于神经网络的权系数W有很多分量W ,W ,----W ;也即是一n12个多参数修改系统。
系统的参数的调整就必定耗时耗量。
目前,提高神经网络的学习速度,减少学习重复次数是十分重要的研究课题,也是实时控制中的关键问题。
二、感知器的学习算法.感知器是有单层计算单元的神经网络,由线性元件及阀值元件组成。
感知器如图1-9所示。
图1-9 感知器结构感知器的数学模型:(1-12)其中:f[.]是阶跃函数,并且有(1-13)θ是阀值。
感知器的最大作用就是可以对输入的样本分类,故它可作分类器,感知器对输入信号的分类如下:即是,当感知器的输出为1时,输入样本称为A类;输出为-1时,输入样本称为B类。
从上可知感知器的分类边界是:(1-15)在输入样本只有两个分量X1,X2时,则有分类边界条件:(1-16)即W X +W X -θ=0 (1-17) 2121也可写成(1-18)这时的分类情况如固1—10所示。
感知器的学习算法目的在于找寻恰当的权系数w=(w1.w2,…,Wn),。
当d熊产生期望值xn),…,x2,(xt=x定的样本使系统对一个特.x分类为A类时,期望值d=1;X为B类时,d=-1。
为了方便说明感知器学习算法,把阀值θ并人权系数w中,同时,样本x也相应增加一个分量x 。
故令:n+1W =-θ,X =1 (1-19) n+1n+1则感知器的输出可表示为:(1-20)感知器学习算法步骤如下:1.对权系数w置初值对权系数w=(W.W ,…,W ,W )的n+11n2各个分量置一个较小的零随机值,但W =—g。

SPSS 17数据管理数据排序数据||数据排序数据文件的拆分与合并数据||拆分文件数据文件的合并横向合并数据||合并文件||添加变量纵向合并数据||合并文件||添加个案数据文件的转置数据||转置观测量的加权数据||加权个案根据已存在的变建立新的变量转换||计算变量产生计数变量转换||对个案内的值计数变量重新赋值对自身变量重新赋值转换||重新编码为相同变量赋值生成新的变量转换||重新编码为不同变量变量取值的求秩(排序)转换||个案排秩缺失值的处理转换||替换缺失值数据的分类汇总数据||分类汇总数据文件的结构重组描述性分析频数分析探索分析反映分布形式正态性检验(原假设为服从正态分布)等方差性检验列联表比率如估算几个不同地区对估价差异的比较在线分析处理报告(OLAP)分析||报告||OLAP立方生成对数据文件的总体描述报告个案摘要报告分析||报告||个案汇总生成个案描述行形式摘要报告分析||报告||按行汇总列形式摘要报告分析||报告||按列汇总均值比较和T 检验均值过程分析||比较均值||均值如比较工作经验与薪水的关系单样本T 检验分析||比较均值||单样本T 检验判断观测值与给定值的差异独立样本T 检验分析||比较均值||独立样本T 检验如比较两班的成绩均值配对样本的T 检验分析||比较均值||配对样本的T检验如比较用药前后某变量均值的差异非参数检验卡方检验分析||非参数检验||卡方检验用于检验是否服从均匀分布原假设为服从二项检验分析||非参数检验||二项式同上两独立样本检验分析||非参数检验||2个独立样本如比较两种治疗效果的独立性多个独立样本检验分析||非参数检验||K 个独立样本两配对样本检验分析||非参数检验||2 个相关样本如比较两变量的系统差异多配对样本检验分析||非参数检验||K 个相关样本游程检验分析||非参数检验||游程检验抽取数据是否为随机单样本K-S检验分析||非参数检验||1 样本K-S检验检测某变量是否服从某分布单因素方差分析分析||比较均值||单因素ANOVA 如比较施三种不同肥料对产量的差异多因素方差分析分析||一般线性模型||单变量如比较两个以上的因素对一变量的影响差异协方差分析分析||一般线性模型||单变量如利用培训前得分协助不同培训方法解释培训后得分多因变量方差分析分析||一般线性模型||多变量如用不同培训方法解释两因变量的差异双变量相关分析分析||相关||双变量偏相关分析分析||相关||偏相关如比较某变量剔除前后各变量间的相关度距离分析分析||相关||距离对所有变量进行相关度分析线性回归分析分析||回归||线性曲线回归分析分析||回归||曲线非线性回归分析分析||回归||非线性用于解出给定方程相关系数Logistic分析||回归||二元Logistic 用于计算逻辑变量各值发生概率有序回归分析分析||回归||有序对有序变量做回归概率单位回归分析||回归||Probit 如抽中选中地块中响应的地块数对季节作用做回归加权回归分析||回归||权重估计对某自变量进行加权多重响应分析多重响应变量集分析||多重响应变量集||自定义变量集多重响应变量集的频数分析分析||多重响应||频率多重响应的交叉表分析分析||多重响应||交叉表分析使用Tables过程研究多重响应变量集分析||表||多重响应集起的作用同上快速聚类分析||分类||K-均值聚类分层聚类分析||分类||分层聚类两阶段聚类分析分析||聚类||两步聚类一般判别分析分析||分类||判别利用已有大量个案计算未分类个案逐步判别分析分析||分类||判别以一般判别分析有基础决策树分析分析||分类||树因子分析和主成分分析因子分析分析||降维||因子分析降维注意观测KMO值主成分分析分析||降维||因子分析转换||计算变量生成新的变量达到降维目的对应分析一般对应分析一般需要先加权分析||降维||对应分析可根据图判断两变量的关系多重对应分析分析||降维||最优尺度多个指标判断分析如螺丝与多个指标的对应时间序列模型时间序列数的预处理数据||定义日期指数平滑模型分析||预测||创建模型对已有数据绘图以供预测ARIMA模型同上季节分解模型分析||预测||季节性分解排除季节的干扰寿命表分析分析||生存函数||寿命表如分析某部门人员随时间的在职与否变动Kplan-Meier分析分析||生存函数||Kplan-MeierCox回归分析分析||生存函数||Cox回归可给出生存函数和风险函数信度分析分析||度量||可靠性分析分析结果的可靠性多维尺度分析分析||度量||多维尺度(ALSCAL)如测定五个景点两两相关性做为区分依据缺失值分析缺失值分析分析||缺失值分析。

目录第一篇?SPSS17基础知识第1章?SPSS17入门 (3)1.1?SPSS软件的特点 (3)1.2?SPSS的组成与安装 (4)1.2.1?SPSSforWindows17.0的模块介绍 (4)1.2.2?SPSSforWindows17.0的安装步骤 (5)1.3?SPSS的运行方式 (10)1.4?SPSS的主要界面 (10)1.4.1?SPSS的启动 (10)1.4.2?SPSS的数据编辑窗口.111.4.3?SPSS的结果输出窗口151.5?本章小结 (18)第2章?数据的基本操作 (19)2.1?建立数据文件 (19)2.1.1?输入数据建立数据文件 (19)2.1.2?直接打开其他格式的数据文件 (20)2.1.3?使用数据库查询建立数据文件 (21)2.1.4?导入文本文件建立数据文件 (22)2.2?编辑数据文件 (23)2.2.1?输入数据 (23)2.2.2?定义数据的属性 (24)2.2.3?插入或删除数据 (33)2.2.4?数据的排序 (34)2.2.5?选择个案 (35)2.2.6?转置数据 (38)2.2.7?合并数据文件 (38)2.2.8?数据的分类汇总 (44)2.2.9?数据菜单的其他功能..462.3?数据加工 (47)2.3.1?数据转换 (47)2.3.2?数据的手动分组(编码) (50)2.3.3?数据的自动分组(编码) (54)2.3.4?产生计数变量 (55)2.3.5?数据秩(序)的确定..572.3.6?替换缺失值 (59)2.4?数据文件的保存或导出 (61)2.4.1?保存数据文件 (61)2.4.2?导出数据文件 (62)2.5?本章小结 (62)第3章?SPSS基础统计描述 (63)3.1?数理统计量概述 (63)3.1.1?均值(Mean)和均值标准误差(S.E.Mean) (63)3.1.2?中位数(Median) (64)3.1.3?众数(Mode) (64)3.1.4?全距(Range) (65)3.1.5?方差(Variance)和标准差(StandardDeviation) (65)3.1.6?峰度(Kurtosis)和偏度(Skewness)..663.1.7?四分位数(Quartiles)、十分位数(Deciles)和百分位数(Percentiles) (66)3.2?数据描述 (67)3.3?频数分析 (69)3.4?探索分析 (73)3.5?交叉列联表分析 (78)3.6?比率分析 (84)3.7?P-P图和Q-Q图 (86)3.8?图表绘制 (89)3.8.1?条形图 (89)3.8.2?线图 (94)3.8.3?面积图 (96)3.8.4?饼形图 (98)3.8.5?高低图 (99)3.8.6?箱图 (101)3.8.7?直方图 (103)3.9?本章小结 (104)第4章?SPSS基础模块分析 (105)4.1?均值分析 (105)4.1.1?均值的计算公式 (105)4.1.2?均值分析菜单 (106)4.2?方差分析 (108)4.2.1?单因素方差分析 (109)4.2.2?其他方差分析 (113)4.3?参数检验 (116)4.3.1?单样本T检验 (117)4.3.2?其他参数检验 (119)4.4?非参数检验 (120)4.4.1?卡方检验 (121)4.4.2?其他非参数检验 (124)4.5?回归分析 (131)4.5.1?线性回归 (131)4.5.2?其他回归分析 (138)4.6?聚类分析 (146)4.6.1?两步聚类分析 (146)4.6.2?其他聚类分析 (152)4.7?判别分析 (154)4.7.1?判别的函数公式 (155)4.7.2?判别分析的菜单 (155)4.8?因子分析与主成分分析 (161)4.8.1?因子分析 (161)4.8.2?主成分分析 (166)4.9?时间序列分析 (167)4.9.1?定义日期变量 (168)4.9.2?创建时间序列 (169)4.9.3?填补缺失数据 (171)4.9.4?时间序列分析 (171)4.10?生存分析 (172)4.10.1?寿命表分析 (173)4.10.2?其他生存分析 (174)4.11?相关分析 (176)4.11.1?简单相关分析 (176)4.11.2?散点图 (181)4.11.3?偏相关分析 (184)4.12?信度分析 (186)4.12.1?信度分析概述 (187)4.12.2?SPSS信度分析 (189)4.12.3?信度分析的其他问题 (192)4.13?本章小结 (197)第二篇?SPSS17统计分析应用实例第一部分?调查统计第5章?调查统计入门实例 (203)5.1?硬币均匀性判断 (203)5.1.1?实例内容说明 (203)5.1.2?实现方法分析 (204)5.1.3?具体操作步骤 (204)5.2?使用回归分析判断住房与收入的关系 (207)5.2.1?实例内容说明 (207)5.2.2?实现方法分析 (208)5.2.3?具体操作步骤 (208)5.3?不同性别同学成绩的均值和方差分析 (216)5.3.1?实例内容说明 (216)5.3.2?实现方法分析 (216)5.3.3?具体操作步骤 (216)5.4?本章小结 (220)第6章?调查统计提高实例 (221)6.1?学生身高的探索性分析 (221)6.1.1?实例内容说明 (221)6.1.2?实现方法分析 (222)6.1.3?具体操作步骤 (222)6.2?使用对数线性模型分析骨折资料 (229)6.2.1?实例内容说明 (229)6.2.2?实现方法分析 (229)6.2.3?具体操作步骤 (230)6.3?培训班学习成绩的显着性分析 (237)6.3.1?实例内容说明 (237)6.3.2?实现方法分析 (238)6.3.3?具体操作步骤 (238)6.4?本章小结 (241)第7章?调查统计经典实例 (243)7.1?学习成绩的聚类分析 (243)7.1.1?实例内容说明 (243)7.1.2?实现方法分析 (243)7.1.3?具体操作步骤 (244)7.2?身体生长发育指标的地区显着性差异判断 (251)7.2.1?实例内容说明 (251)7.2.2?实现方法分析 (252)7.2.3?具体操作步骤 (252)7.3?复习时间和考试成绩的关系判断 (262)7.3.1?实例内容说明 (262)7.3.2?实现方法分析 (263)7.3.3?具体操作步骤 (263)7.4?本章小结 (266)第二部分?市场研究第8章?市场研究入门实例 (269)8.1?机电产品销售额的影响因素分析 (269)8.1.1?实例内容说明 (269)8.1.2?实现方法分析 (270)8.1.3?具体操作步骤 (270)8.2?消费支出与可支配收入的线性回归分析 (276)8.2.1?实例内容说明 (276)8.2.2?实现方法分析 (277)8.2.3?具体操作步骤 (277)8.3?商品的季节性分析 (289)8.3.1?实例内容说明 (289)8.3.2?实现方法分析 (290)8.3.3?具体操作步骤 (290)8.4?本章小结 (300)第9章?市场研究提高实例 (301)9.1?保险公司革新速度与规模及其类型间的关系分析 (301)9.1.1?实例内容说明 (301)9.1.2?实现方法分析 (302)9.1.3?具体操作步骤 (302)9.2?不同厂家同种产品的质量分析 (313)9.2.1?实例内容说明 (313)9.2.2?实现方法分析 (314)9.2.3?具体操作步骤 (314)9.3?合成纤维的强度与拉伸倍数的关系分析 (318)9.3.1?实例内容说明 (318)9.3.2?实现方法分析 (319)9.3.3?具体操作步骤 (319)9.4?本章小结 (325)第10章?市场研究经典实例 (327)10.1?灯丝不同的灯泡的使用寿命分析 (327)10.1.1?实例内容说明 (327)10.1.2?实现方法分析 (327)10.1.3?具体操作步骤 (328)10.2?不同商品的消费者满意度分析 (336)10.2.1?实例内容说明 (336)10.2.2?实现方法分析 (337)10.2.3?具体操作步骤 (337)10.3?顾客对不同款式衬衣喜爱程度的分析 (344)10.3.1?实例内容说明 (344)10.3.2?实现方法分析 (344)10.3.3?具体操作步骤 (344)10.4?本章小结 (348)第三部分?企业/政府数据分析第11章?企业/政府数据分析入门实例 (351)11.1?儿童身高数据频数分析 (351)11.1.1?实例内容说明 (351)11.1.2?实现方法分析 (352)11.1.3?具体操作步骤 (352)11.2?百姓对奥运会评价的方差分析 (360)11.2.1?实例内容说明 (360)11.2.2?实现方法分析 (361)11.2.3?具体操作步骤 (361)11.3?居民交通工具使用情况的回归分析 (369)11.3.1?实例内容说明 (369)11.3.2?实现方法分析 (370)11.3.3?具体操作步骤 (370)第12章?企业/政府数据分析提高实例 (379)12.1?卫生部门对居民寿命情况的分析 (379)12.1.1?实例内容说明 (379)12.1.2?实现方法分析 (379)12.1.3?具体操作步骤 (380)12.2?农作物产量与降水量和平均温度的相关性分析 (38)612.2.1?实例内容说明 (386)12.2.2?实现方法分析 (386)12.2.3?具体操作步骤 (387)12.3?加强体育锻炼与增强身体素质的关系分析..39012.3.1?实例内容说明 (390)12.3.2?实现方法分析 (390)12.3.3?具体操作步骤 (391)12.4?本章小结 (394)第13章?企业/政府数据分析经典实例 (395)13.1?当代大学生价值观的因子分析 (395)13.1.1?实例内容说明 (395)13.1.2?实现方法分析 (396)13.1.3?具体操作步骤 (397)13.2?职业女性家庭特征资料的信度评价 (404)13.2.1?实例内容说明 (404)13.2.2?实现方法分析 (405)13.2.3?具体操作步骤 (405)13.3?对国内生产总值和零售总额之间的关系分析 (4)1213.3.1?实例内容说明 (412)13.3.2?实现方法分析 (413)13.3.3?具体操作步骤 (414)第四部分?医学统计分析第14章?医学统计分析入门实例 (423)14.1?血红蛋白值描述性统计分析 (423)14.1.1?实例内容说明 (423)14.1.2?实现方法分析 (424)14.1.3?具体操作步骤 (424)14.2?环氯胍的半数致死剂量计算 (428)14.2.1?实例内容说明 (428)14.2.2?实现方法分析 (429)14.2.3?具体操作步骤 (429)14.3?发硒与血硒的相关分析 (435)14.3.1?实例内容说明 (435)14.3.2?实现方法分析 (436)14.3.3?具体操作步骤 (436)14.4?本章小结 (439)第15章?医学统计分析提高实例 (441)15.1?用统计图描述血压状态与冠心病的关系 (441)15.1.1?实例内容说明 (441)15.1.2?实现方法分析 (441)15.1.3?具体操作步骤 (442)15.2?判断红细胞计数的频数是否呈正态分布 (448)15.2.1?实例内容说明 (448)15.2.2?实现方法分析 (448)15.2.3?具体操作步骤 (449)15.3?胃癌患者发生术后院内感染的影响因素分析 (4)5215.3.1?实例内容说明 (452)15.3.2?实现方法分析 (453)15.3.3?具体操作步骤 (453)第16章?医学统计分析经典实例 (463)16.1?不同治疗方案的生存率分析 (463)16.1.1?实例内容说明 (463)16.1.2?实现方法分析 (464)16.1.3?具体操作步骤 (465)16.2?不同制剂的药效分析 (473)16.2.1?实例内容说明 (473)16.2.2?实现方法分析 (473)16.2.3?具体操作步骤 (474)16.3?同种药物在不同治疗阶段的药效分析 (481)16.3.1?实例内容说明 (481)16.3.2?实现方法分析 (481)16.3.3?具体操作步骤 (483)16.4?本章小结 (487)《SPSS17中文版统计分析典型实例精粹》:以经典统计学软件SPSS17中文版为写作平台,提供软件命令的中英对照基础篇学习软件基本操作和统计描述知识,实例篇详解案例应用原理、流程和操作技巧36个实例典型、丰富,涉及调查统计、市场研究、企业/政府数据分析和医学统计领域循序渐进、由浅入深,围绕SPSS应用的原理、流程和操作技巧娓娓阐述插图:1.3SPSS的运行方式SPSS提供了三种基本的运行方式:完全窗口菜单运行方式、程序运行方式和批处理方式。
SPSS 17中文版统计分析典型实例精粹目录第一篇 SPSS 17基础知识第1章 SPSS 17入门 (3)1.1 SPSS 软件的特点 (3)1.2 SPSS的组成与安装 (4)1.2.1 SPSS for Windows 17.0的模块介绍 (4)1.2.2 SPSS for Windows 17.0的安装步骤 (5)1.3 SPSS的运行方式 (10)1.4 SPSS的主要界面 (10)1.4.1 SPSS的启动 (10)1.4.2 SPSS的数据编辑窗口. 111.4.3 SPSS的结果输出窗口 151.5 本章小结 (18)第2章数据的基本操作 (19)2.1 建立数据文件 (19)2.1.1 输入数据建立数据文件 (19)2.1.2 直接打开其他格式的数据文件 (20)2.1.3 使用数据库查询建立数据文件 (21)2.1.4 导入文本文件建立数据文件 (22)2.2 编辑数据文件 (23)2.2.1 输入数据 (23)2.2.2 定义数据的属性 (24)2.2.3 插入或删除数据 (33)2.2.4 数据的排序 (34)2.2.5 选择个案 (35)2.2.6 转置数据 (38)2.2.7 合并数据文件 (38)2.2.8 数据的分类汇总 (44)2.2.9 数据菜单的其他功能.. 462.3 数据加工 (47)2.3.1 数据转换 (47)2.3.2 数据的手动分组(编码) (50)2.3.3 数据的自动分组(编码) (54)2.3.4 产生计数变量 (55)2.3.5 数据秩(序)的确定.. 572.3.6 替换缺失值 (59)2.4 数据文件的保存或导出 (61)2.4.1 保存数据文件 (61)2.4.2 导出数据文件 (62)2.5 本章小结 (62)第3章 SPSS基础统计描述 (63)3.1 数理统计量概述 (63)3.1.1 均值(Mean)和均值标准误差(S.E. Mea n) (63)3.1.2 中位数(Median) (64)3.1.3 众数(Mode) (64)3.1.4 全距(Range) (65)3.1.5 方差(Variance)和标准差(Standard Deviatio n) (65)3.1.6 峰度(Kurtosis)和偏度(Skewness).. 663.1.7 四分位数(Quartiles)、十分位数(Deciles)和百分位数(Percentiles) (66)3.2 数据描述 (67)3.3 频数分析 (69)3.4 探索分析 (73)3.5 交叉列联表分析 (78)3.6 比率分析 (84)3.7 P-P图和Q-Q图 (86)3.8 图表绘制 (89)3.8.1 条形图 (89)3.8.2 线图 (94)3.8.3 面积图 (96)3.8.4 饼形图 (98)3.8.5 高低图 (99)3.8.6 箱图 (101)3.8.7 直方图 (103)3.9 本章小结 (104)第4章 SPSS基础模块分析 (105)4.1 均值分析 (105)4.1.1 均值的计算公式 (105)4.1.2 均值分析菜单 (106)4.2 方差分析 (108)4.2.1 单因素方差分析 (109)4.2.2 其他方差分析 (113)4.3 参数检验 (116)4.3.1 单样本T检验 (117)4.3.2 其他参数检验 (119)4.4 非参数检验 (120)4.4.1 卡方检验 (121)4.4.2 其他非参数检验 (124)4.5 回归分析 (131)4.5.1 线性回归 (131)4.5.2 其他回归分析 (138)4.6 聚类分析 (146)4.6.1 两步聚类分析 (146)4.6.2 其他聚类分析 (152)4.7 判别分析 (154)4.7.1 判别的函数公式 (155)4.7.2 判别分析的菜单 (155)4.8 因子分析与主成分分析 (161)4.8.1 因子分析 (161)4.8.2 主成分分析 (166)4.9 时间序列分析 (167)4.9.1 定义日期变量 (168)4.9.2 创建时间序列 (169)4.9.3 填补缺失数据 (171)4.9.4 时间序列分析 (171)4.10 生存分析 (172)4.10.1 寿命表分析 (173)4.10.2 其他生存分析 (174)4.11 相关分析 (176)4.11.1 简单相关分析 (176)4.11.2 散点图 (181)4.11.3 偏相关分析 (184)4.12 信度分析 (186)4.12.1 信度分析概述 (187)4.12.2 SPSS信度分析 (189)4.12.3 信度分析的其他问题 (192)4.13 本章小结 (197)第二篇 SPSS 17统计分析应用实例第一部分调查统计第5章调查统计入门实例 (203)5.1 硬币均匀性判断 (203)5.1.1 实例内容说明 (203)5.1.2 实现方法分析 (204)5.1.3 具体操作步骤 (204)5.2 使用回归分析判断住房与收入的关系 (207)5.2.1 实例内容说明 (207)5.2.2 实现方法分析 (208)5.2.3 具体操作步骤 (208)5.3 不同性别同学成绩的均值和方差分析 (216)5.3.1 实例内容说明 (216)5.3.2 实现方法分析 (216)5.3.3 具体操作步骤 (216)5.4 本章小结 (220)第6章调查统计提高实例 (221)6.1 学生身高的探索性分析 (221)6.1.1 实例内容说明 (221)6.1.2 实现方法分析 (222)6.1.3 具体操作步骤 (222)6.2 使用对数线性模型分析骨折资料 (229)6.2.1 实例内容说明 (229)6.2.2 实现方法分析 (229)6.2.3 具体操作步骤 (230)6.3 培训班学习成绩的显著性分析 (237)6.3.1 实例内容说明 (237)6.3.2 实现方法分析 (238)6.3.3 具体操作步骤 (238)6.4 本章小结 (241)第7章调查统计经典实例 (243)7.1 学习成绩的聚类分析 (243)7.1.1 实例内容说明 (243)7.1.2 实现方法分析 (243)7.1.3 具体操作步骤 (244)7.2 身体生长发育指标的地区显著性差异判断 (251)7.2.1 实例内容说明 (251)7.2.2 实现方法分析 (252)7.2.3 具体操作步骤 (252)7.3 复习时间和考试成绩的关系判断 (262)7.3.1 实例内容说明 (262)7.3.2 实现方法分析 (263)7.3.3 具体操作步骤 (263)7.4 本章小结 (266)第二部分市场研究第8章市场研究入门实例 (269)8.1 机电产品销售额的影响因素分析 (269)8.1.1 实例内容说明 (269)8.1.2 实现方法分析 (270)8.1.3 具体操作步骤 (270)8.2 消费支出与可支配收入的线性回归分析 (276)8.2.1 实例内容说明 (276)8.2.2 实现方法分析 (277)8.2.3 具体操作步骤 (277)8.3 商品的季节性分析 (289)8.3.1 实例内容说明 (289)8.3.2 实现方法分析 (290)8.3.3 具体操作步骤 (290)8.4 本章小结 (300)第9章市场研究提高实例 (301)9.1 保险公司革新速度与规模及其类型间的关系分析 (301)9.1.1 实例内容说明 (301)9.1.2 实现方法分析 (302)9.1.3 具体操作步骤 (302)9.2 不同厂家同种产品的质量分析 (313)9.2.1 实例内容说明 (313)9.2.2 实现方法分析 (314)9.2.3 具体操作步骤 (314)9.3 合成纤维的强度与拉伸倍数的关系分析 (318)9.3.1 实例内容说明 (318)9.3.2 实现方法分析 (319)9.3.3 具体操作步骤 (319)9.4 本章小结 (325)第10章市场研究经典实例 (327)10.1 灯丝不同的灯泡的使用寿命分析 (327)10.1.1 实例内容说明 (327)10.1.2 实现方法分析 (327)10.1.3 具体操作步骤 (328)10.2 不同商品的消费者满意度分析 (336)10.2.1 实例内容说明 (336)10.2.2 实现方法分析 (337)10.2.3 具体操作步骤 (337)10.3 顾客对不同款式衬衣喜爱程度的分析 (344)10.3.2 实现方法分析 (344)10.3.3 具体操作步骤 (344)10.4 本章小结 (348)第三部分企业/政府数据分析第11章企业/政府数据分析入门实例 (351)11.1 儿童身高数据频数分析 (351)11.1.1 实例内容说明 (351)11.1.2 实现方法分析 (352)11.1.3 具体操作步骤 (352)11.2 百姓对奥运会评价的方差分析 (360)11.2.1 实例内容说明 (360)11.2.2 实现方法分析 (361)11.2.3 具体操作步骤 (361)11.3 居民交通工具使用情况的回归分析 (369)11.3.1 实例内容说明 (369)11.3.2 实现方法分析 (370)11.3.3 具体操作步骤 (370)11.4 本章小结 (377)第12章企业/政府数据分析提高实例 (379)12.1 卫生部门对居民寿命情况的分析 (379)12.1.1 实例内容说明 (379)12.1.2 实现方法分析 (379)12.1.3 具体操作步骤 (380)12.2 农作物产量与降水量和平均温度的相关性分析 (386)12.2.1 实例内容说明 (386)12.2.3 具体操作步骤 (387)12.3 加强体育锻炼与增强身体素质的关系分析.. 39012.3.1 实例内容说明 (390)12.3.2 实现方法分析 (390)12.3.3 具体操作步骤 (391)12.4 本章小结 (394)第13章企业/政府数据分析经典实例 (395)13.1 当代大学生价值观的因子分析 (395)13.1.1 实例内容说明 (395)13.1.2 实现方法分析 (396)13.1.3 具体操作步骤 (397)13.2 职业女性家庭特征资料的信度评价 (404)13.2.1 实例内容说明 (404)13.2.2 实现方法分析 (405)13.2.3 具体操作步骤 (405)13.3 对国内生产总值和零售总额之间的关系分析 (412)13.3.1 实例内容说明 (412)13.3.2 实现方法分析 (413)13.3.3 具体操作步骤 (414)13.4 本章小结 (420)第四部分医学统计分析第14章医学统计分析入门实例 (423)14.1 血红蛋白值描述性统计分析 (423)14.1.1 实例内容说明 (423)14.1.2 实现方法分析 (424)14.1.3 具体操作步骤 (424)14.2 环氯胍的半数致死剂量计算 (428)14.2.1 实例内容说明 (428)14.2.2 实现方法分析 (429)14.2.3 具体操作步骤 (429)14.3 发硒与血硒的相关分析 (435)14.3.1 实例内容说明 (435)14.3.2 实现方法分析 (436)14.3.3 具体操作步骤 (436)14.4 本章小结 (439)第15章医学统计分析提高实例 (441)15.1 用统计图描述血压状态与冠心病的关系 (441)15.1.1 实例内容说明 (441)15.1.2 实现方法分析 (441)15.1.3 具体操作步骤 (442)15.2 判断红细胞计数的频数是否呈正态分布 (448)15.2.1 实例内容说明 (448)15.2.2 实现方法分析 (448)15.2.3 具体操作步骤 (449)15.3 胃癌患者发生术后院内感染的影响因素分析 (452)15.3.1 实例内容说明 (452)15.3.2 实现方法分析 (453)15.3.3 具体操作步骤 (453)15.4 本章小结 (462)第16章医学统计分析经典实例 (463)16.1 不同治疗方案的生存率分析 (463)16.1.1 实例内容说明 (463)16.1.2 实现方法分析 (464)16.1.3 具体操作步骤 (465)16.2 不同制剂的药效分析 (473)16.2.1 实例内容说明 (473)16.2.2 实现方法分析 (473)16.2.3 具体操作步骤 (474)16.3 同种药物在不同治疗阶段的药效分析 (481)16.3.1 实例内容说明 (481)16.3.2 实现方法分析 (481)16.3.3 具体操作步骤 (483)16.4 本章小结 (487)《SPSS 17中文版统计分析典型实例精粹》:以经典统计学软件SPSS 17中文版为写作平台,提供软件命令的中英对照基础篇学习软件基本操作和统计描述知识,实例篇详解案例应用原理、流程和操作技巧36个实例典型、丰富,涉及调查统计、市场研究、企业/政府数据分析和医学统计领域循序渐进、由浅入深,围绕SPSS应用的原理、流程和操作技巧娓娓阐述插图:1.3 SPSS的运行方式SPSS提供了三种基本的运行方式:完全窗口菜单运行方式、程序运行方式和批处理方式。
SPSS 神经网络TM17.0 – 说明书
建立预测模型的新工具
您的组织需要从复杂多变的业务中发现潜在的模式和联系,做出更好的决定。
您可能正在使用SPSS Statistics Base 和它的一个或者几个附加模块来帮助您做这些事情。
如果这样,您已经知道了它的强大和多功能性。
但是,您可以做得更多。
使用SPSS神经网络,可以帮助您探索数据中微妙或者隐藏的模式。
这个附加模块可以帮助您发现数据中更复杂的关系,产生更有效果的预测模型。
SPSS神经网络是对SPSS Statistics Base以及附加模块中传统统计方法的一个补充。
您可以使用SPSS神经网络发现数据中间的新关系,然后用传统的统计技术检验其显著性。
SPSS神经网络可以仅仅作为客户端软件安装,但是为了得到更好的性能和扩展性,它也可以与SPSS Statistics Base Sever一起作为Client/Server安装。
为什么要使用神经网络?
神经网络是一个非线性的数据建模工具集合,它包括输入从始至终控制整个过程
SPSS神经网络,包括多层感知器(MLP)或者径向基函数(RBF)两种方法。
这两种方法都是有监督的学习技术-也就是说,他们根据输入的数据映射出关系。
这两种方法都采用前馈结构,意思是数据从一个方向进入,通过输入节点、隐藏层最后进入输出节点。
你对过程的选择受到输入数据的类型和网络的复杂程度的影响。
此外,多层感知器可以发现更复杂的关系,径向基函数的速度更快。
MLP可以发现更复杂的关系,而通常来说RBF更快。
使用这两种方法的任何一种,您可以将数据拆分成训练集、测试集、验证集。
训练集用来估计网络参数。
测试集用来防止过度训练。
验证样本用来单独评估最终的网络,它将应用于整个数据集和新数据。
在多层感知(MLP)对话框中,你可以选择你想包含用神经网络技术探索数据的结果可以用多种图形格式
所示的多层感知器,数据前馈式通过输入层、隐藏层传递到输出层。
■ 选项“结构”用来设置神经网络的结构,您可以设定:
– 是否使用自动选择结构– 神经网络的隐藏层个数
– 隐藏层单元之间的激活函数(双曲函数或者S 型函数)– 输出层单元之间的激活函数(标识,双曲, S 型, SoftMax 函数)
特性
多层感知器(MLP)
MLP 通过多层感知器来拟和神经网络。
多层感知器是一个前馈式有监督的结构。
它可以包含多个隐藏层。
一个或者多个因变量,这些因变量可以是连续型、分类型、或者两者的结合。
如果因变量是连续型,神经网络预测的连续值是输入数据的某个连续函数。
如果因变量是分类型,神经网络会根据输入数据,将记录划分为最适合的类别。
■ 预测
– 因子– 协变量
■ 选项“除外”列出MLP 中需要排除的因子或者协变量。
当
因子或者协变量包含大量的变量时,这个选项很有用。
■ 选项“缩放” 对协变量和因变量进行变换
– 因变量 (如果需要变换):标准化,正态化,调整的正态化,或者无
– 协变量:标准化,正态化,调整的正态化,或者无
■ 选项“拆分”用来设定对当前活动数据集的拆分方法。
训练样本用来训练神经网络、测试集是一个独立的数据集,用来跟踪预测无法来防止过度训练。
验证集是另外一个独立的数据集,用来评估最后的神经网络。
您可以设定:
– 相对记录数来随机分配训练样本
– 预测值或者分类– 预测的伪概率
■ 选项“输出文件”将神经网络的结构输出保存成包含突
触权重的XML 格式。
径向基函数(RBF)
RBF 程序拟和一个前馈型、有监督学习的径向基函数网络,包括输入层、隐藏层(也就是径向基函数层)、输出层。
输入向量通过隐藏层传递到径向基函数。
类似MLP ,RBF 可以进行预测和分类。
RBF 程序分两个阶段训练网络:
1.程序通过聚类方法确定径向基函数。
以及每个径 向基
函数的中心和宽度。
2.估计径向基函数的连接权重。
在预测和分类中都使用激
活函数作为均方误差函数。
使用普通最小二乘方法求均方误差的最小值。
由于RBF 训练过程分两个阶段,因此,一般情况下,RBF 网络的训练速度优于MLP 。
■ 选项“停止训练”决定神经网络停止训练的规则。
您可
以设置:
– 预测误差下降的次数 – 训练时间或者最大训练时间– 最大收敛次数– 训练误差的相对变化率– 训练误差率准则
■ 选项“缺失”用来控制分类变量(因子和分类因变量)
的缺失值是否被作为有效值使用。
■ 选项“打印”指定输出内容,也可以请求一个敏感性分析。
您可以设置:– 处理过程设置概要
– 神经网络的基本信息,包括因变量、输入和输出单元个数、隐藏层单元个数、激活函数
– 神经网络输出结果的概要信息,包括:总体平均误差、停止规则、训练时间– 每个分类因变量的分类表
系统需求
■ 软件:SPSS Statistics Base 17.0■ 其他系统需求根据平台有所不同
MLP 和RBF 的选项基本相同,除了以下几个:
■ 如果使用“结构”选项,用户可以指定隐藏层的高斯径
基函数:标准RBF 或者普通RBF
■ 当使用“准则”选项时,用户可以指定RBF 的计算参数,
指定隐藏层单元的交叠方式。