8第八章Linux下的系统调用
- 格式:pdf
- 大小:217.76 KB
- 文档页数:15

LinuxC讲解系统调⽤readdir,readdir_r以及如何遍历⽬录下的所有⽂件readdir与readdir_r简要说明readdir可以⽤来遍历指定⽬录路径下的所有⽂件。
不过,不包含⼦⽬录的⼦⽂件,如果要递归遍历,可以使⽤深度遍历,或者⼴度遍历算法。
readdir_r 是readdir的可重⼊版本,线程安全。
readdir因为直接返回了⼀个static的struct dirent,因此是⾮线程安全。
readdir如何遍历⽬录⼦⽂件?1. opendir打开⽬录opendir有2个版本:opendir,fopendir。
前者参数为⽬录对应字符串,后者参数为⽬录对应已打开⽂件描述符。
#include <sys/types.h>#include <dirent.h>DIR *opendir(const char *name);DIR *fdopendir(int fd);⽤法模型:DIR *dirp;const char *base_dir = "/home/martin/document";if ((dirp = opendir(base_dir)) != NULL) {perror("opendir error");return -1;}// 调⽤readdir遍历⽬录⼦⽂件...closedir(base_dir);2. readdir遍历⽬录⼦⽂件readdir需要⼀个已打开(调⽤opendir)的DIR对象作为参数。
#include <dirent.h>struct dirent *readdir(DIR *dirp);int readdir_r(DIR *dirp, struct dirent *entry, struct dirent **result);dirent 结构定义struct dirent {ino_t d_ino; /* inode number i节点编号 */off_t d_off; /* not an offset; see NOTES 早期⽂件系统中,telldir返回⽂件在⽬录内的偏移 */unsigned short d_reclen; /* length of this record dirent 记录的实际长度 */unsigned char d_type; /* type of file; not supportedby all filesystem types ⽂件类型 */char d_name[256]; /* filename ⽂件名 */};成员介绍:d_ino i节点编号,操作系统⽤来识别⽂件的,每个⽂件都有⼀个inode number(参见)d_off 早期⽂件系统中,⽂件系统使⽤平⾯表格,telldir返回⽂件在⽬录内的偏移,⽽d_off就代表这个偏移的缓存。




Linux内核中系统调用详解什么是系统调用?(Linux)内核中设置了一组用于实现各种系统功能的子程序,称为系统调用。
用户可以通过系统调用命令在自己的应用程序中调用它们。
从某种角度来看,系统调用和普通的函数调用非常相似。
区别仅仅在于,系统调用由(操作系统)核心提供,运行于核心态;而普通的函数调用由函数库或用户自己提供,运行于用户态。
随Linux核心还提供了一些(C语言)函数库,这些库对系统调用进行了一些包装和扩展,因为这些库函数与系统调用的关系非常紧密,所以习惯上把这些函数也称为系统调用。
为什么要用系统调用?实际上,很多已经被我们习以为常的C语言标准函数,在Linux 平台上的实现都是靠系统调用完成的,所以如果想对系统底层的原理作深入的了解,掌握各种系统调用是初步的要求。
进一步,若想成为一名Linux下(编程)高手,也就是我们常说的Hacker,其标志之一也是能对各种系统调用有透彻的了解。
即使除去上面的原因,在平常的编程中你也会发现,在很多情况下,系统调用是实现你的想法的简洁有效的途径,所以有可能的话应该尽量多掌握一些系统调用,这会对你的程序设计过程带来意想不到的帮助。
系统调用是怎么工作的?一般的,进程是不能访问内核的。
它不能访问内核所占内存空间也不能调用内核函数。
(CPU)(硬件)决定了这些(这就是为什么它被称作"保护模式")。
系统调用是这些规则的一个例外。
其原理是进程先用适当的值填充(寄存器),然后调用一个特殊的指令,这个指令会跳到一个事先定义的内核中的一个位置(当然,这个位置是用户进程可读但是不可写的)。
在(Intel)CPU中,这个由中断0x80实现。
硬件知道一旦你跳到这个位置,你就不是在限制模式下运行的用户,而是作为操作系统的内核--所以你就可以为所欲为。
进程可以跳转到的内核位置叫做sysem_call。
这个过程检查系统调用号,这个号码告诉内核进程请求哪种服务。
然后,它查看系统调用表(sys_call_table)找到所调用的内核函数入口地址。
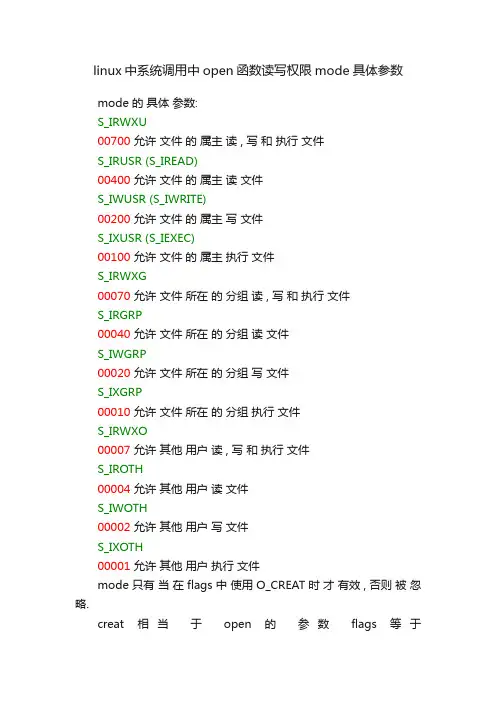
linux中系统调用中open函数读写权限mode具体参数
mode 的具体参数:
S_IRWXU
00700 允许文件的属主读 , 写和执行文件
S_IRUSR (S_IREAD)
00400允许文件的属主读文件
S_IWUSR (S_IWRITE)
00200允许文件的属主写文件
S_IXUSR (S_IEXEC)
00100允许文件的属主执行文件
S_IRWXG
00070允许文件所在的分组读 , 写和执行文件
S_IRGRP
00040允许文件所在的分组读文件
S_IWGRP
00020允许文件所在的分组写文件
S_IXGRP
00010允许文件所在的分组执行文件
S_IRWXO
00007允许其他用户读 , 写和执行文件
S_IROTH
00004允许其他用户读文件
S_IWOTH
00002允许其他用户写文件
S_IXOTH
00001允许其他用户执行文件
mode 只有当在 flags 中使用 O_CREAT 时才有效 , 否则被忽略.
creat 相当于open 的参数flags 等于
O_CREAT|O_WRONLY|O_TRUNC.。

功能描述:获取或设定资源使用限制。
每种资源都有相关的软硬限制,软限制是内核强加给相应资源的限制值,硬限制是软限制的最大值。
非授权调用进程只可以将其软限制指定为0~硬限制范围中的某个值,同时能不可逆转地降低其硬限制。
授权进程可以任意改变其软硬限制。
RLI M_INFINITY的值表示不对资源限制。
用法:#include <sys/resource.h>int getrlimit(int resource, struct rlimit *rlim);int setrlimit(int resource, const struct rlimit *rlim);参数:resource:可能的选择有RLIMIT_AS//进程的最大虚内存空间,字节为单位。
RLIMIT_CORE//内核转存文件的最大长度。
RLIMIT_CPU//最大允许的CPU使用时间,秒为单位。
当进程达到软限制,内核将给其发送SIGXCPU信号,这一信号的默认行为是终止进程的执行。
然而,可以捕捉信号,处理句柄可将控制返回给主程序。
如果进程继续耗费CPU时间,核心会以每秒一次的频率给其发送SIGXCPU信号,直到达到硬限制,那时将给进程发送SIGKILL信号终止其执行。
RLIMIT_DATA//进程数据段的最大值。
RLIMIT_FSIZE//进程可建立的文件的最大长度。
如果进程试图超出这一限制时,核心会给其发送SIGXFSZ信号,默认情况下将终止进程的执行。
RLIMIT_LOCKS//进程可建立的锁和租赁的最大值。
RLIMIT_MEMLOCK//进程可锁定在内存中的最大数据量,字节为单位。
RLIMIT_MSGQUEUE//进程可为POSIX消息队列分配的最大字节数。
RLIMIT_NICE//进程可通过setpriority() 或nice()调用设置的最大完美值。
RLIMIT_NOFILE//指定比进程可打开的最大文件描述词大一的值,超出此值,将会产生EMFILE错误。


linux命令——strace命令(跟踪进程中的系统调⽤)strace常⽤来跟踪进程执⾏时的系统调⽤和所接收的信号。
在Linux世界,进程不能直接访问硬件设备,当进程需要访问硬件设备(⽐如读取磁盘⽂件,接收⽹络数据等等)时,必须由⽤户态模式切换⾄内核态模式,通过系统调⽤访问硬件设备。
strace可以跟踪到⼀个进程产⽣的系统调⽤,包括参数,返回值,执⾏消耗的时间。
1、参数每⼀⾏都是⼀条系统调⽤,等号左边是系统调⽤的函数名及其参数,右边是该调⽤的返回值。
strace 显⽰这些调⽤的参数并返回符号形式的值。
strace 从内核接收信息,⽽且不需要以任何特殊的⽅式来构建内核。
$strace cat /dev/nullexecve("/bin/cat", ["cat", "/dev/null"], [/* 22 vars */]) = 0brk(0) = 0xab1000access("/etc/ld.so.nohwcap", F_OK) = -1 ENOENT (No such file or directory)mmap(NULL, 8192, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f29379a7000access("/etc/ld.so.preload", R_OK) = -1 ENOENT (No such file or directory)...参数含义-c 统计每⼀系统调⽤的所执⾏的时间,次数和出错的次数等.-d 输出strace关于标准错误的调试信息.-f 跟踪由fork调⽤所产⽣的⼦进程.-ff 如果提供-o filename,则所有进程的跟踪结果输出到相应的filename.pid中,pid是各进程的进程号.-F 尝试跟踪vfork调⽤.在-f时,vfork不被跟踪.-h 输出简要的帮助信息.-i 输出系统调⽤的⼊⼝指针.-q 禁⽌输出关于脱离的消息.-r 打印出相对时间关于,,每⼀个系统调⽤.-t 在输出中的每⼀⾏前加上时间信息.-tt 在输出中的每⼀⾏前加上时间信息,微秒级.-ttt 微秒级输出,以秒了表⽰时间.-T 显⽰每⼀调⽤所耗的时间.-v 输出所有的系统调⽤.⼀些调⽤关于环境变量,状态,输⼊输出等调⽤由于使⽤频繁,默认不输出.-V 输出strace的版本信息.-x 以⼗六进制形式输出⾮标准字符串-xx 所有字符串以⼗六进制形式输出.-a column设置返回值的输出位置.默认为40.-e expr指定⼀个表达式,⽤来控制如何跟踪.格式如下:[qualifier=][!]value1[,value2]...qualifier只能是 trace,abbrev,verbose,raw,signal,read,write其中之⼀.value是⽤来限定的符号或数字.默认的 qualifier是 trace.感叹号是否定符号.例如:-eopen等价于 -e trace=open,表⽰只跟踪open调⽤.⽽-etrace!=open表⽰跟踪除了open以外的其他调⽤.有两个特殊的符号 all 和 none.注意有些shell使⽤!来执⾏历史记录⾥的命令,所以要使⽤\\.-e trace=set只跟踪指定的系统调⽤.例如:-e trace=open,close,rean,write表⽰只跟踪这四个系统调⽤.默认的为set=all.-e trace=file只跟踪有关⽂件操作的系统调⽤.-e trace=process只跟踪有关进程控制的系统调⽤.-e trace=network跟踪与⽹络有关的所有系统调⽤.-e strace=signal跟踪所有与系统信号有关的系统调⽤-e trace=ipc跟踪所有与进程通讯有关的系统调⽤-e abbrev=set设定 strace输出的系统调⽤的结果集.-v 等与 abbrev=none.默认为abbrev=all.-e raw=set将指定的系统调⽤的参数以⼗六进制显⽰.-e signal=set指定跟踪的系统信号.默认为all.如 signal=!SIGIO(或者signal=!io),表⽰不跟踪SIGIO信号.-e read=set输出从指定⽂件中读出的数据.例如:-e read=3,5-e write=set输出写⼊到指定⽂件中的数据.-o filename将strace的输出写⼊⽂件filename-p pid跟踪指定的进程pid.-s strsize指定输出的字符串的最⼤长度.默认为32.⽂件名⼀直全部输出.-u username以username 的UID和GID执⾏被跟踪的命令2、使⽤实例实例1:跟踪可执⾏程序strace -f -F -o ~/straceout.txt myserver-f -F选项告诉strace同时跟踪fork和vfork出来的进程,-o选项把所有strace输出写到~/straceout.txt⾥⾯,myserver是要启动和调试的程序。


系统调用和库函数一、系统调用系统调用是操作系统提供给应用程序的接口,它允许应用程序请求操作系统执行某些特权操作,例如读写文件、创建进程、打开网络连接等。
在Linux系统中,系统调用是通过软中断来实现的。
1.1 系统调用的分类Linux系统中有很多种类型的系统调用,按照功能可以分为以下几类:1. 进程控制类:如fork()、exec()等;2. 文件操作类:如open()、read()、write()等;3. 设备操作类:如ioctl()、mmap()等;4. 网络通信类:如socket()、connect()等;5. 内存管理类:如mmap()、brk()等。
1.2 系统调用的使用方法在C语言中,可以使用unistd.h头文件中定义的函数来进行系统调用。
例如:#include <unistd.h>int main(){char buf[1024];int fd = open("test.txt", O_RDONLY);read(fd, buf, sizeof(buf));close(fd);return 0;}上面的代码就是使用了open()和read()两个系统调用来读取一个文本文件。
二、库函数库函数是一组预先编写好的函数集合,可以被应用程序直接调用。
库函数通常被编译成动态链接库或静态链接库,以便于应用程序使用。
在Linux系统中,常见的库函数有标准C库函数、数学库函数、字符串处理库函数等。
2.1 标准C库函数标准C库函数是C语言提供的一组基本的函数,包括输入输出、字符串处理、内存管理等方面。
在Linux系统中,标准C库通常是glibc。
下面是一些常用的标准C库函数:1. 输入输出类:printf()、scanf()、fopen()、fclose()等;2. 字符串处理类:strcpy()、strcat()、strlen()等;3. 内存管理类:malloc()、calloc()、realloc()等。
linux操作系统原理Linux操作系统是一种开源的、多用户、多任务的操作系统,基于Unix的设计理念和技术,由芬兰的林纳斯·托瓦兹(Linus Torvalds)在1991年首次发布。
其原理主要包括以下几个方面:1. 内核与外壳:Linux操作系统的核心是Linux内核,负责管理计算机的资源并为用户程序提供服务。
外壳(Shell)则是用户与内核之间的接口,提供命令行或图形用户界面供用户操作系统。
2. 多用户和多任务:Linux支持多用户和多任务,可以同时运行多个用户程序,并为每个用户分配资源。
多任务由调度器负责,按照一定的算法将CPU时间片分配给各个任务,以提高系统的利用率。
3. 文件系统:Linux采用统一的文件系统作为数据的存储与管理方式。
文件系统将计算机中的存储设备抽象成为一个层次化的文件和目录结构,使用户可以方便地访问和管理文件。
4. 设备管理:Linux操作系统通过设备驱动程序管理计算机的外部设备,如键盘、鼠标、打印机等。
每个设备都有相应的驱动程序,将硬件操作转换成可供内核或用户程序调用的接口。
5. 系统调用:Linux操作系统提供了一组系统调用接口,允许用户程序通过调用这些接口来访问内核提供的功能。
常见的系统调用包括文件操作、进程管理、内存管理等,通过系统调用可以使用户程序与操作系统进行交互。
6. 网络支持:Linux操作系统具有强大的网络功能,支持网络协议栈和网络设备驱动程序。
Linux可以作为服务器提供各种网络服务,如Web服务器、数据库服务器等。
7. 安全性:Linux操作系统注重安全性,提供了许多安全机制来保护系统和数据。
例如,文件权限控制、访问控制列表、加密文件系统等可以保护文件的机密性和完整性;防火墙和入侵检测系统可以保护网络安全。
总之,Linux操作系统具有高度的可定制性、稳定性和安全性,适用于服务器、嵌入式设备和个人计算机等各种场景。
在开源社区的支持下,Linux不断发展壮大,成为当今最受欢迎的操作系统之一。
【转载】Linux系统调⽤SYSCALL_DEFINE详解系统调⽤在内核中的⼊⼝都是sys_xxx,但其实Linux的系统调⽤都改为SYSCALL_DEFINE定义的。
本⽂以socket系统调⽤为例来详解。
1 ⾸先看⼀下SYSCALL_DEFINE的定义,如下:1 #define SYSCALL_DEFINE0(name) asmlinkage long sys_##name(void)2 #define SYSCALL_DEFINE1(name, ...) SYSCALL_DEFINEx(1, _##name, __VA_ARGS__)3 #define SYSCALL_DEFINE2(name, ...) SYSCALL_DEFINEx(2, _##name, __VA_ARGS__)4 #define SYSCALL_DEFINE3(name, ...) SYSCALL_DEFINEx(3, _##name, __VA_ARGS__)5 #define SYSCALL_DEFINE4(name, ...) SYSCALL_DEFINEx(4, _##name, __VA_ARGS__)6 #define SYSCALL_DEFINE5(name, ...) SYSCALL_DEFINEx(5, _##name, __VA_ARGS__)7 #define SYSCALL_DEFINE6(name, ...) SYSCALL_DEFINEx(6, _##name, __VA_ARGS__)2 宏SYSCALL_DEFINEx的定义:1 #define SYSCALL_DEFINEx(x, name, ...) \2 asmlinkage long sys##name(__SC_DECL##x(__VA_ARGS__)); \3 static inline long SYSC##name(__SC_DECL##x(__VA_ARGS__)); \4 asmlinkage long SyS##name(__SC_LONG##x(__VA_ARGS__)) \5 { \6 __SC_TEST##x(__VA_ARGS__); \7 return (long) SYSC##name(__SC_CAST##x(__VA_ARGS__)); \8 } \9 SYSCALL_ALIAS(sys##name, SyS##name); \10 static inline long SYSC##name(__SC_DECL##x(__VA_ARGS__))3 下⾯以socket系统调⽤为实例来分析,其定义:1 SYSCALL_DEFINE3(socket, int, family, int, type, int, protocol)2 {3 int retval;4 struct socket *sock;5 int flags;67 /* Check the SOCK_* constants for consistency. */8 BUILD_BUG_ON(SOCK_CLOEXEC != O_CLOEXEC);9 BUILD_BUG_ON((SOCK_MAX | SOCK_TYPE_MASK) != SOCK_TYPE_MASK);10 BUILD_BUG_ON(SOCK_CLOEXEC & SOCK_TYPE_MASK);11 BUILD_BUG_ON(SOCK_NONBLOCK & SOCK_TYPE_MASK);1213 flags = type & ~SOCK_TYPE_MASK;14 if (flags & ~(SOCK_CLOEXEC | SOCK_NONBLOCK))15 return -EINVAL;16 type &= SOCK_TYPE_MASK;1718 if (SOCK_NONBLOCK != O_NONBLOCK && (flags & SOCK_NONBLOCK))19 flags = (flags & ~SOCK_NONBLOCK) | O_NONBLOCK;2021 retval = sock_create(family, type, protocol, &sock);22 if (retval < 0)23 goto out;2425 retval = sock_map_fd(sock, flags & (O_CLOEXEC | O_NONBLOCK));26 if (retval < 0)27 goto out_release;2829 out:30 /* It may be already another descriptor 8) Not kernel problem. */31 return retval;3233 out_release:34 sock_release(sock);35 return retval;36 }3.1 ##和__VA_ARGS__其中##是连接符,__VA_ARGS__代表前⾯...⾥⾯的可变参数。
系统调⽤的实现原理【转】在看《unix/linux编程实践教程》时,忽然意识到,系统调⽤是如何实现的?在实际编程中,往往是调⽤相关的函数,⽐如open(),read()等等。
但是调⽤这些函数怎么可能让程序的运⾏在⽤户空间和内核空间切换呢?看了下⾯的⽂章,才知道怎么回事。
让我想到了《计算机组成原理》中讲到的东西。
原⽂地址:系统调⽤1什么是系统调⽤系统调⽤,顾名思义,说的是操作系统提供给⽤户程序调⽤的⼀组“特殊”接⼝。
⽤户程序可以通过这组“特殊”接⼝来获得操作系统内核提供的服务,⽐如⽤户可以通过⽂件系统相关的调⽤请求系统打开⽂件、关闭⽂件或读写⽂件,可以通过时钟相关的系统调⽤获得系统时间或设置定时器等。
从逻辑上来说,系统调⽤可被看成是⼀个内核与⽤户空间程序交互的接⼝——它好⽐⼀个中间⼈,把⽤户进程的请求传达给内核,待内核把请求处理完毕后再将处理结果送回给⽤户空间。
系统服务之所以需要通过系统调⽤来提供给⽤户空间的根本原因是为了对系统进⾏“保护”,因为我们知道Linux的运⾏空间分为内核空间与⽤户空间,它们各⾃运⾏在不同的级别中,逻辑上相互隔离。
所以⽤户进程在通常情况下不允许访问内核数据,也⽆法使⽤内核函数,它们只能在⽤户空间操作⽤户数据,调⽤⽤户空间函数。
⽐如我们熟悉的“hello world”程序(执⾏时)就是标准的⽤户空间进程,它使⽤的打印函数printf就属于⽤户空间函数,打印的字符“hello word”字符串也属于⽤户空间数据。
但是很多情况下,⽤户进程需要获得系统服务(调⽤系统程序),这时就必须利⽤系统提供给⽤户的“特殊接⼝”——系统调⽤了,它的特殊性主要在于规定了⽤户进程进⼊内核的具体位置;换句话说,⽤户访问内核的路径是事先规定好的,只能从规定位置进⼊内核,⽽不准许肆意跳⼊内核。
有了这样的陷⼊内核的统⼀访问路径限制才能保证内核安全⽆虞。
我们可以形象地描述这种机制:作为⼀个游客,你可以买票要求进⼊野⽣动物园,但你必须⽼⽼实实地坐在观光车上,按照规定的路线观光游览。
第八章 Linux下的系统调用8.1 系统调用介绍8.1.1 引言系统调用是内核提供的、功能十分强大的一系列函数。
它们在内核中实现,然后通过一定的方式(库、陷入等)呈现给用户,是用户程序与内核交互的一个接口。
如果没有系统调用,则不可能编写出十分强大的用户程序,因为失去了内核的支持。
由此可见系统调用的地位举足轻重。
内核的主体可以归结为:系统调用的集合;实现系统调用的算法。
8.1.2 系统调用的实现流程这里我们通过getuid()这个简单的系统调用来分析一下系统调用的实现流程。
在分析这个程序时并不考虑它的底层是如何实现的,而只需知道每一步执行的功能。
首先来看一个例子:#include <linux/unistd.h> /* all system call need this header*/int main(){int i=getuid();printf(“Hello World! This is my uid: %d\n”,i);}#include<linux/unistd.h>是每个系统调用都必须要的头文件,当系统执行到getuid()时,根据unistd.h中的宏定义把getuid()展开。
展开后程序把系统调用号__NR_getuid(24)放入eax,然后通过执行“int $0x80”这条指令进行模式切换,进入内核。
int 0x80指令由于是一条软中断指令,所以就要看系统规定的这条中断指令的处理程序是什么。
arch/i386/kernel/traps.cset_system_gate(SYSCALL_VECTOR,&system_call);从这行程序我们可以看出,系统规定的系统调用的处理程序就是system_call。
控制转移到内核之前,硬件会自动进行模式和堆栈的切换。
现在控制转移到了system_call,保留系统调用号的最初拷贝之后,由SAVE_ALL来保存上下文,得到该进程结构的指针,放在ebx里面,然后检查系统调用号,如果__NR_getuid(24)是合法的,则根据这个系统调用号,索引sys_call_table,得到相应的内核处理程序:sys_getuid。
执行完sys_getuid之后,保存返回值,从eax移到堆栈中的eax处,假设没有意外发生,于是ret_from_sys_call直接到RESTORE_ALL恢复上下文,从堆栈中弹出保存的寄存器,堆栈切换,iret。
执行完iret后,正如我们所分析的,进程回到用户态,返回值保存在eax中,于是得到返回值,打印:Hello World! This is my uid: 551这时这个最简单的调用系统调用的程序到这里就结束了,系统调用的流程也理了一遍。
跟系统调用相关的内核代码文件主要有:arch/i386/kernel/entry.Sinclude/linux/unistd.h下面将分别介绍这两个文件。
8.1.3 entry.S文件相关说明这个文件中包含了系统调用和异常的底层处理程序,信号量程序。
一.关于SAVE_ALL,RESTORE_ALLarch/i386/kernel/entry.S#define SAVE_ALLcld;pushl %es;pushl %ds;pushl %eax;pushl %ebp;pushl %edi;pushl %esi;pushl %edx;pushl %ecx;pushl %ebx;movl $(__KERNEL_DS),%edx;movl %edx,%ds;movl %edx,%es;#define RESTORE_ALLpopl %ebx;popl %ecx;popl %edx;popl %esi;popl %edi;popl %ebp;popl %eax;1: popl %ds;2: popl %es;addl $4,%esp;3: iret;这一部分程序主要执行的任务就是中断时保存进程的上下文以及执行中断后恢复进程上下文的环境。
二.系统调用表(sys_call_table)在这个文件中还有一个重要的地方就是维护整个系统调用的一张表――系统调用表。
系统调用表一次保存着所有系统调用的函数指针,以方便总的系统调用处理程序(system_call)进行索引调用。
arch/i386/kernel/entry.SENTRY(sys_call_table).long SYMBOL_NAME(sys_ni_syscall).long SYMBOL_NAME(sys_exit).long SYMBOL_NAME(sys_fork).long SYMBOL_NAME(sys_read)….long SYMBOL_NAME(sys_ni_syscall).long SYMBOL_NAME(sys_ni_syscall)1 .rept NR_syscalls-(.-sys_call_table)/4.long SYMBOL_NAME(sys_ni_syscall).endr1行中的‘.’代表当前地址,sys_call_table代表数组首地址,所以1行中两个变量相减,得到差值表示这个系统调用表的大小(两个地址之间相差的byte数),除以4,得到现在的系统调用个数。
用NR_syscalls 减去系统调用个数,得到的是没有定义的系统调用。
然后用.rept ….long SYMBOL_NAME(sys_ni_syscall).endr往数组的剩余空间里填充sys_ni_syscall。
三.system_call和ret_from_sys_callarch/i386/kernel/entry.SENTRY(system_call)pushl %eax # save orig_eaxSAVE_ALLGET_CURRENT(%ebx)testb $0x02,tsk_ptrace(%ebx) # PT_TRACESYSjne tracesyscmpl $(NR_syscalls),%eaxjae badsyscall *SYMBOL_NAME(sys_call_table)(,%eax,4)movl %eax,EAX(%esp) # save the return value ENTRY(ret_from_sys_call)cli # need_resched and signals atomic testcmpl $0,need_resched(%ebx)jne reschedulecmpl $0,sigpending(%ebx)jne signal_returnrestore_all:RESTORE_ALL这部分代码所完成的任务主要如下:首先,系统把eax(里面存放着系统调用号)的值压入堆栈,就是把原来的eax值保存起来,因为使用SAVE_ALL保存起来的eax要用来保存返回值。
但是在保存了返回值到真正返回到用户态还有一些事情要做,内核可能还会需要知道哪个系统调用导致进程陷入了内核。
所以,这里要保留一份eax的最初拷贝。
保存进程上下文。
取得当前进程的task_struct结构的指针返回到ebx中。
看看进程是不是被监视了,如果是则跳转到tracesys检查eax中的参数是否合法。
调用具体的系统调用代码,然后保存返回值到堆栈中。
系统调用返回。
恢复进程上下文。
最后我们用类c代码简化一下system_call过程:void system_call(unsigned int eax){task struct *ebx;save_context();ebx=GET_CURRENT;if(ebx->tsk_ptrace!=0x02)goto tracesys;if(eax>NR_syscalls)goto badsys;retval=(sys_call_table[eax*4])();if(ebx->need_resched!=0)goto reschedule;if(ebx->sigpending!=0)goto signal_return;restore_context();}8.1.4 系统调用中参数的传递及unistd.h前面讲的都是内核中的处理。
进行系统调用的时候可能是这样:getuid()。
那么内核是怎么样跟用户程序进行交互的呢?这包括控制权是怎样转移到内核中的那个system_call处理函数去的,参数是如何传递的等等。
在这里标准C库充当了很重要的角色,它是把用户希望传递的参数装载到CPU的寄存器中,然后发出0x80中断。
当从系统调用返回的时候(ret_from_sys_call)时,标准C库又接过控制权,处理返回值。
头文件include/asm-i386/unistd.h定义了所有的系统调用号,还定义了几个与系统调用相关的关键的宏。
include/asm-i386/unistd.h#define __NR_exit 1#define __NR_fork 2#define __NR_read 3#define __NR_write 4……#define __NR_exit_group 252#define __NR_lookup_dcookie 253#define __NR_set_tid_address 258很清楚,文件一开始就定义了所有的系统调用号,每一个系统调用号都以“__NR_”开头,这可以说是一种习惯,或者说是一种约定。
但事实上,它还有更方便的地方,那就是除了这个“__NR_”头外,所有的系统调用号就是你编写用户程序的那个名字。
标准库函数正是通过这样的共同性,通过宏替换,把一个个用户程序调用的诸如getuid这样的名词转换为__NR_getuid,然后再转换成相应的数字号,通过eax寄存器传递给内核作为深入syscall_table的索引。
接下来,文件连续定义了7个宏,很多系统调用都是通过这些宏,进行展开形成定义,这样用户程序才能进行系统调用。
内核也才能知道用户具体的系统调用,然后进行具体的处理。
使用这些宏把系统调用的工作基本上都是标准C库来做的,所以标准C库是用户程序和内核之间的一个桥梁。
我们可以挑选一个带3个参数的宏来看,include/asm-i386/unistd.h#define_syscall3(type,name,type1,arg1,type2,arg2,type3,arg3) type name(type1 arg1,type2 arg2,type3 arg3){long __res;__asm__ volatile ("int $0x80": "=a" (__res): "0" (__NR_##name),"b" ((long)(arg1)),"c" ((long) (arg2)),"d" ((long)(arg3)));__syscall_return(type,__res);}这个宏用于展开不用参数的系统调用,比如open(“/tmp/foo”,O_RDONLY,S_IREAD)。