数学统计关于北京雾霾的统计
- 格式:ppt
- 大小:291.50 KB
- 文档页数:9


三种霾日统计方法的比较分析——以环首都圈京津冀晋为例三种霾日统计方法的比较分析——以环首都圈京津冀晋为例近年来,空气污染问题日益严重,尤其是大城市和发达地区更是饱受雾霾困扰。
为了更好地了解雾霾的形成机制和影响因素,科研人员提出了多种统计方法。
本文将以中国环首都圈京津冀晋地区为例,对其中的三种统计方法进行比较分析。
一、移动平均法移动平均法是一种常见的天气现象统计方法,适用于分析霾日的演变趋势。
该方法的原理是计算一定时间段内的平均数据,从而观察霾日的变化规律。
在环首都圈京津冀晋地区,常用的时间段包括月平均、季度平均和年平均。
优点是简单易懂,能直观地展现霾日的整体情况。
缺点是无法突出霾日发生的具体时间段,只能呈现平均情况。
二、特大雾霾事件统计法特大雾霾事件统计法是一种对特定时间段内的雾霾事件进行统计的方法。
这种方法适用于短期内雾霾特别严重的情况,能够提供霾日的具体数量和发生时间。
在环首都圈京津冀晋地区,特大雾霾事件统计法常用于统计每年春季和冬季的雾霾情况,特别是十一假期和寒假期间。
优点是能够准确统计雾霾事件的数量和持续时间,有助于制定相关的防控措施。
缺点是无法全面反映霾日的分布情况,只能对特定时间段内的情况进行分析。
三、霾日频次统计法霾日频次统计法是一种对一定时间范围内每日的霾情况进行统计的方法。
该方法适用于长期时间内霾日的分布情况分析,能够掌握不同季节、不同区域的霾日频次变化规律。
在环首都圈京津冀晋地区,霾日频次统计法常用于分析不同季节对环境的影响。
优点是能够全面把握不同季节、不同地区的霾日情况,有助于制定综合性的防控策略。
缺点是对于特大雾霾事件的分析无能为力,只能得到整体的数据。
综上所述,在环首都圈京津冀晋地区的雾霾统计中,三种方法各有其优势和局限性。
移动平均法能够反映雾霾的整体变化趋势,特大雾霾事件统计法能够强调特定时间段内的情况,而霾日频次统计法能够全面了解不同季节、不同地区的变化规律。
科研人员和政府决策者应根据需求选用合适的统计方法,综合考虑数据的准确性、可靠性和实用性。

北京PM2.5数据分析处理张奕辰【摘要】PM2.5是地球大气成分中含量很少的组分,但它对空气质量和能见度等有重要的影响.与较粗的大气颗粒物相比,PM2.5粒径小,面积大,活性强,易附带有毒、有害物质(例如,重金属、微生物等),且在大气中的停留时间长、输送距离远,因而对人体健康和大气环境质量的影响更大.因此,通过对PM2.5浓度的分析处理,能够作为判定空气污染程度的一个重要指标,从而能够为雾霾的防治起到参考作用.【期刊名称】《化工中间体》【年(卷),期】2017(000)010【总页数】4页(P77-80)【关键词】PM2.5;建模分析;数据处理【作者】张奕辰【作者单位】陕西省西安中学陕西 710000【正文语种】中文【中图分类】X1.概述(1)背景雾霾天气是一种大气污染状态,雾霾是对大气中各种悬浮颗粒物含量超标的笼统表述,尤其是PM2.5被认为是造成雾霾天气的“元凶”。
随着空气质量的恶化,阴霾天气现象出现增多,危害加重。
中国不少地区把阴霾天气现象并入雾一起作为灾害性天气预警预报。
统称为“雾霾天气”。
本文将以北京为例,对PM2.5浓度进行时间序列分析,以期对PM2.5的数据进行预测。
(以上概念来自百度百科“雾霾”及百度百科“细颗粒物”)(2)可行性分析①研究PM2.5浓度问题的必要性:空气污染问题的现实意义。
随着现代工业化进程的推进和人民生活水平的提高,人们对环境质量的要求和工业化加速的环境代价之间的矛盾日益突出,其中又尤以空气污染问题最为迫切。
这严重限制了我国经济社会可持续发展,因此,可以通过对PM2.5数据的研究,抛砖引玉,一方面提起对空气污染问题的重视,另一方面为解决这一问题提供具体数据,推动环境友好型资源节约型社会的发展。
②研究PM2.5浓度问题的可行性:近年来关于PM2.5浓度的数据集日趋完善,给研究这一问题提供了极大的方便;有了具体的数据,可以应用时间序列相关的知识进行研究,把实际问题转化成数学模型,找到数据中隐含的信息;充分挖掘信息,并进行深入分析,可以得出适应性较好的模型和一系列结论。
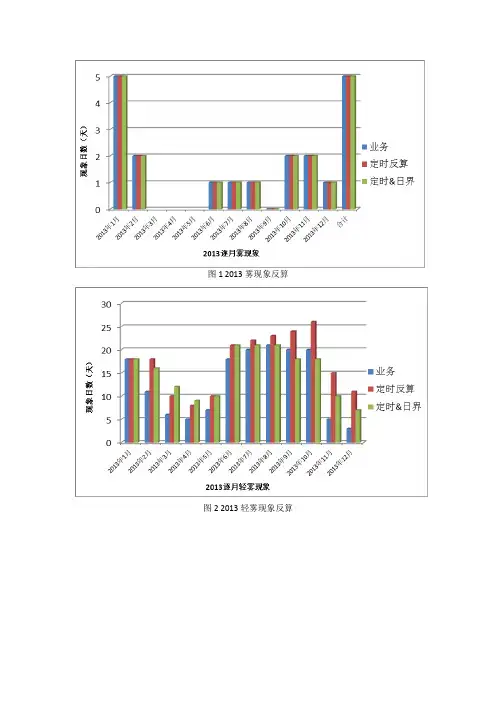
图1 2013雾现象反算
图2 2013轻雾现象反算
图3 2013霾现象反算
图4 轻雾&霾现象年统计及与2012对比
图5 轻雾&霾现象201301-201308统计与及2012同期对比
反算方法:
1.雾现象不论持续时长,均认为正确
2.对于轻雾、霾现象:人工观测记录,基准、基本站按8次定时观
测,考虑转日界符合工作实际
3.对于轻雾、霾现象:自动观测记录,将8次定时每日轻雾或霾现
象出现连续两个定时或累计3个定时以上(含3个)的计为1现象日
长Z修正:
1.根据反算技术方案提取定时时次相应记录(能见度、相对湿度、
CW天气现象、MW段),CW段现在天气现象编码为04、06-10、31—49的均保留;根据技术方案,修正CW段天气现象编码记录;
提取各定时MW段记录,保留原始长Z文件
2.人工审验提取的定时记录,修正逐日天气现象记录(相当于修正A
文件逐日天气现象),重点考虑轻雾、霾现象转日界以及降水类现象影响
3.修正CW段“现在天气现象编码”,对于非定时正点长Z文件,均
置为“//”,对于定时长Z文件,根据第1步技术方案中除05改为10外,其他编码全部保留(保留更多的原始记录)。
根据修正的逐日天气现象,重写所有时次长Z文件的MW字段;重写所有时次长Z文件更正标识由000改为CCZ。

鲁东大学数学与统计科学学院2015-2016学年第一学期《统计案例分析》课程论文A卷课程号:210030155任课教师刘全辉成绩气象因子对北京市雾霾天气影响的统计分析摘要:雾霾天气是一种十分重要的城市气候灾害,雾霾会对大气环境产生副作用,严重的雾霾甚至还会影响到人们的身体健康、交通出行安全及农业生产。
本文根据2010年—2013年北京市连续3个冬季气象数据和空气污染物监测数据,分析了北京市雾霾天气与气象因子(主要是温度、相对湿度、风速等)之间的相关关系。
分析结果表明空气温度、相对湿度和风速是影响雾霾天气形成的重要气象要素。
较高的空气相对湿度和低风速不但促进雾霾天气的形成,而且是导致持续性雾霾天气的主要原因。
利用判别分析方法导出了气象因子与雾霾关系的判别函数模型,为用气象数据判别雾霾提供了方法。
关键词:雾霾;AQI;空气相对湿度;温度;风速;判别函数模型一:前言随着经济发展和城市化进程的加快及机动车保有量的迅速增加,向大气排放的污染物也不断增多,导致大气污染日趋严重,雾霾天气增多,2013年1月份北京经历了几十年来最为严重的雾霾天气。
雾霾天气不但给人们带来了极大的交通不便和危险,而且造成了严重的环境污染,影响健康(Schwartz等,1996),成为北京人民普遍关注的热点问题之一(周涛和汝小龙,2012)。
在交通出行方面,雾霾形成后,大气能见度明显降低,极易引发交通事故。
据北京市交通局统计,仅仅是2013年1月31日的半天时间北京市就发生了2000多起交通事故,造成了多人受伤,二人死亡和巨大的财产损失。
这种恶劣的天气环境不仅仅只会给人们的出行造成麻烦,还会对人们的健康安全造成极大的威胁(Ostro等,1999)。
在今年一月份连续四次的雾霾天气过程中,北京市各大医院急诊患者中,呼吸道感染患者比例也开始同比上升。
北京市疾病控制中心的统计结果显示:1月5日至11日期间,仅北京市儿童医院日急诊量最高峰就曾达到9000多人次,呼吸道感染占到内科病人的50%左右。


数学统计关于北京雾霾的统计雾霾是一个全球性问题,严重影响着人们的生活和健康。
作为中国首都,北京也经历了多次严重的雾霾污染事件。
本文将通过数学统计的方法,对北京雾霾污染进行一次深入分析和研究,以期找出其中的规律和趋势,为改善空气质量提供参考。
一、数据收集在进行数学统计之前,首先需要收集与北京雾霾有关的数据。
我们选择了以下几个指标来进行统计分析:1. PM2.5浓度:PM2.5是颗粒物的一种,其直径小于等于2.5微米。
测量PM2.5浓度是衡量空气质量的重要指标。
2. AQI指数:AQI(Air Quality Index)是衡量空气质量的综合指数,常见于气象预报和环境监测。
3. 可见度:由于雾霾天气会导致空气中颗粒物的增多,可见度会受到较大影响。
4. 风速和风向:风速和风向对空气污染的扩散具有重要影响。
收集过程中,我们从北京市環境保護局、气象局和其他相关机构获取了每日的监测数据,并将其整理为数据表格,以便后续分析。
二、数据分析在收集到数据之后,我们可以运用数学统计方法对数据进行分析。
1. 雾霾事件频率分析首先,我们可以对雾霾事件的频率进行分析。
通过统计每年、每月或每周雾霾事件的发生次数,我们可以了解到雾霾的季节性变化和趋势。
2. 污染指标的统计分析我们可以计算出PM2.5浓度、AQI指数和可见度的平均值、最大值和最小值,以及它们的变异系数和标准差等。
这些指标可以帮助我们更好地了解雾霾污染的严重程度和变化趋势。
3. 风速和风向的影响分析风速和风向是影响雾霾扩散的重要因素。
我们可以通过分析风速和风向与PM2.5浓度之间的相关性,来研究雾霾的来源和传播路径。
三、统计结果与讨论通过对数据进行分析,我们得出了以下几个结论:1. 雾霾事件在冬季和春季较为频繁,其中冬季更为严重。
2. PM2.5浓度和AQI指数在雾霾事件期间明显升高,可见度显著下降。
3. 风速较低和风向静稳时,雾霾问题更为严重,说明本地污染物扩散能力较差。

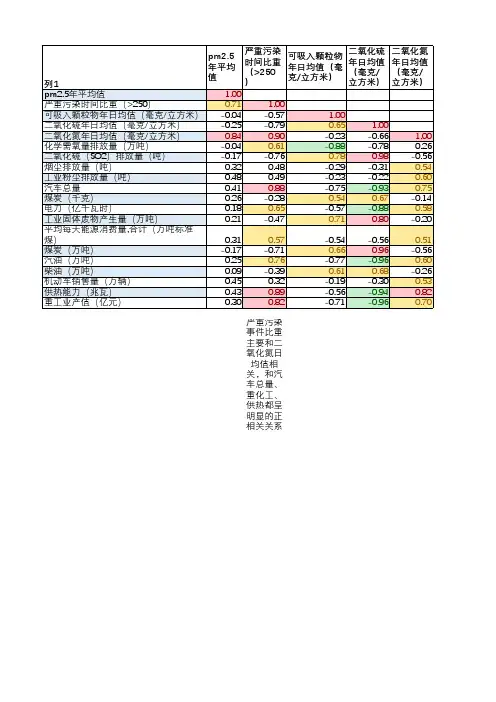
雾霾、PM2.5以及相关问题研究模型摘要本文通过搜集样本数据,建立层次分析模型,对影响北京PM2.5指标的主要因素进行研究。
构建二重趋势组合预测模型,实现PM 2.5 的预测及报警。
问题一:结合单项污染指数法和内梅罗综合指数法,评价PM 2.5 污染程度。
结果表明PM2.5 超标天数达68.5% ,与所给照片雾霾天数比例趋近,由此判定照片真实。
问题二:应用层次分析法,以矩阵形式C = (C ij ) n ×n 表达每一层各因素对上层某因素的相对重要性,采用排序向量公式:11 1 w i =− +n∑ r ikn 2a na k =1得出PM 2.5 影响因素重要性排序为:工业、日常生活;发电;车辆、船舶、飞机尾气;农作物燃烧;外来排放。
问题三:以所搜集样本数据,构建基于G M (1,1) 、BP 神经网络、AR IM A 的二重趋势时间序列组合预测模型:y ˆ s (k) = a + b BP y ˆ BP (k) + b ARIMA y ˆ ARIMA (k )y ˆ(k)=y ˆs (k)y ˆGM (k)+ε(k)对模型检验后,确定最优模型为二重趋势组合预测模型。
利用所建立模型,对北京地区PM2.5 预测并与实际数据对比分析。
问题四:对PM 2.5 所造成的雾霾天气,PM 2.5 的成因分析及所构建的预测 报警机制,向有关部门提出控制PM 2.5 排放的相关建议。
关键词:内梅综合指数法层次分析模型灰色预测模型 BP 神经网络ARIMA 模型组合模型i i 一、问题的提出进入 2 0 1 3 年以来,雾霾天气一直影响着北方地区,给人们的生活与出行带来诸多不便。
1 . 查找北京相关时间段内的PM 2.5 数据,建立相应的数学模型,分析图中照片的真实性;2 . 分析影响北京PM 2.5 指标的主要因素;PM 2.5 与雾霾天气之间的关系;3 . 建立PM 2.5 的预测及报警机制。
4 . 在报告的最后,请给有关部门写一封信,在信中阐述你的观点,提出你的建议或者是减少PM 2.5 的改进方案等。

数学统计关于北京雾霾的统计北京雾霾的统计数据表明,这个城市的空气质量问题严重。
根据最新的研究,雾霾是由大气中的颗粒物和有害气体污染物形成的。
下面将详细讨论北京雾霾的统计数据以及对该问题的深入分析。
根据北京市环境保护局的数据,每年有大约200多天的时间北京的空气质量不达标。
这主要是由于细颗粒物(PM2.5)和可吸入颗粒物(PM10)的浓度过高。
PM2.5是指直径小于等于2.5微米的颗粒物,PM10则是指直径小于等于10微米的颗粒物。
这些颗粒物可以导致空气污染并对人体健康产生严重影响。
北京的雾霾问题与多个因素密切相关。
首先,巨大的人口数量和车辆密度是主要的因素之一。
北京是一个人口密集的城市,同时也是中国最大的汽车消费市场之一。
大量的车辆排放物质进入大气,导致了空气污染的加剧。
其次,工业活动也是雾霾问题的一个重要原因。
北京周边地区有多个工业区,这些工业活动产生大量的废气和颗粒物排放,严重影响了空气质量。
还有,天气条件也会对雾霾形成起到重要影响。
北京的冬季是雾霾问题最为严重的时候,主要是由于温度、湿度和风速组合的原因。
冷空气会造成逆温层,使得颗粒物在低层大气中停留,无法有效扩散,从而导致雾霾天气的形成。
在对北京的雾霾问题进行深入分析时,可以提供一些相关的实例。
例如,可以引用过去几年来北京市空气质量指数(AQI)的数据,以展示雾霾问题的严重性。
还可以列举一些雾霾天气对居民健康的影响,如呼吸系统问题和心血管疾病的增加。
此外,为了解决北京的雾霾问题,政府、企业和居民都采取了一系列措施。
政府实施了一些具有挑战性的政策,如限制工业排放、减少车辆尾气排放以及推广清洁能源。
此外,还成立了多个环保组织来推动研究和监测雾霾问题。
最后,需要指出的是,解决雾霾问题需要国际合作。
因为雾霾并不仅仅是北京的问题,而是全球各地都面临的挑战。
国际社区应共同努力,分享经验和技术,共同应对雾霾问题。
总结起来,北京的雾霾问题严重,主要是由于细颗粒物和可吸入颗粒物的浓度过高。

KNN数据开掘算法在北京地区霾等级预报中的应用在现代社会里,空气污染已成为严峻的环境问题之一,尤其在高度城市化的地区,如北京。
北京地区的空气质量受到了大量的关注,尤其是霾天气的频繁出现,给人们的生活和健康带来了严峻的影响。
因此,准确猜测霾天气的发生和等级对于实行相应的应对措施至关重要。
近年来,数据开掘算法在猜测和预警领域的应用越来越广泛。
其中,K最近邻(K-Nearest Neighbor,简称KNN)算法因其简易易用,且能够依据历史数据进行分类和猜测的特点,被广泛应用于各种领域。
本文将探讨KNN数据开掘算法在北京地区霾等级预报中的应用。
一、KNN算法简介KNN算法是一种监督进修的分类算法。
该算法的核心思想是,若果一个样本在特征空间中的K个最邻近样本中的大多数属于某一个类别,那么该样本也属于这个类别。
换言之,KNN 算法通过计算距离来确定待分类样本所属的类别。
KNN算法的主要步骤如下:1. 计算待分类样本与全部训练样本之间的距离;2. 选择K个最近邻样本;3. 统计K个最近邻样本中各类别的数量;4. 将待分类样本归类到数量最多的类别中。
二、数据收集和预处理在应用KNN算法进行霾等级预报时,起首需要收集大量的历史气象和空气质量数据。
这些数据包括不同时期的PM2.5、PM10、AQI指数,天气状况、风向、风速等信息。
这些数据可以通过监测站点、气象台等渠道得到。
在数据预处理阶段,需要对原始数据进行清洗和处理。
起首,将缺失值和异常值进行处理;其次,对连续型数据进行离散化处理,转换为符合KNN算法要求的离散型数据;最后,对数据进行归一化,以消除不同量纲的影响。
三、特征选择和模型训练在特征选择阶段,需要依据实际状况筛选出对霾等级猜测有较大影响的特征。
依据阅历或领域知识,可以选择PM2.5、风向、风速等作为输入特征。
在模型训练阶段,可以接受交叉验证的方法将数据集分为训练集和测试集。
通过调整K值,选择合适的K值,以使得猜测结果更加准确。
五年级数学综合实践活动设计用统计图表达空气质量变化2018年7月,国务院颁布了《打赢蓝天保卫战三年行动计划》。
北京市积极响应,聚焦移动源、扬尘源、生产生活源等重点污染源,深化秋冬季大气污染防治攻坚,人们普遍感觉到雾霾天数明显减少。
请用统计图表达空气质量是否得到改善。
01.活动说明本活动可以通过主题活动的方式进行,让学生经历设计方案、收集数据、整理和表达数据的全过程,感受数据蕴含着信息以及如何提取信息,发展数据意识。
这样的活动适合第三学段学生,具体可作如下设计。
(1)自主设计方案。
分组实施,启发学生广开思路,设计收集数据的方案。
显然方案有多种:把2018年某月的空气质量情况,先按照污染程度分类,计算各类别的天数,然后分别计算2019年和2020年这个月份的相应数据,进行比较,判断空气质量是否得到改善;也可以先按污染程度分类,分别计算每年中各类别的天数,然后进行比较:还可以计算一年中空气质量优良的天数并进行比较:等等。
引发学生对不同方案展开讨论,最终形成小组意见。
在这样的过程中,培养学生的交流能力。
(2)实施设计方案。
每个小组按照自己设计的方案,收集、整理和表达数据。
学生可以查阅相关图书,也可以通过网络查询,培养获取数据的能力;对获取的数据进行整理,尝试用各种统计图表达整理后的数据,在尝试的过程中体会各种统计图的功能,知道对于这类与过程有关的数据,用复式条形统计图或折线统计图表达的合理性;借助统计图对空气质量的变化进行分析。
在这样的过程中,培养学生的推理意识,让学生感悟如何用数学的语言表达现实世界。
(3)组织学生进行小组汇报,分析各自小组的设计思路、数据收集过程、构建统计图的理由、最终的结论,让学生体会数据收集、整理和分析的现实意义,提升数据意识。
02.教学设计一、创设情境,导入新知:1、谈话师:同学们,某学校每年的春天和秋天,学校都要组织大家一起春游和秋游,通过春游和秋游活动,不但可以培养同学们的观察能力,体验大自然的美,而且能增多同学们的知识面.你除了学校组织的春游和秋游到过少许比较近的地方。
三种霾日统计方法的比较分析——以环首都圈京津冀晋为例三种霾日统计方法的比较分析——以环首都圈京津冀晋为例近年来,随着环境问题的日益突出,空气污染已成为人们普遍关注的焦点之一。
在环首都圈京津冀晋地区,雾霾天气频繁出现,给人们的生活和健康带来了严重的影响。
为了更好地了解和研究霾日的时空分布规律,科研人员提出了多种霾日统计方法。
本文将比较分析三种常用的霾日统计方法,以期为环首都圈的霾日监测和预警提供科学依据。
首先,我们来介绍一下三种霾日统计方法。
第一种是根据PM2.5浓度超标的天数进行统计,这是目前最常用的方法之一。
通过设定PM2.5浓度的标准值,比如国家标准为35微克/立方米,将超过该标准值的天数定义为霾日。
第二种方法是根据能见度风险等级进行统计。
该方法根据能见度的不同等级划分,比如根据能见度小于500米、500-1000米、1000-2000米等三个等级,统计霾日的发生频次。
第三种方法则是根据空气质量指数(AQI)进行统计。
AQI是根据环境空气质量状况和对人体的影响,将空气质量分为六个等级,通过统计不同等级的天数来估计霾日的发生情况。
接下来,我们将对这三种统计方法进行比较分析。
首先是数据来源的差异。
PM2.5浓度超标统计方法主要需要依赖空气质量监测站采集的空气质量数据,而能见度风险等级和AQI统计方法则需要同时获取相应的能见度数据和AQI数据。
由于监测站的分布有限,可能无法覆盖整个研究区域,从而可能会导致数据的不完整性。
其次是统计结果的不同。
PM2.5浓度超标统计方法给出的是具体的超标天数,能够直观地反映霾日的发生频次。
而能见度风险等级和AQI统计方法给出的是不同等级的天数,无法直接得知超标情况的具体天数。
最后是方法的灵活性和适用性。
PM2.5浓度超标统计方法相对简单,容易实施,但只能反映空气中特定污染物的含量。
能见度风险等级和AQI统计方法则同时考虑了多种污染物的影响,能够综合评估空气质量状况,但需要相应的数据支持,并且需要设置一定的阈值来划分等级。
数学统计关于北京雾霾的统计近年来,北京的雾霾问题一直备受关注和讨论。
数学统计作为一种科学方法,可以为我们提供对于雾霾问题的更深入的了解和分析。
本文将从数学统计的角度来探讨北京雾霾问题,并且分析其影响因素和解决方法。
首先,我们可以通过数学统计方法来对北京雾霾的频率进行分析。
统计数据显示,北京的雾霾现象日益凸显。
我们可以收集并统计过去几年雾霾的发生次数和持续时间,进而通过数学模型来预测未来雾霾的可能发生情况。
这种预测将为政府和居民提供重要的参考信息,以便他们能够采取相应的应对措施。
其次,数学统计还可以帮助我们分析雾霾的成因和影响因素。
通过收集和整理大量的气象数据和环境指标,我们可以建立数学模型来研究雾霾的形成机理。
例如,通过对空气中颗粒物、气象条件和排放源的监测与分析,可以建立起相关的统计模型,从而找到雾霾成因的规律和可能的解决方案。
另外,数学统计还可以帮助我们评估雾霾对人体健康的影响。
通过收集雾霾期间居民的健康数据,如呼吸系统疾病发病率、就诊人数等,我们可以利用统计学模型来分析雾霾与健康之间的关系,并量化雾霾对健康的危害程度。
这种分析结果可以提供给医疗机构和公众,以便采取适当的健康保护措施。
另外一个重要的方面是,数学统计能够帮助我们评估雾霾对经济的影响。
通过收集相关的经济数据,如交通状况、旅游业收入、工业生产等指标,我们可以建立经济模型,来研究雾霾对各个领域的经济损失。
这种分析可以为政府制定雾霾治理政策和措施提供重要的参考依据。
最后,数学统计还可以帮助我们寻找解决雾霾问题的方法。
通过对雾霾治理措施的效果进行统计评估,我们可以找到最有效的控制雾霾的方法。
例如,通过对不同城市雾霾治理措施的数据进行比较和分析,我们可以找到最佳的治理方案,以便将其应用到北京的雾霾治理中去。
综上所述,数学统计在解决北京雾霾问题中起着重要的作用。
通过数学统计的分析,我们可以更好地了解雾霾问题的成因和影响,评估其对人类健康和经济的影响,并寻找解决问题的最佳方法。
北京霾指数近年来,随着城市化进程的加快和工业化程度的提高,大气污染问题日益严重。
北京作为我国的首都,也备受关注。
其中,北京的霾天气尤为突出。
为了更好地反映北京的空气质量,北京市政府推出了“北京霾指数”。
一、“北京霾指数”是什么?北京霾指数指的是北京市空气中PM2.5浓度的24小时滑动平均浓度。
具体来说,就是通过监测北京市各区域内的PM2.5浓度,计算出24小时内的平均值,然后将其归一化,得到一个0~500的数值,这个数就是“北京霾指数”。
二、“北京霾指数”如何运用?1. 预警和应急措施:北京市政府每天会根据“北京霾指数”发布相应的预警和应急措施,如关闭工地或减少私家车出行。
2. 空气质量评价:北京霾指数是衡量北京市空气质量的重要指数。
根据国家环保部空气质量标准,0~50为优,51~100为良,101~150为轻度污染,151~200为中度污染,201~300为重度污染,大于300为严重污染。
如果“北京霾指数”超过了150,就说明空气质量开始出现问题。
3. 排放权交易:近年来,中国开始推动排放权交易市场。
排放权交易市场的运作需要大量的空气污染指数数据。
而在北京,就可以使用“北京霾指数”作为重要参考指标。
三、“北京霾指数”表现出来的问题1. 多地实施的空气质量评估标准不一:如“北京霾指数”超过150就说明空气质量开始出现问题,而在其他城市可能是100或120。
2. 目前只是表面治理:对于霾天气,采取的应对措施大多都是表面治理,如关闭工地、减少汽车行驶等,而对于治理大气污染根源的措施仍然较少。
3. 只能反映PM2.5:即使是“北京霾指数”,仍然仅仅反映了PM2.5浓度的情况,而并不能全面反映空气质量。
总之,“北京霾指数”是一项很好的空气质量数据指标。
但是,在使用和分析过程中,还是需要更多的注意和完善。
同时,应该加强治理大气污染源头的措施,做好空气质量的长期治理工作。
北京雾霾影响因素及其相关性分析——实际生活中的数学应
用
张行健;李新萍
【期刊名称】《中学生数理化:高考理化》
【年(卷),期】2017(0)9
【摘要】近几年来,北京雾霾天气频频发生,严重影响了人们的身体健康和生产生活,雾霾天气已经成为北京最重要的气象灾害。
本文针对北京雾霾天气,通过查阅大量资料数据和深入研究,概述了雾霾产生的原因、危害及其重要因子
PM2.5,分析了空气质量指数人QI、PM2.5的变化特征、并进行了PM2.5的相关性分析。
研究结果表明:PM2.5和空气质量指数AQI呈现相似的走势,有很强的相关性.,PM2.5与CO、NO2高度相关、与SO2中等相关;据此研究结果作为治理雾霾的一个依据和突破口,提出了相应的建议和措施,希望能对治理北京雾霾有所裨益。
【总页数】2页(P89-90)
【关键词】北京雾霾;PM2.5;相关性
【作者】张行健;李新萍
【作者单位】北京市八一学校2018届(1)班
【正文语种】中文
【中图分类】G633.6
【相关文献】
1.北京房山雾霾与GNSS水汽相关性分析 [J], 陈广鄂;卢茜;曾攀;韩建锋;吴德钊
2.风廓线雷达资料在北京秋季雾霾天气过程分析中的应用 [J], 花丛;刘超;张恒德
3.北京市雾霾的社会经济影响因素实证研究 [J], 李卫东;黄霞
4.基于污染物和气象要素的北京市雾霾影响因素分析 [J], 许昌日;朱法华;刘丹丹;史丽羽
5.北京雾霾污染影响因素实证分析 [J], 陈弄祺;许瀛
因版权原因,仅展示原文概要,查看原文内容请购买。