SMART技术检测磁盘故障参数
- 格式:docx
- 大小:39.91 KB
- 文档页数:20

硬盘SMART检测参数详解用户最不愿意看到的事情,莫过于在毫无警告的情况下发现硬盘崩溃了。
诸如RAID的备份和存储技术可以在任何时候帮用户恢复数据,但为预防硬件崩溃造成数据丢失所花费的代价却是相当可观的,特别是在用户从来没有提前考虑过在这些情况下的应对措施时。
硬盘的故障一般分为两种:可预测的〔predictable〕和不可预测的〔unpredictable〕。
后者偶而会发生,也没有方法去预防它,例如芯片突然失效,机械撞击等。
但像电机轴承磨损、盘片磁介质性能下降等都属于可预测的情况,可以在在几天甚至几星期前就发现这种不正常的现象。
对于可预测的情况,如果能通过磁盘监控技术,通过测量硬盘的几个重要的安全参数和评估他们的情况,然后由监控软件得出两种结果:“硬盘安全〞或“不久后会发生故障〞。
那么在发生故障前,至少有足够的时间让使用者把重要资料转移到其它储存设备上。
最早期的硬盘监控技术起源于1992年,IBM在AS/400计算机的IBM 0662 SCSI 2代硬盘驱动器中使用了后来被命名为Predictive Failure Analysis〔故障预警分析技术〕的监控技术,它是通过在固件中测量几个重要的硬盘安全参数和评估他们的情况,然后由监控软件得出两种结果:“硬盘安全〞或“不久后会发生故障〞。
不久,当时的微机制造商康柏和硬盘制造商希捷、昆腾以与康纳共同提出了名为IntelliSafe的类似技术。
通过该技术,硬盘可以测量自身的的健康指标并将参量值传送给操作系统和用户的监控软件中,每个硬盘生产商有权决定哪些指标需要被监控以与设定它们的安全阈值。
1995年,康柏公司将该技术方案提交到Small Form Factor(SFF)委员会进展标准化,该方案得到IBM、希捷、昆腾、康纳和西部数据的支持,1996年6月进展了1.3版的修正,正式更名为S.M.A.R.T.〔Self-Monitoring Analysis And Reporting Technology〕,全称就是“自我检测分析与报告技术〞,成为一种自动监控硬盘驱动器完好状况和报告潜在问题的技术标准。

了解电脑硬盘的SMART技术SMART(自我监测、分析和报告技术)是一种用于硬盘驱动器的监测和诊断功能,可以帮助用户及时了解硬盘的健康状况,以便采取预防措施或及时更换硬盘。
在本文中,我们将探讨SMART技术的背景、原理和作用,以及如何利用SMART工具来监测和维护硬盘。
一、SMART技术的背景介绍SMART技术是由硬盘制造商引入的一项先进功能,旨在提供硬盘驱动器的自我监测和预警机制。
在过去,当硬盘出现问题时,用户可能无法及时发现,直到硬盘彻底失效或丢失重要数据。
SMART技术的引入旨在改变这一现状,提供更准确、及时的硬盘健康状况报告。
二、SMART技术的原理SMART技术基于硬盘驱动器内置的传感器和自检功能,通过监测多个参数和指标来评估硬盘的健康状况。
这些参数包括温度、旋转速度、读写错误率、寻道时间、驱动器使用时间等。
通过对这些参数进行监测和分析,SMART技术可以提前预测硬盘故障的可能性,并发送警报,提醒用户备份数据或更换硬盘。
三、SMART技术的作用1. 提前发现硬盘问题:SMART技术可以对硬盘进行实时监测,当硬盘出现异常时,如读写错误率过高或温度超过安全范围,SMART会向用户发送警报。
通过这些警报,用户可以及时采取措施来避免数据丢失或硬盘故障。
2. 数据备份和恢复:SMART技术不仅可以监测硬盘的健康状况,还可以提供有关硬盘寿命和剩余寿命的报告。
这使用户能够根据硬盘的状态来制定数据备份计划,以防止重要数据的丢失。
此外,在更换硬盘时,SMART技术也可以帮助用户进行数据的迁移和恢复。
3. 保证系统稳定性:硬盘是计算机系统的关键组件之一,其稳定性对于计算机的性能和可靠性至关重要。
通过使用SMART技术,用户可以及时检测硬盘的健康状况,预防潜在的硬盘故障,从而确保计算机系统的稳定性和可靠性。
四、如何利用SMART工具进行硬盘监测和维护1. 安装SMART工具:SMART技术通常由硬盘制造商提供相应的软件工具,用户可以从官方网站下载并安装这些工具。

SMART技术检测磁盘故障参数SMART检测参数说明一般情况下,用户只要观察当前值、最差值和临界值的关系,并注意状态提示信息即可大致了解硬盘的健康状况。
下面简单介绍各参数的含义,以红色标出的项目是寿命关键项,蓝色为固态硬盘(SSD)特有的项目。
在基于闪存的固态硬盘中,存储单元分为两类:SLC(Single Layer Cell,单层单元)和MLC(Multi-Level Cell,多层单元)。
SLC成本高、容量小、但读写速度快,可靠性高,擦写次数可高达100000次,比MLC高10倍。
而MLC虽容量大、成本低,但其性能大幅落后于SLC。
为了保证MLC的寿命,控制芯片还要有智能磨损平衡技术算法,使每个存储单元的写入次数可以平均分摊,以达到100万小时的平均无故障时间。
因此固态硬盘有许多SMART参数是机械硬盘所没有的,如存储单元的擦写次数、备用块统计等等,这些新增项大都由厂家自定义,有些尚无详细的解释,有些解释也未必准确,此处也只是仅供参考。
下面凡未注明厂商的固态硬盘特有的项均为SandForce主控芯片特有的,其它厂商各自单独注明。
01(001)底层数据读取错误率 Raw Read Error Rate数据为0或任意值,当前值应远大于与临界值。
底层数据读取错误率是磁头从磁盘表面读取数据时出现的错误,对某些硬盘来说,大于0的数据表明磁盘表面或者读写磁头发生问题,如介质损伤、磁头污染、磁头共振等等。
不过对希捷硬盘来说,许多硬盘的这一项会有很大的数据量,这不代表有任何问题,主要是看当前值下降的程度。
在固态硬盘中,此项的数据值包含了可校正的错误与不可校正的RAISE错误(UECC+URAISE)。
注:RAISE(Redundant Array of Independent Silicon Elements)意为独立硅元素冗余阵列,是固态硬盘特有的一种冗余恢复技术,保证内部有类似RAID 阵列的数据安全性。
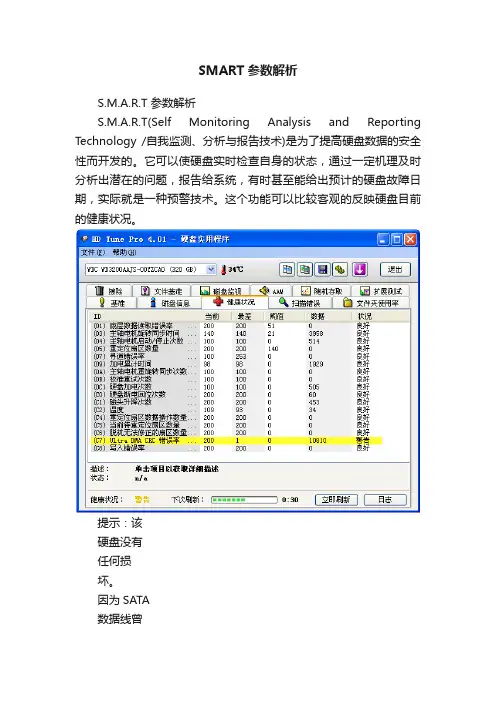
SMART参数解析S.M.A.R.T 参数解析S.M.A.R.T(Self Monitoring Analysis and Reporting Technology /自我监测、分析与报告技术)是为了提高硬盘数据的安全性而开发的。
它可以使硬盘实时检查自身的状态,通过一定机理及时分析出潜在的问题,报告给系统,有时甚至能给出预计的硬盘故障日期,实际就是一种预警技术。
这个功能可以比较客观的反映硬盘目前的健康状况。
提示:该硬盘没有任何损坏。
因为SATA数据线曾经被多次拔插过,造成SATA数据线接口处,金属弹簧触片磨损氧化、弹性下降引起的接触不良。
使(C7)值上升。
故障表现:电脑卡死、蓝屏、无法开机。
甚至硬盘丢失(BIOS里也没有硬盘信息)运行一些程序时会弹出警告:(C7)值也不再增加。
后来网上查看资料,SATA数据线有弊端:就是SATA数据线拔插次数有限,质量差的,拔插几次就没用了。
Value/Current(当前值) 当前硬盘该属性的值。
Worst(最坏值) 该属性出现过的峰值。
Threshold/Warn(阈值/临界/极限值) 硬盘厂商所规定的该属性峰值。
如果某个属性超过Threshold规定的极限值时,就表示你的硬盘可能出现了问题。
Raw Values/Data (Raw值/数据) 。
和该属性有关联的数据总值。
怎么看这类属性?主要是看Raw和Worst的值是否还在临界值之内(>或<临界值)一般使用软件如HDTune、CrystalDiskInfo等,一般属性中有黄色或者红色你就要注意了,硬盘可能快坏了,要是还在保修期内,就赶紧备份数据,送去检修。
下面我们来介绍各个属性(按2010年2月11日维基百科上的解释)指从磁盘表面读取数据时发生的硬件读取错误的比率,Raw值对于不同的厂商有着不同的体系,单纯看做1个十进制数字是没有任何意义的。
*以上为Wiki上的英文翻译版本,此属性貌似存在分歧,有的说值高了好,有的说低了好,此处我们还是按照Wiki上的吧,反正只要Worst不小于 Threshold 就行了。
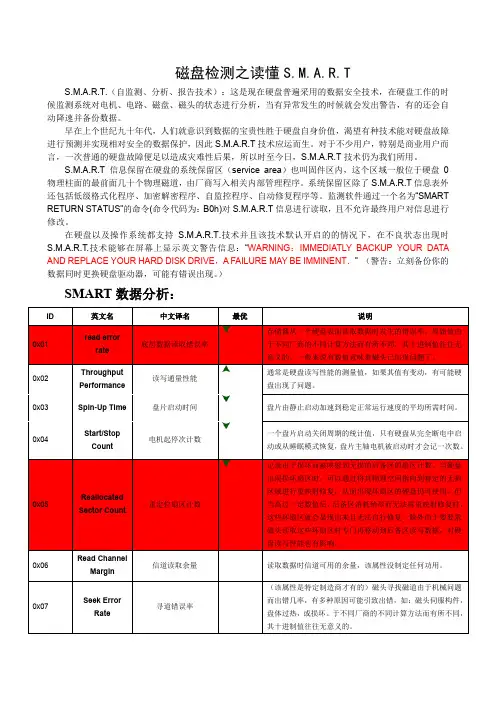
磁盘检测之读懂S.M.A.R.TS.M.A.R.T.(自监测、分析、报告技术):这是现在硬盘普遍采用的数据安全技术,在硬盘工作的时候监测系统对电机、电路、磁盘、磁头的状态进行分析,当有异常发生的时候就会发出警告,有的还会自动降速并备份数据。
早在上个世纪九十年代,人们就意识到数据的宝贵性胜于硬盘自身价值,渴望有种技术能对硬盘故障进行预测并实现相对安全的数据保护,因此S.M.A.R.T技术应运而生。
对于不少用户,特别是商业用户而言,一次普通的硬盘故障便足以造成灾难性后果,所以时至今日,S.M.A.R.T技术仍为我们所用。
S.M.A.R.T信息保留在硬盘的系统保留区(service area)也叫固件区内,这个区域一般位于硬盘0物理柱面的最前面几十个物理磁道,由厂商写入相关内部管理程序。
系统保留区除了S.M.A.R.T信息表外还包括低级格式化程序、加密解密程序、自监控程序、自动修复程序等。
监测软件通过一个名为“SMART RETURN STATUS”的命令(命令代码为:B0h)对S.M.A.R.T信息进行读取,且不允许最终用户对信息进行修改。
在硬盘以及操作系统都支持S.M.A.R.T.技术并且该技术默认开启的的情况下,在不良状态出现时S.M.A.R.T.技术能够在屏幕上显示英文警告信息:“WARNING:IMMEDIATLY BACKUP YOUR DATA AND REPLACE YOUR HARD DISK DRIVE,A FAILURE MAY BE IMMINENT.” (警告:立刻备份你的数据同时更换硬盘驱动器,可能有错误出现。
)SMART数据分析:例如用任意软件查看硬盘的SMART结果如下:S.M.A.R.T检测参数分为7列,分别是ID检测代码、属性描述、属性值、最大错误值、阈值、实际值和属性状态。
ID检测代码(ID)ID检测代码不是唯一的,厂商可以根据需要,使用不同的ID代码或根据检测参数的多少增减ID代码的数量。

1 磁盘smart信息介绍S.M.A.R.T的全称为“Self-Monitoring,Analysis and Reporting Technology”,即“自我监测、分析及报告技术”。
支持S.M.A.R.T技术的硬盘可以通过硬盘上的监测指令和主机上的监测软件对磁头、盘片、马达、电路的运行情况、历史记录及预设的安全值进行分析、比较。
当出现安全值范围以外的情况时,就会自动向用户发出警告。
磁盘Smart信息中包含各种值的介绍:1、属性当前值(value)属性值是指硬盘出厂时预设的最大正常值,一般范围为1~253。
通常,最大的属性值等于100(适用于IBM、富士通)或253(适用于三星)。
当然,也有例外的时候,比如由西部数据公司生产的部分型号硬盘,就用了两个不同的属性值,最初生产时属性值设为200,但后来生产的有些硬盘属性值又改为100。
2、最大出错值(Worst)最大出错值是硬盘运行中曾出现过的最大的非正常值。
它是对硬盘累计运行的计算值,根据运行周期,该数值会不断地刷新,并且会非常接近阈值。
S.M.A.R.T分析和判定硬盘的状态是否正常,就是根据这个数值和阈值的比较结果而定。
新硬盘开始时有最大的属性值,但随着日常使用或出现错误,该值会不断减小。
因此,较大的属性值意味着硬盘质量较好而且可靠性较高,而较小的属性值则意味着故障发生的可能性增大。
3、实际值(Date)是硬盘各检测项目运行中的实际数值,很多项目是累计值。
例如:Start/Stop Count(启停次数),累计的实际值是436,即该硬盘从开始到现在累计加电启停436次。
4、属性状态(Status)这是S.M.A.R.T针对前面的各项属性值进行比较分析后,提供的硬盘各属性目前的状态,也是我们直观判断硬盘“健康”状态的重要信息。
根据S.M.A.R.T的规定,这种状态一般有正常、警告和报告故障或错误等3种状态。
5、阈值(Threshold)又称门限值。

硬盘SMART参数解释Raw Read Error Rate 底层读取错误率,⾼值暗⽰盘体/磁头有问题Throughput Performance 读写通量性能 (越⾼越好) * ⼀般在进⾏了⼈⼯ Offline S.M.A.R.T. 测试以后才会有值。
Spin Up Time 电机起转时间,单位为秒或者毫秒Start/Stop Count 电机起停次计数,⾼值暗⽰故障概率增加Reallocated Sector Count 重定位扇区计数,表⽰硬件已经发现了多少坏扇区* 理想情况下这个值应该为0,如果不为0也不要太惊慌,⽽是应该⽐较密切的关注这个值的变化情况:如果连续⼏周没有变化,那你应该可以放⼼的继续使⽤⽐较长的⼀段时间;如果这个值持续攀升,那么请尽快备份所有数据,并考虑购买新硬盘。
Seek Error Rate 寻道错误率,这个视硬盘⼚家⽽定,有的⼚新硬盘都会有* ⼀般不为零也不要紧,但是如果持续升⾼,暗⽰盘体/磁头机械有问题。
Seek Time Performance 寻道性能 (越⾼越好),如果持续减低,暗⽰盘体/磁头机械有问题Power-On Hours 磁盘加电时间。
* 参考磁盘⼚家给的该款硬盘的 MTBF(平均故障间隔时间) 可以估计故障概率。
但是也有可能超过MTBF⽽不会出现故障,因为统计数据对于个体来说是不精确的v-Spin Retry Count 电机起转重试,理想情况应该为0,⾮0表⽰电机或者控制芯⽚可能存在问题* 当然,在某些情况下可能认为造成这个值的⾮故障升⾼,⽐如电压供给不⾜。
Recalibration Retries 磁头校准重试,⾼值暗⽰磁头机械有问题Device Power Cycle Count 设备开关计数,⾼值暗⽰故障概率增加mSoft Read Error Rate 软件读取错误率,⾼值暗⽰有扇区不稳定G-Sense Error Rate 加速度错误率* ⼀般存在于笔记本硬盘和企业级硬盘中,表⽰硬盘受到的可能导致故障的冲击次数。

SMART详解1、查看SMART状态Worst=最坏值;这个名称容易产生歧意,其实就是某个属性出现过的峰值;Value=目前的值;Threshold=阈值/极限值;如果磁盘的某个属性超过阈值时,就表示该盘出现了问题;Status=状态;OK表示正常;FAIL表示磁盘已经出现问题了;如果当一个参数的数值(Value)往阈值(Threshold)变化,就表示该项参数在恶化,也许是常态的老化现象,也许是出现了问题;相反的,如果往门槛值的反方向变化时,则表示该问题在改善,或是状况已经暂时解除。
但不管怎样,只要数值(Value)曾低于阈值(包括Worst),就代表这颗磁盘快挂了,应该尽快备份数据。
SMART数据会因硬盘厂商和产品型号的不同而有差异,不过不必担心,因为关键属性是任何一款硬盘都不会遗漏的。
那什么叫关键属性?其实SMART的属性分为Critical Attributes和Informative Attributes两类,关键属性和信息属性。
其中关键属性包括了有关硬盘健康的最重要的数据,而信息属性所提供的数据一般只是辅助性的,相对来说比较次要的。
区分它们的方法是看threshold(阈值/极限值),值为非零代表关键属性,为零代表信息属性。
2、S.M.A.R.T.AttributesID Hex Attribute name Description0101Read Error Rate读取出错率Indicates the rate of hardware read errors that occurred when readingdata from a disk surface.The raw value has different structure fordifferent vendors and is often not meaningful as a decimal number.0202ThroughputPerformance输出性能Overall(general)throughput performance of a hard disk drive.If thevalue of this attribute is decreasing there is a high probability thatthere is a problem with the disk.0303Spin-Up Time旋上时间Average time of spindle spin up(from zero RPM to fully operational[millisecs]).硬盘马达达到规定转速所花费的时间0404Start/Stop Count启停次数A tally of spindle start/stop cycles.The spindle turns on,and hencethe count is increased,both when the hard disk is turned on afterhaving before been turned entirely off(disconnected from powersource)and when the hard disk returns from having previously beenput to sleep mode.[13]硬盘马达启动/停止的次数。
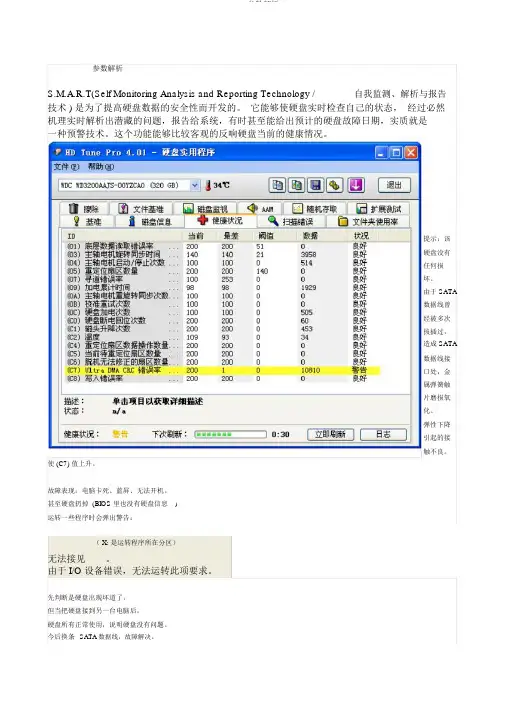
参数解析S.M.A.R.T(Self Monitoring Analysis and Reporting Technology /自我监测、解析与报告技术 ) 是为了提高硬盘数据的安全性而开发的。
它能够使硬盘实时检查自己的状态,经过必然机理实时解析出潜藏的问题,报告给系统,有时甚至能给出预计的硬盘故障日期,实质就是一种预警技术。
这个功能能够比较客观的反响硬盘当前的健康情况。
提示:该硬盘没有任何损坏。
由于 SATA数据线曾经被多次拔插过,造成 SATA数据线接口处,金属弹簧触片磨损氧化、弹性下降引起的接触不良。
使 (C7) 值上升。
故障表现:电脑卡死、蓝屏、无法开机。
甚至硬盘扔掉 (BIOS 里也没有硬盘信息)运转一些程序时会弹出警告:( X: 是运转程序所在分区)无法接见。
由于 I/O 设备错误,无法运转此项要求。
先判断是硬盘出现坏道了,但当把硬盘接到另一台电脑后,硬盘所有正常使用,说明硬盘没有问题。
今后换条SATA数据线,故障解决。
(C7) 值也不再增加。
今后网上查察资料,SATA数据线出弊端:就是 SATA数据线拔插次数有限,质量差的,拔插几次就没用了。
Value/Current(当前值)当前硬盘该属性的值。
Worst( 最坏值 )该属性出现过的峰值。
Threshold/Warn( 阈值 / 临界 / 极限值 ) 硬盘厂商所规定的该属性峰值。
若是某个属性高出Threshold 规定的极限值时,就表示你的硬盘可能出现了问题。
Raw Values/Data (Raw 值/ 数据 ) 。
和该属性有关系的数据总值。
怎么看这类属性?主若是看 Raw和 Worst 的值可否还在临界值之内(> 或<临界值 )一般使用软件如 HDTune、CrystalDiskInfo 等,一般属性中有黄色也许红色你就要注意了,硬盘可能快坏了,若是还在保修期内,就连忙备份数据,送去检修。
下面我们来介绍各个属性( 按 2010 年 2 月 11 日维基百科上的讲解)ID Hex = 英文属性名 /中文属性名属性描述01 01 =Read Error Rate / (基层)数据读取错误率指从磁盘表面读取数据时发生的硬件读取错误的比率, Raw值对于不相同的厂商有着不相同的系统,单纯看做 1 个十进制数字是没有任何意义的。
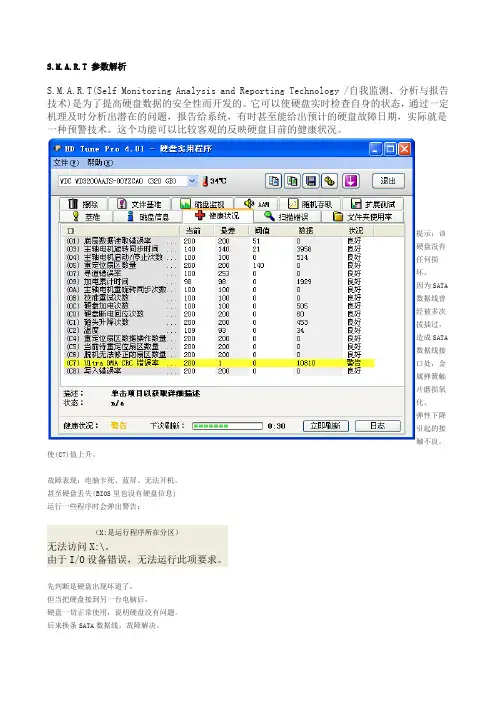
S.M.A.R.T 参数解析S.M.A.R.T(Self Monitoring Analysis and Reporting Technology /自我监测、分析与报告技术)是为了提高硬盘数据的安全性而开发的。
它可以使硬盘实时检查自身的状态,通过一定机理及时分析出潜在的问题,报告给系统,有时甚至能给出预计的硬盘故障日期,实际就是一种预警技术。
这个功能可以比较客观的反映硬盘目前的健康状况。
提示:该硬盘没有任何损坏。
因为SATA数据线曾经被多次拔插过,造成SATA数据线接口处,金属弹簧触片磨损氧化、弹性下降引起的接触不良。
使(C7)值上升。
故障表现:电脑卡死、蓝屏、无法开机。
甚至硬盘丢失(BIOS里也没有硬盘信息)运行一些程序时会弹出警告:(C7)值也不再增加。
后来网上查看资料,SATA 数据线有弊端: 就是SATA 数据线拔插次数有限, 质量差的,拔插几次就没用了。
Value/Current(当前值) 当前硬盘该属性的值。
Worst(最坏值) 该属性出现过的峰值。
Threshold/Warn(阈值/临界/极限值) 硬盘厂商所规定的该属性峰值。
如果某个属性超过Threshold 规定的极限值时,就表示你的硬盘可能出现了问题。
Raw Values/Data (Raw 值/数据) 。
和该属性有关联的数据总值。
怎么看这类属性?主要是看Raw 和Worst 的值是否还在临界值之内(>或<临界值)一般使用软件如HDTune 、CrystalDiskInfo 等,一般属性中有黄色或者红色你就要注意了,硬盘可能快坏了,要是还在保修期内,就赶紧备份数据,送去检修。
下面我们来介绍各个属性(按2010年2月11日 维基百科 上的解释)指从磁盘表面读取数据时发生的硬件读取错误的比率,Raw 值对于不同的厂商有着不同的体系,单纯看做1个十进制数字是没有任何意义的。
*以上为Wiki 上的英文翻译版本,此属性貌似存在分歧,有的说值高了好,有的说低了好,此处我们还是按照Wiki 上的吧,反正只要 Worst 不小于 Threshold 就行了。

硬盘SMART检测参数详解SMART(Self-Monitoring, Analysis and Reporting Technology)是一种嵌入在硬盘中的自我监测、分析和报告技术,用于检测硬盘的健康状况和预测可能的故障。
SMART报告显示了硬盘的各种检测参数,可以帮助用户及时采取措施以保护硬盘中的数据。
本文将详细介绍一些常见的SMART检测参数及其含义。
1. Raw Read Error Rate(原始读取错误率):表示在从硬盘中读取数据时发生的错误次数。
数值越小越好,如果该值超过了硬盘的阈值,说明硬盘的读取性能可能有问题。
2. Spin-Up Time(启动时间):指硬盘从静止状态启动到正常运转所需的时间。
数值越小越好,如果启动时间过长,可能是硬盘的电机出现了问题。
3. Start/Stop Count(启动/停止计数):指硬盘启动和停止的次数。
当硬盘的启动/停止次数超过阈值时,可能表示硬盘可能发生故障。
4. Reallocated Sectors Count(重分配扇区计数):表示硬盘因为发现一些扇区出现故障而将其重新分配给备用扇区的次数。
数值越大表示硬盘上的坏扇区越多,可能意味着硬盘的寿命已经接近尽头。
5. Seek Error Rate(寻道错误率):表示在寻找指定数据时发生的错误次数。
数值越小越好,如果这个值过高,可能是硬盘磁头或电机出现故障。
6. Power-On Hours(通电时间):指硬盘从上次通电以来的总工作时间。
数值越大表示硬盘使用时间越长,寿命可能越接近尽头。
7. Temperature(温度):硬盘的温度。
高温会对硬盘的寿命造成不利影响,用户应确保硬盘处于适宜的工作温度范围内。
8. Hardware ECC Recovered(硬件ECC恢复):表示硬盘自动纠错功能(ECC)成功恢复错误的次数。
数值越大表示纠错功能越有效。
9. Current Pending Sector Count(当前待定扇区计数):表示硬盘当前有多少个扇区出现了错误但尚未被硬盘重新分配。
电脑硬盘SMART监测与故障智能硬盘监测技术(Self-Monitoring, Analysis and Reporting Technology,简称SMART)是一种为电脑硬盘提供自动检测和监测的机制。
通过SMART技术,我们可以及时发现硬盘的潜在问题以及预测故障的可能性,从而采取相应的措施来保护重要的数据。
一、SMART技术原理及作用SMART技术通过硬盘内置的传感器和自我诊断工具来收集与硬盘运行情况相关的各种数据,包括温度、读写错误率、旋转速度、起停次数等。
通过这些数据的收集和分析,SMART技术可以对硬盘的健康状况进行评估。
当硬盘出现问题或存在潜在故障时,SMART技术会提供警告信息,使用户能够及早采取防护措施,防止数据丢失和系统崩溃的风险。
二、SMART监测的方法和工具为了实施SMART监测,我们可以使用多种方式和工具。
以下是一些常见的SMART监测工具:1. 硬盘厂商提供的监测工具:大多数硬盘厂商都提供了自家设计的SMART监测工具,用户可以从厂商官方网站下载和安装。
这些工具通常具有用户友好的界面,并可以提供详细的硬盘状态报告。
2. 第三方监测工具:除了硬盘厂商提供的工具,还有许多第三方软件也提供了SMART监测功能。
例如CrystalDiskInfo、HD Tune等。
这些工具通常具有丰富的功能和可视化界面,可以更直观地展示硬盘的运行状态。
三、SMART监测结果的解读在进行SMART监测后,我们需要对监测结果进行分析和解读。
以下是一些常见的SMART监测参数及其含义:1. 温度:硬盘的工作温度。
过高的温度可能导致硬盘寿命的缩短和数据丢失的风险。
2. 读写错误率:硬盘在读写数据时出现错误的频率。
高错误率可能意味着硬盘驱动器有坏道或其他故障。
3. 旋转速度:硬盘的旋转速度。
过低或过高的旋转速度可能导致读取和写入速度的下降,影响系统性能。
4. 起停次数:硬盘的启动和停止次数。
频繁的起停操作可能加速硬盘的磨损,增加故障风险。
SMART参数(05,C5)硬盘SMART参数中(05)是非常重要的一项,称为重新映射扇区计数(Reallocated Sectors Count),它直接表示硬盘是否已经出现了不良扇区。
以前的硬盘只要某磁道出现一个坏扇区,该磁道就算“坏磁道(Bad Track)”,修复时就整个磁道所有扇区一起“跳过(skipped)”。
所以,坏磁道和坏扇区没有区别开,一起称为“坏道”。
而现在的硬盘每个磁道划为数百上千个扇区,不能因为有一个坏扇区就丢掉整个磁道。
再说硬盘在制造完成后本身就已有相当多的不良扇区(可能有成百上千之多),所以为了提高成品率,硬盘的设计容量是大于标称容量的,多余的那部分(用户不可见的)容量就是用来弥补“制造时已出现的”以及“以后使用时新增的”不良扇区的。
这也是现代硬盘的一个自修复功能,只要这个功能在起作用,你就不会发现硬盘出现坏道,所以说“坏道”也是一个应该淘汰的老词了。
这一自修复功能的原理是:当硬盘的某扇区持续出现读/写/校验错误时,硬盘固件程序会将这个不良扇区的地址重定向到预先保留的某个备用扇区,这就称为重新映射扇区。
此后这个不良扇区不会再被使用,这等于将这个不良扇区屏蔽了,所以这样的硬盘容量不会减少,在Windows常规检测中也不会发现坏扇区,只有从SMART参数中才能发现已经有不良扇区被替换。
完好的硬盘,(05)项的数据肯定为零,当前值远大于临界值。
如果数据不为零就表示已经有不良扇区被“重映射”,被重映射的扇区增加,当前值就会下降。
如果当前值下降到接近临界值,就说明备用扇区将用尽。
与(05)项相配合的参数还有(C5)。
(C5)是当前待映射扇区计数(Current Pending Sector Count),这一参数的数据表示了“不稳定”的扇区数,即“等待被映射”的扇区数量。
因为扇区仅仅读取错误并不会导致立即重映射,只有在写入失败时才会发生重映射。
所以,如果有扇区在读取时出现错误,(C5)就会有计数,表示有扇区不稳定。
硬盘S M A R T检测参数详解Document number:NOCG-YUNOO-BUYTT-UU986-1986UT硬盘SMART检测参数详解用户最不愿意看到的事情,莫过于在毫无警告的情况下发现硬盘崩溃了。
诸如RAID的备份和存储技术可以在任何时候帮用户恢复数据,但为预防硬件崩溃造成数据丢失所花费的代价却是相当可观的,特别是在用户从来没有提前考虑过在这些情况下的应对措施时。
硬盘的故障一般分为两种:可预测的(predictable)和不可预测的(unpredictable)。
后者偶而会发生,也没有办法去预防它,例如芯片突然失效,机械撞击等。
但像电机轴承磨损、盘片磁介质性能下降等都属于可预测的情况,可以在在几天甚至几星期前就发现这种不正常的现象。
对于可预测的情况,如果能通过磁盘监控技术,通过测量硬盘的几个重要的安全参数和评估他们的情况,然后由监控软件得出两种结果:“硬盘安全”或“不久后会发生故障”。
那么在发生故障前,至少有足够的时间让使用者把重要资料转移到其它储存设备上。
最早期的硬盘监控技术起源于1992年,IBM在AS/400计算机的IBM0662SCSI2代硬盘驱动器中使用了后来被命名为PredictiveFailureAnalysis(故障预警分析技术)的监控技术,它是通过在固件中测量几个重要的硬盘安全参数和评估他们的情况,然后由监控软件得出两种结果:“硬盘安全”或“不久后会发生故障”。
不久,当时的微机制造商康柏和硬盘制造商希捷、昆腾以及康纳共同提出了名为IntelliSafe的类似技术。
通过该技术,硬盘可以测量自身的的健康指标并将参量值传送给操作系统和用户的监控软件中,每个硬盘生产商有权决定哪些指标需要被监控以及设定它们的安全阈值。
1995年,康柏公司将该技术方案提交到SmallFormAnalysisAndReportingTechnology),全称就是“自我检测分析与报告技术”,成为一种自动监控硬盘驱动器完好状况和报告潜在问题的技术标准。
检测服务器硬盘的方法概述:服务器是现代计算机网络中不可或缺的重要组成部分,而硬盘则是服务器中存储数据的关键设备。
为了确保服务器的正常运行和数据的安全性,定期检测服务器硬盘的健康状态就显得尤为重要。
本文将介绍几种常用的检测服务器硬盘的方法,帮助管理员及时发现并解决可能存在的问题。
一、使用SMART技术检测SMART(Self-Monitoring, Analysis and Reporting Technology)是一种内置在大多数硬盘上的技术,可以监测硬盘的各项指标,如温度、读写错误率、寿命等。
管理员可以通过SMART工具获取硬盘数据,并分析其中的参数,判断硬盘是否存在故障或潜在故障。
常用的SMART工具有smartmontools、HDDScan等,通过这些工具可以获取硬盘的详细信息,并进行健康状态的评估。
二、使用厂商提供的检测工具大部分硬盘厂商都提供了专门的硬盘检测工具,可以通过官方网站下载并安装。
这些工具通常可以检测硬盘的健康状态、温度、固件版本等信息,并提供详细的报告和建议。
管理员可以根据厂商提供的工具对硬盘进行全面的检测和评估,及时发现并解决问题。
三、使用第三方硬盘检测软件除了厂商提供的工具,还有一些第三方软件可以用于检测服务器硬盘。
例如,CrystalDiskInfo是一款免费的硬盘检测工具,可以监测硬盘的健康状态、温度、S.M.A.R.T信息等。
另外,HD Tune也是一款功能强大的硬盘检测和性能优化工具,可以通过扫描硬盘表面来检测坏道,并提供详细的报告和建议。
四、使用RAID控制器的监控功能如果服务器采用了RAID阵列来提高数据的可靠性和性能,那么可以通过RAID控制器的监控功能来检测硬盘。
RAID控制器通常提供了图形化的界面,可以实时监测硬盘的状态、温度、读写速度等指标,并发出警报以提醒管理员。
管理员可以通过RAID控制器的界面来查看硬盘的详细信息,并进行必要的维护和修复操作。
S.M.A.R.T 参数解析S.M.A.R.T(Self Monitoring Analysis and Reporting Technology /自我监测、分析与报告技术)是为了提高硬盘数据的安全性而开发的。
它可以使硬盘实时检查自身的状态,通过一定机理及时分析出潜在的问题,报告给系统,有时甚至能给出预计的硬盘故障日期,实际就是一种预警技术。
这个功能可以比较客观的反映硬盘目前的健康状况。
提示:该硬盘没有任何损坏。
因为SATA数据线曾经被多次拔插过,造成SATA数据线接口处,金属弹簧触片磨损氧化、弹性下降引起的接触不良。
使(C7)值上升。
故障表现:电脑卡死、蓝屏、无法开机。
甚至硬盘丢失(BIOS里也没有硬盘信息)运行一些程序时会弹出警告:(C7)值也不再增加。
后来网上查看资料,SATA数据线有弊端:就是SATA数据线拔插次数有限,质量差的,拔插几次就没用了。
Value/Current(当前值) 当前硬盘该属性的值。
Worst(最坏值) 该属性出现过的峰值。
Threshold/Warn(阈值/临界/极限值) 硬盘厂商所规定的该属性峰值。
如果某个属性超过Threshold规定的极限值时,就表示你的硬盘可能出现了问题。
Raw Values/Data (Raw值/数据) 。
和该属性有关联的数据总值。
怎么看这类属性?主要是看Raw和Worst的值是否还在临界值之内(>或<临界值)一般使用软件如HDTune、CrystalDiskInfo等,一般属性中有黄色或者红色你就要注意了,硬盘可能快坏了,要是还在保修期内,就赶紧备份数据,送去检修。
下面我们来介绍各个属性(按2010年2月11日维基百科上的解释)指从磁盘表面读取数据时发生的硬件读取错误的比率,Raw值对于不同的厂商有着不同的体系,单纯看做1个十进制数字是没有任何意义的。
*以上为Wiki上的英文翻译版本,此属性貌似存在分歧,有的说值高了好,有的说低了好,此处我们还是按照Wiki上的吧,反正只要 Worst不小于 Threshold 就行了。
硬盘SMART相关指标Linux 2010-07-07 15:42:04 阅读54 评论0 字号:大中小订阅S.M.A.R.T(Self Monitoring Analysis and Reporting Technology /自我监测、分析与报告技术)是为了提高硬盘数据的安全性而开发的。
它可以使硬盘实时检查自身的状态,通过一定机理及时分析出潜在的问题,报告给系统,有时甚至能给出预计的硬盘故障日期,实际就是一种预警技术。
这个功能可以比较客观的反映硬盘目前的健康状况。
Value/Current(当前值) 当前硬盘改属性的值。
Worst(最坏值) 该属性出现过的峰值。
Threshold/Warn(阈值/临界/极限值) 硬盘厂商所规定的该属性峰值。
如果某个属性超过Threshold规定的极限值时,就表示你的硬盘可能出现了问题。
Raw Values/Data (Raw值/数据) 。
和该属性有关联的数据总值。
怎么看这类属性?主要是看Raw和Worst的值是否还在临界值之内(>或<临界值)一般使用软件如HDTune、CrystalDiskInfo等,一般属性中有黄色或者红色你就要注意了,硬盘可能快坏了,要是还在保修期内,就赶紧备份数据,送去检修。
下面我们来介绍各个属性(按2010年2月11日维基百科上的解释)ID Hex =英文属性名/ 中文属性名属性描述--------------------------------------------------01 01 =Read Error Rate / (底层)数据读取错误率指从磁盘表面读取数据时发生的硬件读取错误的比率,Raw值对于不同的厂商有着不同的体系,单纯看做1个十进制数字是没有任何意义的。
*以上为Wiki上的英文翻译版本,此属性貌似存在分歧,有的说值高了好,有的说低了好,此处我们还是按照Wiki上的吧,反正只要Worst不小于Threshold 就行了。
SMART检测参数说明一般情况下,用户只要观察当前值、最差值和临界值的关系,并注意状态提示信息即可大致了解硬盘的健康状况。
下面简单介绍各参数的含义,以红色标出的项目是寿命关键项,蓝色为固态硬盘(SSD)特有的项目。
在基于闪存的固态硬盘中,存储单元分为两类:SLC(Single Layer Cell,单层单元)和MLC(Multi-Level Cell,多层单元)。
SLC成本高、容量小、但读写速度快,可靠性高,擦写次数可高达100000次,比MLC高10倍。
而MLC虽容量大、成本低,但其性能大幅落后于SLC。
为了保证MLC的寿命,控制芯片还要有智能磨损平衡技术算法,使每个存储单元的写入次数可以平均分摊,以达到100万小时的平均无故障时间。
因此固态硬盘有许多SMART参数是机械硬盘所没有的,如存储单元的擦写次数、备用块统计等等,这些新增项大都由厂家自定义,有些尚无详细的解释,有些解释也未必准确,此处也只是仅供参考。
下面凡未注明厂商的固态硬盘特有的项均为SandForce主控芯片特有的,其它厂商各自单独注明。
01(001)底层数据读取错误率 Raw Read Error Rate数据为0或任意值,当前值应远大于与临界值。
底层数据读取错误率是磁头从磁盘表面读取数据时出现的错误,对某些硬盘来说,大于0的数据表明磁盘表面或者读写磁头发生问题,如介质损伤、磁头污染、磁头共振等等。
不过对希捷硬盘来说,许多硬盘的这一项会有很大的数据量,这不代表有任何问题,主要是看当前值下降的程度。
在固态硬盘中,此项的数据值包含了可校正的错误与不可校正的RAISE错误(UECC+URAISE)。
注:RAISE(Redundant Array of Independent Silicon Elements)意为独立硅元素冗余阵列,是固态硬盘特有的一种冗余恢复技术,保证内部有类似RAID 阵列的数据安全性。
02(002)磁盘读写通量性能 Throughput Performance此参数表示硬盘的读写通量性能,数据值越大越好。
当前值如果偏低或趋近临界值,表示硬盘存在严重的问题,但现在的硬盘通常显示数据值为0或根本不显示此项,一般在进行了人工脱机SMART测试后才会有数据量。
03(003)主轴起旋时间 Spin Up Time主轴起旋时间就是主轴电机从启动至达到额定转速所用的时间,数据值直接显示时间,单位为毫秒或者秒,因此数据值越小越好。
不过对于正常硬盘来说,这一项仅仅是一个参考值,硬盘每次的启动时间都不相同,某次启动的稍慢些也不表示就有问题。
硬盘的主轴电机从启动至达到额定转速大致需要4秒~15秒左右,过长的启动时间说明电机驱动电路或者轴承机构有问题。
旦这一参数的数据值在某些型号的硬盘上总是为0,这就要看当前值和最差值来判断了。
对于固态硬盘来说,所有的数据都是保存在半导体集成电路中,没有主轴电机,所以这项没有意义,数据固定为0,当前值固定为100。
04(004)启停计数Start/Stop Count这一参数的数据是累计值,表示硬盘主轴电机启动/停止的次数,新硬盘通常只有几次,以后会逐渐增加。
系统的某些功能如空闲时关闭硬盘等会使硬盘启动/停止的次数大为增加,在排除定时功能的影响下,过高的启动/停止次数(远大于通电次数0C)暗示硬盘电机及其驱动电路可能有问题。
这个参数的当前值是依据某种公式计算的结果,例如对希捷某硬盘来说临界值为20,当前值是通过公式“100-(启停计数/1024)”计算得出的。
若新硬盘的启停计数为0,当前值为100-(0/1024)=100,随着启停次数的增加,该值不断下降,当启停次数达到81920次时,当前值为100-(81920/1024)=20,已达到临界值,表示从启停次数来看,该硬盘已达设计寿命,当然这只是个寿命参考值,并不具有确定的指标性。
这一项对于固态硬盘同样没有意义,数据固定为0,当前值固定为100。
05(005)重映射扇区计数Reallocated Sectors Count/退役块计数Retired Block Count数据应为0,当前值应远大于临界值。
当硬盘的某扇区持续出现读/写/校验错误时,硬盘固件程序会将这个扇区的物理地址加入缺陷表(G-list),将该地址重新定向到预先保留的备用扇区并将其中的数据一并转移,这就称为重映射。
执行重映射操作后的硬盘在Windows常规检测中是无法发现不良扇区的,因其地址已被指向备用扇区,这等于屏蔽了不良扇区。
这项参数的数据值直接表示已经被重映射扇区的数量,当前值则随着数据值的增加而持续下降。
当发现此项的数据值不为零时,要密切注意其发展趋势,若能长期保持稳定,则硬盘还可以正常运行;若数据值不断上升,说明不良扇区不断增加,硬盘已处于不稳定状态,应当考虑更换了。
如果当前值接近或已到达临界值(此时的数据值并不一定很大,因为不同硬盘保留的备用扇区数并不相同),表示缺陷表已满或备用扇区已用尽,已经失去了重映射功能,再出现不良扇区就会显现出来并直接导致数据丢失。
这一项不仅是硬盘的寿命关键参数,而且重映射扇区的数量也直接影响硬盘的性能,例如某些硬盘会出现数据量很大,但当前值下降不明显的情况,这种硬盘尽管还可正常运行,但也不宜继续使用。
因为备用扇区都是位于磁盘尾部(靠近盘片轴心处),大量的使用备用扇区会使寻道时间增加,硬盘性能明显下降。
这个参数在机械硬盘上是非常敏感的,而对于固态硬盘来说同样具有重要意义。
闪存的寿命是正态分布的,例如说MLC能写入一万次以上,实际上说的是写入一万次之前不会发生“批量损坏”,但某些单元可能写入几十次就损坏了。
换言之,机械硬盘的盘片不会因读写而损坏,出现不良扇区大多与工艺质量相关,而闪存的读写次数则是有限的,因而损坏是正常的。
所以固态硬盘在制造时也保留了一定的空间,当某个存储单元出现问题后即把损坏的部分隔离,用好的部分来顶替。
这一替换方法和机械硬盘的扇区重映射是一个道理,只不过机械硬盘正常时极少有重映射操作,而对于固态硬盘是经常性的。
在固态硬盘中这一项的数据会随着使用而不断增长,只要增长的速度保持稳定就可以。
通常情况下,数据值=100-(100×被替换块/必需块总数),因此也可以估算出硬盘的剩余寿命。
Intel固态硬盘型号的第十二个字母表示了两种规格,该字母为1表示第一代的50纳米技术的SSD,为2表示第二代的34纳米技术的SSD,如SSDSA2M160G2GN就表示是34nm的SSD。
所以参数的查看也有两种情况:50nm的SSD(一代)要看当前值。
这个值初始是100,当出现替换块的时候这个值并不会立即变化,一直到已替换四个块时这个值变为1,之后每增加四个块当前值就+1。
也就是100对应0~3个块,1对应4~7个块,2对应8~11个块……34nm的SSD(二代)直接查看数据值,数据值直接表示有多少个被替换的块。
06(006)读取通道余量 Read Channel Margin这一项功能不明,现在的硬盘也不显示这一项。
07(007)寻道错误率Seek Error Rate数据应为0,当前值应远大于与临界值。
这一项表示磁头寻道时的错误率,有众多因素可导致寻道错误率上升,如磁头组件的机械系统、伺服电路有局部问题,盘片表面介质不良,硬盘温度过高等等。
通常此项的数据应为0,但对希捷硬盘来说,即使是新硬盘,这一项也可能有很大的数据量,这不代表有任何问题,还是要看当前值是否下降。
08(008)寻道性能Seek Time Performance此项表示硬盘寻道操作的平均性能(寻道速度),通常与前一项(寻道错误率)相关联。
当前值持续下降标志着磁头组件、寻道电机或伺服电路出现问题,但现在许多硬盘并不显示这一项。
09(009)通电时间累计Power-On Time Count (POH)这个参数的含义一目了然,表示硬盘通电的时间,数据值直接累计了设备通电的时长,新硬盘当然应该接近0,但不同硬盘的计数单位有所不同,有以小时计数的,也有以分、秒甚至30秒为单位的,这由磁盘制造商来定义。
这一参数的临界值通常为0,当前值随着硬盘通电时间增加会逐渐下降,接近临界值表明硬盘已接近预计的设计寿命,当然这并不表明硬盘将出现故障或立即报废。
参考磁盘制造商给出的该型号硬盘的MTBF(平均无故障时间)值,可以大致估计剩余寿命或故障概率。
对于固态硬盘,要注意“设备优先电源管理功能(device initiated power management,DIPM)”会影响这个统计:如果启用了DIPM,持续通电计数里就不包括睡眠时间;如果关闭了DIPM功能,那么活动、空闲和睡眠三种状态的时间都会被统计在内。
0A(010)主轴起旋重试次数Spin up Retry Count数据应为0,当前值应大于临界值。
主轴起旋重试次数的数据值就是主轴电机尝试重新启动的计数,即主轴电机启动后在规定的时间里未能成功达到额定转速而尝试再次启动的次数。
数据量的增加表示电机驱动电路或是机械子系统出现问题,整机供电不足也会导致这一问题。
0B(011)磁头校准重试计数Calibration Retry Count数据应为0,当前值应远大于与临界值。
硬盘在温度发生变化时,机械部件(特别是盘片)会因热胀冷缩出现形变,因此需要执行磁头校准操作消除误差,有的硬盘还内置了磁头定时校准功能。
这一项记录了需要再次校准(通常因上次校准失败)的次数。
这一项的数据量增加,表示电机驱动电路或是机械子系统出现问题,但有些型号的新硬盘也有一定的数据量,并不表示有问题,还要看当前值和最差值。
0C(012)通电周期计数Power Cycle Count通电周期计数的数据值表示了硬盘通电/断电的次数,即电源开关次数的累计,新硬盘通常只有几次。
这一项与启停计数(04)是有区别的,一般来说,硬盘通电/断电意味着计算机的开机与关机,所以经历一次开关机数据才会加1;而启停计数(04)表示硬盘主轴电机的启动/停止(硬盘在运行时可能多次启停,如系统进入休眠或被设置为空闲多少时间而关闭)。
所以大多情况下这个通电/断电的次数会小于启停计数(04)的次数。
通常,硬盘设计的通电次数都很高,如至少5000次,因此这一计数只是寿命参考值,本身不具指标性。
0D(013)软件读取错误率Soft Read Error Rate软件读取错误率也称为可校正的读取误码率,就是报告给操作系统的未经校正的读取错误。
数据值越低越好,过高则可能暗示盘片磁介质有问题。
AA(170)坏块增长计数Grown Failing Block Count(Micron 镁光)读写失败的块增长的总数。
AB(171)编程失败块计数Program Fail Block CountFlash编程失败块的数量。